 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards a variational Jordan-Lee-Preskill quantum algorithm
Sep 12, 2021
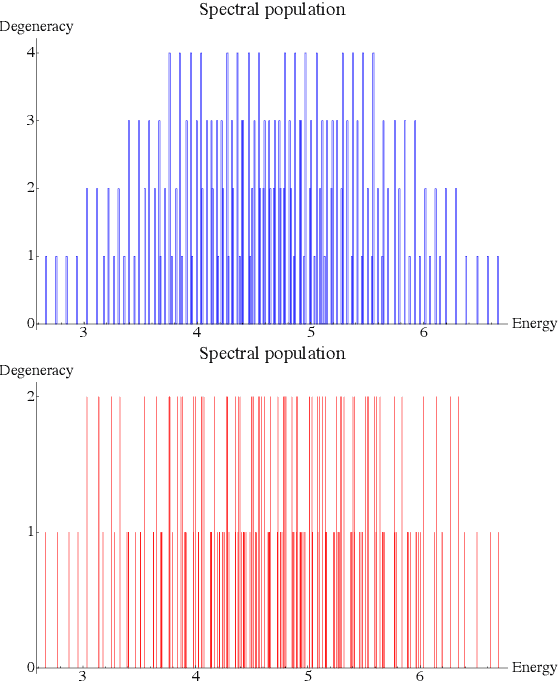
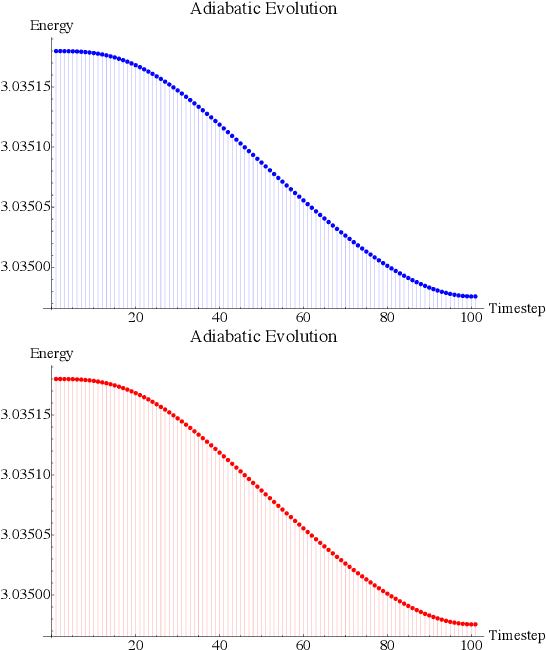
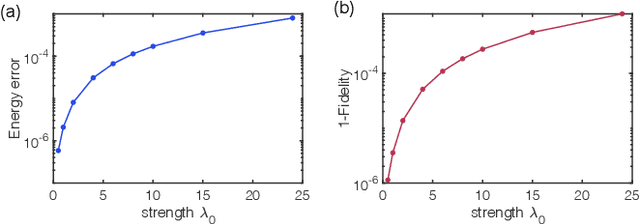
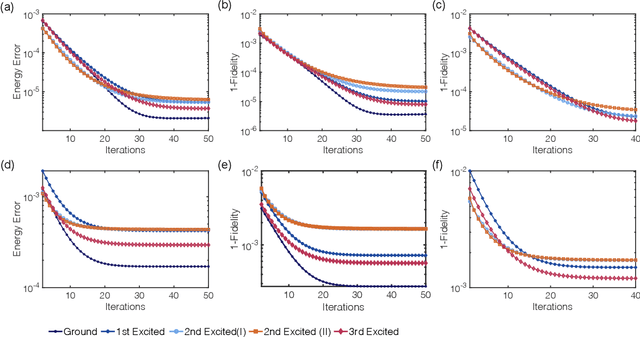
Rapid developments of quantum information technology show promising opportunities for simulating quantum field theory in near-term quantum devices. In this work, we formulate the theory of (time-dependent) variational quantum simulation, explicitly designed for quantum simulation of quantum field theory. We develop hybrid quantum-classical algorithms for crucial ingredients in particle scattering experiments, including encoding, state preparation, and time evolution, with several numerical simulations to demonstrate our algorithms in the 1+1 dimensional $\lambda \phi^4$ quantum field theory. These algorithms could be understood as near-term analogs of the Jordan-Lee-Preskill algorithm, the basic algorithm for simulating quantum field theory using universal quantum devices. Our contribution also includes a bosonic version of the Unitary Coupled Cluster ansatz with physical interpretation in quantum field theory, a discussion about the subspace fidelity, a comparison among different bases in the 1+1 dimensional $\lambda \phi^4$ theory, and the "spectral crowding" in the quantum field theory simulation.
EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2021: Team M3EM Technical Report
Jun 18, 2021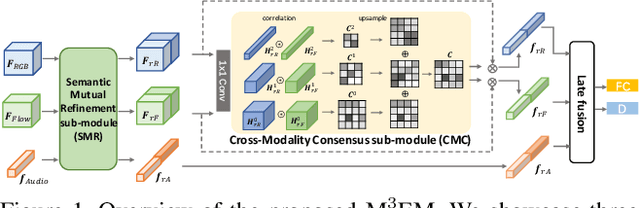

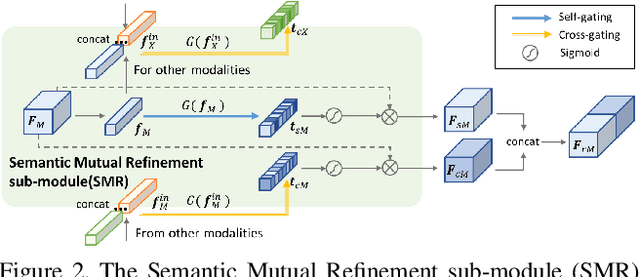
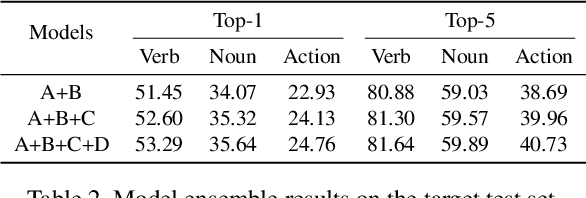
In this report, we describe the technical details of our submission to the 2021 EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition. Leveraging multiple modalities has been proved to benefit the Unsupervised Domain Adaptation (UDA) task. In this work, we present Multi-Modal Mutual Enhancement Module (M3EM), a deep module for jointly considering information from multiple modalities to find the most transferable representations across domains. We achieve this by implementing two sub-modules for enhancing each modality using the context of other modalities. The first sub-module exchanges information across modalities through the semantic space, while the second sub-module finds the most transferable spatial region based on the consensus of all modalities.
Heterogeneous Contrastive Learning
May 19, 2021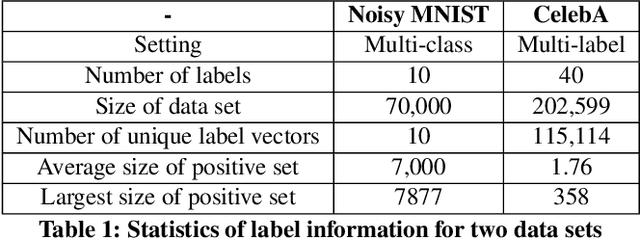
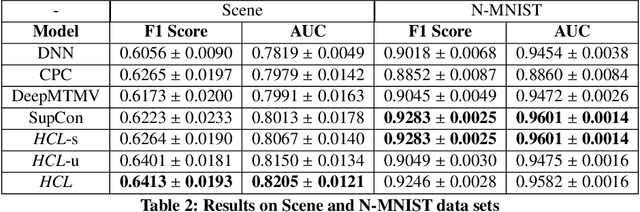
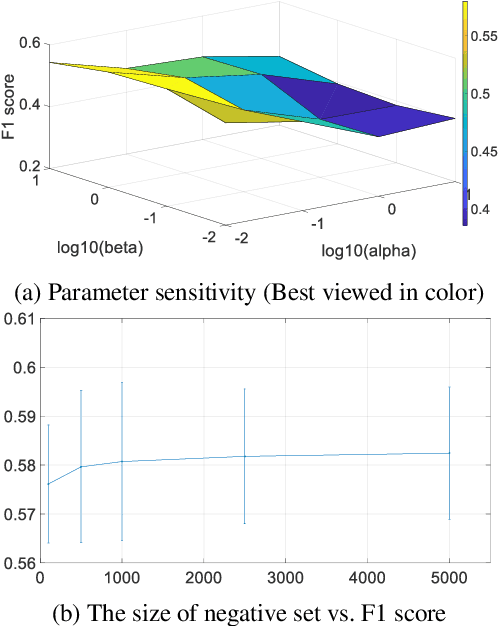
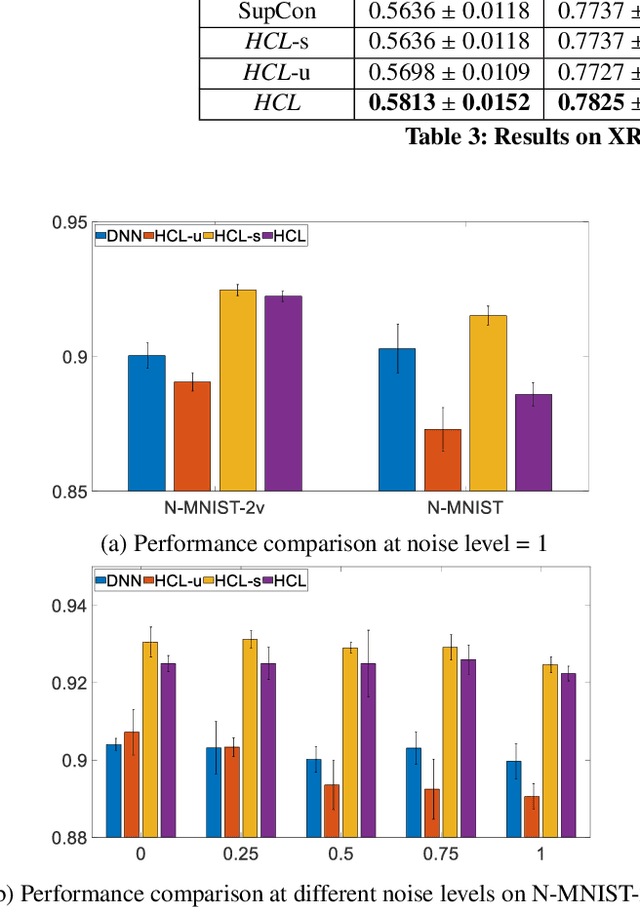
With the advent of big data across multiple high-impact applications, we are often facing the challenge of complex heterogeneity. The newly collected data usually consist of multiple modalities and characterized with multiple labels, thus exhibiting the co-existence of multiple types of heterogeneity. Although state-of-the-art techniques are good at modeling the complex heterogeneity with sufficient label information, such label information can be quite expensive to obtain in real applications, leading to sub-optimal performance using these techniques. Inspired by the capability of contrastive learning to utilize rich unlabeled data for improving performance, in this paper, we propose a unified heterogeneous learning framework, which combines both weighted unsupervised contrastive loss and weighted supervised contrastive loss to model multiple types of heterogeneity. We also provide theoretical analyses showing that the proposed weighted supervised contrastive loss is the lower bound of the mutual information of two samples from the same class and the weighted unsupervised contrastive loss is the lower bound of the mutual information between the hidden representation of two views of the same sample. Experimental results on real-world data sets demonstrate the effectiveness and the efficiency of the proposed method modeling multiple types of heterogeneity.
Inference Attacks Against Graph Neural Networks
Oct 06, 2021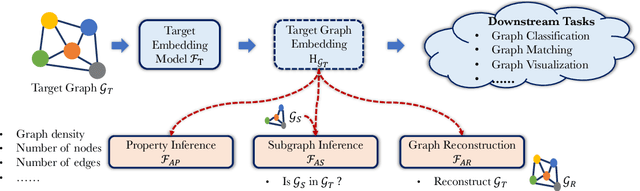
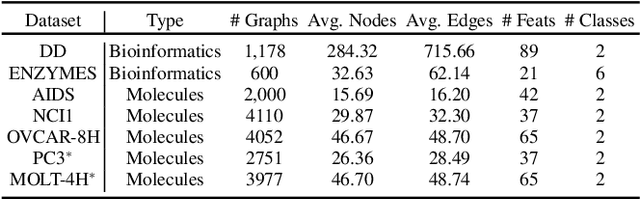
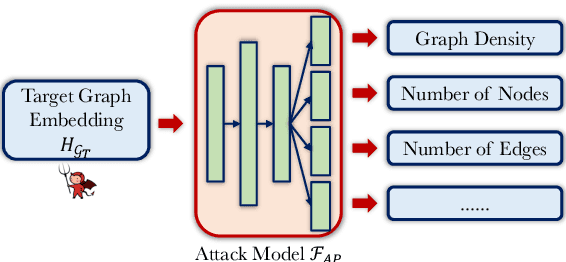

Graph is an important data representation ubiquitously existing in the real world. However, analyzing the graph data is computationally difficult due to its non-Euclidean nature. Graph embedding is a powerful tool to solve the graph analytics problem by transforming the graph data into low-dimensional vectors. These vectors could also be shared with third parties to gain additional insights of what is behind the data. While sharing graph embedding is intriguing, the associated privacy risks are unexplored. In this paper, we systematically investigate the information leakage of the graph embedding by mounting three inference attacks. First, we can successfully infer basic graph properties, such as the number of nodes, the number of edges, and graph density, of the target graph with up to 0.89 accuracy. Second, given a subgraph of interest and the graph embedding, we can determine with high confidence that whether the subgraph is contained in the target graph. For instance, we achieve 0.98 attack AUC on the DD dataset. Third, we propose a novel graph reconstruction attack that can reconstruct a graph that has similar graph structural statistics to the target graph. We further propose an effective defense mechanism based on graph embedding perturbation to mitigate the inference attacks without noticeable performance degradation for graph classification tasks. Our code is available at https://github.com/Zhangzhk0819/GNN-Embedding-Leaks.
CasEE: A Joint Learning Framework with Cascade Decoding for Overlapping Event Extraction
Jul 04, 2021
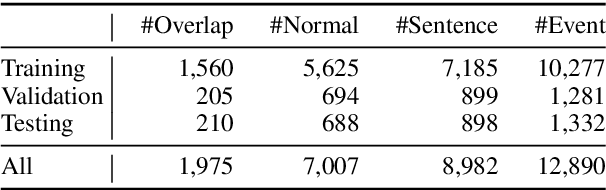
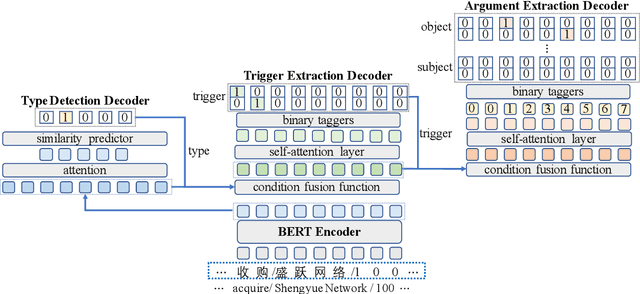
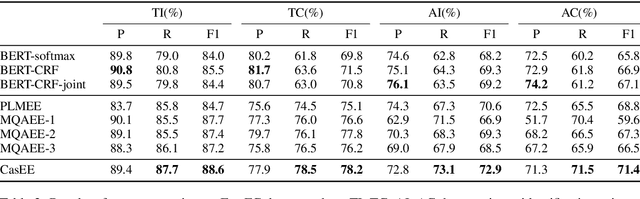
Event extraction (EE) is a crucial information extraction task that aims to extract event information in texts. Most existing methods assume that events appear in sentences without overlaps, which are not applicable to the complicated overlapping event extraction. This work systematically studies the realistic event overlapping problem, where a word may serve as triggers with several types or arguments with different roles. To tackle the above problem, we propose a novel joint learning framework with cascade decoding for overlapping event extraction, termed as CasEE. Particularly, CasEE sequentially performs type detection, trigger extraction and argument extraction, where the overlapped targets are extracted separately conditioned on the specific former prediction. All the subtasks are jointly learned in a framework to capture dependencies among the subtasks. The evaluation on a public event extraction benchmark FewFC demonstrates that CasEE achieves significant improvements on overlapping event extraction over previous competitive methods.
Relating Zipf's law to textual information
Sep 22, 2018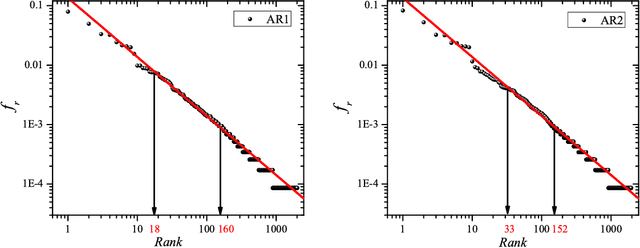
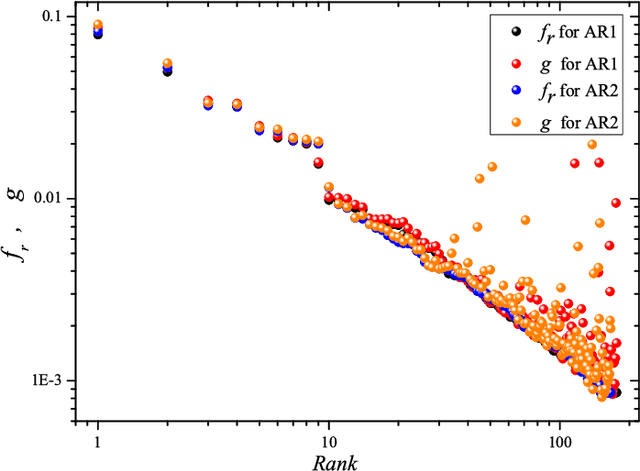
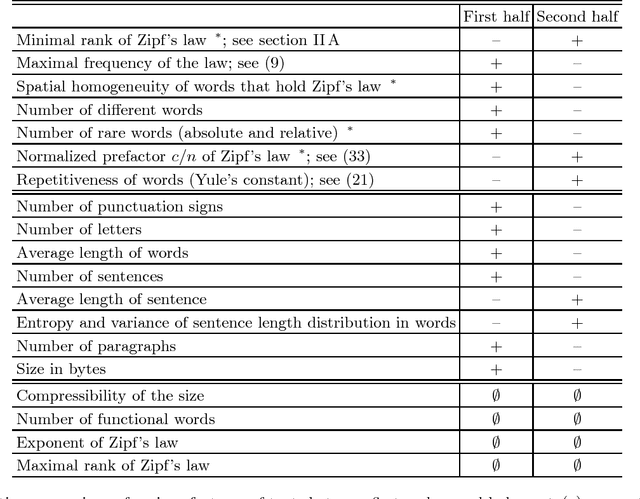
Zipf's law is the main regularity of quantitative linguistics. Despite of many works devoted to foundations of this law, it is still unclear whether it is only a statistical regularity, or it has deeper relations with information-carrying structures of the text. This question relates to that of distinguishing a meaningful text (written in an unknown system) from a meaningless set of symbols that mimics statistical features of a text. Here we contribute to resolving these questions by comparing features of the first half of a text (from the beginning to the middle) to its second half. This comparison can uncover hidden effects, because the halves have the same values of many parameters (style, genre, author's vocabulary {\it etc}). In all studied texts we saw that for the first half Zipf's law applies from smaller ranks than in the second half, i.e. the law applies better to the first half. Also, words that hold Zipf's law in the first half are distributed more homogeneously over the text. These features do allow to distinguish a meaningful text from a random sequence of words. Our findings correlate with a number of textual characteristics that hold in most cases we studied: the first half is lexically richer, has longer and less repetitive words, more and shorter sentences, more punctuation signs and more paragraphs. These differences between the halves indicate on a higher hierarchic level of text organization that so far went unnoticed in text linguistics. They relate the validity of Zipf's law to textual information. A complete description of this effect requires new models, though one existing model can account for some of its aspects.
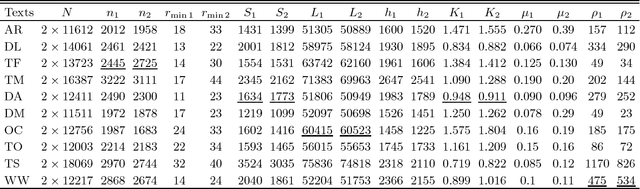
An Applied Deep Learning Approach for Estimating Soybean Relative Maturity from UAV Imagery to Aid Plant Breeding Decisions
Aug 02, 2021
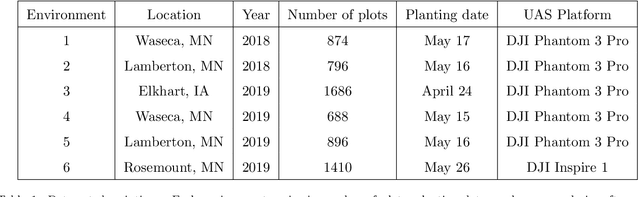
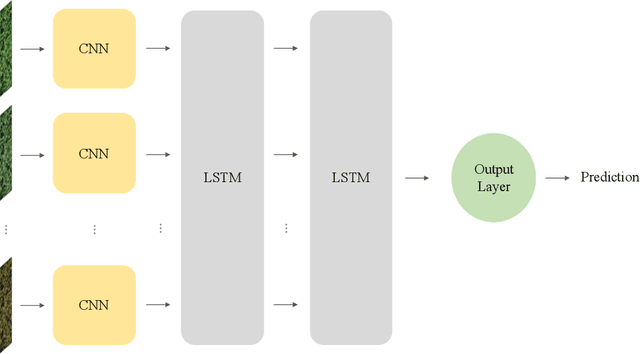
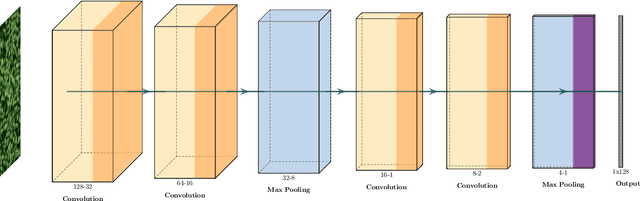
For a global breeding organization, identifying the next generation of superior crops is vital for its success. Recognizing new genetic varieties requires years of in-field testing to gather data about the crop's yield, pest resistance, heat resistance, etc. At the conclusion of the growing season, organizations need to determine which varieties will be advanced to the next growing season (or sold to farmers) and which ones will be discarded from the candidate pool. Specifically for soybeans, identifying their relative maturity is a vital piece of information used for advancement decisions. However, this trait needs to be physically observed, and there are resource limitations (time, money, etc.) that bottleneck the data collection process. To combat this, breeding organizations are moving toward advanced image capturing devices. In this paper, we develop a robust and automatic approach for estimating the relative maturity of soybeans using a time series of UAV images. An end-to-end hybrid model combining Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) is proposed to extract features and capture the sequential behavior of time series data. The proposed deep learning model was tested on six different environments across the United States. Results suggest the effectiveness of our proposed CNN-LSTM model compared to the local regression method. Furthermore, we demonstrate how this newfound information can be used to aid in plant breeding advancement decisions.
Deep Random Forest with Ferroelectric Analog Content Addressable Memory
Oct 06, 2021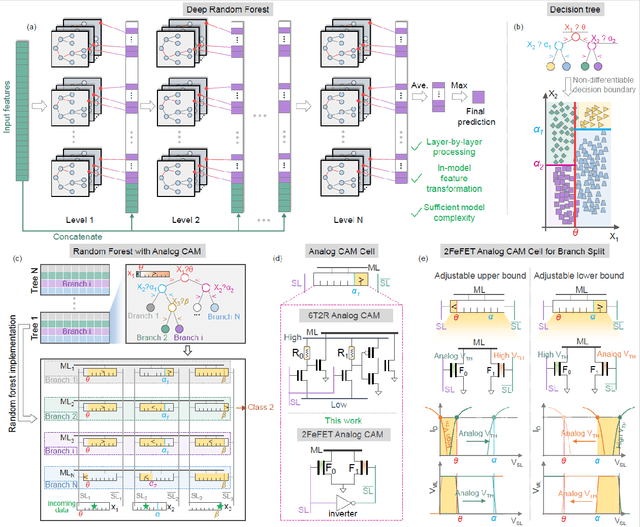
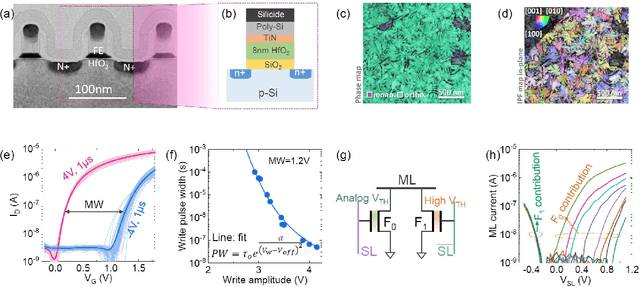
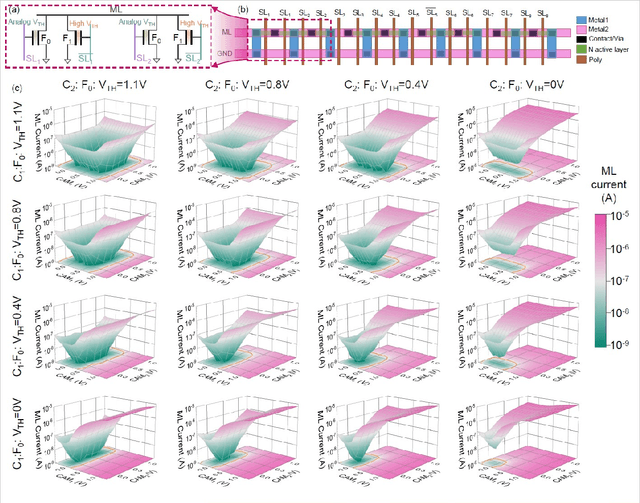
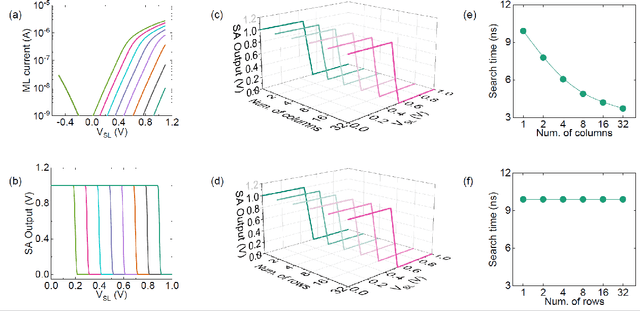
Deep random forest (DRF), which incorporates the core features of deep learning and random forest (RF), exhibits comparable classification accuracy, interpretability, and low memory and computational overhead when compared with deep neural networks (DNNs) in various information processing tasks for edge intelligence. However, the development of efficient hardware to accelerate DRF is lagging behind its DNN counterparts. The key for hardware acceleration of DRF lies in efficiently realizing the branch-split operation at decision nodes when traversing a decision tree. In this work, we propose to implement DRF through simple associative searches realized with ferroelectric analog content addressable memory (ACAM). Utilizing only two ferroelectric field effect transistors (FeFETs), the ultra-compact ACAM cell can perform a branch-split operation with an energy-efficient associative search by storing the decision boundaries as the analog polarization states in an FeFET. The DRF accelerator architecture and the corresponding mapping of the DRF model to the ACAM arrays are presented. The functionality, characteristics, and scalability of the FeFET ACAM based DRF and its robustness against FeFET device non-idealities are validated both in experiments and simulations. Evaluation results show that the FeFET ACAM DRF accelerator exhibits 10^6x/16x and 10^6x/2.5x improvements in terms of energy and latency when compared with other deep random forest hardware implementations on the state-of-the-art CPU/ReRAM, respectively.
Hierarchical Relation-Guided Type-Sentence Alignment for Long-Tail Relation Extraction with Distant Supervision
Sep 19, 2021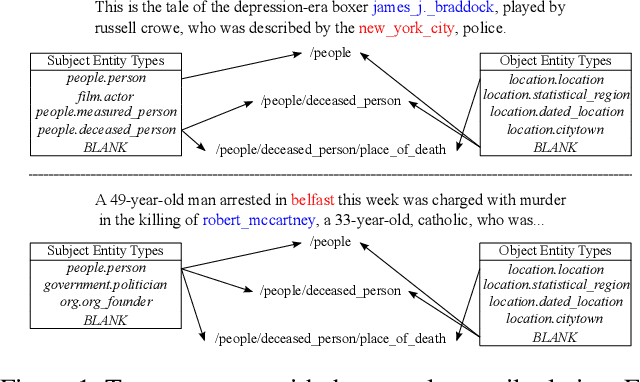
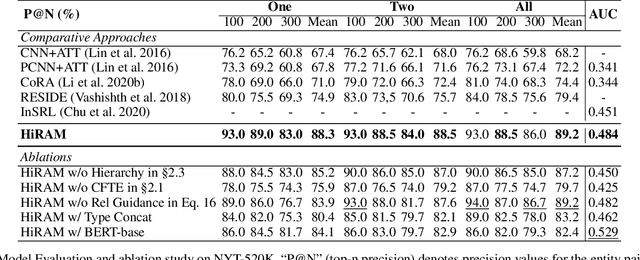
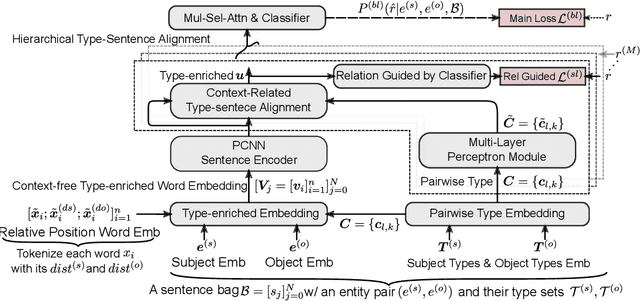
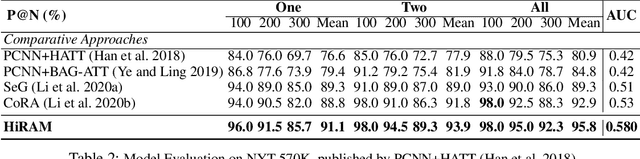
Distant supervision uses triple facts in knowledge graphs to label a corpus for relation extraction, leading to wrong labeling and long-tail problems. Some works use the hierarchy of relations for knowledge transfer to long-tail relations. However, a coarse-grained relation often implies only an attribute (e.g., domain or topic) of the distant fact, making it hard to discriminate relations based solely on sentence semantics. One solution is resorting to entity types, but open questions remain about how to fully leverage the information of entity types and how to align multi-granular entity types with sentences. In this work, we propose a novel model to enrich distantly-supervised sentences with entity types. It consists of (1) a pairwise type-enriched sentence encoding module injecting both context-free and -related backgrounds to alleviate sentence-level wrong labeling, and (2) a hierarchical type-sentence alignment module enriching a sentence with the triple fact's basic attributes to support long-tail relations. Our model achieves new state-of-the-art results in overall and long-tail performance on benchmarks.
Automated Quality Control of Vacuum Insulated Glazing by Convolutional Neural Network Image Classification
Oct 15, 2021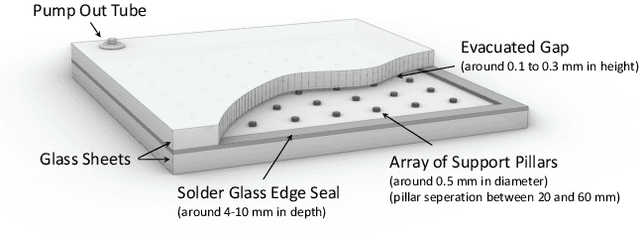


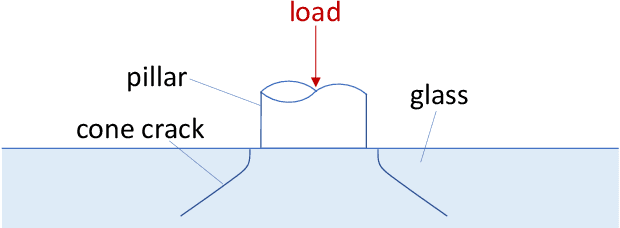
Vacuum Insulated Glazing (VIG) is a highly thermally insulating window technology, which boasts an extremely thin profile and lower weight as compared to gas-filled insulated glazing units of equivalent performance. The VIG is a double-pane configuration with a submillimeter vacuum gap between the panes and therefore under constant atmospheric pressure over their service life. Small pillars are positioned between the panes to maintain the gap, which can damage the glass reducing the lifetime of the VIG unit. To efficiently assess any surface damage on the glass, an automated damage detection system is highly desirable. For the purpose of classifying the damage, we have developed, trained, and tested a deep learning computer vision system using convolutional neural networks. The classification model flawlessly classified the test dataset with an area under the curve (AUC) for the receiver operating characteristic (ROC) of 100%. We have automatically cropped the images down to their relevant information by using Faster-RCNN to locate the position of the pillars. We employ the state-of-the-art methods Grad-CAM and Score-CAM of explainable Artificial Intelligence (XAI) to provide an understanding of the internal mechanisms and were able to show that our classifier outperforms ResNet50V2 for identification of crack locations and geometry. The proposed methods can therefore be used to detect systematic defects even without large amounts of training data. Further analyses of our model's predictive capabilities demonstrates its superiority over state-of-the-art models (ResNet50V2, ResNet101V2 and ResNet152V2) in terms of convergence speed, accuracy, precision at 100% recall and AUC for ROC.