 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Opponent Modeling via Adversarial Ensemble Reinforcement Learning in Asymmetric Imperfect-Information Games
Sep 18, 2019
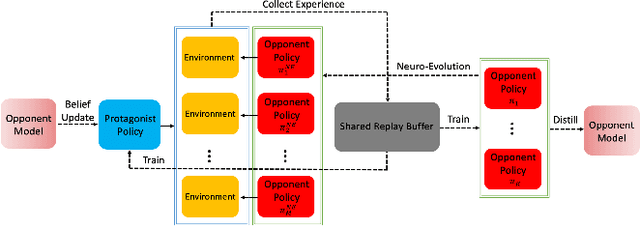
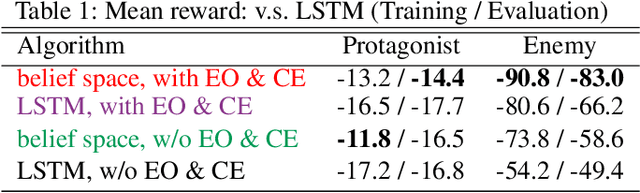

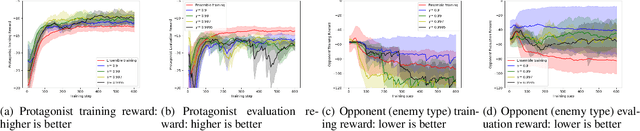
This paper presents an algorithmic framework for learning robust policies in asymmetric imperfect-information games, where the joint reward could depend on the uncertain opponent type (a private information known only to the opponent itself and its ally). In order to maximize the reward, the protagonist agent has to infer the opponent type through agent modeling. We use multiagent reinforcement learning (MARL) to learn opponent models through self-play, which captures the full strategy interaction and reasoning between agents. However, agent policies learned from self-play can suffer from mutual overfitting. Ensemble training methods can be used to improve the robustness of agent policy against different opponents, but it also significantly increases the computational overhead. In order to achieve a good trade-off between the robustness of the learned policy and the computation complexity, we propose to train a separate opponent policy against the protagonist agent for evaluation purposes. The reward achieved by this opponent is a noisy measure of the robustness of the protagonist agent policy due to the intrinsic stochastic nature of a reinforcement learner. To handle this stochasticity, we apply a stochastic optimization scheme to dynamically update the opponent ensemble to optimize an objective function that strikes a balance between robustness and computation complexity. We empirically show that, under the same limited computational budget, the proposed method results in more robust policy learning than standard ensemble training.
Unsupervised-learning-based method for chest MRI-CT transformation using structure constrained unsupervised generative attention networks
Jun 16, 2021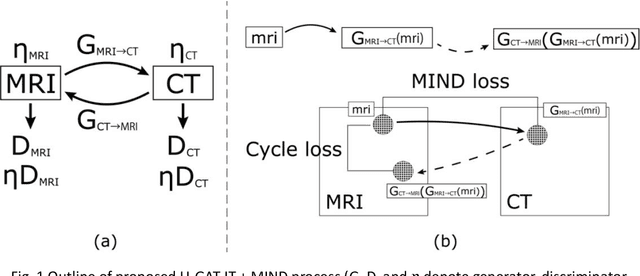
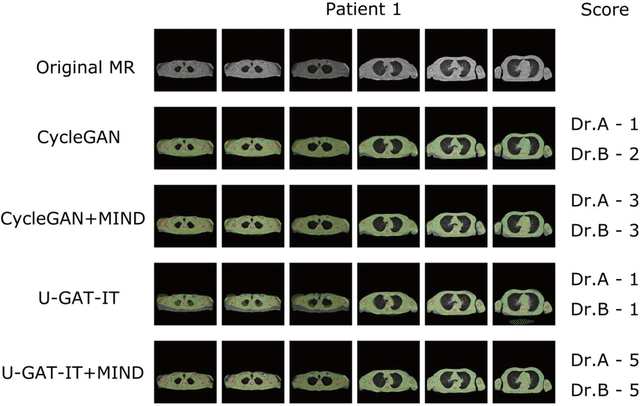
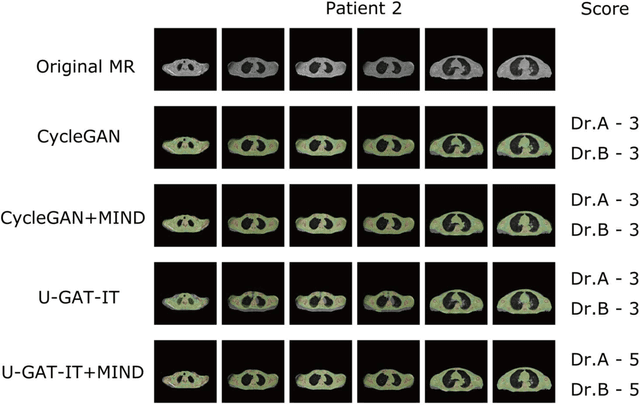
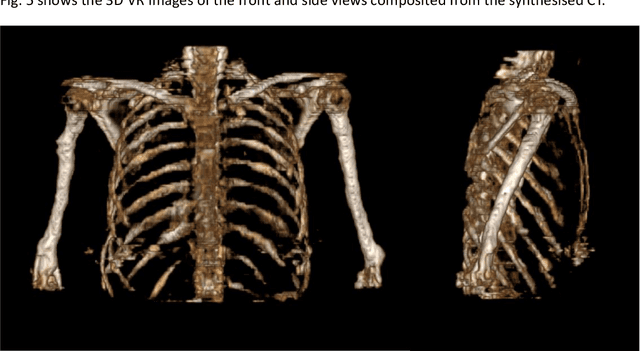
The integrated positron emission tomography/magnetic resonance imaging (PET/MRI) scanner facilitates the simultaneous acquisition of metabolic information via PET and morphological information with high soft-tissue contrast using MRI. Although PET/MRI facilitates the capture of high-accuracy fusion images, its major drawback can be attributed to the difficulty encountered when performing attenuation correction, which is necessary for quantitative PET evaluation. The combined PET/MRI scanning requires the generation of attenuation-correction maps from MRI owing to no direct relationship between the gamma-ray attenuation information and MRIs. While MRI-based bone-tissue segmentation can be readily performed for the head and pelvis regions, the realization of accurate bone segmentation via chest CT generation remains a challenging task. This can be attributed to the respiratory and cardiac motions occurring in the chest as well as its anatomically complicated structure and relatively thin bone cortex. This paper presents a means to minimise the anatomical structural changes without human annotation by adding structural constraints using a modality-independent neighbourhood descriptor (MIND) to a generative adversarial network (GAN) that can transform unpaired images. The results obtained in this study revealed the proposed U-GAT-IT + MIND approach to outperform all other competing approaches. The findings of this study hint towards possibility of synthesising clinically acceptable CT images from chest MRI without human annotation, thereby minimising the changes in the anatomical structure.
Towards Building a Food Knowledge Graph for Internet of Food
Jul 13, 2021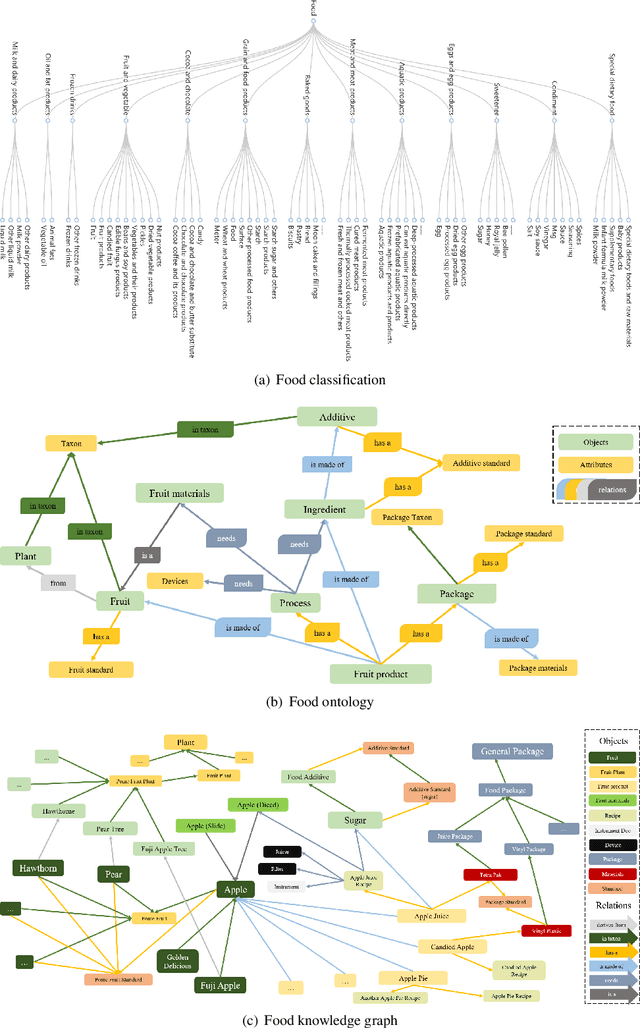
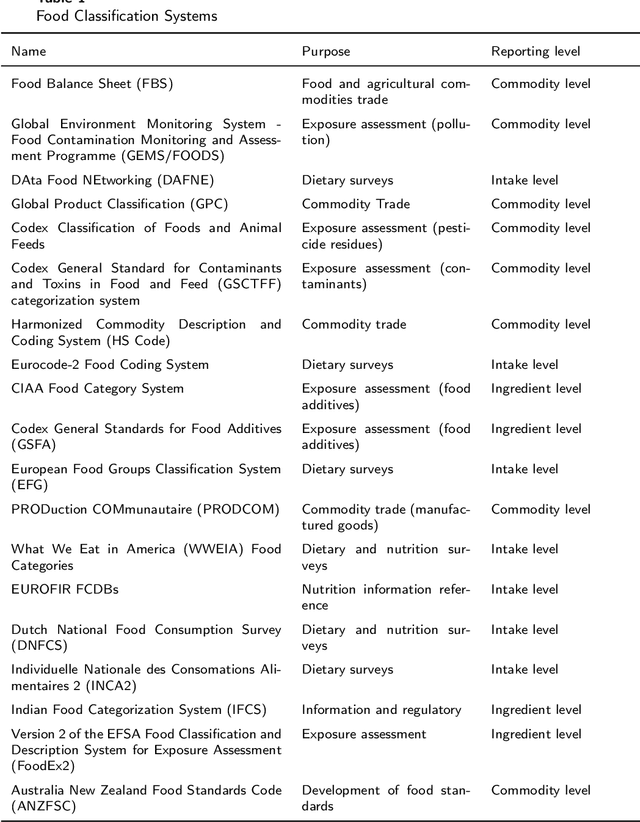
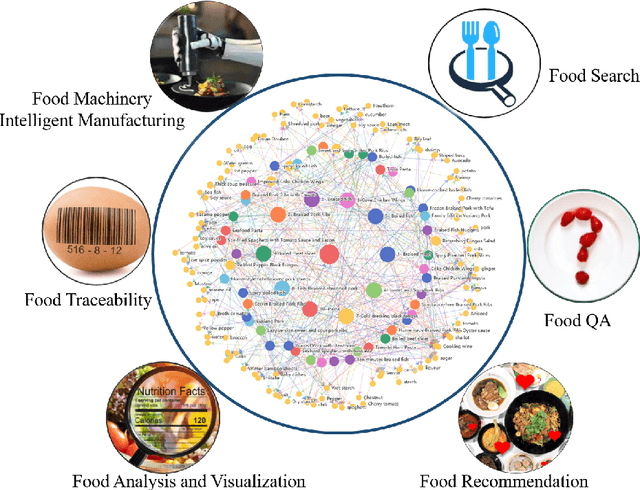
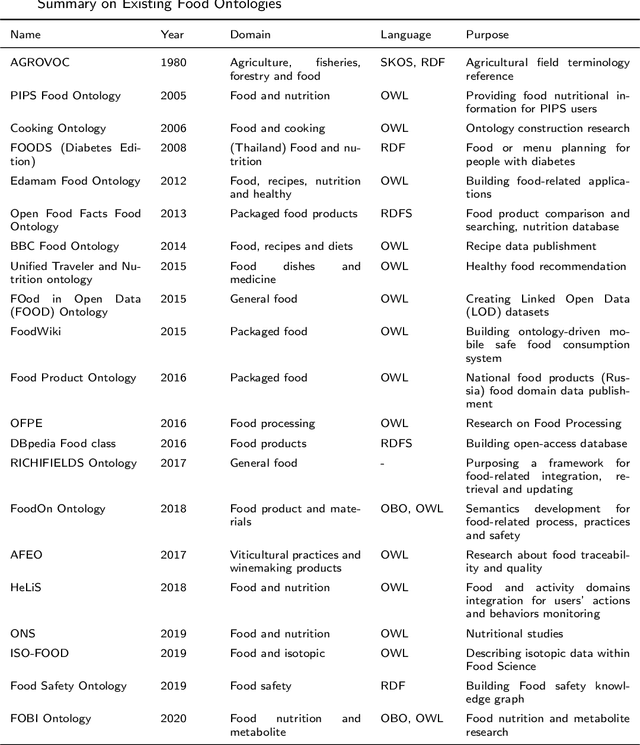
Background: The deployment of various networks (e.g., Internet of Things (IoT) and mobile networks) and databases (e.g., nutrition tables and food compositional databases) in the food system generates massive information silos due to the well-known data harmonization problem. The food knowledge graph provides a unified and standardized conceptual terminology and their relationships in a structured form and thus can transform these information silos across the whole food system to a more reusable globally digitally connected Internet of Food, enabling every stage of the food system from farm-to-fork. Scope and approach: We review the evolution of food knowledge organization, from food classification, food ontology to food knowledge graphs. We then discuss the progress in food knowledge graphs from several representative applications. We finally discuss the main challenges and future directions. Key findings and conclusions: Our comprehensive summary of current research on food knowledge graphs shows that food knowledge graphs play an important role in food-oriented applications, including food search and Question Answering (QA), personalized dietary recommendation, food analysis and visualization, food traceability, and food machinery intelligent manufacturing. Future directions for food knowledge graphs cover several fields such as multimodal food knowledge graphs and food intelligence.
Deep learning long-range information in undirected graphs with wave networks
Oct 29, 2018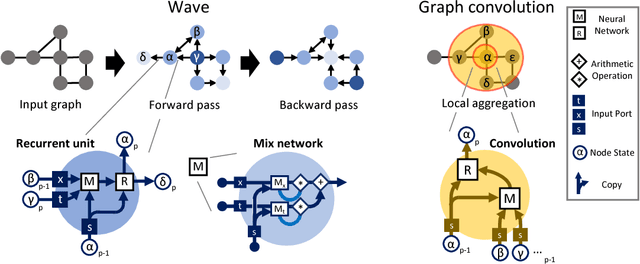
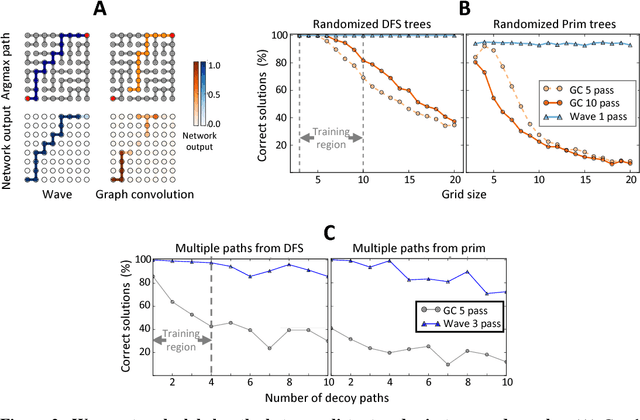
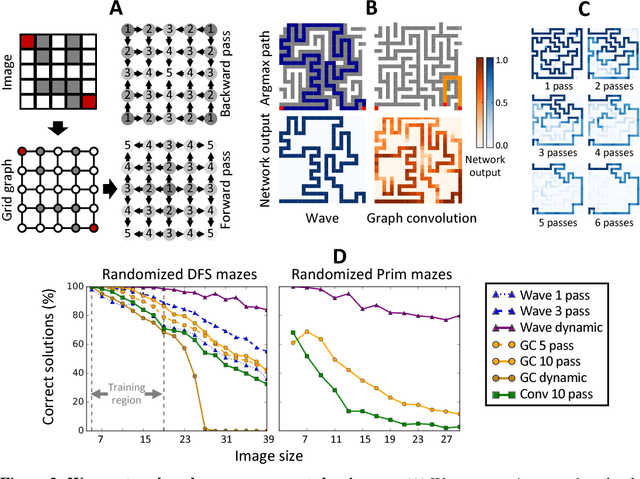
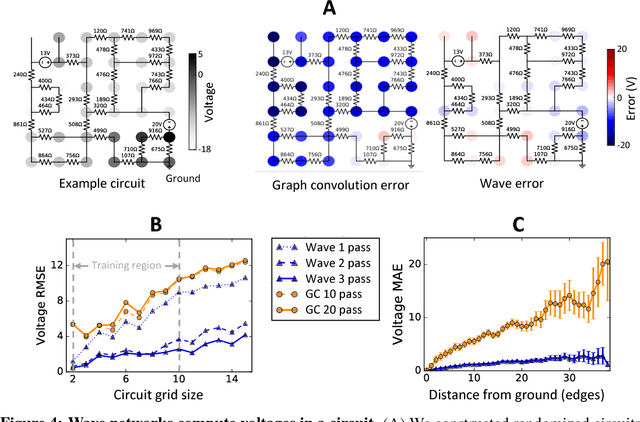
Graph algorithms are key tools in many fields of science and technology. Some of these algorithms depend on propagating information between distant nodes in a graph. Recently, there have been a number of deep learning architectures proposed to learn on undirected graphs. However, most of these architectures aggregate information in the local neighborhood of a node, and therefore they may not be capable of efficiently propagating long-range information. To solve this problem we examine a recently proposed architecture, wave, which propagates information back and forth across an undirected graph in waves of nonlinear computation. We compare wave to graph convolution, an architecture based on local aggregation, and find that wave learns three different graph-based tasks with greater efficiency and accuracy. These three tasks include (1) labeling a path connecting two nodes in a graph, (2) solving a maze presented as an image, and (3) computing voltages in a circuit. These tasks range from trivial to very difficult, but wave can extrapolate from small training examples to much larger testing examples. These results show that wave may be able to efficiently solve a wide range of problems that require long-range information propagation across undirected graphs. An implementation of the wave network, and example code for the maze problem are included in the tflon deep learning toolkit (https://bitbucket.org/mkmatlock/tflon).
COSMic: A Coherence-Aware Generation Metric for Image Descriptions
Sep 11, 2021
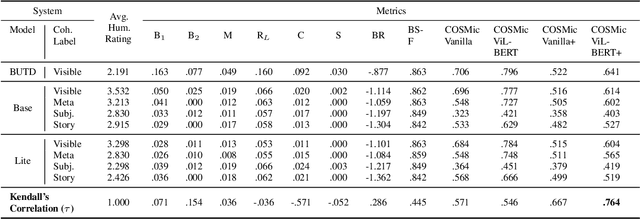

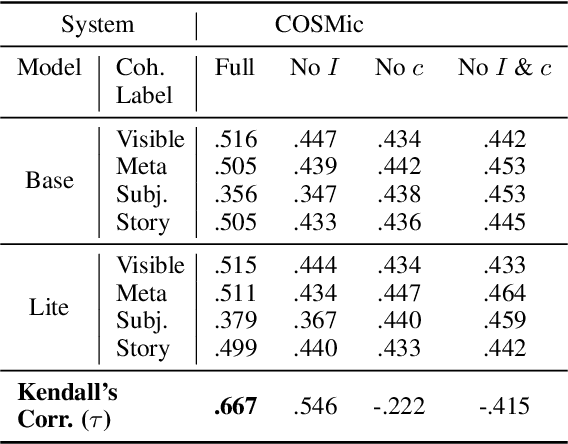
Developers of text generation models rely on automated evaluation metrics as a stand-in for slow and expensive manual evaluations. However, image captioning metrics have struggled to give accurate learned estimates of the semantic and pragmatic success of output text. We address this weakness by introducing the first discourse-aware learned generation metric for evaluating image descriptions. Our approach is inspired by computational theories of discourse for capturing information goals using coherence. We present a dataset of image$\unicode{x2013}$description pairs annotated with coherence relations. We then train a coherence-aware metric on a subset of the Conceptual Captions dataset and measure its effectiveness$\unicode{x2014}$its ability to predict human ratings of output captions$\unicode{x2014}$on a test set composed of out-of-domain images. We demonstrate a higher Kendall Correlation Coefficient for our proposed metric with the human judgments for the results of a number of state-of-the-art coherence-aware caption generation models when compared to several other metrics including recently proposed learned metrics such as BLEURT and BERTScore.
Cross Attention-guided Dense Network for Images Fusion
Sep 23, 2021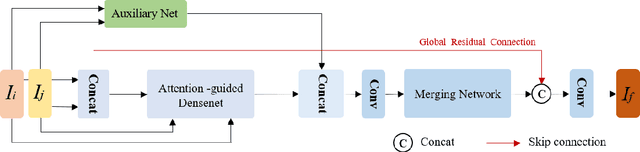
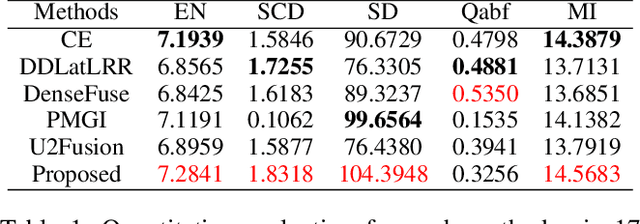
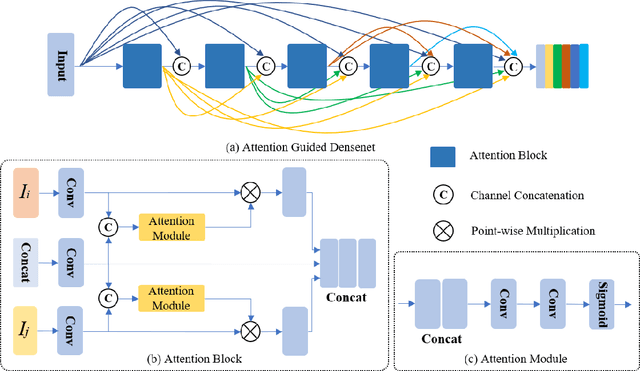
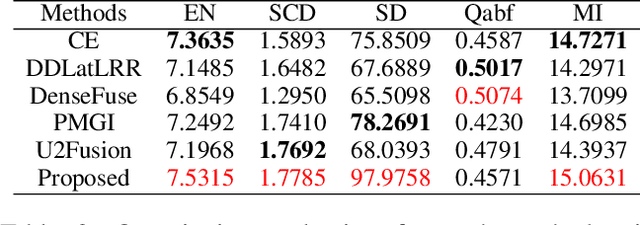
In recent years, various applications in computer vision have achieved substantial progress based on deep learning, which has been widely used for image fusion and shown to achieve adequate performance. However, suffering from limited ability in modelling the spatial correspondence of different source images, it still remains a great challenge for existing unsupervised image fusion models to extract appropriate feature and achieves adaptive and balanced fusion. In this paper, we propose a novel cross attention-guided image fusion network, which is a unified and unsupervised framework for multi-modal image fusion, multi-exposure image fusion, and multi-focus image fusion. Different from the existing self-attention module, our cross attention module focus on modelling the cross-correlation between different source images. Using the proposed cross attention module as core block, a densely connected cross attention-guided network is built to dynamically learn the spatial correspondence to derive better alignment of important details from different input images. Meanwhile, an auxiliary branch is also designed to model the long-range information, and a merging network is attached to finally reconstruct the fusion image. Extensive experiments have been carried out on publicly available datasets, and the results demonstrate that the proposed model outperforms the state-of-the-art quantitatively and qualitatively.
Contour location via entropy reduction leveraging multiple information sources
Oct 24, 2018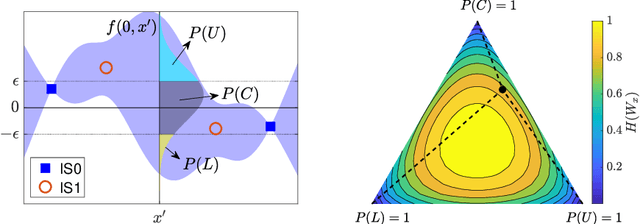
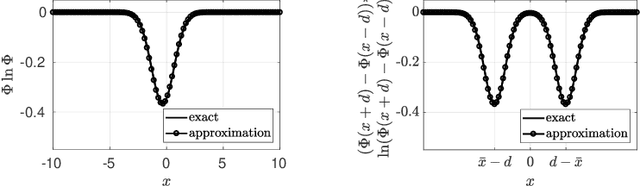
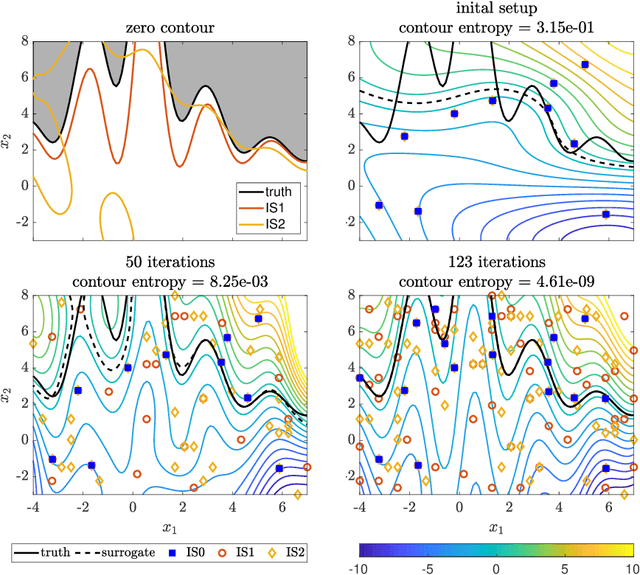
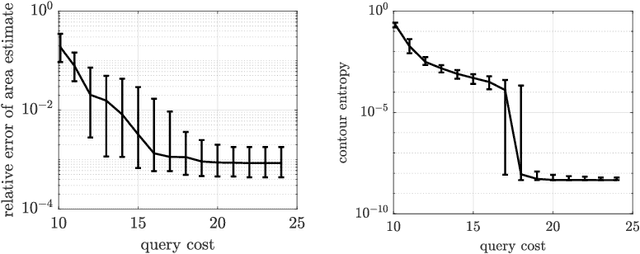
We introduce an algorithm to locate contours of functions that are expensive to evaluate. The problem of locating contours arises in many applications, including classification, constrained optimization, and performance analysis of mechanical and dynamical systems (reliability, probability of failure, stability, etc.). Our algorithm locates contours using information from multiple sources, which are available in the form of relatively inexpensive, biased, and possibly noisy approximations to the original function. Considering multiple information sources can lead to significant cost savings. We also introduce the concept of contour entropy, a formal measure of uncertainty about the location of the zero contour of a function approximated by a statistical surrogate model. Our algorithm locates contours efficiently by maximizing the reduction of contour entropy per unit cost.
Novel EEG-based BCIs for Elderly Rehabilitation Enhancement
Oct 08, 2021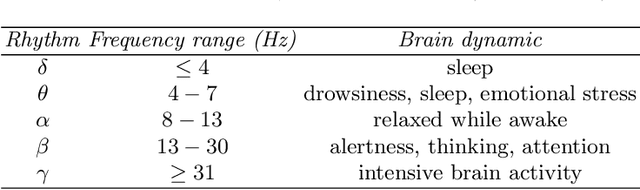
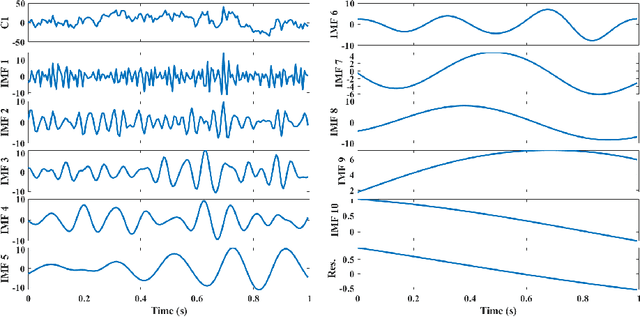
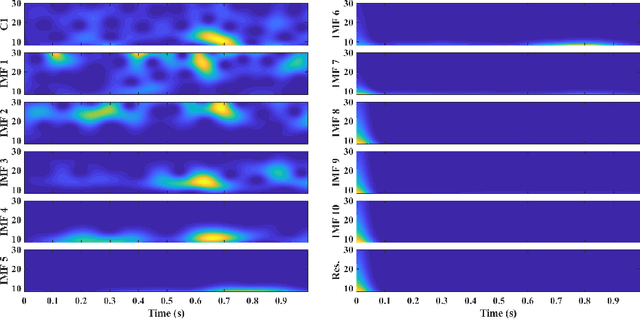

The ageing process may lead to cognitive and physical impairments, which may affect elderly everyday life. In recent years, the use of Brain Computer Interfaces (BCIs) based on Electroencephalography (EEG) has revealed to be particularly effective to promote and enhance rehabilitation procedures, especially by exploiting motor imagery experimental paradigms. Moreover, BCIs seem to increase patients' engagement and have proved to be reliable tools for elderly overall wellness improvement. However, EEG signals usually present a low signal-to-noise ratio and can be recorded for a limited time. Thus, irrelevant information and faulty samples could affect the BCI performance. Introducing a methodology that allows the extraction of informative components from the EEG signal while maintaining its intrinsic characteristics, may provide a solution to both the described issues: noisy data may be avoided by having only relevant components and combining relevant components may represent a good strategy to substitute the data without requiring long or repeated EEG recordings. Moreover, substituting faulty trials may significantly improve the classification performances of a BCI when translating imagined movement to rehabilitation systems. To this end, in this work the EEG signal decomposition by means of multivariate empirical mode decomposition is proposed to obtain its oscillatory modes, called Intrinsic Mode Functions (IMFs). Subsequently, a novel procedure for relevant IMF selection criterion based on the IMF time-frequency representation and entropy is provided. After having verified the reliability of the EEG signal reconstruction with the relevant IMFs only, the relevant IMFs are combined to produce new artificial data and provide new samples to use for BCI training.
A New Approach for Image Authentication Framework for Media Forensics Purpose
Oct 03, 2021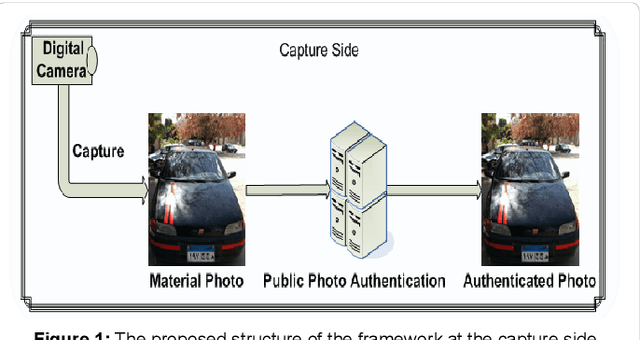

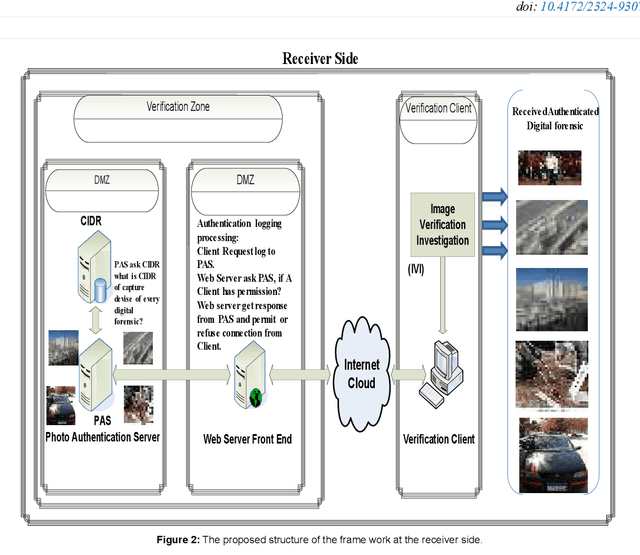
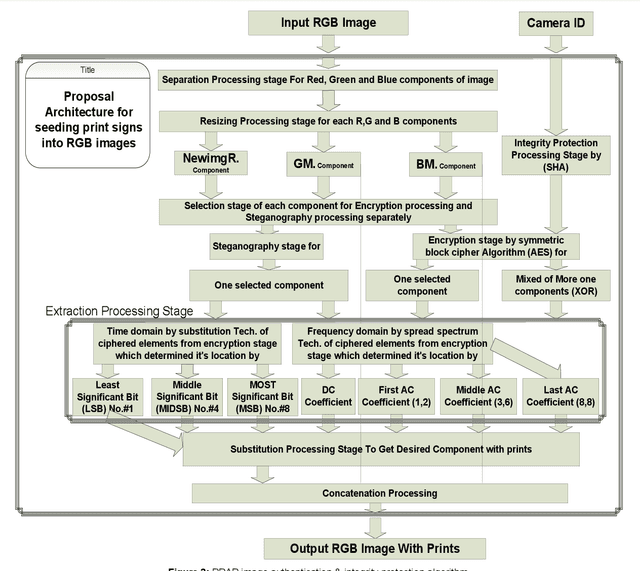
With the increasing widely spread digital media become using in most fields such as medical care, Oceanography, Exploration processing, security purpose, military fields and astronomy, evidence in criminals and more vital fields and then digital Images become have different appreciation values according to what is important of carried information by digital images. Due to the easy manipulation property of digital images (by proper computer software) makes us doubtful when are juries using digital images as forensic evidence in courts, especially, if the digital images are main evidence to demonstrate the relationship between suspects and the criminals. Obviously, here demonstrate importance of data Originality Protection methods to detect unauthorized process like modification or duplication and then enhancement protection of evidence to guarantee rights of incriminatory. In this paper, we shall introduce a novel digital forensic security framework for digital image authentication and originality identification techniques and related methodologies, algorithms and protocols that are applied on camera captured images. The approach depends on implanting secret code into RGB images that should indicate any unauthorized modification on the image under investigation. The secret code generation depends mainly on two main parameter types, namely the image characteristics and capturing device identifier. In this paper, the architecture framework will be analyzed, explained and discussed together with the associated protocols, algorithms and methodologies. Also, the secret code deduction and insertion techniques will be analyzed and discussed, in addition to the image benchmarking and quality testing techniques.
* 11 pages, 19 figures and one table
Deep learning facilitates fully automated brain image registration of optoacoustic tomography and magnetic resonance imaging
Sep 04, 2021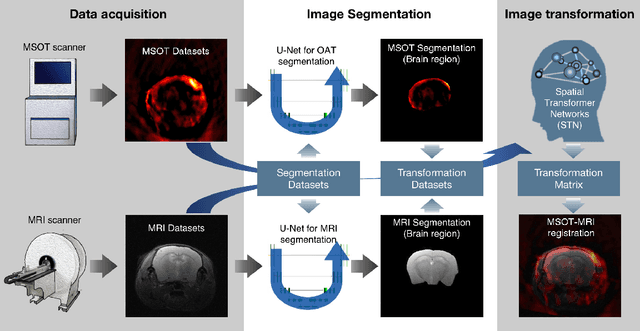
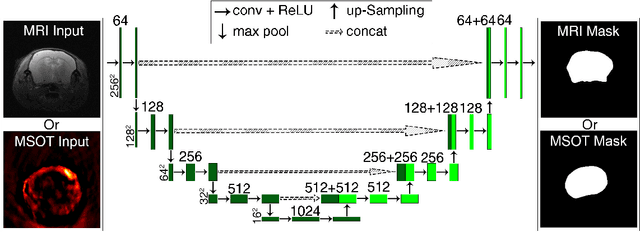
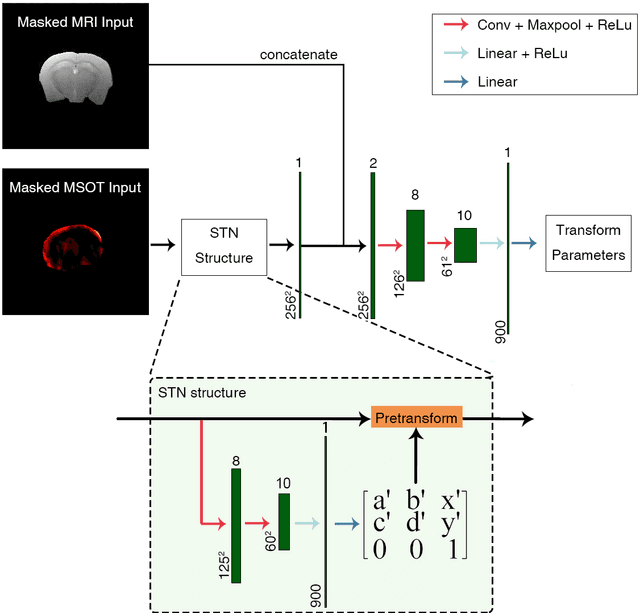
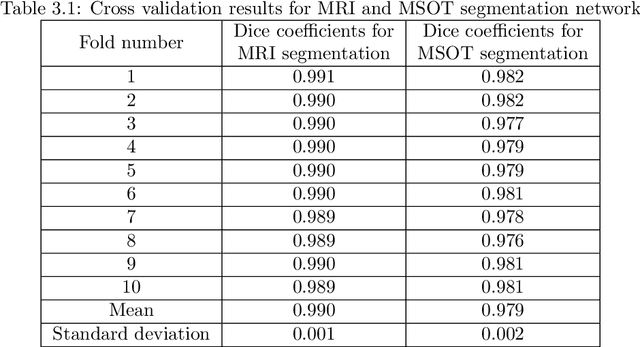
Multi-spectral optoacoustic tomography (MSOT) is an emerging optical imaging method providing multiplex molecular and functional information from the rodent brain. It can be greatly augmented by magnetic resonance imaging (MRI) that offers excellent soft-tissue contrast and high-resolution brain anatomy. Nevertheless, registration of multi-modal images remains challenging, chiefly due to the entirely different image contrast rendered by these modalities. Previously reported registration algorithms mostly relied on manual user-dependent brain segmentation, which compromised data interpretation and accurate quantification. Here we propose a fully automated registration method for MSOT-MRI multimodal imaging empowered by deep learning. The automated workflow includes neural network-based image segmentation to generate suitable masks, which are subsequently registered using an additional neural network. Performance of the algorithm is showcased with datasets acquired by cross-sectional MSOT and high-field MRI preclinical scanners. The automated registration method is further validated with manual and half-automated registration, demonstrating its robustness and accuracy.