 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lung Cancer Risk Estimation with Incomplete Data: A Joint Missing Imputation Perspective
Jul 25, 2021
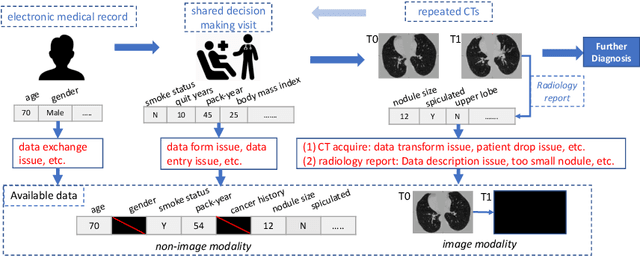
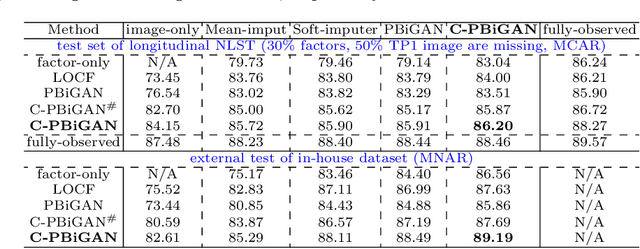
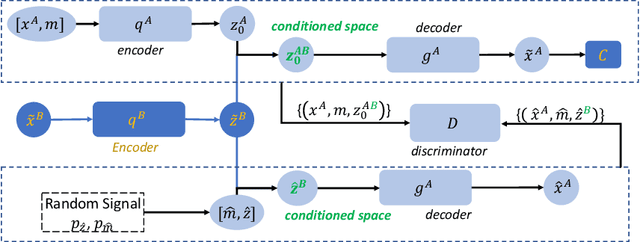
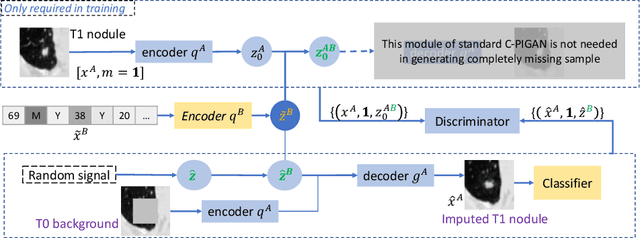
Data from multi-modality provide complementary information in clinical prediction, but missing data in clinical cohorts limits the number of subjects in multi-modal learning context. Multi-modal missing imputation is challenging with existing methods when 1) the missing data span across heterogeneous modalities (e.g., image vs. non-image); or 2) one modality is largely missing. In this paper, we address imputation of missing data by modeling the joint distribution of multi-modal data. Motivated by partial bidirectional generative adversarial net (PBiGAN), we propose a new Conditional PBiGAN (C-PBiGAN) method that imputes one modality combining the conditional knowledge from another modality. Specifically, C-PBiGAN introduces a conditional latent space in a missing imputation framework that jointly encodes the available multi-modal data, along with a class regularization loss on imputed data to recover discriminative information. To our knowledge, it is the first generative adversarial model that addresses multi-modal missing imputation by modeling the joint distribution of image and non-image data. We validate our model with both the national lung screening trial (NLST) dataset and an external clinical validation cohort. The proposed C-PBiGAN achieves significant improvements in lung cancer risk estimation compared with representative imputation methods (e.g., AUC values increase in both NLST (+2.9\%) and in-house dataset (+4.3\%) compared with PBiGAN, p$<$0.05).
Synerise at RecSys 2021: Twitter user engagement prediction with a fast neural model
Sep 28, 2021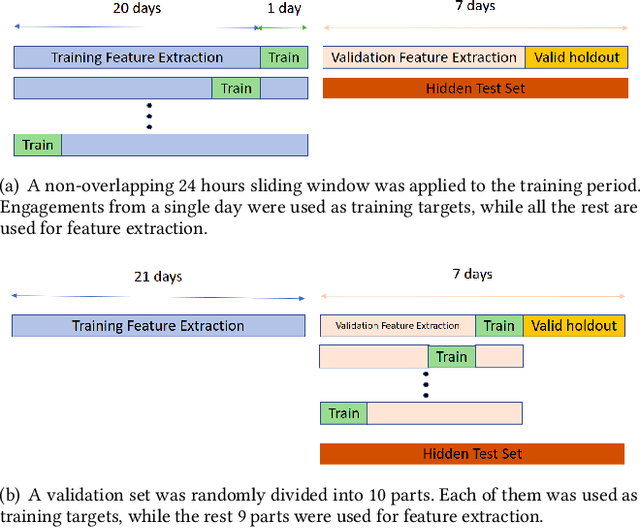

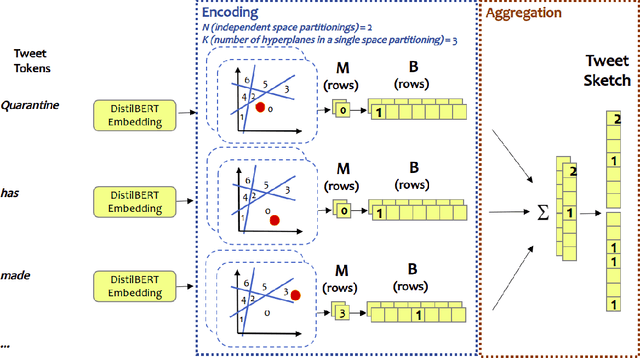

In this paper we present our 2nd place solution to ACM RecSys 2021 Challenge organized by Twitter. The challenge aims to predict user engagement for a set of tweets, offering an exceptionally large data set of 1 billion data points sampled from over four weeks of real Twitter interactions. Each data point contains multiple sources of information, such as tweet text along with engagement features, user features, and tweet features. The challenge brings the problem close to a real production environment by introducing strict latency constraints in the model evaluation phase: the average inference time for single tweet engagement prediction is limited to 6ms on a single CPU core with 64GB memory. Our proposed model relies on extensive feature engineering performed with methods such as the Efficient Manifold Density Estimator (EMDE) - our previously introduced algorithm based on Locality Sensitive Hashing method, and novel Fourier Feature Encoding, among others. In total, we create numerous features describing a user's Twitter account status and the content of a tweet. In order to adhere to the strict latency constraints, the underlying model is a simple residual feed-forward neural network. The system is a variation of our previous methods which proved successful in KDD Cup 2021, WSDM Challenge 2021, and SIGIR eCom Challenge 2020. We release the source code at: https://github.com/Synerise/recsys-challenge-2021
DYPLODOC: Dynamic Plots for Document Classification
Jul 26, 2021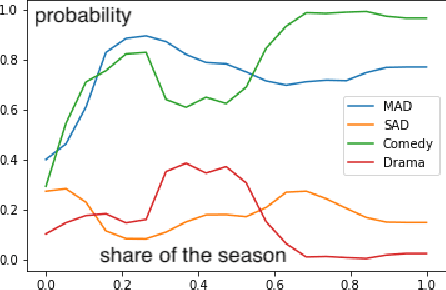
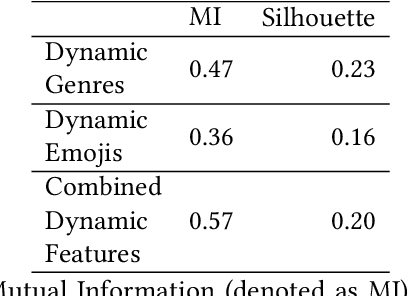
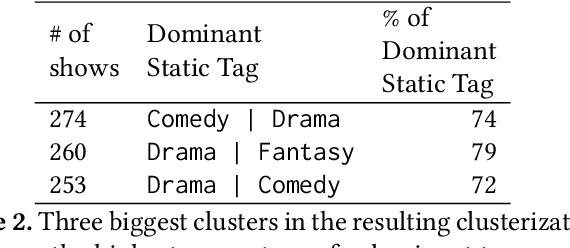

Narrative generation and analysis are still on the fringe of modern natural language processing yet are crucial in a variety of applications. This paper proposes a feature extraction method for plot dynamics. We present a dataset that consists of the plot descriptions for thirteen thousand TV shows alongside meta-information on their genres and dynamic plots extracted from them. We validate the proposed tool for plot dynamics extraction and discuss possible applications of this method to the tasks of narrative analysis and generation.
Concept Embedding for Information Retrieval
Feb 01, 2020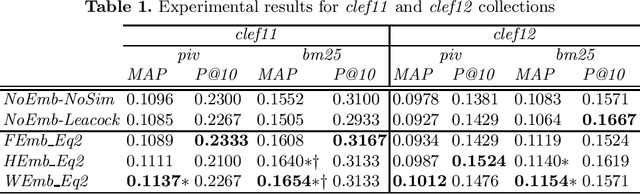
Concepts are used to solve the term-mismatch problem. However, we need an effective similarity measure between concepts. Word embedding presents a promising solution. We present in this study three approaches to build concepts vectors based on words vectors. We use a vector-based measure to estimate inter-concepts similarity. Our experiments show promising results. Furthermore, words and concepts become comparable. This could be used to improve conceptual indexing process.
Rapid detection and recognition of whole brain activity in a freely behaving Caenorhabditis elegans
Sep 23, 2021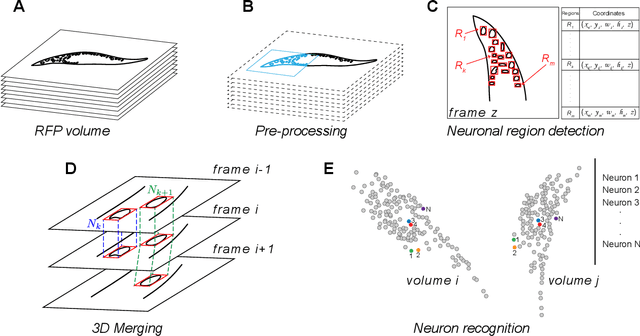

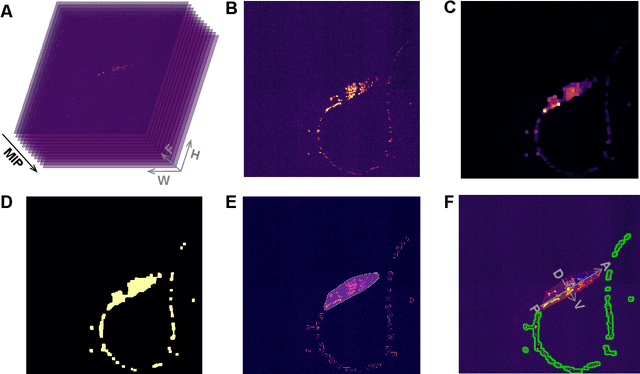
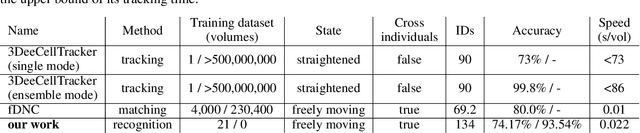
Advanced volumetric imaging methods and genetically encoded activity indicators have permitted a comprehensive characterization of whole brain activity at single neuron resolution in \textit{Caenorhabditis elegans}. The constant motion and deformation of the mollusc nervous system, however, impose a great challenge for a consistent identification of densely packed neurons in a behaving animal. Here, we propose a cascade solution for long-term and rapid recognition of head ganglion neurons in a freely moving \textit{C. elegans}. First, potential neuronal regions from a stack of fluorescence images are detected by a deep learning algorithm. Second, 2 dimensional neuronal regions are fused into 3 dimensional neuron entities. Third, by exploiting the neuronal density distribution surrounding a neuron and relative positional information between neurons, a multi-class artificial neural network transforms engineered neuronal feature vectors into digital neuronal identities. Under the constraint of a small number (20-40 volumes) of training samples, our bottom-up approach is able to process each volume - $1024 \times 1024 \times 18$ in voxels - in less than 1 second and achieves an accuracy of $91\%$ in neuronal detection and $74\%$ in neuronal recognition. Our work represents an important development towards a rapid and fully automated algorithm for decoding whole brain activity underlying natural animal behaviors.
TOHAN: A One-step Approach towards Few-shot Hypothesis Adaptation
Jun 11, 2021
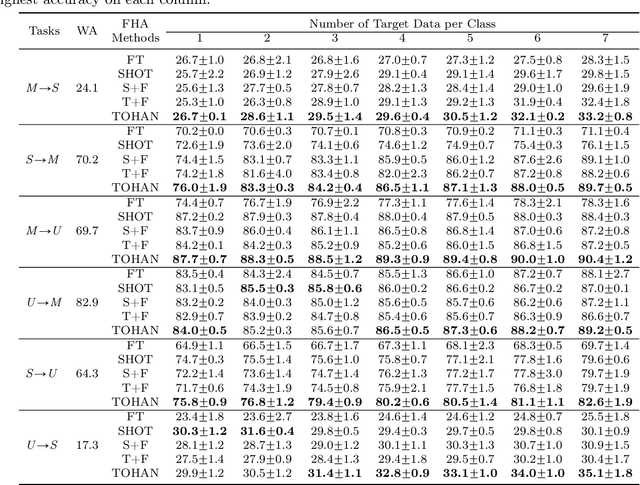
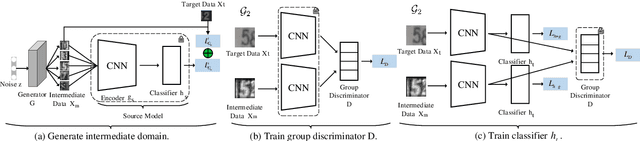

In few-shot domain adaptation (FDA), classifiers for the target domain are trained with accessible labeled data in the source domain (SD) and few labeled data in the target domain (TD). However, data usually contain private information in the current era, e.g., data distributed on personal phones. Thus, the private information will be leaked if we directly access data in SD to train a target-domain classifier (required by FDA methods). In this paper, to thoroughly prevent the privacy leakage in SD, we consider a very challenging problem setting, where the classifier for the TD has to be trained using few labeled target data and a well-trained SD classifier, named few-shot hypothesis adaptation (FHA). In FHA, we cannot access data in SD, as a result, the private information in SD will be protected well. To this end, we propose a target orientated hypothesis adaptation network (TOHAN) to solve the FHA problem, where we generate highly-compatible unlabeled data (i.e., an intermediate domain) to help train a target-domain classifier. TOHAN maintains two deep networks simultaneously, where one focuses on learning an intermediate domain and the other takes care of the intermediate-to-target distributional adaptation and the target-risk minimization. Experimental results show that TOHAN outperforms competitive baselines significantly.
Deep learning facilitates fully automated brain image registration of optoacoustic tomography and magnetic resonance imaging
Sep 04, 2021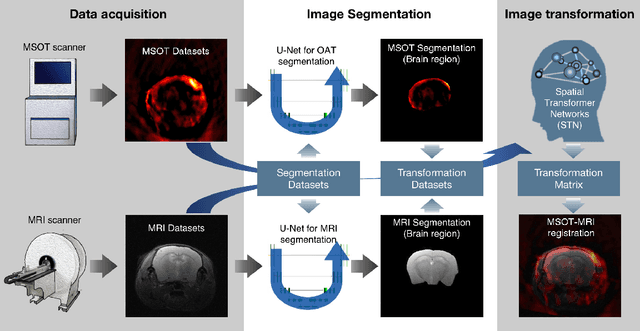
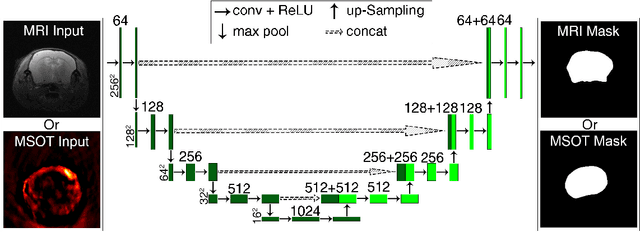
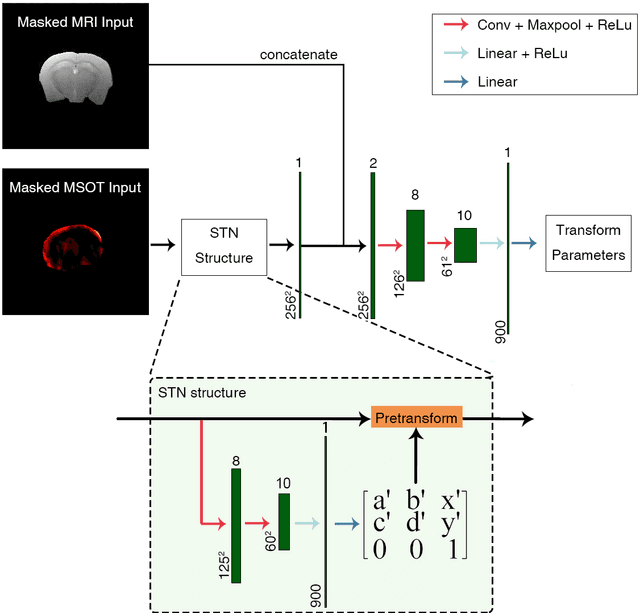
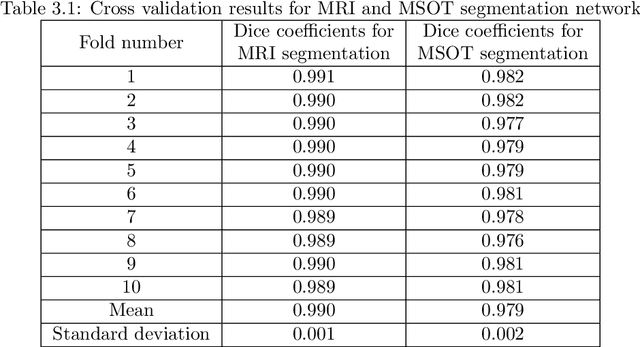
Multi-spectral optoacoustic tomography (MSOT) is an emerging optical imaging method providing multiplex molecular and functional information from the rodent brain. It can be greatly augmented by magnetic resonance imaging (MRI) that offers excellent soft-tissue contrast and high-resolution brain anatomy. Nevertheless, registration of multi-modal images remains challenging, chiefly due to the entirely different image contrast rendered by these modalities. Previously reported registration algorithms mostly relied on manual user-dependent brain segmentation, which compromised data interpretation and accurate quantification. Here we propose a fully automated registration method for MSOT-MRI multimodal imaging empowered by deep learning. The automated workflow includes neural network-based image segmentation to generate suitable masks, which are subsequently registered using an additional neural network. Performance of the algorithm is showcased with datasets acquired by cross-sectional MSOT and high-field MRI preclinical scanners. The automated registration method is further validated with manual and half-automated registration, demonstrating its robustness and accuracy.
Improving 360 Monocular Depth Estimation via Non-local Dense Prediction Transformer and Joint Supervised and Self-supervised Learning
Sep 23, 2021
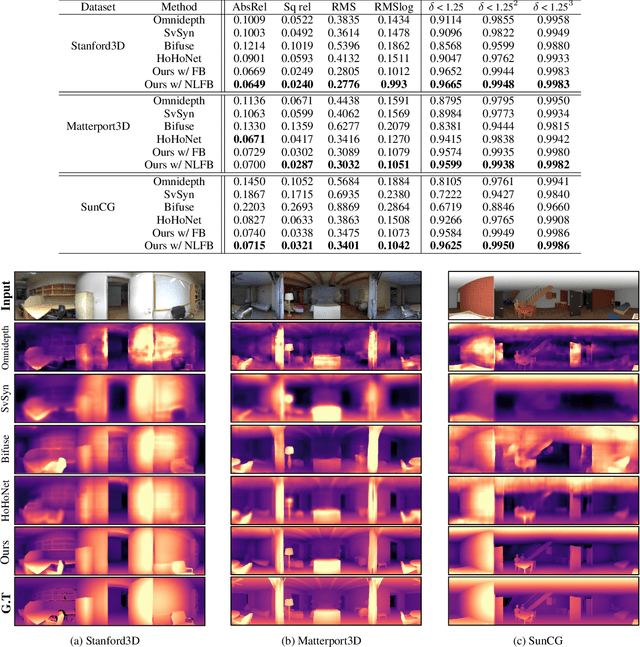

Due to difficulties in acquiring ground truth depth of equirectangular (360) images, the quality and quantity of equirectangular depth data today is insufficient to represent the various scenes in the world. Therefore, 360 depth estimation studies, which relied solely on supervised learning, are destined to produce unsatisfactory results. Although self-supervised learning methods focusing on equirectangular images (EIs) are introduced, they often have incorrect or non-unique solutions, causing unstable performance. In this paper, we propose 360 monocular depth estimation methods which improve on the areas that limited previous studies. First, we introduce a self-supervised 360 depth learning method that only utilizes gravity-aligned videos, which has the potential to eliminate the needs for depth data during the training procedure. Second, we propose a joint learning scheme realized by combining supervised and self-supervised learning. The weakness of each learning is compensated, thus leading to more accurate depth estimation. Third, we propose a non-local fusion block, which retains global information encoded by vision transformer when reconstructing the depths. With the proposed methods, we successfully apply the transformer to 360 depth estimations, to the best of our knowledge, which has not been tried before. On several benchmarks, our approach achieves significant improvements over previous works and establishes a state of the art.
Fail-Safe Human Detection for Drones Using a Multi-Modal Curriculum Learning Approach
Sep 28, 2021
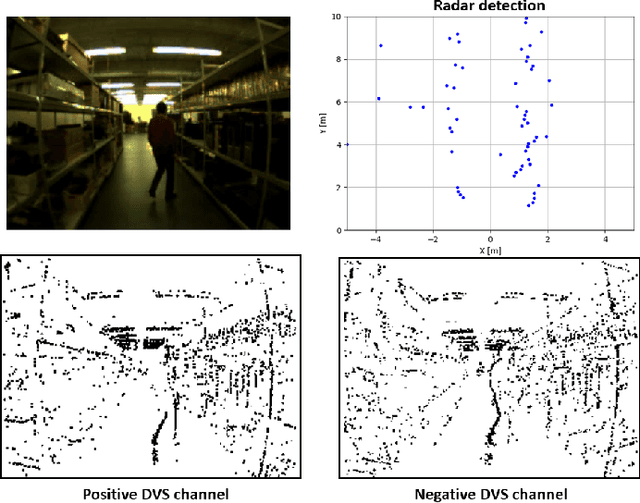
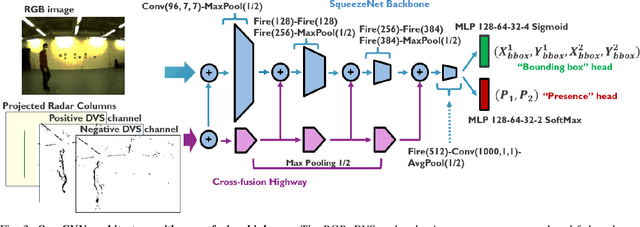

Drones are currently being explored for safety-critical applications where human agents are expected to evolve in their vicinity. In such applications, robust people avoidance must be provided by fusing a number of sensing modalities in order to avoid collisions. Currently however, people detection systems used on drones are solely based on standard cameras besides an emerging number of works discussing the fusion of imaging and event-based cameras. On the other hand, radar-based systems provide up-most robustness towards environmental conditions but do not provide complete information on their own and have mainly been investigated in automotive contexts, not for drones. In order to enable the fusion of radars with both event-based and standard cameras, we present KUL-UAVSAFE, a first-of-its-kind dataset for the study of safety-critical people detection by drones. In addition, we propose a baseline CNN architecture with cross-fusion highways and introduce a curriculum learning strategy for multi-modal data termed SAUL, which greatly enhances the robustness of the system towards hard RGB failures and provides a significant gain of 15% in peak F1 score compared to the use of BlackIn, previously proposed for cross-fusion networks. We demonstrate the real-time performance and feasibility of the approach by implementing the system in an edge-computing unit. We release our dataset and additional material in the project home page.
Opening the Black Box of Deep Neural Networks in Physical Layer Communication
Jun 06, 2021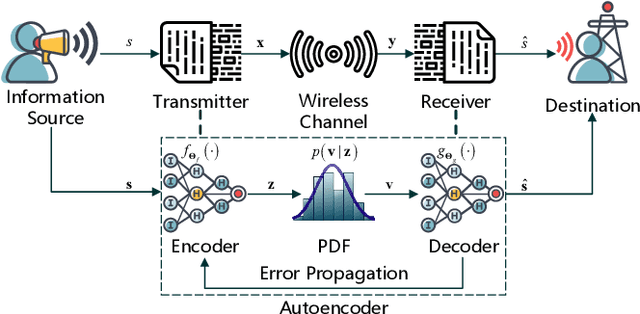
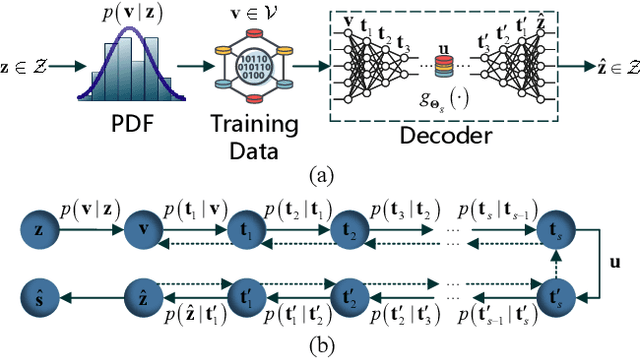
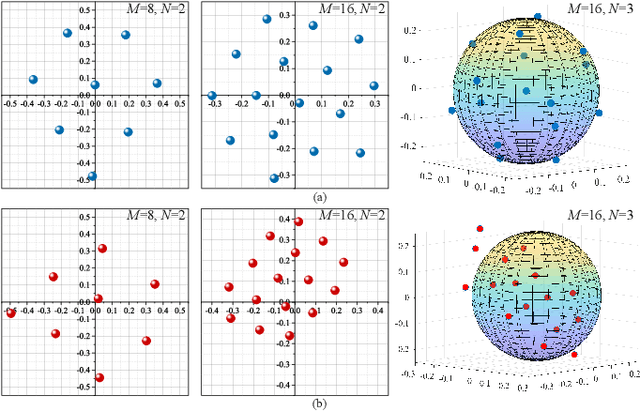
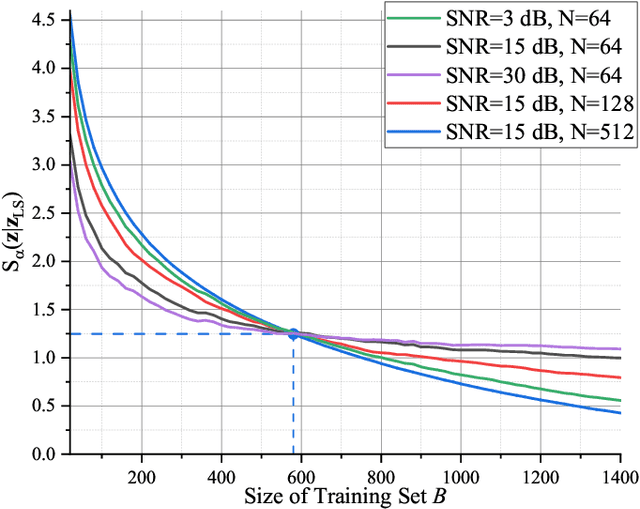
Deep Neural Network (DNN)-based physical layer techniques are attracting considerable interest due to their potential to enhance communication systems. However, most studies in the physical layer have tended to focus on the application of DNN models to wireless communication problems but not to theoretically understand how does a DNN work in a communication system. In this letter, we aim to quantitatively analyse why DNNs can achieve comparable performance in the physical layer comparing with traditional techniques and their cost in terms of computational complexity. We further investigate and also experimentally validate how information is flown in a DNN-based communication system under the information theoretic concepts.