 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Impact of Positional Encodings on Multilingual Compression
Sep 11, 2021

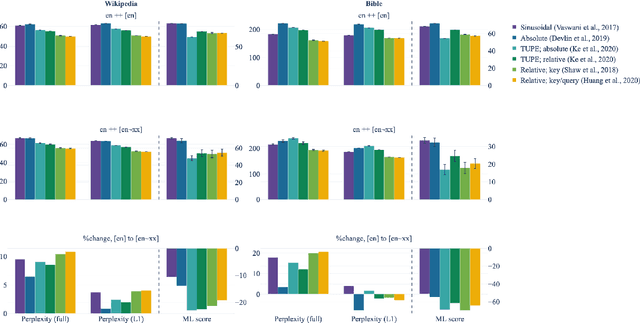

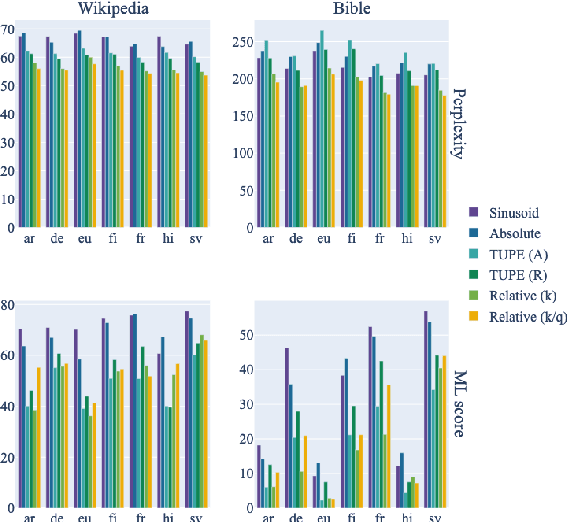
In order to preserve word-order information in a non-autoregressive setting, transformer architectures tend to include positional knowledge, by (for instance) adding positional encodings to token embeddings. Several modifications have been proposed over the sinusoidal positional encodings used in the original transformer architecture; these include, for instance, separating position encodings and token embeddings, or directly modifying attention weights based on the distance between word pairs. We first show that surprisingly, while these modifications tend to improve monolingual language models, none of them result in better multilingual language models. We then answer why that is: Sinusoidal encodings were explicitly designed to facilitate compositionality by allowing linear projections over arbitrary time steps. Higher variances in multilingual training distributions requires higher compression, in which case, compositionality becomes indispensable. Learned absolute positional encodings (e.g., in mBERT) tend to approximate sinusoidal embeddings in multilingual settings, but more complex positional encoding architectures lack the inductive bias to effectively learn compositionality and cross-lingual alignment. In other words, while sinusoidal positional encodings were originally designed for monolingual applications, they are particularly useful in multilingual language models.
Classifying vaccine sentiment tweets by modelling domain-specific representation and commonsense knowledge into context-aware attentive GRU
Jun 17, 2021
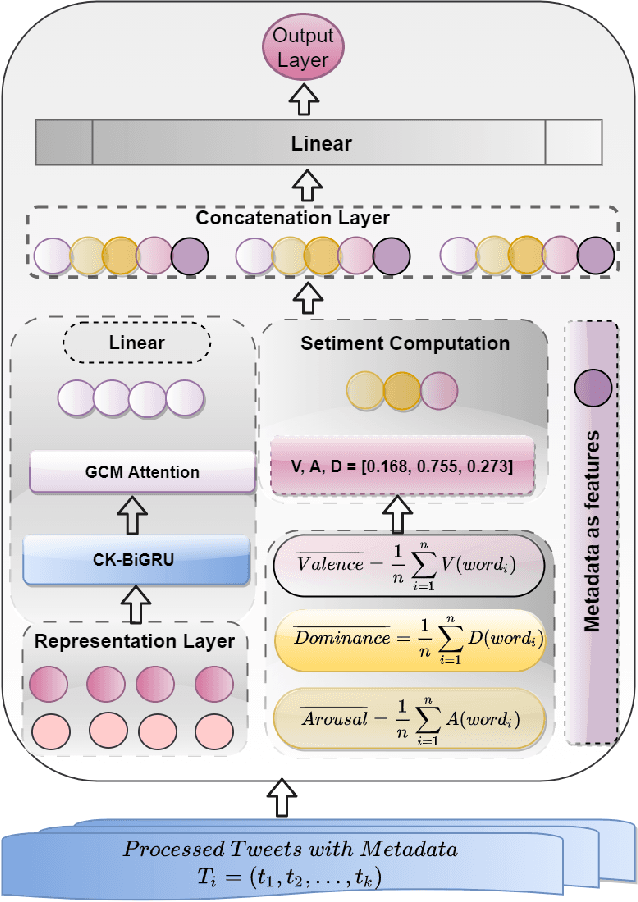
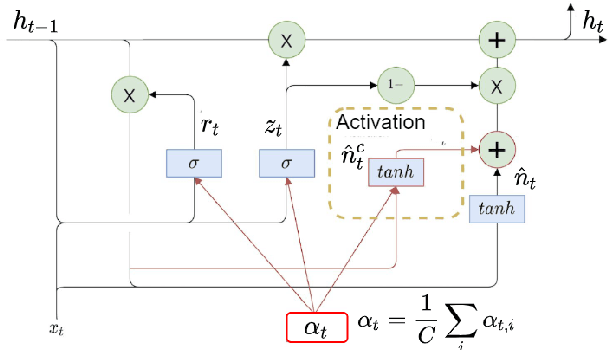
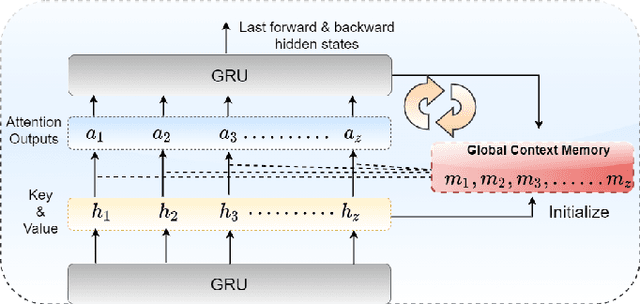
Vaccines are an important public health measure, but vaccine hesitancy and refusal can create clusters of low vaccine coverage and reduce the effectiveness of vaccination programs. Social media provides an opportunity to estimate emerging risks to vaccine acceptance by including geographical location and detailing vaccine-related concerns. Methods for classifying social media posts, such as vaccine-related tweets, use language models (LMs) trained on general domain text. However, challenges to measuring vaccine sentiment at scale arise from the absence of tonal stress and gestural cues and may not always have additional information about the user, e.g., past tweets or social connections. Another challenge in LMs is the lack of commonsense knowledge that are apparent in users metadata, i.e., emoticons, positive and negative words etc. In this study, to classify vaccine sentiment tweets with limited information, we present a novel end-to-end framework consisting of interconnected components that use domain-specific LM trained on vaccine-related tweets and models commonsense knowledge into a bidirectional gated recurrent network (CK-BiGRU) with context-aware attention. We further leverage syntactical, user metadata and sentiment information to capture the sentiment of a tweet. We experimented using two popular vaccine-related Twitter datasets and demonstrate that our proposed approach outperforms state-of-the-art models in identifying pro-vaccine, anti-vaccine and neutral tweets.
Novel Visual Category Discovery with Dual Ranking Statistics and Mutual Knowledge Distillation
Jul 07, 2021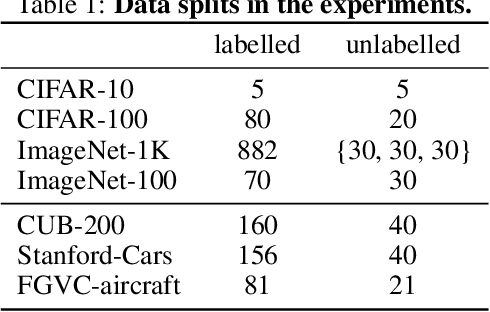
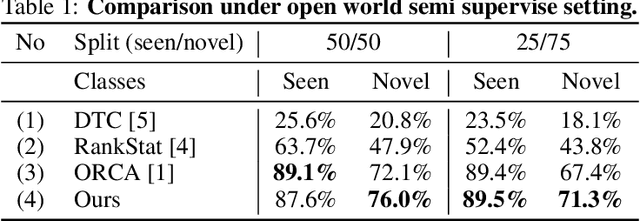
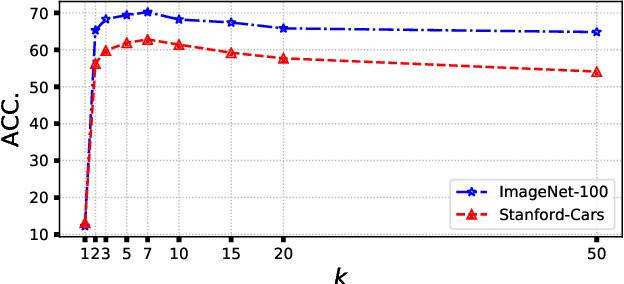
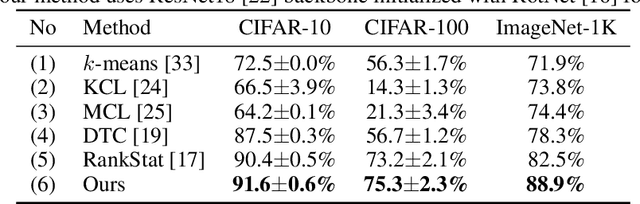
In this paper, we tackle the problem of novel visual category discovery, i.e., grouping unlabelled images from new classes into different semantic partitions by leveraging a labelled dataset that contains images from other different but relevant categories. This is a more realistic and challenging setting than conventional semi-supervised learning. We propose a two-branch learning framework for this problem, with one branch focusing on local part-level information and the other branch focusing on overall characteristics. To transfer knowledge from the labelled data to the unlabelled, we propose using dual ranking statistics on both branches to generate pseudo labels for training on the unlabelled data. We further introduce a mutual knowledge distillation method to allow information exchange and encourage agreement between the two branches for discovering new categories, allowing our model to enjoy the benefits of global and local features. We comprehensively evaluate our method on public benchmarks for generic object classification, as well as the more challenging datasets for fine-grained visual recognition, achieving state-of-the-art performance.
Covert Beamforming Design for Intelligent Reflecting Surface Assisted IoT Networks
Sep 01, 2021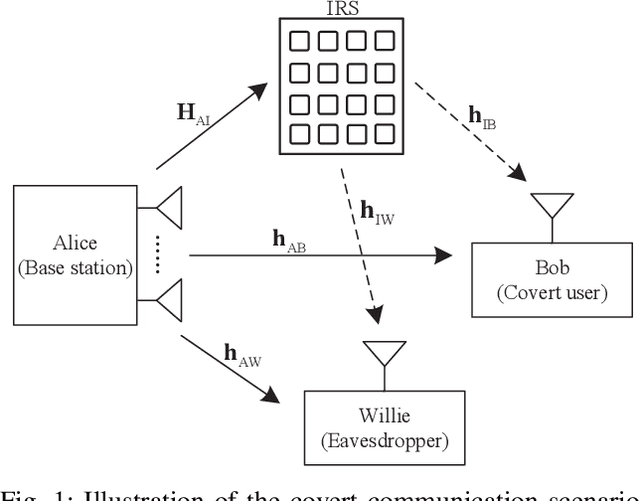
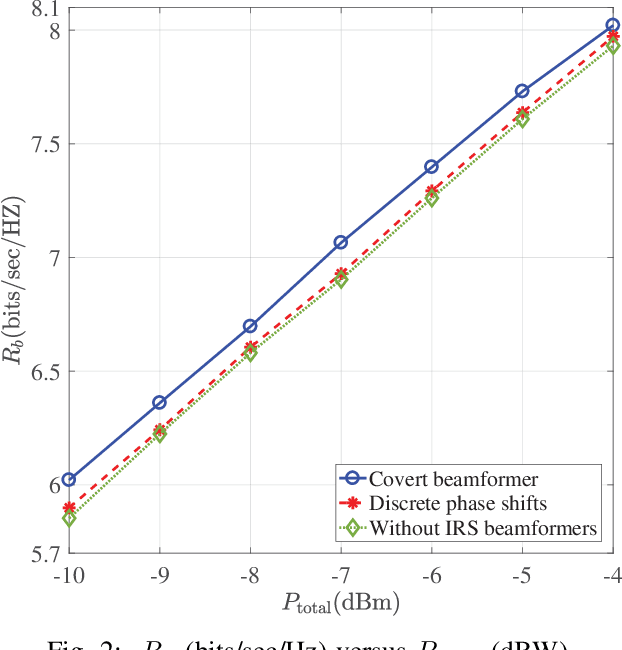
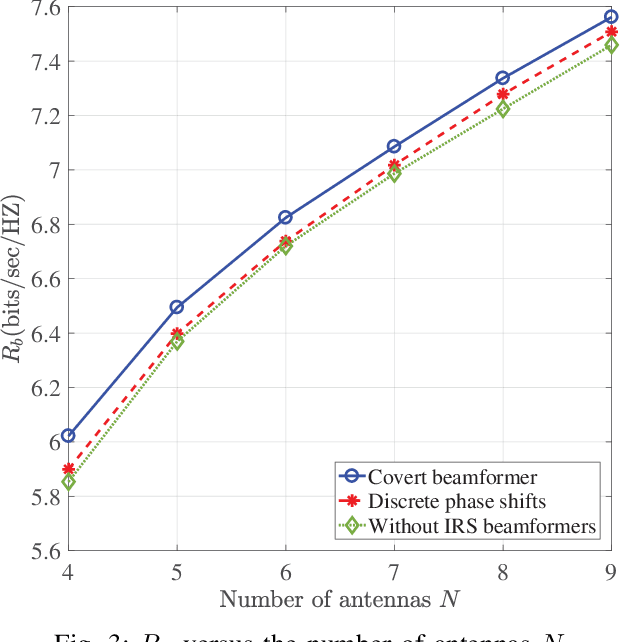
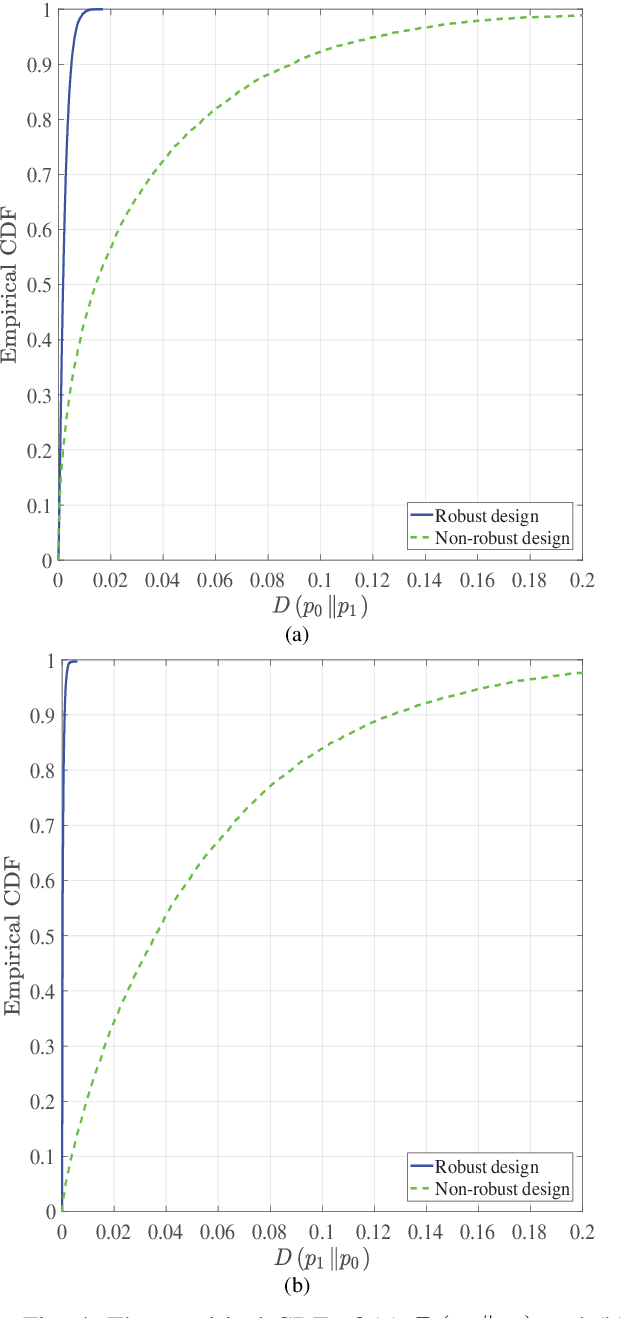
In this paper, we consider covert beamforming design for intelligent reflecting surface (IRS) assisted Internet of Things (IoT) networks, where Alice utilizes IRS to covertly transmit a message to Bob without being recognized by Willie. We investigate the joint beamformer design of Alice and IRS to maximize the covert rate of Bob when the knowledge about Willie's channel state information (WCSI) is perfect and imperfect at Alice, respectively. For the former case, we develop a covert beamformer under the perfect covert constraint by applying semidefinite relaxation. For the later case, the optimal decision threshold of Willie is derived, and we analyze the false alarm and the missed detection probabilities. Furthermore, we utilize the property of Kullback-Leibler divergence to develop the robust beamformer based on a relaxation, S-Lemma and alternate iteration approach. Finally, the numerical experiments evaluate the performance of the proposed covert beamformer design and robust beamformer design.
Novel EEG-based BCIs for Elderly Rehabilitation Enhancement
Oct 08, 2021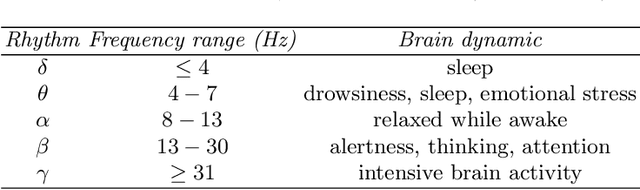
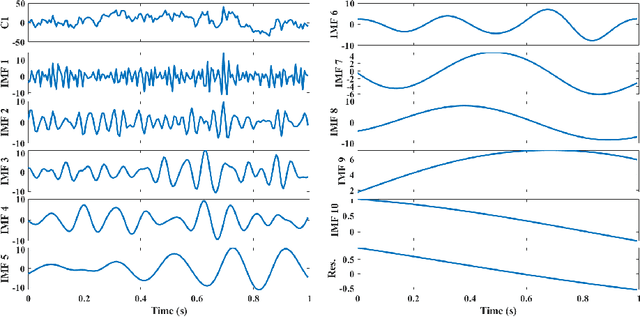
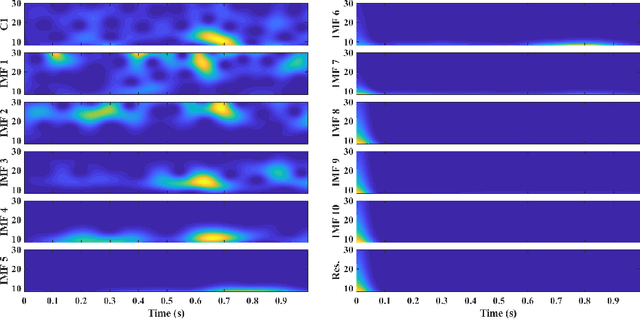

The ageing process may lead to cognitive and physical impairments, which may affect elderly everyday life. In recent years, the use of Brain Computer Interfaces (BCIs) based on Electroencephalography (EEG) has revealed to be particularly effective to promote and enhance rehabilitation procedures, especially by exploiting motor imagery experimental paradigms. Moreover, BCIs seem to increase patients' engagement and have proved to be reliable tools for elderly overall wellness improvement. However, EEG signals usually present a low signal-to-noise ratio and can be recorded for a limited time. Thus, irrelevant information and faulty samples could affect the BCI performance. Introducing a methodology that allows the extraction of informative components from the EEG signal while maintaining its intrinsic characteristics, may provide a solution to both the described issues: noisy data may be avoided by having only relevant components and combining relevant components may represent a good strategy to substitute the data without requiring long or repeated EEG recordings. Moreover, substituting faulty trials may significantly improve the classification performances of a BCI when translating imagined movement to rehabilitation systems. To this end, in this work the EEG signal decomposition by means of multivariate empirical mode decomposition is proposed to obtain its oscillatory modes, called Intrinsic Mode Functions (IMFs). Subsequently, a novel procedure for relevant IMF selection criterion based on the IMF time-frequency representation and entropy is provided. After having verified the reliability of the EEG signal reconstruction with the relevant IMFs only, the relevant IMFs are combined to produce new artificial data and provide new samples to use for BCI training.
DDR-Net: Dividing and Downsampling Mixed Network for Diffeomorphic Image Registration
May 24, 2021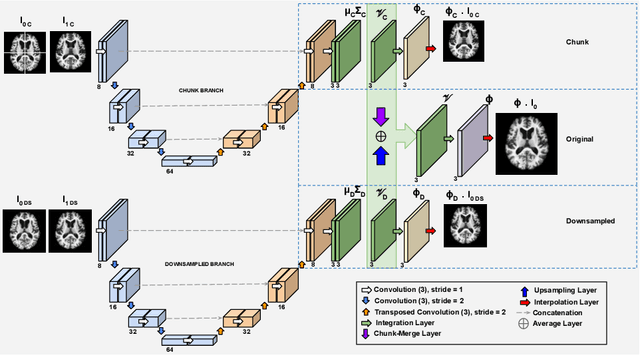
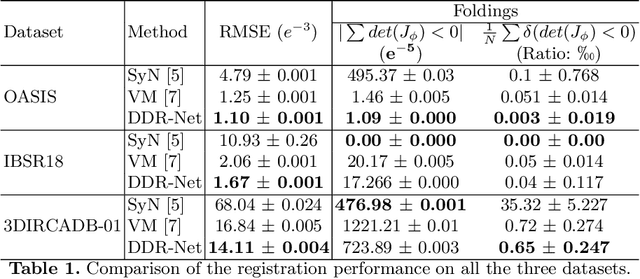
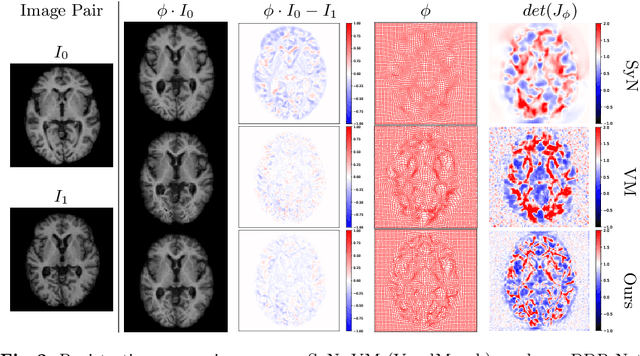
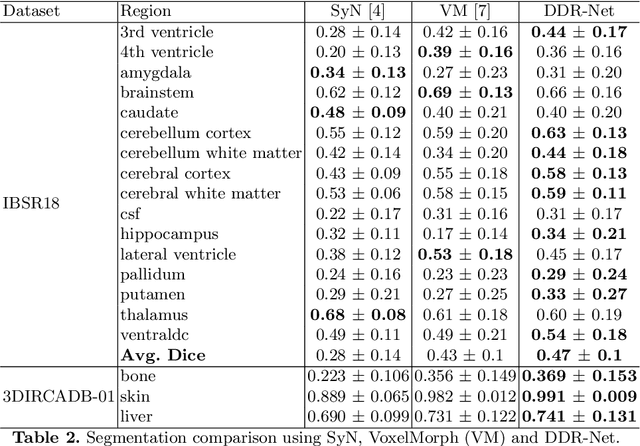
Deep diffeomorphic registration faces significant challenges for high-dimensional images, especially in terms of memory limits. Existing approaches either downsample original images, or approximate underlying transformations, or reduce model size. The information loss during the approximation or insufficient model capacity is a hindrance to the registration accuracy for high-dimensional images, e.g., 3D medical volumes. In this paper, we propose a Dividing and Downsampling mixed Registration network (DDR-Net), a general architecture that preserves most of the image information at multiple scales. DDR-Net leverages the global context via downsampling the input and utilizes the local details from divided chunks of the input images. This design reduces the network input size and its memory cost; meanwhile, by fusing global and local information, DDR-Net obtains both coarse-level and fine-level alignments in the final deformation fields. We evaluate DDR-Net on three public datasets, i.e., OASIS, IBSR18, and 3DIRCADB-01, and the experimental results demonstrate our approach outperforms existing approaches.
A New Approach for Image Authentication Framework for Media Forensics Purpose
Oct 03, 2021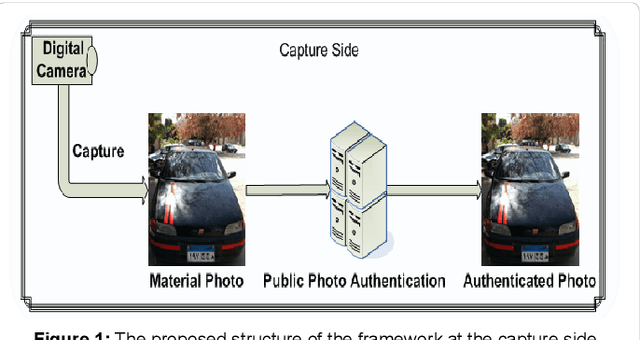

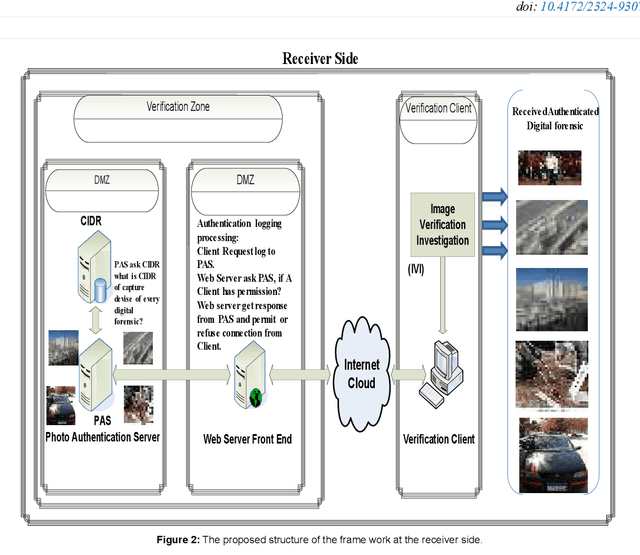
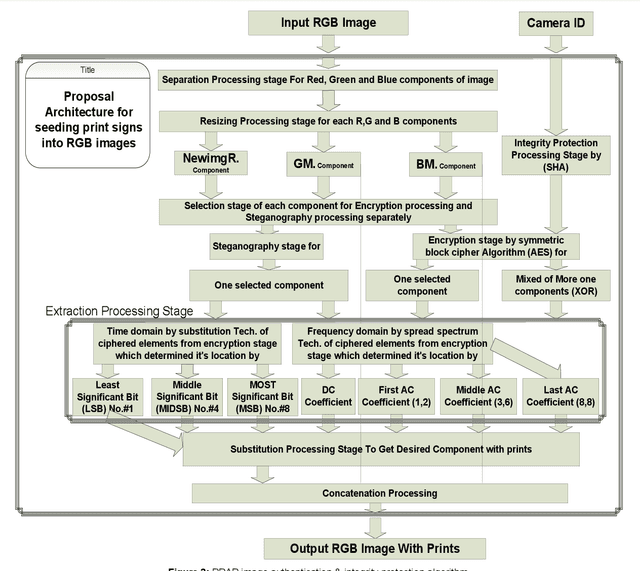
With the increasing widely spread digital media become using in most fields such as medical care, Oceanography, Exploration processing, security purpose, military fields and astronomy, evidence in criminals and more vital fields and then digital Images become have different appreciation values according to what is important of carried information by digital images. Due to the easy manipulation property of digital images (by proper computer software) makes us doubtful when are juries using digital images as forensic evidence in courts, especially, if the digital images are main evidence to demonstrate the relationship between suspects and the criminals. Obviously, here demonstrate importance of data Originality Protection methods to detect unauthorized process like modification or duplication and then enhancement protection of evidence to guarantee rights of incriminatory. In this paper, we shall introduce a novel digital forensic security framework for digital image authentication and originality identification techniques and related methodologies, algorithms and protocols that are applied on camera captured images. The approach depends on implanting secret code into RGB images that should indicate any unauthorized modification on the image under investigation. The secret code generation depends mainly on two main parameter types, namely the image characteristics and capturing device identifier. In this paper, the architecture framework will be analyzed, explained and discussed together with the associated protocols, algorithms and methodologies. Also, the secret code deduction and insertion techniques will be analyzed and discussed, in addition to the image benchmarking and quality testing techniques.
* 11 pages, 19 figures and one table
End-to-end Neural Video Coding Using a Compound Spatiotemporal Representation
Aug 05, 2021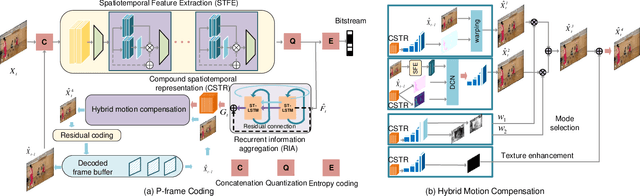
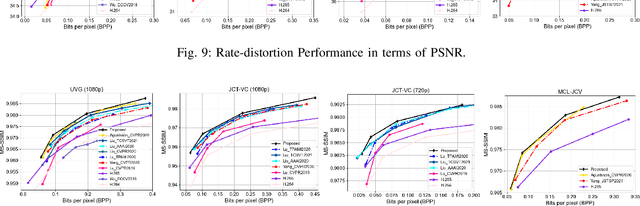
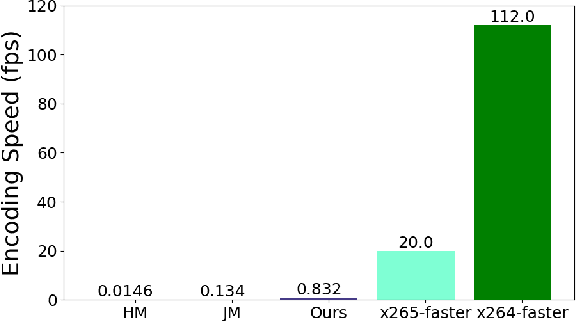
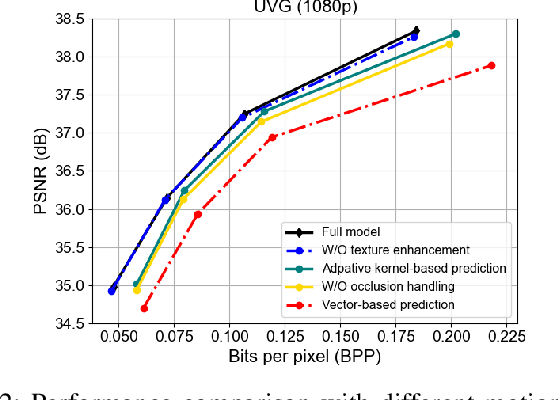
Recent years have witnessed rapid advances in learnt video coding. Most algorithms have solely relied on the vector-based motion representation and resampling (e.g., optical flow based bilinear sampling) for exploiting the inter frame redundancy. In spite of the great success of adaptive kernel-based resampling (e.g., adaptive convolutions and deformable convolutions) in video prediction for uncompressed videos, integrating such approaches with rate-distortion optimization for inter frame coding has been less successful. Recognizing that each resampling solution offers unique advantages in regions with different motion and texture characteristics, we propose a hybrid motion compensation (HMC) method that adaptively combines the predictions generated by these two approaches. Specifically, we generate a compound spatiotemporal representation (CSTR) through a recurrent information aggregation (RIA) module using information from the current and multiple past frames. We further design a one-to-many decoder pipeline to generate multiple predictions from the CSTR, including vector-based resampling, adaptive kernel-based resampling, compensation mode selection maps and texture enhancements, and combines them adaptively to achieve more accurate inter prediction. Experiments show that our proposed inter coding system can provide better motion-compensated prediction and is more robust to occlusions and complex motions. Together with jointly trained intra coder and residual coder, the overall learnt hybrid coder yields the state-of-the-art coding efficiency in low-delay scenario, compared to the traditional H.264/AVC and H.265/HEVC, as well as recently published learning-based methods, in terms of both PSNR and MS-SSIM metrics.
Omnidirectional ghost imaging system and unwrapping-free panoramic ghost imaging
Aug 11, 2021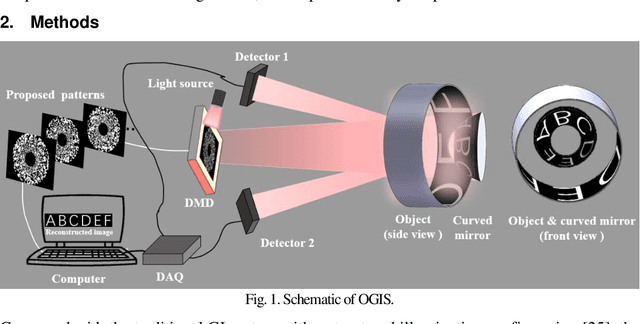
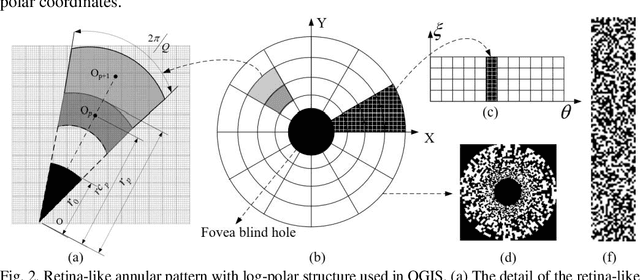

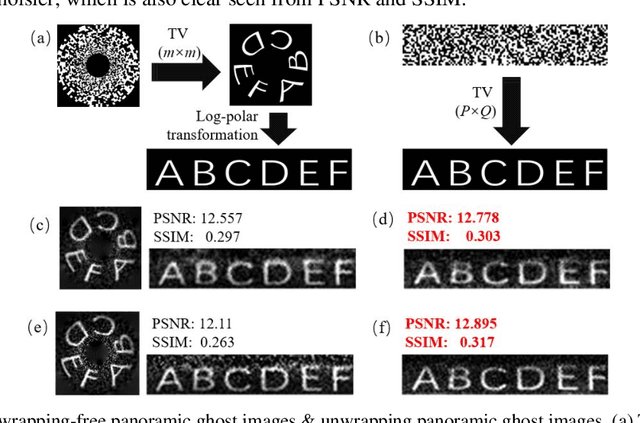
Ghost imaging (GI) is a novel imaging method, which can reconstruct the object information by the light intensity correlation measurements. However, at present, the field of view (FOV) is limited to the illuminating range of the light patterns. To enlarge FOV of GI efficiently, here we proposed the omnidirectional ghost imaging system (OGIS), which can achieve a 360{\deg} omnidirectional FOV at one shot only by adding a curved mirror. Moreover, by designing the retina-like annular patterns with log-polar patterns, OGIS can obtain unwrapping-free undistorted panoramic images with uniform resolution, which opens up a new way for the application of GI.
Cross Attention-guided Dense Network for Images Fusion
Sep 23, 2021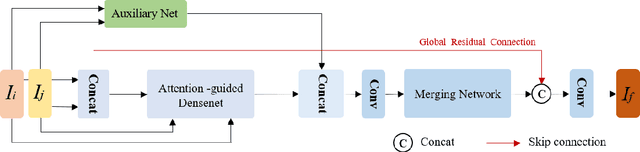
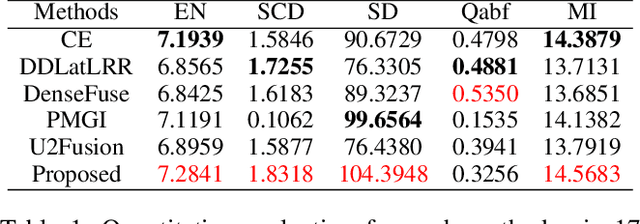
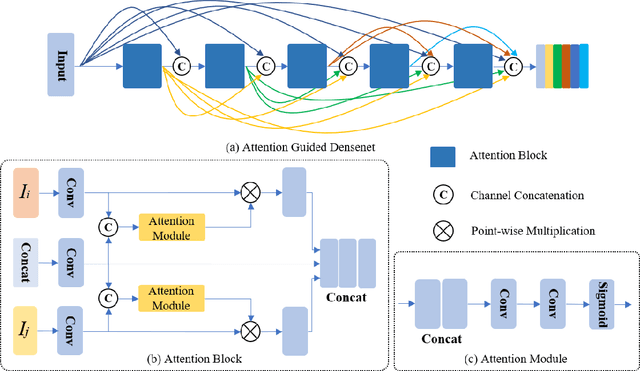
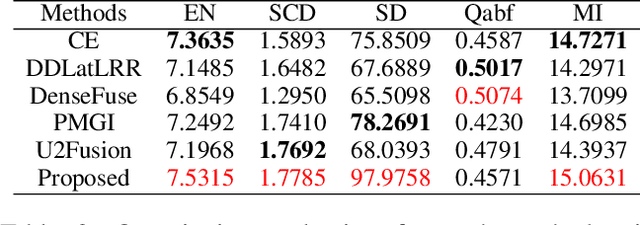
In recent years, various applications in computer vision have achieved substantial progress based on deep learning, which has been widely used for image fusion and shown to achieve adequate performance. However, suffering from limited ability in modelling the spatial correspondence of different source images, it still remains a great challenge for existing unsupervised image fusion models to extract appropriate feature and achieves adaptive and balanced fusion. In this paper, we propose a novel cross attention-guided image fusion network, which is a unified and unsupervised framework for multi-modal image fusion, multi-exposure image fusion, and multi-focus image fusion. Different from the existing self-attention module, our cross attention module focus on modelling the cross-correlation between different source images. Using the proposed cross attention module as core block, a densely connected cross attention-guided network is built to dynamically learn the spatial correspondence to derive better alignment of important details from different input images. Meanwhile, an auxiliary branch is also designed to model the long-range information, and a merging network is attached to finally reconstruct the fusion image. Extensive experiments have been carried out on publicly available datasets, and the results demonstrate that the proposed model outperforms the state-of-the-art quantitatively and qualitatively.