 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Embedding and Beamforming: All-neural Causal Beamformer for Multichannel Speech Enhancement
Sep 02, 2021
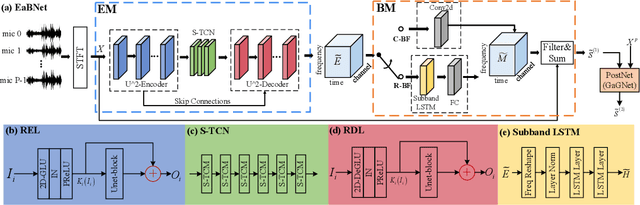
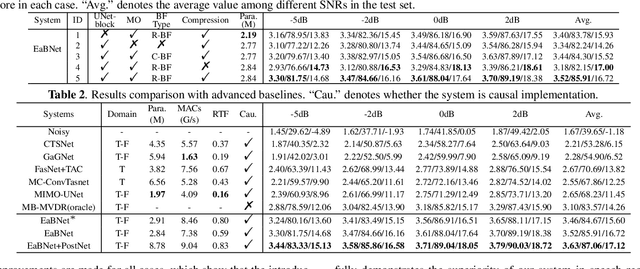
The spatial covariance matrix has been considered to be significant for beamformers. Standing upon the intersection of traditional beamformers and deep neural networks, we propose a causal neural beamformer paradigm called Embedding and Beamforming, and two core modules are designed accordingly, namely EM and BM. For EM, instead of estimating spatial covariance matrix explicitly, the 3-D embedding tensor is learned with the network, where both spectral and spatial discriminative information can be represented. For BM, a network is directly leveraged to derive the beamforming weights so as to implement filter-and-sum operation. To further improve the speech quality, a post-processing module is introduced to further suppress the residual noise. Based on the DNS-Challenge dataset, we conduct the experiments for multichannel speech enhancement and the results show that the proposed system outperforms previous advanced baselines by a large margin in multiple evaluation metrics.
Towards Instance-Optimal Offline Reinforcement Learning with Pessimism
Oct 17, 2021

We study the offline reinforcement learning (offline RL) problem, where the goal is to learn a reward-maximizing policy in an unknown Markov Decision Process (MDP) using the data coming from a policy $\mu$. In particular, we consider the sample complexity problems of offline RL for finite-horizon MDPs. Prior works study this problem based on different data-coverage assumptions, and their learning guarantees are expressed by the covering coefficients which lack the explicit characterization of system quantities. In this work, we analyze the Adaptive Pessimistic Value Iteration (APVI) algorithm and derive the suboptimality upper bound that nearly matches \[ O\left(\sum_{h=1}^H\sum_{s_h,a_h}d^{\pi^\star}_h(s_h,a_h)\sqrt{\frac{\mathrm{Var}_{P_{s_h,a_h}}{(V^\star_{h+1}+r_h)}}{d^\mu_h(s_h,a_h)}}\sqrt{\frac{1}{n}}\right). \] In complementary, we also prove a per-instance information-theoretical lower bound under the weak assumption that $d^\mu_h(s_h,a_h)>0$ if $d^{\pi^\star}_h(s_h,a_h)>0$. Different from the previous minimax lower bounds, the per-instance lower bound (via local minimaxity) is a much stronger criterion as it applies to individual instances separately. Here $\pi^\star$ is a optimal policy, $\mu$ is the behavior policy and $d_h^\mu$ is the marginal state-action probability. We call the above equation the intrinsic offline reinforcement learning bound since it directly implies all the existing optimal results: minimax rate under uniform data-coverage assumption, horizon-free setting, single policy concentrability, and the tight problem-dependent results. Later, we extend the result to the assumption-free regime (where we make no assumption on $ \mu$) and obtain the assumption-free intrinsic bound. Due to its generic form, we believe the intrinsic bound could help illuminate what makes a specific problem hard and reveal the fundamental challenges in offline RL.
Knowledge Enhanced Fine-Tuning for Better Handling Unseen Entities in Dialogue Generation
Sep 12, 2021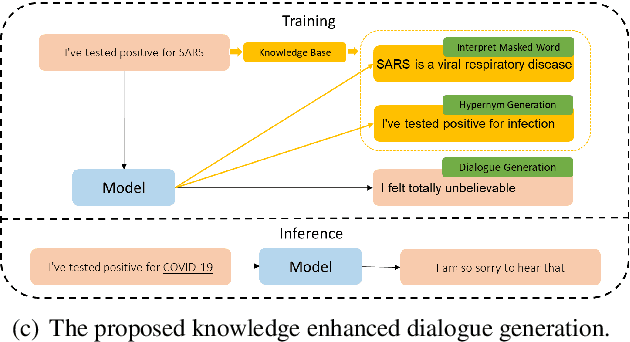
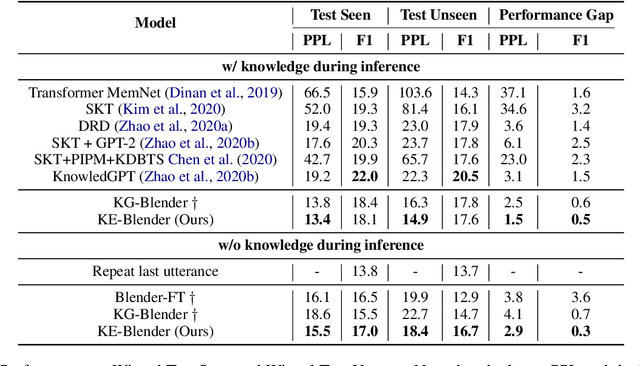
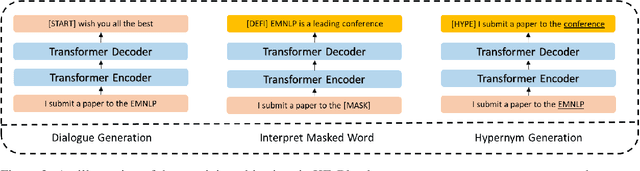
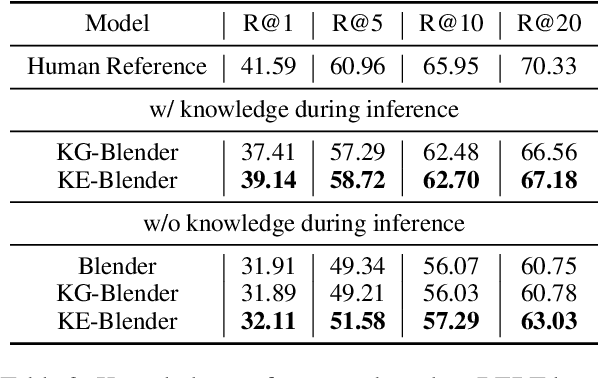
Although pre-training models have achieved great success in dialogue generation, their performance drops dramatically when the input contains an entity that does not appear in pre-training and fine-tuning datasets (unseen entity). To address this issue, existing methods leverage an external knowledge base to generate appropriate responses. In real-world scenario, the entity may not be included by the knowledge base or suffer from the precision of knowledge retrieval. To deal with this problem, instead of introducing knowledge base as the input, we force the model to learn a better semantic representation by predicting the information in the knowledge base, only based on the input context. Specifically, with the help of a knowledge base, we introduce two auxiliary training objectives: 1) Interpret Masked Word, which conjectures the meaning of the masked entity given the context; 2) Hypernym Generation, which predicts the hypernym of the entity based on the context. Experiment results on two dialogue corpus verify the effectiveness of our methods under both knowledge available and unavailable settings.
Ethereum Data Structures
Aug 12, 2021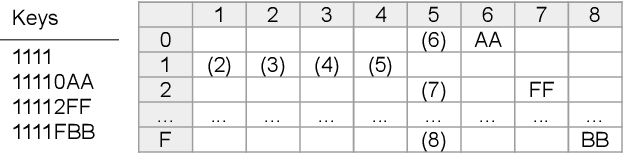
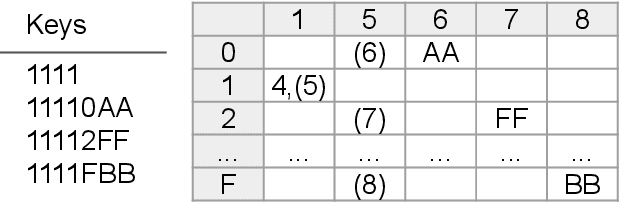
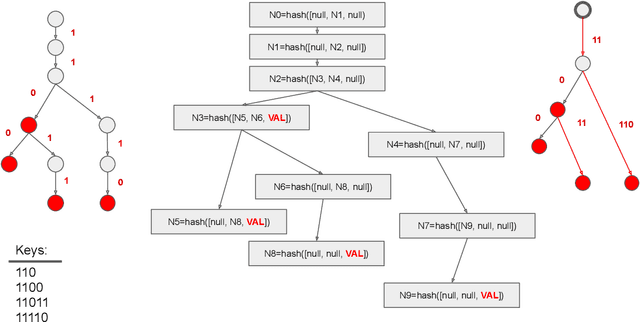
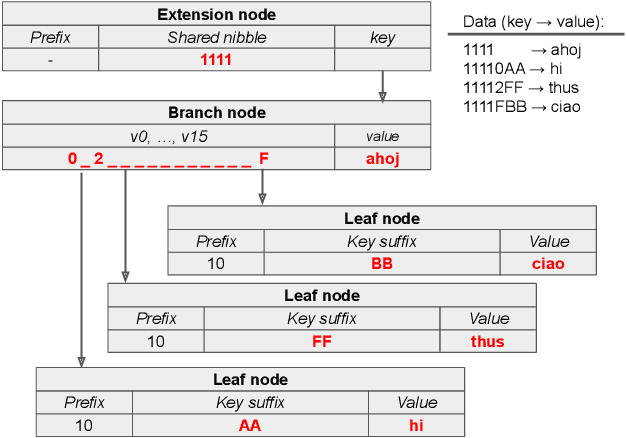
Ethereum platform operates with rich spectrum of data structures and hashing and coding functions. The main source describing them is the Yellow paper, complemented by a lot of informal blogs. These sources are somehow limited. In particular, the Yellow paper does not ideally balance brevity and detail, in some parts it is very detail, while too shallow elsewhere. The blogs on the other hand are often too vague and in certain cases contain incorrect information. As a solution, we provide this document, which summarises data structures used in Ethereum. The goal is to provide sufficient detail while keeping brevity. Sufficiently detailed formal view is enriched with examples to extend on clarity.
In-Vehicle False Information Attack Detection and Mitigation Framework using Machine Learning and Software Defined Networking
Jun 24, 2019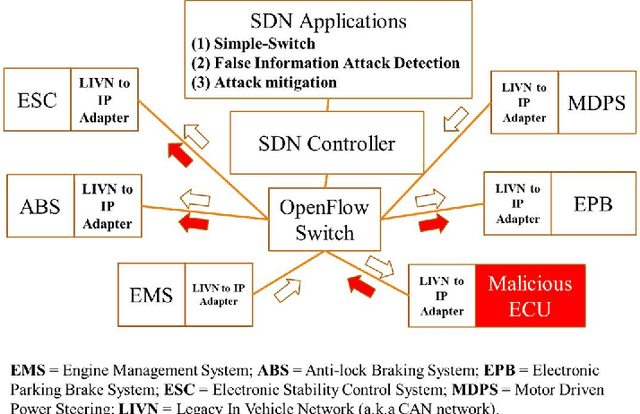
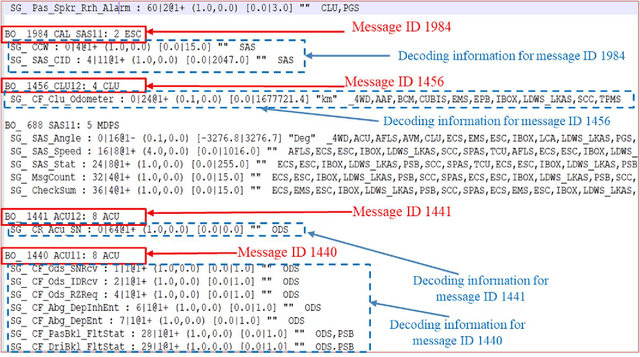
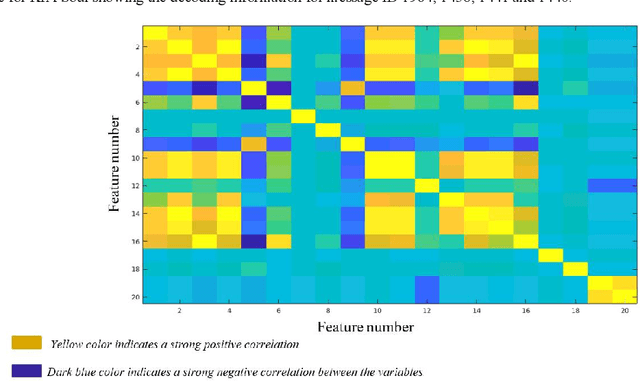
A modern vehicle contains many electronic control units (ECUs), which communicate with each other through the Controller Area Network (CAN) bus to ensure vehicle safety and performance. Emerging Connected and Automated Vehicles (CAVs) will have more ECUs and coupling between them due to the vast array of additional sensors, advanced driving features (such as lane keeping and navigation) and Vehicle-to-Everything (V2X) connectivity. As a result, CAVs will have more vulnerabilities within the in-vehicle network. In this study, we develop a software defined networking (SDN) based in-vehicle networking framework for security against false information attacks on CAN frames. We then created an attack model and attack datasets for false information attacks on brake-related ECUs in an SDN based in-vehicle network. We subsequently developed a machine-learning based false information attack/anomaly detection model for the real-time detection of anomalies within the in-vehicle network. Specifically, we utilized the concept of time-series classification and developed a Long Short-Term Memory (LSTM) based model that detects false information within the CAN data traffic. Additionally, based on our research, we highlighted policies for mitigating the effect of cyber-attacks using the SDN framework. The SDN-based attack detection model can detect false information with an accuracy, precision and recall of 95%, 95% and 87%, respectively, while satisfying the real-time communication and computational requirements.
Validation of Information Fusion
Jul 22, 2016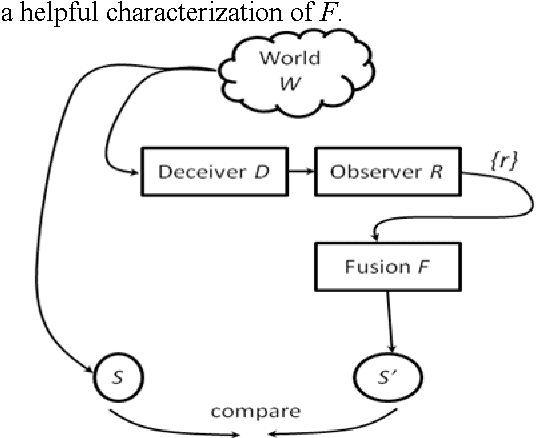
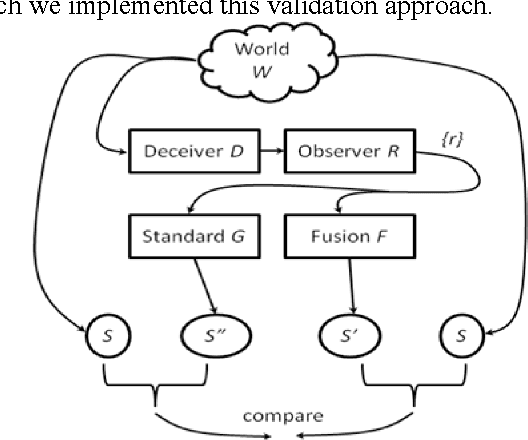
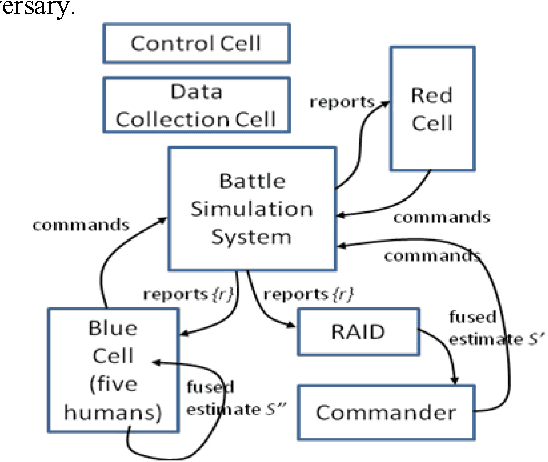
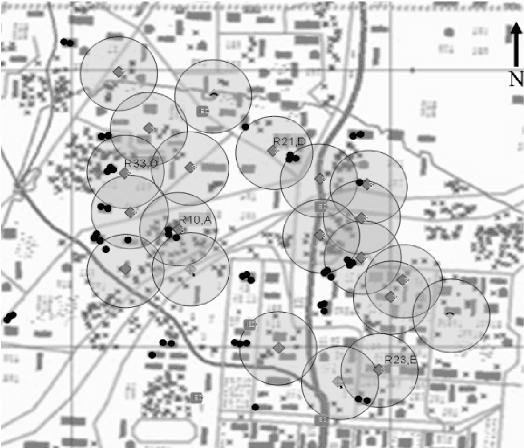
We motivate and offer a formal definition of validation as it applies to information fusion systems. Common definitions of validation compare the actual state of the world with that derived by the fusion process. This definition conflates properties of the fusion system with properties of systems that intervene between the world and the fusion system. We propose an alternative definition where validation of an information fusion system references a standard fusion device, such as recognized human experts. We illustrate the approach by describing the validation process implemented in RAID, a program conducted by DARPA and focused on information fusion in adversarial, deceptive environments.
Optimal Power Allocation for Rate Splitting Communications with Deep Reinforcement Learning
Jul 01, 2021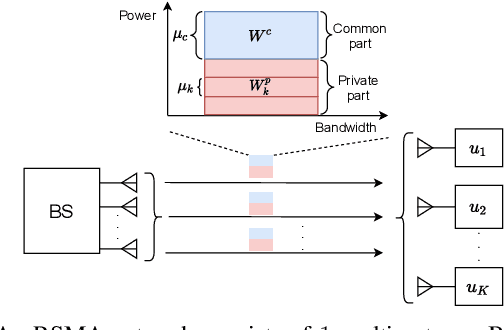
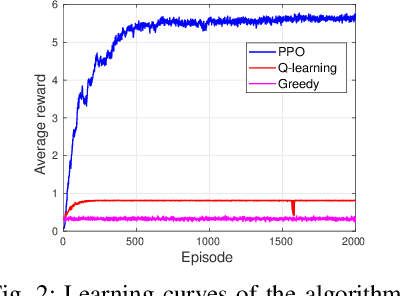
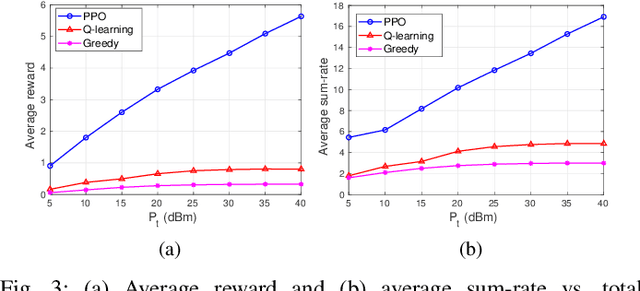
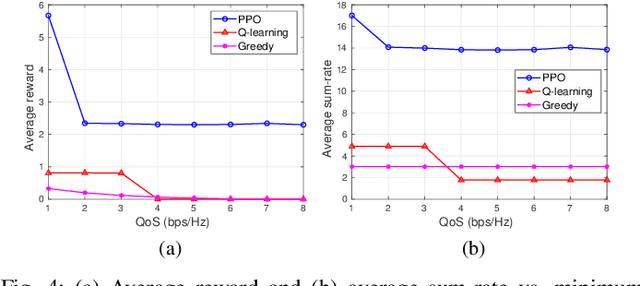
This letter introduces a novel framework to optimize the power allocation for users in a Rate Splitting Multiple Access (RSMA) network. In the network, messages intended for users are split into different parts that are a single common part and respective private parts. This mechanism enables RSMA to flexibly manage interference and thus enhance energy and spectral efficiency. Although possessing outstanding advantages, optimizing power allocation in RSMA is very challenging under the uncertainty of the communication channel and the transmitter has limited knowledge of the channel information. To solve the problem, we first develop a Markov Decision Process framework to model the dynamic of the communication channel. The deep reinforcement algorithm is then proposed to find the optimal power allocation policy for the transmitter without requiring any prior information of the channel. The simulation results show that the proposed scheme can outperform baseline schemes in terms of average sum-rate under different power and QoS requirements.
Computing an Optimal Pitching Strategy in a Baseball At-Bat
Oct 08, 2021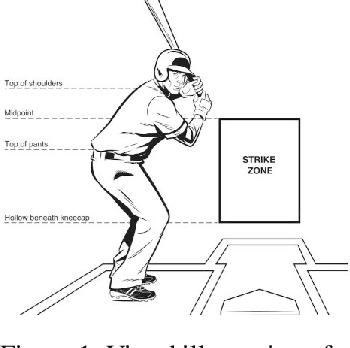
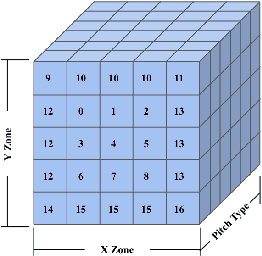
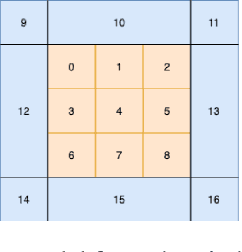
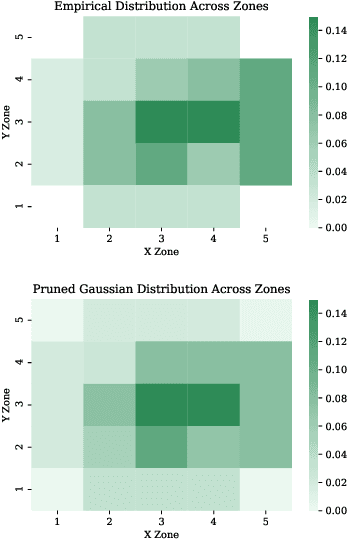
The field of quantitative analytics has transformed the world of sports over the last decade. To date, these analytic approaches are statistical at their core, characterizing what is and what was, while using this information to drive decisions about what to do in the future. However, as we often view team sports, such as soccer, hockey, and baseball, as pairwise win-lose encounters, it seems natural to model these as zero-sum games. We propose such a model for one important class of sports encounters: a baseball at-bat, which is a matchup between a pitcher and a batter. Specifically, we propose a novel model of this encounter as a zero-sum stochastic game, in which the goal of the batter is to get on base, an outcome the pitcher aims to prevent. The value of this game is the on-base percentage (i.e., the probability that the batter gets on base). In principle, this stochastic game can be solved using classical approaches. The main technical challenges lie in predicting the distribution of pitch locations as a function of pitcher intention, predicting the distribution of outcomes if the batter decides to swing at a pitch, and characterizing the level of patience of a particular batter. We address these challenges by proposing novel pitcher and batter representations as well as a novel deep neural network architecture for outcome prediction. Our experiments using Kaggle data from the 2015 to 2018 Major League Baseball seasons demonstrate the efficacy of the proposed approach.
Prioritized Subnet Sampling for Resource-Adaptive Supernet Training
Sep 12, 2021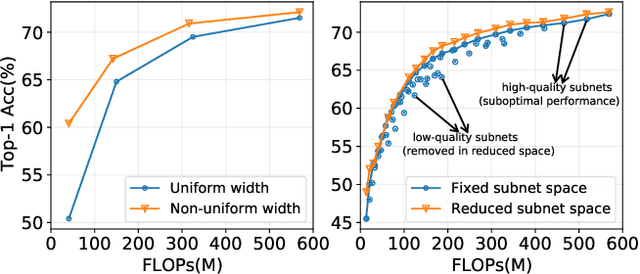
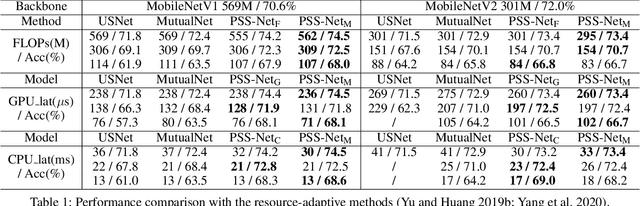
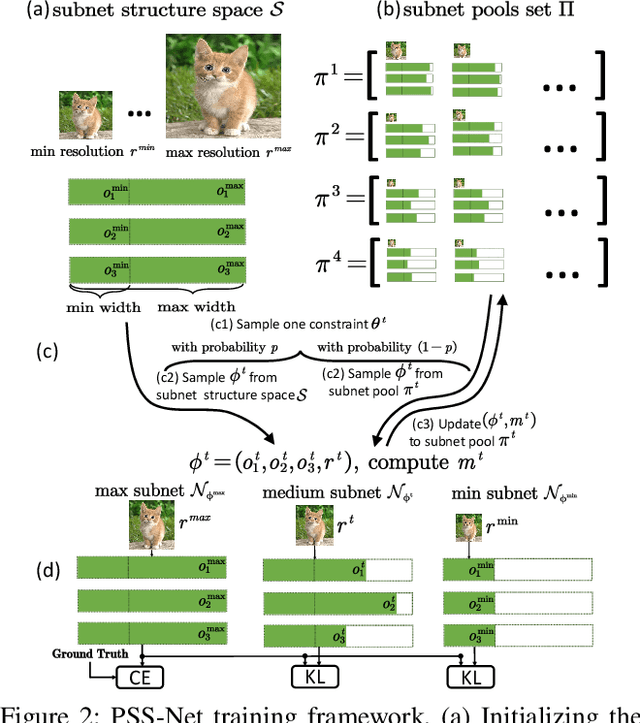
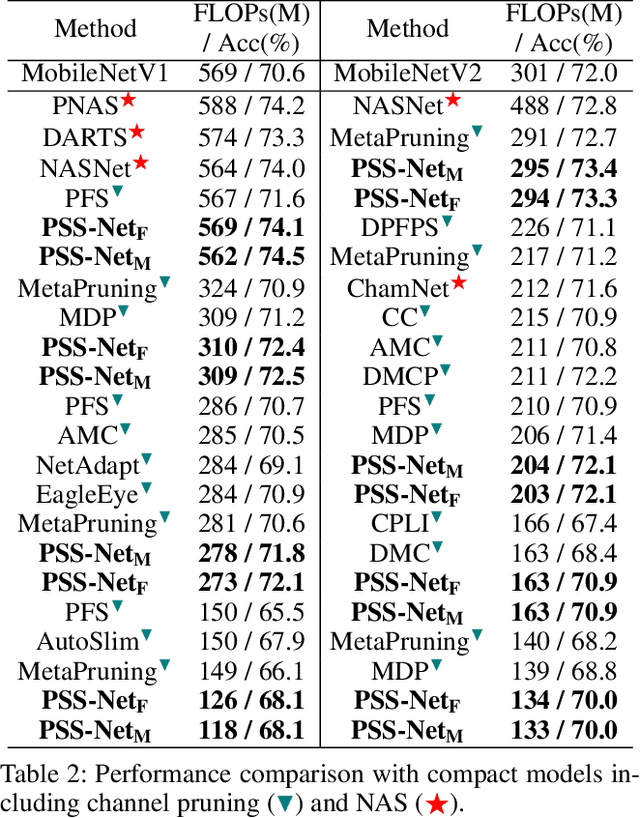
A resource-adaptive supernet adjusts its subnets for inference to fit the dynamically available resources. In this paper, we propose Prioritized Subnet Sampling to train a resource-adaptive supernet, termed PSS-Net. We maintain multiple subnet pools, each of which stores the information of substantial subnets with similar resource consumption. Considering a resource constraint, subnets conditioned on this resource constraint are sampled from a pre-defined subnet structure space and high-quality ones will be inserted into the corresponding subnet pool. Then, the sampling will gradually be prone to sampling subnets from the subnet pools. Moreover, the one with a better performance metric is assigned with higher priority to train our PSS-Net, if sampling is from a subnet pool. At the end of training, our PSS-Net retains the best subnet in each pool to entitle a fast switch of high-quality subnets for inference when the available resources vary. Experiments on ImageNet using MobileNetV1/V2 show that our PSS-Net can well outperform state-of-the-art resource-adaptive supernets. Our project is at https://github.com/chenbong/PSS-Net.
The 2nd Anti-UAV Workshop & Challenge: Methods and Results
Aug 25, 2021

The 2nd Anti-UAV Workshop \& Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two subsets in the dataset, $i.e.$, the test-dev subset and test-challenge subset. Both subsets consist of 140 thermal infrared video sequences, spanning multiple occurrences of multi-scale UAVs. Around 24 participating teams from the globe competed in the 2nd Anti-UAV Challenge. In this paper, we provide a brief summary of the 2nd Anti-UAV Workshop \& Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.