 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A comprehensive review of Binary Neural Network
Oct 19, 2021


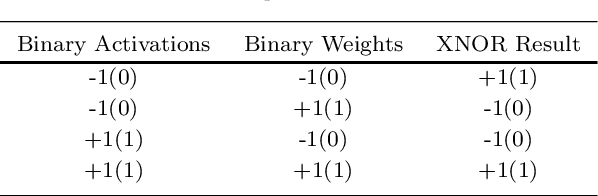
Binary Neural Network (BNN) method is an extreme application of convolutional neural network (CNN) parameter quantization. As opposed to the original CNN methods which employed floating-point computation with full-precision weights and activations, BBN uses 1-bit activations and weights. With BBNs, a significant amount of storage, network complexity and energy consumption can be reduced, and neural networks can be implemented more efficiently in embedded applications. Unfortunately, binarization causes severe information loss. A gap still exists between full-precision CNN models and their binarized counterparts. The recent developments in BNN have led to a lot of algorithms and solutions that have helped address this issue. This article provides a full overview of recent developments in BNN. The present paper focuses exclusively on 1-bit activations and weights networks, as opposed to previous surveys in which low-bit works are mixed in. In this paper, we conduct a complete investigation of BNN's development from their predecessors to the latest BNN algorithms and techniques, presenting a broad design pipeline, and discussing each module's variants. Along the way, this paper examines BNN (a) purpose: their early successes and challenges; (b) BNN optimization: selected representative works that contain key optimization techniques; (c) deployment: open-source frameworks for BNN modeling and development; (d) terminal: efficient computing architectures and devices for BNN and (e) applications: diverse applications with BNN. Moreover, this paper discusses potential directions and future research opportunities for the latest BNN algorithms and techniques, presents a broad design pipeline, and discusses each module's variants.
High-Power and High-Capacity Mobile Optical SWIPT
Jul 26, 2021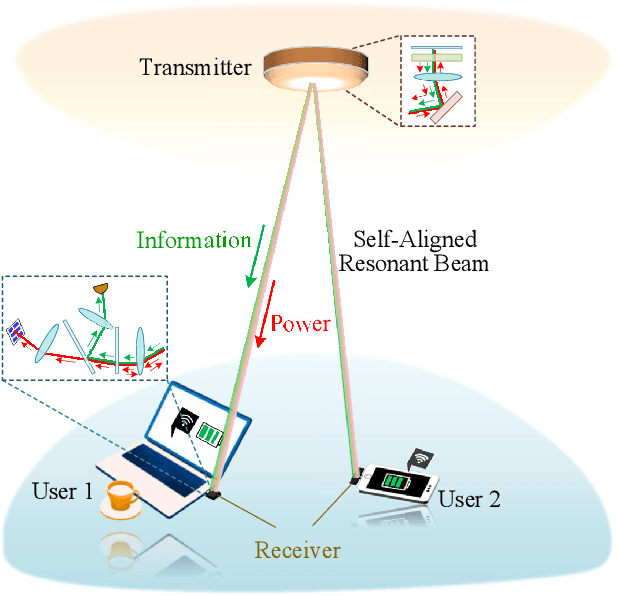
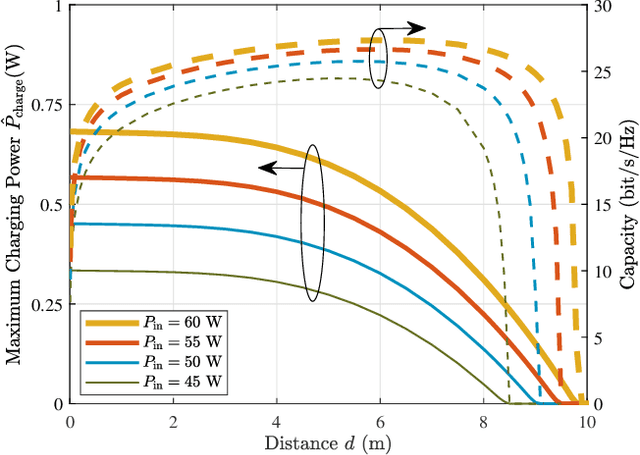
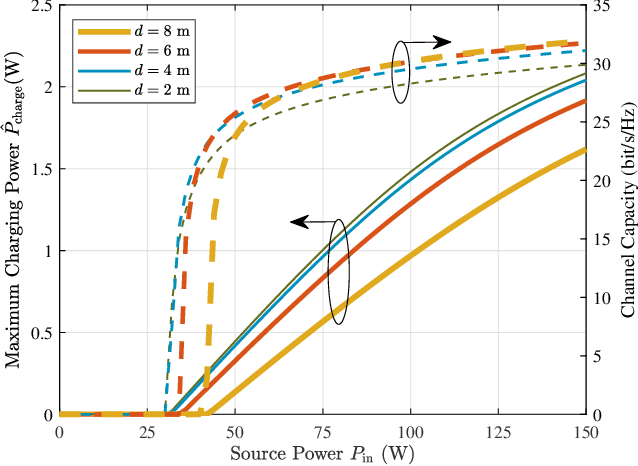
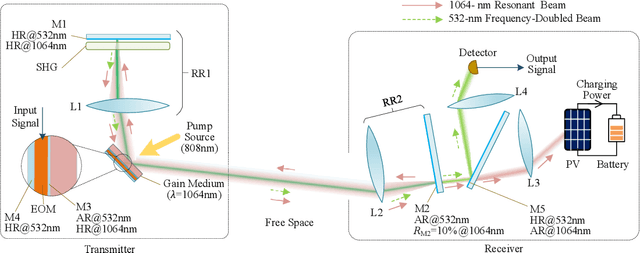
The increasing demands of power supply and data rate for mobile devices promote the research of simultaneous information and power transfer (SWIPT). Optical SWIPT, as known as simultaneous light information and power transfer (SLIPT), can provide high-capacity communication and high-power charging. However, light emitting diodes (LEDs)-based SLIPT technologies have low efficiency due to energy dissipation over the air. Laser-based SLIPT technologies face the challenge in mobility, as it needs accurate positioning, fast beam steering, and real-time tracking. In this paper, we propose a mobile SLIPT scheme based on spatially separated laser resonator (SSLR) and intra-cavity second harmonic generation (SHG). The power and data are transferred via separated frequencies, while they share the same self-aligned resonant beam path, without the needs of receiver positioning and beam steering. We establish the analysis model of the resonant beam power and its second harmonic power. We also evaluate the system performance on deliverable power and channel capacity. Numerical results show that the proposed system can achieve watt-level battery charging power and above 20-bit/s/Hz communication capacity over 8-m distance, which satisfies the requirements of most indoor mobile devices.
Compression, The Fermi Paradox and Artificial Super-Intelligence
Oct 05, 2021The following briefly discusses possible difficulties in communication with and control of an AGI (artificial general intelligence), building upon an explanation of The Fermi Paradox and preceding work on symbol emergence and artificial general intelligence. The latter suggests that to infer what someone means, an agent constructs a rationale for the observed behaviour of others. Communication then requires two agents labour under similar compulsions and have similar experiences (construct similar solutions to similar tasks). Any non-human intelligence may construct solutions such that any rationale for their behaviour (and thus the meaning of their signals) is outside the scope of what a human is inclined to notice or comprehend. Further, the more compressed a signal, the closer it will appear to random noise. Another intelligence may possess the ability to compress information to the extent that, to us, their signals would appear indistinguishable from noise (an explanation for The Fermi Paradox). To facilitate predictive accuracy an AGI would tend to more compressed representations of the world, making any rationale for their behaviour more difficult to comprehend for the same reason. Communication with and control of an AGI may subsequently necessitate not only human-like compulsions and experiences, but imposed cognitive impairment.
Event-Based Communication in Multi-Agent Distributed Q-Learning
Sep 09, 2021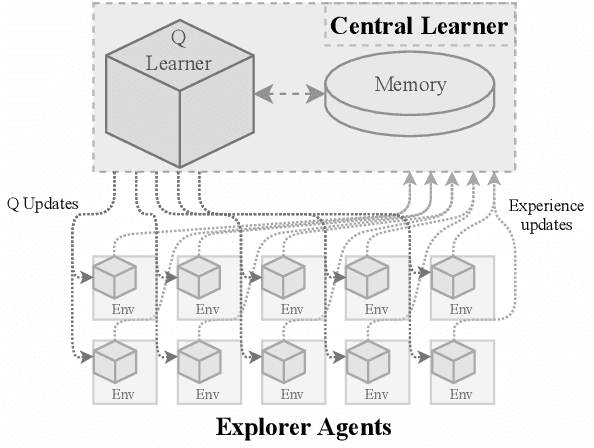
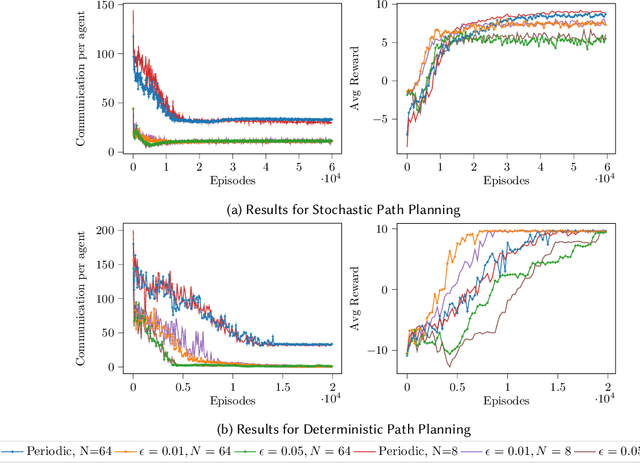
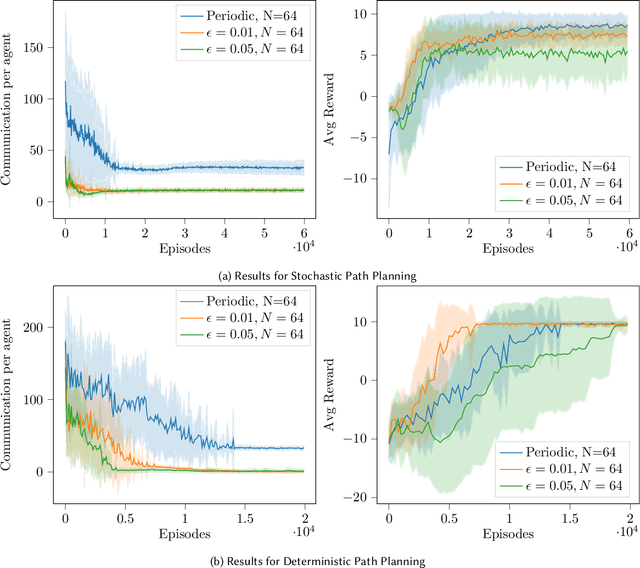
We present in this work an approach to reduce the communication of information needed on a multi-agent learning system inspired by Event Triggered Control (ETC) techniques. We consider a baseline scenario of a distributed Q-learning problem on a Markov Decision Process (MDP). Following an event-based approach, N agents explore the MDP and communicate experiences to a central learner only when necessary, which performs updates of the actor Q functions. We analyse the convergence guarantees retained with respect to a regular Q-learning algorithm, and present experimental results showing that event-based communication results in a substantial reduction of data transmission rates in such distributed systems. Additionally, we discuss what effects (desired and undesired) these event-based approaches have on the learning processes studied, and how they can be applied to more complex multi-agent learning systems.
Good for Misconceived Reasons: An Empirical Revisiting on the Need for Visual Context in Multimodal Machine Translation
May 30, 2021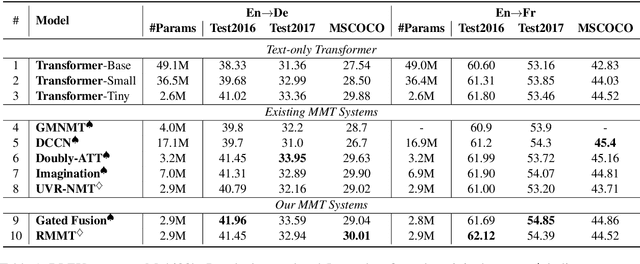
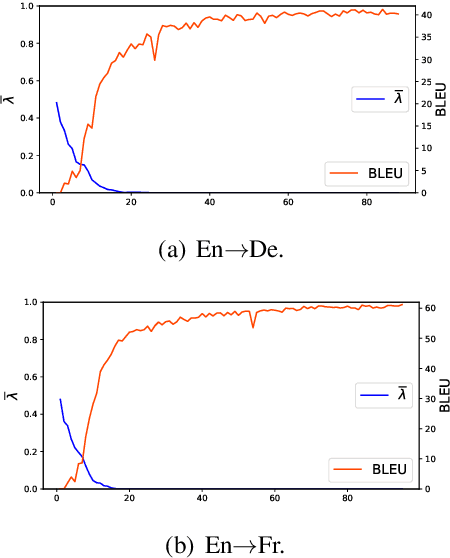
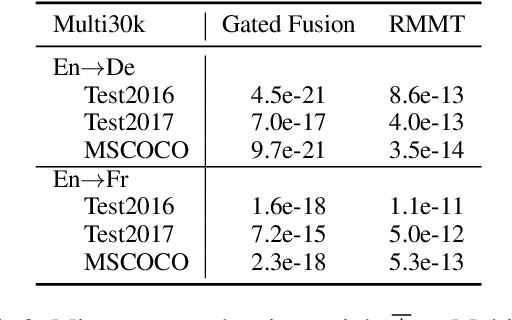
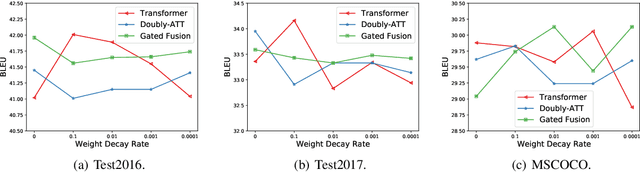
A neural multimodal machine translation (MMT) system is one that aims to perform better translation by extending conventional text-only translation models with multimodal information. Many recent studies report improvements when equipping their models with the multimodal module, despite the controversy of whether such improvements indeed come from the multimodal part. We revisit the contribution of multimodal information in MMT by devising two interpretable MMT models. To our surprise, although our models replicate similar gains as recently developed multimodal-integrated systems achieved, our models learn to ignore the multimodal information. Upon further investigation, we discover that the improvements achieved by the multimodal models over text-only counterparts are in fact results of the regularization effect. We report empirical findings that highlight the importance of MMT models' interpretability, and discuss how our findings will benefit future research.
Topological Attention for Time Series Forecasting
Jul 19, 2021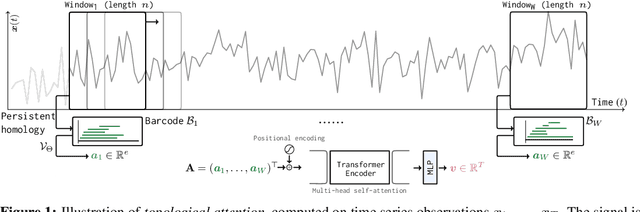
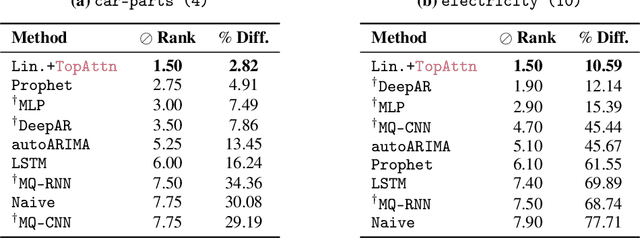
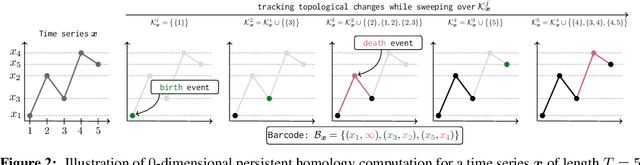
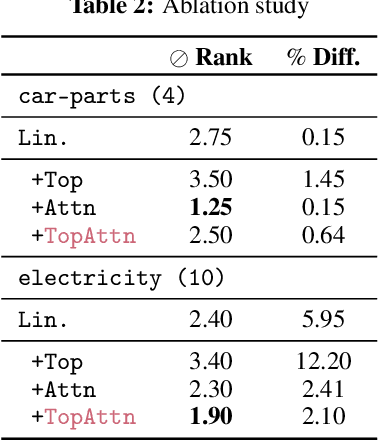
The problem of (point) forecasting $ \textit{univariate} $ time series is considered. Most approaches, ranging from traditional statistical methods to recent learning-based techniques with neural networks, directly operate on raw time series observations. As an extension, we study whether $\textit{local topological properties}$, as captured via persistent homology, can serve as a reliable signal that provides complementary information for learning to forecast. To this end, we propose $\textit{topological attention}$, which allows attending to local topological features within a time horizon of historical data. Our approach easily integrates into existing end-to-end trainable forecasting models, such as $\texttt{N-BEATS}$, and in combination with the latter exhibits state-of-the-art performance on the large-scale M4 benchmark dataset of 100,000 diverse time series from different domains. Ablation experiments, as well as a comparison to a broad range of forecasting methods in a setting where only a single time series is available for training, corroborate the beneficial nature of including local topological information through an attention mechanism.
From Pivots to Graphs: Augmented CycleDensity as a Generalization to One Time InverseConsultation
Aug 27, 2021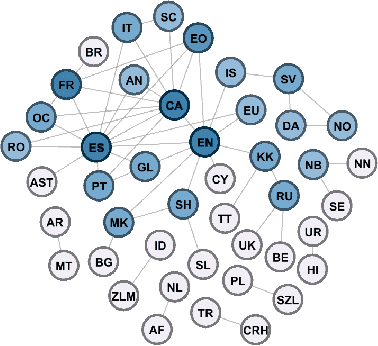
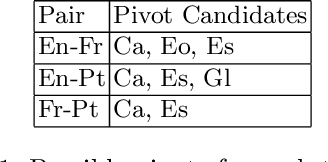
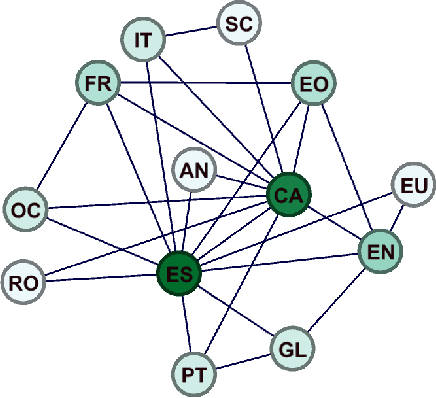
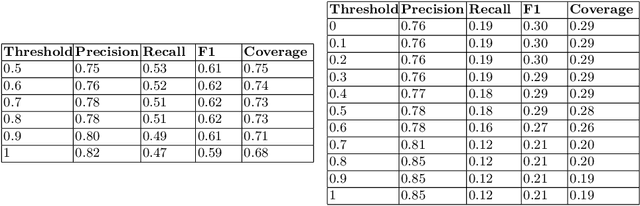
This paper describes an approach used to generate new translations using raw bilingual dictionaries as part of the 4th Task Inference Across Dictionaries (TIAD 2021) shared task. We propose Augmented Cycle Density (ACD) as a framework that combines insights from two state of the art methods that require no sense information and parallel corpora: Cycle Density (CD) and One Time Inverse Consultation (OTIC). The task results show that across 3 unseen language pairs, ACD's predictions, has more than double (74%) the coverage of OTIC at almost the same precision (76%). ACD combines CD's scalability - leveraging rich multilingual graphs for better predictions, and OTIC's data efficiency - producing good results with the minimum possible resource of one pivot language.
GeoSeq2Seq: Information Geometric Sequence-to-Sequence Networks
Jan 05, 2018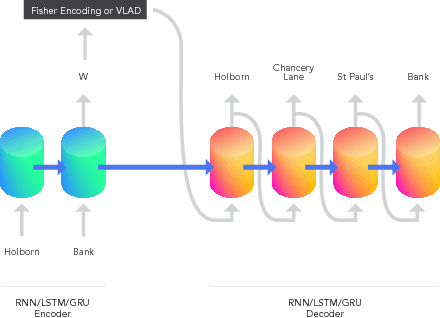
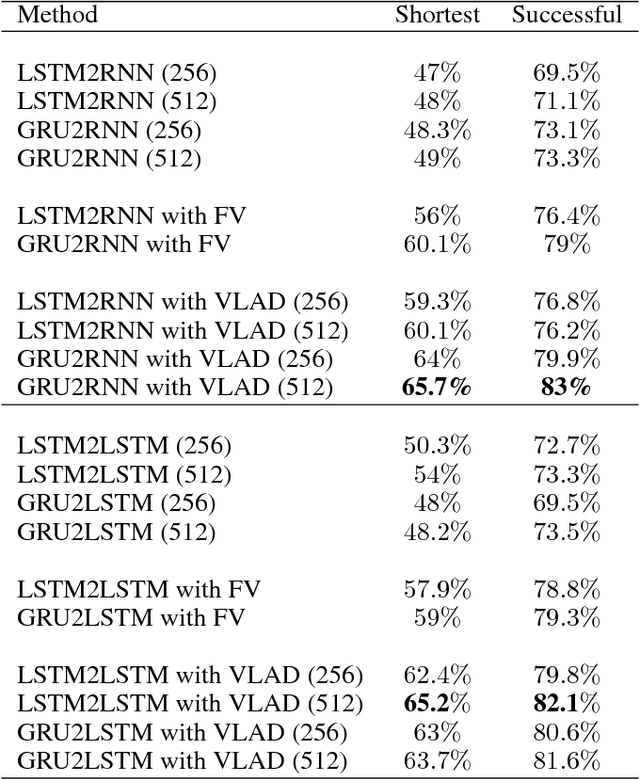
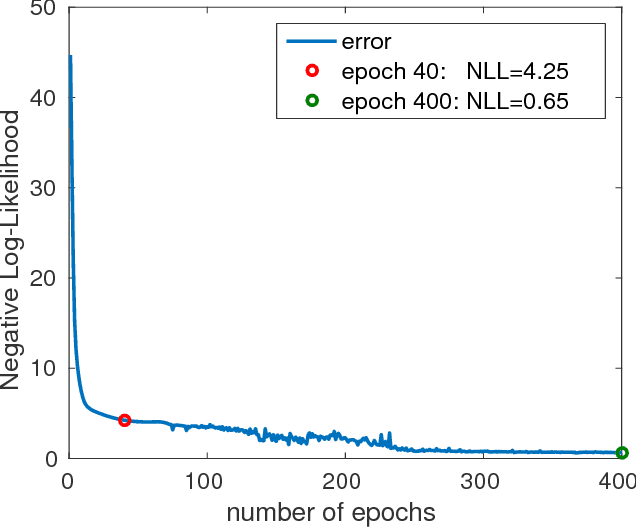
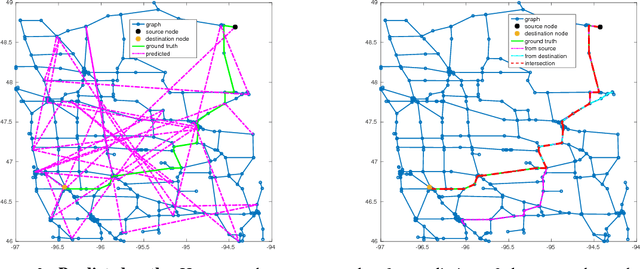
The Fisher information metric is an important foundation of information geometry, wherein it allows us to approximate the local geometry of a probability distribution. Recurrent neural networks such as the Sequence-to-Sequence (Seq2Seq) networks that have lately been used to yield state-of-the-art performance on speech translation or image captioning have so far ignored the geometry of the latent embedding, that they iteratively learn. We propose the information geometric Seq2Seq (GeoSeq2Seq) network which abridges the gap between deep recurrent neural networks and information geometry. Specifically, the latent embedding offered by a recurrent network is encoded as a Fisher kernel of a parametric Gaussian Mixture Model, a formalism common in computer vision. We utilise such a network to predict the shortest routes between two nodes of a graph by learning the adjacency matrix using the GeoSeq2Seq formalism; our results show that for such a problem the probabilistic representation of the latent embedding supersedes the non-probabilistic embedding by 10-15\%.
LDC-Net: A Unified Framework for Localization, Detection and Counting in Dense Crowds
Oct 10, 2021
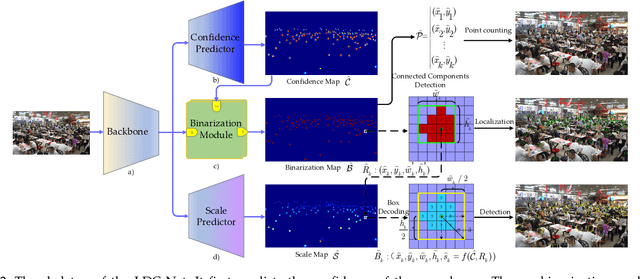

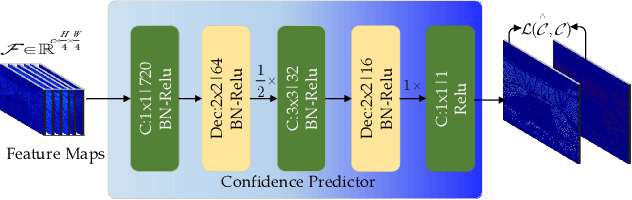
The rapid development in visual crowd analysis shows a trend to count people by positioning or even detecting, rather than simply summing a density map. It also enlightens us back to the essence of the field, detection to count, which can give more abundant crowd information and has more practical applications. However, some recent work on crowd localization and detection has two limitations: 1) The typical detection methods can not handle the dense crowds and a large variation in scale; 2) The density map heuristic methods suffer from performance deficiency in position and box prediction, especially in high density or large-size crowds. In this paper, we devise a tailored baseline for dense crowds location, detection, and counting from a new perspective, named as LDC-Net for convenience, which has the following features: 1) A strong but minimalist paradigm to detect objects by only predicting a location map and a size map, which endows an ability to detect in a scene with any capacity ($0 \sim 10,000+$ persons); 2) Excellent cross-scale ability in facing a large variation, such as the head ranging in $0 \sim 100,000+$ pixels; 3) Achieve superior performance in location and box prediction tasks, as well as a competitive counting performance compared with the density-based methods. Finally, the source code and pre-trained models will be released.
A Medical Pre-Diagnosis System for Histopathological Image of Breast Cancer
Sep 16, 2021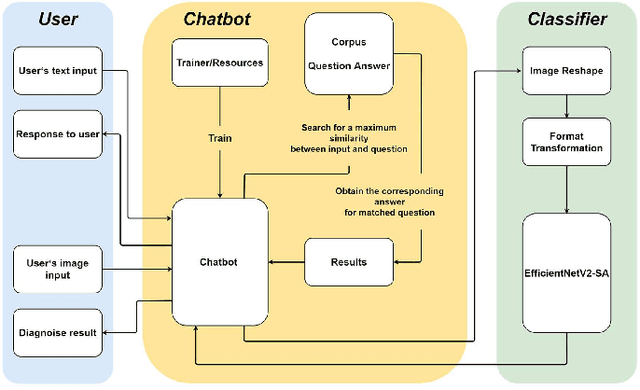
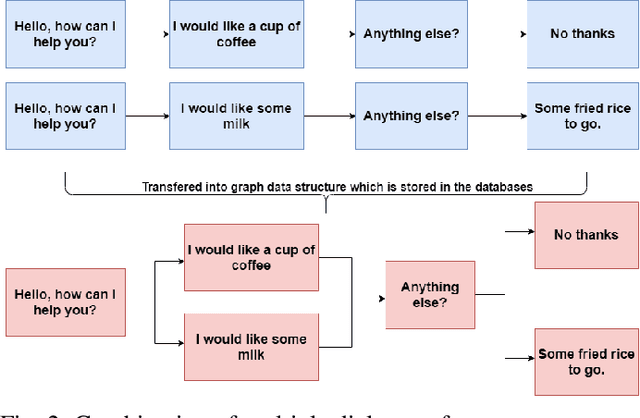
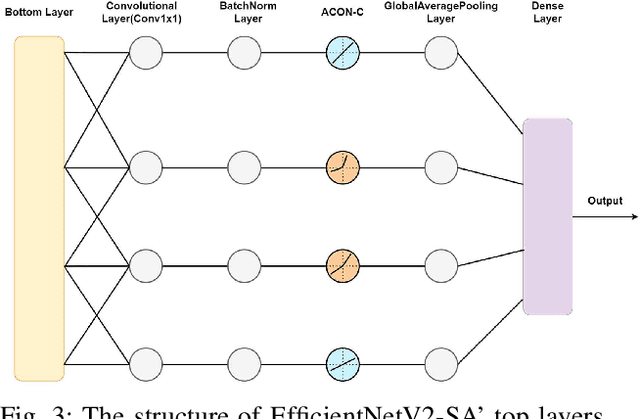

This paper constructs a novel intelligent medical diagnosis system, which can realize automatic communication and breast cancer pathological image recognition. This system contains two main parts, including a pre-training chatbot called M-Chatbot and an improved neural network model of EfficientNetV2-S named EfficientNetV2-SA, in which the activation function in top layers is replaced by ACON-C. Using information retrieval mechanism, M-Chatbot instructs patients to send breast pathological image to EfficientNetV2-SA network, and then the classifier trained by transfer learning will return the diagnosis results. We verify the performance of our chatbot and classification on the extrinsic metrics and BreaKHis dataset, respectively. The task completion rate of M-Chatbot reached 63.33\%. For the BreaKHis dataset, the highest accuracy of EfficientNetV2-SA network have achieved 84.71\%. All these experimental results illustrate that the proposed model can improve the accuracy performance of image recognition and our new intelligent medical diagnosis system is successful and efficient in providing automatic diagnosis of breast cancer.