 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Tailed, Multi-Headed, Spatial Dynamic Memory refined Text-to-Image Synthesis
Oct 15, 2021
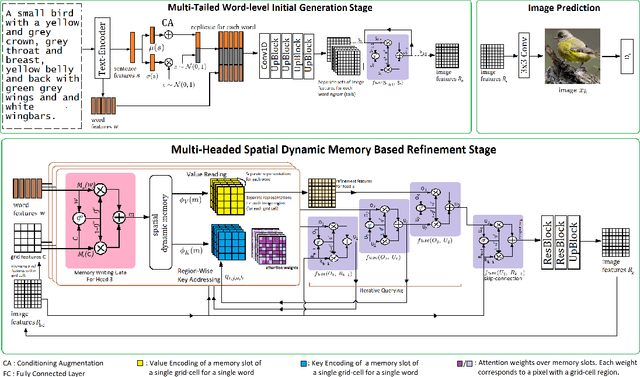


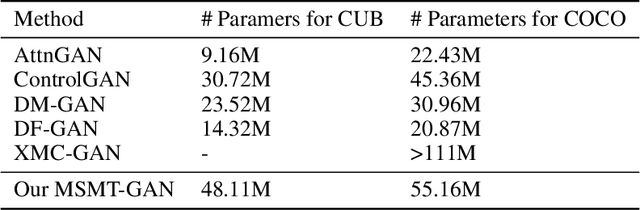
Synthesizing high-quality, realistic images from text-descriptions is a challenging task, and current methods synthesize images from text in a multi-stage manner, typically by first generating a rough initial image and then refining image details at subsequent stages. However, existing methods that follow this paradigm suffer from three important limitations. Firstly, they synthesize initial images without attempting to separate image attributes at a word-level. As a result, object attributes of initial images (that provide a basis for subsequent refinement) are inherently entangled and ambiguous in nature. Secondly, by using common text-representations for all regions, current methods prevent us from interpreting text in fundamentally different ways at different parts of an image. Different image regions are therefore only allowed to assimilate the same type of information from text at each refinement stage. Finally, current methods generate refinement features only once at each refinement stage and attempt to address all image aspects in a single shot. This single-shot refinement limits the precision with which each refinement stage can learn to improve the prior image. Our proposed method introduces three novel components to address these shortcomings: (1) An initial generation stage that explicitly generates separate sets of image features for each word n-gram. (2) A spatial dynamic memory module for refinement of images. (3) An iterative multi-headed mechanism to make it easier to improve upon multiple image aspects. Experimental results demonstrate that our Multi-Headed Spatial Dynamic Memory image refinement with our Multi-Tailed Word-level Initial Generation (MSMT-GAN) performs favourably against the previous state of the art on the CUB and COCO datasets.
Reinforcement Learning for Systematic FX Trading
Oct 15, 2021
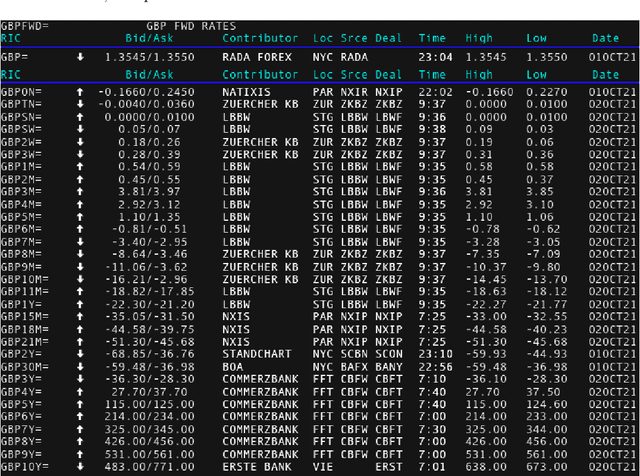
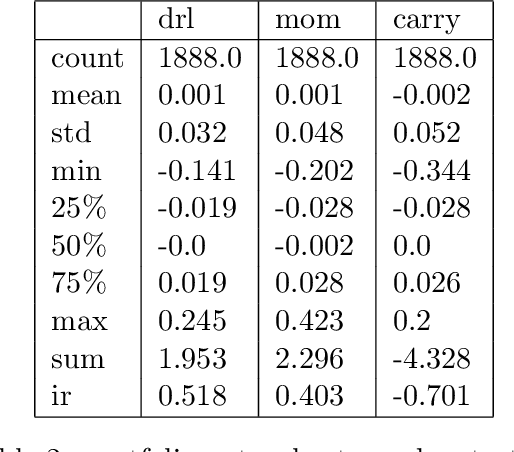
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
Learning High-Speed Flight in the Wild
Oct 11, 2021Quadrotors are agile. Unlike most other machines, they can traverse extremely complex environments at high speeds. To date, only expert human pilots have been able to fully exploit their capabilities. Autonomous operation with on-board sensing and computation has been limited to low speeds. State-of-the-art methods generally separate the navigation problem into subtasks: sensing, mapping, and planning. While this approach has proven successful at low speeds, the separation it builds upon can be problematic for high-speed navigation in cluttered environments. Indeed, the subtasks are executed sequentially, leading to increased processing latency and a compounding of errors through the pipeline. Here we propose an end-to-end approach that can autonomously fly quadrotors through complex natural and man-made environments at high speeds, with purely onboard sensing and computation. The key principle is to directly map noisy sensory observations to collision-free trajectories in a receding-horizon fashion. This direct mapping drastically reduces processing latency and increases robustness to noisy and incomplete perception. The sensorimotor mapping is performed by a convolutional network that is trained exclusively in simulation via privileged learning: imitating an expert with access to privileged information. By simulating realistic sensor noise, our approach achieves zero-shot transfer from simulation to challenging real-world environments that were never experienced during training: dense forests, snow-covered terrain, derailed trains, and collapsed buildings. Our work demonstrates that end-to-end policies trained in simulation enable high-speed autonomous flight through challenging environments, outperforming traditional obstacle avoidance pipelines.
* 16 pages (+7 supplementary)
Video Similarity and Alignment Learning on Partial Video Copy Detection
Aug 04, 2021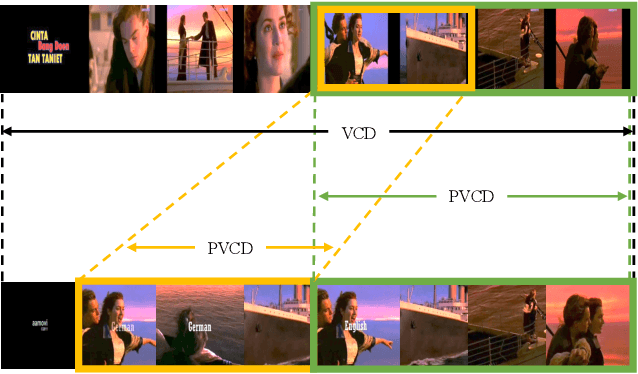
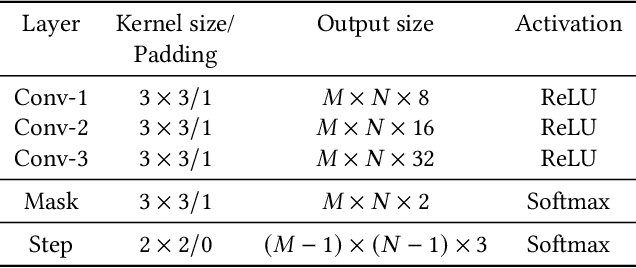
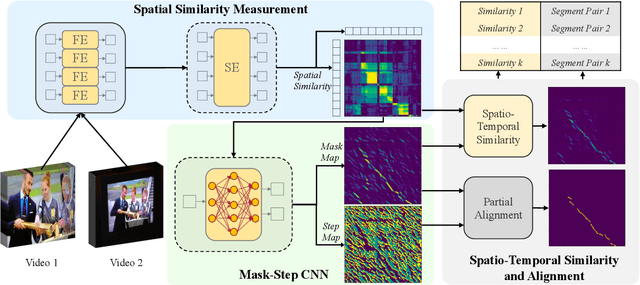
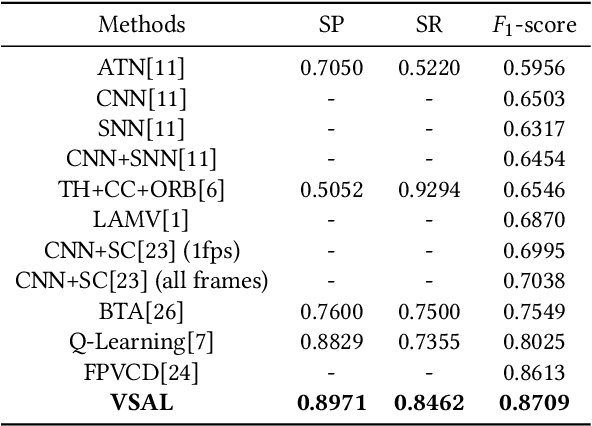
Existing video copy detection methods generally measure video similarity based on spatial similarities between key frames, neglecting the latent similarity in temporal dimension, so that the video similarity is biased towards spatial information. There are methods modeling unified video similarity in an end-to-end way, but losing detailed partial alignment information, which causes the incapability of copy segments localization. To address the above issues, we propose the Video Similarity and Alignment Learning (VSAL) approach, which jointly models spatial similarity, temporal similarity and partial alignment. To mitigate the spatial similarity bias, we model the temporal similarity as the mask map predicted from frame-level spatial similarity, where each element indicates the probability of frame pair lying right on the partial alignments. To further localize partial copies, the step map is learned from the spatial similarity where the elements indicate extending directions of the current partial alignments on the spatial-temporal similarity map. Obtained from the mask map, the start points extend out into partial optimal alignments following instructions of the step map. With the similarity and alignment learning strategy, VSAL achieves the state-of-the-art F1-score on VCDB core dataset. Furthermore, we construct a new benchmark of partial video copy detection and localization by adding new segment-level annotations for FIVR-200k dataset, where VSAL also achieves the best performance, verifying its effectiveness in more challenging situations. Our project is publicly available at https://pvcd-vsal.github.io/vsal/.
Machine Learning Advances aiding Recognition and Classification of Indian Monuments and Landmarks
Jul 29, 2021



Tourism in India plays a quintessential role in the country's economy with an estimated 9.2% GDP share for the year 2018. With a yearly growth rate of 6.2%, the industry holds a huge potential for being the primary driver of the economy as observed in the nations of the Middle East like the United Arab Emirates. The historical and cultural diversity exhibited throughout the geography of the nation is a unique spectacle for people around the world and therefore serves to attract tourists in tens of millions in number every year. Traditionally, tour guides or academic professionals who study these heritage monuments were responsible for providing information to the visitors regarding their architectural and historical significance. However, unfortunately this system has several caveats when considered on a large scale such as unavailability of sufficient trained people, lack of accurate information, failure to convey the richness of details in an attractive format etc. Recently, machine learning approaches revolving around the usage of monument pictures have been shown to be useful for rudimentary analysis of heritage sights. This paper serves as a survey of the research endeavors undertaken in this direction which would eventually provide insights for building an automated decision system that could be utilized to make the experience of tourism in India more modernized for visitors.
AirDOS: Dynamic SLAM benefits from Articulated Objects
Sep 21, 2021
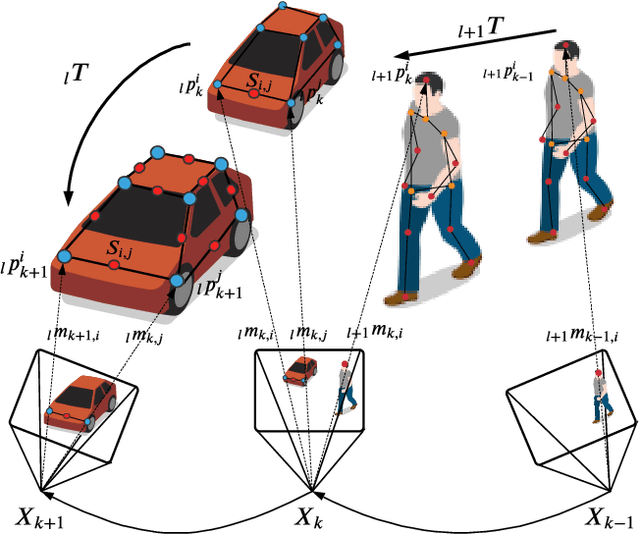
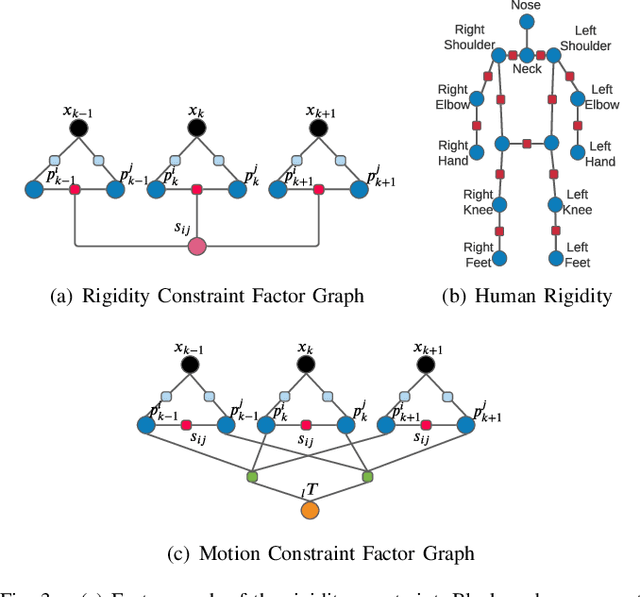
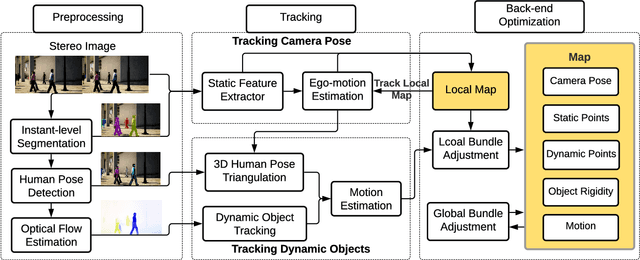
Dynamic Object-aware SLAM (DOS) exploits object-level information to enable robust motion estimation in dynamic environments. It has attracted increasing attention with the recent success of learning-based models. Existing methods mainly focus on identifying and excluding dynamic objects from the optimization. In this paper, we show that feature-based visual SLAM systems can also benefit from the presence of dynamic articulated objects by taking advantage of two observations: (1) The 3D structure of an articulated object remains consistent over time; (2) The points on the same object follow the same motion. In particular, we present AirDOS, a dynamic object-aware system that introduces rigidity and motion constraints to model articulated objects. By jointly optimizing the camera pose, object motion, and the object 3D structure, we can rectify the camera pose estimation, preventing tracking loss, and generate 4D spatio-temporal maps for both dynamic objects and static scenes. Experiments show that our algorithm improves the robustness of visual SLAM algorithms in challenging crowded urban environments. To the best of our knowledge, AirDOS is the first dynamic object-aware SLAM system demonstrating that camera pose estimation can be improved by incorporating dynamic articulated objects.
Fractal measures of image local features: an application to texture recognition
Aug 27, 2021
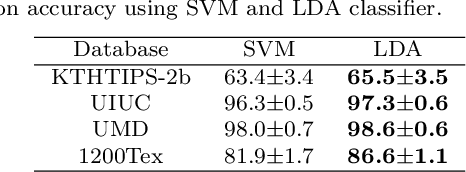
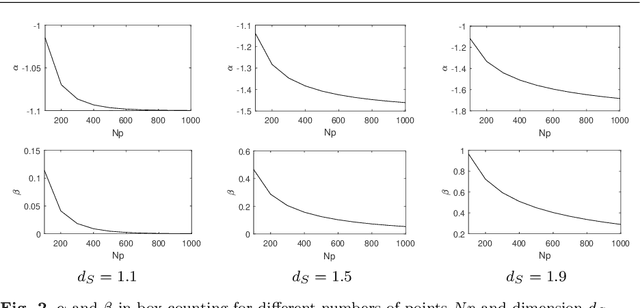
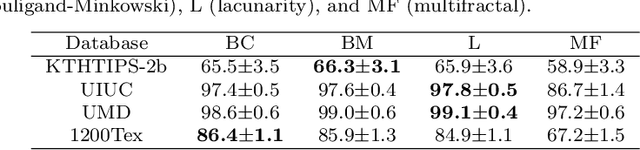
Here we propose a new method for the classification of texture images combining fractal measures (fractal dimension, multifractal spectrum and lacunarity) with local binary patterns. More specifically we compute the box counting dimension of the local binary codes thresholded at different levels to compose the feature vector. The proposal is assessed in the classification of three benchmark databases: KTHTIPS-2b, UMD and UIUC as well as in a real-world problem, namely the identification of Brazilian plant species (database 1200Tex) using scanned images of their leaves. The proposed method demonstrated to be competitive with other state-of-the-art solutions reported in the literature. Such results confirmed the potential of combining a powerful local coding description with the multiscale information captured by the fractal dimension for texture classification.
Learning Deep Representations by Mutual Information for Person Re-identification
Aug 16, 2019
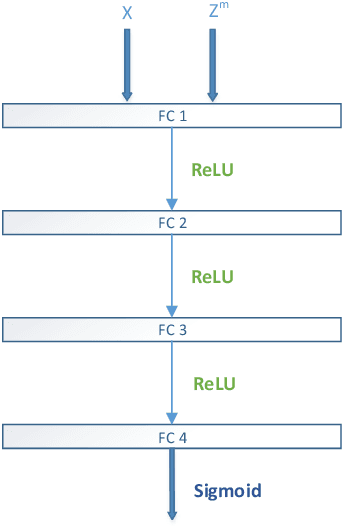

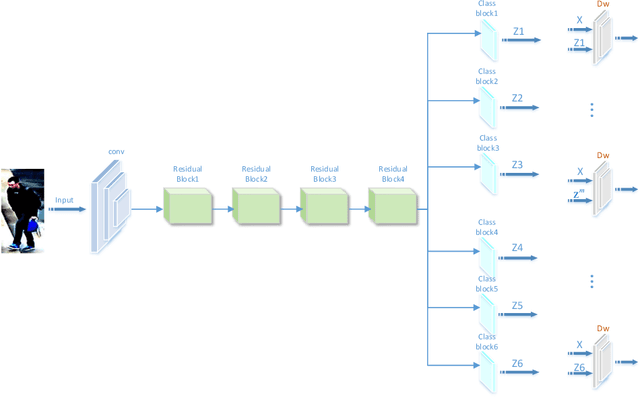
Most existing person re-identification (ReID) methods have good feature representations to distinguish pedestrians with deep convolutional neural network (CNN) and metric learning methods. However, these works concentrate on the similarity between encoder output and ground-truth, ignoring the correlation between input and encoder output, which affects the performance of identifying different pedestrians. To address this limitation, We design a Deep InfoMax (DIM) network to maximize the mutual information (MI) between the input image and encoder output, which doesn't need any auxiliary labels. To evaluate the effectiveness of the DIM network, we propose end-to-end Global-DIM and Local-DIM models. Additionally, the DIM network provides a new solution for cross-dataset unsupervised ReID issue as it needs no extra labels. The experiments prove the superiority of MI theory on the ReID issue, which achieves the state-of-the-art results.
On the Fundamental Trade-offs in Learning Invariant Representations
Sep 08, 2021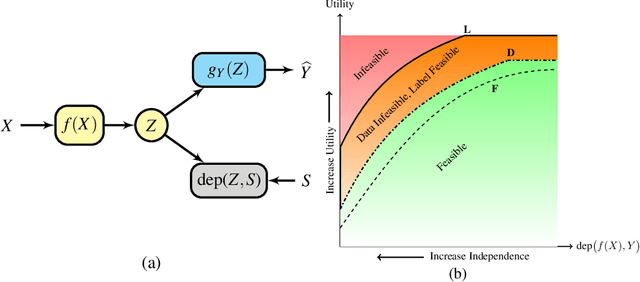
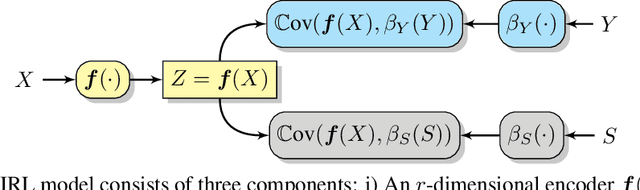
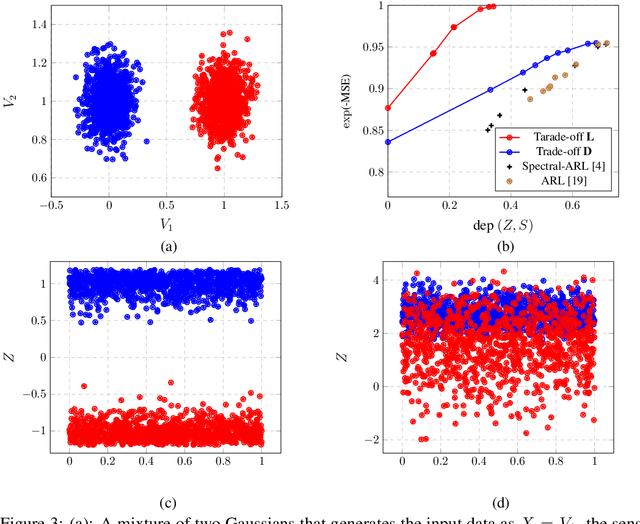
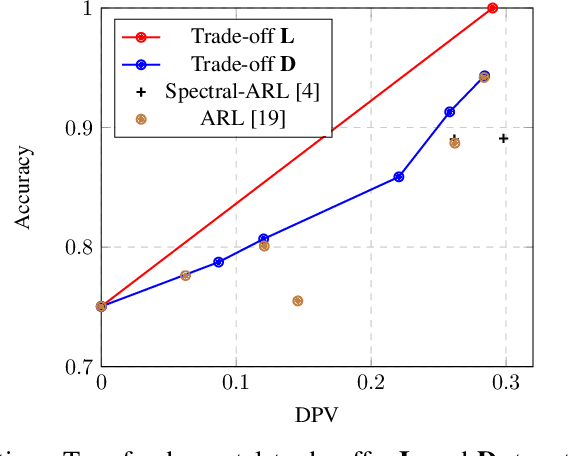
Many applications of representation learning, such as privacy-preservation, algorithmic fairness and domain adaptation, desire explicit control over semantic information being discarded. This goal is often formulated as satisfying two potentially competing objectives: maximizing utility for predicting a target attribute while simultaneously being independent or invariant with respect to a known semantic attribute. In this paper, we \emph{identify and determine} two fundamental trade-offs between utility and semantic dependence induced by the statistical dependencies between the data and its corresponding target and semantic attributes. We derive closed-form solutions for the global optima of the underlying optimization problems under mild assumptions, which in turn yields closed formulae for the exact trade-offs. We also derive empirical estimates of the trade-offs and show their convergence to the corresponding population counterparts. Finally, we numerically quantify the trade-offs on representative problems and compare to the solutions achieved by baseline representation learning algorithms.
Two-Way Reflecting Communication with UAV-Borne Reconfigurable Intelligent Surfaces
Aug 23, 2021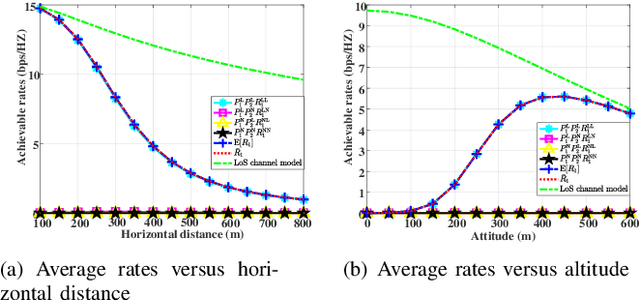
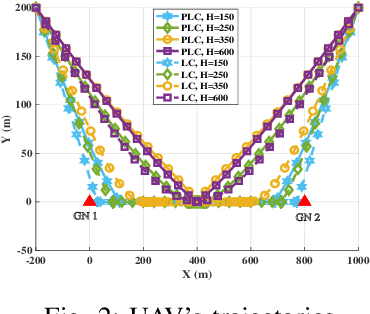
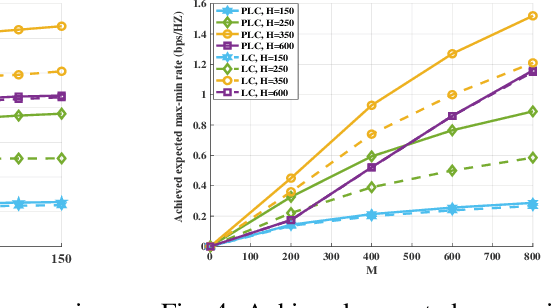
This paper investigates the unmanned aerial vehicle (UAV)-aided two-way reflecting (TWR) communication system under the probabilistic line-of-sight (LoS) channel model, where a UAV equipped with an RIS is deployed to assist two ground nodes in their information exchange. An optimization problem with the objective of maximizing the expected achievable rate is formulated to design the communication scheduling, the RIS's phase, and the UAV trajectory. To solve such a non-convex problem, we propose an efficient iterative algorithm to obtain suboptimal its solution. Simulation results show that our proposed design provides new insights into the elevation angle-distance trade-off for the TWR communication system, and improves the rate by $28\%$ compared to the scheme under the conventional LoS channel model.