 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
System Optimization in Synchronous Federated Training: A Survey
Sep 09, 2021
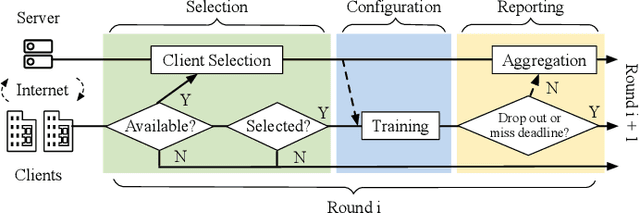
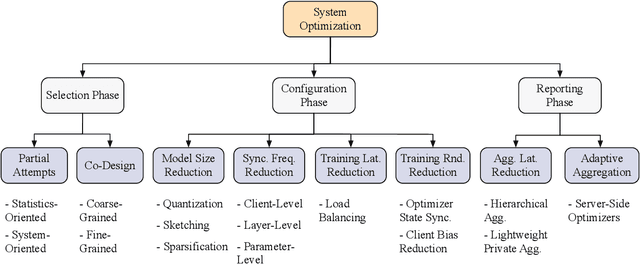
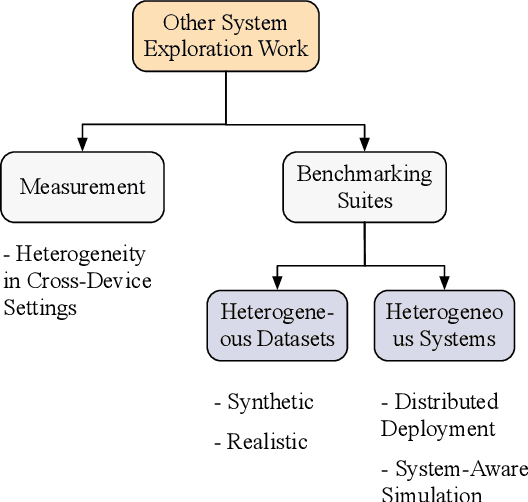
The unprecedented demand for collaborative machine learning in a privacy-preserving manner gives rise to a novel machine learning paradigm called federated learning (FL). Given a sufficient level of privacy guarantees, the practicality of an FL system mainly depends on its time-to-accuracy performance during the training process. Despite bearing some resemblance with traditional distributed training, FL has four distinct challenges that complicate the optimization towards shorter time-to-accuracy: information deficiency, coupling for contrasting factors, client heterogeneity, and huge configuration space. Motivated by the need for inspiring related research, in this paper we survey highly relevant attempts in the FL literature and organize them by the related training phases in the standard workflow: selection, configuration, and reporting. We also review exploratory work including measurement studies and benchmarking tools to friendly support FL developers. Although a few survey articles on FL already exist, our work differs from them in terms of the focus, classification, and implications.
A Novel Method to Estimate the Coordinates of LEDs in Wireless Optical Positioning Systems
Sep 09, 2021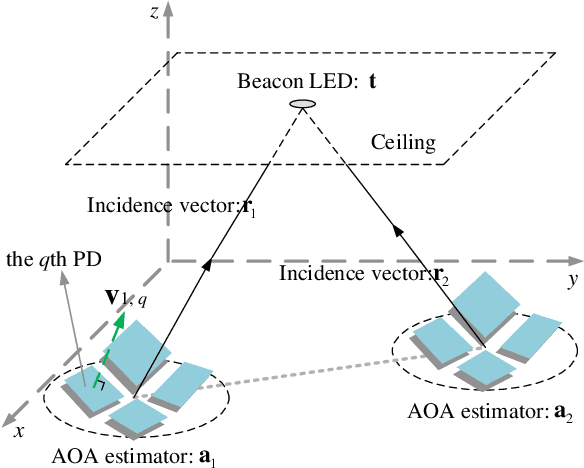
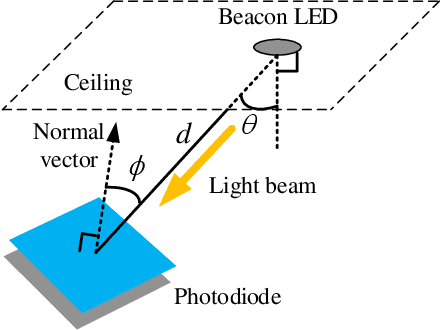
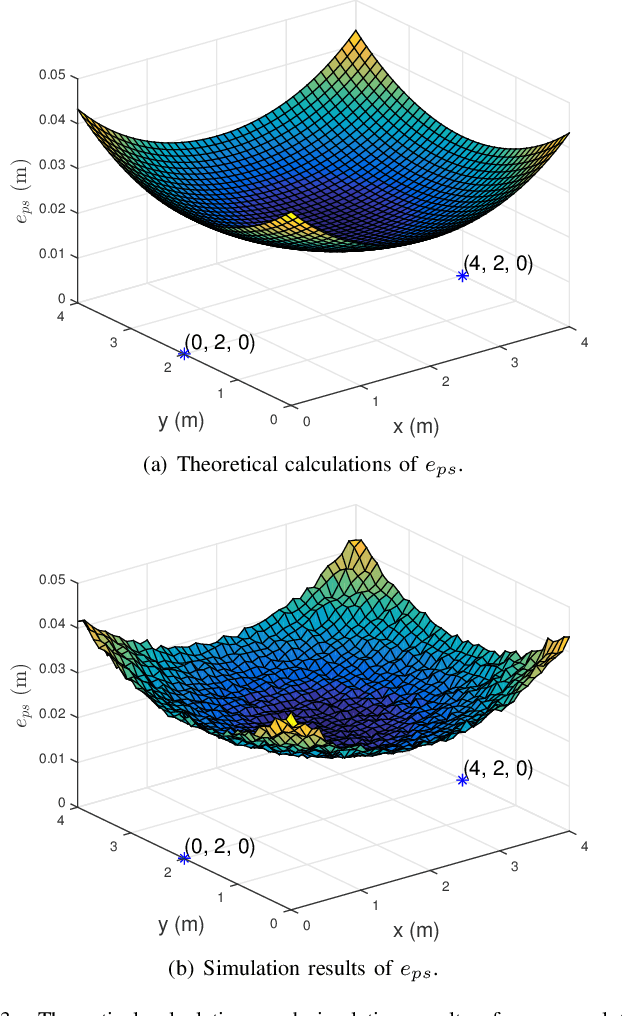
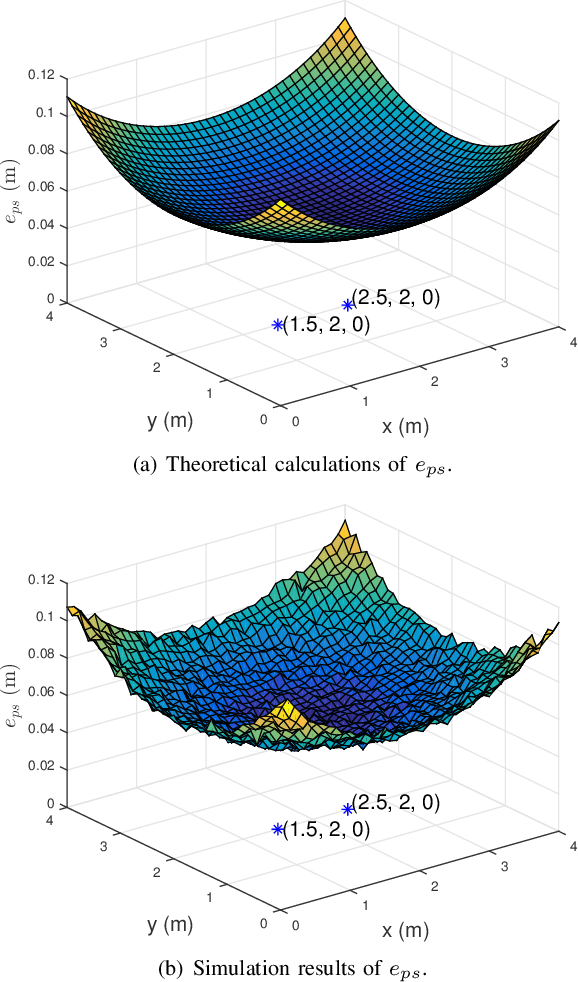
Traditional visible light positioning (VLP) systems estimate receivers' coordinates based on the known light-emitting diode (LED) coordinates. However, the LED coordinates are not always known accurately. Because of the structural changes of the buildings due to temperature, humidity or material aging, even measured by highly accurate laser range finders, the LED coordinates may change unpredictably. In this paper, we propose an easy and low-cost method to update the position information of the LEDs. We use two optical angle-of-arrival (AOA) estimators to detect the beam directions of the LEDs. Each AOA estimator has four differently oriented photodiodes (PDs). Considering the additive noises of the PDs, we derive the closed-form error expression for the proposed LED coordinates estimator. Both analytical and Monte Carlo experimental results show that the layout of the AOA estimators could affect the estimation error. These results may provide intuitive insights for the design of the optical indoor positioning systems.
Better Word Embeddings by Disentangling Contextual n-Gram Information
Apr 10, 2019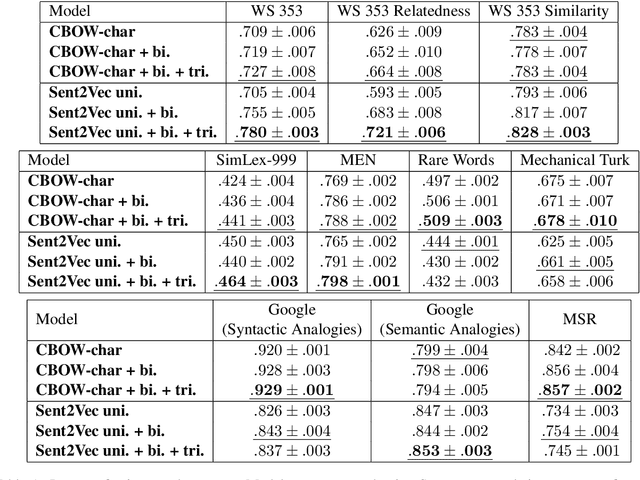
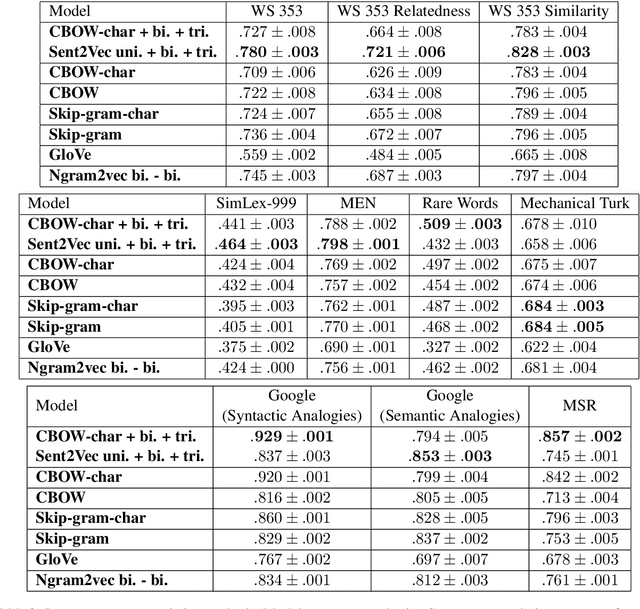
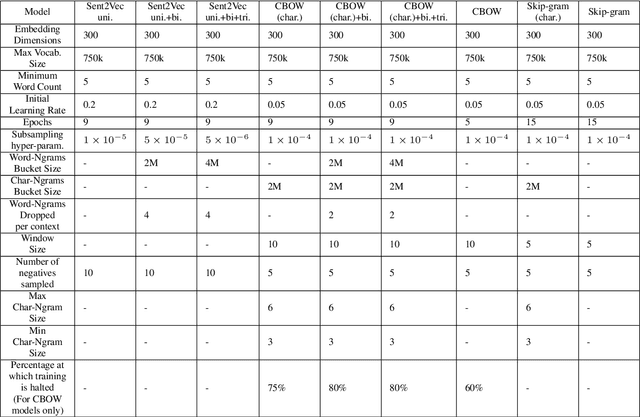
Pre-trained word vectors are ubiquitous in Natural Language Processing applications. In this paper, we show how training word embeddings jointly with bigram and even trigram embeddings, results in improved unigram embeddings. We claim that training word embeddings along with higher n-gram embeddings helps in the removal of the contextual information from the unigrams, resulting in better stand-alone word embeddings. We empirically show the validity of our hypothesis by outperforming other competing word representation models by a significant margin on a wide variety of tasks. We make our models publicly available.
A comprehensive review of Binary Neural Network
Oct 11, 2021

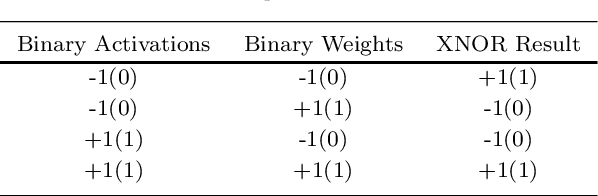
Binary Neural Network (BNN) method is an extreme application of convolutional neural network (CNN) parameter quantization. As opposed to the original CNN methods which employed floating-point computation with full-precision weights and activations, BBN uses 1-bit activations and weights. With BBNs, a significant amount of storage, network complexity and energy consumption can be reduced, and neural networks can be implemented more efficiently in embedded applications. Unfortunately, binarization causes severe information loss. A gap still exists between full-precision CNN models and their binarized counterparts. The recent developments in BNN have led to a lot of algorithms and solutions that have helped address this issue. This article provides a full overview of recent developments in BNN. The present paper focuses exclusively on 1-bit activations and weights networks, as opposed to previous surveys in which low-bit works are mixed in. In this paper, we conduct a complete investigation of BNN's development from their predecessors to the latest BNN algorithms and techniques, presenting a broad design pipeline, and discussing each module's variants. Along the way, this paper examines BNN (a) purpose: their early successes and challenges; (b) BNN optimization: selected representative works that contain key optimization techniques; (c) deployment: open-source frameworks for BNN modeling and development; (d) terminal: efficient computing architectures and devices for BNN and (e) applications: diverse applications with BNN. Moreover, this paper discusses potential directions and future research opportunities for the latest BNN algorithms and techniques, presents a broad design pipeline, and discusses each module's variants.
InfoGram and Admissible Machine Learning
Aug 20, 2021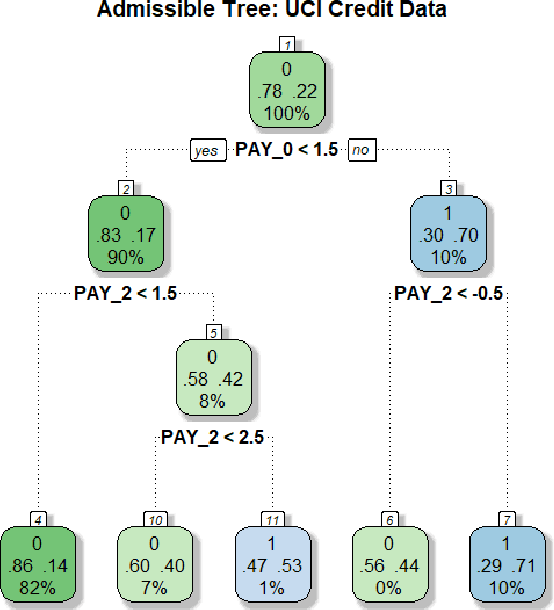
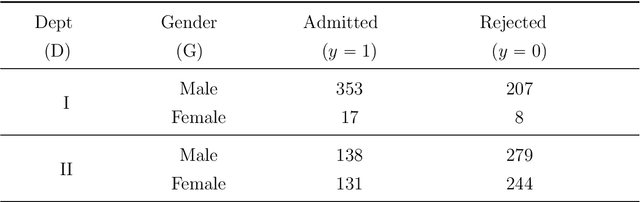
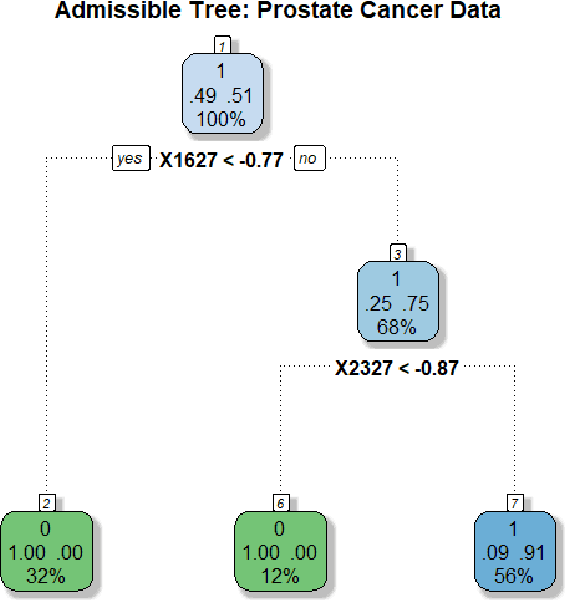

We have entered a new era of machine learning (ML), where the most accurate algorithm with superior predictive power may not even be deployable, unless it is admissible under the regulatory constraints. This has led to great interest in developing fair, transparent and trustworthy ML methods. The purpose of this article is to introduce a new information-theoretic learning framework (admissible machine learning) and algorithmic risk-management tools (InfoGram, L-features, ALFA-testing) that can guide an analyst to redesign off-the-shelf ML methods to be regulatory compliant, while maintaining good prediction accuracy. We have illustrated our approach using several real-data examples from financial sectors, biomedical research, marketing campaigns, and the criminal justice system.
Two algorithms for vehicular obstacle detection in sparse pointcloud
Sep 15, 2021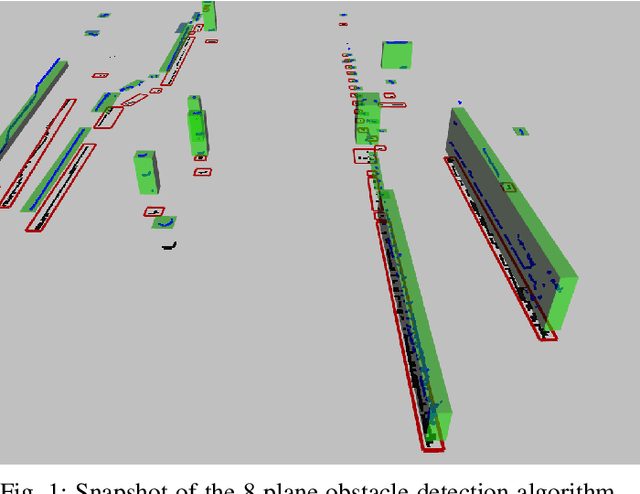


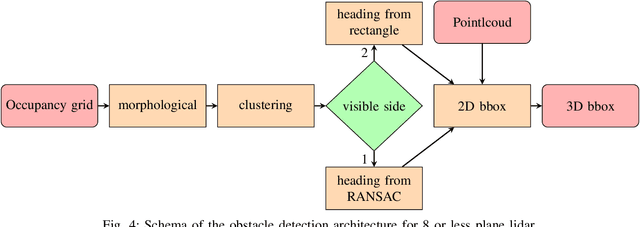
One of the main components of an autonomous vehicle is the obstacle detection pipeline. Most prototypes, both from research and industry, rely on lidars for this task. Pointcloud information from lidar is usually combined with data from cameras and radars, but the backbone of the architecture is mainly based on 3D bounding boxes computed from lidar data. To retrieve an accurate representation, sensors with many planes, e.g., greater than 32 planes, are usually employed. The returned pointcloud is indeed dense and well defined, but high-resolution sensors are still expensive and often require powerful GPUs to be processed. Lidars with fewer planes are cheaper, but the returned data are not dense enough to be processed with state of the art deep learning approaches to retrieve 3D bounding boxes. In this paper, we propose two solutions based on occupancy grid and geometric refinement to retrieve a list of 3D bounding boxes employing lidar with a low number of planes (i.e., 16 and 8 planes). Our solutions have been validated on a custom acquired dataset with accurate ground truth to prove its feasibility and accuracy.
HybridSVD: When Collaborative Information is Not Enough
Jul 27, 2018
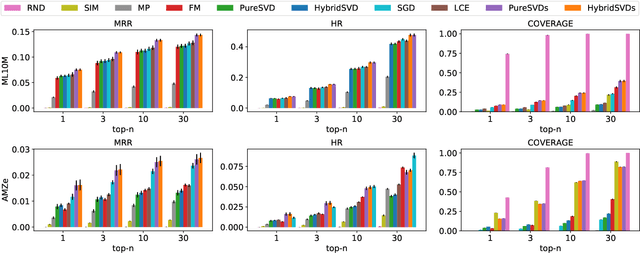
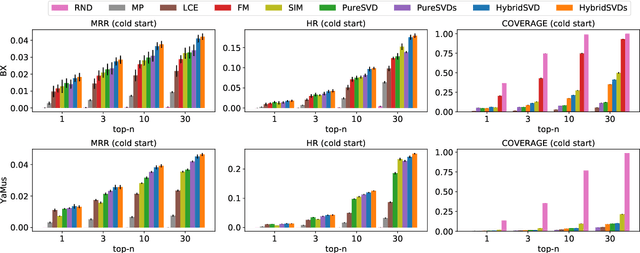
We propose a hybrid algorithm for top-$n$ recommendation task that allows to incorporate both user and item side information within the standard collaborative filtering approach. The algorithm extends PureSVD -- one of the state-of-the-art latent factor models -- by exploiting a generalized formulation of the singular value decomposition. This allows to inherit key advantages of the classical algorithm such as highly efficient Lanczos-based optimization procedure, minimal parameter tuning during a model selection phase and a quick folding-in computation to generate recommendations instantly even in a highly dynamic online environment. Within the generalized formulation itself we provide an efficient scheme for side information fusion which avoids undesirable computational overhead and addresses the scalability question. Evaluation of the model is performed in both standard and cold-start scenarios using the datasets with different sparsity levels. We demonstrate in which cases our approach outperforms conventional methods and also provide some intuition on when it may give no significant improvement.
Inference under Information Constraints I: Lower Bounds from Chi-Square Contraction
Dec 30, 2018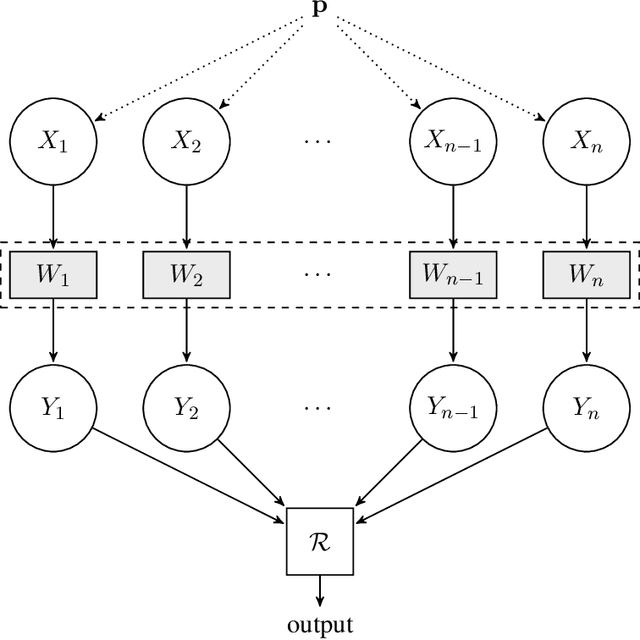
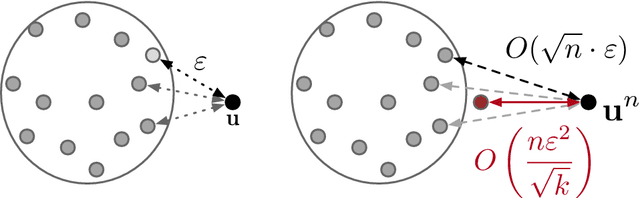

We consider a distributed inference problem where only limited information is allowed from each sample. We present a general framework where multiple players are given one independent sample each about which they can only provide limited information to a central referee. Motivated by important instances of communication and privacy constraints, in our abstraction we allow each player to describe its observed sample to the referee using a channel from a prespecified family of channels $\cal W$. This family $\cal W$ can be instantiated to capture both the communication- and privacy-constrained settings and beyond. The central referee uses the messages from players to solve an inference problem for the unknown underlying distribution that generated samples of the players. We derive lower bounds for sample complexity of learning and testing discrete distributions in this information-constrained setting. Underlying our lower bounds is a quantitative characterization of the contraction in chi-square distances between the observed distributions of the samples when an information constraint is placed. This contraction is captured in a local neighborhood in terms of chi-square and decoupled chi-square fluctuations of a given channel, two quantities we introduce in this work. The former captures the average distance between two product distributions and the latter the distance of a product distribution to a mixture of product distributions. These quantities may be of independent interest. As a corollary, we quantify the sample complexity blow-up in the learning and testing settings when enforcing the corresponding local information constraints. In addition, we systematically study the role of randomness and consider both private- and public-coin protocols.
Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions
Sep 27, 2021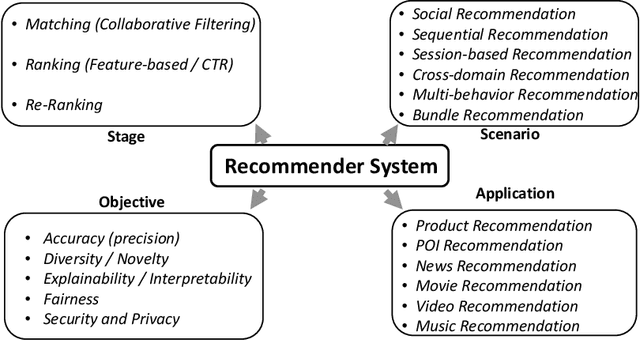

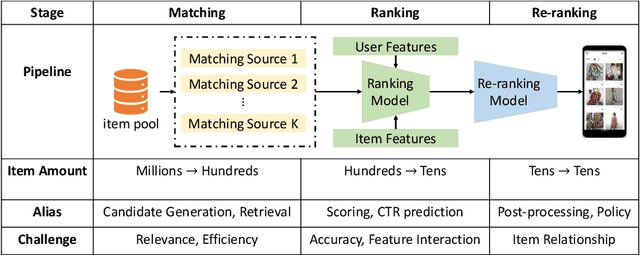
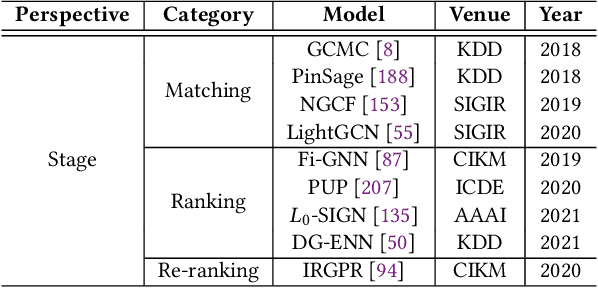
Recommender system is one of the most important information services on today's Internet. Recently, graph neural networks have become the new state-of-the-art approach of recommender systems. In this survey, we conduct a comprehensive review of the literature in graph neural network-based recommender systems. We first introduce the background and the history of the development of both recommender systems and graph neural networks. For recommender systems, in general, there are four aspects for categorizing existing works: stage, scenario, objective, and application. For graph neural networks, the existing methods consist of two categories, spectral models and spatial ones. We then discuss the motivation of applying graph neural networks into recommender systems, mainly consisting of the high-order connectivity, the structural property of data, and the enhanced supervision signal. We then systematically analyze the challenges in graph construction, embedding propagation/aggregation, model optimization, and computation efficiency. Afterward and primarily, we provide a comprehensive overview of a multitude of existing works of graph neural network-based recommender systems, following the taxonomy above. Finally, we raise discussions on the open problems and promising future directions of this area. We summarize the representative papers along with their codes repositories in https://github.com/tsinghua-fib-lab/GNN-Recommender-Systems.
Scalable Traffic Signal Controls using Fog-Cloud Based Multiagent Reinforcement Learning
Oct 11, 2021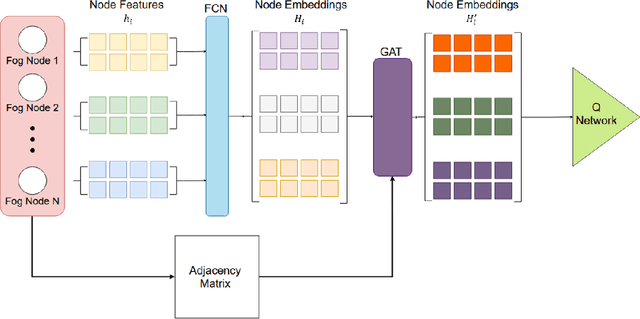
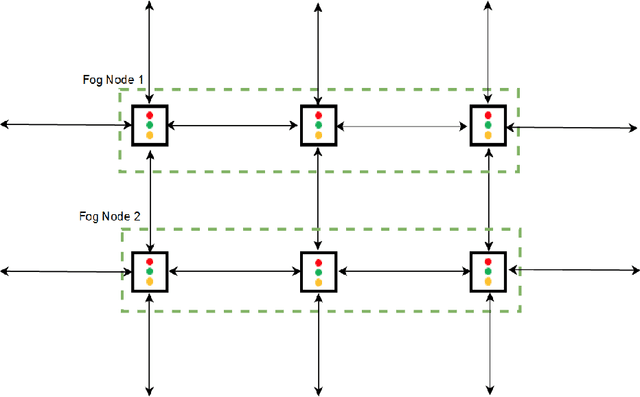
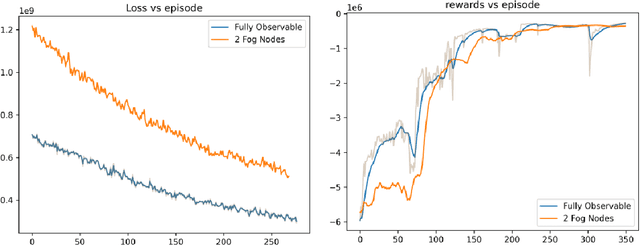
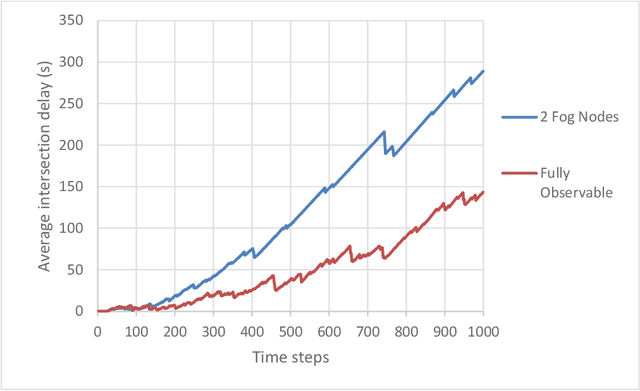
Optimizing traffic signal control (TSC) at intersections continues to pose a challenging problem, particularly for large-scale traffic networks. It has been shown in past research that it is feasible to optimize the operations of individual TSC systems or a small number of such systems. However, it has been computationally difficult to scale these solution approaches to large networks partly due to the curse of dimensionality that is encountered as the number of intersections increases. Fortunately, recent studies have recognized the potential of exploiting advancements in deep and reinforcement learning to address this problem, and some preliminary successes have been achieved in this regard. However, facilitating such intelligent solution approaches may require large amounts of infrastructural investments such as roadside units (RSUs) and drones in order to ensure thorough connectivity across all intersections in large networks, an investment that may be burdensome for agencies to undertake. As such, this study builds on recent work to present a scalable TSC model that may reduce the number of required enabling infrastructure. This is achieved using graph attention networks (GATs) to serve as the neural network for deep reinforcement learning, which aids in maintaining the graph topology of the traffic network while disregarding any irrelevant or unnecessary information. A case study is carried out to demonstrate the effectiveness of the proposed model, and the results show much promise. The overall research outcome suggests that by decomposing large networks using fog-nodes, the proposed fog-based graphic RL (FG-RL) model can be easily applied to scale into larger traffic networks.