 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Attributed Graph Representations with Communicative Message Passing Transformer
Jul 28, 2021
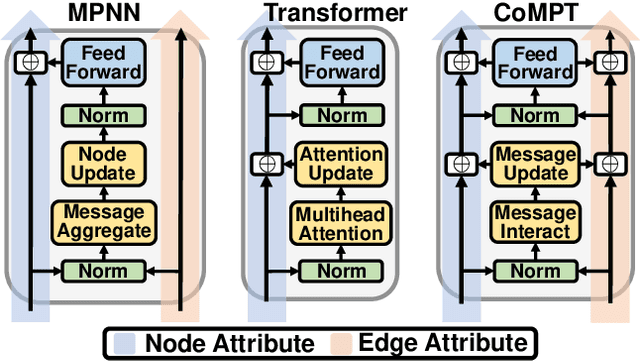
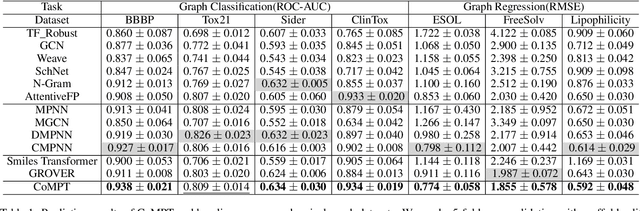
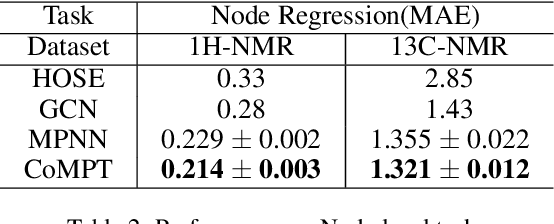
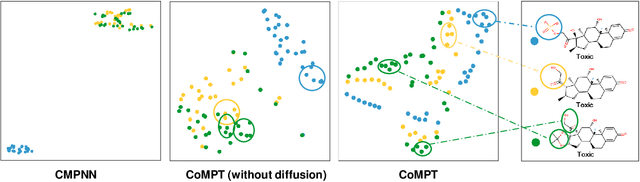
Constructing appropriate representations of molecules lies at the core of numerous tasks such as material science, chemistry and drug designs. Recent researches abstract molecules as attributed graphs and employ graph neural networks (GNN) for molecular representation learning, which have made remarkable achievements in molecular graph modeling. Albeit powerful, current models either are based on local aggregation operations and thus miss higher-order graph properties or focus on only node information without fully using the edge information. For this sake, we propose a Communicative Message Passing Transformer (CoMPT) neural network to improve the molecular graph representation by reinforcing message interactions between nodes and edges based on the Transformer architecture. Unlike the previous transformer-style GNNs that treat molecules as fully connected graphs, we introduce a message diffusion mechanism to leverage the graph connectivity inductive bias and reduce the message enrichment explosion. Extensive experiments demonstrated that the proposed model obtained superior performances (around 4$\%$ on average) against state-of-the-art baselines on seven chemical property datasets (graph-level tasks) and two chemical shift datasets (node-level tasks). Further visualization studies also indicated a better representation capacity achieved by our model.
Kompetenzerwerbsförderung durch E-Assessment: Individuelle Kompetenzerfassung am Beispiel des Fachs Mathematik
Aug 20, 2021In this article, we present a concept of how micro- and e-assessments can be used for the mathematical domain to automatically determine acquired and missing individual skills and, based on these information, guide individuals to acquire missing or additional skills in a software-supported process. The models required for this concept are a digitally prepared and annotated e-assessment item pool, a digital modeling of the domain that includes topics, necessary competencies, as well as introductory and continuative material, as well as a digital individual model, which can reliably record competencies and integrates aspects about the loss of such.
Variational voxelwise rs-fMRI representation learning: Evaluation of sex, age, and neuropsychiatric signatures
Aug 29, 2021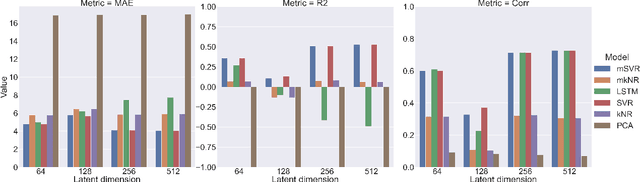
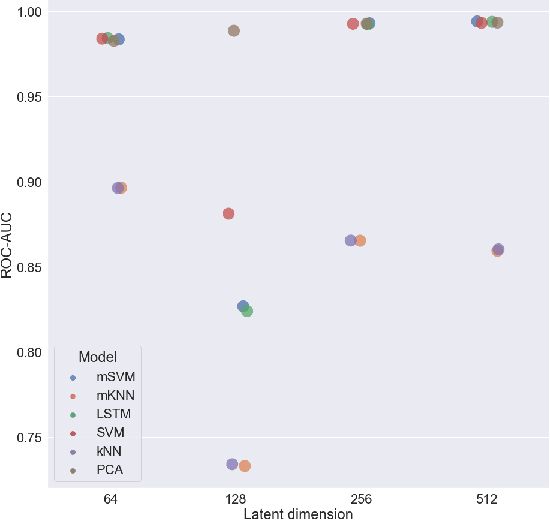
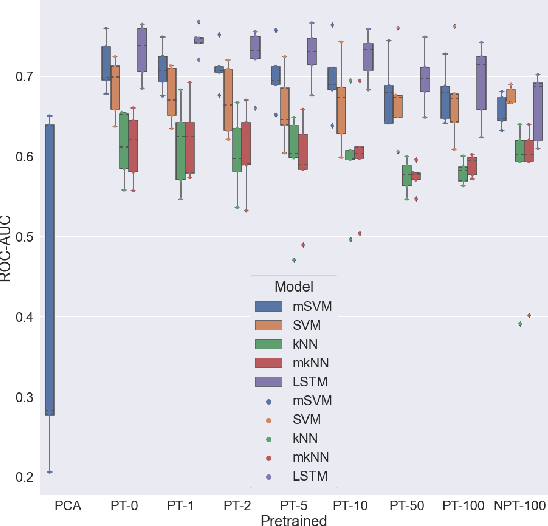
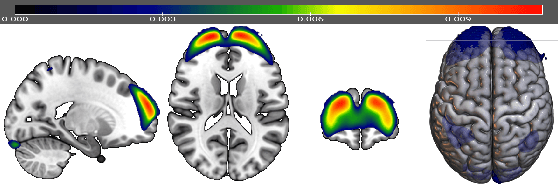
We propose to apply non-linear representation learning to voxelwise rs-fMRI data. Learning the non-linear representations is done using a variational autoencoder (VAE). The VAE is trained on voxelwise rs-fMRI data and performs non-linear dimensionality reduction that retains meaningful information. The retention of information in the model's representations is evaluated using downstream age regression and sex classification tasks. The results on these tasks are highly encouraging and a linear regressor trained with the representations of our unsupervised model performs almost as well as a supervised neural network, trained specifically for age regression on the same dataset. The model is also evaluated with a schizophrenia diagnosis prediction task, to assess its feasibility as a dimensionality reduction method for neuropsychiatric datasets. These results highlight the potential for pre-training on a larger set of individuals who do not have mental illness, to improve the downstream neuropsychiatric task results. The pre-trained model is fine-tuned for a variable number of epochs on a schizophrenia dataset and we find that fine-tuning for 1 epoch yields the best results. This work therefore not only opens up non-linear dimensionality reduction for voxelwise rs-fMRI data but also shows that pre-training a deep learning model on voxelwise rs-fMRI datasets greatly increases performance even on smaller datasets. It also opens up the ability to look at the distribution of rs-fMRI time series in the latent space of the VAE for heterogeneous neuropsychiatric disorders like schizophrenia in future work. This can be complemented with the generative aspect of the model that allows us to reconstruct points from the model's latent space back into brain space and obtain an improved understanding of the relation that the VAE learns between subjects, timepoints, and a subject's characteristics.
Pitch Preservation In Singing Voice Synthesis
Oct 12, 2021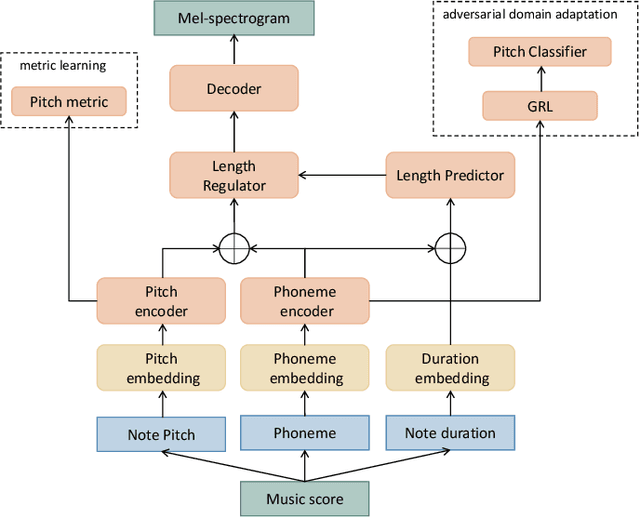
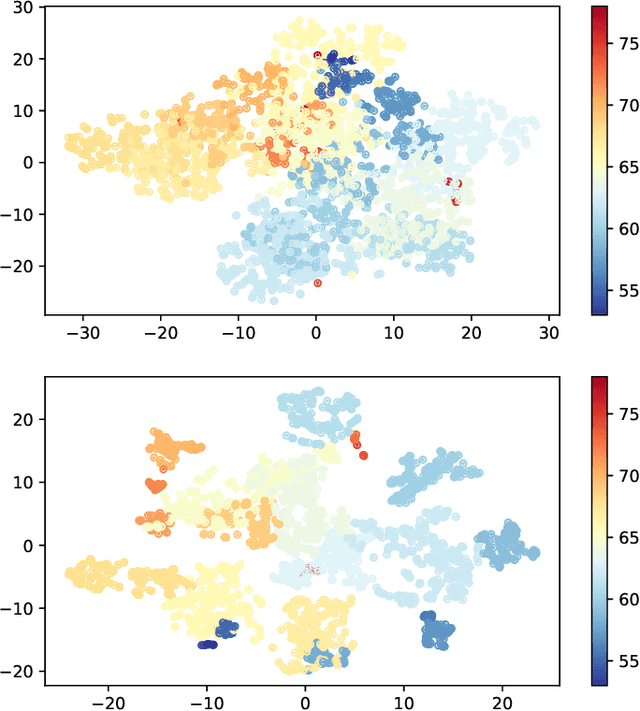
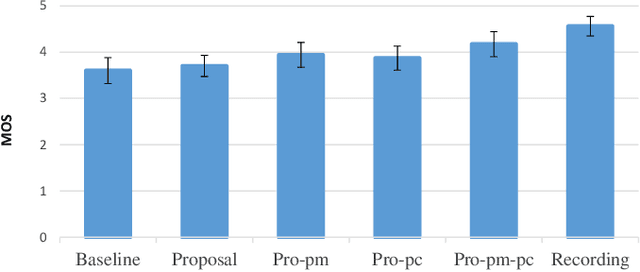
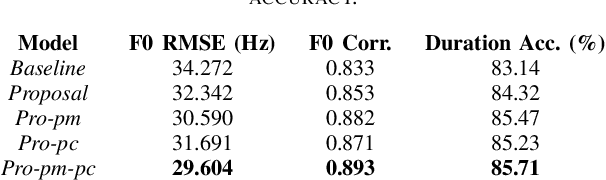
Suffering from limited singing voice corpus, existing singing voice synthesis (SVS) methods that build encoder-decoder neural networks to directly generate spectrogram could lead to out-of-tune issues during the inference phase. To attenuate these issues, this paper presents a novel acoustic model with independent pitch encoder and phoneme encoder, which disentangles the phoneme and pitch information from music score to fully utilize the corpus. Specifically, according to equal temperament theory, the pitch encoder is constrained by a pitch metric loss that maps distances between adjacent input pitches into corresponding frequency multiples between the encoder outputs. For the phoneme encoder, based on the analysis that same phonemes corresponding to varying pitches can produce similar pronunciations, this encoder is followed by an adversarially trained pitch classifier to enforce the identical phonemes with different pitches mapping into the same phoneme feature space. By these means, the sparse phonemes and pitches in original input spaces can be transformed into more compact feature spaces respectively, where the same elements cluster closely and cooperate mutually to enhance synthesis quality. Then, the outputs of the two encoders are summed together to pass through the following decoder in the acoustic model. Experimental results indicate that the proposed approaches can characterize intrinsic structure between pitch inputs to obtain better pitch synthesis accuracy and achieve superior singing synthesis performance against the advanced baseline system.
NOPE: A Corpus of Naturally-Occurring Presuppositions in English
Sep 14, 2021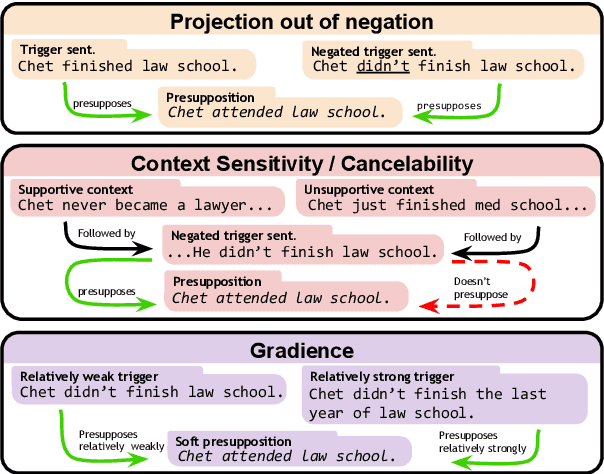
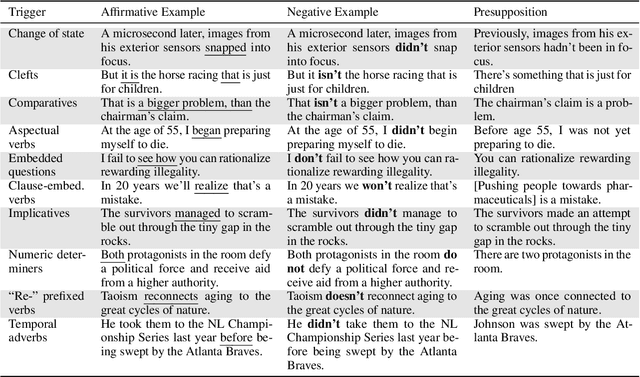
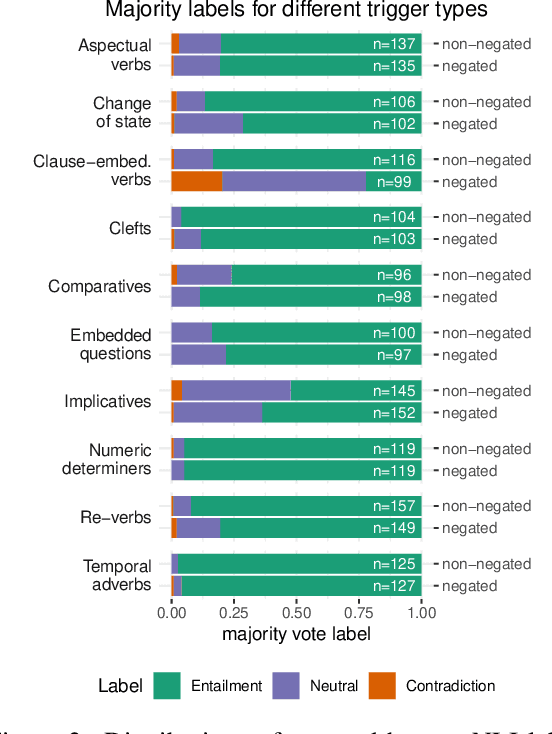
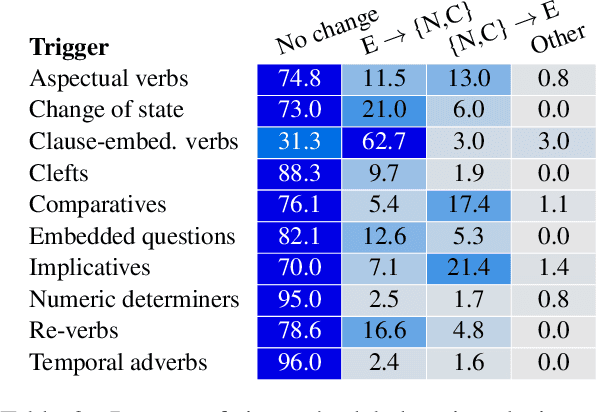
Understanding language requires grasping not only the overtly stated content, but also making inferences about things that were left unsaid. These inferences include presuppositions, a phenomenon by which a listener learns about new information through reasoning about what a speaker takes as given. Presuppositions require complex understanding of the lexical and syntactic properties that trigger them as well as the broader conversational context. In this work, we introduce the Naturally-Occurring Presuppositions in English (NOPE) Corpus to investigate the context-sensitivity of 10 different types of presupposition triggers and to evaluate machine learning models' ability to predict human inferences. We find that most of the triggers we investigate exhibit moderate variability. We further find that transformer-based models draw correct inferences in simple cases involving presuppositions, but they fail to capture the minority of exceptional cases in which human judgments reveal complex interactions between context and triggers.
Shaping the Narrative Arc: An Information-Theoretic Approach to Collaborative Dialogue
Jan 31, 2019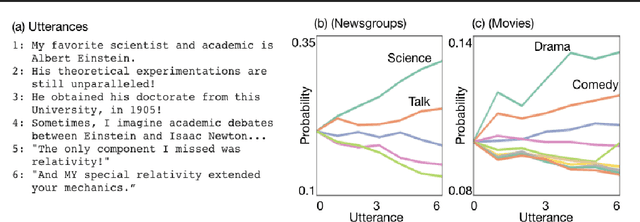
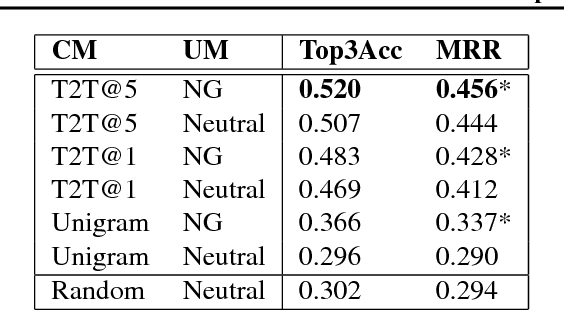
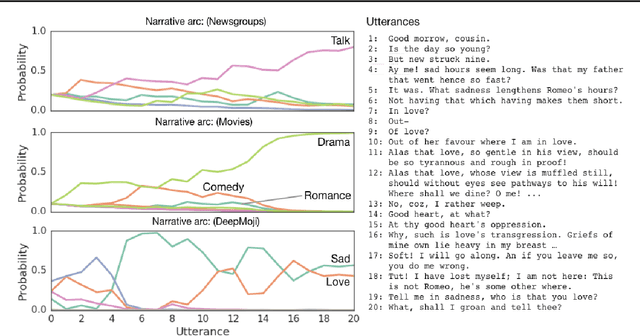
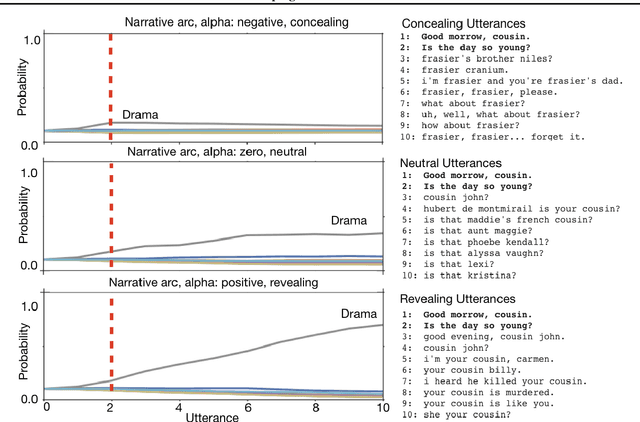
We consider the problem of designing an artificial agent capable of interacting with humans in collaborative dialogue to produce creative, engaging narratives. In this task, the goal is to establish universe details, and to collaborate on an interesting story in that universe, through a series of natural dialogue exchanges. Our model can augment any probabilistic conversational agent by allowing it to reason about universe information established and what potential next utterances might reveal. Ideally, with each utterance, agents would reveal just enough information to add specificity and reduce ambiguity without limiting the conversation. We empirically show that our model allows control over the rate at which the agent reveals information and that doing so significantly improves accuracy in predicting the next line of dialogues from movies. We close with a case-study with four professional theatre performers, who preferred interactions with our model-augmented agent over an unaugmented agent.
SpaceMeshLab: Spatial Context Memoization and Meshgrid Atrous Convolution Consensus for Semantic Segmentation
Jun 08, 2021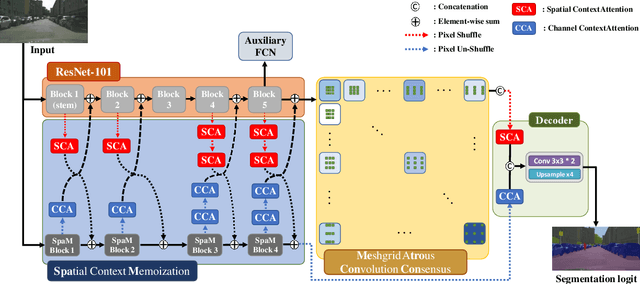

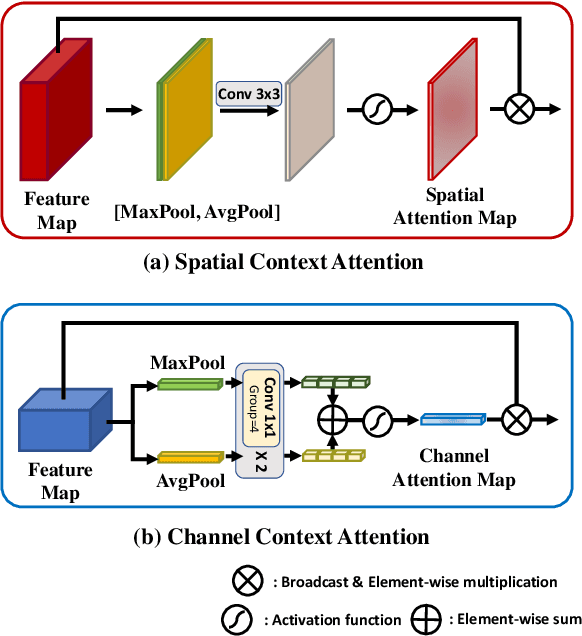

Semantic segmentation networks adopt transfer learning from image classification networks which occurs a shortage of spatial context information. For this reason, we propose Spatial Context Memoization (SpaM), a bypassing branch for spatial context by retaining the input dimension and constantly communicating its spatial context and rich semantic information mutually with the backbone network. Multi-scale context information for semantic segmentation is crucial for dealing with diverse sizes and shapes of target objects in the given scene. Conventional multi-scale context scheme adopts multiple effective receptive fields by multiple dilation rates or pooling operations, but often suffer from misalignment problem with respect to the target pixel. To this end, we propose Meshgrid Atrous Convolution Consensus (MetroCon^2) which brings multi-scale scheme into fine-grained multi-scale object context using convolutions with meshgrid-like scattered dilation rates. SpaceMeshLab (ResNet-101 + SpaM + MetroCon^2) achieves 82.0% mIoU in Cityscapes test and 53.5% mIoU on Pascal-Context validation set.
Inducing Equilibria via Incentives: Simultaneous Design-and-Play Finds Global Optima
Oct 12, 2021
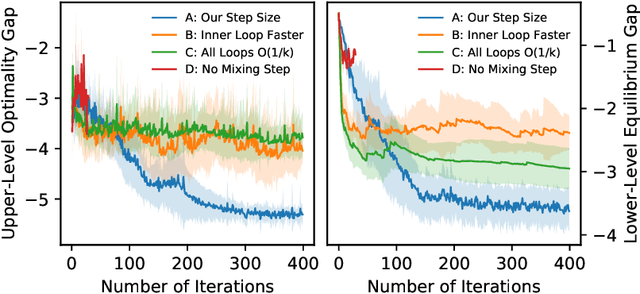
To regulate a social system comprised of self-interested agents, economic incentives (e.g., taxes, tolls, and subsidies) are often required to induce a desirable outcome. This incentive design problem naturally possesses a bi-level structure, in which an upper-level "designer" modifies the payoffs of the agents with incentives while anticipating the response of the agents at the lower level, who play a non-cooperative game that converges to an equilibrium. The existing bi-level optimization algorithms developed in machine learning raise a dilemma when applied to this problem: anticipating how incentives affect the agents at equilibrium requires solving the equilibrium problem repeatedly, which is computationally inefficient; bypassing the time-consuming step of equilibrium-finding can reduce the computational cost, but may lead the designer to a sub-optimal solution. To address such a dilemma, we propose a method that tackles the designer's and agents' problems simultaneously in a single loop. In particular, at each iteration, both the designer and the agents only move one step based on the first-order information. In the proposed scheme, although the designer does not solve the equilibrium problem repeatedly, it can anticipate the overall influence of the incentives on the agents, which guarantees optimality. We prove that the algorithm converges to the global optima at a sublinear rate for a broad class of games.
Low SNR Capacity of Keyhole MIMO Channel in Nakagami-m Fading With Full CSI
Sep 07, 2021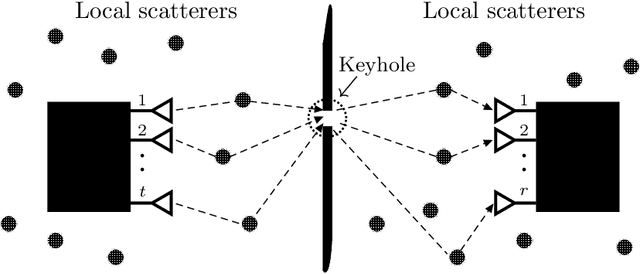
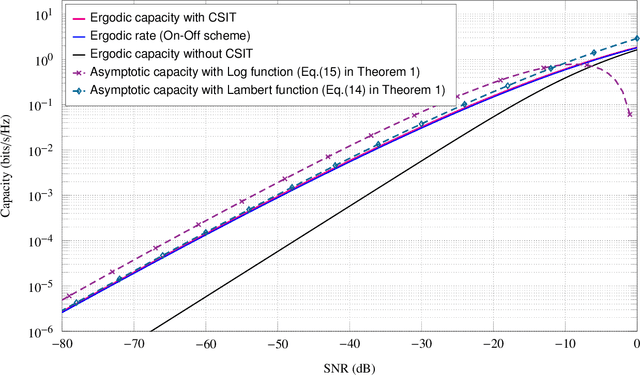
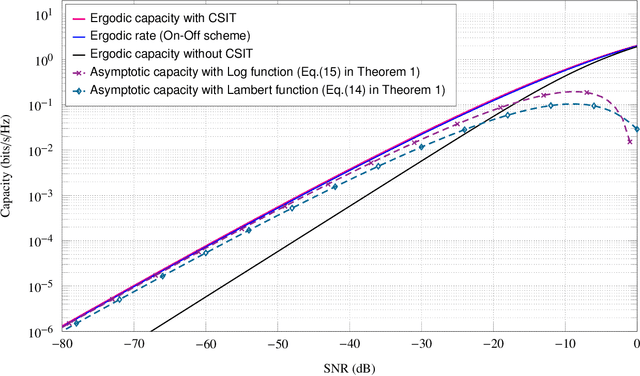
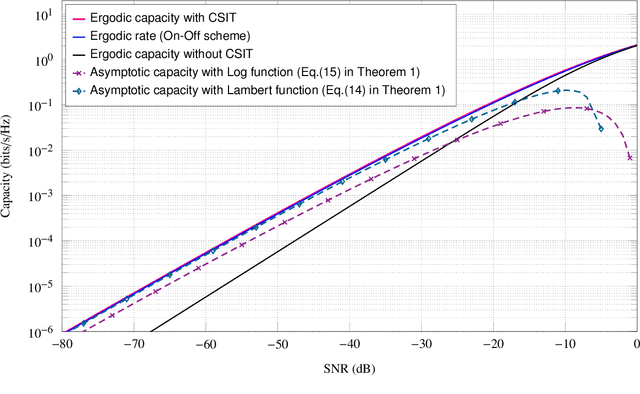
In this paper, we derive asymptotic expressions for the ergodic capacity of the multiple-input multiple-output (MIMO) keyhole channel at low SNR in independent and identically distributed (i.i.d.) Nakagami-$m$ fading conditions with perfect channel state information available at both the transmitter (CSI-T) and the receiver (CSI-R). We show that the low-SNR capacity of this keyhole channel scales proportionally as $\frac{\textrm{SNR}}{4} \log^2 \left(1/{\textrm{SNR}}\right)$. Further, we develop a practically appealing On-Off transmission scheme that is aymptotically capacity achieving at low SNR; it requires only one-bit CSI-T feedback and is robust against both mild and severe Nakagami-$m$ fadings for a very wide range of low-SNR values. These results also extend to the Rayleigh keyhole MIMO channel as a special case.
The Image Local Autoregressive Transformer
Jun 04, 2021

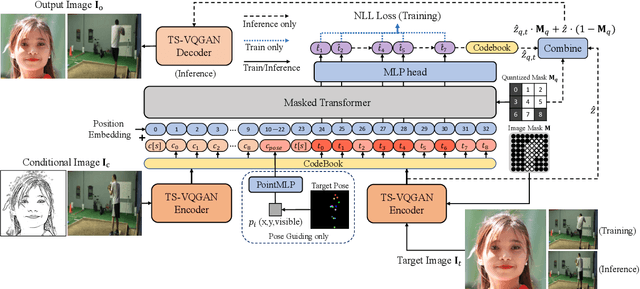
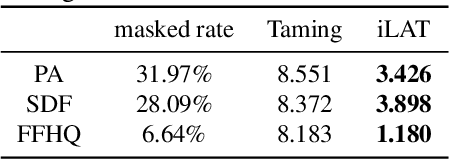
Recently, AutoRegressive (AR) models for the whole image generation empowered by transformers have achieved comparable or even better performance to Generative Adversarial Networks (GANs). Unfortunately, directly applying such AR models to edit/change local image regions, may suffer from the problems of missing global information, slow inference speed, and information leakage of local guidance. To address these limitations, we propose a novel model -- image Local Autoregressive Transformer (iLAT), to better facilitate the locally guided image synthesis. Our iLAT learns the novel local discrete representations, by the newly proposed local autoregressive (LA) transformer of the attention mask and convolution mechanism. Thus iLAT can efficiently synthesize the local image regions by key guidance information. Our iLAT is evaluated on various locally guided image syntheses, such as pose-guided person image synthesis and face editing. Both the quantitative and qualitative results show the efficacy of our model.