 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Few-shot Learning Based on Multi-stage Transfer and Class-Balanced Loss for Diabetic Retinopathy Grading
Sep 24, 2021

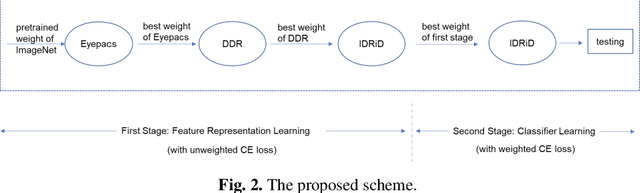
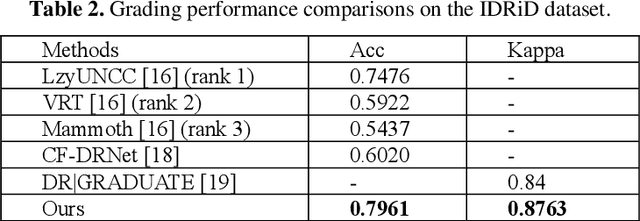
Diabetic retinopathy (DR) is one of the major blindness-causing diseases current-ly known. Automatic grading of DR using deep learning methods not only speeds up the diagnosis of the disease but also reduces the rate of misdiagnosis. However, problems such as insufficient samples and imbalanced class distribu-tion in DR datasets have constrained the improvement of grading performance. In this paper, we introduce the idea of multi-stage transfer into the grading task of DR. The new transfer learning technique leverages multiple datasets with differ-ent scales to enable the model to learn more feature representation information. Meanwhile, to cope with imbalanced DR datasets, we present a class-balanced loss function that performs well in natural image classification tasks, and adopt a simple and easy-to-implement training method for it. The experimental results show that the application of multi-stage transfer and class-balanced loss function can effectively improve the grading performance metrics such as accuracy and quadratic weighted kappa. In fact, our method has outperformed two state-of-the-art methods and achieved the best result on the DR grading task of IDRiD Sub-Challenge 2.
Truth-Conditional Captioning of Time Series Data
Oct 05, 2021
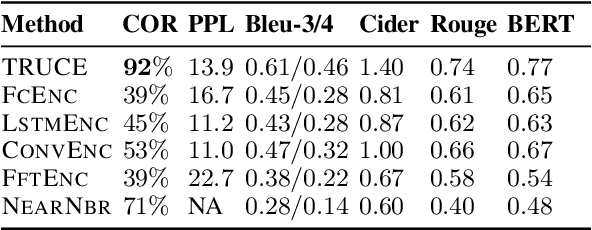
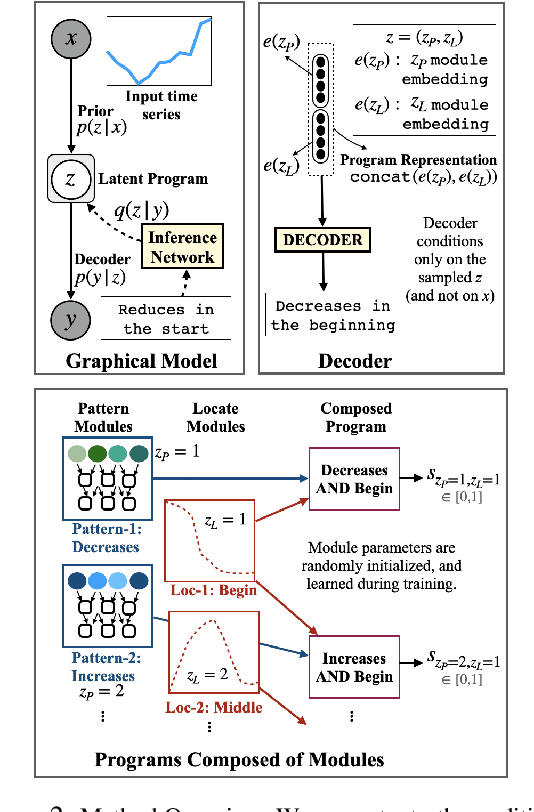
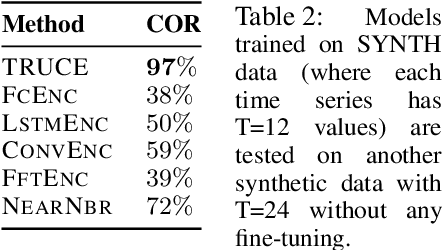
In this paper, we explore the task of automatically generating natural language descriptions of salient patterns in a time series, such as stock prices of a company over a week. A model for this task should be able to extract high-level patterns such as presence of a peak or a dip. While typical contemporary neural models with attention mechanisms can generate fluent output descriptions for this task, they often generate factually incorrect descriptions. We propose a computational model with a truth-conditional architecture which first runs small learned programs on the input time series, then identifies the programs/patterns which hold true for the given input, and finally conditions on only the chosen valid program (rather than the input time series) to generate the output text description. A program in our model is constructed from modules, which are small neural networks that are designed to capture numerical patterns and temporal information. The modules are shared across multiple programs, enabling compositionality as well as efficient learning of module parameters. The modules, as well as the composition of the modules, are unobserved in data, and we learn them in an end-to-end fashion with the only training signal coming from the accompanying natural language text descriptions. We find that the proposed model is able to generate high-precision captions even though we consider a small and simple space of module types.
Learning Dual Dynamic Representations on Time-Sliced User-Item Interaction Graphs for Sequential Recommendation
Sep 24, 2021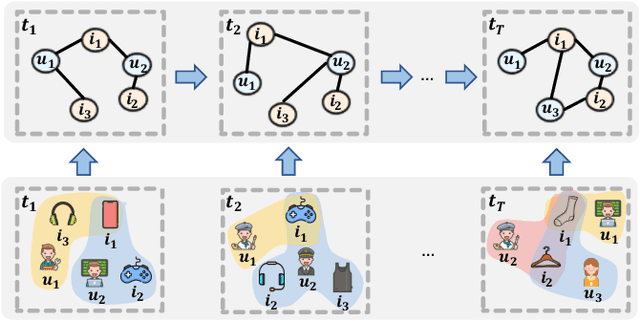
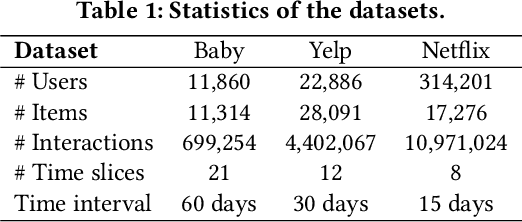
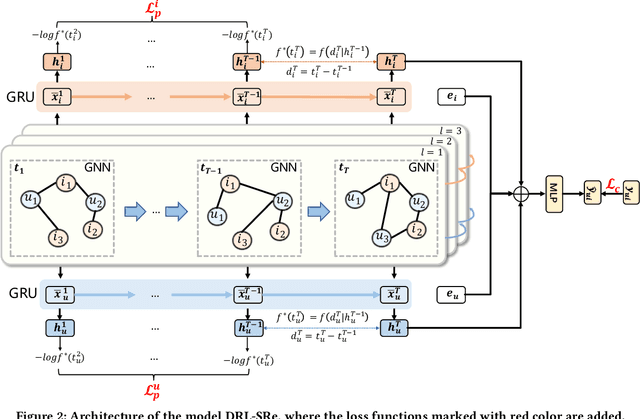
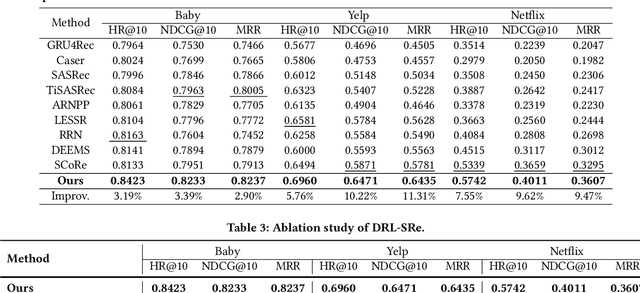
Sequential Recommendation aims to recommend items that a target user will interact with in the near future based on the historically interacted items. While modeling temporal dynamics is crucial for sequential recommendation, most of the existing studies concentrate solely on the user side while overlooking the sequential patterns existing in the counterpart, i.e., the item side. Although a few studies investigate the dynamics involved in the dual sides, the complex user-item interactions are not fully exploited from a global perspective to derive dynamic user and item representations. In this paper, we devise a novel Dynamic Representation Learning model for Sequential Recommendation (DRL-SRe). To better model the user-item interactions for characterizing the dynamics from both sides, the proposed model builds a global user-item interaction graph for each time slice and exploits time-sliced graph neural networks to learn user and item representations. Moreover, to enable the model to capture fine-grained temporal information, we propose an auxiliary temporal prediction task over consecutive time slices based on temporal point process. Comprehensive experiments on three public real-world datasets demonstrate DRL-SRe outperforms the state-of-the-art sequential recommendation models with a large margin.
Multi-modal AsynDGAN: Learn From Distributed Medical Image Data without Sharing Private Information
Dec 15, 2020As deep learning technologies advance, increasingly more data is necessary to generate general and robust models for various tasks. In the medical domain, however, large-scale and multi-parties data training and analyses are infeasible due to the privacy and data security concerns. In this paper, we propose an extendable and elastic learning framework to preserve privacy and security while enabling collaborative learning with efficient communication. The proposed framework is named distributed Asynchronized Discriminator Generative Adversarial Networks (AsynDGAN), which consists of a centralized generator and multiple distributed discriminators. The advantages of our proposed framework are five-fold: 1) the central generator could learn the real data distribution from multiple datasets implicitly without sharing the image data; 2) the framework is applicable for single-modality or multi-modality data; 3) the learned generator can be used to synthesize samples for down-stream learning tasks to achieve close-to-real performance as using actual samples collected from multiple data centers; 4) the synthetic samples can also be used to augment data or complete missing modalities for one single data center; 5) the learning process is more efficient and requires lower bandwidth than other distributed deep learning methods.
Solution of Physics-based Bayesian Inverse Problems with Deep Generative Priors
Jul 06, 2021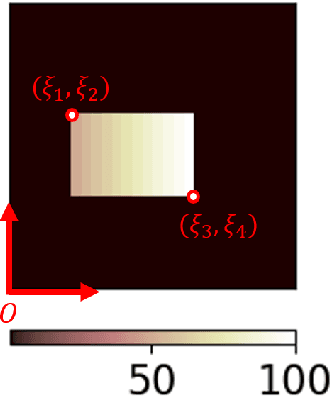
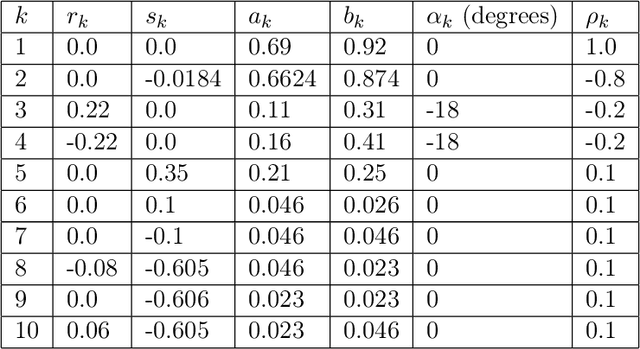
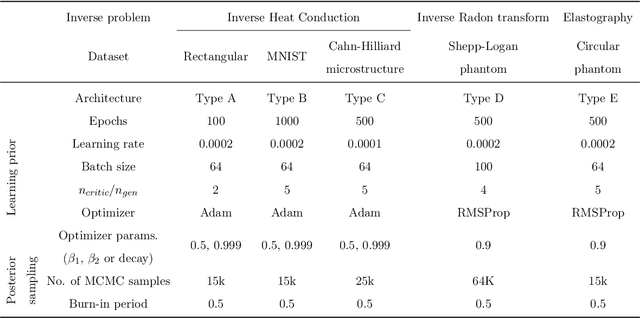
Inverse problems are notoriously difficult to solve because they can have no solutions, multiple solutions, or have solutions that vary significantly in response to small perturbations in measurements. Bayesian inference, which poses an inverse problem as a stochastic inference problem, addresses these difficulties and provides quantitative estimates of the inferred field and the associated uncertainty. However, it is difficult to employ when inferring vectors of large dimensions, and/or when prior information is available through previously acquired samples. In this paper, we describe how deep generative adversarial networks can be used to represent the prior distribution in Bayesian inference and overcome these challenges. We apply these ideas to inverse problems that are diverse in terms of the governing physical principles, sources of prior knowledge, type of measurement, and the extent of available information about measurement noise. In each case we apply the proposed approach to infer the most likely solution and quantitative estimates of uncertainty.
Spatio-Temporal Context for Action Detection
Jun 29, 2021
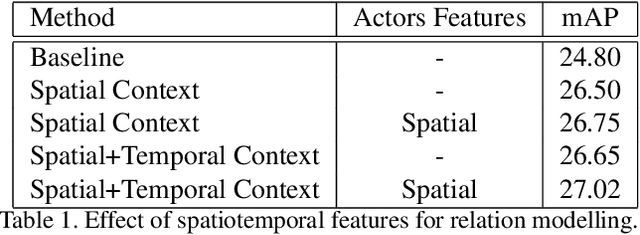
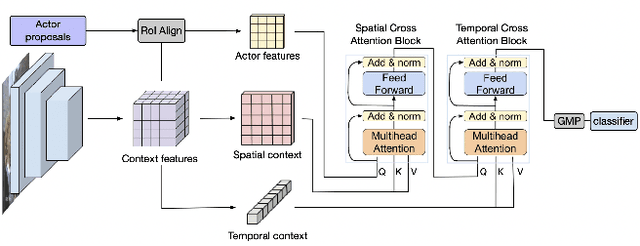
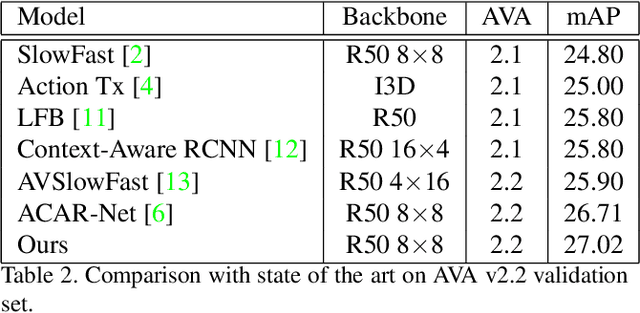
Research in action detection has grown in the recentyears, as it plays a key role in video understanding. Modelling the interactions (either spatial or temporal) between actors and their context has proven to be essential for this task. While recent works use spatial features with aggregated temporal information, this work proposes to use non-aggregated temporal information. This is done by adding an attention based method that leverages spatio-temporal interactions between elements in the scene along the clip.The main contribution of this work is the introduction of two cross attention blocks to effectively model the spatial relations and capture short range temporal interactions.Experiments on the AVA dataset show the advantages of the proposed approach that models spatio-temporal relations between relevant elements in the scene, outperforming other methods that model actor interactions with their context by +0.31 mAP.
End-to-end Waveform Learning Through Joint Optimization of Pulse and Constellation Shaping
Jun 29, 2021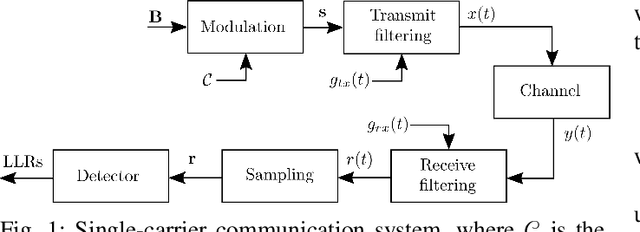

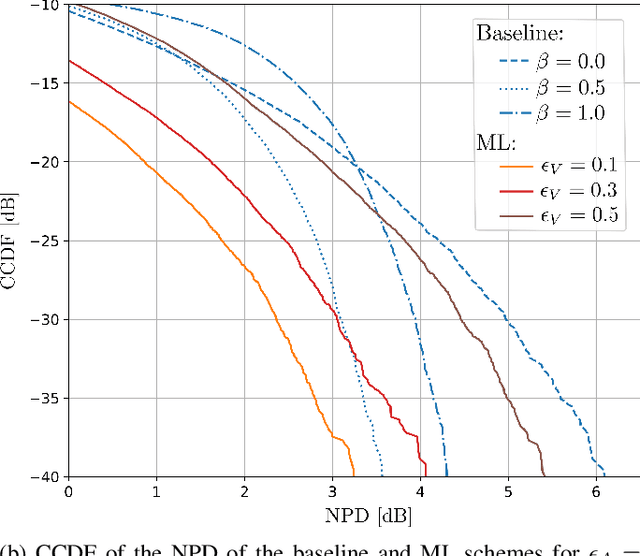
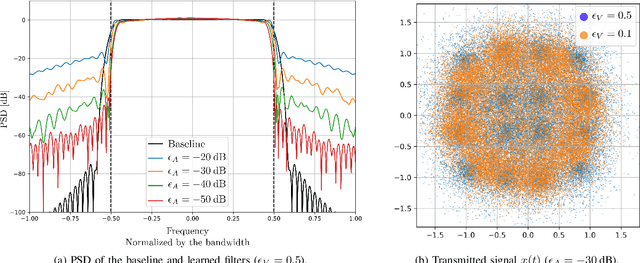
As communication systems are foreseen to enable new services such as joint communication and sensing and utilize parts of the sub-THz spectrum, the design of novel waveforms that can support these emerging applications becomes increasingly challenging. We present in this work an end-to-end learning approach to design waveforms through joint learning of pulse shaping and constellation geometry, together with a neural network (NN)-based receiver. Optimization is performed to maximize an achievable information rate, while satisfying constraints on out-of-band emission and power envelope. Our results show that the proposed approach enables up to orders of magnitude smaller adjacent channel leakage ratios (ACLRs) with peak-to-average power ratios (PAPRs) competitive with traditional filters, without significant loss of information rate on an additive white Gaussian noise (AWGN) channel, and no additional complexity at the transmitter.
BIOPAK Flasher: Epidemic disease monitoring and detection in Pakistan using text mining
Jun 12, 2021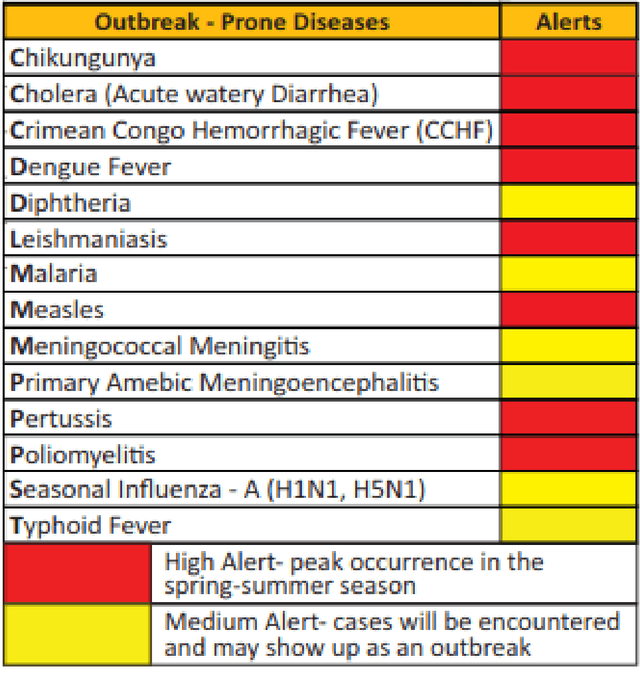
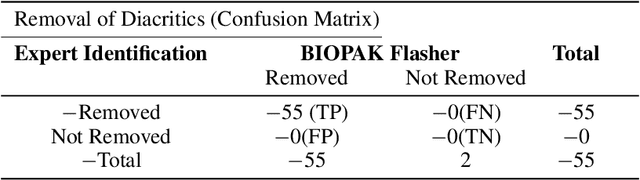
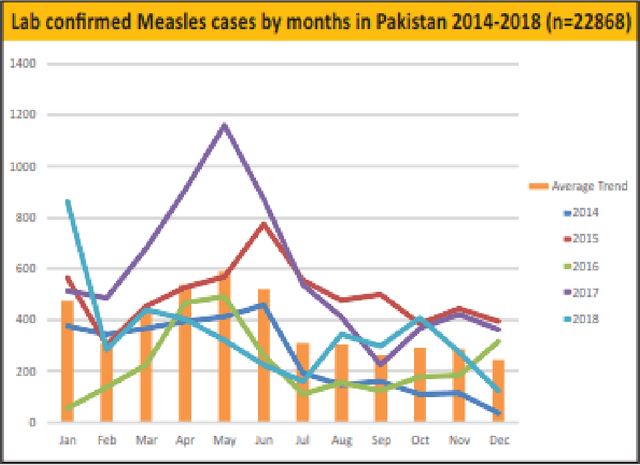
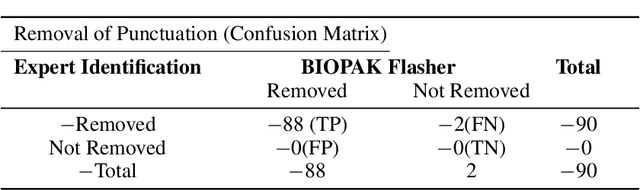
Infectious disease outbreak has a significant impact on morbidity, mortality and can cause economic instability of many countries. As global trade is growing, goods and individuals are expected to travel across the border, an infected epidemic area carrier can pose a great danger to his hostile. If a disease outbreak is recognized promptly, then commercial products and travelers (traders/visitors) will be effectively vaccinated, and therefore the disease stopped. Early detection of outbreaks plays an important role here, and beware of the rapid implementation of control measures by citizens, public health organizations, and government. Many indicators have valuable information, such as online news sources (RSS) and social media sources (Twitter, Facebook) that can be used, but are unstructured and bulky, to extract information about disease outbreaks. Few early warning outbreak systems exist with some limitation of linguistic (Urdu) and covering areas (Pakistan). In Pakistan, few channels are published the outbreak news in Urdu or English. The aim is to procure information from Pakistan's English and Urdu news channels and then investigate process, integrate, and visualize the disease epidemic. Urdu ontology is not existed before to match extracted diseases, so we also build that ontology of disease.
Analysis of the relation between smartphone usage changes during the COVID-19 pandemic and usage preferences on apps
Oct 05, 2021
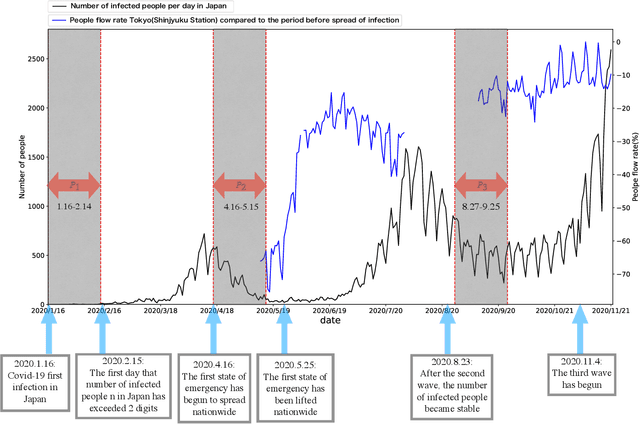

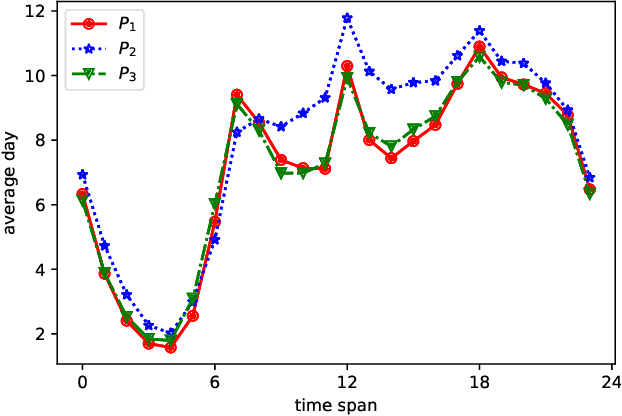
Since the World Health Organization announced the COVID-19 pandemic in March 2020, curbing the spread of the virus has become an international priority. It has greatly affected people's lifestyles. In this article, we observe and analyze the impact of the pandemic on people's lives using changes in smartphone application usage. First, through observing the daily usage change trends of all users during the pandemic, we can understand and analyze the effects of restrictive measures and policies during the pandemic on people's lives. In addition, it is also helpful for the government and health departments to take more appropriate restrictive measures in the case of future pandemics. Second, we defined the usage change features and found 9 different usage change patterns during the pandemic according to clusters of users and show the diversity of daily usage changes. It helps to understand and analyze the different impacts of the pandemic and restrictive measures on different types of people in more detail. Finally, according to prediction models, we discover the main related factors of each usage change type from user preferences and demographic information. It helps to predict changes in smartphone activity during future pandemics or when other restrictive measures are implemented, which may become a new indicator to judge and manage the risks of measures or events.
A 3D Mesh-based Lifting-and-Projection Network for Human Pose Transfer
Sep 24, 2021
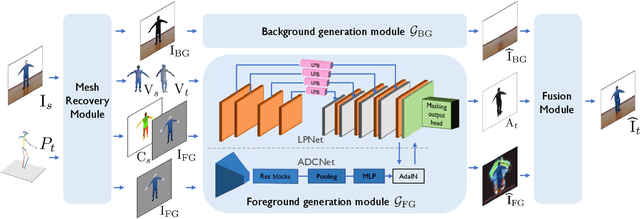
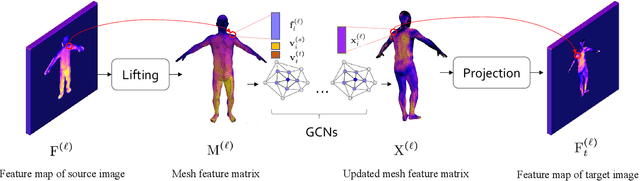

Human pose transfer has typically been modeled as a 2D image-to-image translation problem. This formulation ignores the human body shape prior in 3D space and inevitably causes implausible artifacts, especially when facing occlusion. To address this issue, we propose a lifting-and-projection framework to perform pose transfer in the 3D mesh space. The core of our framework is a foreground generation module, that consists of two novel networks: a lifting-and-projection network (LPNet) and an appearance detail compensating network (ADCNet). To leverage the human body shape prior, LPNet exploits the topological information of the body mesh to learn an expressive visual representation for the target person in the 3D mesh space. To preserve texture details, ADCNet is further introduced to enhance the feature produced by LPNet with the source foreground image. Such design of the foreground generation module enables the model to better handle difficult cases such as those with occlusions. Experiments on the iPER and Fashion datasets empirically demonstrate that the proposed lifting-and-projection framework is effective and outperforms the existing image-to-image-based and mesh-based methods on human pose transfer task in both self-transfer and cross-transfer settings.