 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-class Road Defect Detection and Segmentation using Spatial and Channel-wise Attention for Autonomous Road Repairing
Feb 06, 2024
Road pavement detection and segmentation are critical for developing autonomous road repair systems. However, developing an instance segmentation method that simultaneously performs multi-class defect detection and segmentation is challenging due to the textural simplicity of road pavement image, the diversity of defect geometries, and the morphological ambiguity between classes. We propose a novel end-to-end method for multi-class road defect detection and segmentation. The proposed method comprises multiple spatial and channel-wise attention blocks available to learn global representations across spatial and channel-wise dimensions. Through these attention blocks, more globally generalised representations of morphological information (spatial characteristics) of road defects and colour and depth information of images can be learned. To demonstrate the effectiveness of our framework, we conducted various ablation studies and comparisons with prior methods on a newly collected dataset annotated with nine road defect classes. The experiments show that our proposed method outperforms existing state-of-the-art methods for multi-class road defect detection and segmentation methods.
Synergizing Spatial Optimization with Large Language Models for Open-Domain Urban Itinerary Planning
Feb 11, 2024In this paper, we for the first time propose the task of Open-domain Urban Itinerary Planning (OUIP) for citywalk, which directly generates itineraries based on users' requests described in natural language. OUIP is different from conventional itinerary planning, which limits users from expressing more detailed needs and hinders true personalization. Recently, large language models (LLMs) have shown potential in handling diverse tasks. However, due to non-real-time information, incomplete knowledge, and insufficient spatial awareness, they are unable to independently deliver a satisfactory user experience in OUIP. Given this, we present ItiNera, an OUIP system that synergizes spatial optimization with Large Language Models (LLMs) to provide services that customize urban itineraries based on users' needs. Specifically, we develop an LLM-based pipeline for extracting and updating POI features to create a user-owned personalized POI database. For each user request, we leverage LLM in cooperation with an embedding-based module for retrieving candidate POIs from the user's POI database. Then, a spatial optimization module is used to order these POIs, followed by LLM crafting a personalized, spatially coherent itinerary. To the best of our knowledge, this study marks the first integration of LLMs to innovate itinerary planning solutions. Extensive experiments on offline datasets and online subjective evaluation have demonstrated the capacities of our system to deliver more responsive and spatially coherent itineraries than current LLM-based solutions. Our system has been deployed in production at the TuTu online travel service and has attracted thousands of users for their urban travel planning.
YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction
Jan 08, 2024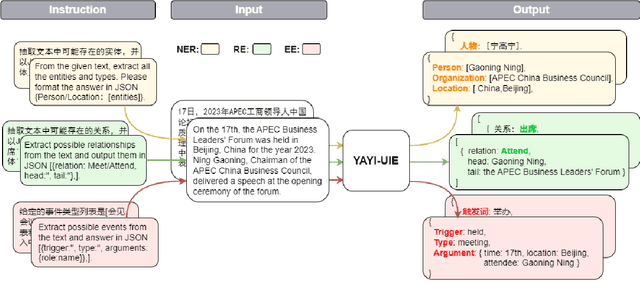
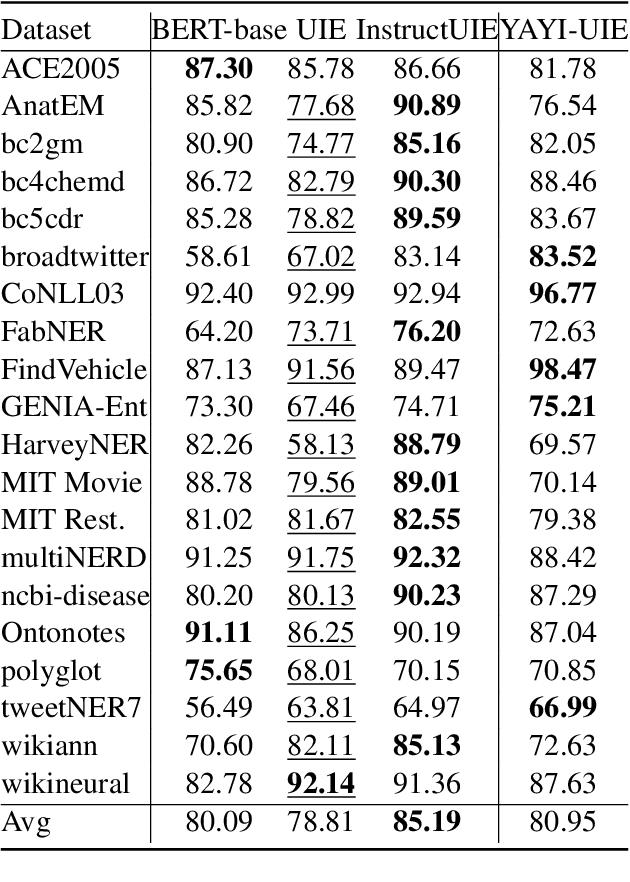
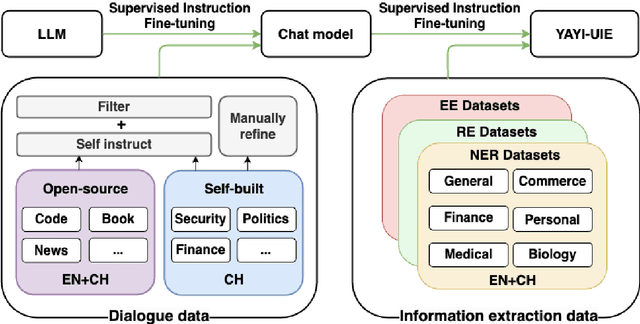
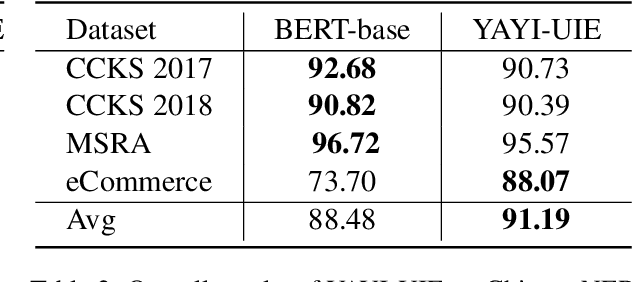
The difficulty of the information extraction task lies in dealing with the task-specific label schemas and heterogeneous data structures. Recent work has proposed methods based on large language models to uniformly model different information extraction tasks. However, these existing methods are deficient in their information extraction capabilities for Chinese languages other than English. In this paper, we propose an end-to-end chat-enhanced instruction tuning framework for universal information extraction (YAYI-UIE), which supports both Chinese and English. Specifically, we utilize dialogue data and information extraction data to enhance the information extraction performance jointly. Experimental results show that our proposed framework achieves state-of-the-art performance on Chinese datasets while also achieving comparable performance on English datasets under both supervised settings and zero-shot settings.
Zero-shot Explainable Mental Health Analysis on Social Media by incorporating Mental Scales
Feb 09, 2024Traditional discriminative approaches in mental health analysis are known for their strong capacity but lack interpretability and demand large-scale annotated data. On the other hand, generative approaches, such as those based on large language models (LLMs),have the potential to get rid of heavy annotations and provide explanations. However, their capabilities still fall short compared to discriminative approaches, and their explanations may be unreliable due to the fact that the generation of explanation is a black-box process. Inspired by the psychological assessment practice of using scales to evaluate mental states, our method incorporates two procedures via LLMs. First, the patient completes mental health questionnaires, and second, the psychologist interprets the collected information from the mental health questions and makes informed decisions. Experimental results show that our method outperforms other zero-shot methods. Our method can generate more rigorous explanation based on the outputs of mental questionnaires.
Capturing Cancer as Music: Cancer Mechanisms Expressed through Musification
Feb 09, 2024The development of cancer is difficult to express on a simple and intuitive level due to its complexity. Since cancer is so widespread, raising public awareness about its mechanisms can help those affected cope with its realities, as well as inspire others to make lifestyle adjustments and screen for the disease. Unfortunately, studies have shown that cancer literature is too technical for the general public to understand. We found that musification, the process of turning data into music, remains an unexplored avenue for conveying this information. We explore the pedagogical effectiveness of musification through the use of an algorithm that manipulates a piece of music in a manner analogous to the development of cancer. We conducted two lab studies and found that our approach is marginally more effective at promoting cancer literacy when accompanied by a text-based article than text-based articles alone.
Maia: A Real-time Non-Verbal Chat for Human-AI Interaction
Feb 09, 2024Face-to-face communication modeling in computer vision is an area of research focusing on developing algorithms that can recognize and analyze non-verbal cues and behaviors during face-to-face interactions. We propose an alternative to text chats for Human-AI interaction, based on non-verbal visual communication only, using facial expressions and head movements that mirror, but also improvise over the human user, to efficiently engage with the users, and capture their attention in a low-cost and real-time fashion. Our goal is to track and analyze facial expressions, and other non-verbal cues in real-time, and use this information to build models that can predict and understand human behavior. We offer three different complementary approaches, based on retrieval, statistical, and deep learning techniques. We provide human as well as automatic evaluations and discuss the advantages and disadvantages of each direction.
What's documented in AI? Systematic Analysis of 32K AI Model Cards
Feb 07, 2024The rapid proliferation of AI models has underscored the importance of thorough documentation, as it enables users to understand, trust, and effectively utilize these models in various applications. Although developers are encouraged to produce model cards, it's not clear how much information or what information these cards contain. In this study, we conduct a comprehensive analysis of 32,111 AI model documentations on Hugging Face, a leading platform for distributing and deploying AI models. Our investigation sheds light on the prevailing model card documentation practices. Most of the AI models with substantial downloads provide model cards, though the cards have uneven informativeness. We find that sections addressing environmental impact, limitations, and evaluation exhibit the lowest filled-out rates, while the training section is the most consistently filled-out. We analyze the content of each section to characterize practitioners' priorities. Interestingly, there are substantial discussions of data, sometimes with equal or even greater emphasis than the model itself. To evaluate the impact of model cards, we conducted an intervention study by adding detailed model cards to 42 popular models which had no or sparse model cards previously. We find that adding model cards is moderately correlated with an increase weekly download rates. Our study opens up a new perspective for analyzing community norms and practices for model documentation through large-scale data science and linguistics analysis.
Multilingual E5 Text Embeddings: A Technical Report
Feb 08, 2024This technical report presents the training methodology and evaluation results of the open-source multilingual E5 text embedding models, released in mid-2023. Three embedding models of different sizes (small / base / large) are provided, offering a balance between the inference efficiency and embedding quality. The training procedure adheres to the English E5 model recipe, involving contrastive pre-training on 1 billion multilingual text pairs, followed by fine-tuning on a combination of labeled datasets. Additionally, we introduce a new instruction-tuned embedding model, whose performance is on par with state-of-the-art, English-only models of similar sizes. Information regarding the model release can be found at https://github.com/microsoft/unilm/tree/master/e5 .
Let Your Graph Do the Talking: Encoding Structured Data for LLMs
Feb 08, 2024How can we best encode structured data into sequential form for use in large language models (LLMs)? In this work, we introduce a parameter-efficient method to explicitly represent structured data for LLMs. Our method, GraphToken, learns an encoding function to extend prompts with explicit structured information. Unlike other work which focuses on limited domains (e.g. knowledge graph representation), our work is the first effort focused on the general encoding of structured data to be used for various reasoning tasks. We show that explicitly representing the graph structure allows significant improvements to graph reasoning tasks. Specifically, we see across the board improvements - up to 73% points - on node, edge and, graph-level tasks from the GraphQA benchmark.
Doing Experiments and Revising Rules with Natural Language and Probabilistic Reasoning
Feb 08, 2024We build a computational model of how humans actively infer hidden rules by doing experiments. The basic principles behind the model is that, even if the rule is deterministic, the learner considers a broader space of fuzzy probabilistic rules, which it represents in natural language, and updates its hypotheses online after each experiment according to approximately Bayesian principles. In the same framework we also model experiment design according to information-theoretic criteria. We find that the combination of these three principles -- explicit hypotheses, probabilistic rules, and online updates -- can explain human performance on a Zendo-style task, and that removing any of these components leaves the model unable to account for the data.