 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coordinated Random Access for Industrial IoT With Correlated Traffic By Reinforcement-Learning
Sep 17, 2021
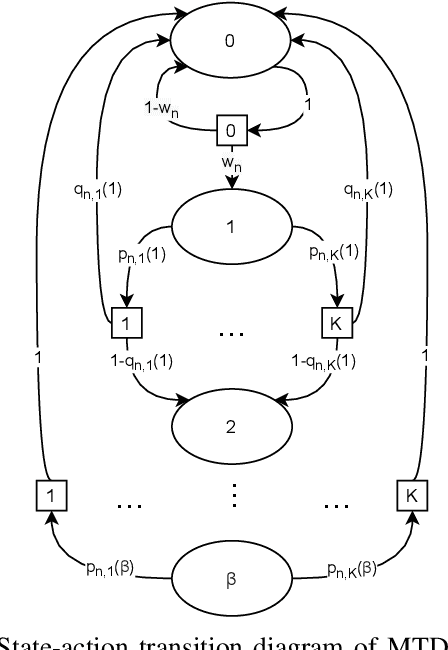
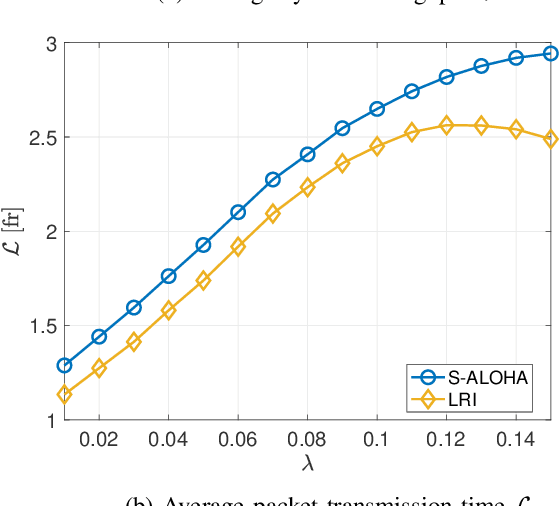
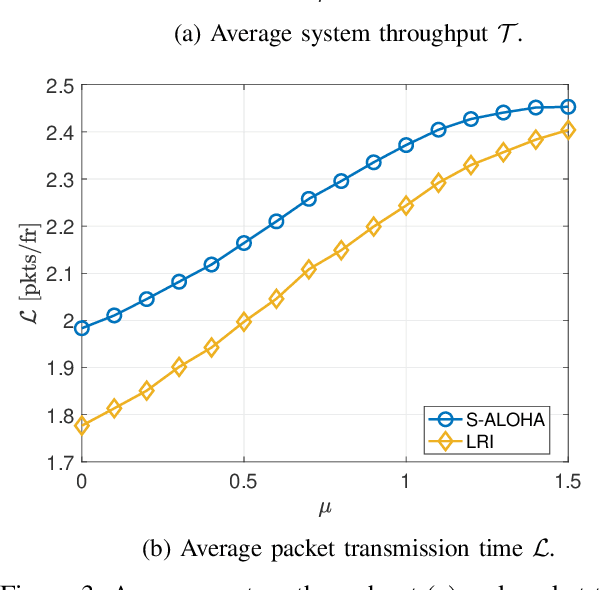
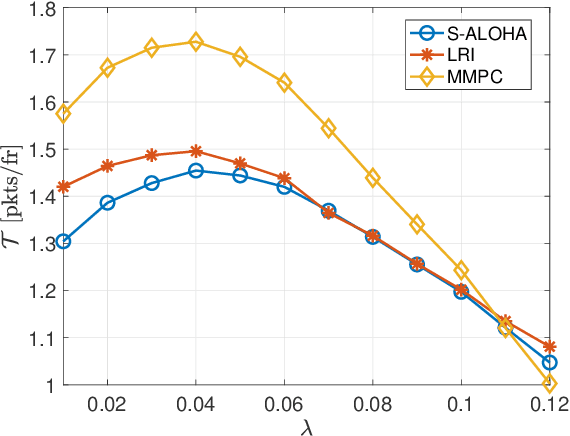
We propose a coordinated random access scheme for industrial internet-of-things (IIoT) scenarios, with machine-type devices (MTDs) generating sporadic correlated traffic. This occurs, e.g., when external events trigger data generation at multiple MTDs simultaneously. Time is divided into frames, each split into slots and each MTD randomly selects one slot for (re)transmission, with probability density functions (PDFs) specific of both the MTD and the number of the current retransmission. PDFs are locally optimized to minimize the probability of packet collision. The optimization problem is modeled as a repeated Markov game with incomplete information, and the linear reward-inaction algorithm is used at each MTD, which provably converges to a deterministic (suboptimal) slot assignment. We compare our solution with both the slotted ALOHA and the min-max pairwise correlation random access schemes, showing that our approach achieves a higher network throughput with moderate traffic intensity.
RAP-Net: Region Attention Predictive Network for Precipitation Nowcasting
Oct 03, 2021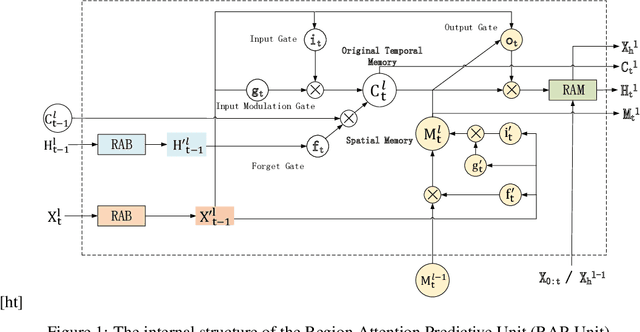
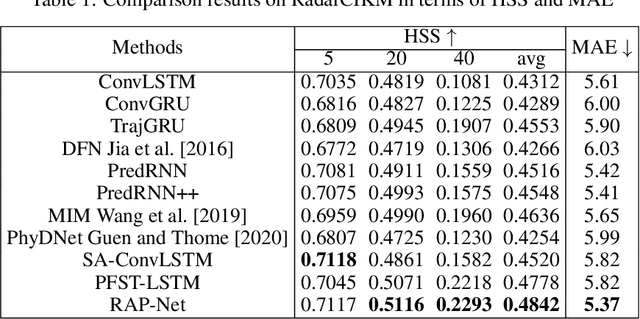
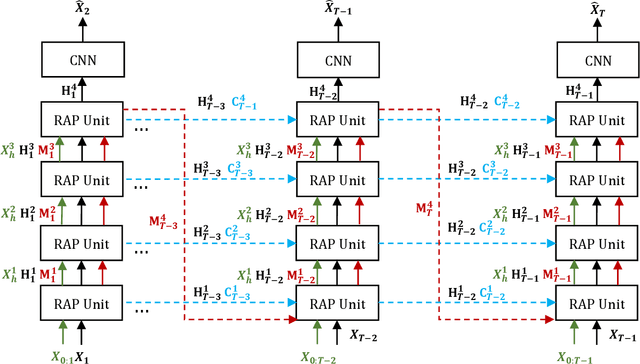
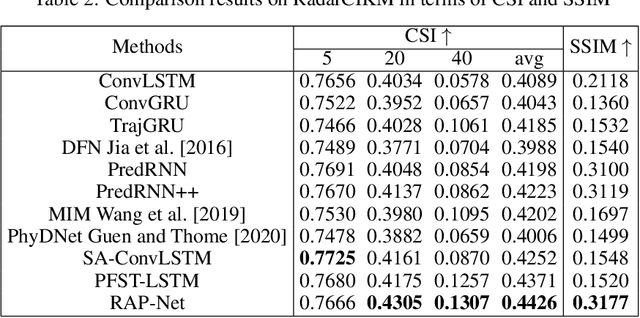
Natural disasters caused by heavy rainfall often cost huge loss of life and property. To avoid it, the task of precipitation nowcasting is imminent. To solve the problem, increasingly deep learning methods are proposed to forecast future radar echo images and then the predicted maps have converted the distribution of rainfall. The prevailing spatiotemporal sequence prediction methods apply ConvRNN structure which combines the Convolution and Recurrent neural network. Although improvements based on ConvRNN achieve remarkable success, these methods ignore capturing both local and global spatial features simultaneously, which degrades the nowcasting in the region of heavy rainfall. To address this issue, we proposed the Region Attention Block (RAB) and embed it into ConvRNN to enhance the forecast in the area with strong rainfall. Besides, the ConvRNN models are hard to memory longer history representations with limited parameters. Considering it, we propose Recall Attention Mechanism (RAM) to improve the prediction. By preserving longer temporal information, RAM contributes to the forecasting, especially in the middle rainfall intensity. The experiments show that the proposed model Region Attention Predictive Network (RAP-Net) has outperformed the state-of-art method.
Gradient Disaggregation: Breaking Privacy in Federated Learning by Reconstructing the User Participant Matrix
Jun 10, 2021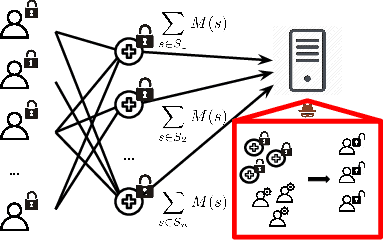
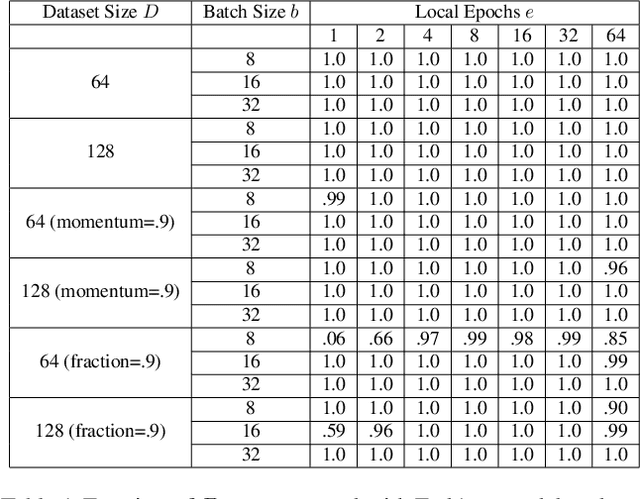
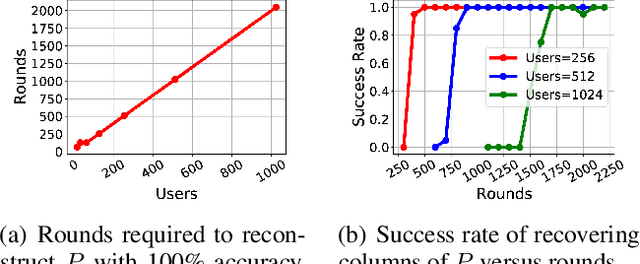

We show that aggregated model updates in federated learning may be insecure. An untrusted central server may disaggregate user updates from sums of updates across participants given repeated observations, enabling the server to recover privileged information about individual users' private training data via traditional gradient inference attacks. Our method revolves around reconstructing participant information (e.g: which rounds of training users participated in) from aggregated model updates by leveraging summary information from device analytics commonly used to monitor, debug, and manage federated learning systems. Our attack is parallelizable and we successfully disaggregate user updates on settings with up to thousands of participants. We quantitatively and qualitatively demonstrate significant improvements in the capability of various inference attacks on the disaggregated updates. Our attack enables the attribution of learned properties to individual users, violating anonymity, and shows that a determined central server may undermine the secure aggregation protocol to break individual users' data privacy in federated learning.
An Enhanced Span-based Decomposition Method for Few-Shot Sequence Labeling
Sep 27, 2021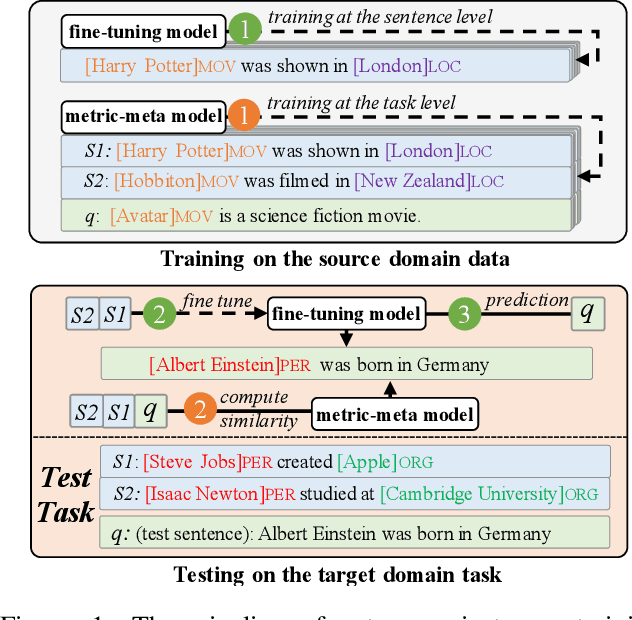

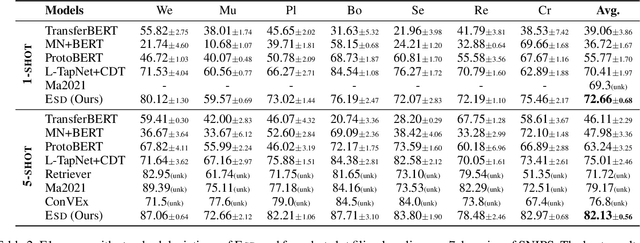
Few-Shot Sequence Labeling (FSSL) is a canonical solution for the tagging models to generalize on an emerging, resource-scarce domain. In this paper, we propose ESD, an Enhanced Span-based Decomposition method, which follows the metric-based meta-learning paradigm for FSSL. ESD improves previous methods from two perspectives: a) Introducing an optimal span decomposition framework. We formulate FSSL as an optimization problem that seeks for an optimal span matching between test query and supporting instances. During inference, we propose a post-processing algorithm to alleviate false positive labeling by resolving span conflicts. b) Enhancing representation for spans and class prototypes. We refine span representation by inter- and cross-span attention, and obtain the class prototypical representation with multi-instance learning. To avoid the semantic drift when representing the O-type (not a specific entity or slot) prototypes, we divide the O-type spans into three categories according to their boundary information. ESD outperforms previous methods in two popular FSSL benchmarks, FewNERD and SNIPS, and is proven to be more robust in the nested and noisy tagging scenarios.
Adaptive importance sampling for seismic fragility curve estimation
Sep 09, 2021
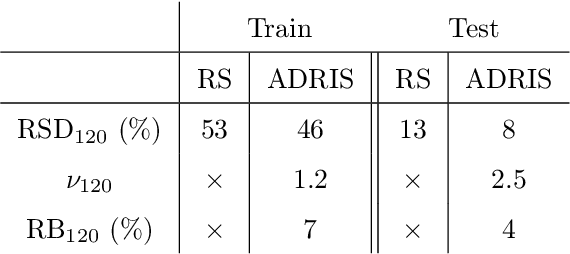
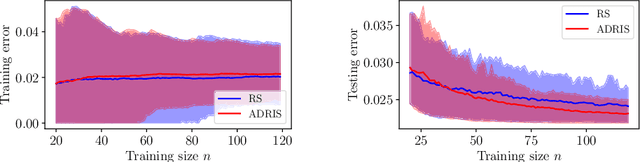
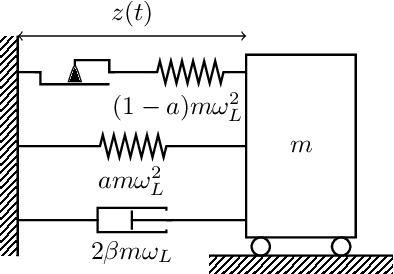
As part of Probabilistic Risk Assessment studies, it is necessary to study the fragility of mechanical and civil engineered structures when subjected to seismic loads. This risk can be measured with fragility curves, which express the probability of failure of the structure conditionally to a seismic intensity measure. The estimation of fragility curves relies on time-consuming numerical simulations, so that careful experimental design is required in order to gain the maximum information on the structure's fragility with a limited number of code evaluations. We propose and implement an active learning methodology based on adaptive importance sampling in order to reduce the variance of the training loss. The efficiency of the proposed method in terms of bias, standard deviation and prediction interval coverage are theoretically and numerically characterized.
Challenging the Semi-Supervised VAE Framework for Text Classification
Sep 27, 2021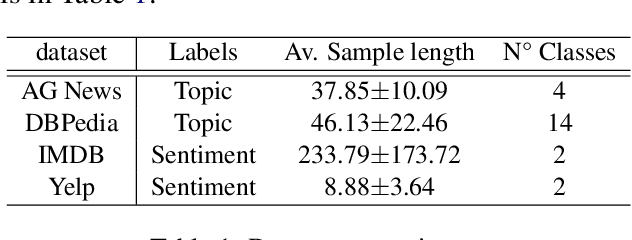
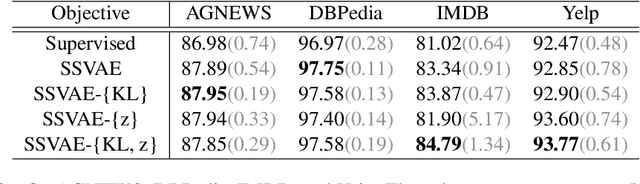


Semi-Supervised Variational Autoencoders (SSVAEs) are widely used models for data efficient learning. In this paper, we question the adequacy of the standard design of sequence SSVAEs for the task of text classification as we exhibit two sources of overcomplexity for which we provide simplifications. These simplifications to SSVAEs preserve their theoretical soundness while providing a number of practical advantages in the semi-supervised setup where the result of training is a text classifier. These simplifications are the removal of (i) the Kullback-Liebler divergence from its objective and (ii) the fully unobserved latent variable from its probabilistic model. These changes relieve users from choosing a prior for their latent variables, make the model smaller and faster, and allow for a better flow of information into the latent variables. We compare the simplified versions to standard SSVAEs on 4 text classification tasks. On top of the above-mentioned simplification, experiments show a speed-up of 26%, while keeping equivalent classification scores. The code to reproduce our experiments is public.
GraFormer: Graph Convolution Transformer for 3D Pose Estimation
Sep 17, 2021Exploiting relations among 2D joints plays a crucial role yet remains semi-developed in 2D-to-3D pose estimation. To alleviate this issue, we propose GraFormer, a novel transformer architecture combined with graph convolution for 3D pose estimation. The proposed GraFormer comprises two repeatedly stacked core modules, GraAttention and ChebGConv block. GraAttention enables all 2D joints to interact in global receptive field without weakening the graph structure information of joints, which introduces vital features for later modules. Unlike vanilla graph convolutions that only model the apparent relationship of joints, ChebGConv block enables 2D joints to interact in the high-order sphere, which formulates their hidden implicit relations. We empirically show the superiority of GraFormer through conducting extensive experiments across popular benchmarks. Specifically, GraFormer outperforms state of the art on Human3.6M dataset while using 18$\%$ parameters. The code is available at https://github.com/Graformer/GraFormer .
Multi-Layer Pseudo-Supervision for Histopathology Tissue Semantic Segmentation using Patch-level Classification Labels
Oct 14, 2021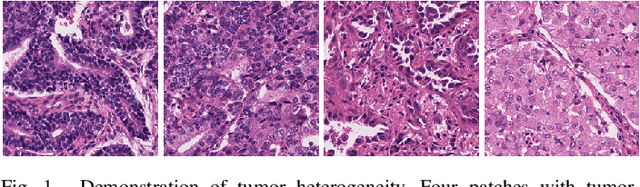

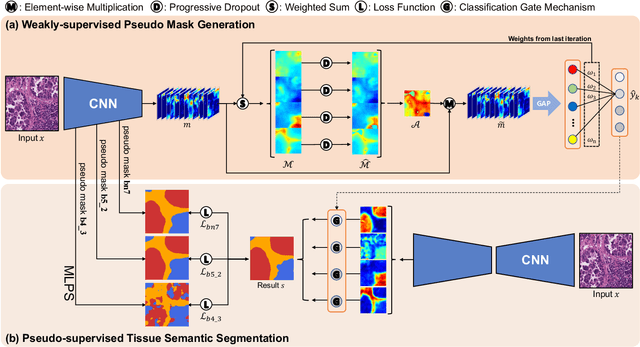
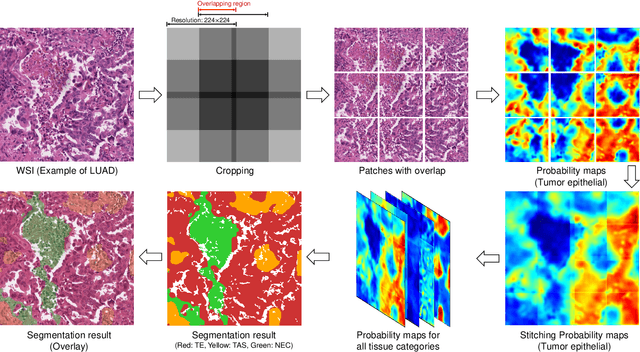
Tissue-level semantic segmentation is a vital step in computational pathology. Fully-supervised models have already achieved outstanding performance with dense pixel-level annotations. However, drawing such labels on the giga-pixel whole slide images is extremely expensive and time-consuming. In this paper, we use only patch-level classification labels to achieve tissue semantic segmentation on histopathology images, finally reducing the annotation efforts. We proposed a two-step model including a classification and a segmentation phases. In the classification phase, we proposed a CAM-based model to generate pseudo masks by patch-level labels. In the segmentation phase, we achieved tissue semantic segmentation by our proposed Multi-Layer Pseudo-Supervision. Several technical novelties have been proposed to reduce the information gap between pixel-level and patch-level annotations. As a part of this paper, we introduced a new weakly-supervised semantic segmentation (WSSS) dataset for lung adenocarcinoma (LUAD-HistoSeg). We conducted several experiments to evaluate our proposed model on two datasets. Our proposed model outperforms two state-of-the-art WSSS approaches. Note that we can achieve comparable quantitative and qualitative results with the fully-supervised model, with only around a 2\% gap for MIoU and FwIoU. By comparing with manual labeling, our model can greatly save the annotation time from hours to minutes. The source code is available at: \url{https://github.com/ChuHan89/WSSS-Tissue}.
Zooming Into the Darknet: Characterizing Internet Background Radiation and its Structural Changes
Aug 05, 2021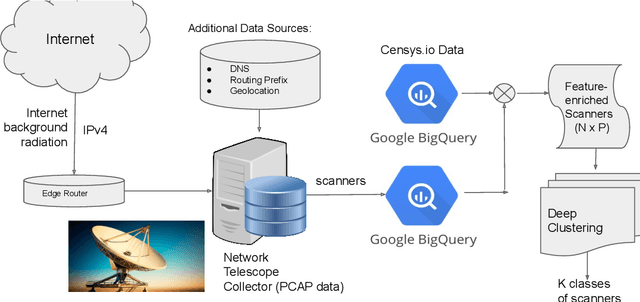

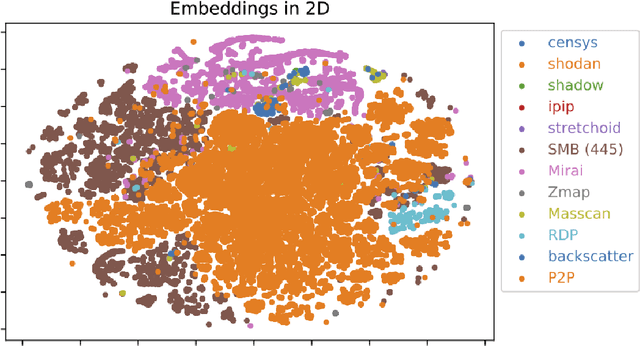

Network telescopes or "Darknets" provide a unique window into Internet-wide malicious activities associated with malware propagation, denial of service attacks, scanning performed for network reconnaissance, and others. Analyses of the resulting data can provide actionable insights to security analysts that can be used to prevent or mitigate cyber-threats. Large Darknets, however, observe millions of nefarious events on a daily basis which makes the transformation of the captured information into meaningful insights challenging. We present a novel framework for characterizing Darknet behavior and its temporal evolution aiming to address this challenge. The proposed framework: (i) Extracts a high dimensional representation of Darknet events composed of features distilled from Darknet data and other external sources; (ii) Learns, in an unsupervised fashion, an information-preserving low-dimensional representation of these events (using deep representation learning) that is amenable to clustering; (iv) Performs clustering of the scanner data in the resulting representation space and provides interpretable insights using optimal decision trees; and (v) Utilizes the clustering outcomes as "signatures" that can be used to detect structural changes in the Darknet activities. We evaluate the proposed system on a large operational Network Telescope and demonstrate its ability to detect real-world, high-impact cybersecurity incidents.
IQ-Learn: Inverse soft-Q Learning for Imitation
Jun 23, 2021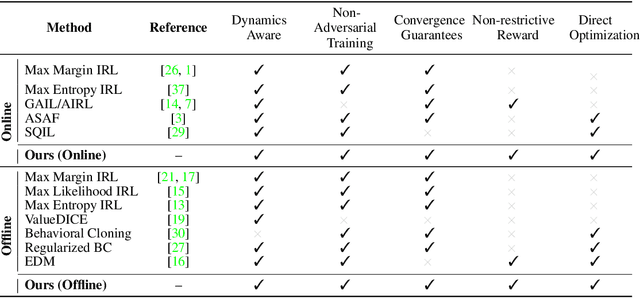
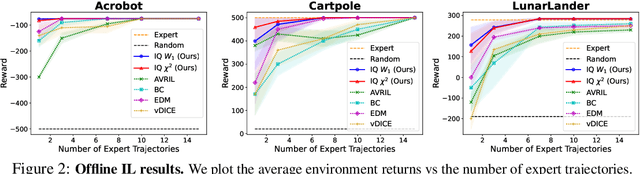
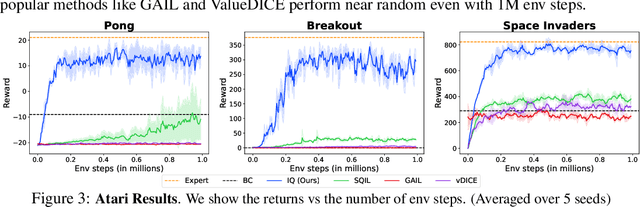
In many sequential decision-making problems (e.g., robotics control, game playing, sequential prediction), human or expert data is available containing useful information about the task. However, imitation learning (IL) from a small amount of expert data can be challenging in high-dimensional environments with complex dynamics. Behavioral cloning is a simple method that is widely used due to its simplicity of implementation and stable convergence but doesn't utilize any information involving the environment's dynamics. Many existing methods that exploit dynamics information are difficult to train in practice due to an adversarial optimization process over reward and policy approximators or biased, high variance gradient estimators. We introduce a method for dynamics-aware IL which avoids adversarial training by learning a single Q-function, implicitly representing both reward and policy. On standard benchmarks, the implicitly learned rewards show a high positive correlation with the ground-truth rewards, illustrating our method can also be used for inverse reinforcement learning (IRL). Our method, Inverse soft-Q learning (IQ-Learn) obtains state-of-the-art results in offline and online imitation learning settings, surpassing existing methods both in the number of required environment interactions and scalability in high-dimensional spaces.