 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bandit Quickest Changepoint Detection
Jul 22, 2021
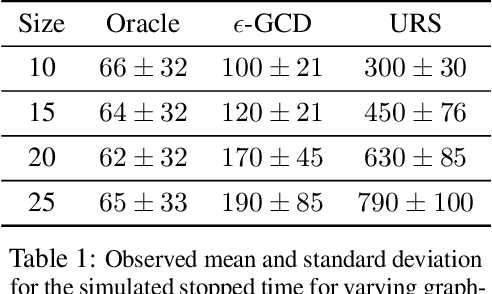
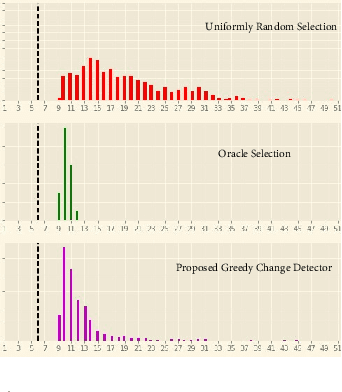
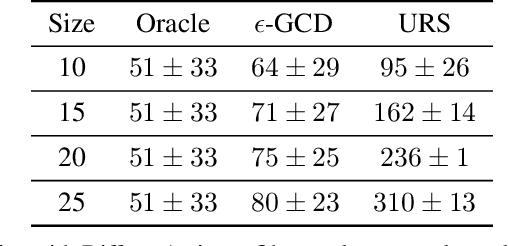
Detecting abrupt changes in temporal behavior patterns is of interest in many industrial and security applications. Abrupt changes are often local and observable primarily through a well-aligned sensing action (e.g., a camera with a narrow field-of-view). Due to resource constraints, continuous monitoring of all of the sensors is impractical. We propose the bandit quickest changepoint detection framework as a means of balancing sensing cost with detection delay. In this framework, sensing actions (or sensors) are sequentially chosen, and only measurements corresponding to chosen actions are observed. We derive an information-theoretic lower bound on the detection delay for a general class of finitely parameterized probability distributions. We then propose a computationally efficient online sensing scheme, which seamlessly balances the need for exploration of different sensing options with exploitation of querying informative actions. We derive expected delay bounds for the proposed scheme and show that these bounds match our information-theoretic lower bounds at low false alarm rates, establishing optimality of the proposed method. We then perform a number of experiments on synthetic and real datasets demonstrating the efficacy of our proposed method.
Applications of the Free Energy Principle to Machine Learning and Neuroscience
Jun 30, 2021In this PhD thesis, we explore and apply methods inspired by the free energy principle to two important areas in machine learning and neuroscience. The free energy principle is a general mathematical theory of the necessary information-theoretic behaviours of systems that maintain a separation from their environment. A core postulate of the theory is that complex systems can be seen as performing variational Bayesian inference and minimizing an information-theoretic quantity called the variational free energy. The thesis is structured into three independent sections. Firstly, we focus on predictive coding, a neurobiologically plausible process theory derived from the free energy principle which argues that the primary function of the brain is to minimize prediction errors, showing how predictive coding can be scaled up and extended to be more biologically plausible, and elucidating its close links with other methods such as Kalman Filtering. Secondly, we study active inference, a neurobiologically grounded account of action through variational message passing, and investigate how these methods can be scaled up to match the performance of deep reinforcement learning methods. We additionally provide a detailed mathematical understanding of the nature and origin of the information-theoretic objectives that underlie exploratory behaviour. Finally, we investigate biologically plausible methods of credit assignment in the brain. We first demonstrate a close link between predictive coding and the backpropagation of error algorithm. We go on to propose novel and simpler algorithms which allow for backprop to be implemented in purely local, biologically plausible computations.
Policy Optimization with Second-Order Advantage Information
May 09, 2018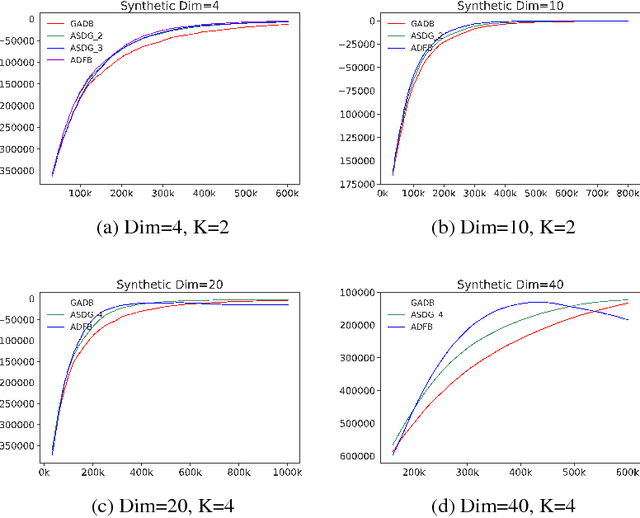
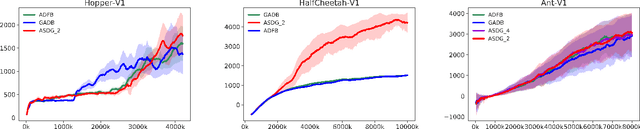
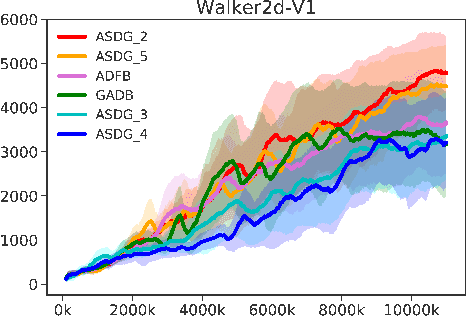
Policy optimization on high-dimensional continuous control tasks exhibits its difficulty caused by the large variance of the policy gradient estimators. We present the action subspace dependent gradient (ASDG) estimator which incorporates the Rao-Blackwell theorem (RB) and Control Variates (CV) into a unified framework to reduce the variance. To invoke RB, our proposed algorithm (POSA) learns the underlying factorization structure among the action space based on the second-order advantage information. POSA captures the quadratic information explicitly and efficiently by utilizing the wide & deep architecture. Empirical studies show that our proposed approach demonstrates the performance improvements on high-dimensional synthetic settings and OpenAI Gym's MuJoCo continuous control tasks.
Learning-Based Depth and Pose Estimation for Monocular Endoscope with Loss Generalization
Jul 28, 2021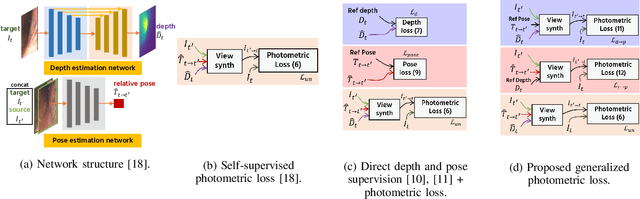
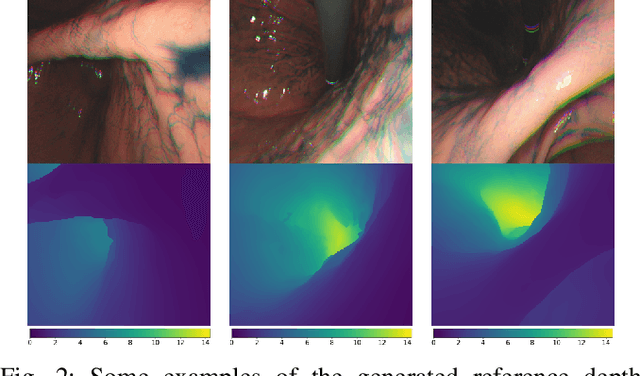
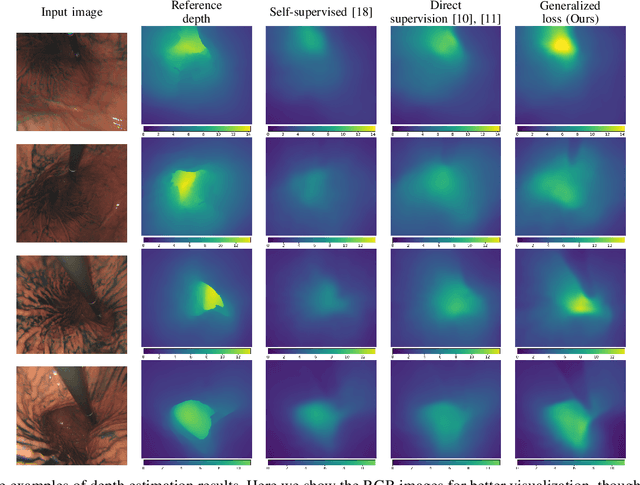
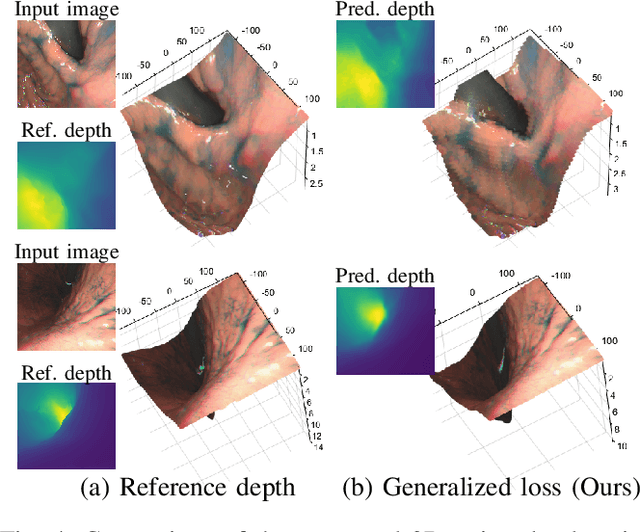
Gastroendoscopy has been a clinical standard for diagnosing and treating conditions that affect a part of a patient's digestive system, such as the stomach. Despite the fact that gastroendoscopy has a lot of advantages for patients, there exist some challenges for practitioners, such as the lack of 3D perception, including the depth and the endoscope pose information. Such challenges make navigating the endoscope and localizing any found lesion in a digestive tract difficult. To tackle these problems, deep learning-based approaches have been proposed to provide monocular gastroendoscopy with additional yet important depth and pose information. In this paper, we propose a novel supervised approach to train depth and pose estimation networks using consecutive endoscopy images to assist the endoscope navigation in the stomach. We firstly generate real depth and pose training data using our previously proposed whole stomach 3D reconstruction pipeline to avoid poor generalization ability between computer-generated (CG) models and real data for the stomach. In addition, we propose a novel generalized photometric loss function to avoid the complicated process of finding proper weights for balancing the depth and the pose loss terms, which is required for existing direct depth and pose supervision approaches. We then experimentally show that our proposed generalized loss performs better than existing direct supervision losses.
Differential Music: Automated Music Generation Using LSTM Networks with Representation Based on Melodic and Harmonic Intervals
Aug 23, 2021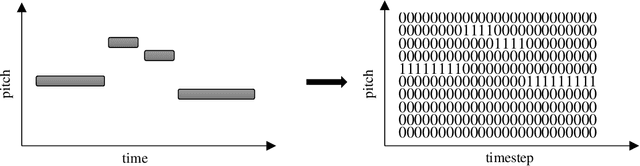

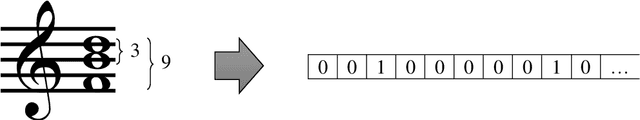
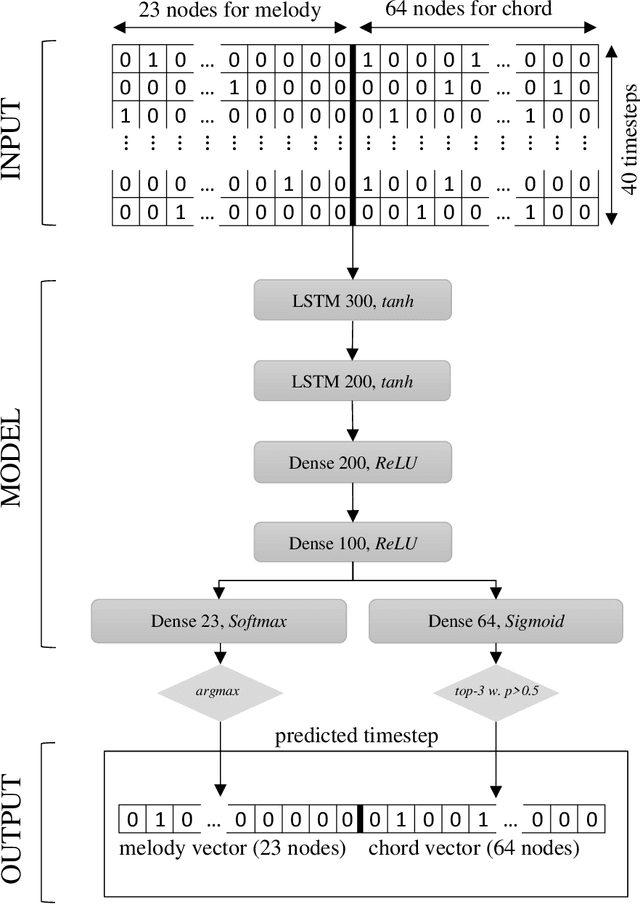
This paper presents a generative AI model for automated music composition with LSTM networks that takes a novel approach at encoding musical information which is based on movement in music rather than absolute pitch. Melodies are encoded as a series of intervals rather than a series of pitches, and chords are encoded as the set of intervals that each chord note makes with the melody at each timestep. Experimental results show promise as they sound musical and tonal. There are also weaknesses to this method, mainly excessive modulations in the compositions, but that is expected from the nature of the encoding. This issue is discussed later in the paper and is a potential topic for future work.
Quantum belief function
Jul 08, 2021
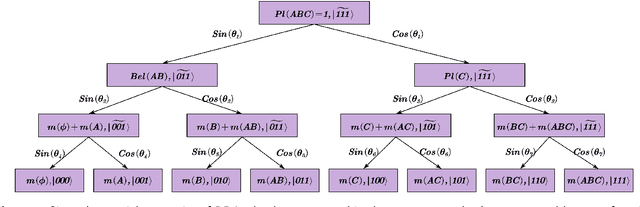

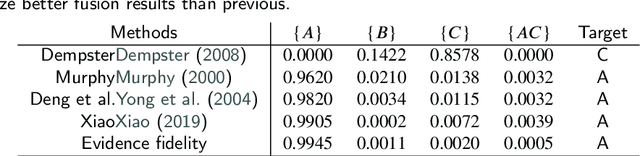
The belief function in Dempster Shafer evidence theory can express more information than the traditional Bayesian distribution. It is widely used in approximate reasoning, decision-making and information fusion. However, its power exponential explosion characteristics leads to the extremely high computational complexity when handling large amounts of elements in classic computers. In order to solve the problem, we encode the basic belief assignment (BBA) into quantum states, which makes each qubit correspond to control an element. Besides the high efficiency, this quantum expression is very conducive to measure the similarity between two BBAs, and the measuring quantum algorithm we come up with has exponential acceleration theoretically compared to the corresponding classical algorithm. In addition, we simulate our quantum version of BBA on Qiskit platform, which ensures the rationality of our algorithm experimentally. We believe our results will shed some light on utilizing the characteristic of quantum computation to handle belief function more conveniently.
Efficient Training of High-Resolution Representation Seismic Image Fault Segmentation Network by Weakening Anomaly Labels
Oct 11, 2021
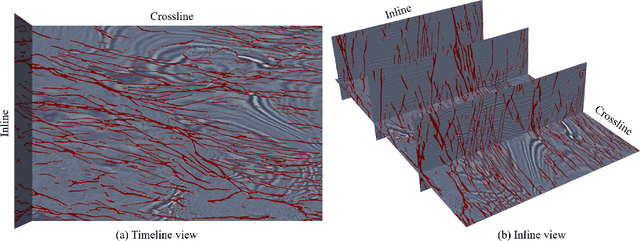


Seismic data fault detection has recently been regarded as a 3D image segmentation task. The nature of fault structures in seismic image makes it difficult to manually label faults. Manual labeling often has many false negative labels (abnormal labels), which will seriously harm the training process. In this work, we find that region-based loss significantly outperforms distribution-based loss when dealing with falsenegative labels, therefore we propose Mask Dice loss (MD loss), which is the first reported region-based loss function for training 3D image segmentation models using sparse 2D slice labels. In addition, fault is an edge feature, and the current network widely used for fault segmentation downsamples the features multiple times, which is not conducive to edge characterization and thus requires many parameters and computational effort to preserve the features. We propose Fault-Net, which always maintains the high-resolution features of seismic images, and the inference process preserves the edge information of faults and performs effective feature fusion to achieve high-quality fault segmentation with only a few parameters and computational effort. Experimental results show that MD loss can clearly weaken the effect of anomalous labels. The Fault-Net parameter is only 0.42MB, support up to 528^3(1.5x10^8, Float32) size cuboid inference on 16GB video ram, and its inference speed on CPU and GPU is significantly faster than other networks, but the result of our method is the state-of-the-art in the FORCE fault identification competition.
Graph-MLP: Node Classification without Message Passing in Graph
Jun 08, 2021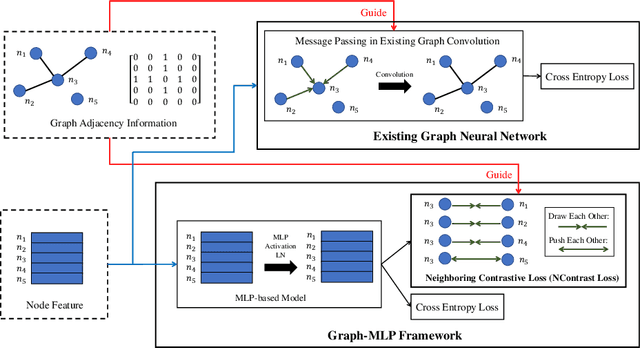
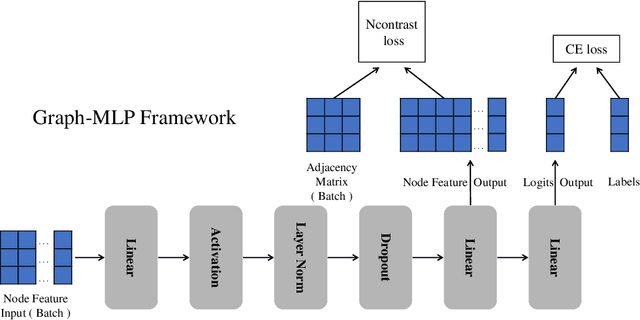
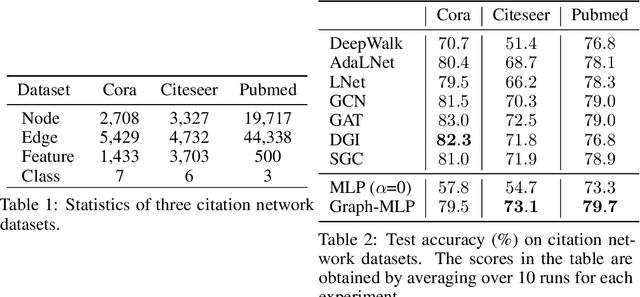
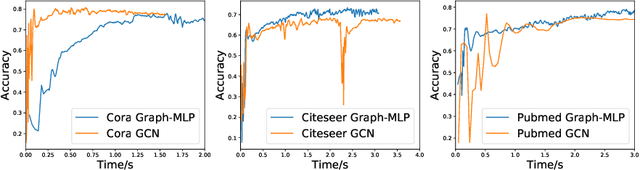
Graph Neural Network (GNN) has been demonstrated its effectiveness in dealing with non-Euclidean structural data. Both spatial-based and spectral-based GNNs are relying on adjacency matrix to guide message passing among neighbors during feature aggregation. Recent works have mainly focused on powerful message passing modules, however, in this paper, we show that none of the message passing modules is necessary. Instead, we propose a pure multilayer-perceptron-based framework, Graph-MLP with the supervision signal leveraging graph structure, which is sufficient for learning discriminative node representation. In model-level, Graph-MLP only includes multi-layer perceptrons, activation function, and layer normalization. In the loss level, we design a neighboring contrastive (NContrast) loss to bridge the gap between GNNs and MLPs by utilizing the adjacency information implicitly. This design allows our model to be lighter and more robust when facing large-scale graph data and corrupted adjacency information. Extensive experiments prove that even without adjacency information in testing phase, our framework can still reach comparable and even superior performance against the state-of-the-art models in the graph node classification task.
Neural Human Deformation Transfer
Oct 01, 2021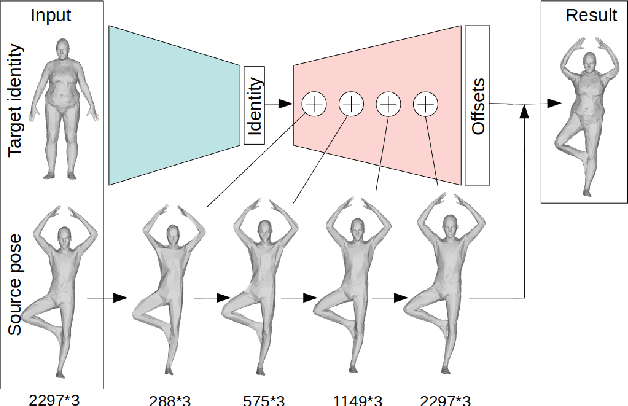

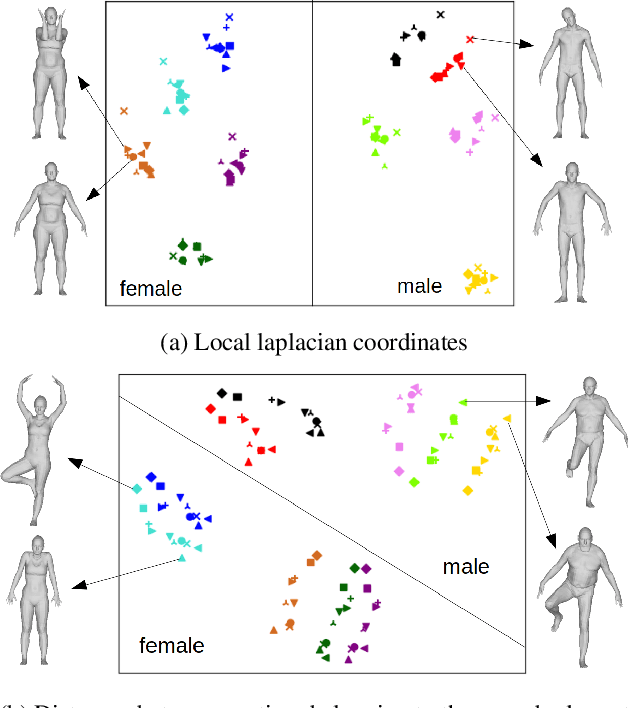
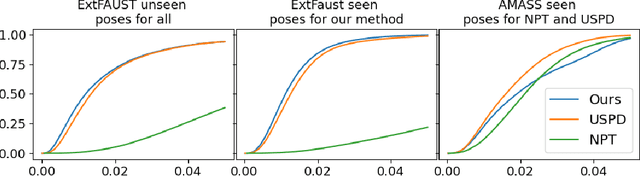
We consider the problem of human deformation transfer, where the goal is to retarget poses between different characters. Traditional methods that tackle this problem require a clear definition of the pose, and use this definition to transfer poses between characters. In this work, we take a different approach and transform the identity of a character into a new identity without modifying the character's pose. This offers the advantage of not having to define equivalences between 3D human poses, which is not straightforward as poses tend to change depending on the identity of the character performing them, and as their meaning is highly contextual. To achieve the deformation transfer, we propose a neural encoder-decoder architecture where only identity information is encoded and where the decoder is conditioned on the pose. We use pose independent representations, such as isometry-invariant shape characteristics, to represent identity features. Our model uses these features to supervise the prediction of offsets from the deformed pose to the result of the transfer. We show experimentally that our method outperforms state-of-the-art methods both quantitatively and qualitatively, and generalises better to poses not seen during training. We also introduce a fine-tuning step that allows to obtain competitive results for extreme identities, and allows to transfer simple clothing.
Integrating Unsupervised Clustering and Label-specific Oversampling to Tackle Imbalanced Multi-label Data
Sep 25, 2021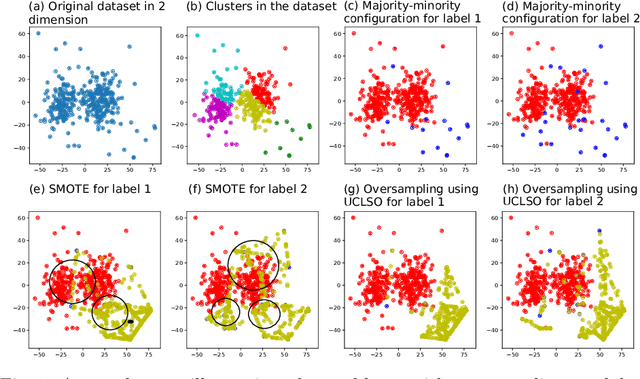
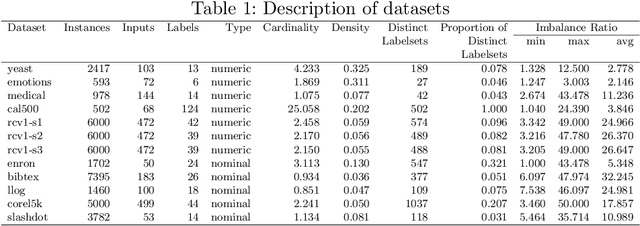
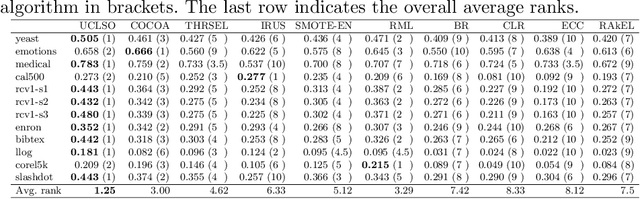
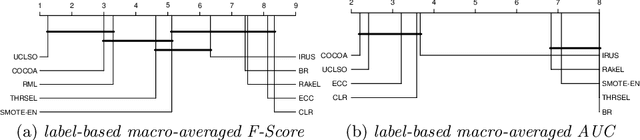
There is often a mixture of very frequent labels and very infrequent labels in multi-label datatsets. This variation in label frequency, a type class imbalance, creates a significant challenge for building efficient multi-label classification algorithms. In this paper, we tackle this problem by proposing a minority class oversampling scheme, UCLSO, which integrates Unsupervised Clustering and Label-Specific data Oversampling. Clustering is performed to find out the key distinct and locally connected regions of a multi-label dataset (irrespective of the label information). Next, for each label, we explore the distributions of minority points in the cluster sets. Only the minority points within a cluster are used to generate the synthetic minority points that are used for oversampling. Even though the cluster set is the same across all labels, the distributions of the synthetic minority points will vary across the labels. The training dataset is augmented with the set of label-specific synthetic minority points, and classifiers are trained to predict the relevance of each label independently. Experiments using 12 multi-label datasets and several multi-label algorithms show that the proposed method performed very well compared to the other competing algorithms.