 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Minimizing AoI in Resource-Constrained Multi-Source Relaying Systems with Stochastic Arrivals
Sep 10, 2021
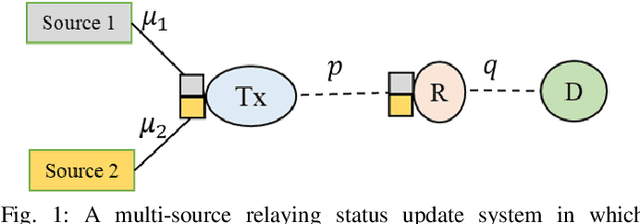
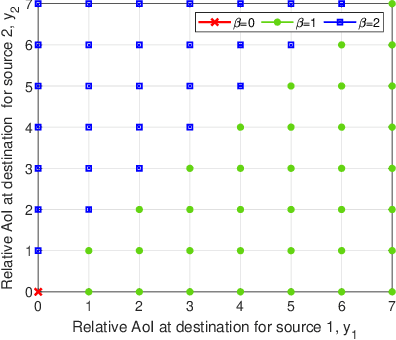
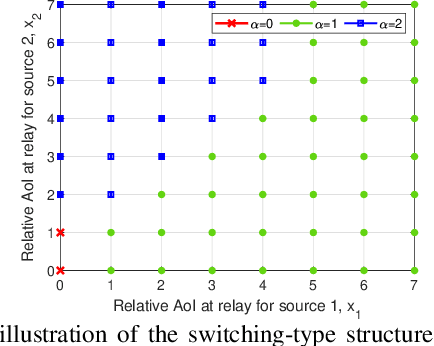
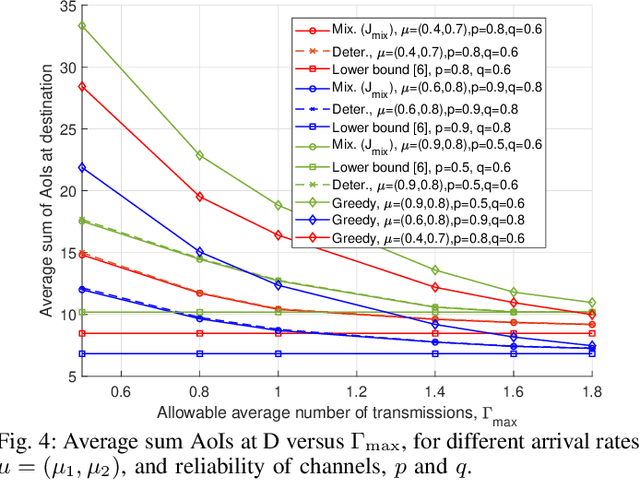
We consider a multi-source relaying system where the sources independently and randomly generate status update packets which are sent to the destination with the aid of a bufferaided relay through unreliable links. We formulate a stochastic optimization problem aiming to minimize the sum average age of information (AAoI) of sources under per-slot transmission capacity constraints and a long-run average resource constraint. To solve the problem, we recast it as a constrained Markov decision process (CMDP) problem and adopt the Lagrangian method. We analyze the structure of an optimal policy for the resulting MDP problem that possesses a switching-type structure. We propose an algorithm that obtains a stationary deterministic near-optimal policy, establishing a benchmark for the system. Simulation results show the effectiveness of our algorithm compared to benchmark algorithms.
Entropic Inequality Constraints from $e$-separation Relations in Directed Acyclic Graphs with Hidden Variables
Jul 15, 2021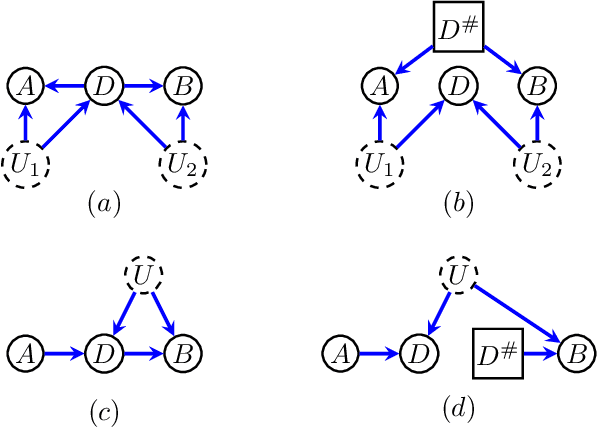
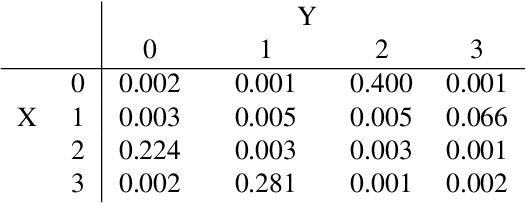
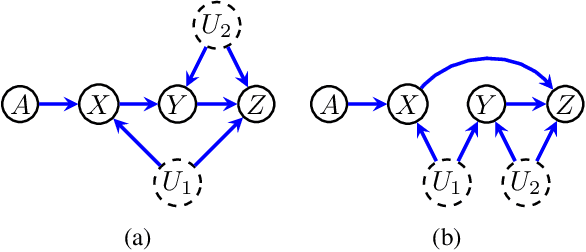
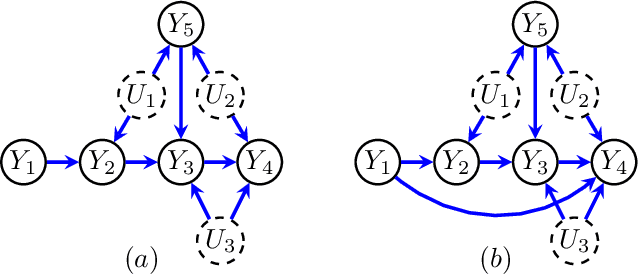
Directed acyclic graphs (DAGs) with hidden variables are often used to characterize causal relations between variables in a system. When some variables are unobserved, DAGs imply a notoriously complicated set of constraints on the distribution of observed variables. In this work, we present entropic inequality constraints that are implied by $e$-separation relations in hidden variable DAGs with discrete observed variables. The constraints can intuitively be understood to follow from the fact that the capacity of variables along a causal pathway to convey information is restricted by their entropy; e.g. at the extreme case, a variable with entropy $0$ can convey no information. We show how these constraints can be used to learn about the true causal model from an observed data distribution. In addition, we propose a measure of causal influence called the minimal mediary entropy, and demonstrate that it can augment traditional measures such as the average causal effect.
Brief View and Analysis to Latest Android Security Issues and Approaches
Sep 02, 2021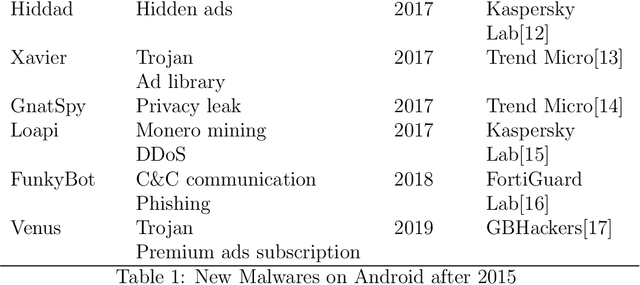
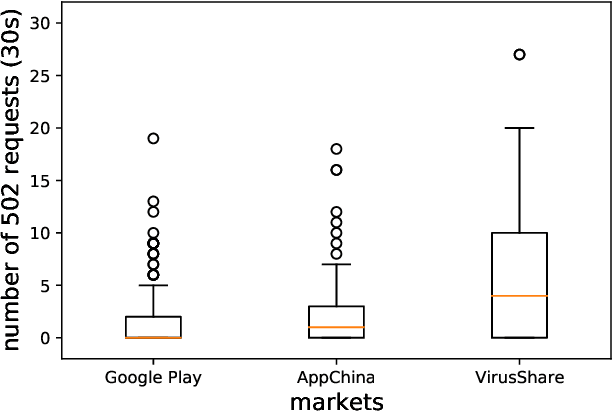
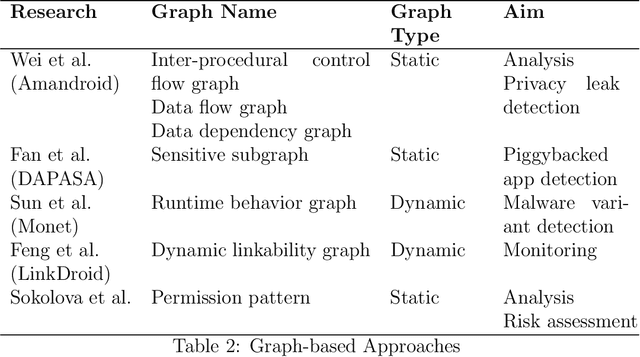
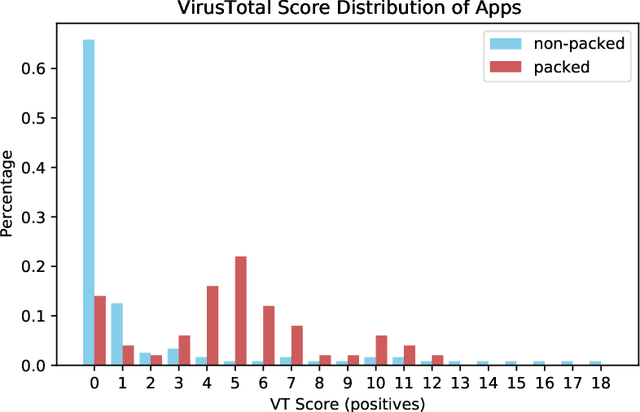
Due to the continuous improvement of performance and functions, Android remains the most popular operating system on mobile phone today. However, various malicious applications bring great threats to the system. Over the past few years, significant changes occured in both malwares and counter measures. Specifically, malwares are continuously evolving, and advanced approaches are adopted for more accurate detection. To keep up with the latest situation, in this paper, we conduct a wide range of analysis, including latest malwares, Android security features, and approaches. We also provide some finding when we are gathering information and carrying on experiments, which we think is useful for further researches and has not been mentioned in previous works.
TAG: Toward Accurate Social Media Content Tagging with a Concept Graph
Oct 24, 2021
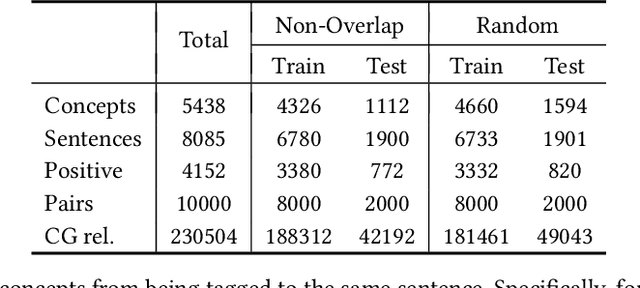

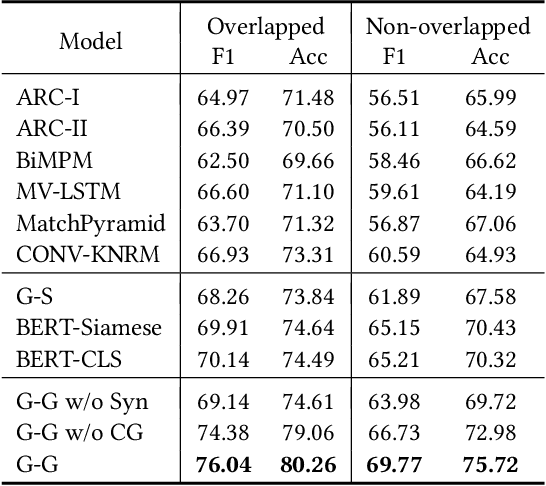
Although conceptualization has been widely studied in semantics and knowledge representation, it is still challenging to find the most accurate concept phrases to characterize the main idea of a text snippet on the fast-growing social media. This is partly attributed to the fact that most knowledge bases contain general terms of the world, such as trees and cars, which do not have the defining power or are not interesting enough to social media app users. Another reason is that the intricacy of natural language allows the use of tense, negation and grammar to change the logic or emphasis of language, thus conveying completely different meanings. In this paper, we present TAG, a high-quality concept matching dataset consisting of 10,000 labeled pairs of fine-grained concepts and web-styled natural language sentences, mined from the open-domain social media. The concepts we consider represent the trending interests of online users. Associated with TAG is a concept graph of these fine-grained concepts and entities to provide the structural context information. We evaluate a wide range of popular neural text matching models as well as pre-trained language models on TAG, and point out their insufficiency to tag social media content with the most appropriate concept. We further propose a novel graph-graph matching method that demonstrates superior abstraction and generalization performance by better utilizing both the structural context in the concept graph and logic interactions between semantic units in the sentence via syntactic dependency parsing. We open-source both the TAG dataset and the proposed methods to facilitate further research.
Bridge Networks
Jun 15, 2021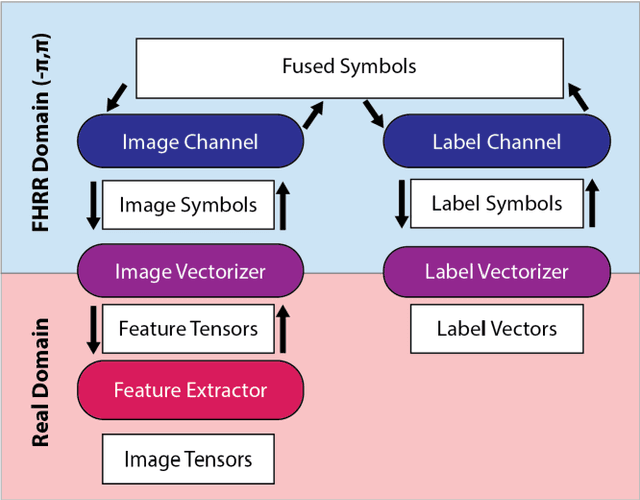
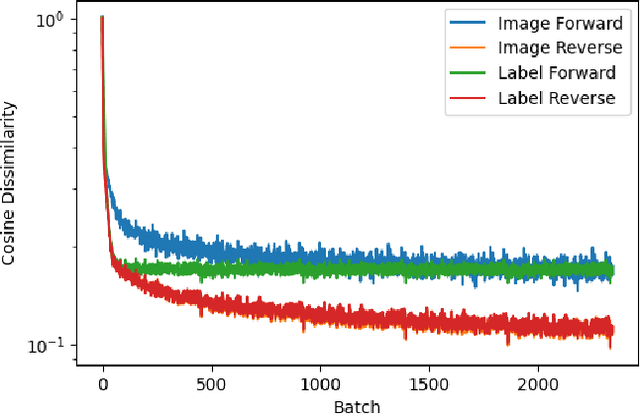
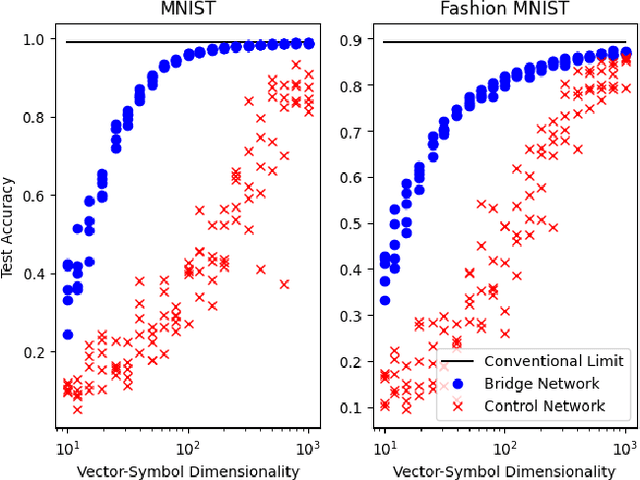
Despite rapid progress, current deep learning methods face a number of critical challenges. These include high energy consumption, catastrophic forgetting, dependance on global losses, and an inability to reason symbolically. By combining concepts from information bottleneck theory and vector-symbolic architectures, we propose and implement a novel information processing architecture, the 'Bridge network.' We show this architecture provides unique advantages which can address the problem of global losses and catastrophic forgetting. Furthermore, we argue that it provides a further basis for increasing energy efficiency of execution and the ability to reason symbolically.
Exact Expression For Information Distance
Jul 11, 2017Information distance can be defined not only between two strings but also in a finite multiset of strings of cardinality greater than two. We give an elementary proof for expressing the information distance in terms of plain Kolmogorov complexity. It is exact since for each cardinality of the multiset the lower bound for some multiset equals the upper bound for all multisets up to a constant additive term.
ChaLearn Looking at People: Inpainting and Denoising challenges
Jun 24, 2021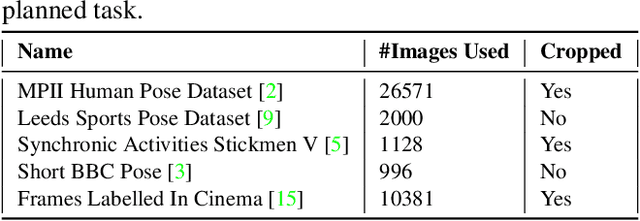
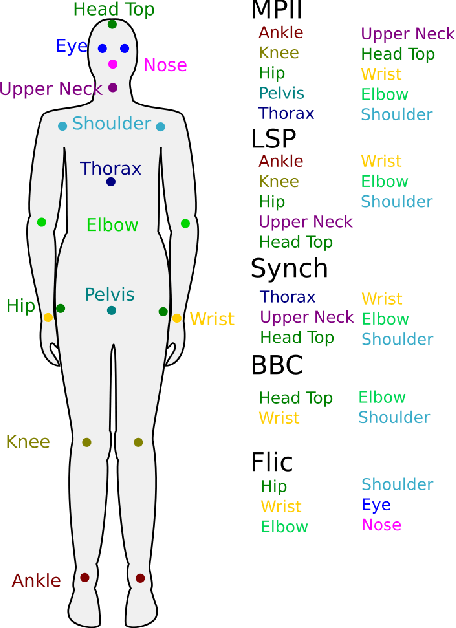

Dealing with incomplete information is a well studied problem in the context of machine learning and computational intelligence. However, in the context of computer vision, the problem has only been studied in specific scenarios (e.g., certain types of occlusions in specific types of images), although it is common to have incomplete information in visual data. This chapter describes the design of an academic competition focusing on inpainting of images and video sequences that was part of the competition program of WCCI2018 and had a satellite event collocated with ECCV2018. The ChaLearn Looking at People Inpainting Challenge aimed at advancing the state of the art on visual inpainting by promoting the development of methods for recovering missing and occluded information from images and video. Three tracks were proposed in which visual inpainting might be helpful but still challenging: human body pose estimation, text overlays removal and fingerprint denoising. This chapter describes the design of the challenge, which includes the release of three novel datasets, and the description of evaluation metrics, baselines and evaluation protocol. The results of the challenge are analyzed and discussed in detail and conclusions derived from this event are outlined.
VTAMIQ: Transformers for Attention Modulated Image Quality Assessment
Oct 04, 2021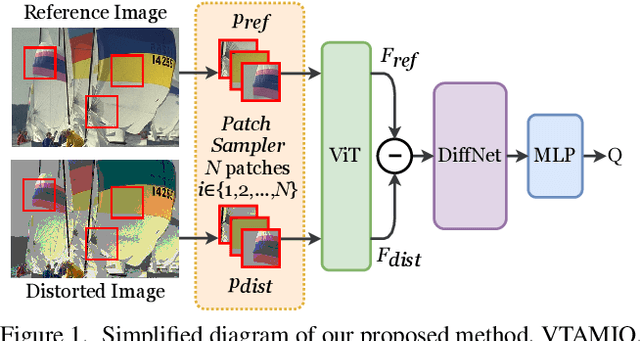
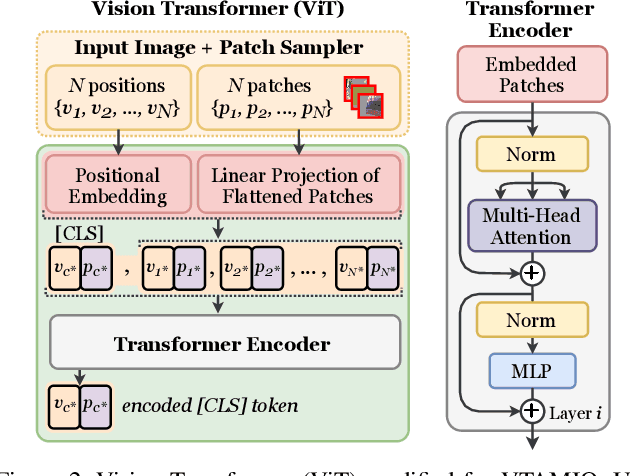
Following the major successes of self-attention and Transformers for image analysis, we investigate the use of such attention mechanisms in the context of Image Quality Assessment (IQA) and propose a novel full-reference IQA method, Vision Transformer for Attention Modulated Image Quality (VTAMIQ). Our method achieves competitive or state-of-the-art performance on the existing IQA datasets and significantly outperforms previous metrics in cross-database evaluations. Most patch-wise IQA methods treat each patch independently; this partially discards global information and limits the ability to model long-distance interactions. We avoid this problem altogether by employing a transformer to encode a sequence of patches as a single global representation, which by design considers interdependencies between patches. We rely on various attention mechanisms -- first with self-attention within the Transformer, and second with channel attention within our difference modulation network -- specifically to reveal and enhance the more salient features throughout our architecture. With large-scale pre-training for both classification and IQA tasks, VTAMIQ generalizes well to unseen sets of images and distortions, further demonstrating the strength of transformer-based networks for vision modelling.
Extracting Fine-Grained Knowledge Graphs of Scientific Claims: Dataset and Transformer-Based Results
Sep 21, 2021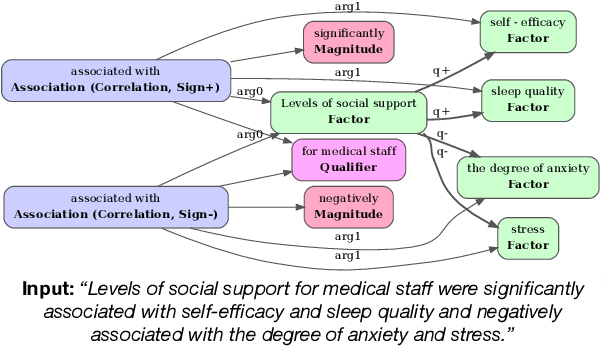
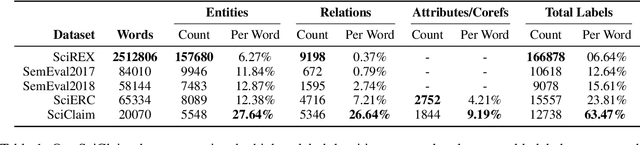
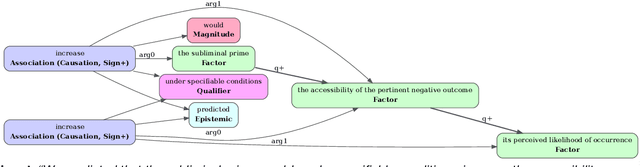
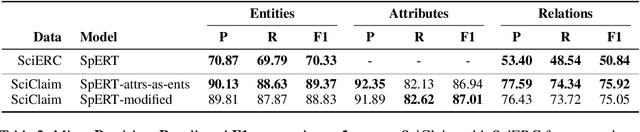
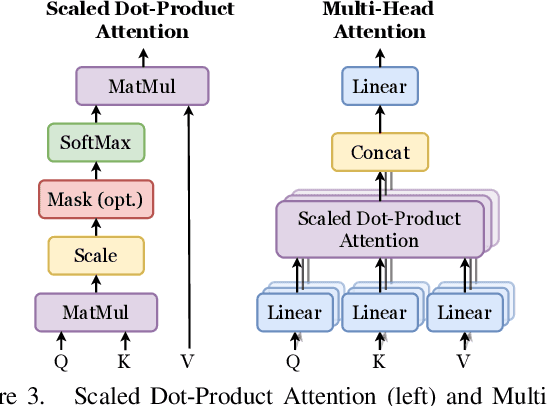
Recent transformer-based approaches demonstrate promising results on relational scientific information extraction. Existing datasets focus on high-level description of how research is carried out. Instead we focus on the subtleties of how experimental associations are presented by building SciClaim, a dataset of scientific claims drawn from Social and Behavior Science (SBS), PubMed, and CORD-19 papers. Our novel graph annotation schema incorporates not only coarse-grained entity spans as nodes and relations as edges between them, but also fine-grained attributes that modify entities and their relations, for a total of 12,738 labels in the corpus. By including more label types and more than twice the label density of previous datasets, SciClaim captures causal, comparative, predictive, statistical, and proportional associations over experimental variables along with their qualifications, subtypes, and evidence. We extend work in transformer-based joint entity and relation extraction to effectively infer our schema, showing the promise of fine-grained knowledge graphs in scientific claims and beyond.
Towards Theme Detection in Personal Finance Questions
Oct 04, 2021
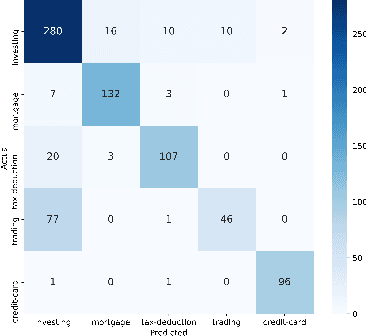
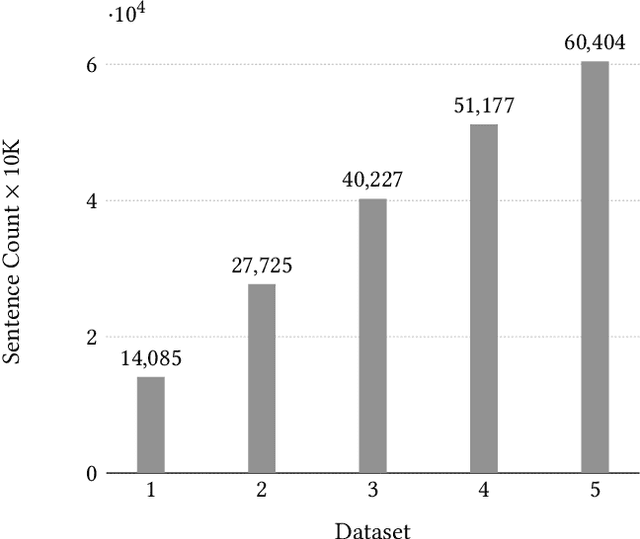
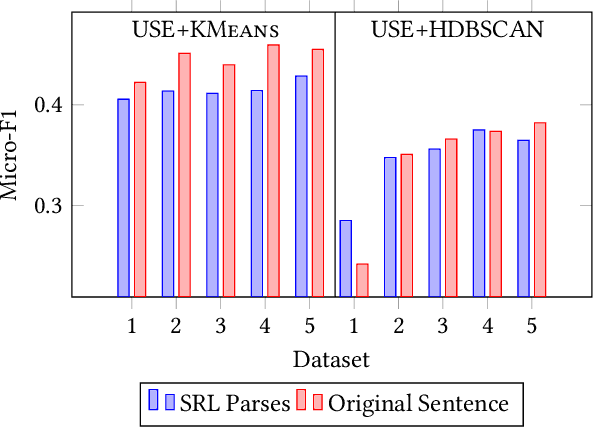
Banking call centers receive millions of calls annually, with much of the information in these calls unavailable to analysts interested in tracking new and emerging call center trends. In this study we present an approach to call center theme detection that captures the occurrence of multiple themes in a question, using a publicly available corpus of StackExchange personal finance questions, labeled by users with topic tags, as a testbed. To capture the occurrence of multiple themes in a single question, the approach encodes and clusters at the sentence- rather than question-level. We also present a comparison of state-of-the-art sentence encoding models, including the SBERT family of sentence encoders. We frame our evaluation as a multiclass classification task and show that a simple combination of the original sentence text, Universal Sentence Encoder, and KMeans outperforms more sophisticated techniques that involve semantic parsing, SBERT-family models, and HDBSCAN. Our highest performing approach achieves a Micro-F1 of 0.46 for this task and we show that the resulting clusters, even when slightly noisy, contain sentences that are topically consistent with the label associated with the cluster.