 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Disentangling Online Chats with DAG-Structured LSTMs
Jun 16, 2021

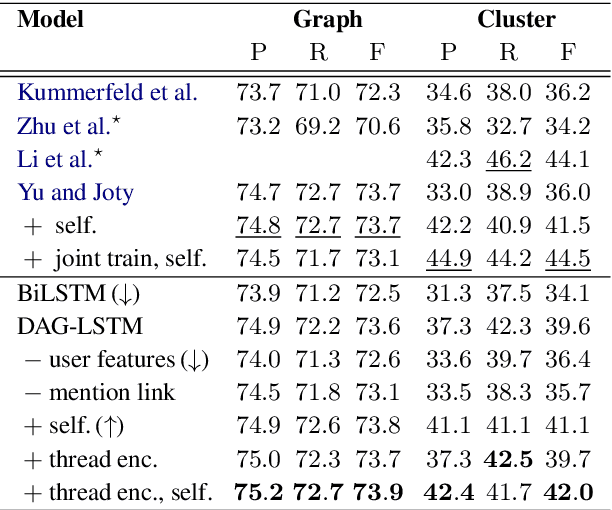
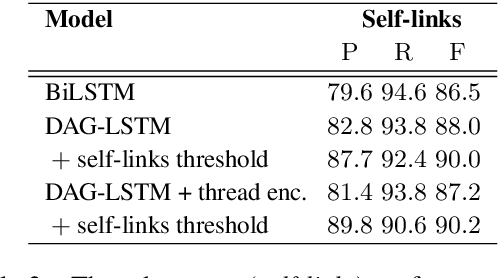

Many modern messaging systems allow fast and synchronous textual communication among many users. The resulting sequence of messages hides a more complicated structure in which independent sub-conversations are interwoven with one another. This poses a challenge for any task aiming to understand the content of the chat logs or gather information from them. The ability to disentangle these conversations is then tantamount to the success of many downstream tasks such as summarization and question answering. Structured information accompanying the text such as user turn, user mentions, timestamps, is used as a cue by the participants themselves who need to follow the conversation and has been shown to be important for disentanglement. DAG-LSTMs, a generalization of Tree-LSTMs that can handle directed acyclic dependencies, are a natural way to incorporate such information and its non-sequential nature. In this paper, we apply DAG-LSTMs to the conversation disentanglement task. We perform our experiments on the Ubuntu IRC dataset. We show that the novel model we propose achieves state of the art status on the task of recovering reply-to relations and it is competitive on other disentanglement metrics.
Edge-similarity-aware Graph Neural Networks
Sep 20, 2021
Graph are a ubiquitous data representation, as they represent a flexible and compact representation. For instance, the 3D structure of RNA can be efficiently represented as $\textit{2.5D graphs}$, graphs whose nodes are nucleotides and edges represent chemical interactions. In this setting, we have biological evidence of the similarity between the edge types, as some chemical interactions are more similar than others. Machine learning on graphs have recently experienced a breakthrough with the introduction of Graph Neural Networks. This algorithm can be framed as a message passing algorithm between graph nodes over graph edges. These messages can depend on the edge type they are transmitted through, but no method currently constrains how a message is altered when the edge type changes. Motivated by the RNA use case, in this project we introduce a graph neural network layer which can leverage prior information about similarities between edges. We show that despite the theoretical appeal of including this similarity prior, the empirical performance is not enhanced on the tasks and datasets we include here.
Frequency Disentangled Residual Network
Sep 26, 2021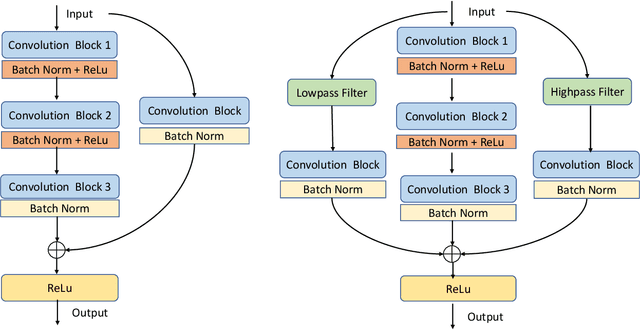
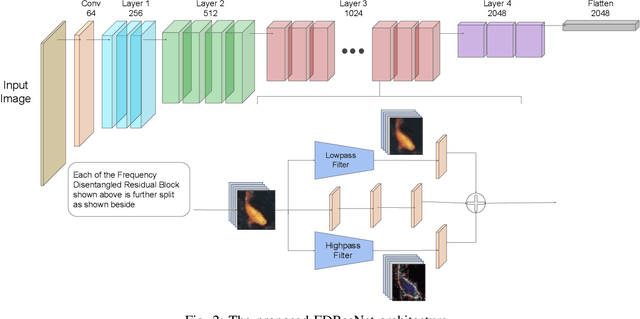

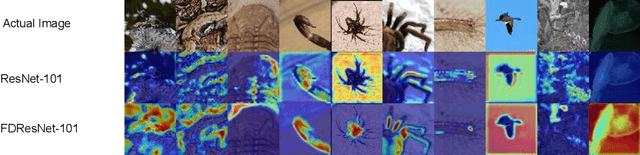
Residual networks (ResNets) have been utilized for various computer vision and image processing applications. The residual connection improves the training of the network with better gradient flow. A residual block consists of few convolutional layers having trainable parameters, which leads to overfitting. Moreover, the present residual networks are not able to utilize the high and low frequency information suitably, which also challenges the generalization capability of the network. In this paper, a frequency disentangled residual network (FDResNet) is proposed to tackle these issues. Specifically, FDResNet includes separate connections in the residual block for low and high frequency components, respectively. Basically, the proposed model disentangles the low and high frequency components to increase the generalization ability. Moreover, the computation of low and high frequency components using fixed filters further avoids the overfitting. The proposed model is tested on benchmark CIFAR10/100, Caltech and TinyImageNet datasets for image classification. The performance of the proposed model is also tested in image retrieval framework. It is noticed that the proposed model outperforms its counterpart residual model. The effect of kernel size and standard deviation is also evaluated. The impact of the frequency disentangling is also analyzed using saliency map.
Learning to Navigate from Simulation via Spatial and Semantic Information Synthesis with Noise Model Embedding
Nov 12, 2019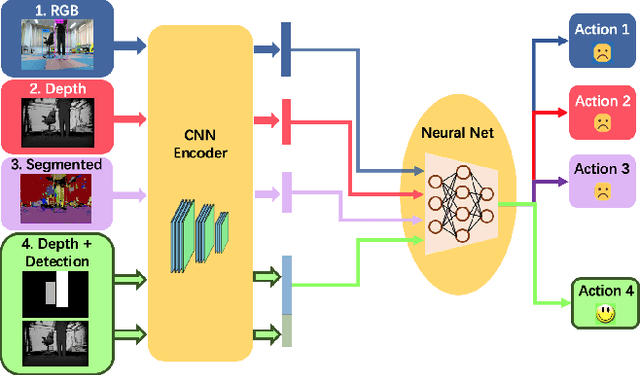
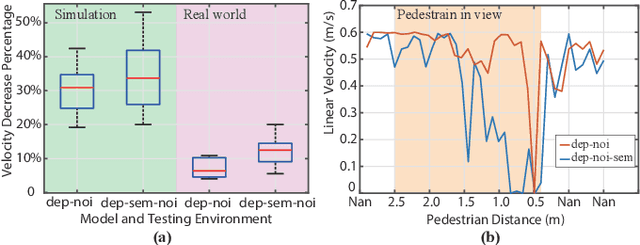

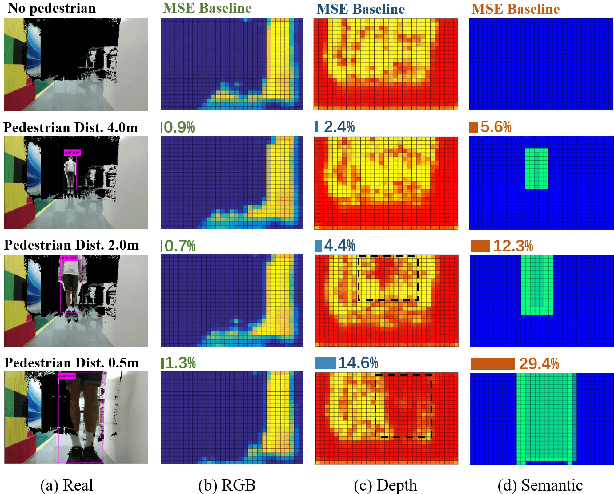
While training an end-to-end navigation network in the real world is usually of high cost, simulation provides a safe and cheap environment in this training stage. However, training neural network models in simulation brings up the problem of how to effectively transfer the model from simulation to the real world (sim-to-real). In this work, we regard the environment representation as a crucial element in this transfer process and propose a visual information pyramid (VIP) model to systematically investigate a practical environment representation. A novel representation composed of spatial and semantic information synthesis is then established accordingly, where noise model embedding is particularly considered. To explore the effectiveness of this representation, we compared the performance with representations popularly used in the literature in both simulated and real-world scenarios. Results suggest that our environment representation stands out. Furthermore, an analysis on the feature map is implemented to investigate the effectiveness through inner reaction, which could be irradiative for future researches on end-to-end navigation.
A Shadowcasting-Based Next-Best-View Planner for Autonomous 3D Exploration
Sep 20, 2021
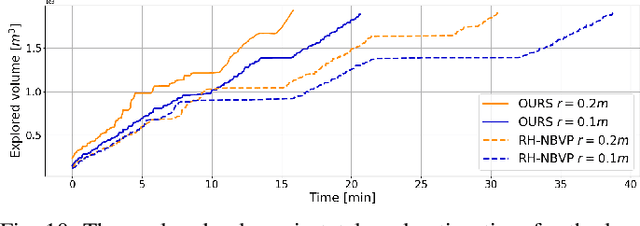
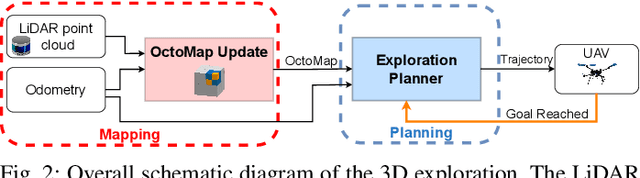
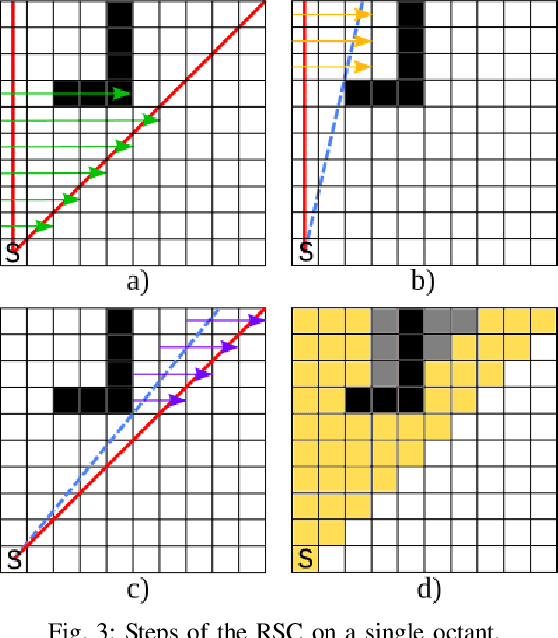
In this paper, we address the problem of autonomous exploration of unknown environments with an aerial robot equipped with a sensory set that produces large point clouds, such as LiDARs. The main goal is to gradually explore an area while planning paths and calculating information gain in short computation time, suitable for implementation on an on-board computer. To this end, we present a planner that randomly samples viewpoints in the environment map. It relies on a novel and efficient gain calculation based on the Recursive Shadowcasting algorithm. To determine the Next-Best-View (NBV), our planner uses a cuboid-based evaluation method that results in an enviably short computation time. To reduce the overall exploration time, we also use a dead end resolving strategy that allows us to quickly recover from dead ends in a challenging environment. Comparative experiments in simulation have shown that our approach outperforms the current state-of-the-art in terms of computational efficiency and total exploration time. The video of our approach can be found at https://www.youtube.com/playlist?list=PLC0C6uwoEQ8ZDhny1VdmFXLeTQOSBibQl.
Question-controlled Text-aware Image Captioning
Aug 04, 2021

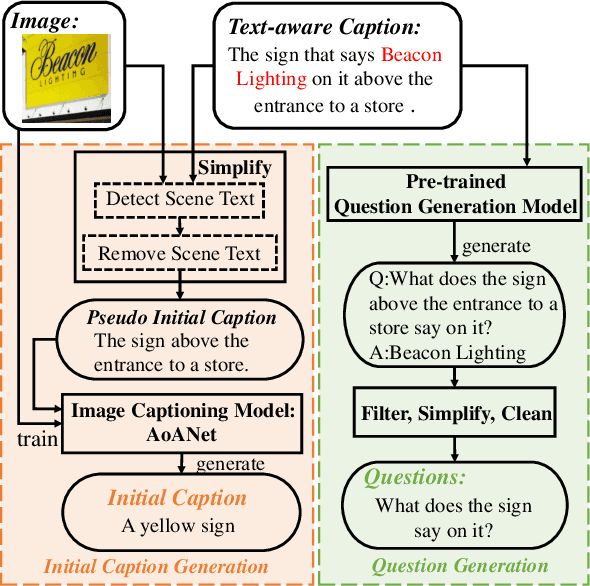
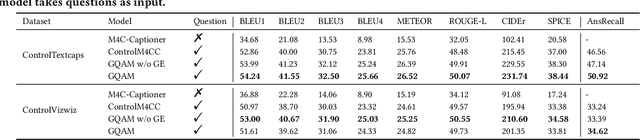
For an image with multiple scene texts, different people may be interested in different text information. Current text-aware image captioning models are not able to generate distinctive captions according to various information needs. To explore how to generate personalized text-aware captions, we define a new challenging task, namely Question-controlled Text-aware Image Captioning (Qc-TextCap). With questions as control signals, this task requires models to understand questions, find related scene texts and describe them together with objects fluently in human language. Based on two existing text-aware captioning datasets, we automatically construct two datasets, ControlTextCaps and ControlVizWiz to support the task. We propose a novel Geometry and Question Aware Model (GQAM). GQAM first applies a Geometry-informed Visual Encoder to fuse region-level object features and region-level scene text features with considering spatial relationships. Then, we design a Question-guided Encoder to select the most relevant visual features for each question. Finally, GQAM generates a personalized text-aware caption with a Multimodal Decoder. Our model achieves better captioning performance and question answering ability than carefully designed baselines on both two datasets. With questions as control signals, our model generates more informative and diverse captions than the state-of-the-art text-aware captioning model. Our code and datasets are publicly available at https://github.com/HAWLYQ/Qc-TextCap.
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
Aug 04, 2021
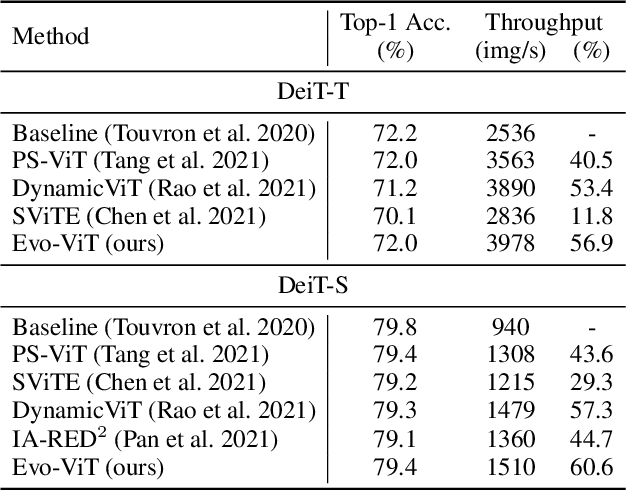

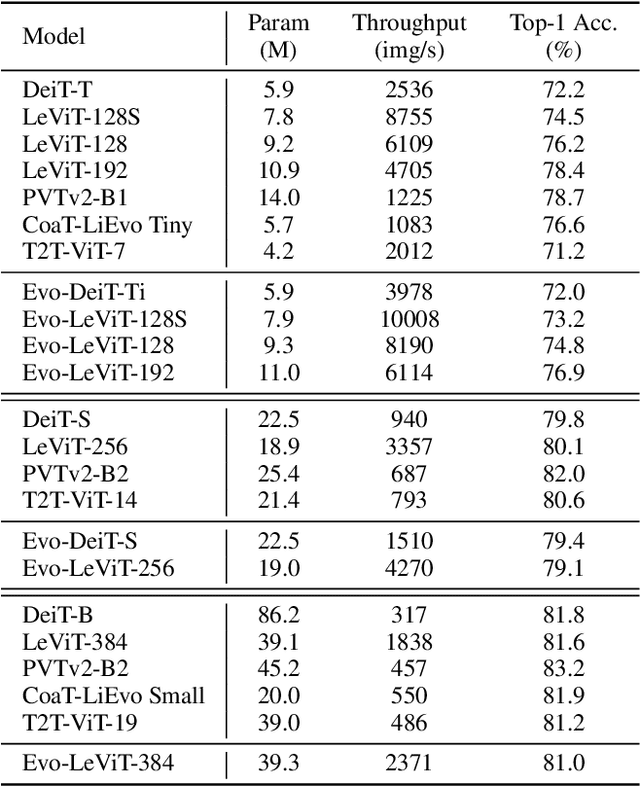
Vision transformers have recently received explosive popularity, but the huge computational cost is still a severe issue. Recent efficient designs for vision transformers follow two pipelines, namely, structural compression based on local spatial prior and non-structural token pruning. However, token pruning breaks the spatial structure that is indispensable for local spatial prior. To take advantage of both two pipelines, this work seeks to dynamically identify uninformative tokens for each instance and trim down both the training and inference complexity while maintaining complete spatial structure and information flow. To achieve this goal, we propose Evo-ViT, a self-motivated slow-fast token evolution method for vision transformers. Specifically, we conduct unstructured instance-wise token selection by taking advantage of the global class attention that is unique to vision transformers. Then, we propose to update informative tokens and placeholder tokens that contribute little to the final prediction with different computational priorities, namely, slow-fast updating. Thanks to the slow-fast updating mechanism that guarantees information flow and spatial structure, our Evo-ViT can accelerate vanilla transformers of both flat and deep-narrow structures from the very beginning of the training process. Experimental results demonstrate that the proposed method can significantly reduce the computational costs of vision transformers while maintaining comparable performance on image classification. For example, our method accelerates DeiTS by over 60% throughput while only sacrificing 0.4% top-1 accuracy.
CTRL-C: Camera calibration TRansformer with Line-Classification
Sep 06, 2021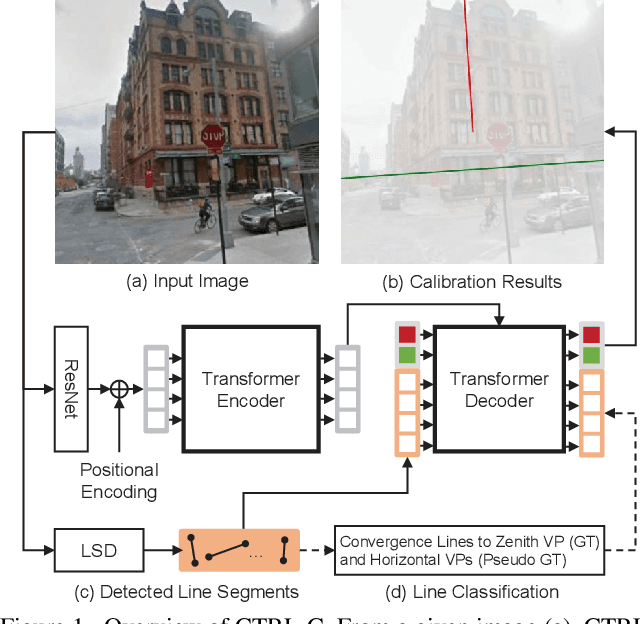
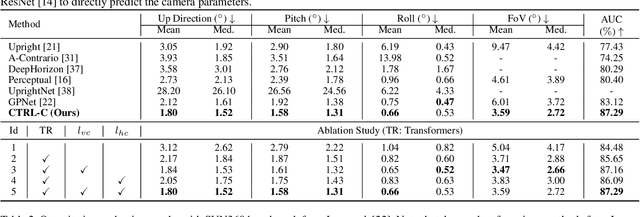
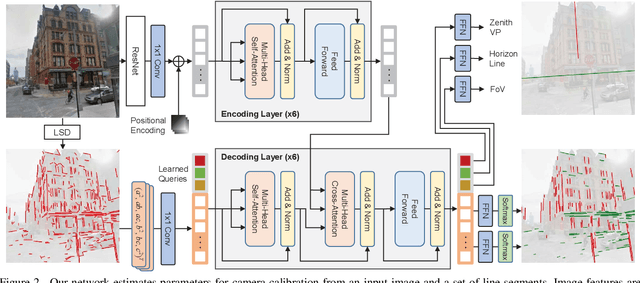
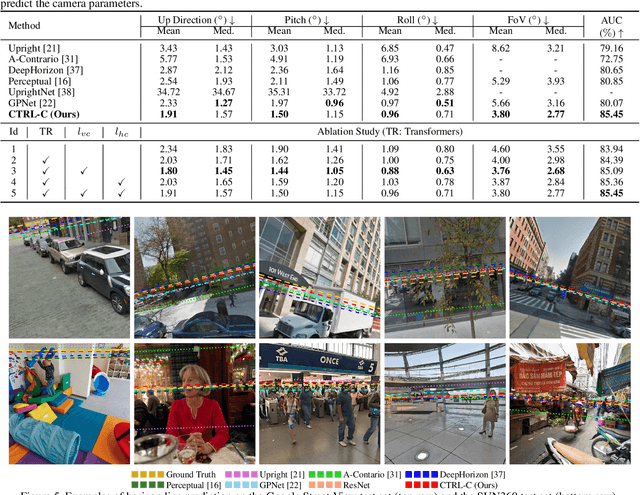
Single image camera calibration is the task of estimating the camera parameters from a single input image, such as the vanishing points, focal length, and horizon line. In this work, we propose Camera calibration TRansformer with Line-Classification (CTRL-C), an end-to-end neural network-based approach to single image camera calibration, which directly estimates the camera parameters from an image and a set of line segments. Our network adopts the transformer architecture to capture the global structure of an image with multi-modal inputs in an end-to-end manner. We also propose an auxiliary task of line classification to train the network to extract the global geometric information from lines effectively. Our experiments demonstrate that CTRL-C outperforms the previous state-of-the-art methods on the Google Street View and SUN360 benchmark datasets.
An information-geometric approach to feature extraction and moment reconstruction in dynamical systems
Apr 05, 2020
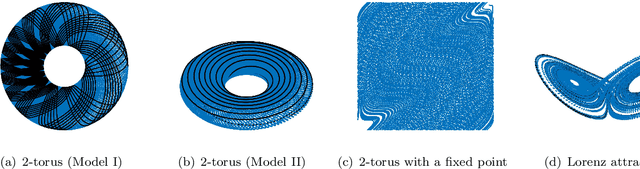
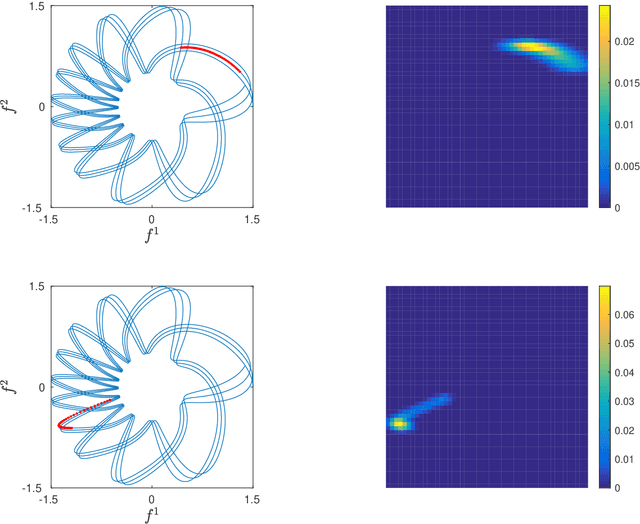
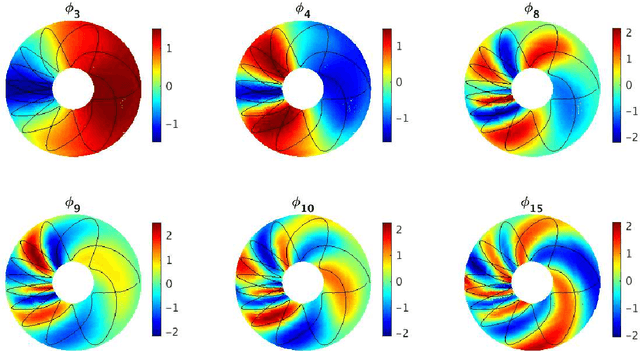
We propose a dimension reduction framework for feature extraction and moment reconstruction in dynamical systems that operates on spaces of probability measures induced by observables of the system rather than directly in the original data space of the observables themselves as in more conventional methods. Our approach is based on the fact that orbits of a dynamical system induce probability measures over the measurable space defined by (partial) observations of the system. We equip the space of these probability measures with a divergence, i.e., a distance between probability distributions, and use this divergence to define a kernel integral operator. The eigenfunctions of this operator create an orthonormal basis of functions that capture different timescales of the dynamical system. One of our main results shows that the evolution of the moments of the dynamics-dependent probability measures can be related to a time-averaging operator on the original dynamical system. Using this result, we show that the moments can be expanded in the eigenfunction basis, thus opening up the avenue for nonparametric forecasting of the moments. If the collection of probability measures is itself a manifold, we can in addition equip the statistical manifold with the Riemannian metric and use techniques from information geometry. We present applications to ergodic dynamical systems on the 2-torus and the Lorenz 63 system, and show on a real-world example that a small number of eigenvectors is sufficient to reconstruct the moments (here the first four moments) of an atmospheric time series, i.e., the realtime multivariate Madden-Julian oscillation index.
A First-Occupancy Representation for Reinforcement Learning
Oct 06, 2021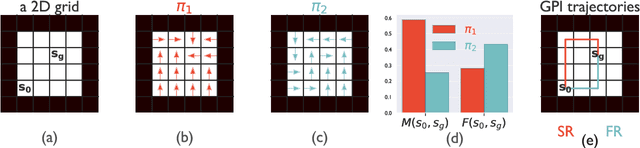
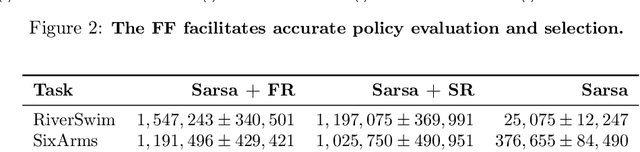
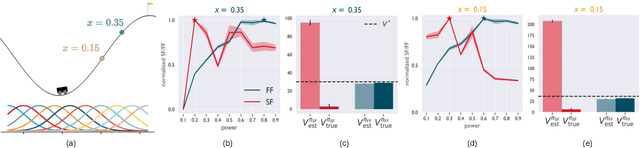
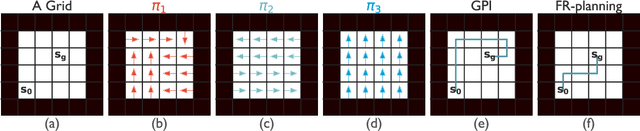
Both animals and artificial agents benefit from state representations that support rapid transfer of learning across tasks and which enable them to efficiently traverse their environments to reach rewarding states. The successor representation (SR), which measures the expected cumulative, discounted state occupancy under a fixed policy, enables efficient transfer to different reward structures in an otherwise constant Markovian environment and has been hypothesized to underlie aspects of biological behavior and neural activity. However, in the real world, rewards may move or only be available for consumption once, may shift location, or agents may simply aim to reach goal states as rapidly as possible without the constraint of artificially imposed task horizons. In such cases, the most behaviorally-relevant representation would carry information about when the agent was likely to first reach states of interest, rather than how often it should expect to visit them over a potentially infinite time span. To reflect such demands, we introduce the first-occupancy representation (FR), which measures the expected temporal discount to the first time a state is accessed. We demonstrate that the FR facilitates exploration, the selection of efficient paths to desired states, allows the agent, under certain conditions, to plan provably optimal trajectories defined by a sequence of subgoals, and induces similar behavior to animals avoiding threatening stimuli.