 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Fully Attention-Based Information Retriever
Oct 22, 2018
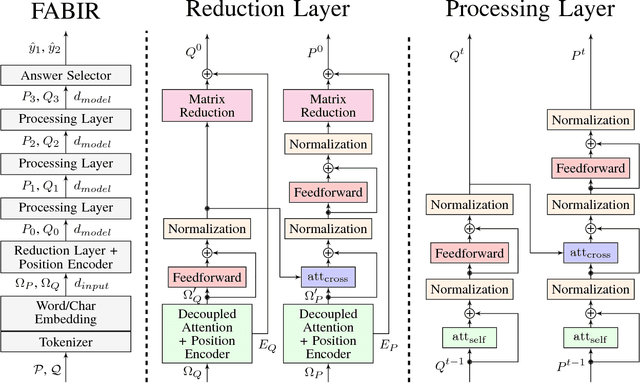
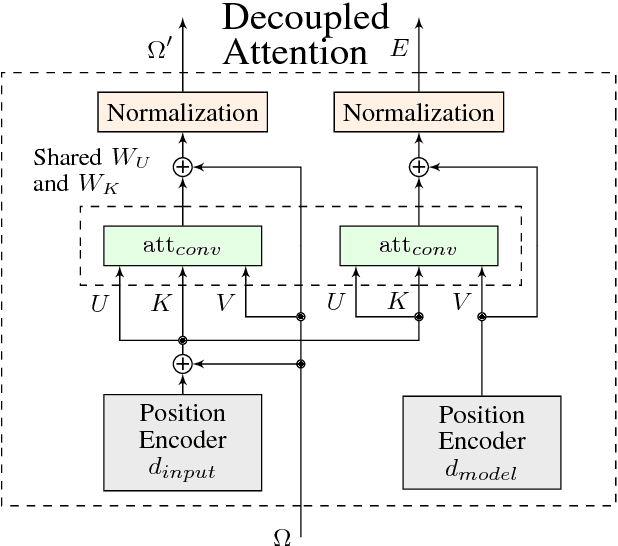
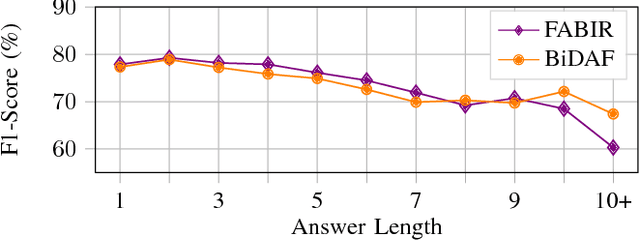
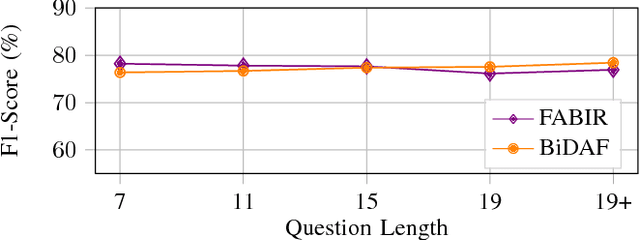
Recurrent neural networks are now the state-of-the-art in natural language processing because they can build rich contextual representations and process texts of arbitrary length. However, recent developments on attention mechanisms have equipped feedforward networks with similar capabilities, hence enabling faster computations due to the increase in the number of operations that can be parallelized. We explore this new type of architecture in the domain of question-answering and propose a novel approach that we call Fully Attention Based Information Retriever (FABIR). We show that FABIR achieves competitive results in the Stanford Question Answering Dataset (SQuAD) while having fewer parameters and being faster at both learning and inference than rival methods.
* Accepted for presentation at the International Joint Conference on Neural Networks (IJCNN) 2018
StructuralLM: Structural Pre-training for Form Understanding
May 24, 2021
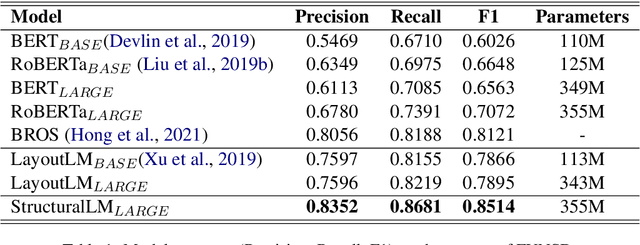
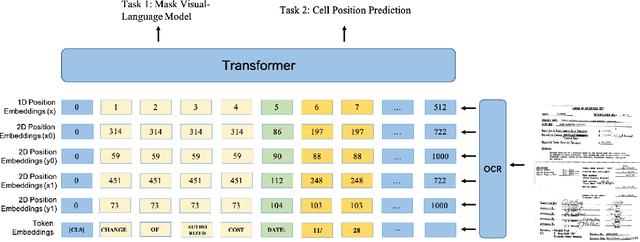
Large pre-trained language models achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, they almost exclusively focus on text-only representation, while neglecting cell-level layout information that is important for form image understanding. In this paper, we propose a new pre-training approach, StructuralLM, to jointly leverage cell and layout information from scanned documents. Specifically, we pre-train StructuralLM with two new designs to make the most of the interactions of cell and layout information: 1) each cell as a semantic unit; 2) classification of cell positions. The pre-trained StructuralLM achieves new state-of-the-art results in different types of downstream tasks, including form understanding (from 78.95 to 85.14), document visual question answering (from 72.59 to 83.94) and document image classification (from 94.43 to 96.08).
Global Rhythm Style Transfer Without Text Transcriptions
Jun 16, 2021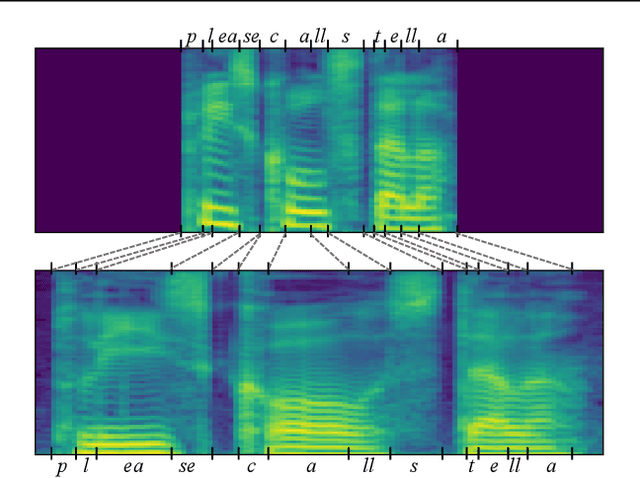
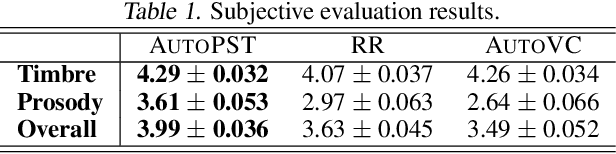

Prosody plays an important role in characterizing the style of a speaker or an emotion, but most non-parallel voice or emotion style transfer algorithms do not convert any prosody information. Two major components of prosody are pitch and rhythm. Disentangling the prosody information, particularly the rhythm component, from the speech is challenging because it involves breaking the synchrony between the input speech and the disentangled speech representation. As a result, most existing prosody style transfer algorithms would need to rely on some form of text transcriptions to identify the content information, which confines their application to high-resource languages only. Recently, SpeechSplit has made sizeable progress towards unsupervised prosody style transfer, but it is unable to extract high-level global prosody style in an unsupervised manner. In this paper, we propose AutoPST, which can disentangle global prosody style from speech without relying on any text transcriptions. AutoPST is an Autoencoder-based Prosody Style Transfer framework with a thorough rhythm removal module guided by the self-expressive representation learning. Experiments on different style transfer tasks show that AutoPST can effectively convert prosody that correctly reflects the styles of the target domains.
Boundary-aware Transformers for Skin Lesion Segmentation
Oct 08, 2021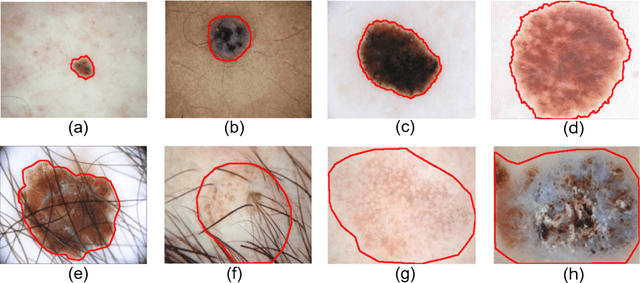
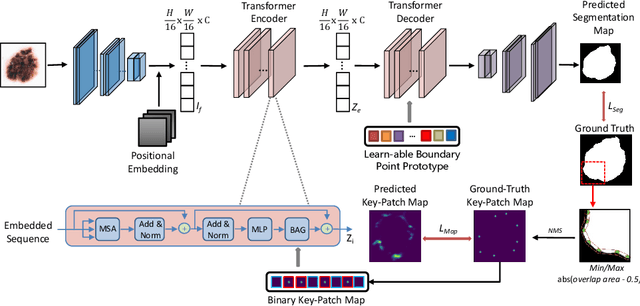
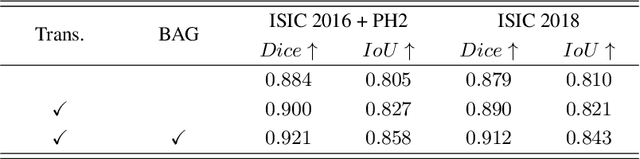
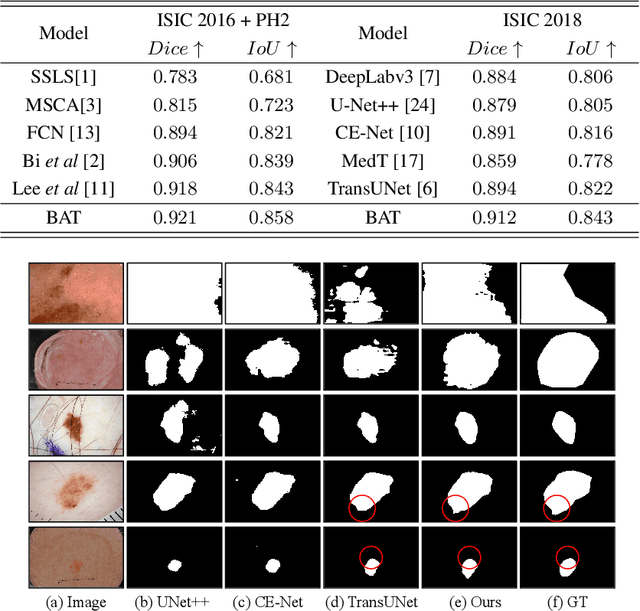
Skin lesion segmentation from dermoscopy images is of great importance for improving the quantitative analysis of skin cancer. However, the automatic segmentation of melanoma is a very challenging task owing to the large variation of melanoma and ambiguous boundaries of lesion areas. While convolutional neutral networks (CNNs) have achieved remarkable progress in this task, most of existing solutions are still incapable of effectively capturing global dependencies to counteract the inductive bias caused by limited receptive fields. Recently, transformers have been proposed as a promising tool for global context modeling by employing a powerful global attention mechanism, but one of their main shortcomings when applied to segmentation tasks is that they cannot effectively extract sufficient local details to tackle ambiguous boundaries. We propose a novel boundary-aware transformer (BAT) to comprehensively address the challenges of automatic skin lesion segmentation. Specifically, we integrate a new boundary-wise attention gate (BAG) into transformers to enable the whole network to not only effectively model global long-range dependencies via transformers but also, simultaneously, capture more local details by making full use of boundary-wise prior knowledge. Particularly, the auxiliary supervision of BAG is capable of assisting transformers to learn position embedding as it provides much spatial information. We conducted extensive experiments to evaluate the proposed BAT and experiments corroborate its effectiveness, consistently outperforming state-of-the-art methods in two famous datasets.
Tribrid: Stance Classification with Neural Inconsistency Detection
Sep 14, 2021
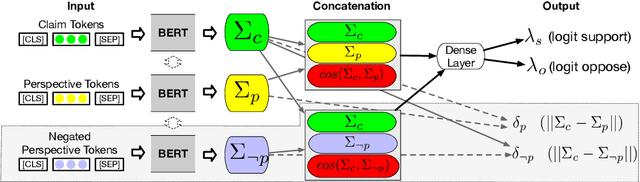
We study the problem of performing automatic stance classification on social media with neural architectures such as BERT. Although these architectures deliver impressive results, their level is not yet comparable to the one of humans and they might produce errors that have a significant impact on the downstream task (e.g., fact-checking). To improve the performance, we present a new neural architecture where the input also includes automatically generated negated perspectives over a given claim. The model is jointly learned to make simultaneously multiple predictions, which can be used either to improve the classification of the original perspective or to filter out doubtful predictions. In the first case, we propose a weakly supervised method for combining the predictions into a final one. In the second case, we show that using the confidence scores to remove doubtful predictions allows our method to achieve human-like performance over the retained information, which is still a sizable part of the original input.
Instance-wise Graph-based Framework for Multivariate Time Series Forecasting
Sep 14, 2021
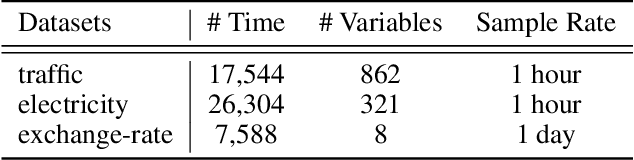
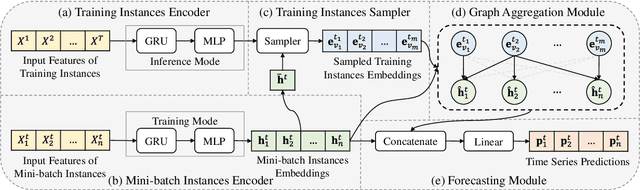
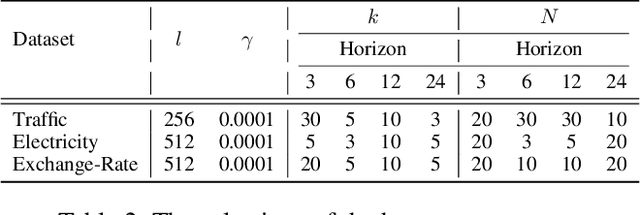
The multivariate time series forecasting has attracted more and more attention because of its vital role in different fields in the real world, such as finance, traffic, and weather. In recent years, many research efforts have been proposed for forecasting multivariate time series. Although some previous work considers the interdependencies among different variables in the same timestamp, existing work overlooks the inter-connections between different variables at different time stamps. In this paper, we propose a simple yet efficient instance-wise graph-based framework to utilize the inter-dependencies of different variables at different time stamps for multivariate time series forecasting. The key idea of our framework is aggregating information from the historical time series of different variables to the current time series that we need to forecast. We conduct experiments on the Traffic, Electricity, and Exchange-Rate multivariate time series datasets. The results show that our proposed model outperforms the state-of-the-art baseline methods.
3D Meta-Segmentation Neural Network
Oct 08, 2021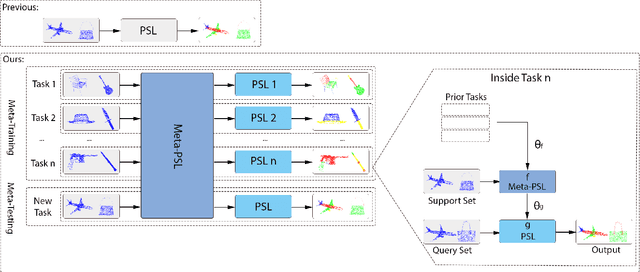

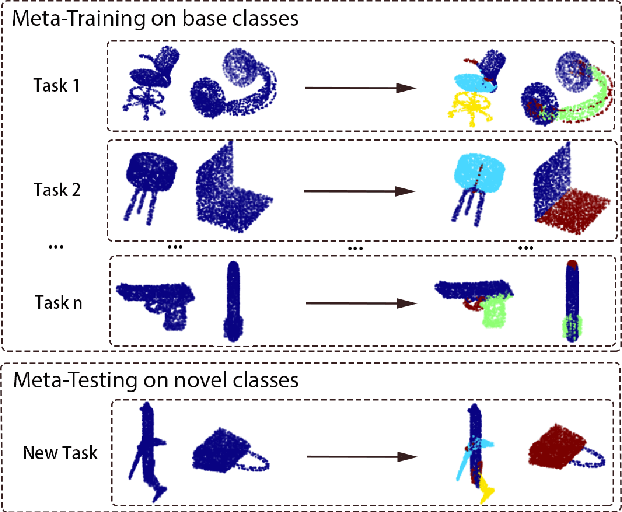
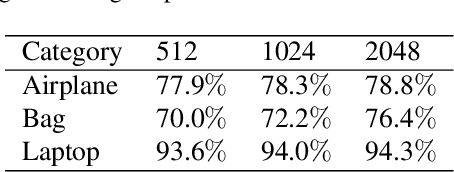
Though deep learning methods have shown great success in 3D point cloud part segmentation, they generally rely on a large volume of labeled training data, which makes the model suffer from unsatisfied generalization abilities to unseen classes with limited data. To address this problem, we present a novel meta-learning strategy that regards the 3D shape segmentation function as a task. By training over a number of 3D part segmentation tasks, our method is capable to learn the prior over the respective 3D segmentation function space which leads to an optimal model that is rapidly adapting to new part segmentation tasks. To implement our meta-learning strategy, we propose two novel modules: meta part segmentation learner and part segmentation learner. During the training process, the part segmentation learner is trained to complete a specific part segmentation task in the few-shot scenario. In the meantime, the meta part segmentation learner is trained to capture the prior from multiple similar part segmentation tasks. Based on the learned information of task distribution, our meta part segmentation learner is able to dynamically update the part segmentation learner with optimal parameters which enable our part segmentation learner to rapidly adapt and have great generalization ability on new part segmentation tasks. We demonstrate that our model achieves superior part segmentation performance with the few-shot setting on the widely used dataset: ShapeNet.
AligNART: Non-autoregressive Neural Machine Translation by Jointly Learning to Estimate Alignment and Translate
Sep 14, 2021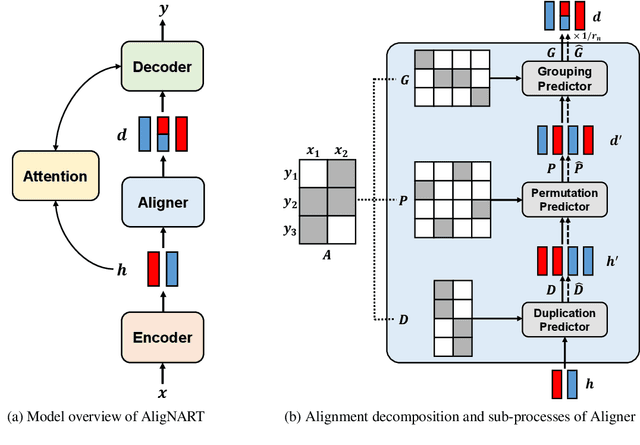
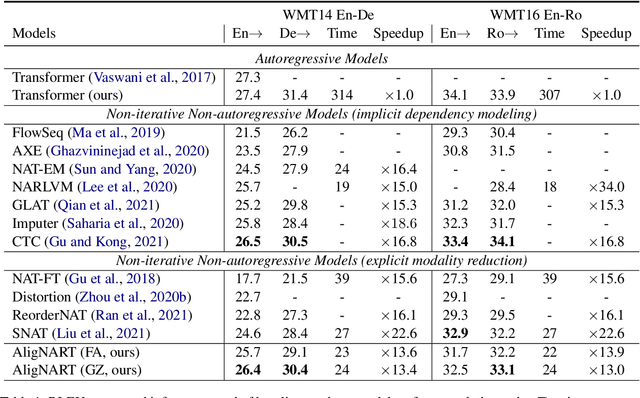
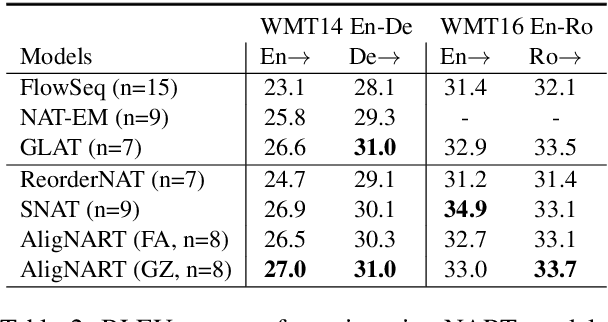
Non-autoregressive neural machine translation (NART) models suffer from the multi-modality problem which causes translation inconsistency such as token repetition. Most recent approaches have attempted to solve this problem by implicitly modeling dependencies between outputs. In this paper, we introduce AligNART, which leverages full alignment information to explicitly reduce the modality of the target distribution. AligNART divides the machine translation task into $(i)$ alignment estimation and $(ii)$ translation with aligned decoder inputs, guiding the decoder to focus on simplified one-to-one translation. To alleviate the alignment estimation problem, we further propose a novel alignment decomposition method. Our experiments show that AligNART outperforms previous non-iterative NART models that focus on explicit modality reduction on WMT14 En$\leftrightarrow$De and WMT16 Ro$\rightarrow$En. Furthermore, AligNART achieves BLEU scores comparable to those of the state-of-the-art connectionist temporal classification based models on WMT14 En$\leftrightarrow$De. We also observe that AligNART effectively addresses the token repetition problem even without sequence-level knowledge distillation.
2nd-order Updates with 1st-order Complexity
May 27, 2021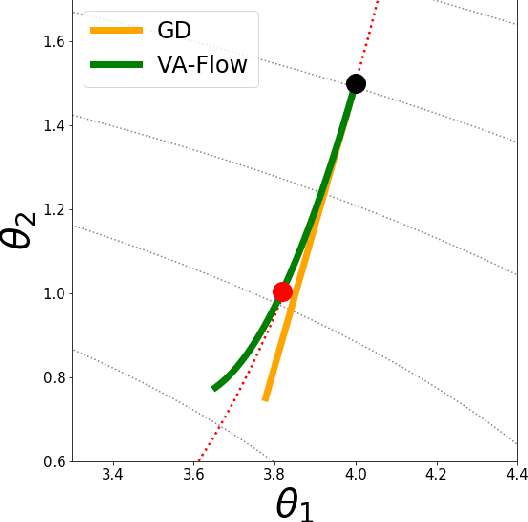
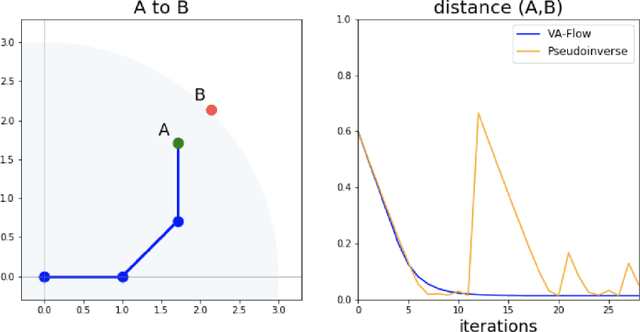
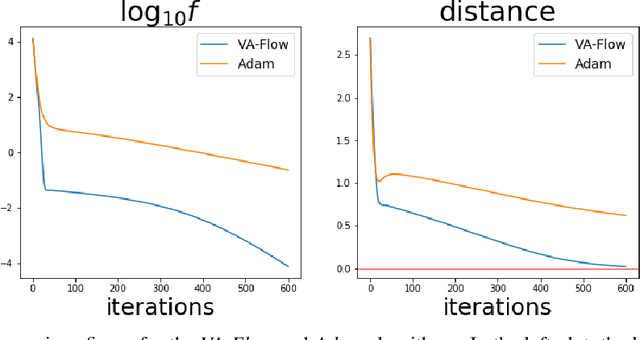
It has long been a goal to efficiently compute and use second order information on a function ($f$) to assist in numerical approximations. Here it is shown how, using only basic physics and a numerical approximation, such information can be accurately obtained at a cost of ${\cal O}(N)$ complexity, where $N$ is the dimensionality of the parameter space of $f$. In this paper, an algorithm ({\em VA-Flow}) is developed to exploit this second order information, and pseudocode is presented. It is applied to two classes of problems, that of inverse kinematics (IK) and gradient descent (GD). In the IK application, the algorithm is fast and robust, and is shown to lead to smooth behavior even near singularities. For GD the algorithm also works very well, provided the cost function is locally well-described by a polynomial.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.