 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Secure Multi-Function Computation with Private Remote Sources
Jun 17, 2021
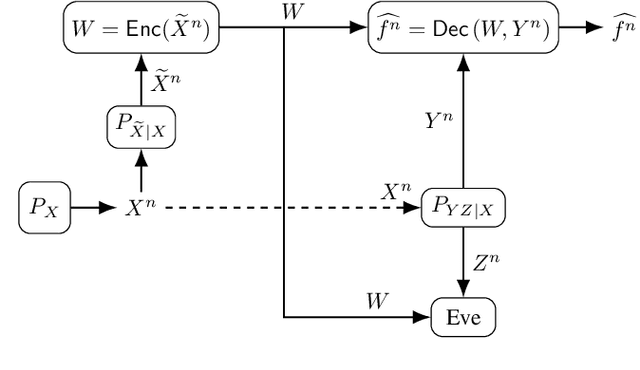
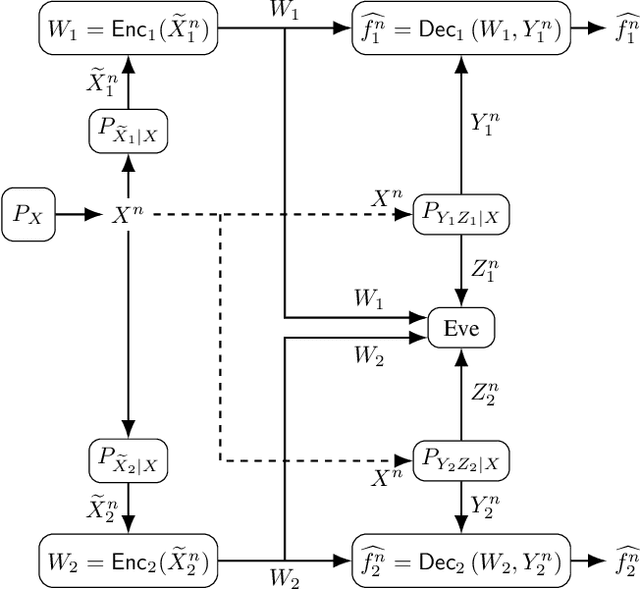
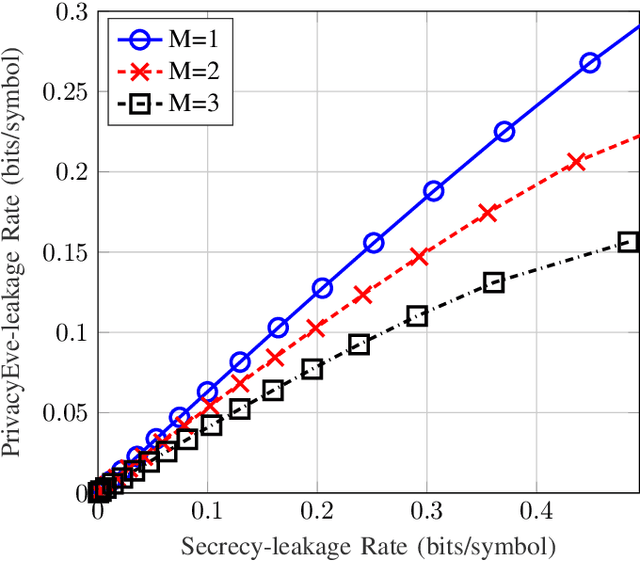
We consider a distributed function computation problem in which parties observing noisy versions of a remote source facilitate the computation of a function of their observations at a fusion center through public communication. The distributed function computation is subject to constraints, including not only reliability and storage but also privacy and secrecy. Specifically, 1) the remote source should remain private from an eavesdropper and the fusion center, measured in terms of the information leaked about the remote source; 2) the function computed should remain secret from the eavesdropper, measured in terms of the information leaked about the arguments of the function, to ensure secrecy regardless of the exact function used. We derive the exact rate regions for lossless and lossy single-function computation and illustrate the lossy single-function computation rate region for an information bottleneck example, in which the optimal auxiliary random variables are characterized for binary-input symmetric-output channels. We extend the approach to lossless and lossy asynchronous multiple-function computations with joint secrecy and privacy constraints, in which case inner and outer bounds for the rate regions differing only in the Markov chain conditions imposed are characterized.
Attention Gate in Traffic Forecasting
Sep 27, 2021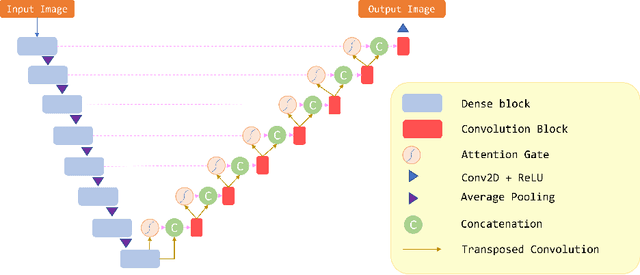
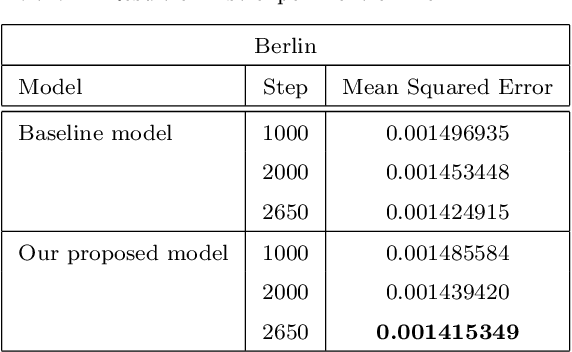
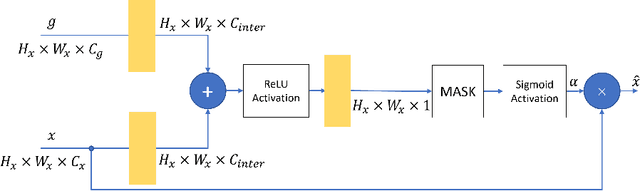
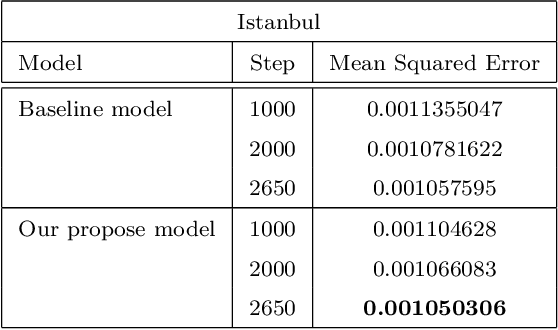
Because of increased urban complexity and growing populations, more and more challenges about predicting city-wide mobility behavior are being organized. Traffic Map Movie Forecasting Challenge 2020 is secondly held in the competition track of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS). Similar to Traffic4Cast 2019, the task is to predict traffic flow volume, average speed in major directions on the geographical area of three big cities: Berlin, Istanbul, and Moscow. In this paper, we apply the attention mechanism on U-Net based model, especially we add an attention gate on the skip-connection between contraction path and expansion path. An attention gates filter features from the contraction path before combining with features on the expansion path, it enables our model to reduce the effect of non-traffic region features and focus more on crucial region features. In addition to the competition data, we also propose two extra features which often affect traffic flow, that are time and weekdays. We experiment with our model on the competition dataset and reproduce the winner solution in the same environment. Overall, our model archives better performance than recent methods.
ConTIG: Continuous Representation Learning on Temporal Interaction Graphs
Sep 27, 2021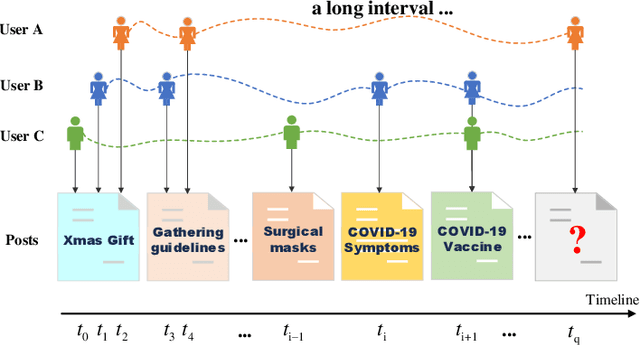
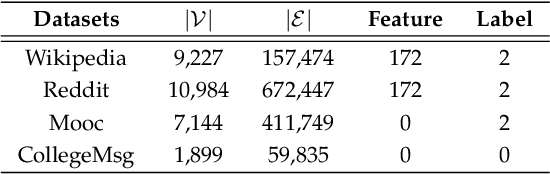
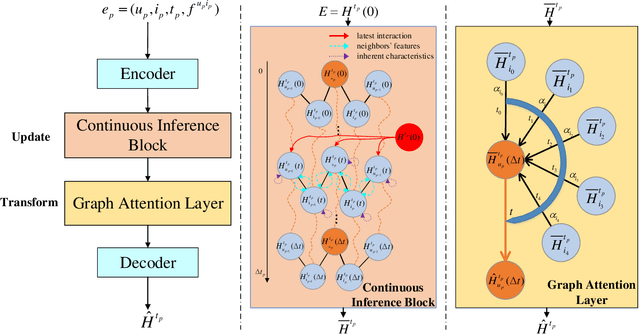
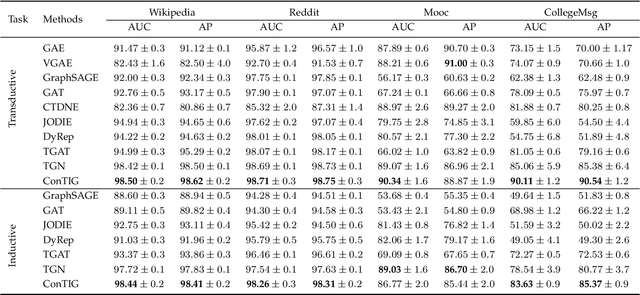
Representation learning on temporal interaction graphs (TIG) is to model complex networks with the dynamic evolution of interactions arising in a broad spectrum of problems. Existing dynamic embedding methods on TIG discretely update node embeddings merely when an interaction occurs. They fail to capture the continuous dynamic evolution of embedding trajectories of nodes. In this paper, we propose a two-module framework named ConTIG, a continuous representation method that captures the continuous dynamic evolution of node embedding trajectories. With two essential modules, our model exploit three-fold factors in dynamic networks which include latest interaction, neighbor features and inherent characteristics. In the first update module, we employ a continuous inference block to learn the nodes' state trajectories by learning from time-adjacent interaction patterns between node pairs using ordinary differential equations. In the second transform module, we introduce a self-attention mechanism to predict future node embeddings by aggregating historical temporal interaction information. Experiments results demonstrate the superiority of ConTIG on temporal link prediction, temporal node recommendation and dynamic node classification tasks compared with a range of state-of-the-art baselines, especially for long-interval interactions prediction.
LOTR: Face Landmark Localization Using Localization Transformer
Sep 21, 2021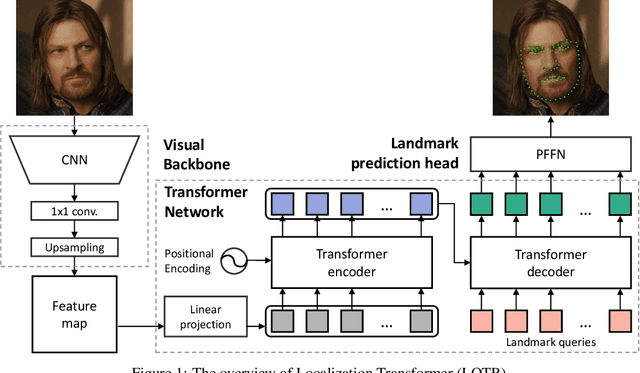
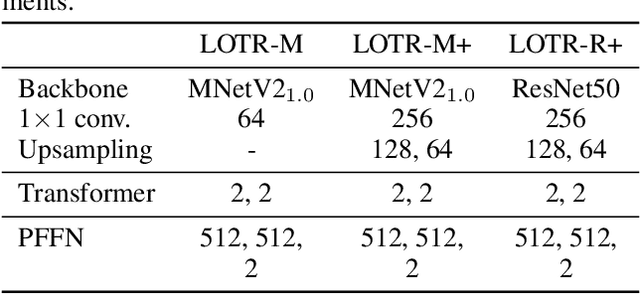
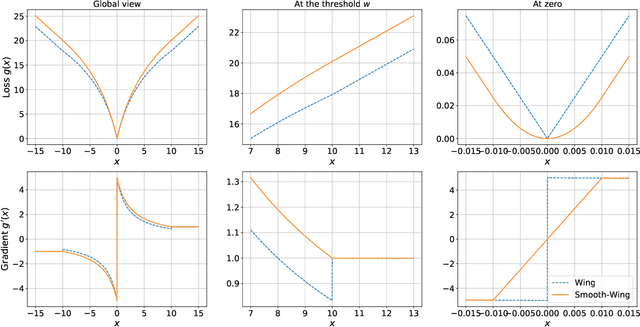
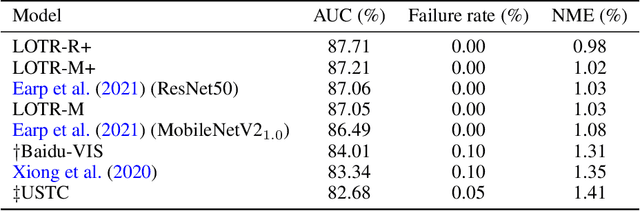
This paper presents a novel Transformer-based facial landmark localization network named Localization Transformer (LOTR). The proposed framework is a direct coordinate regression approach leveraging a Transformer network to better utilize the spatial information in the feature map. An LOTR model consists of three main modules: 1) a visual backbone that converts an input image into a feature map, 2) a Transformer module that improves the feature representation from the visual backbone, and 3) a landmark prediction head that directly predicts the landmark coordinates from the Transformer's representation. Given cropped-and-aligned face images, the proposed LOTR can be trained end-to-end without requiring any post-processing steps. This paper also introduces the smooth-Wing loss function, which addresses the gradient discontinuity of the Wing loss, leading to better convergence than standard loss functions such as L1, L2, and Wing loss. Experimental results on the JD landmark dataset provided by the First Grand Challenge of 106-Point Facial Landmark Localization indicate the superiority of LOTR over the existing methods on the leaderboard and two recent heatmap-based approaches.
Timely Status Updating Over Erasure Channels Using an Energy Harvesting Sensor: Single and Multiple Sources
Sep 14, 2021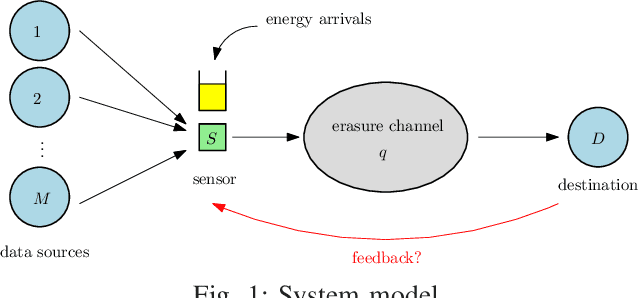
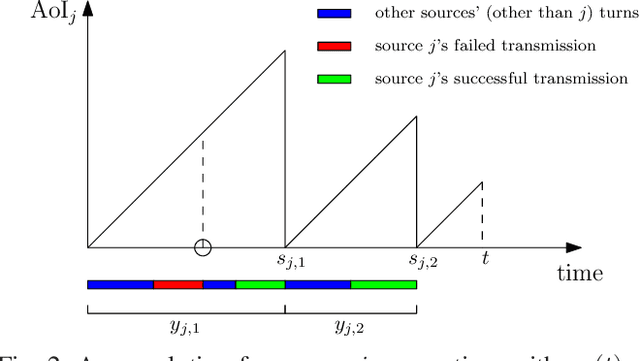
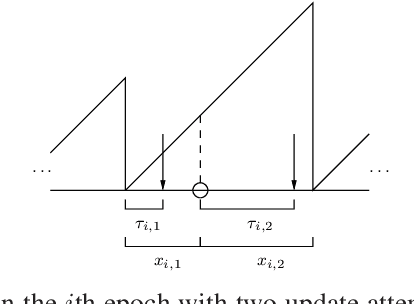
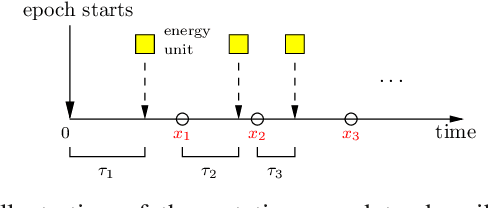
A status updating system is considered in which data from multiple sources are sampled by an energy harvesting sensor and transmitted to a remote destination through an erasure channel. The goal is to deliver status updates of all sources in a timely manner, such that the cumulative long-term average age-of-information (AoI) is minimized. The AoI for each source is defined as the time elapsed since the generation time of the latest successful status update received at the destination from that source. Transmissions are subject to energy availability, which arrives in units according to a Poisson process, with each energy unit capable of carrying out one transmission from only one source. The sensor is equipped with a unit-sized battery to save the incoming energy. A scheduling policy is designed in order to determine which source is sampled using the available energy. The problem is studied in two main settings: no erasure status feedback, and perfect instantaneous feedback.
The Integrated Probabilistic Data Association Filter Adapted to Lie Groups
Aug 16, 2021
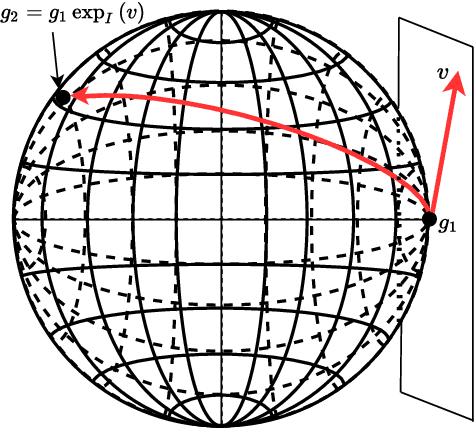
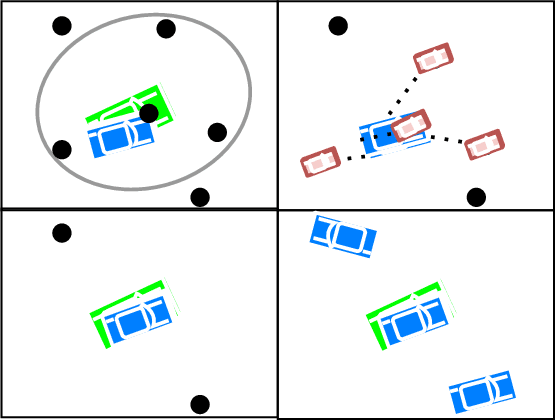
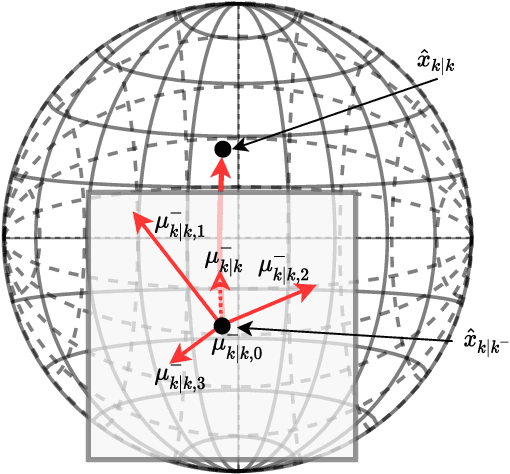
The Integrated Probabilistic Data Association Filter is a target tracking algorithm based on the Probabilistic Data Association Filter (PDAF) that calculates a statistical measure that indicates if a track should be rejected or confirmed to represent a target. The main contribution of this paper is to adapt the IPDA filter to target models that evolve on connected unimodular Lie groups, and where the measurements models also involve a Lie group. The paper contains a high level introduction to Lie groups, and then shows applications of the theory to tracking a car from an overhead UAV using camera information.
SWIPT with Intelligent Reflecting Surfaces under Spatial Correlation
Jun 01, 2021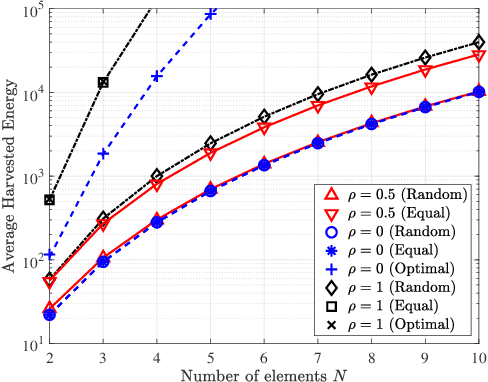
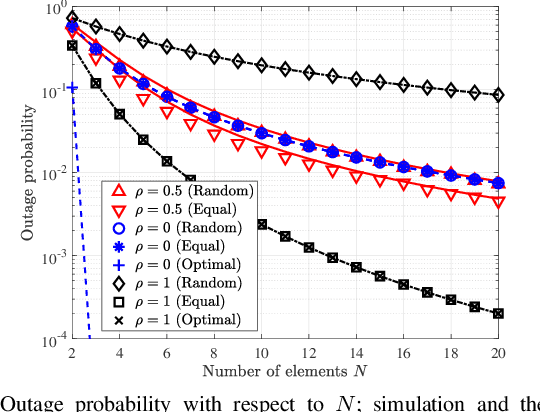
Intelligent reflecting surfaces (IRSs) can be beneficial to both information and energy transfer, due to the gains achieved by their multiple elements. In this work, we deal with the impact of spatial correlation between the IRS elements, in the context of simultaneous wireless information and power transfer. The performance is evaluated in terms of the average harvested energy and the outage probability for random and equal phase shifts. Closed-form analytical expressions for both metrics under spatial correlation are derived. Moreover, the optimal case is considered when the elements are uncorrelated and fully correlated. In the uncorrelated case, random and equal phase shifts provide the same performance. However, the performance of correlated elements attains significant gains when there are equal phase shifts. Finally, we show that correlation is always beneficial to energy transfer, whereas it is a degrading factor for information transfer under random and optimal configurations.
Intelligent Reflecting Surface for Multi-Path Beam Routing with Active/Passive Beam Splitting and Combining
Oct 21, 2021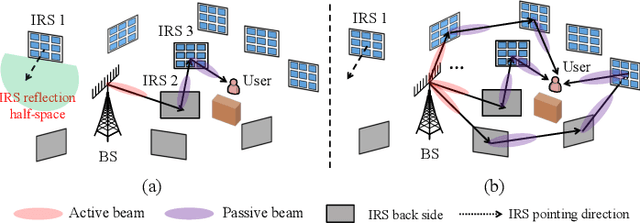
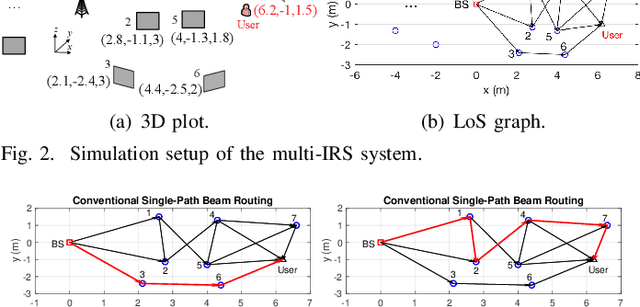
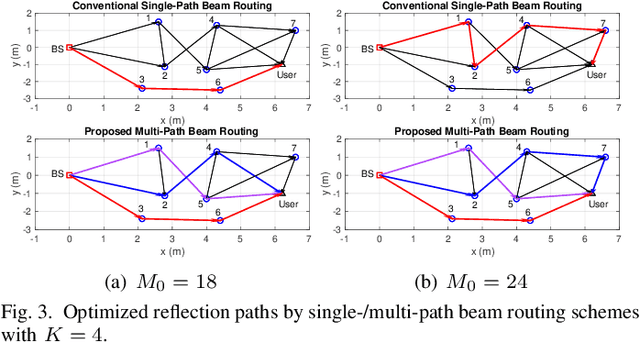
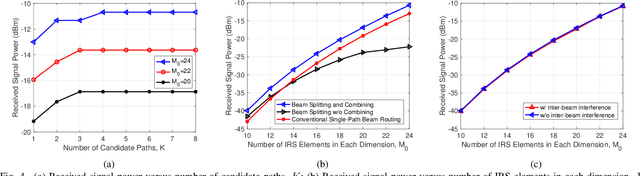
Intelligent reflecting surface (IRS) can be densely deployed in wireless networks to significantly enhance the communication channels. In this letter, we consider the downlink transmission from a multi-antenna base station (BS) to a single-antenna user, by exploiting the cooperative passive beamforming (CPB) and line-of-sight (LoS) path diversity gains of multi-IRS signal reflection. Unlike existing works where only one single multi-IRS reflection path from the BS to user is selected, we propose a new and more general {\it \textbf{multi-path beam routing}} scheme. Specifically, the BS sends the user's information signal via multiple orthogonal active beams (termed as {\it \textbf{active beam splitting}}), which point towards different IRSs. Then, these beamed signals are subsequently reflected by selected IRSs via their CPB in different paths, and finally coherently combined at the user's receiver (thus named {\it \textbf{passive beam combining}}). For this scheme, we formulate a new multi-path beam routing design problem to jointly optimize the number of IRS reflection paths, the selected IRSs for each of the reflection paths, the active/passive beamforming at the BS/each selected IRS, as well as the BS's power allocation over different active beams, so as to maximize the received signal power at the user. To solve this challenging problem, we first derive the optimal BS/IRS beamforming and BS power allocation for a given set of reflection paths. The clique-based approach in graph theory is then applied to solve the remaining multi-path selection problem efficiently. Simulation results show that our proposed multi-path beam routing scheme significantly outperforms its conventional single-path beam routing special case.
GeoSeq2Seq: Information Geometric Sequence-to-Sequence Networks
Jan 05, 2018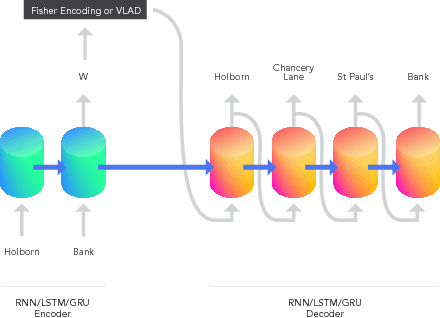
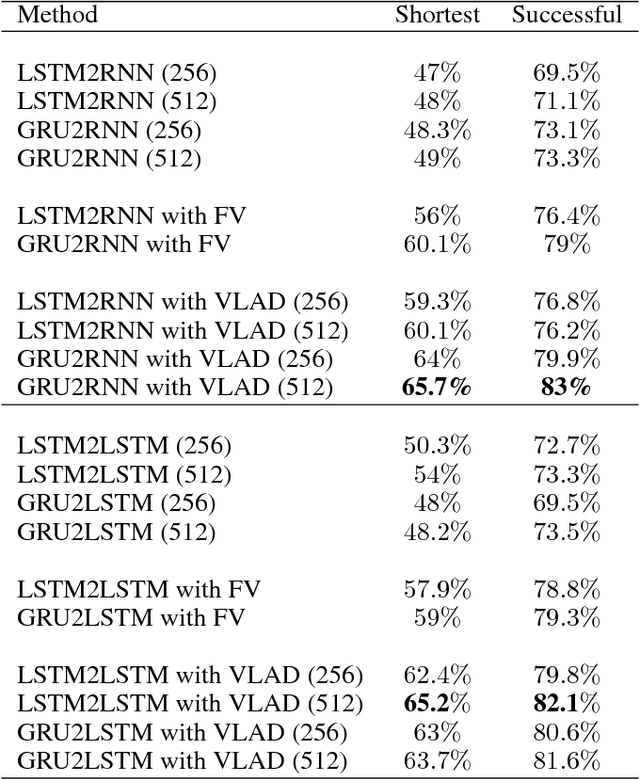
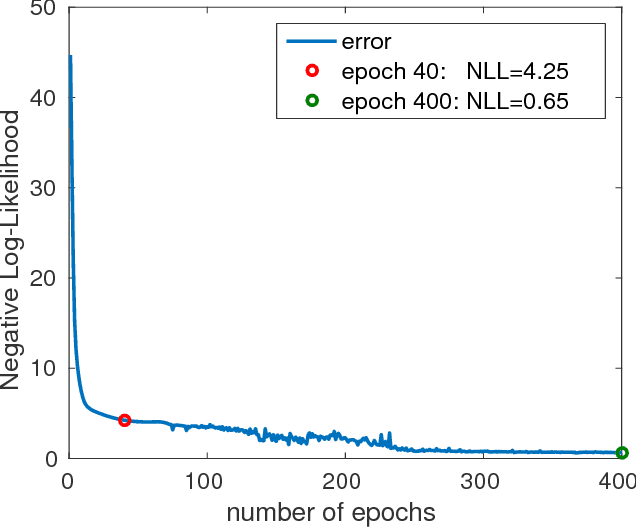
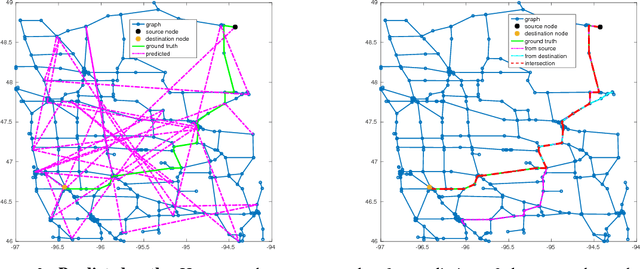
The Fisher information metric is an important foundation of information geometry, wherein it allows us to approximate the local geometry of a probability distribution. Recurrent neural networks such as the Sequence-to-Sequence (Seq2Seq) networks that have lately been used to yield state-of-the-art performance on speech translation or image captioning have so far ignored the geometry of the latent embedding, that they iteratively learn. We propose the information geometric Seq2Seq (GeoSeq2Seq) network which abridges the gap between deep recurrent neural networks and information geometry. Specifically, the latent embedding offered by a recurrent network is encoded as a Fisher kernel of a parametric Gaussian Mixture Model, a formalism common in computer vision. We utilise such a network to predict the shortest routes between two nodes of a graph by learning the adjacency matrix using the GeoSeq2Seq formalism; our results show that for such a problem the probabilistic representation of the latent embedding supersedes the non-probabilistic embedding by 10-15\%.
Boundary-aware Transformers for Skin Lesion Segmentation
Oct 08, 2021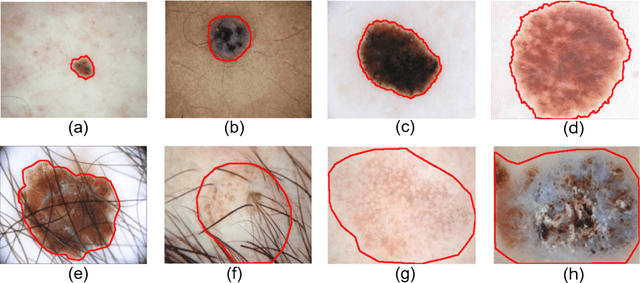
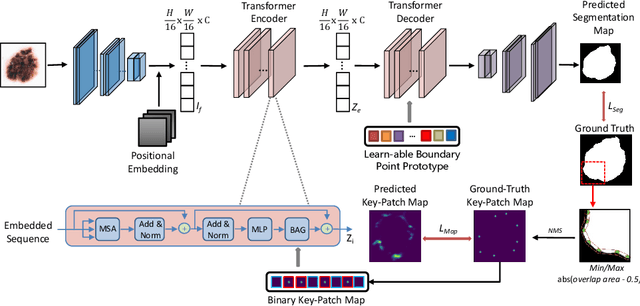
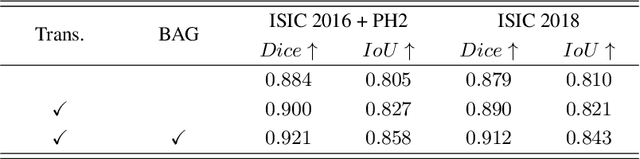
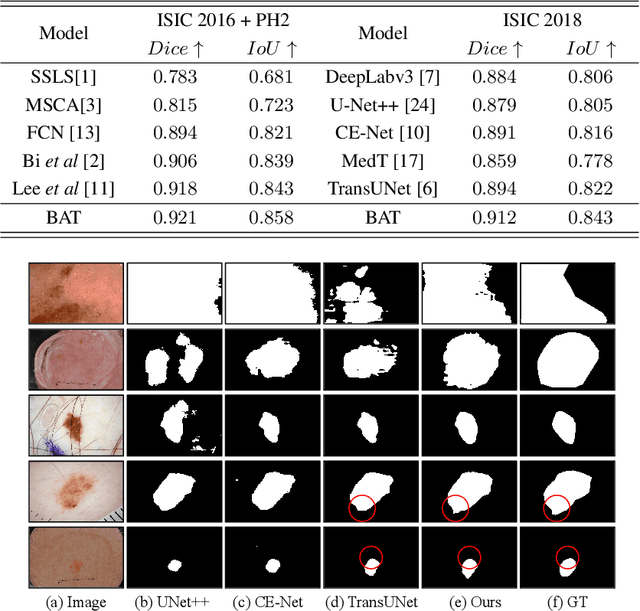
Skin lesion segmentation from dermoscopy images is of great importance for improving the quantitative analysis of skin cancer. However, the automatic segmentation of melanoma is a very challenging task owing to the large variation of melanoma and ambiguous boundaries of lesion areas. While convolutional neutral networks (CNNs) have achieved remarkable progress in this task, most of existing solutions are still incapable of effectively capturing global dependencies to counteract the inductive bias caused by limited receptive fields. Recently, transformers have been proposed as a promising tool for global context modeling by employing a powerful global attention mechanism, but one of their main shortcomings when applied to segmentation tasks is that they cannot effectively extract sufficient local details to tackle ambiguous boundaries. We propose a novel boundary-aware transformer (BAT) to comprehensively address the challenges of automatic skin lesion segmentation. Specifically, we integrate a new boundary-wise attention gate (BAG) into transformers to enable the whole network to not only effectively model global long-range dependencies via transformers but also, simultaneously, capture more local details by making full use of boundary-wise prior knowledge. Particularly, the auxiliary supervision of BAG is capable of assisting transformers to learn position embedding as it provides much spatial information. We conducted extensive experiments to evaluate the proposed BAT and experiments corroborate its effectiveness, consistently outperforming state-of-the-art methods in two famous datasets.