 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The edge of chaos: quantum field theory and deep neural networks
Sep 27, 2021
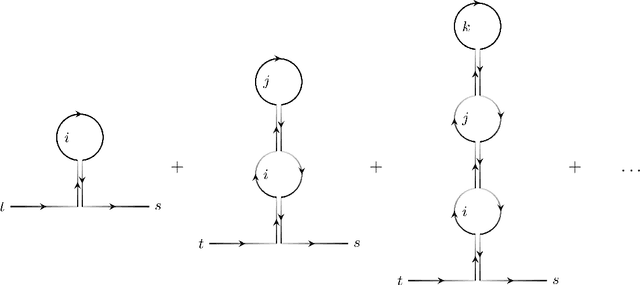
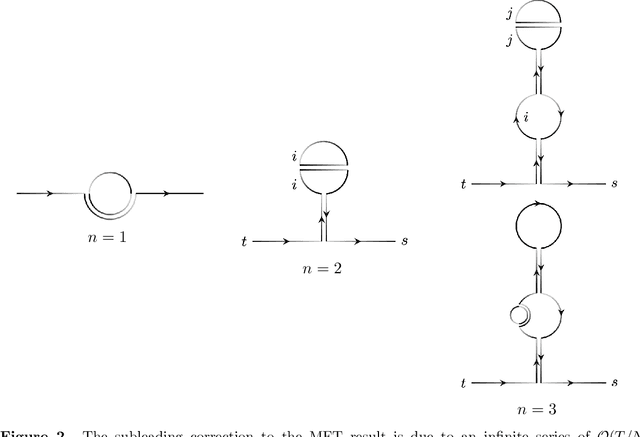
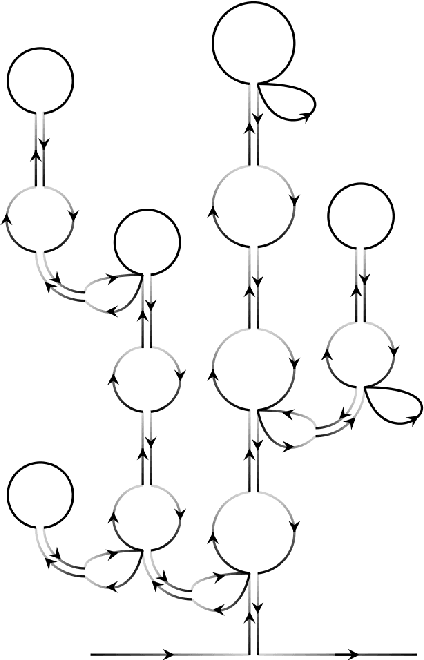

We explicitly construct the quantum field theory corresponding to a general class of deep neural networks encompassing both recurrent and feedforward architectures. We first consider the mean-field theory (MFT) obtained as the leading saddlepoint in the action, and derive the condition for criticality via the largest Lyapunov exponent. We then compute the loop corrections to the correlation function in a perturbative expansion in the ratio of depth $T$ to width $N$, and find a precise analogy with the well-studied $O(N)$ vector model, in which the variance of the weight initializations plays the role of the 't Hooft coupling. In particular, we compute both the $\mathcal{O}(1)$ corrections quantifying fluctuations from typicality in the ensemble of networks, and the subleading $\mathcal{O}(T/N)$ corrections due to finite-width effects. These provide corrections to the correlation length that controls the depth to which information can propagate through the network, and thereby sets the scale at which such networks are trainable by gradient descent. Our analysis provides a first-principles approach to the rapidly emerging NN-QFT correspondence, and opens several interesting avenues to the study of criticality in deep neural networks.
Unified Likelihood Ratio Estimation for High- to Zero-frequency N-grams
Oct 03, 2021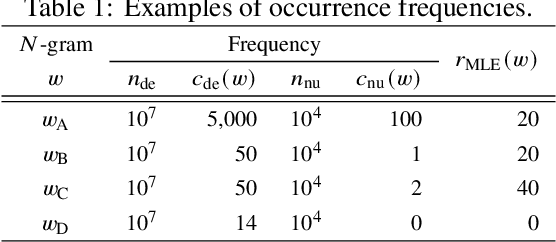
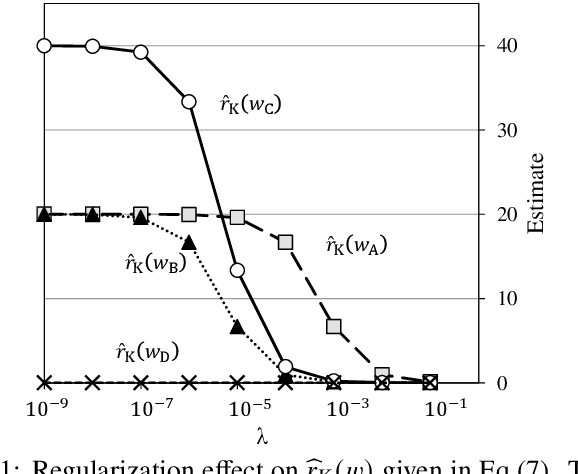

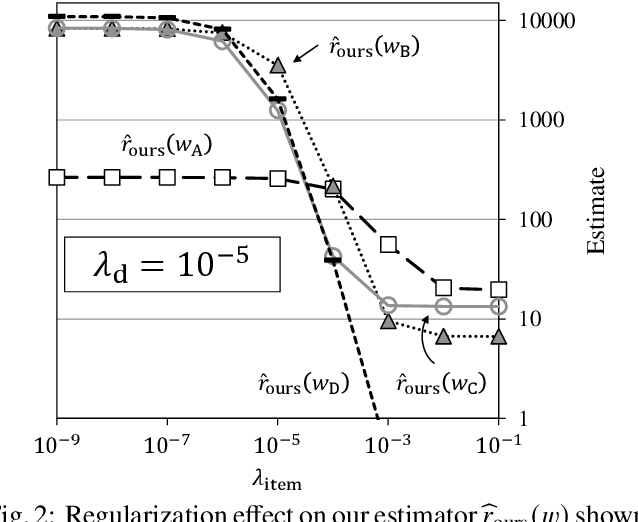
Likelihood ratios (LRs), which are commonly used for probabilistic data processing, are often estimated based on the frequency counts of individual elements obtained from samples. In natural language processing, an element can be a continuous sequence of $N$ items, called an $N$-gram, in which each item is a word, letter, etc. In this paper, we attempt to estimate LRs based on $N$-gram frequency information. A naive estimation approach that uses only $N$-gram frequencies is sensitive to low-frequency (rare) $N$-grams and not applicable to zero-frequency (unobserved) $N$-grams; these are known as the low- and zero-frequency problems, respectively. To address these problems, we propose a method for decomposing $N$-grams into item units and then applying their frequencies along with the original $N$-gram frequencies. Our method can obtain the estimates of unobserved $N$-grams by using the unit frequencies. Although using only unit frequencies ignores dependencies between items, our method takes advantage of the fact that certain items often co-occur in practice and therefore maintains their dependencies by using the relevant $N$-gram frequencies. We also introduce a regularization to achieve robust estimation for rare $N$-grams. Our experimental results demonstrate that our method is effective at solving both problems and can effectively control dependencies.
* 17 pages, 8 figures
Global Context Enhanced Social Recommendation with Hierarchical Graph Neural Networks
Oct 08, 2021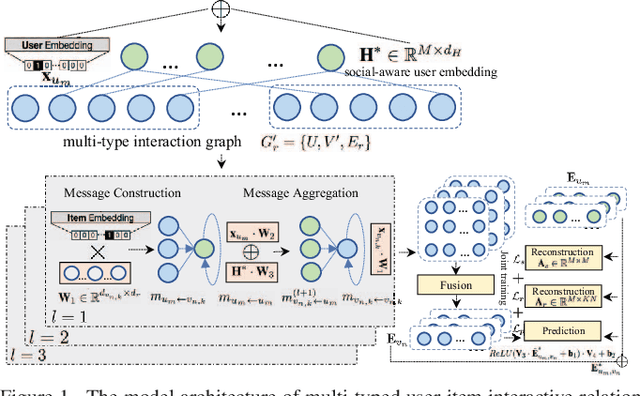
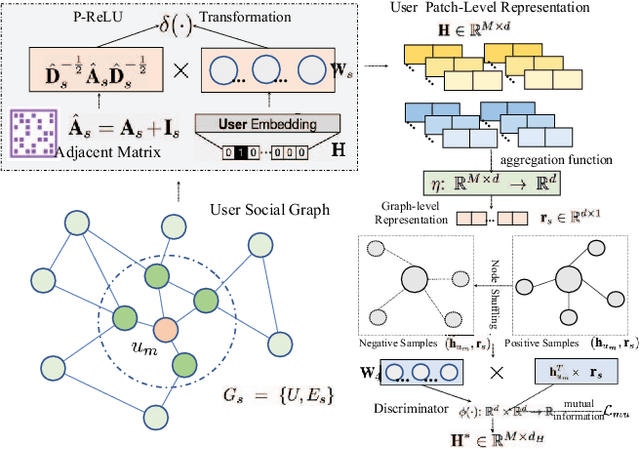
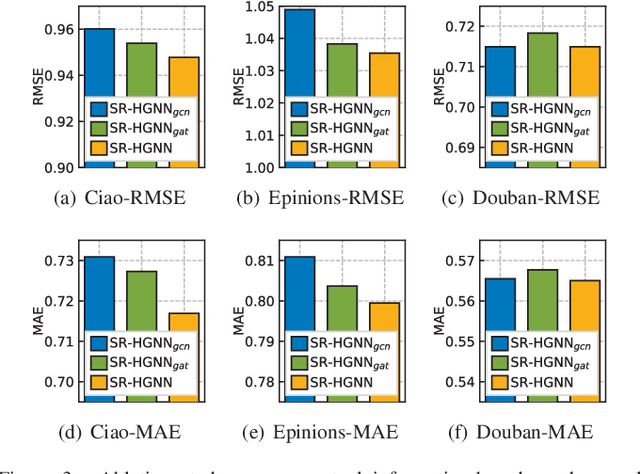
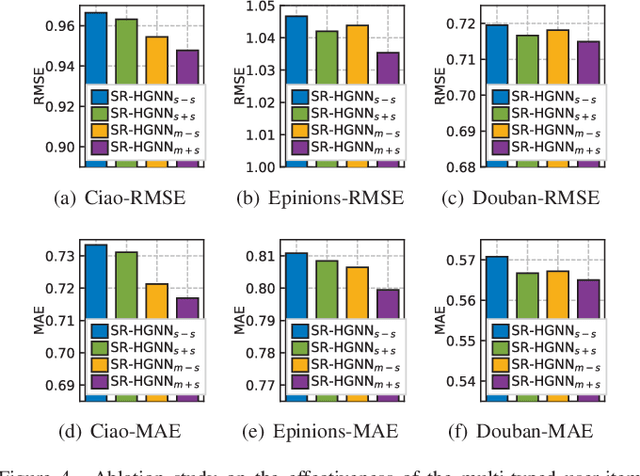
Social recommendation which aims to leverage social connections among users to enhance the recommendation performance. With the revival of deep learning techniques, many efforts have been devoted to developing various neural network-based social recommender systems, such as attention mechanisms and graph-based message passing frameworks. However, two important challenges have not been well addressed yet: (i) Most of existing social recommendation models fail to fully explore the multi-type user-item interactive behavior as well as the underlying cross-relational inter-dependencies. (ii) While the learned social state vector is able to model pair-wise user dependencies, it still has limited representation capacity in capturing the global social context across users. To tackle these limitations, we propose a new Social Recommendation framework with Hierarchical Graph Neural Networks (SR-HGNN). In particular, we first design a relation-aware reconstructed graph neural network to inject the cross-type collaborative semantics into the recommendation framework. In addition, we further augment SR-HGNN with a social relation encoder based on the mutual information learning paradigm between low-level user embeddings and high-level global representation, which endows SR-HGNN with the capability of capturing the global social contextual signals. Empirical results on three public benchmarks demonstrate that SR-HGNN significantly outperforms state-of-the-art recommendation methods. Source codes are available at: https://github.com/xhcdream/SR-HGNN.
TL-SDD: A Transfer Learning-Based Method for Surface Defect Detection with Few Samples
Aug 16, 2021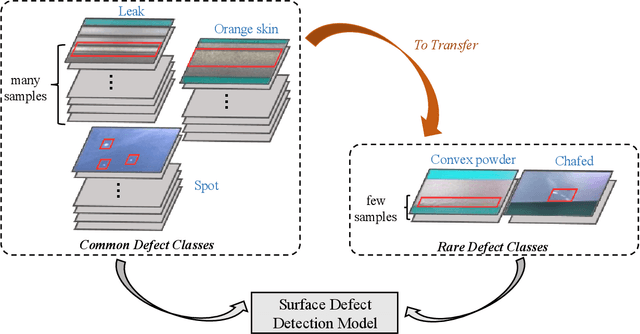
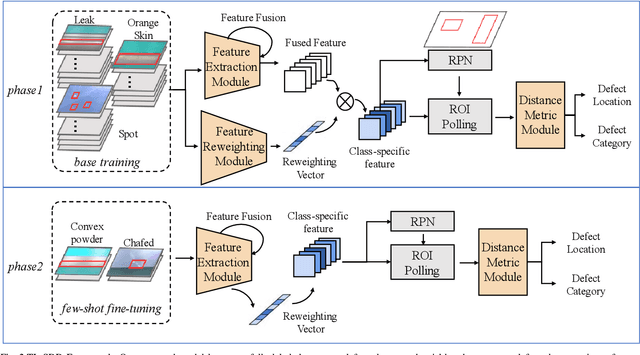
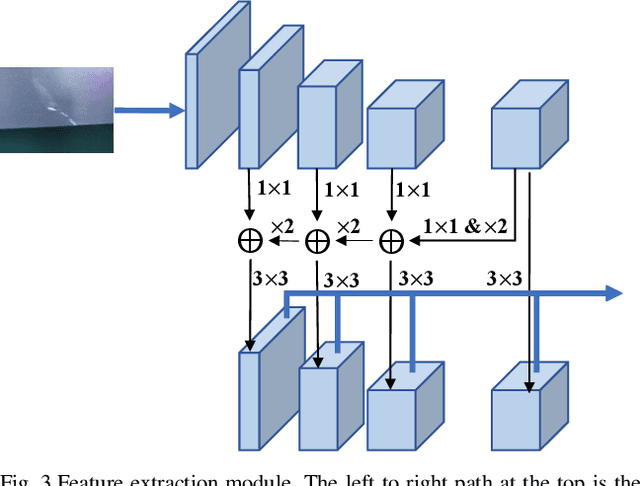
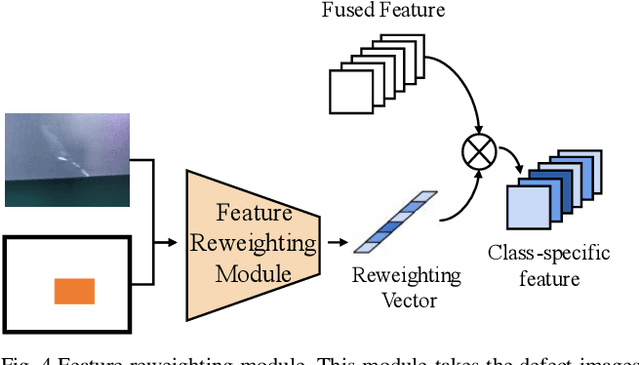
Surface defect detection plays an increasingly important role in manufacturing industry to guarantee the product quality. Many deep learning methods have been widely used in surface defect detection tasks, and have been proven to perform well in defects classification and location. However, deep learning-based detection methods often require plenty of data for training, which fail to apply to the real industrial scenarios since the distribution of defect categories is often imbalanced. In other words, common defect classes have many samples but rare defect classes have extremely few samples, and it is difficult for these methods to well detect rare defect classes. To solve the imbalanced distribution problem, in this paper we propose TL-SDD: a novel Transfer Learning-based method for Surface Defect Detection. First, we adopt a two-phase training scheme to transfer the knowledge from common defect classes to rare defect classes. Second, we propose a novel Metric-based Surface Defect Detection (M-SDD) model. We design three modules for this model: (1) feature extraction module: containing feature fusion which combines high-level semantic information with low-level structural information. (2) feature reweighting module: transforming examples to a reweighting vector that indicates the importance of features. (3) distance metric module: learning a metric space in which defects are classified by computing distances to representations of each category. Finally, we validate the performance of our proposed method on a real dataset including surface defects of aluminum profiles. Compared to the baseline methods, the performance of our proposed method has improved by up to 11.98% for rare defect classes.
Analysis for full face mechanical behaviors through spatial deduction model with real-time monitoring data
Sep 27, 2021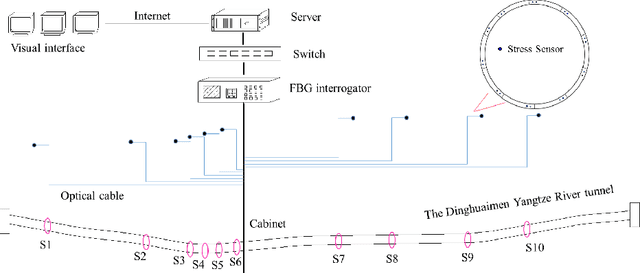
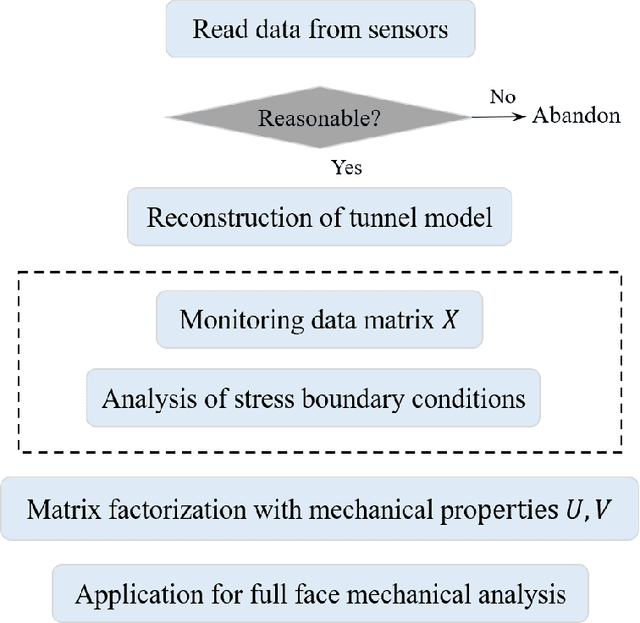
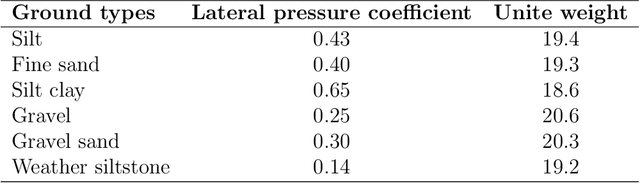
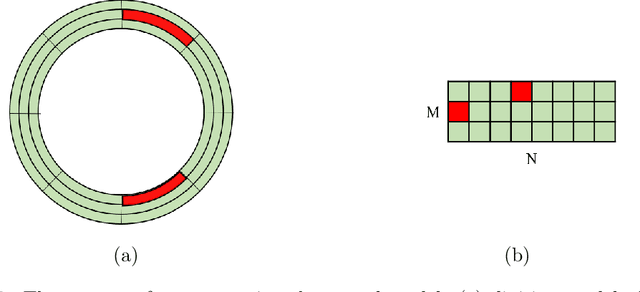
Mechanical analysis for the full face of tunnel structure is crucial to maintain stability, which is a challenge in classical analytical solutions and data analysis. Along this line, this study aims to develop a spatial deduction model to obtain the full-faced mechanical behaviors through integrating mechanical properties into pure data-driven model. The spatial tunnel structure is divided into many parts and reconstructed in a form of matrix. Then, the external load applied on structure in the field was considered to study the mechanical behaviors of tunnel. Based on the limited observed monitoring data in matrix and mechanical analysis results, a double-driven model was developed to obtain the full-faced information, in which the data-driven model was the dominant one and the mechanical constraint was the secondary one. To verify the presented spatial deduction model, cross-test was conducted through assuming partial monitoring data are unknown and regarding them as testing points. The well agreement between deduction results with actual monitoring results means the proposed model is reasonable. Therefore, it was employed to deduct both the current and historical performance of tunnel full face, which is crucial to prevent structural disasters.
Federated Learning for Big Data: A Survey on Opportunities, Applications, and Future Directions
Oct 17, 2021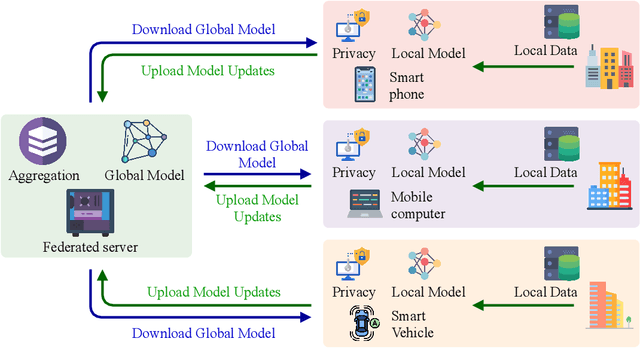
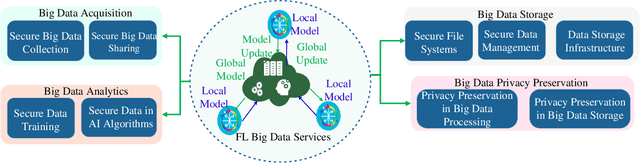
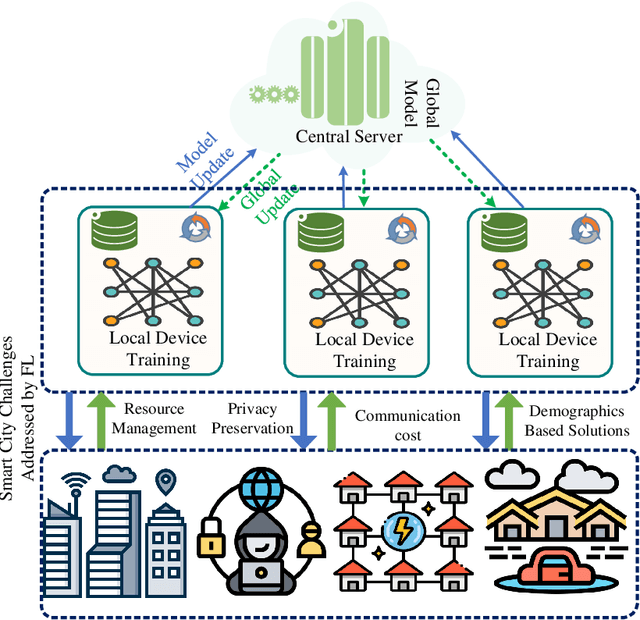
Big data has remarkably evolved over the last few years to realize an enormous volume of data generated from newly emerging services and applications and a massive number of Internet-of-Things (IoT) devices. The potential of big data can be realized via analytic and learning techniques, in which the data from various sources is transferred to a central cloud for central storage, processing, and training. However, this conventional approach faces critical issues in terms of data privacy as the data may include sensitive data such as personal information, governments, banking accounts. To overcome this challenge, federated learning (FL) appeared to be a promising learning technique. However, a gap exists in the literature that a comprehensive survey on FL for big data services and applications is yet to be conducted. In this article, we present a survey on the use of FL for big data services and applications, aiming to provide general readers with an overview of FL, big data, and the motivations behind the use of FL for big data. In particular, we extensively review the use of FL for key big data services, including big data acquisition, big data storage, big data analytics, and big data privacy preservation. Subsequently, we review the potential of FL for big data applications, such as smart city, smart healthcare, smart transportation, smart grid, and social media. Further, we summarize a number of important projects on FL-big data and discuss key challenges of this interesting topic along with several promising solutions and directions.
Learnable Reconstruction Methods from RGB Images to Hyperspectral Imaging: A Survey
Jun 30, 2021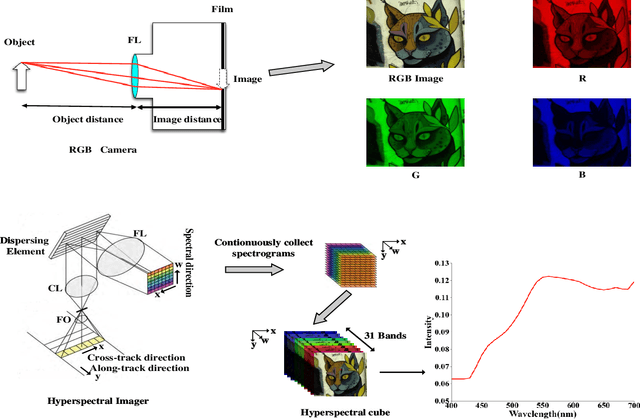
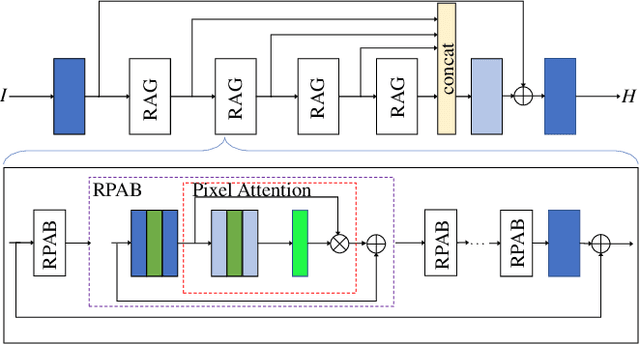
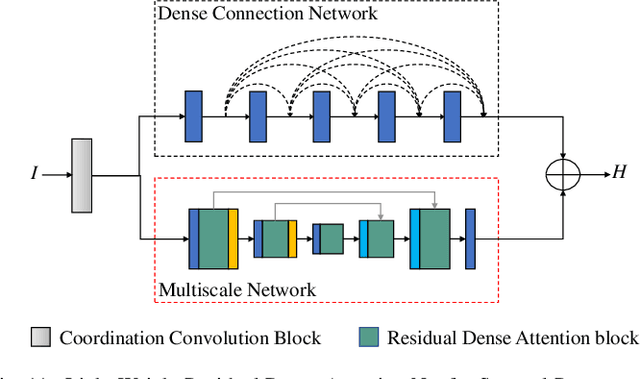
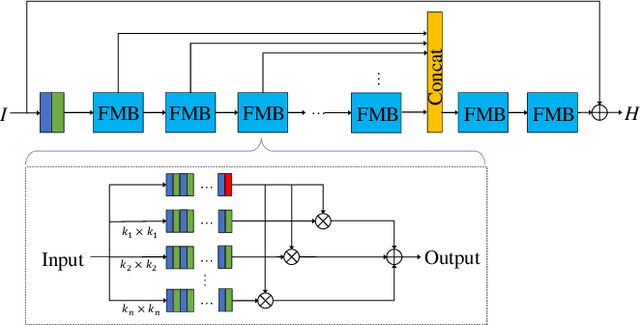
Hyperspectral imaging enables versatile applications due to its competence in capturing abundant spatial and spectral information, which are crucial for identifying substances. However, the devices for acquiring hyperspectral images are expensive and complicated. Therefore, many alternative spectral imaging methods have been proposed by directly reconstructing the hyperspectral information from lower-cost, more available RGB images. We present a thorough investigation of these state-of-the-art spectral reconstruction methods from the widespread RGB images. A systematic study and comparison of more than 25 methods has revealed that most of the data-driven deep learning methods are superior to prior-based methods in terms of reconstruction accuracy and quality despite lower speeds. This comprehensive review can serve as a fruitful reference source for peer researchers, thus further inspiring future development directions in related domains.
Musical Tempo Estimation Using a Multi-scale Network
Sep 03, 2021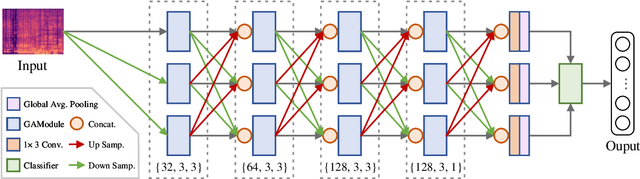

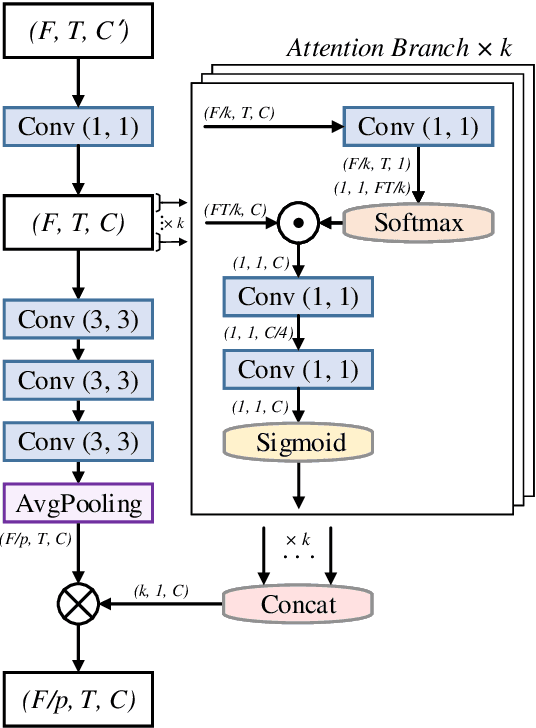
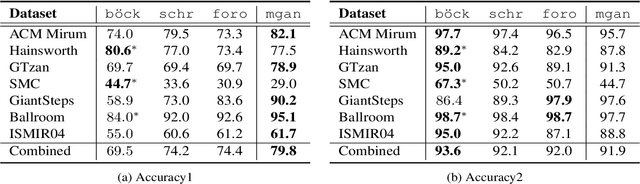
Recently, some single-step systems without onset detection have shown their effectiveness in automatic musical tempo estimation. Following the success of these systems, in this paper we propose a Multi-scale Grouped Attention Network to further explore the potential of such methods. A multi-scale structure is introduced as the overall network architecture where information from different scales is aggregated to strengthen contextual feature learning. Furthermore, we propose a Grouped Attention Module as the key component of the network. The proposed module separates the input feature into several groups along the frequency axis, which makes it capable of capturing long-range dependencies from different frequency positions on the spectrogram. In comparison experiments, the results on public datasets show that the proposed model outperforms existing state-of-the-art methods on Accuracy1.
Deep HDR Hallucination for Inverse Tone Mapping
Jun 17, 2021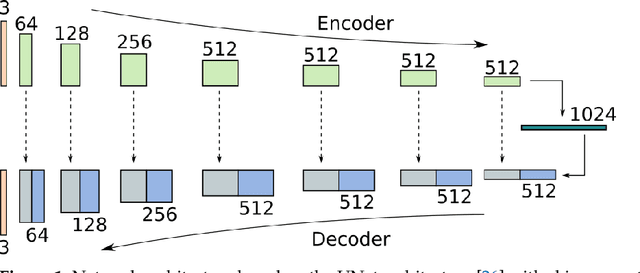
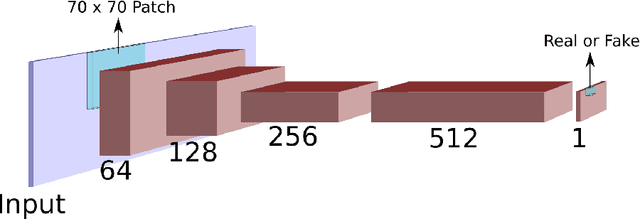
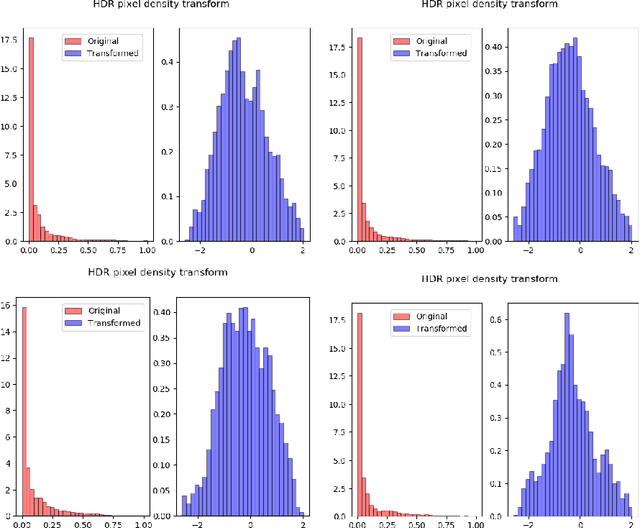

Inverse Tone Mapping (ITM) methods attempt to reconstruct High Dynamic Range (HDR) information from Low Dynamic Range (LDR) image content. The dynamic range of well-exposed areas must be expanded and any missing information due to over/under-exposure must be recovered (hallucinated). The majority of methods focus on the former and are relatively successful, while most attempts on the latter are not of sufficient quality, even ones based on Convolutional Neural Networks (CNNs). A major factor for the reduced inpainting quality in some works is the choice of loss function. Work based on Generative Adversarial Networks (GANs) shows promising results for image synthesis and LDR inpainting, suggesting that GAN losses can improve inverse tone mapping results. This work presents a GAN-based method that hallucinates missing information from badly exposed areas in LDR images and compares its efficacy with alternative variations. The proposed method is quantitatively competitive with state-of-the-art inverse tone mapping methods, providing good dynamic range expansion for well-exposed areas and plausible hallucinations for saturated and under-exposed areas. A density-based normalisation method, targeted for HDR content, is also proposed, as well as an HDR data augmentation method targeted for HDR hallucination.
Secure Multi-Function Computation with Private Remote Sources
Jun 17, 2021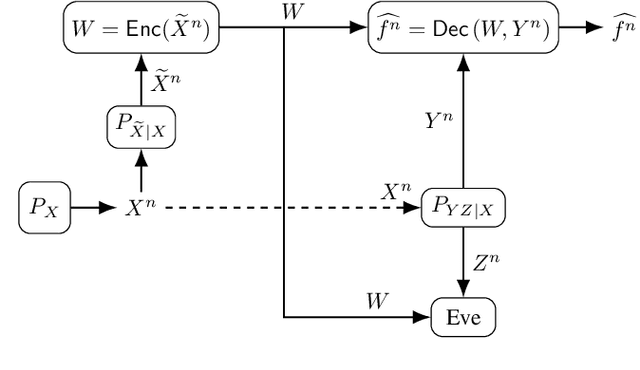
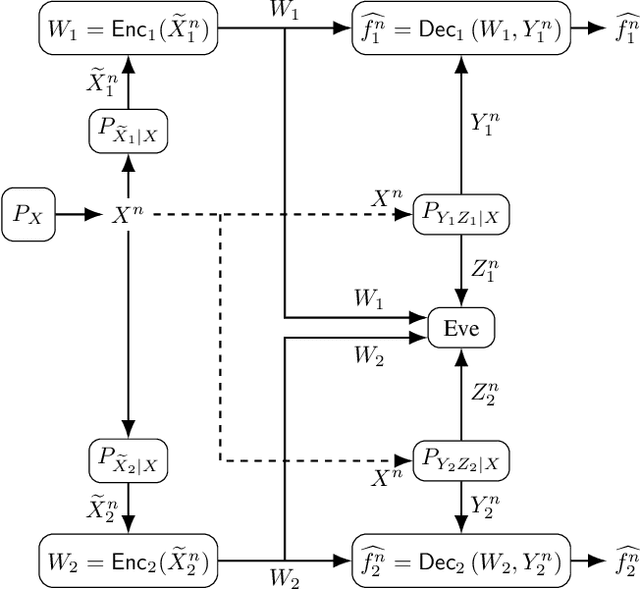
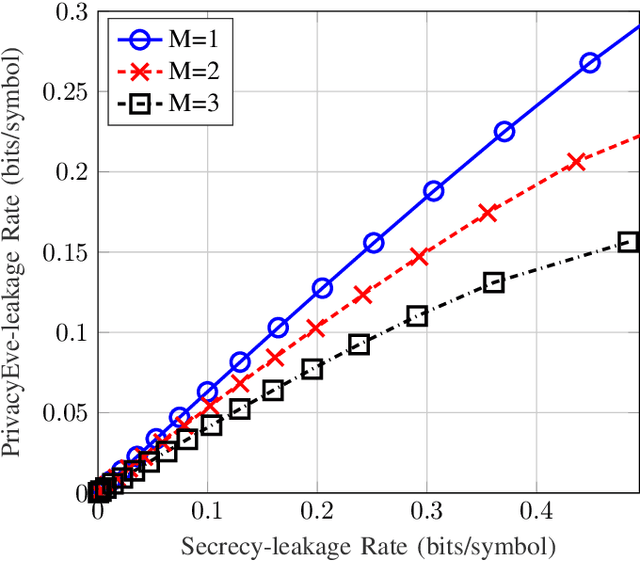
We consider a distributed function computation problem in which parties observing noisy versions of a remote source facilitate the computation of a function of their observations at a fusion center through public communication. The distributed function computation is subject to constraints, including not only reliability and storage but also privacy and secrecy. Specifically, 1) the remote source should remain private from an eavesdropper and the fusion center, measured in terms of the information leaked about the remote source; 2) the function computed should remain secret from the eavesdropper, measured in terms of the information leaked about the arguments of the function, to ensure secrecy regardless of the exact function used. We derive the exact rate regions for lossless and lossy single-function computation and illustrate the lossy single-function computation rate region for an information bottleneck example, in which the optimal auxiliary random variables are characterized for binary-input symmetric-output channels. We extend the approach to lossless and lossy asynchronous multiple-function computations with joint secrecy and privacy constraints, in which case inner and outer bounds for the rate regions differing only in the Markov chain conditions imposed are characterized.