 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Simultaneously Transmitting and Reflecting (STAR)-RISs: A Coupled Phase-Shift Model
Oct 05, 2021
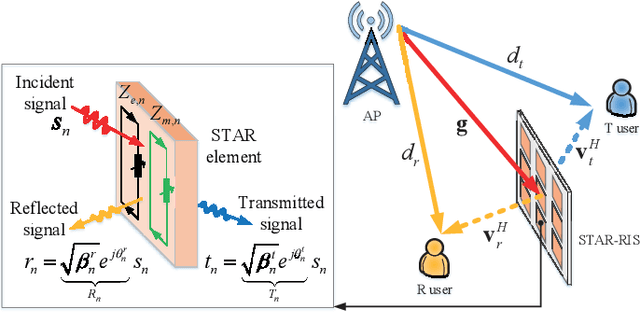
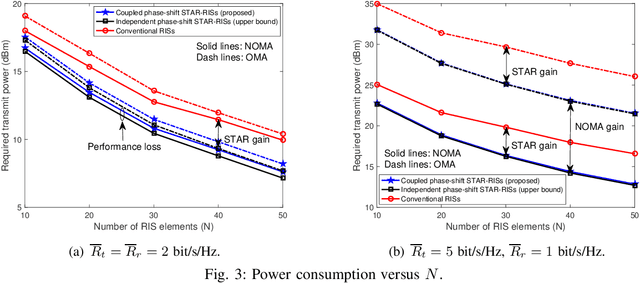
A simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) aided communication system is investigated, where an access point sends information to two users located on each side of the STAR-RIS. Different from current works assuming that the phase-shift coefficients for transmission and reflection can be independently adjusted, which is non-trivial to realize for purely passive STAR-RISs, a coupled transmission and reflection phase-shift model is considered. Based on this model, a power consumption minimization problem is formulated for both non-orthogonal multiple access (NOMA) and orthogonal multiple access (OMA). In particular, the amplitude and phase-shift coefficients for transmission and reflection are jointly optimized, subject to the rate constraints of the users. To solve this non-convex problem, an efficient element-wise alternating optimization algorithm is developed to find a high-quality suboptimal solution, whose complexity scales only linearly with the number of STAR elements. Finally, numerical results are provided for both NOMA and OMA to validate the effectiveness of the proposed algorithm by comparing its performance with that of STAR-RISs using the independent phase-shift model and conventional reflecting/transmitting-only RISs.
TransAttUnet: Multi-level Attention-guided U-Net with Transformer for Medical Image Segmentation
Jul 12, 2021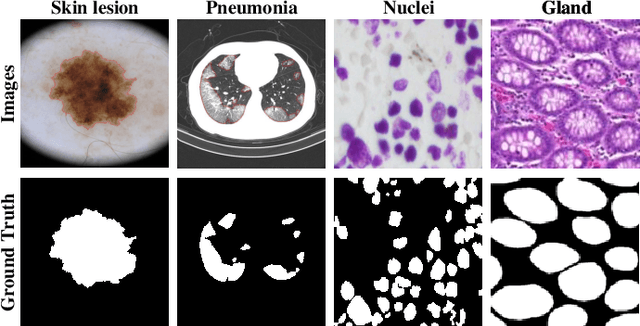
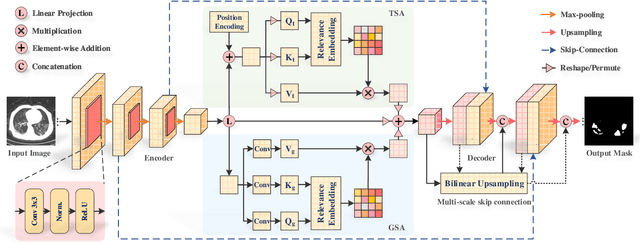
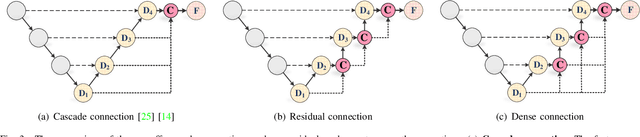
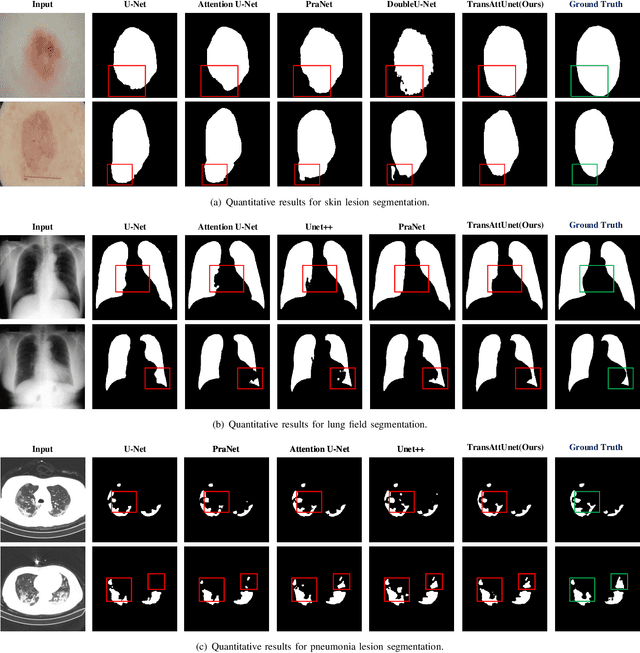
With the development of deep encoder-decoder architectures and large-scale annotated medical datasets, great progress has been achieved in the development of automatic medical image segmentation. Due to the stacking of convolution layers and the consecutive sampling operations, existing standard models inevitably encounter the information recession problem of feature representations, which fails to fully model the global contextual feature dependencies. To overcome the above challenges, this paper proposes a novel Transformer based medical image semantic segmentation framework called TransAttUnet, in which the multi-level guided attention and multi-scale skip connection are jointly designed to effectively enhance the functionality and flexibility of traditional U-shaped architecture. Inspired by Transformer, a novel self-aware attention (SAA) module with both Transformer Self Attention (TSA) and Global Spatial Attention (GSA) is incorporated into TransAttUnet to effectively learn the non-local interactions between encoder features. In particular, we also establish additional multi-scale skip connections between decoder blocks to aggregate the different semantic-scale upsampling features. In this way, the representation ability of multi-scale context information is strengthened to generate discriminative features. Benefitting from these complementary components, the proposed TransAttUnet can effectively alleviate the loss of fine details caused by the information recession problem, improving the diagnostic sensitivity and segmentation quality of medical image analysis. Extensive experiments on multiple medical image segmentation datasets of different imaging demonstrate that our method consistently outperforms the state-of-the-art baselines.
Adversarial defenses via a mixture of generators
Oct 05, 2021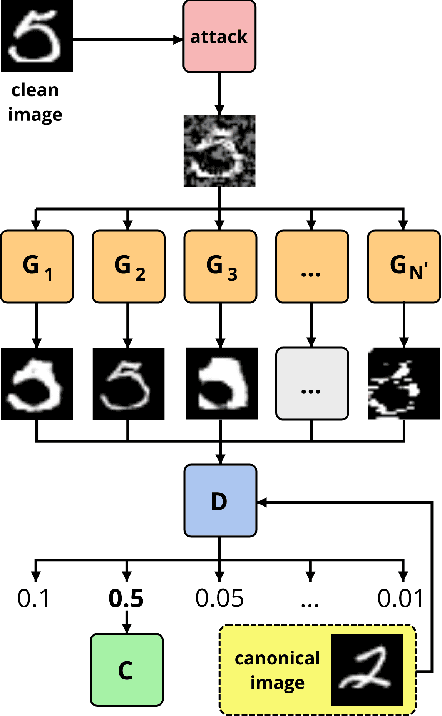


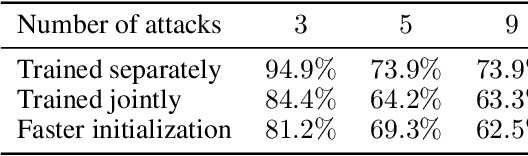
In spite of the enormous success of neural networks, adversarial examples remain a relatively weakly understood feature of deep learning systems. There is a considerable effort in both building more powerful adversarial attacks and designing methods to counter the effects of adversarial examples. We propose a method to transform the adversarial input data through a mixture of generators in order to recover the correct class obfuscated by the adversarial attack. A canonical set of images is used to generate adversarial examples through potentially multiple attacks. Such transformed images are processed by a set of generators, which are trained adversarially as a whole to compete in inverting the initial transformations. To our knowledge, this is the first use of a mixture-based adversarially trained system as a defense mechanism. We show that it is possible to train such a system without supervision, simultaneously on multiple adversarial attacks. Our system is able to recover class information for previously-unseen examples with neither attack nor data labels on the MNIST dataset. The results demonstrate that this multi-attack approach is competitive with adversarial defenses tested in single-attack settings.
MoDIR: Motion-Compensated Training for Deep Image Reconstruction without Ground Truth
Jul 12, 2021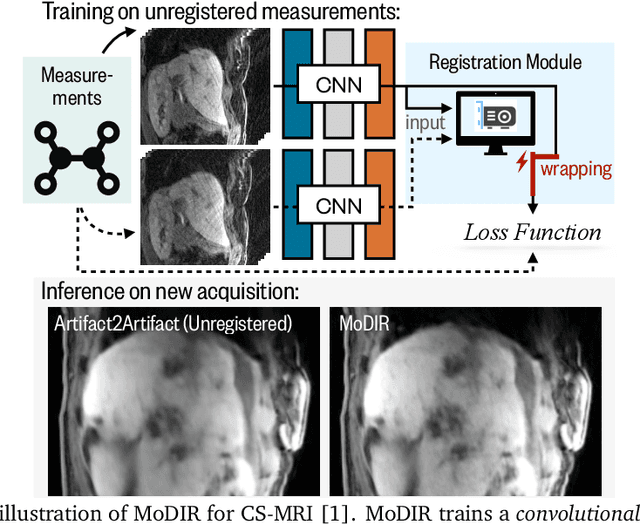
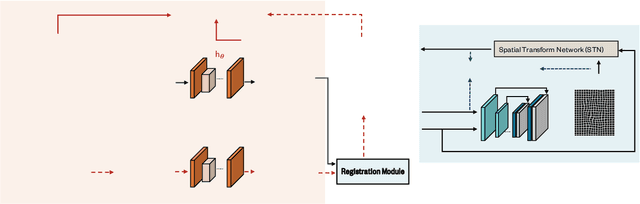
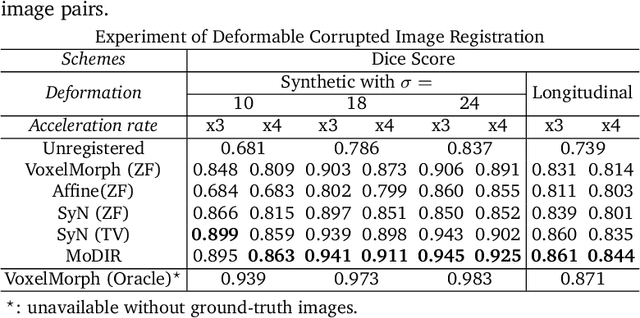
Deep neural networks for medical image reconstruction are traditionally trained using high-quality ground-truth images as training targets. Recent work onNoise2Noise (N2N) has shown the potential of using multiple noisy measurements of the same object as an alternative to having a ground truth. However, existing N2N-based methods cannot exploit information from various motion states, limiting their ability to learn on moving objects. This paper addresses this issue by proposing a novel motion-compensated deep image reconstruction (MoDIR) method that can use information from several unregistered and noisy measurements for training. MoDIR deals with object motion by including a deep registration module jointly trained with the deep reconstruction network without any ground-truth supervision. We validate MoDIR on both simulated and experimentally collected magnetic resonance imaging (MRI) data and show that it significantly improves imaging quality.
Waveform Design and Performance Analysis for Full-Duplex Integrated Sensing and Communication
Aug 14, 2021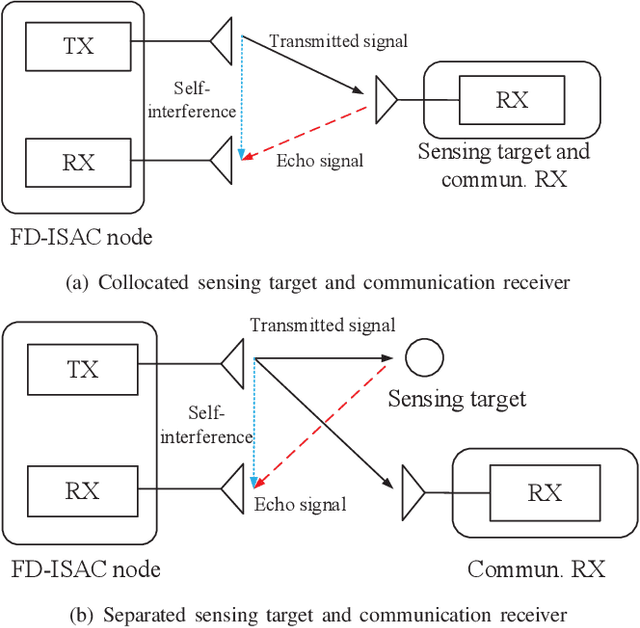
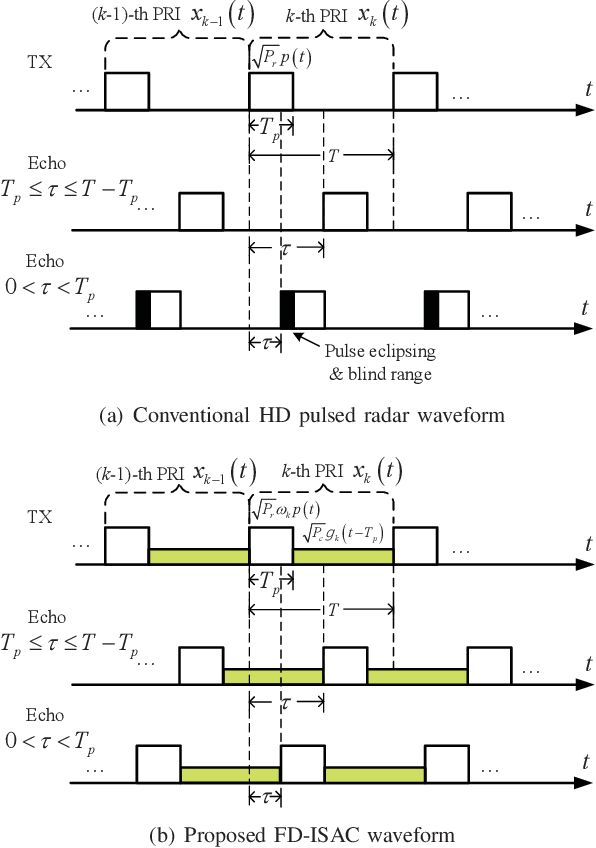
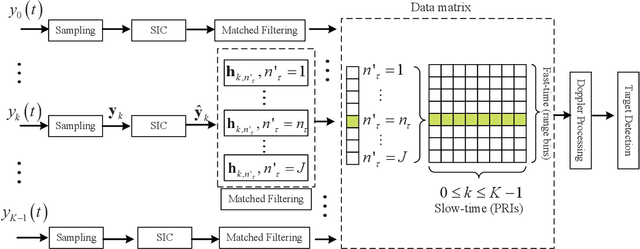
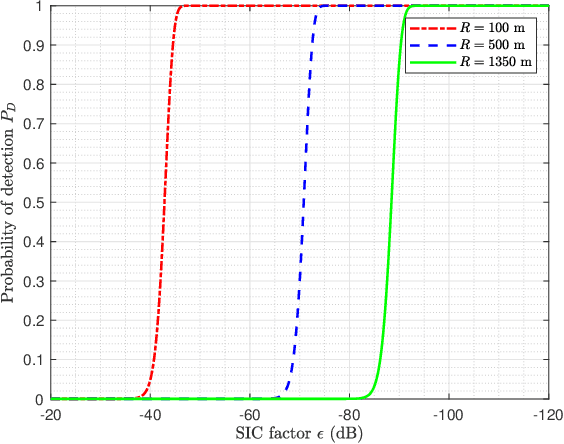
Integrated sensing and communication (ISAC) is a promising technology to fully utilize the precious spectrum and hardware in wireless systems, which has attracted significant attentions recently. This paper studies ISAC for the important and challenging monostatic setup, where one single ISAC node wishes to simultaneously sense a radar target while communicating with a communication receiver. Different from most existing schemes that rely on either radar-centric half-duplex (HD) pulsed transmission with information embedding that suffers from extremely low communication rate, or communication-centric waveform that suffers from degraded sensing performance, we propose a novel full-duplex (FD) ISAC scheme that utilizes the waiting time of conventional pulsed radars to transmit dedicated communication signals. Compared to radar-centric pulsed waveform with information embedding, the proposed design can drastically increase the communication rate, and also mitigate the sensing eclipsing and near-target blind range issues, as long as the self-interference (SI) is effectively suppressed. On the other hand, compared to communication-centric ISAC waveform, the proposed design has better auto-correlation property as it preserves the classic radar waveform for sensing. Performance analysis is developed by taking into account the residual SI, in terms of the probability of detection and ambiguity function for sensing, as well as the spectrum efficiency for communication. Numerical results are provided to show the significant performance gain of our proposed design over benchmark schemes.
Using Known Information to Accelerate HyperParameters Optimization Based on SMBO
Nov 08, 2018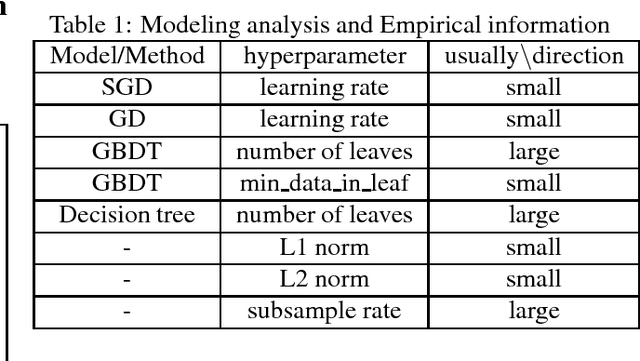
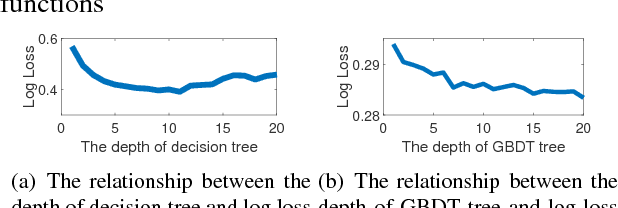
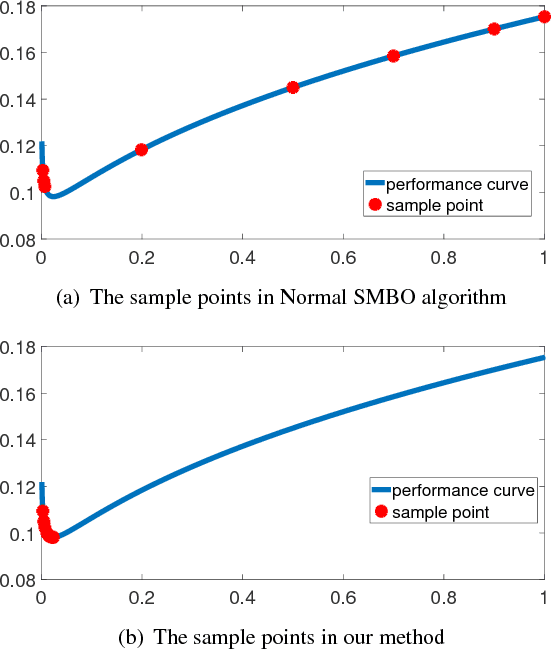
Automl is the key technology for machine learning problem. Current state of art hyperparameter optimization methods are based on traditional black-box optimization methods like SMBO (SMAC, TPE). The objective function of black-box optimization is non-smooth, or time-consuming to evaluate, or in some way noisy. Recent years, many researchers offered the work about the properties of hyperparameters. However, traditional hyperparameter optimization methods do not take those information into consideration. In this paper, we use gradient information and machine learning model analysis information to accelerate traditional hyperparameter optimization methods SMBO. In our L2 norm experiments, our method yielded state-of-the-art performance, and in many cases outperformed the previous best configuration approach.
Simplified Belief-Dependent Reward MCTS Planning with Guaranteed Tree Consistency
May 29, 2021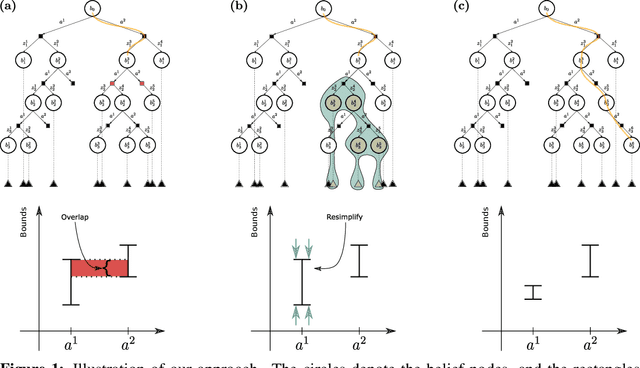
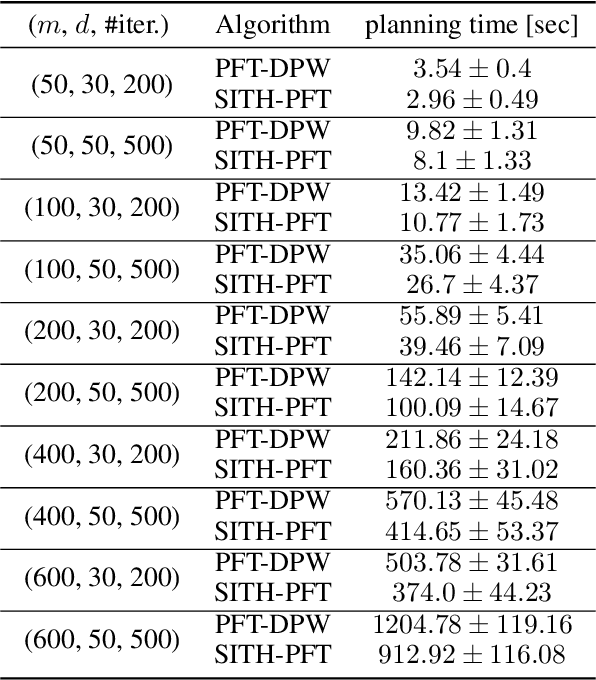
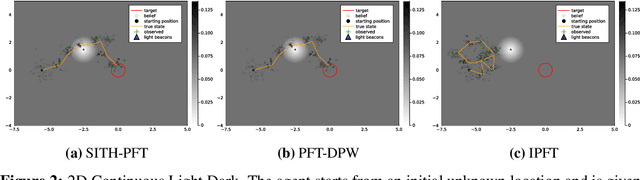
Partially Observable Markov Decision Processes (POMDPs) are notoriously hard to solve. Most advanced state-of-the-art online solvers leverage ideas of Monte Carlo Tree Search (MCTS). These solvers rapidly converge to the most promising branches of the belief tree, avoiding the suboptimal sections. Most of these algorithms are designed to utilize straightforward access to the state reward and assume the belief-dependent reward is nothing but expectation over the state reward. Thus, they are inapplicable to a more general and essential setting of belief-dependent rewards. One example of such reward is differential entropy approximated using a set of weighted particles of the belief. Such an information-theoretic reward introduces a significant computational burden. In this paper, we embed the paradigm of simplification into the MCTS algorithm. In particular, we present Simplified Information-Theoretic Particle Filter Tree (SITH-PFT), a novel variant to the MCTS algorithm that considers information-theoretic rewards but avoids the need to calculate them completely. We replace the costly calculation of information-theoretic rewards with adaptive upper and lower bounds. These bounds are easy to calculate and tightened only by the demand of our algorithm. Crucially, we guarantee precisely the same belief tree and solution that would be obtained by MCTS, which explicitly calculates the original information-theoretic rewards. Our approach is general; namely, any converging to the reward bounds can be easily plugged-in to achieve substantial speedup without any loss in performance.
Privacy Policy Question Answering Assistant: A Query-Guided Extractive Summarization Approach
Sep 29, 2021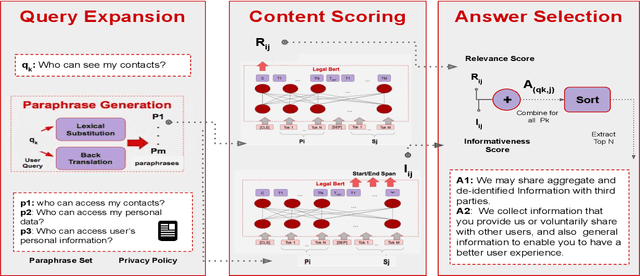


Existing work on making privacy policies accessible has explored new presentation forms such as color-coding based on the risk factors or summarization to assist users with conscious agreement. To facilitate a more personalized interaction with the policies, in this work, we propose an automated privacy policy question answering assistant that extracts a summary in response to the input user query. This is a challenging task because users articulate their privacy-related questions in a very different language than the legal language of the policy, making it difficult for the system to understand their inquiry. Moreover, existing annotated data in this domain are limited. We address these problems by paraphrasing to bring the style and language of the user's question closer to the language of privacy policies. Our content scoring module uses the existing in-domain data to find relevant information in the policy and incorporates it in a summary. Our pipeline is able to find an answer for 89% of the user queries in the privacyQA dataset.
Transfer Learning for Mining Feature Requests and Bug Reports from Tweets and App Store Reviews
Aug 02, 2021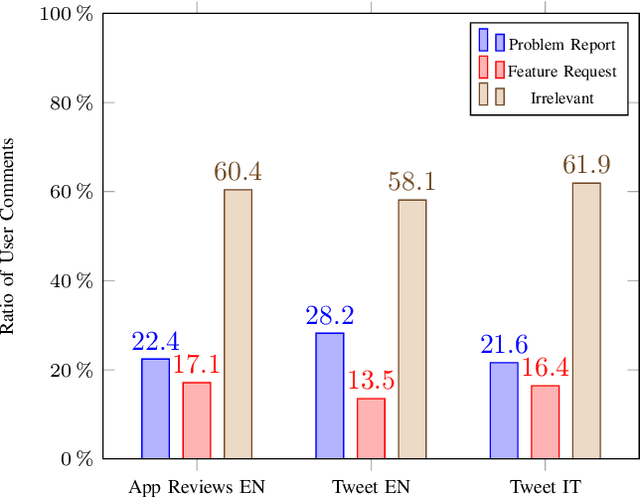
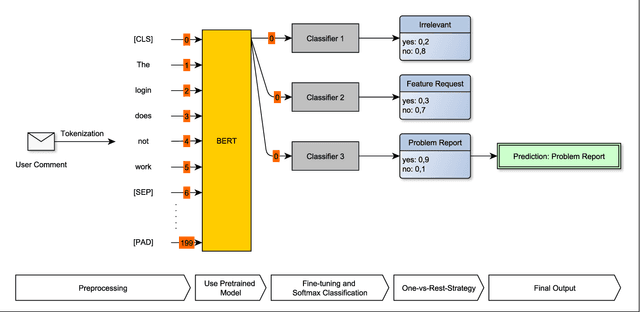
Identifying feature requests and bug reports in user comments holds great potential for development teams. However, automated mining of RE-related information from social media and app stores is challenging since (1) about 70% of user comments contain noisy, irrelevant information, (2) the amount of user comments grows daily making manual analysis unfeasible, and (3) user comments are written in different languages. Existing approaches build on traditional machine learning (ML) and deep learning (DL), but fail to detect feature requests and bug reports with high Recall and acceptable Precision which is necessary for this task. In this paper, we investigate the potential of transfer learning (TL) for the classification of user comments. Specifically, we train both monolingual and multilingual BERT models and compare the performance with state-of-the-art methods. We found that monolingual BERT models outperform existing baseline methods in the classification of English App Reviews as well as English and Italian Tweets. However, we also observed that the application of heavyweight TL models does not necessarily lead to better performance. In fact, our multilingual BERT models perform worse than traditional ML methods.
Explore before Moving: A Feasible Path Estimation and Memory Recalling Framework for Embodied Navigation
Oct 16, 2021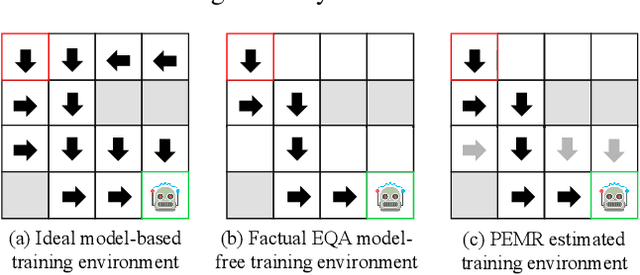
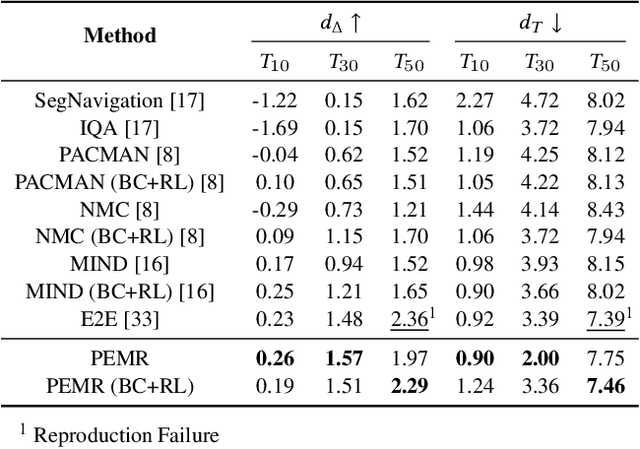
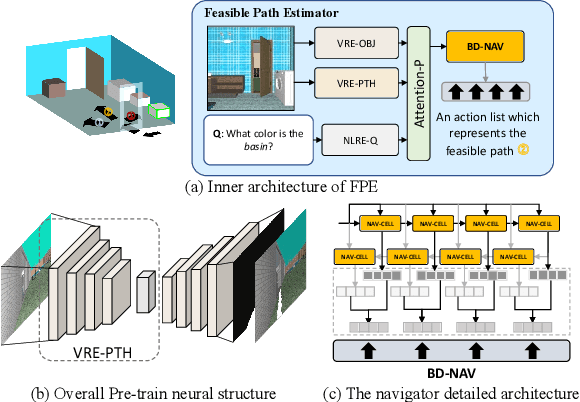
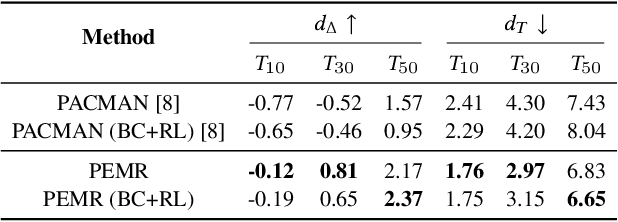
An embodied task such as embodied question answering (EmbodiedQA), requires an agent to explore the environment and collect clues to answer a given question that related with specific objects in the scene. The solution of such task usually includes two stages, a navigator and a visual Q&A module. In this paper, we focus on the navigation and solve the problem of existing navigation algorithms lacking experience and common sense, which essentially results in a failure finding target when robot is spawn in unknown environments. Inspired by the human ability to think twice before moving and conceive several feasible paths to seek a goal in unfamiliar scenes, we present a route planning method named Path Estimation and Memory Recalling (PEMR) framework. PEMR includes a "looking ahead" process, \textit{i.e.} a visual feature extractor module that estimates feasible paths for gathering 3D navigational information, which is mimicking the human sense of direction. PEMR contains another process ``looking behind'' process that is a memory recall mechanism aims at fully leveraging past experience collected by the feature extractor. Last but not the least, to encourage the navigator to learn more accurate prior expert experience, we improve the original benchmark dataset and provide a family of evaluation metrics for diagnosing both navigation and question answering modules. We show strong experimental results of PEMR on the EmbodiedQA navigation task.