 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Counterfactual Interventions Reveal the Causal Effect of Relative Clause Representations on Agreement Prediction
May 19, 2021
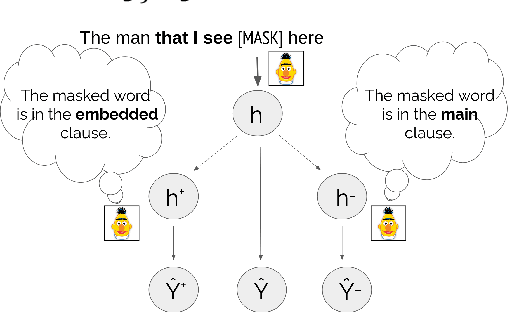

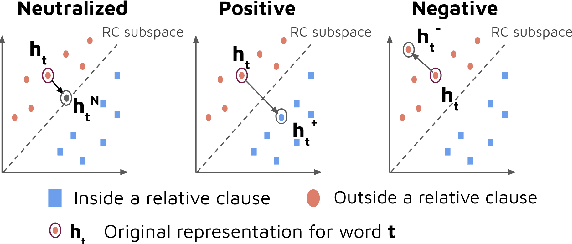
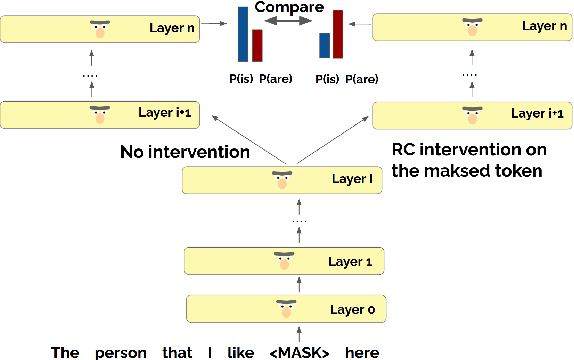
When language models process syntactically complex sentences, do they use abstract syntactic information present in these sentences in a manner that is consistent with the grammar of English, or do they rely solely on a set of heuristics? We propose a method to tackle this question, AlterRep. For any linguistic feature in the sentence, AlterRep allows us to generate counterfactual representations by altering how this feature is encoded, while leaving all other aspects of the original representation intact. Then, by measuring the change in a models' word prediction with these counterfactual representations in different sentences, we can draw causal conclusions about the contexts in which the model uses the linguistic feature (if any). Applying this method to study how BERT uses relative clause (RC) span information, we found that BERT uses information about RC spans during agreement prediction using the linguistically correct strategy. We also found that counterfactual representations generated for a specific RC subtype influenced the number prediction in sentences with other RC subtypes, suggesting that information about RC boundaries was encoded abstractly in BERT's representation.
CAMul: Calibrated and Accurate Multi-view Time-Series Forecasting
Sep 15, 2021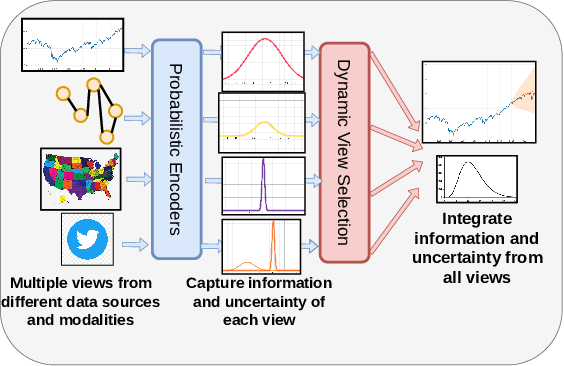
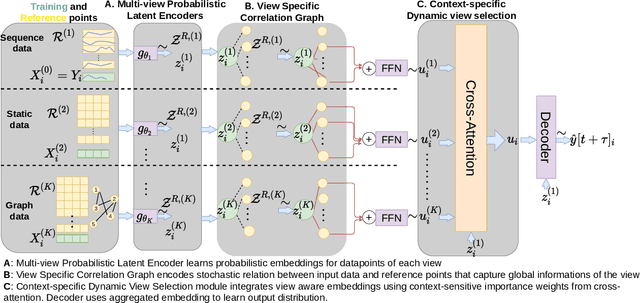

Probabilistic time-series forecasting enables reliable decision making across many domains. Most forecasting problems have diverse sources of data containing multiple modalities and structures. Leveraging information as well as uncertainty from these data sources for well-calibrated and accurate forecasts is an important challenging problem. Most previous work on multi-modal learning and forecasting simply aggregate intermediate representations from each data view by simple methods of summation or concatenation and do not explicitly model uncertainty for each data-view. We propose a general probabilistic multi-view forecasting framework CAMul, that can learn representations and uncertainty from diverse data sources. It integrates the knowledge and uncertainty from each data view in a dynamic context-specific manner assigning more importance to useful views to model a well-calibrated forecast distribution. We use CAMul for multiple domains with varied sources and modalities and show that CAMul outperforms other state-of-art probabilistic forecasting models by over 25\% in accuracy and calibration.
Exploratory State Representation Learning
Sep 28, 2021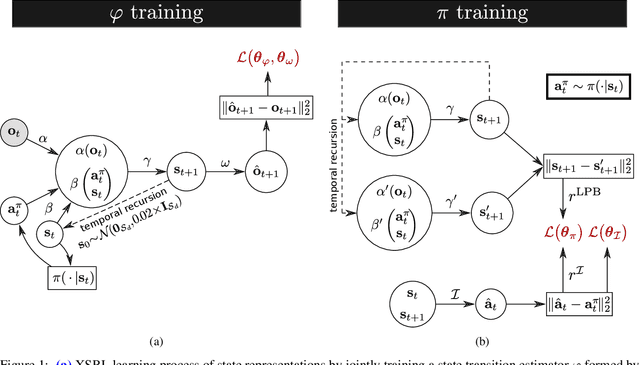
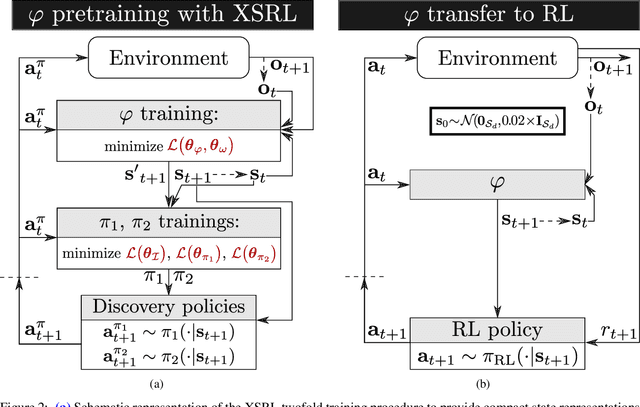

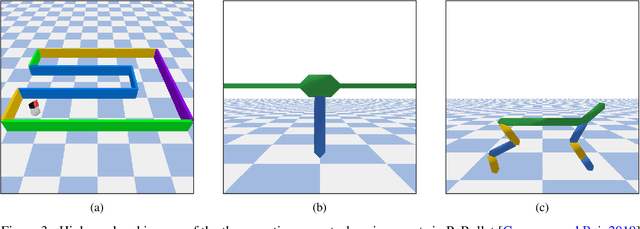
Not having access to compact and meaningful representations is known to significantly increase the complexity of reinforcement learning (RL). For this reason, it can be useful to perform state representation learning (SRL) before tackling RL tasks. However, obtaining a good state representation can only be done if a large diversity of transitions is observed, which can require a difficult exploration, especially if the environment is initially reward-free. To solve the problems of exploration and SRL in parallel, we propose a new approach called XSRL (eXploratory State Representation Learning). On one hand, it jointly learns compact state representations and a state transition estimator which is used to remove unexploitable information from the representations. On the other hand, it continuously trains an inverse model, and adds to the prediction error of this model a $k$-step learning progress bonus to form the maximization objective of a discovery policy. This results in a policy that seeks complex transitions from which the trained models can effectively learn. Our experimental results show that the approach leads to efficient exploration in challenging environments with image observations, and to state representations that significantly accelerate learning in RL tasks.
Why So Down? The Role of Negative (and Positive) Pointwise Mutual Information in Distributional Semantics
Aug 19, 2019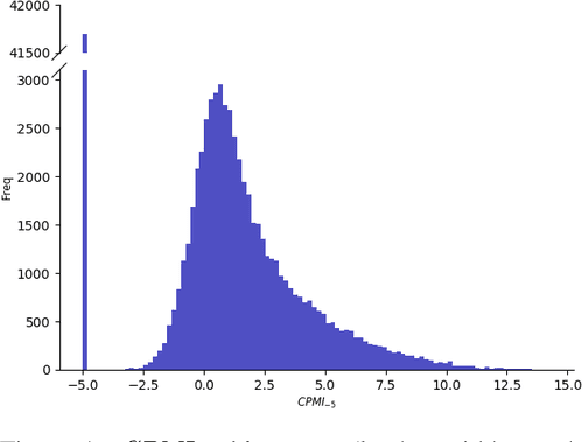
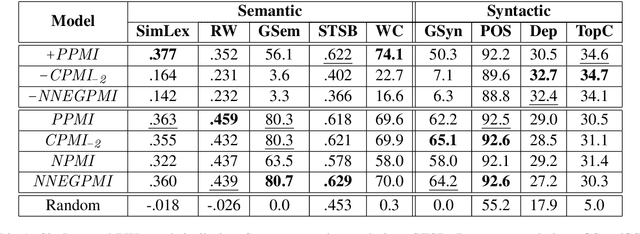
In distributional semantics, the pointwise mutual information ($\mathit{PMI}$) weighting of the cooccurrence matrix performs far better than raw counts. There is, however, an issue with unobserved pair cooccurrences as $\mathit{PMI}$ goes to negative infinity. This problem is aggravated by unreliable statistics from finite corpora which lead to a large number of such pairs. A common practice is to clip negative $\mathit{PMI}$ ($\mathit{\texttt{-} PMI}$) at $0$, also known as Positive $\mathit{PMI}$ ($\mathit{PPMI}$). In this paper, we investigate alternative ways of dealing with $\mathit{\texttt{-} PMI}$ and, more importantly, study the role that negative information plays in the performance of a low-rank, weighted factorization of different $\mathit{PMI}$ matrices. Using various semantic and syntactic tasks as probes into models which use either negative or positive $\mathit{PMI}$ (or both), we find that most of the encoded semantics and syntax come from positive $\mathit{PMI}$, in contrast to $\mathit{\texttt{-} PMI}$ which contributes almost exclusively syntactic information. Our findings deepen our understanding of distributional semantics, while also introducing novel $PMI$ variants and grounding the popular $PPMI$ measure.
Unsupervised Shot Boundary Detection for Temporal Segmentation of Long Capsule Endoscopy Videos
Oct 18, 2021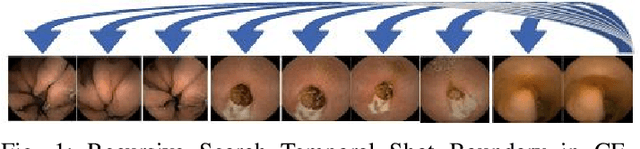
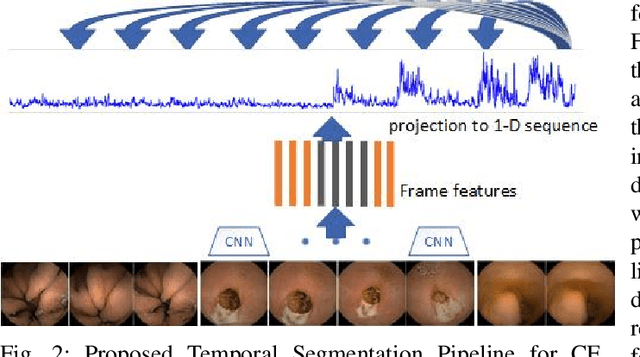
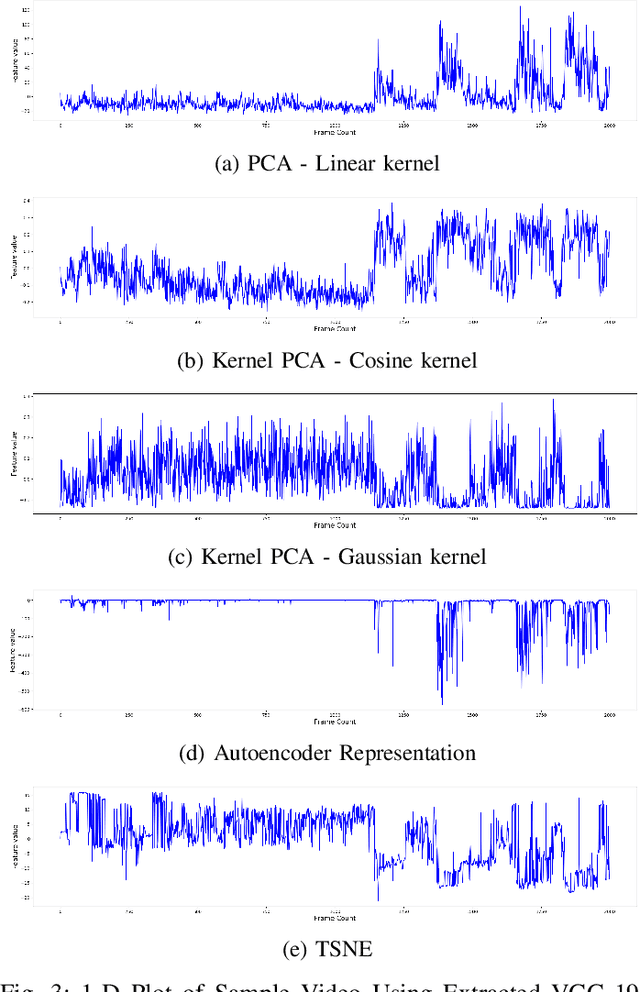
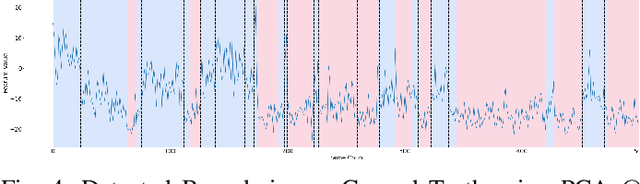
Physicians use Capsule Endoscopy (CE) as a non-invasive and non-surgical procedure to examine the entire gastrointestinal (GI) tract for diseases and abnormalities. A single CE examination could last between 8 to 11 hours generating up to 80,000 frames which is compiled as a video. Physicians have to review and analyze the entire video to identify abnormalities or diseases before making diagnosis. This review task can be very tedious, time consuming and prone to error. While only as little as a single frame may capture useful content that is relevant to the physicians' final diagnosis, frames covering the small bowel region alone could be as much as 50,000. To minimize physicians' review time and effort, this paper proposes a novel unsupervised and computationally efficient temporal segmentation method to automatically partition long CE videos into a homogeneous and identifiable video segments. However, the search for temporal boundaries in a long video using high dimensional frame-feature matrix is computationally prohibitive and impracticable for real clinical application. Therefore, leveraging both spatial and temporal information in the video, we first extracted high level frame features using a pretrained CNN model and then projected the high-dimensional frame-feature matrix to lower 1-dimensional embedding. Using this 1-dimensional sequence embedding, we applied the Pruned Exact Linear Time (PELT) algorithm to searched for temporal boundaries that indicates the transition points from normal to abnormal frames and vice-versa. We experimented with multiple real patients' CE videos and our model achieved an AUC of 66\% on multiple test videos against expert provided labels.
Multi-Lead ECG Classification via an Information-Based Attention Convolutional Neural Network
Mar 25, 2020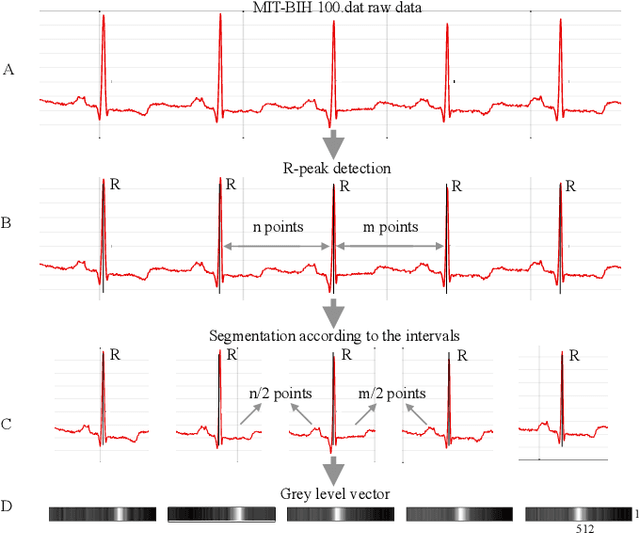
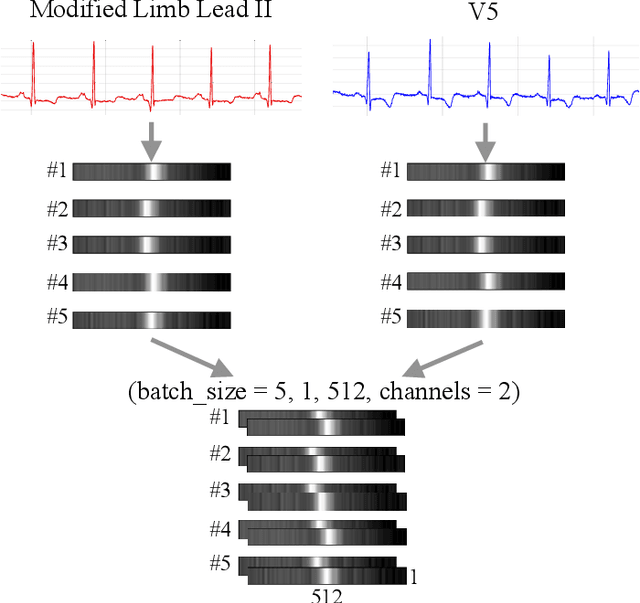

Objective: A novel structure based on channel-wise attention mechanism is presented in this paper. Embedding with the proposed structure, an efficient classification model that accepts multi-lead electrocardiogram (ECG) as input is constructed. Methods: One-dimensional convolutional neural networks (CNN) have proven to be effective in pervasive classification tasks, enabling the automatic extraction of features while classifying targets. We implement the Residual connection and design a structure which can learn the weights from the information contained in different channels in the input feature map during the training process. An indicator named mean square deviation is introduced to monitor the performance of a particular model segment in the classification task on the two out of the five ECG classes. The data in the MIT-BIH arrhythmia database is used and a series of control experiments is conducted. Results: Utilizing both leads of the ECG signals as input to the neural network classifier can achieve better classification results than those from using single channel inputs in different application scenarios. Models embedded with the channel-wise attention structure always achieve better scores on sensitivity and precision than the plain Resnet models. The proposed model exceeds the performance of most of the state-of-the-art models in ventricular ectopic beats (VEB) classification, and achieves competitive scores for supraventricular ectopic beats (SVEB). Conclusion: Adopting more lead ECG signals as input can increase the dimensions of the input feature maps, helping to improve both the performance and generalization of the network model. Significance: Due to its end-to-end characteristics, and the extensible intrinsic for multi-lead heart diseases diagnosing, the proposed model can be used for the real-time ECG tracking of ECG waveforms for Holter or wearable devices.
Investigating and Modeling the Dynamics of Long Ties
Sep 22, 2021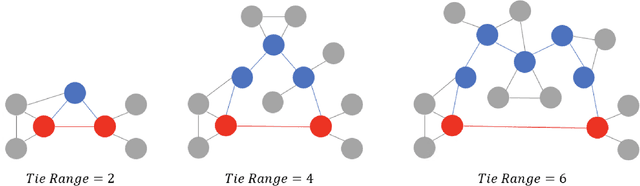
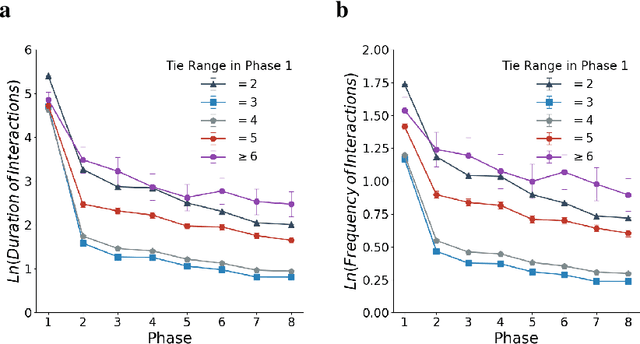
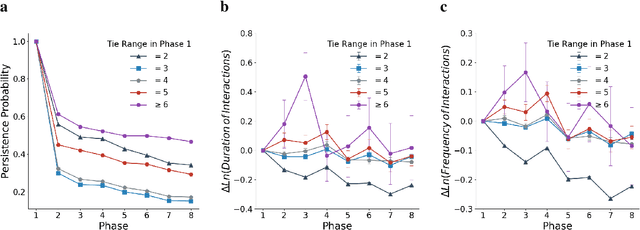
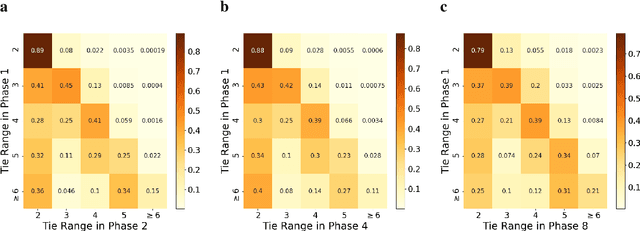
Long ties, the social ties that bridge different communities, are widely believed to play crucial roles in spreading novel information in social networks. However, some existing network theories and prediction models indicate that long ties might dissolve quickly or eventually become redundant, thus putting into question the long-term value of long ties. Our empirical analysis of real-world dynamic networks shows that contrary to such reasoning, long ties are more likely to persist than other social ties, and that many of them constantly function as social bridges without being embedded in local networks. Using a novel cost-benefit analysis model combined with machine learning, we show that long ties are highly beneficial, which instinctively motivates people to expend extra effort to maintain them. This partly explains why long ties are more persistent than what has been suggested by many existing theories and models. Overall, our study suggests the need for social interventions that can promote the formation of long ties, such as mixing people with diverse backgrounds.
AudioVisual Video Summarization
May 17, 2021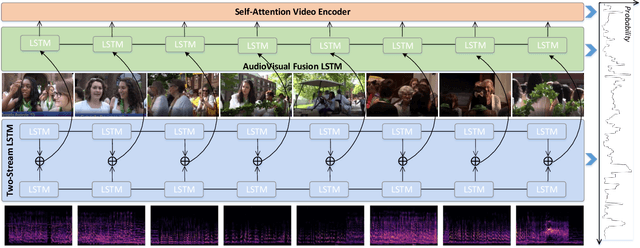
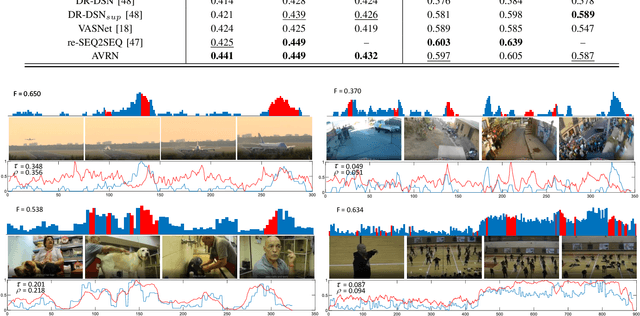
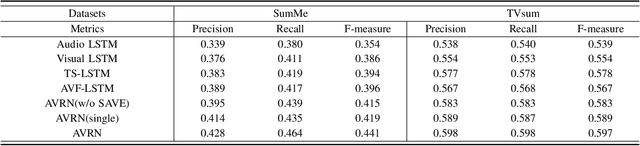
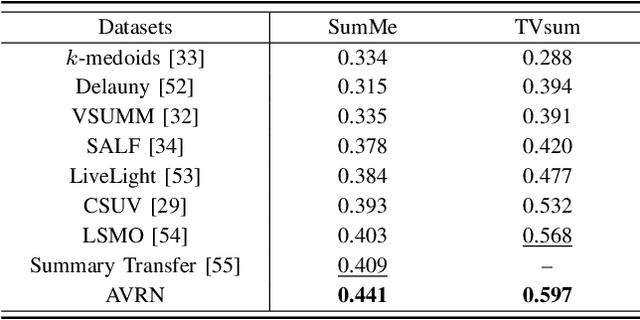
Audio and vision are two main modalities in video data. Multimodal learning, especially for audiovisual learning, has drawn considerable attention recently, which can boost the performance of various computer vision tasks. However, in video summarization, existing approaches just exploit the visual information while neglect the audio information. In this paper, we argue that the audio modality can assist vision modality to better understand the video content and structure, and further benefit the summarization process. Motivated by this, we propose to jointly exploit the audio and visual information for the video summarization task, and develop an AudioVisual Recurrent Network (AVRN) to achieve this. Specifically, the proposed AVRN can be separated into three parts: 1) the two-stream LSTM is utilized to encode the audio and visual feature sequentially by capturing their temporal dependency. 2) the audiovisual fusion LSTM is employed to fuse the two modalities by exploring the latent consistency between them. 3) the self-attention video encoder is adopted to capture the global dependency in the video. Finally, the fused audiovisual information, and the integrated temporal and global dependencies are jointly used to predict the video summary. Practically, the experimental results on the two benchmarks, \emph{i.e.,} SumMe and TVsum, have demonstrated the effectiveness of each part, and the superiority of AVRN compared to those approaches just exploiting visual information for video summarization.
Output Space Entropy Search Framework for Multi-Objective Bayesian Optimization
Oct 13, 2021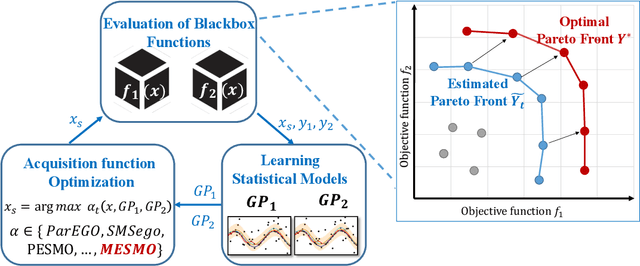
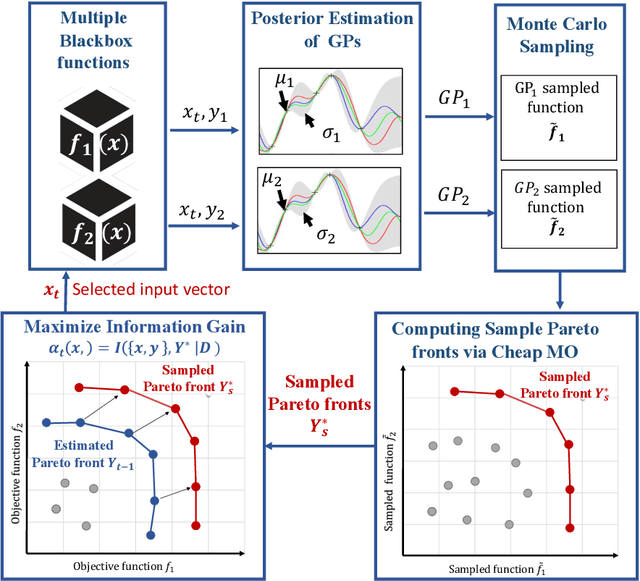
We consider the problem of black-box multi-objective optimization (MOO) using expensive function evaluations (also referred to as experiments), where the goal is to approximate the true Pareto set of solutions by minimizing the total resource cost of experiments. For example, in hardware design optimization, we need to find the designs that trade-off performance, energy, and area overhead using expensive computational simulations. The key challenge is to select the sequence of experiments to uncover high-quality solutions using minimal resources. In this paper, we propose a general framework for solving MOO problems based on the principle of output space entropy (OSE) search: select the experiment that maximizes the information gained per unit resource cost about the true Pareto front. We appropriately instantiate the principle of OSE search to derive efficient algorithms for the following four MOO problem settings: 1) The most basic em single-fidelity setting, where experiments are expensive and accurate; 2) Handling em black-box constraints} which cannot be evaluated without performing experiments; 3) The discrete multi-fidelity setting, where experiments can vary in the amount of resources consumed and their evaluation accuracy; and 4) The em continuous-fidelity setting, where continuous function approximations result in a huge space of experiments. Experiments on diverse synthetic and real-world benchmarks show that our OSE search based algorithms improve over state-of-the-art methods in terms of both computational-efficiency and accuracy of MOO solutions.
* Accepted to Journal of Artificial Intelligence Research. arXiv admin note: substantial text overlap with arXiv:2009.05700, arXiv:2009.01721, arXiv:2011.01542
Object-Region Video Transformers
Oct 13, 2021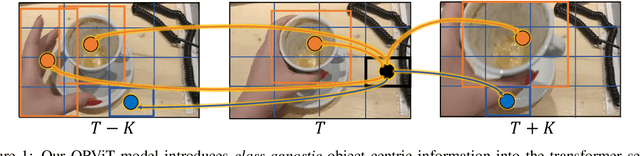
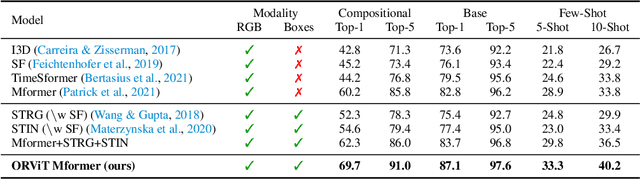
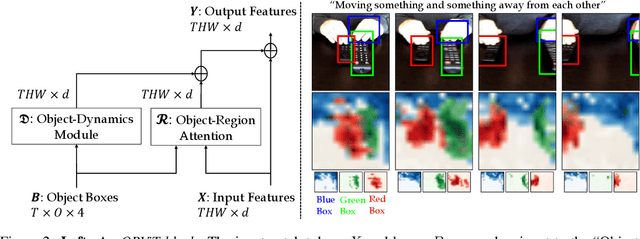
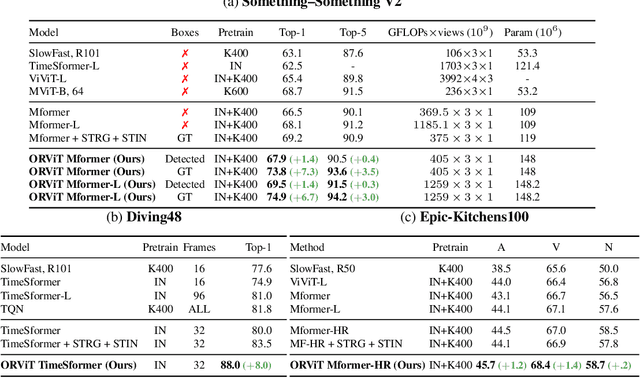
Evidence from cognitive psychology suggests that understanding spatio-temporal object interactions and dynamics can be essential for recognizing actions in complex videos. Therefore, action recognition models are expected to benefit from explicit modeling of objects, including their appearance, interaction, and dynamics. Recently, video transformers have shown great success in video understanding, exceeding CNN performance. Yet, existing video transformer models do not explicitly model objects. In this work, we present Object-Region Video Transformers (ORViT), an \emph{object-centric} approach that extends video transformer layers with a block that directly incorporates object representations. The key idea is to fuse object-centric spatio-temporal representations throughout multiple transformer layers. Our ORViT block consists of two object-level streams: appearance and dynamics. In the appearance stream, an ``Object-Region Attention'' element applies self-attention over the patches and \emph{object regions}. In this way, visual object regions interact with uniform patch tokens and enrich them with contextualized object information. We further model object dynamics via a separate ``Object-Dynamics Module'', which captures trajectory interactions, and show how to integrate the two streams. We evaluate our model on standard and compositional action recognition on Something-Something V2, standard action recognition on Epic-Kitchen100 and Diving48, and spatio-temporal action detection on AVA. We show strong improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a transformer architecture. For code and pretrained models, visit the project page at https://roeiherz.github.io/ORViT/.