 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal Knowledge Graph Reasoning Triggered by Memories
Oct 17, 2021
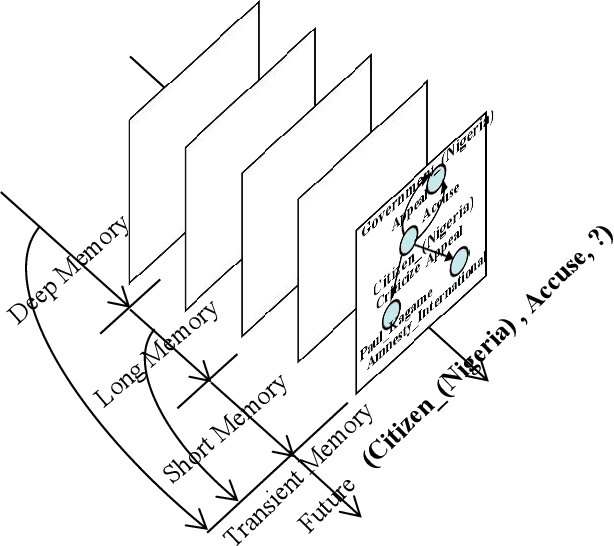
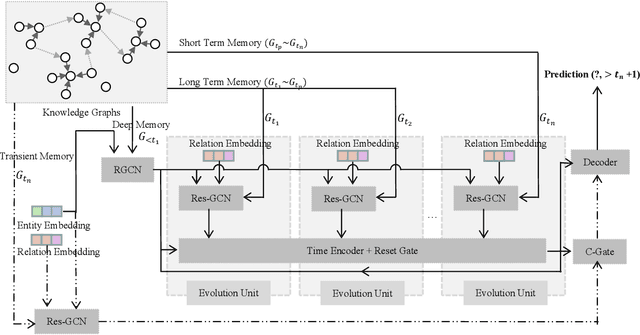
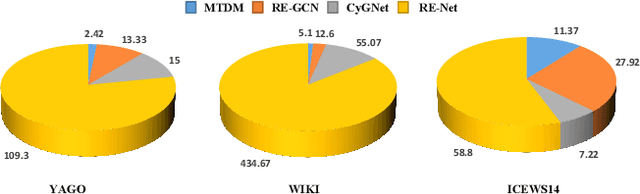
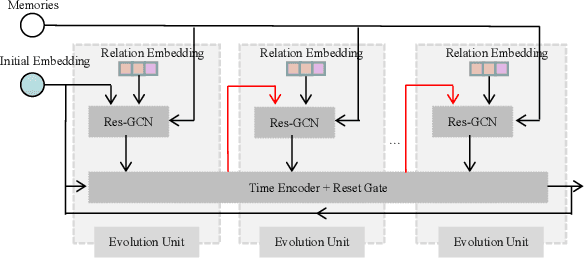
Inferring missing facts in temporal knowledge graphs is a critical task and has been widely explored. Extrapolation in temporal reasoning tasks is more challenging and gradually attracts the attention of researchers since no direct history facts for prediction. Previous works attempted to apply evolutionary representation learning to solve the extrapolation problem. However, these techniques do not explicitly leverage various time-aware attribute representations, i.e. the reasoning performance is significantly affected by the history length. To alleviate the time dependence when reasoning future missing facts, we propose a memory-triggered decision-making (MTDM) network, which incorporates transient memories, long-short-term memories, and deep memories. Specifically, the transient learning network considers transient memories as a static knowledge graph, and the time-aware recurrent evolution network learns representations through a sequence of recurrent evolution units from long-short-term memories. Each evolution unit consists of a structural encoder to aggregate edge information, a time encoder with a gating unit to update attribute representations of entities. MTDM utilizes the crafted residual multi-relational aggregator as the structural encoder to solve the multi-hop coverage problem. We also introduce the dissolution learning constraint for better understanding the event dissolution process. Extensive experiments demonstrate the MTDM alleviates the history dependence and achieves state-of-the-art prediction performance. Moreover, compared with the most advanced baseline, MTDM shows a faster convergence speed and training speed.
Safe, Deterministic Trajectory Planning for Unstructured and Partially Occluded Environments
Sep 30, 2021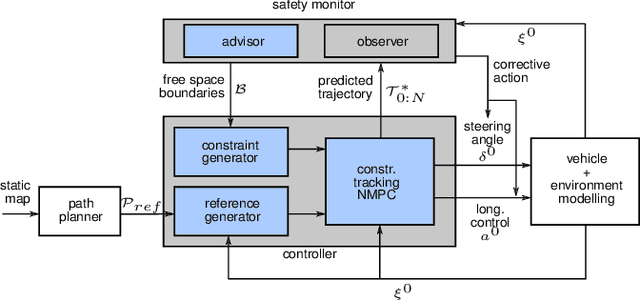

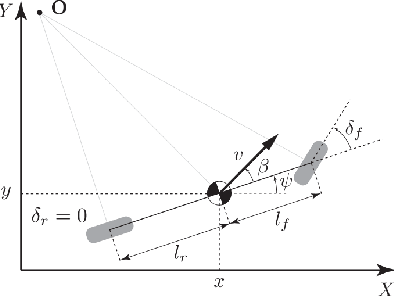
Ensuring safe behavior for automated vehicles in unregulated traffic areas poses a complex challenge for the industry. It is an open problem to provide scalable and certifiable solutions to this challenge. We derive a trajectory planner based on model predictive control which interoperates with a monitoring system for pedestrian safety based on cellular automata. The combined planner-monitor system is demonstrated on the example of a narrow indoor parking environment. The system features deterministic behavior, mitigating the immanent risk of black boxes and offering full certifiability. By using fundamental and conservative prediction models of pedestrians the monitor is able to determine a safe drivable area in the partially occluded and unstructured parking environment. The information is fed to the trajectory planner which ensures the vehicle remains in the safe drivable area at any time through constrained optimization. We show how the approach enables solving plenty of situations in tight parking garage scenarios. Even though conservative prediction models are applied, evaluations indicate a performant system for the tested low-speed navigation.
Census-Independent Population Estimation using Representation Learning
Oct 06, 2021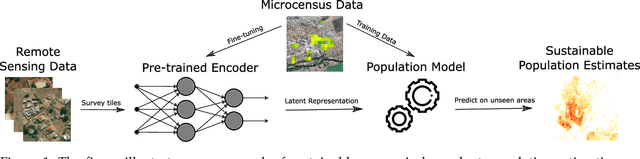
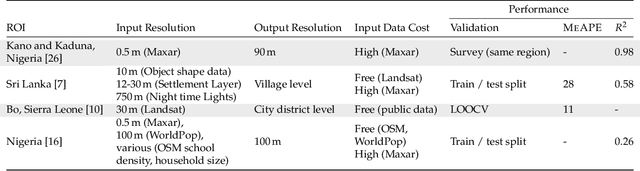

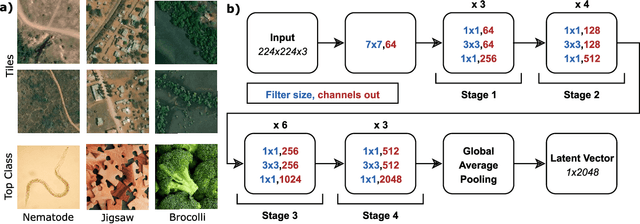
Knowledge of population distribution is critical for building infrastructure, distributing resources, and monitoring the progress of sustainable development goals. Although censuses can provide this information, they are typically conducted every ten years with some countries having forgone the process for several decades. Population can change in the intercensal period due to rapid migration, development, urbanisation, natural disasters, and conflicts. Census-independent population estimation approaches using alternative data sources, such as satellite imagery, have shown promise in providing frequent and reliable population estimates locally. Existing approaches, however, require significant human supervision, for example annotating buildings and accessing various public datasets, and therefore, are not easily reproducible. We explore recent representation learning approaches, and assess the transferability of representations to population estimation in Mozambique. Using representation learning reduces required human supervision, since features are extracted automatically, making the process of population estimation more sustainable and likely to be transferable to other regions or countries. We compare the resulting population estimates to existing population products from GRID3, Facebook (HRSL) and WorldPop. We observe that our approach matches the most accurate of these maps, and is interpretable in the sense that it recognises built-up areas to be an informative indicator of population.
Generic Bounds on the Maximum Deviations in Sequential Prediction: An Information-Theoretic Analysis
Oct 11, 2019In this paper, we derive generic bounds on the maximum deviations in prediction errors for sequential prediction via an information-theoretic approach. The fundamental bounds are shown to depend only on the conditional entropy of the data point to be predicted given the previous data points. In the asymptotic case, the bounds are achieved if and only if the prediction error is white and uniformly distributed.
Dynamic Feature Regularized Loss for Weakly Supervised Semantic Segmentation
Aug 03, 2021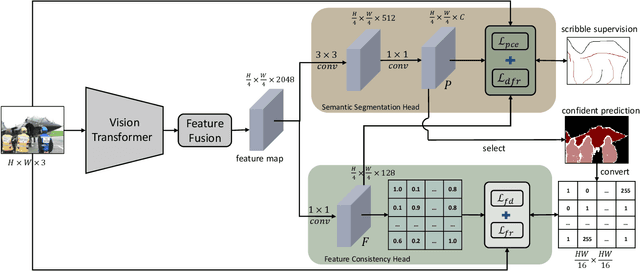
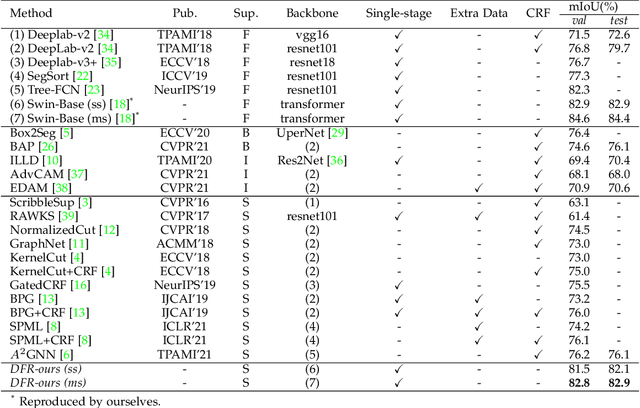
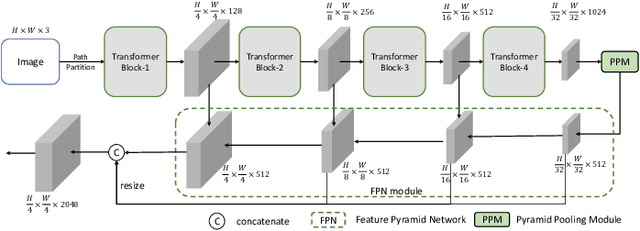

We focus on tackling weakly supervised semantic segmentation with scribble-level annotation. The regularized loss has been proven to be an effective solution for this task. However, most existing regularized losses only leverage static shallow features (color, spatial information) to compute the regularized kernel, which limits its final performance since such static shallow features fail to describe pair-wise pixel relationship in complicated cases. In this paper, we propose a new regularized loss which utilizes both shallow and deep features that are dynamically updated in order to aggregate sufficient information to represent the relationship of different pixels. Moreover, in order to provide accurate deep features, we adopt vision transformer as the backbone and design a feature consistency head to train the pair-wise feature relationship. Unlike most approaches that adopt multi-stage training strategy with many bells and whistles, our approach can be directly trained in an end-to-end manner, in which the feature consistency head and our regularized loss can benefit from each other. Extensive experiments show that our approach achieves new state-of-the-art performances, outperforming other approaches by a significant margin with more than 6\% mIoU increase.
Graph Fourier Transform based Audio Zero-watermarking
Sep 16, 2021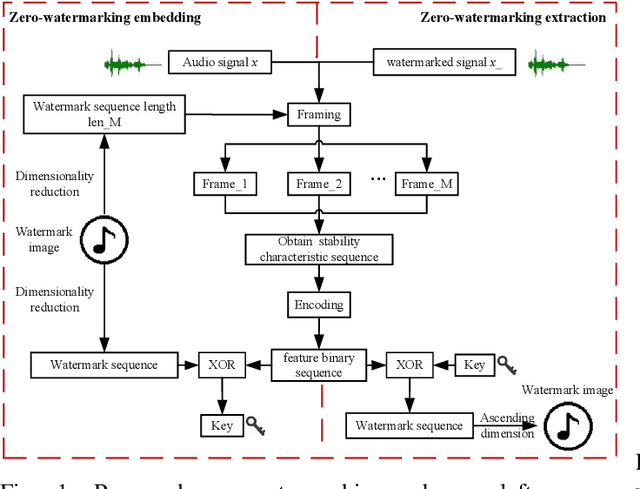
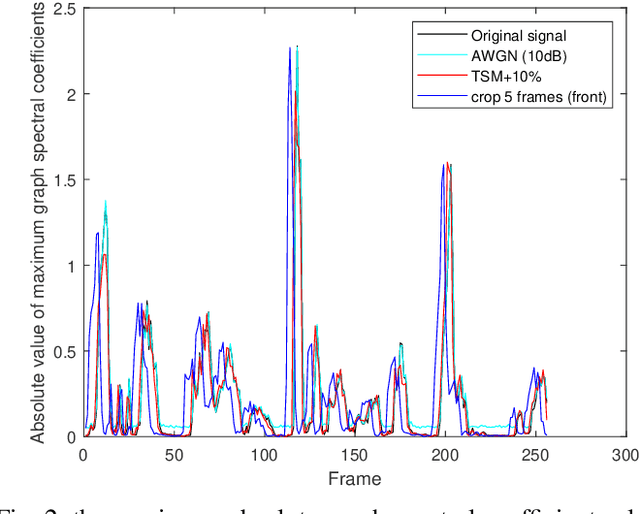


The frequent exchange of multimedia information in the present era projects an increasing demand for copyright protection. In this work, we propose a novel audio zero-watermarking technology based on graph Fourier transform for enhancing the robustness with respect to copyright protection. In this approach, the combined shift operator is used to construct the graph signal, upon which the graph Fourier analysis is performed. The selected maximum absolute graph Fourier coefficients representing the characteristics of the audio segment are then encoded into a feature binary sequence using K-means algorithm. Finally, the resultant feature binary sequence is XOR-ed with the watermark binary sequence to realize the embedding of the zero-watermarking. The experimental studies show that the proposed approach performs more effectively in resisting common or synchronization attacks than the existing state-of-the-art methods.
Adversarial Semantic Contour for Object Detection
Sep 30, 2021
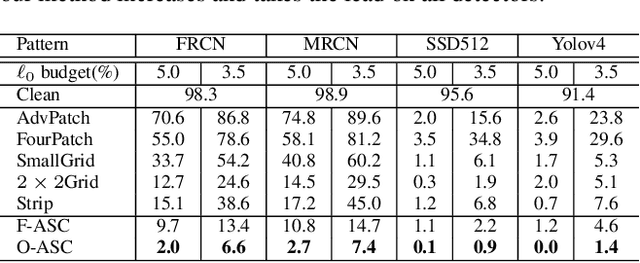

Modern object detectors are vulnerable to adversarial examples, which brings potential risks to numerous applications, e.g., self-driving car. Among attacks regularized by $\ell_p$ norm, $\ell_0$-attack aims to modify as few pixels as possible. Nevertheless, the problem is nontrivial since it generally requires to optimize the shape along with the texture simultaneously, which is an NP-hard problem. To address this issue, we propose a novel method of Adversarial Semantic Contour (ASC) guided by object contour as prior. With this prior, we reduce the searching space to accelerate the $\ell_0$ optimization, and also introduce more semantic information which should affect the detectors more. Based on the contour, we optimize the selection of modified pixels via sampling and their colors with gradient descent alternately. Extensive experiments demonstrate that our proposed ASC outperforms the most commonly manually designed patterns (e.g., square patches and grids) on task of disappearing. By modifying no more than 5\% and 3.5\% of the object area respectively, our proposed ASC can successfully mislead the mainstream object detectors including the SSD512, Yolov4, Mask RCNN, Faster RCNN, etc.
VoteHMR: Occlusion-Aware Voting Network for Robust 3D Human Mesh Recovery from Partial Point Clouds
Oct 17, 2021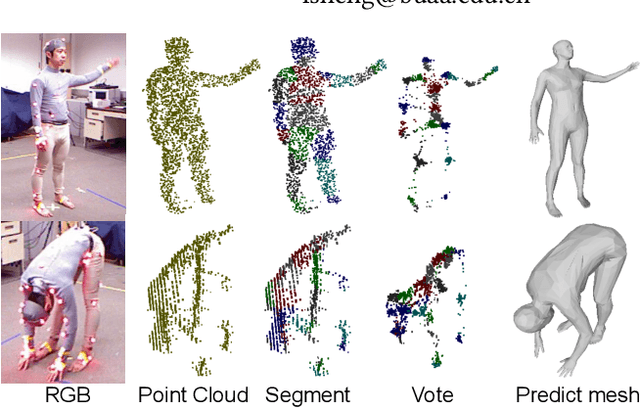
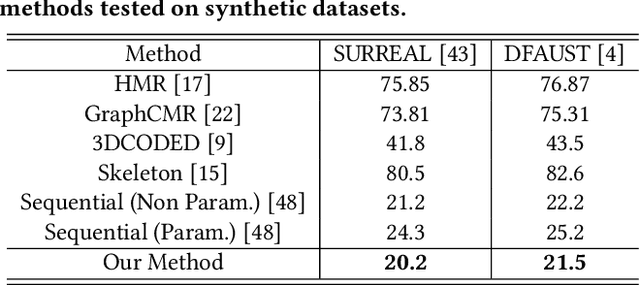
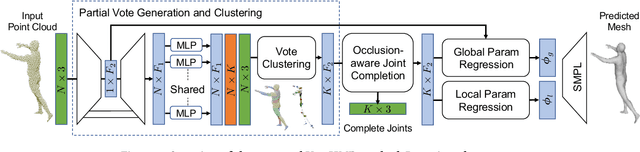
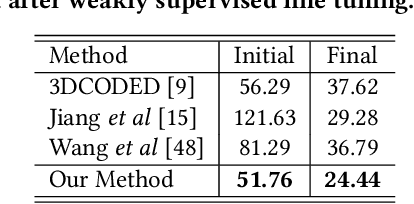
3D human mesh recovery from point clouds is essential for various tasks, including AR/VR and human behavior understanding. Previous works in this field either require high-quality 3D human scans or sequential point clouds, which cannot be easily applied to low-quality 3D scans captured by consumer-level depth sensors. In this paper, we make the first attempt to reconstruct reliable 3D human shapes from single-frame partial point clouds.To achieve this, we propose an end-to-end learnable method, named VoteHMR. The core of VoteHMR is a novel occlusion-aware voting network that can first reliably produce visible joint-level features from the input partial point clouds, and then complete the joint-level features through the kinematic tree of the human skeleton. Compared with holistic features used by previous works, the joint-level features can not only effectively encode the human geometry information but also be robust to noisy inputs with self-occlusions and missing areas. By exploiting the rich complementary clues from the joint-level features and global features from the input point clouds, the proposed method encourages reliable and disentangled parameter predictions for statistical 3D human models, such as SMPL. The proposed method achieves state-of-the-art performances on two large-scale datasets, namely SURREAL and DFAUST. Furthermore, VoteHMR also demonstrates superior generalization ability on real-world datasets, such as Berkeley MHAD.
Event and Activity Recognition in Video Surveillance for Cyber-Physical Systems
Nov 03, 2021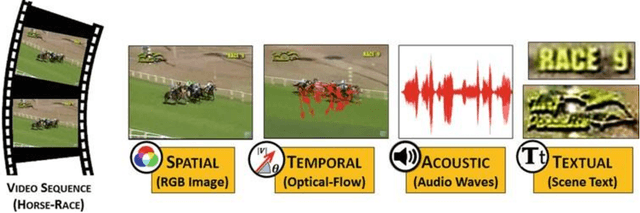
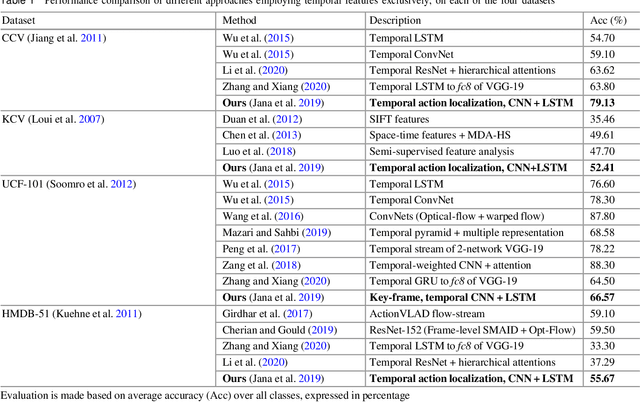

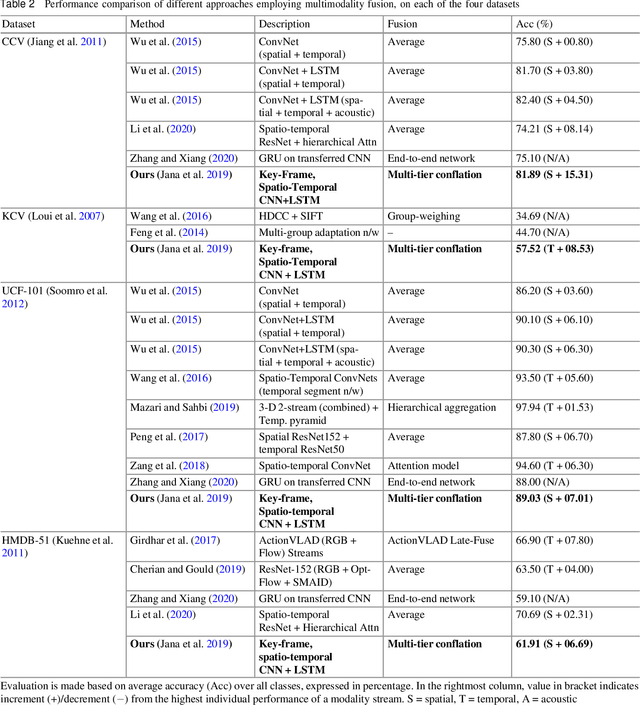
This chapter aims to aid the development of Cyber-Physical Systems (CPS) in automated understanding of events and activities in various applications of video-surveillance. These events are mostly captured by drones, CCTVs or novice and unskilled individuals on low-end devices. Being unconstrained, these videos are immensely challenging due to a number of quality factors. We present an extensive account of the various approaches taken to solve the problem over the years. This ranges from methods as early as Structure from Motion (SFM) based approaches to recent solution frameworks involving deep neural networks. We show that the long-term motion patterns alone play a pivotal role in the task of recognizing an event. Consequently each video is significantly represented by a fixed number of key-frames using a graph-based approach. Only the temporal features are exploited using a hybrid Convolutional Neural Network (CNN) + Recurrent Neural Network (RNN) architecture. The results we obtain are encouraging as they outperform standard temporal CNNs and are at par with those using spatial information along with motion cues. Further exploring multistream models, we conceive a multi-tier fusion strategy for the spatial and temporal wings of a network. A consolidated representation of the respective individual prediction vectors on video and frame levels is obtained using a biased conflation technique. The fusion strategy endows us with greater rise in precision on each stage as compared to the state-of-the-art methods, and thus a powerful consensus is achieved in classification. Results are recorded on four benchmark datasets widely used in the domain of action recognition, namely CCV, HMDB, UCF-101 and KCV. It is inferable that focusing on better classification of the video sequences certainly leads to robust actuation of a system designed for event surveillance and object cum activity tracking.
* This is a preprint of the chapter:S Bhaumik, P Jana, PP Mohanta, Event and Activity Recognition in Video Surveillance for Cyber-Physical Systems, published in Emergence of Cyber Physical System.., edited by KK Singh et al, 2021, Springer reproduced with permission of Springer Nature Switzerland AG. The final authenticated version is available online at http://dx.doi.org/10.1007/978-3-030-66222-6_4
Objective crystallographic symmetry classifications of noisy and noise-free 2D periodic patterns with strong Fedorov type pseudosymmetries
Aug 03, 2021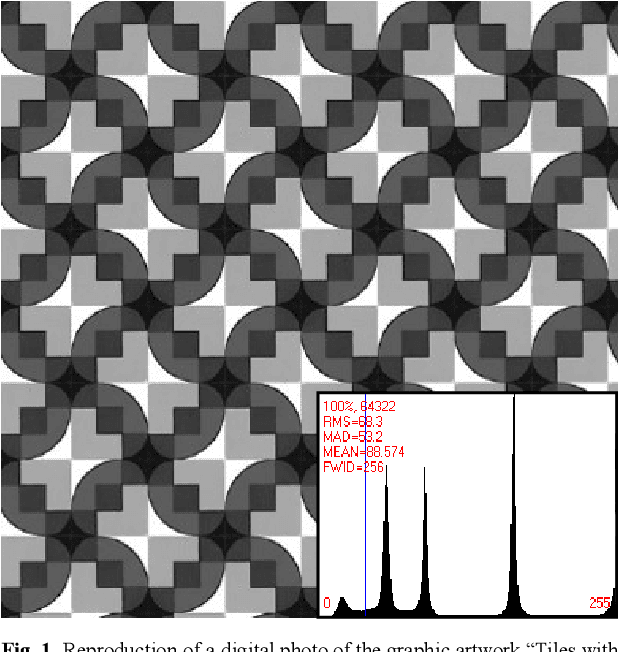

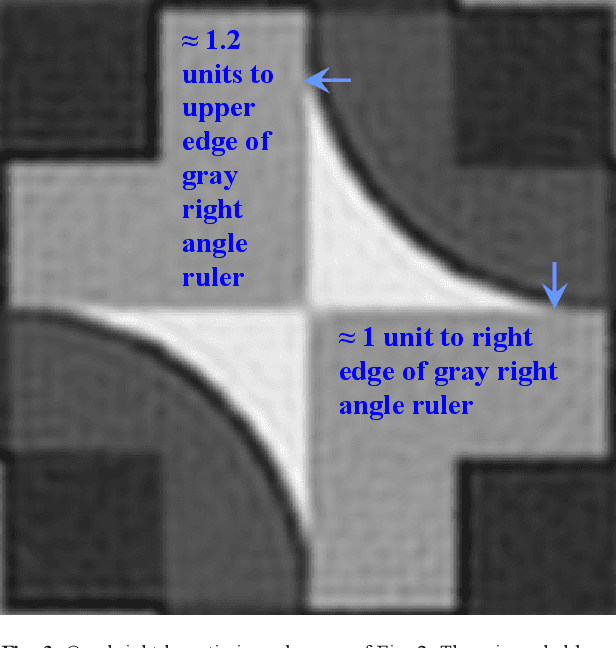
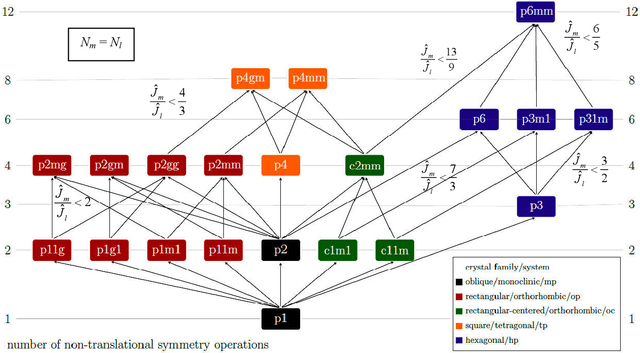
Statistically sound crystallographic symmetry classifications are obtained with information theory based methods in the presence of approximately Gaussian distributed noise. A set of three synthetic images with very strong Fedorov type pseudosymmetries and varying amounts of noise serve as examples. The correct distinctions between genuine symmetries and their Fedorov type pseudosymmetry counterparts failed only for the noisiest image of the series where an inconsistent combination of plane symmetry group and projected Laue class was obtained. Contrary to traditional crystallographic symmetry classifications with an image processing program such as CRISP, the classification process does not need to be supervised by a human being. This enables crystallographic symmetry classification of digital images that are more or less periodic in two dimensions (2D) as recorded with sufficient spatial resolution from a wide range of samples with different types of scanning probe microscopes. Alternatives to the employed objective classification methods as proposed by members of the computational symmetry community and machine learning proponents are briefly discussed in an appendix and are found to be wanting because they ignore Fedorov type pseudosymmetries completely. The information theory based methods are more accurate than visual classifications at first sight by most human experts.