 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GFINNs: GENERIC Formalism Informed Neural Networks for Deterministic and Stochastic Dynamical Systems
Aug 31, 2021
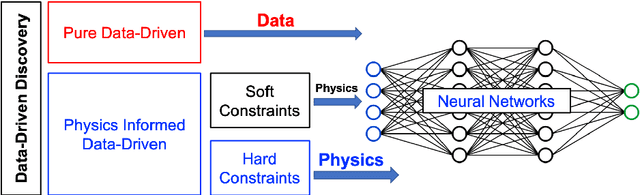

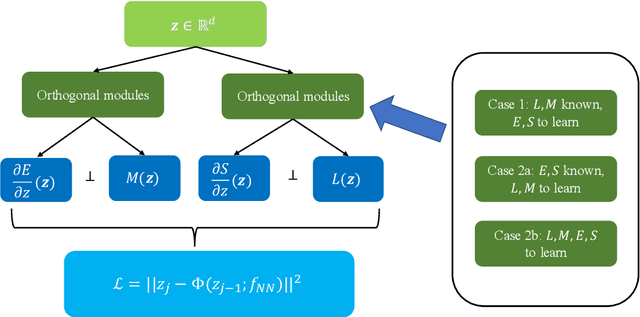
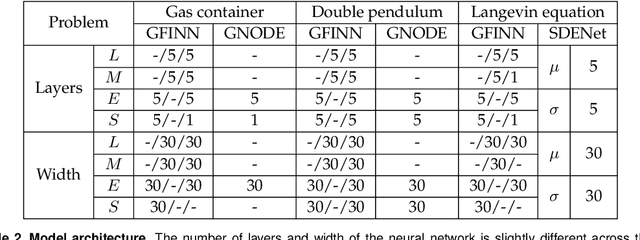
We propose the GENERIC formalism informed neural networks (GFINNs) that obey the symmetric degeneracy conditions of the GENERIC formalism. GFINNs comprise two modules, each of which contains two components. We model each component using a neural network whose architecture is designed to satisfy the required conditions. The component-wise architecture design provides flexible ways of leveraging available physics information into neural networks. We prove theoretically that GFINNs are sufficiently expressive to learn the underlying equations, hence establishing the universal approximation theorem. We demonstrate the performance of GFINNs in three simulation problems: gas containers exchanging heat and volume, thermoelastic double pendulum and the Langevin dynamics. In all the examples, GFINNs outperform existing methods, hence demonstrating good accuracy in predictions for both deterministic and stochastic systems.
Shaping the Narrative Arc: An Information-Theoretic Approach to Collaborative Dialogue
Jan 31, 2019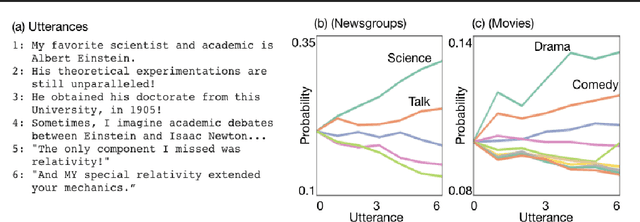
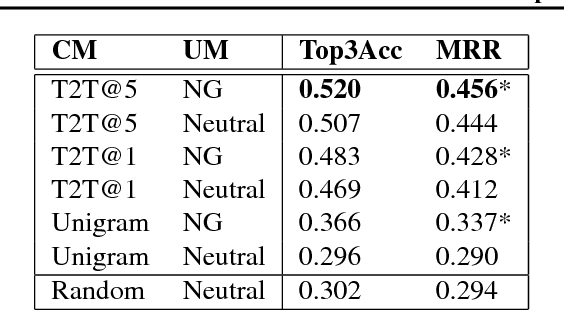
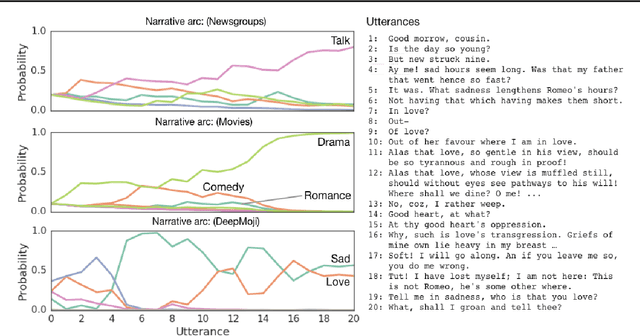
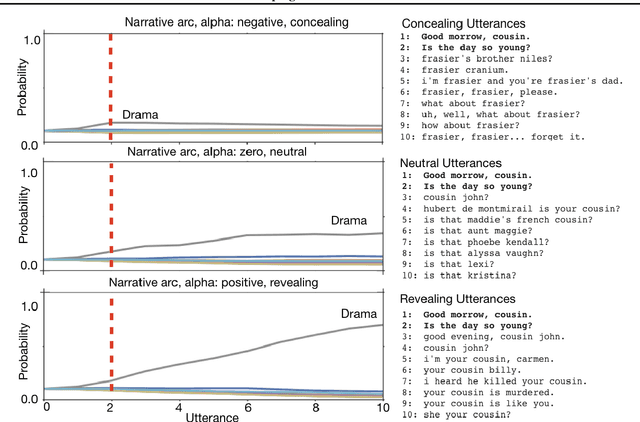
We consider the problem of designing an artificial agent capable of interacting with humans in collaborative dialogue to produce creative, engaging narratives. In this task, the goal is to establish universe details, and to collaborate on an interesting story in that universe, through a series of natural dialogue exchanges. Our model can augment any probabilistic conversational agent by allowing it to reason about universe information established and what potential next utterances might reveal. Ideally, with each utterance, agents would reveal just enough information to add specificity and reduce ambiguity without limiting the conversation. We empirically show that our model allows control over the rate at which the agent reveals information and that doing so significantly improves accuracy in predicting the next line of dialogues from movies. We close with a case-study with four professional theatre performers, who preferred interactions with our model-augmented agent over an unaugmented agent.
High-Power and High-Capacity Mobile Optical SWIPT
Jul 26, 2021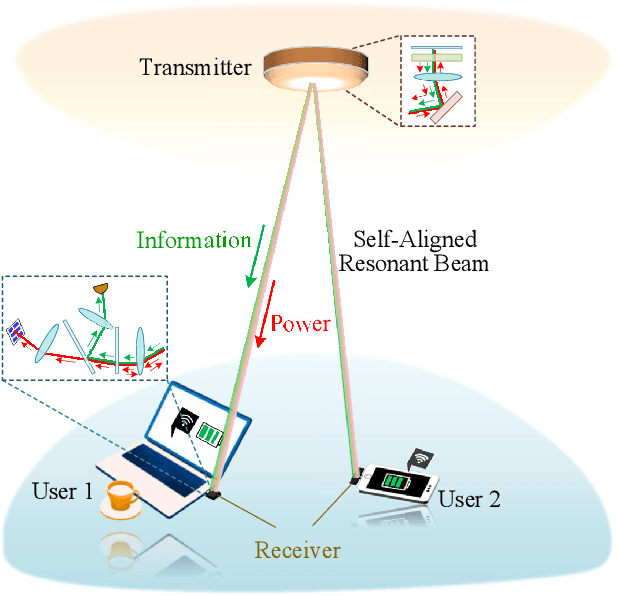
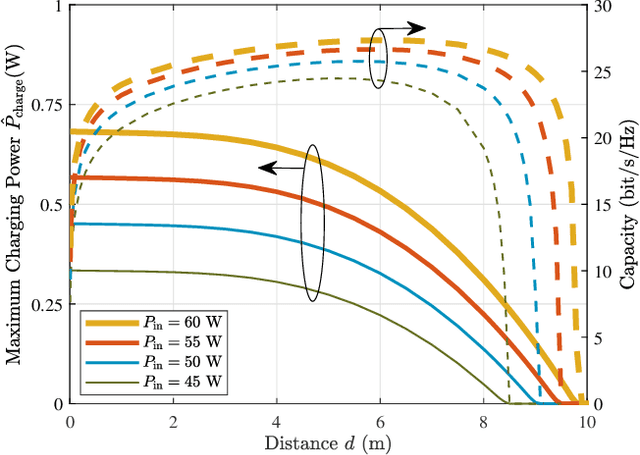
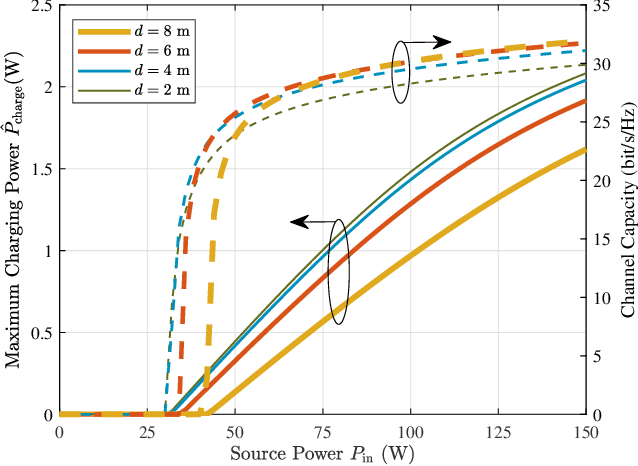
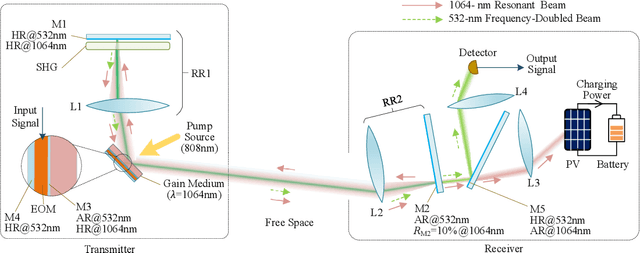
The increasing demands of power supply and data rate for mobile devices promote the research of simultaneous information and power transfer (SWIPT). Optical SWIPT, as known as simultaneous light information and power transfer (SLIPT), can provide high-capacity communication and high-power charging. However, light emitting diodes (LEDs)-based SLIPT technologies have low efficiency due to energy dissipation over the air. Laser-based SLIPT technologies face the challenge in mobility, as it needs accurate positioning, fast beam steering, and real-time tracking. In this paper, we propose a mobile SLIPT scheme based on spatially separated laser resonator (SSLR) and intra-cavity second harmonic generation (SHG). The power and data are transferred via separated frequencies, while they share the same self-aligned resonant beam path, without the needs of receiver positioning and beam steering. We establish the analysis model of the resonant beam power and its second harmonic power. We also evaluate the system performance on deliverable power and channel capacity. Numerical results show that the proposed system can achieve watt-level battery charging power and above 20-bit/s/Hz communication capacity over 8-m distance, which satisfies the requirements of most indoor mobile devices.
Permutation Invariance of Deep Neural Networks with ReLUs
Oct 18, 2021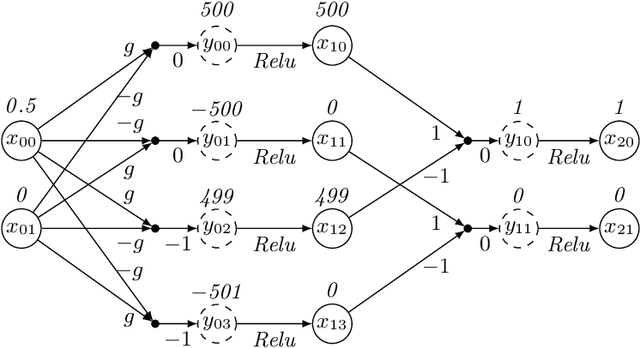
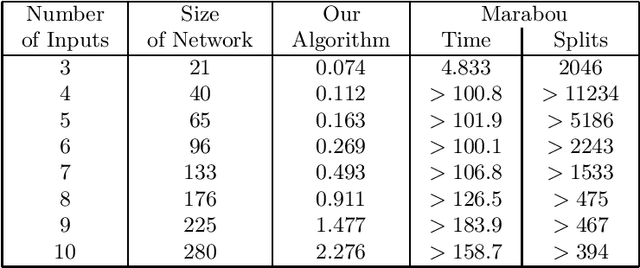
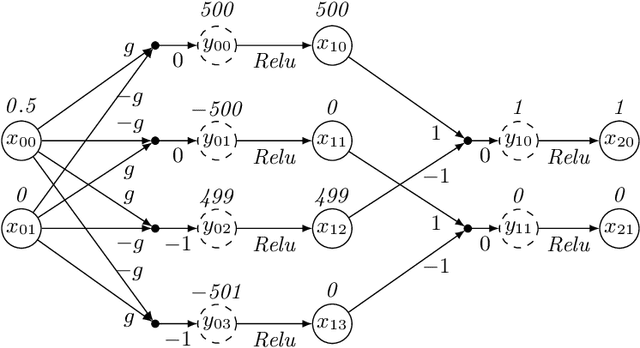
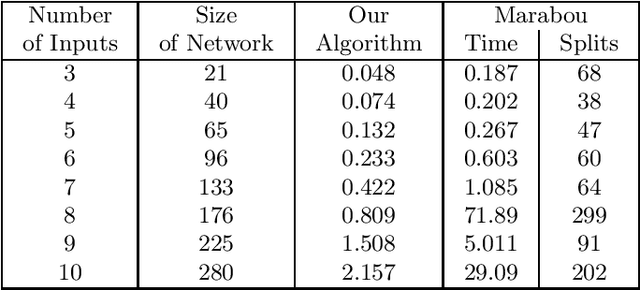
Consider a deep neural network (DNN) that is being used to suggest the direction in which an aircraft must turn to avoid a possible collision with an intruder aircraft. Informally, such a network is well-behaved if it asks the own ship to turn right (left) when an intruder approaches from the left (right). Consider another network that takes four inputs -- the cards dealt to the players in a game of contract bridge -- and decides which team can bid game. Loosely speaking, if you exchange the hands of partners (north and south, or east and west), the decision would not change. However, it will change if, say, you exchange north's hand with east. This permutation invariance property, for certain permutations at input and output layers, is central to the correctness and robustness of these networks. This paper proposes a sound, abstraction-based technique to establish permutation invariance in DNNs with ReLU as the activation function. The technique computes an over-approximation of the reachable states, and an under-approximation of the safe states, and propagates this information across the layers, both forward and backward. The novelty of our approach lies in a useful tie-class analysis, that we introduce for forward propagation, and a scalable 2-polytope under-approximation method that escapes the exponential blow-up in the number of regions during backward propagation. An experimental comparison shows the efficiency of our algorithm over that of verifying permutation invariance as a two-safety property (using FFNN verification over two copies of the network).
Fisher Information and Natural Gradient Learning of Random Deep Networks
Aug 22, 2018
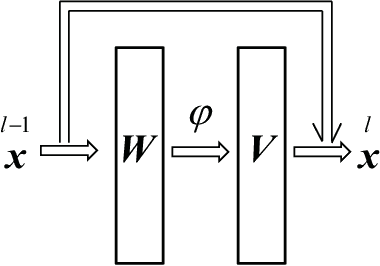
A deep neural network is a hierarchical nonlinear model transforming input signals to output signals. Its input-output relation is considered to be stochastic, being described for a given input by a parameterized conditional probability distribution of outputs. The space of parameters consisting of weights and biases is a Riemannian manifold, where the metric is defined by the Fisher information matrix. The natural gradient method uses the steepest descent direction in a Riemannian manifold, so it is effective in learning, avoiding plateaus. It requires inversion of the Fisher information matrix, however, which is practically impossible when the matrix has a huge number of dimensions. Many methods for approximating the natural gradient have therefore been introduced. The present paper uses statistical neurodynamical method to reveal the properties of the Fisher information matrix in a net of random connections under the mean field approximation. We prove that the Fisher information matrix is unit-wise block diagonal supplemented by small order terms of off-block-diagonal elements, which provides a justification for the quasi-diagonal natural gradient method by Y. Ollivier. A unitwise block-diagonal Fisher metrix reduces to the tensor product of the Fisher information matrices of single units. We further prove that the Fisher information matrix of a single unit has a simple reduced form, a sum of a diagonal matrix and a rank 2 matrix of weight-bias correlations. We obtain the inverse of Fisher information explicitly. We then have an explicit form of the natural gradient, without relying on the numerical matrix inversion, which drastically speeds up stochastic gradient learning.
Self-supervised Point Cloud Prediction Using 3D Spatio-temporal Convolutional Networks
Sep 28, 2021
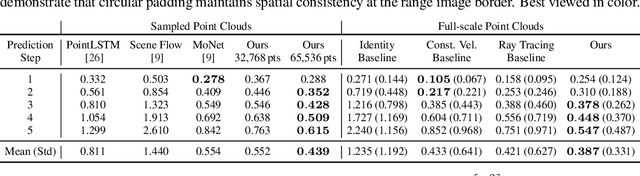
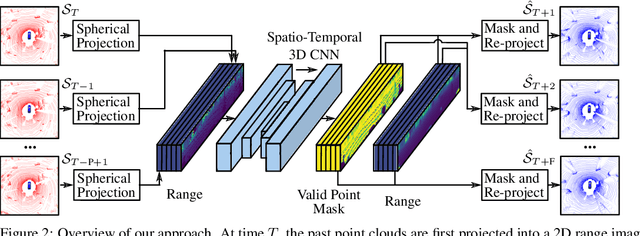
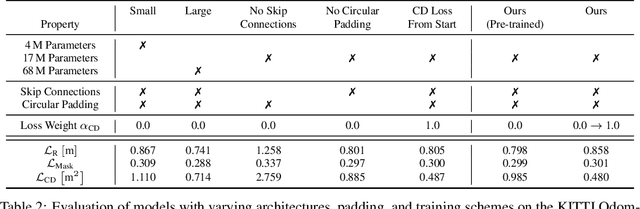
Exploiting past 3D LiDAR scans to predict future point clouds is a promising method for autonomous mobile systems to realize foresighted state estimation, collision avoidance, and planning. In this paper, we address the problem of predicting future 3D LiDAR point clouds given a sequence of past LiDAR scans. Estimating the future scene on the sensor level does not require any preceding steps as in localization or tracking systems and can be trained self-supervised. We propose an end-to-end approach that exploits a 2D range image representation of each 3D LiDAR scan and concatenates a sequence of range images to obtain a 3D tensor. Based on such tensors, we develop an encoder-decoder architecture using 3D convolutions to jointly aggregate spatial and temporal information of the scene and to predict the future 3D point clouds. We evaluate our method on multiple datasets and the experimental results suggest that our method outperforms existing point cloud prediction architectures and generalizes well to new, unseen environments without additional fine-tuning. Our method operates online and is faster than the common LiDAR frame rate of 10 Hz.
Benchmarking Safety Monitors for Image Classifiers with Machine Learning
Oct 04, 2021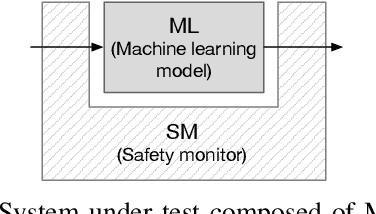
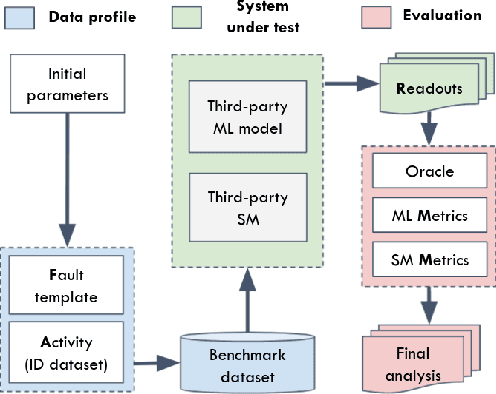
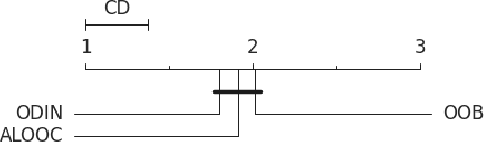
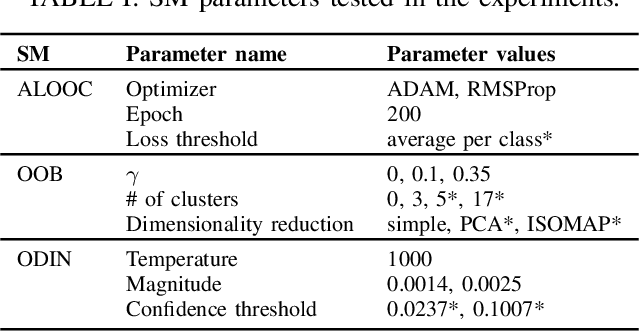
High-accurate machine learning (ML) image classifiers cannot guarantee that they will not fail at operation. Thus, their deployment in safety-critical applications such as autonomous vehicles is still an open issue. The use of fault tolerance mechanisms such as safety monitors is a promising direction to keep the system in a safe state despite errors of the ML classifier. As the prediction from the ML is the core information directly impacting safety, many works are focusing on monitoring the ML model itself. Checking the efficiency of such monitors in the context of safety-critical applications is thus a significant challenge. Therefore, this paper aims at establishing a baseline framework for benchmarking monitors for ML image classifiers. Furthermore, we propose a framework covering the entire pipeline, from data generation to evaluation. Our approach measures monitor performance with a broader set of metrics than usually proposed in the literature. Moreover, we benchmark three different monitor approaches in 79 benchmark datasets containing five categories of out-of-distribution data for image classifiers: class novelty, noise, anomalies, distributional shifts, and adversarial attacks. Our results indicate that these monitors are no more accurate than a random monitor. We also release the code of all experiments for reproducibility.
Recurrent Neural Network Controllers Synthesis with Stability Guarantees for Partially Observed Systems
Sep 08, 2021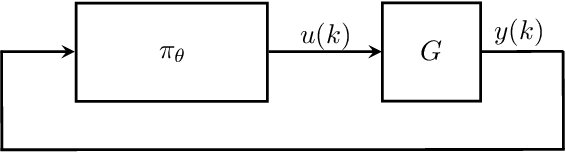
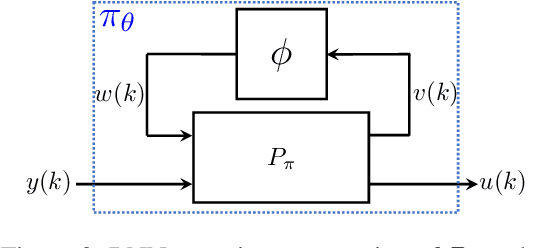
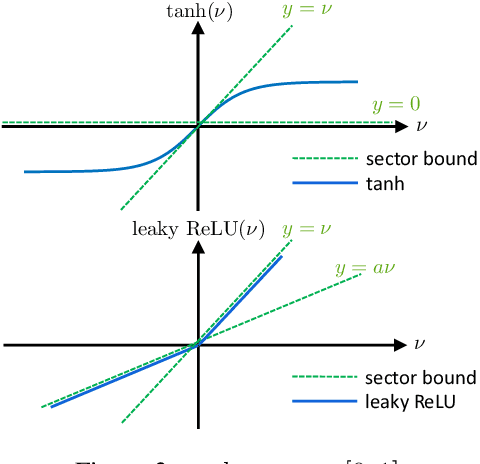
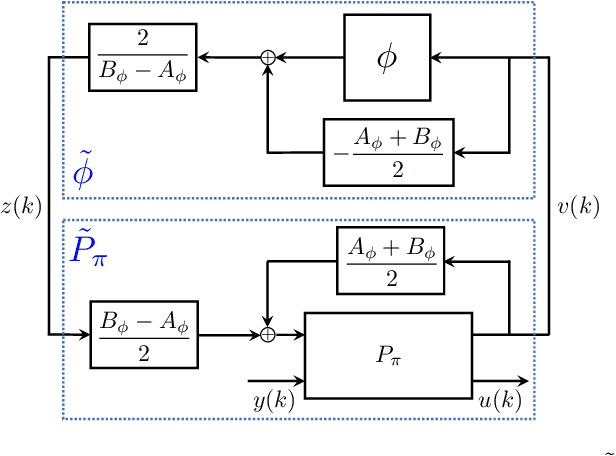
Neural network controllers have become popular in control tasks thanks to their flexibility and expressivity. Stability is a crucial property for safety-critical dynamical systems, while stabilization of partially observed systems, in many cases, requires controllers to retain and process long-term memories of the past. We consider the important class of recurrent neural networks (RNN) as dynamic controllers for nonlinear uncertain partially-observed systems, and derive convex stability conditions based on integral quadratic constraints, S-lemma and sequential convexification. To ensure stability during the learning and control process, we propose a projected policy gradient method that iteratively enforces the stability conditions in the reparametrized space taking advantage of mild additional information on system dynamics. Numerical experiments show that our method learns stabilizing controllers while using fewer samples and achieving higher final performance compared with policy gradient.
Learning Structural Representations for Recipe Generation and Food Retrieval
Oct 04, 2021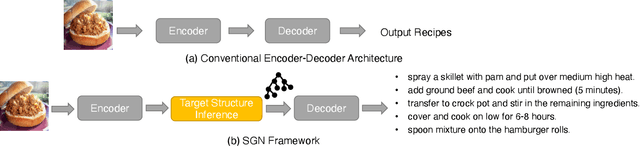
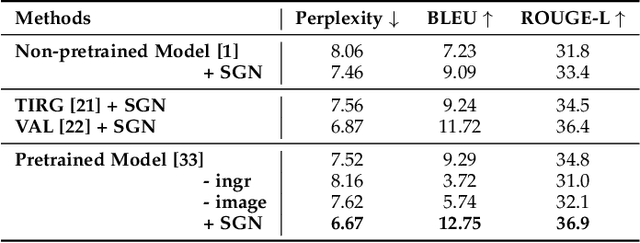
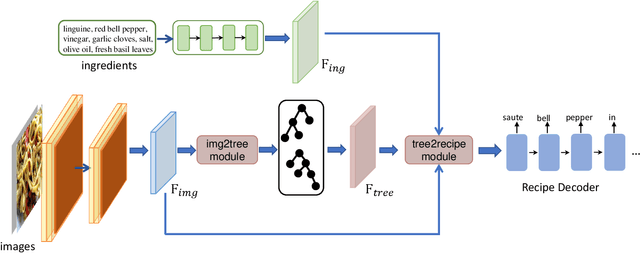
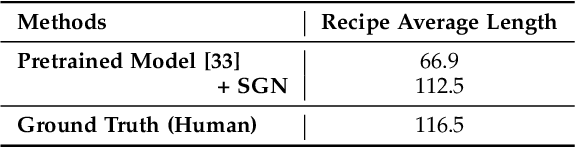
Food is significant to human daily life. In this paper, we are interested in learning structural representations for lengthy recipes, that can benefit the recipe generation and food retrieval tasks. We mainly investigate an open research task of generating cooking instructions based on food images and ingredients, which is similar to the image captioning task. However, compared with image captioning datasets, the target recipes are lengthy paragraphs and do not have annotations on structure information. To address the above limitations, we propose a novel framework of Structure-aware Generation Network (SGN) to tackle the food recipe generation task. Our approach brings together several novel ideas in a systematic framework: (1) exploiting an unsupervised learning approach to obtain the sentence-level tree structure labels before training; (2) generating trees of target recipes from images with the supervision of tree structure labels learned from (1); and (3) integrating the inferred tree structures into the recipe generation procedure. Our proposed model can produce high-quality and coherent recipes, and achieve the state-of-the-art performance on the benchmark Recipe1M dataset. We also validate the usefulness of our learned tree structures in the food cross-modal retrieval task, where the proposed model with tree representations can outperform state-of-the-art benchmark results.
Topological Attention for Time Series Forecasting
Jul 19, 2021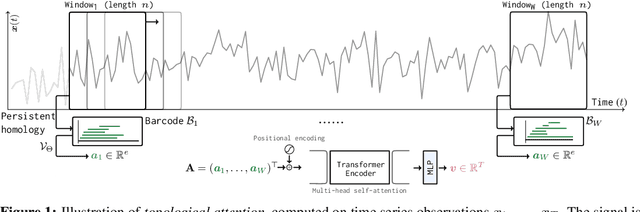
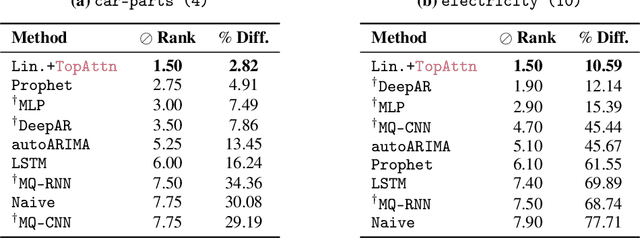
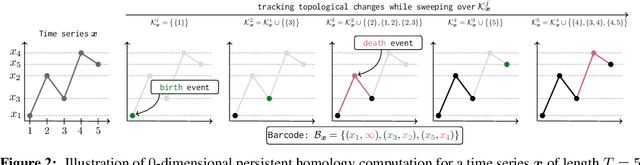
The problem of (point) forecasting $ \textit{univariate} $ time series is considered. Most approaches, ranging from traditional statistical methods to recent learning-based techniques with neural networks, directly operate on raw time series observations. As an extension, we study whether $\textit{local topological properties}$, as captured via persistent homology, can serve as a reliable signal that provides complementary information for learning to forecast. To this end, we propose $\textit{topological attention}$, which allows attending to local topological features within a time horizon of historical data. Our approach easily integrates into existing end-to-end trainable forecasting models, such as $\texttt{N-BEATS}$, and in combination with the latter exhibits state-of-the-art performance on the large-scale M4 benchmark dataset of 100,000 diverse time series from different domains. Ablation experiments, as well as a comparison to a broad range of forecasting methods in a setting where only a single time series is available for training, corroborate the beneficial nature of including local topological information through an attention mechanism.