 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
M2GAN: A Multi-Stage Self-Attention Network for Image Rain Removal on Autonomous Vehicles
Oct 12, 2021

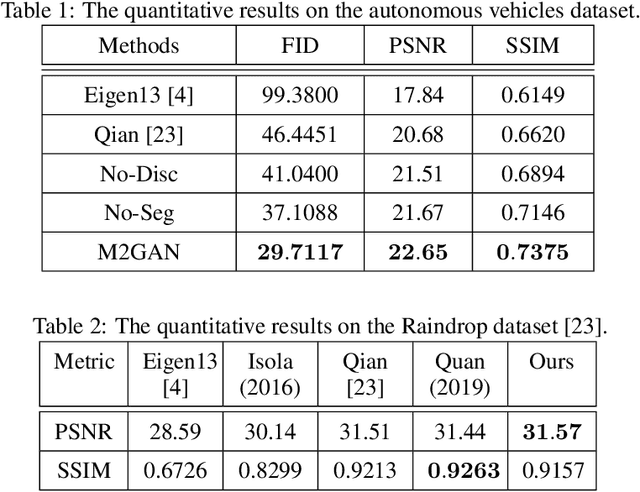

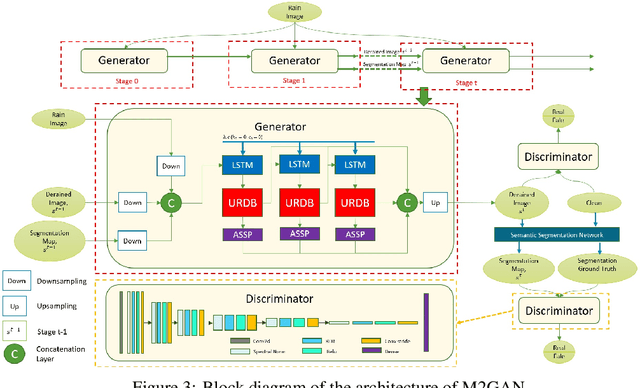
Image deraining is a new challenging problem in applications of autonomous vehicles. In a bad weather condition of heavy rainfall, raindrops, mainly hitting the vehicle's windshield, can significantly reduce observation ability even though the windshield wipers might be able to remove part of it. Moreover, rain flows spreading over the windshield can yield the physical effect of refraction, which seriously impede the sightline or undermine the machine learning system equipped in the vehicle. In this paper, we propose a new multi-stage multi-task recurrent generative adversarial network (M2GAN) to deal with challenging problems of raindrops hitting the car's windshield. This method is also applicable for removing raindrops appearing on a glass window or lens. M2GAN is a multi-stage multi-task generative adversarial network that can utilize prior high-level information, such as semantic segmentation, to boost deraining performance. To demonstrate M2GAN, we introduce the first real-world dataset for rain removal on autonomous vehicles. The experimental results show that our proposed method is superior to other state-of-the-art approaches of deraining raindrops in respect of quantitative metrics and visual quality. M2GAN is considered the first method to deal with challenging problems of real-world rains under unconstrained environments such as autonomous vehicles.
Sequential Joint Shape and Pose Estimation of Vehicles with Application to Automatic Amodal Segmentation Labeling
Sep 20, 2021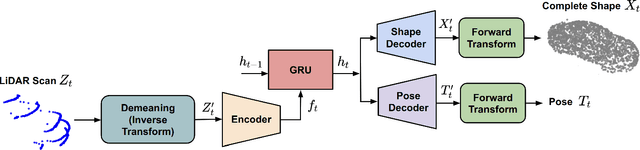

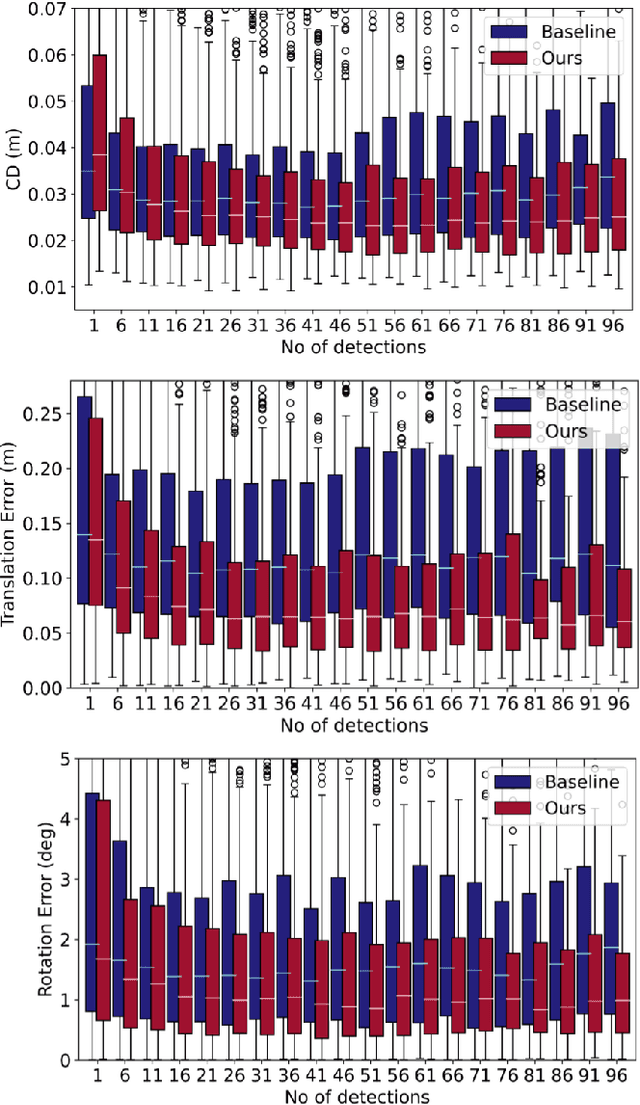

Shape and pose estimation is a critical perception problem for a self-driving car to fully understand its surrounding environment. One fundamental challenge in solving this problem is the incomplete sensor signal (e.g., LiDAR scans), especially for faraway or occluded objects. In this paper, we propose a novel algorithm to address this challenge, we explicitly leverage the sensor signal captured over consecutive time: the consecutive signals can provide more information of an object, including different viewpoints and its motion. By encoding the consecutive signal via a recurrent neural network, our algorithm not only improves shape and pose estimation, but also produces a labeling tool that can benefit other tasks in autonomous driving research. Specifically, building upon our algorithm, we propose a novel pipeline to automatically annotate high-quality labels for amodal segmentation on images, which are hard and laborious to annotate manually. Our code and data will be made publicly available.
Mining Legacy Issues in Open Pit Mining Sites: Innovation & Support of Renaturalization and Land Utilization
May 13, 2021
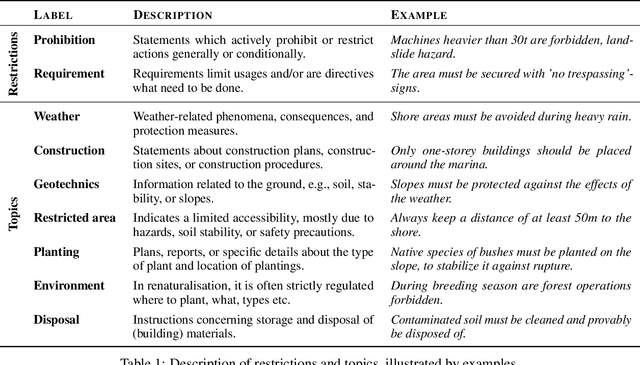
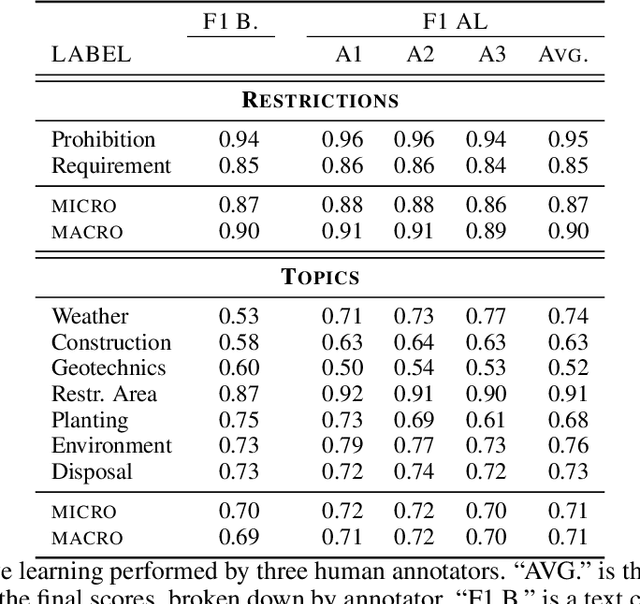
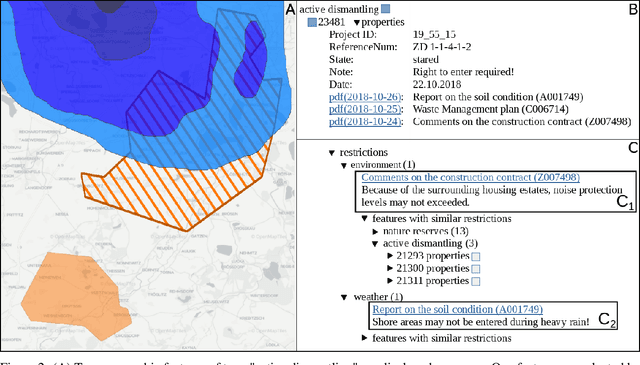
Open pit mines left many regions worldwide inhospitable or uninhabitable. To put these regions back into use, entire stretches of land must be renaturalized. For the sustainable subsequent use or transfer to a new primary use, many contaminated sites and soil information have to be permanently managed. In most cases, this information is available in the form of expert reports in unstructured data collections or file folders, which in the best case are digitized. Due to size and complexity of the data, it is difficult for a single person to have an overview of this data in order to be able to make reliable statements. This is one of the most important obstacles to the rapid transfer of these areas to after-use. An information-based approach to this issue supports fulfilling several Sustainable Development Goals regarding environment issues, health and climate action. We use a stack of Optical Character Recognition, Text Classification, Active Learning and Geographic Information System Visualization to effectively mine and visualize this information. Subsequently, we link the extracted information to geographic coordinates and visualize them using a Geographic Information System. Active Learning plays a vital role because our dataset provides no training data. In total, we process nine categories and actively learn their representation in our dataset. We evaluate the OCR, Active Learning and Text Classification separately to report the performance of the system. Active Learning and text classification results are twofold: Whereas our categories about restrictions work sufficient ($>$.85 F1), the seven topic-oriented categories were complicated for human coders and hence the results achieved mediocre evaluation scores ($<$.70 F1).
Generic Bounds on the Maximum Deviations in Sequential Prediction: An Information-Theoretic Analysis
Oct 11, 2019In this paper, we derive generic bounds on the maximum deviations in prediction errors for sequential prediction via an information-theoretic approach. The fundamental bounds are shown to depend only on the conditional entropy of the data point to be predicted given the previous data points. In the asymptotic case, the bounds are achieved if and only if the prediction error is white and uniformly distributed.
Efficient Bayesian network structure learning via local Markov boundary search
Oct 12, 2021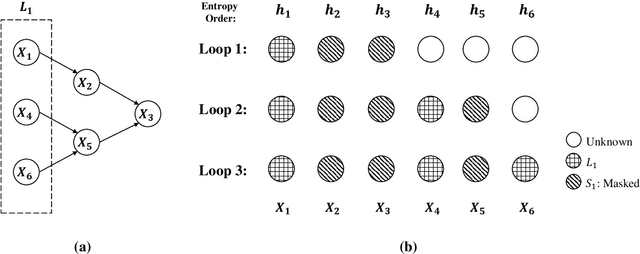
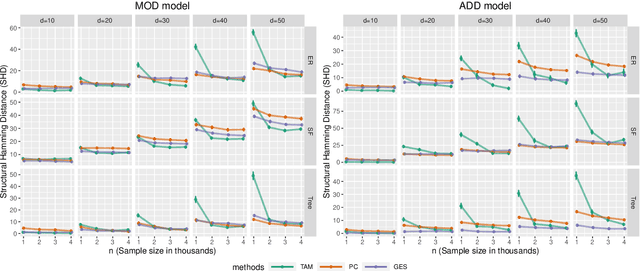
We analyze the complexity of learning directed acyclic graphical models from observational data in general settings without specific distributional assumptions. Our approach is information-theoretic and uses a local Markov boundary search procedure in order to recursively construct ancestral sets in the underlying graphical model. Perhaps surprisingly, we show that for certain graph ensembles, a simple forward greedy search algorithm (i.e. without a backward pruning phase) suffices to learn the Markov boundary of each node. This substantially improves the sample complexity, which we show is at most polynomial in the number of nodes. This is then applied to learn the entire graph under a novel identifiability condition that generalizes existing conditions from the literature. As a matter of independent interest, we establish finite-sample guarantees for the problem of recovering Markov boundaries from data. Moreover, we apply our results to the special case of polytrees, for which the assumptions simplify, and provide explicit conditions under which polytrees are identifiable and learnable in polynomial time. We further illustrate the performance of the algorithm, which is easy to implement, in a simulation study. Our approach is general, works for discrete or continuous distributions without distributional assumptions, and as such sheds light on the minimal assumptions required to efficiently learn the structure of directed graphical models from data.
Surrogate and inverse modeling for two-phase flow in porous media via theory-guided convolutional neural network
Oct 12, 2021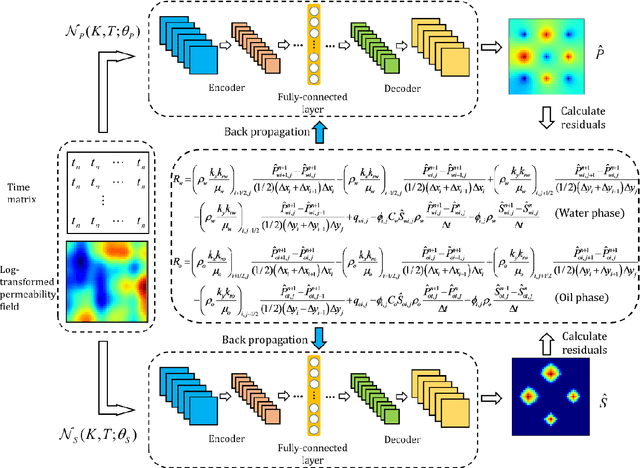
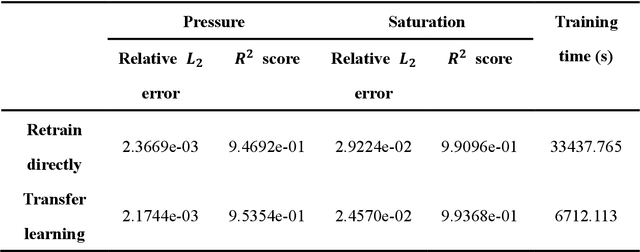
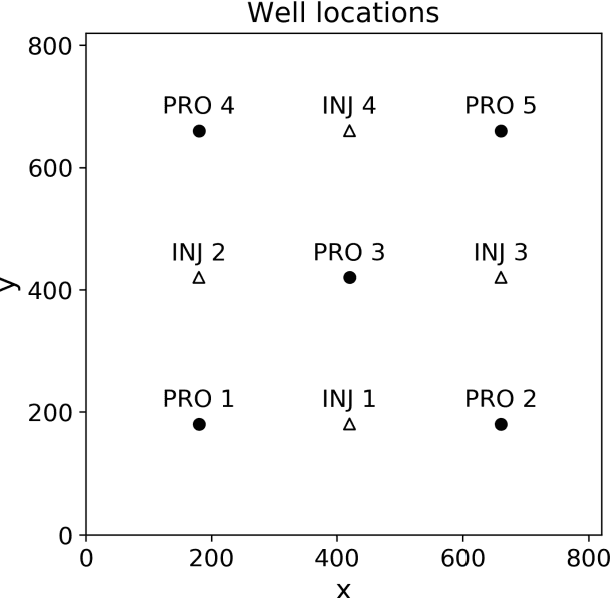

The theory-guided convolutional neural network (TgCNN) framework, which can incorporate discretized governing equation residuals into the training of convolutional neural networks (CNNs), is extended to two-phase porous media flow problems in this work. The two principal variables of the considered problem, pressure and saturation, are approximated simultaneously with two CNNs, respectively. Pressure and saturation are coupled with each other in the governing equations, and thus the two networks are also mutually conditioned in the training process by the discretized governing equations, which also increases the difficulty of model training. The coupled and discretized equations can provide valuable information in the training process. With the assistance of theory-guidance, the TgCNN surrogates can achieve better accuracy than ordinary CNN surrogates in two-phase flow problems. Moreover, a piecewise training strategy is proposed for the scenario with varying well controls, in which the TgCNN surrogates are constructed for different segments on the time dimension and stacked together to predict solutions for the whole time-span. For scenarios with larger variance of the formation property field, the TgCNN surrogates can also achieve satisfactory performance. The constructed TgCNN surrogates are further used for inversion of permeability fields by combining them with the iterative ensemble smoother (IES) algorithm, and sufficient inversion accuracy is obtained with improved efficiency.
Privacy-Preserving Phishing Email Detection Based on Federated Learning and LSTM
Oct 12, 2021
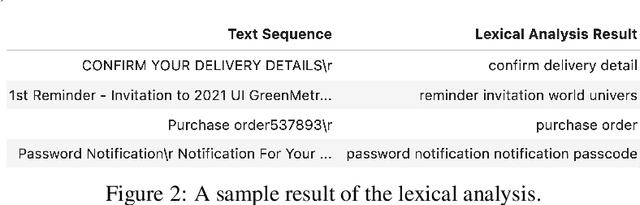
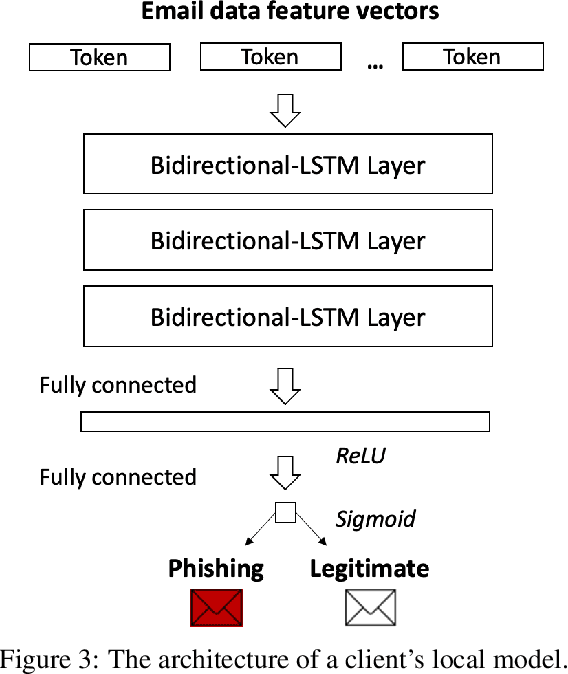
Phishing emails that appear legitimate lure people into clicking on the attached malicious links or documents. Increasingly more sophisticated phishing campaigns in recent years necessitate a more adaptive detection system other than traditional signature-based methods. In this regard, natural language processing (NLP) with deep neural networks (DNNs) is adopted for knowledge acquisition from a large number of emails. However, such sensitive daily communications containing personal information are difficult to collect on a server for centralized learning in real life due to escalating privacy concerns. To this end, we propose a decentralized phishing email detection method called the Federated Phish Bowl (FPB) leveraging federated learning and long short-term memory (LSTM). FPB allows common knowledge representation and sharing among different clients through the aggregation of trained models to safeguard the email security and privacy. A recent phishing email dataset was collected from an intergovernmental organization to train the model. Moreover, we evaluated the model performance based on various assumptions regarding the total client number and the level of data heterogeneity. The comprehensive experimental results suggest that FPB is robust to a continually increasing client number and various data heterogeneity levels, retaining a detection accuracy of 0.83 and protecting the privacy of sensitive email communications.
Causal Analysis of Carnatic Music: A Preliminary Study
Sep 24, 2021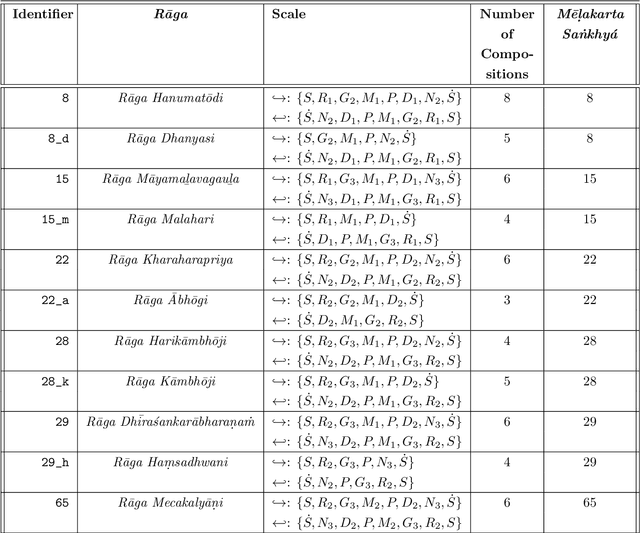


The musicological analysis of Carnatic music is challenging, owing to its rich structure and complexity. Automated \textit{r\=aga} classification, pitch detection, tonal analysis, modelling and information retrieval of this form of southern Indian classical music have, however, made significant progress in recent times. A causal analysis to investigate the musicological structure of Carnatic compositions and the identification of the relationships embedded in them have never been previously attempted. In this study, we propose a novel framework for causal discovery, using a compression-complexity measure. Owing to the limited number of compositions available, however, we generated surrogates to further facilitate the analysis of the prevailing causal relationships. Our analysis indicates that the context-free grammar, inferred from more complex compositions, such as the \textit{M\=e\d{l}akarta} \textit{r\=aga}, are a \textit{structural cause} for the \textit{Janya} \textit{r\=aga}. We also analyse certain special cases of the \textit{Janya r\=aga} in order to understand their origins and structure better.
CPNet: Cycle Prototype Network for Weakly-supervised 3D Renal Compartments Segmentation on CT Images
Aug 15, 2021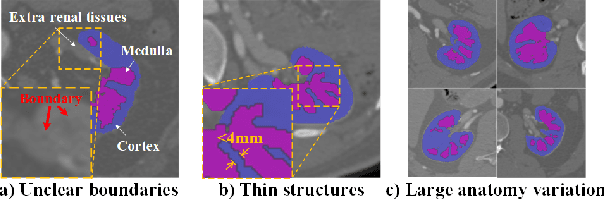
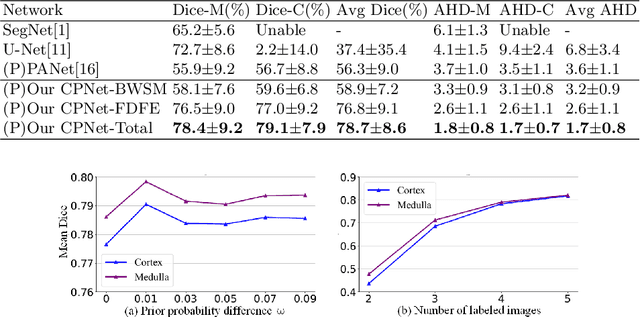
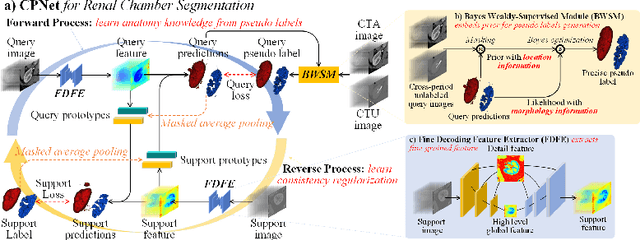
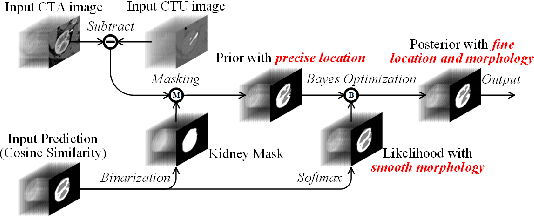
Renal compartment segmentation on CT images targets on extracting the 3D structure of renal compartments from abdominal CTA images and is of great significance to the diagnosis and treatment for kidney diseases. However, due to the unclear compartment boundary, thin compartment structure and large anatomy variation of 3D kidney CT images, deep-learning based renal compartment segmentation is a challenging task. We propose a novel weakly supervised learning framework, Cycle Prototype Network, for 3D renal compartment segmentation. It has three innovations: 1) A Cycle Prototype Learning (CPL) is proposed to learn consistency for generalization. It learns from pseudo labels through the forward process and learns consistency regularization through the reverse process. The two processes make the model robust to noise and label-efficient. 2) We propose a Bayes Weakly Supervised Module (BWSM) based on cross-period prior knowledge. It learns prior knowledge from cross-period unlabeled data and perform error correction automatically, thus generates accurate pseudo labels. 3) We present a Fine Decoding Feature Extractor (FDFE) for fine-grained feature extraction. It combines global morphology information and local detail information to obtain feature maps with sharp detail, so the model will achieve fine segmentation on thin structures. Our model achieves Dice of 79.1% and 78.7% with only four labeled images, achieving a significant improvement by about 20% than typical prototype model PANet.
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
Jul 21, 2021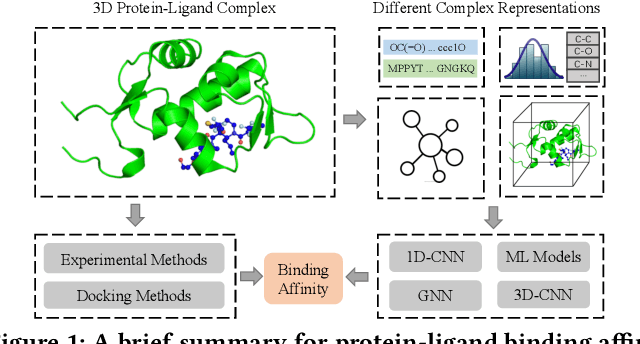
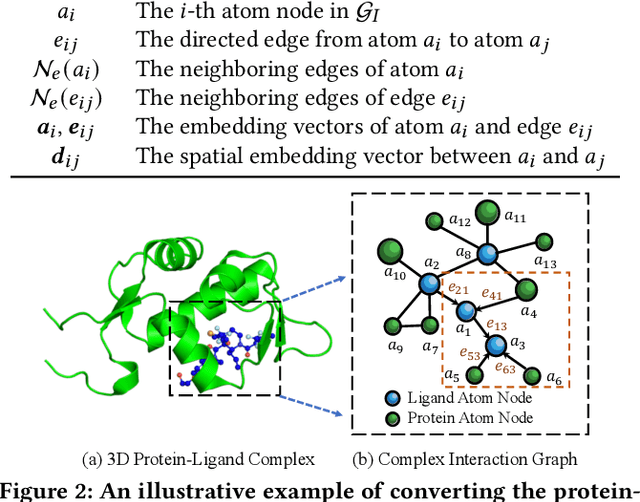
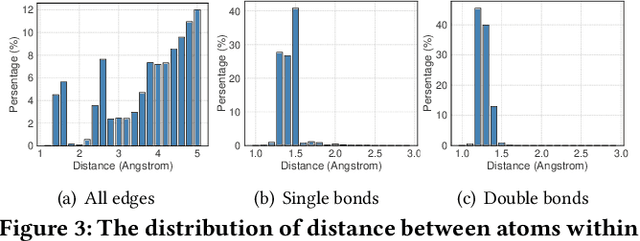
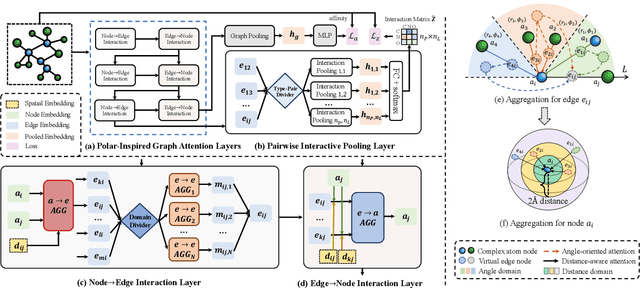
Drug discovery often relies on the successful prediction of protein-ligand binding affinity. Recent advances have shown great promise in applying graph neural networks (GNNs) for better affinity prediction by learning the representations of protein-ligand complexes. However, existing solutions usually treat protein-ligand complexes as topological graph data, thus the biomolecular structural information is not fully utilized. The essential long-range interactions among atoms are also neglected in GNN models. To this end, we propose a structure-aware interactive graph neural network (SIGN) which consists of two components: polar-inspired graph attention layers (PGAL) and pairwise interactive pooling (PiPool). Specifically, PGAL iteratively performs the node-edge aggregation process to update embeddings of nodes and edges while preserving the distance and angle information among atoms. Then, PiPool is adopted to gather interactive edges with a subsequent reconstruction loss to reflect the global interactions. Exhaustive experimental study on two benchmarks verifies the superiority of SIGN.