 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SpaceMeshLab: Spatial Context Memoization and Meshgrid Atrous Convolution Consensus for Semantic Segmentation
Jun 08, 2021
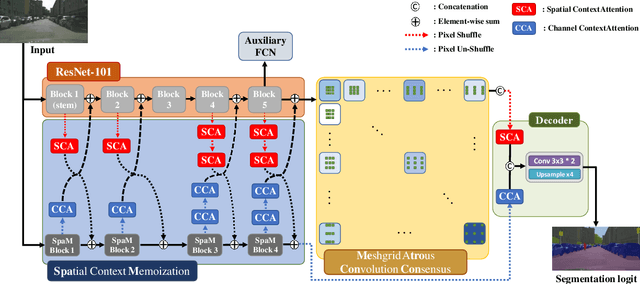

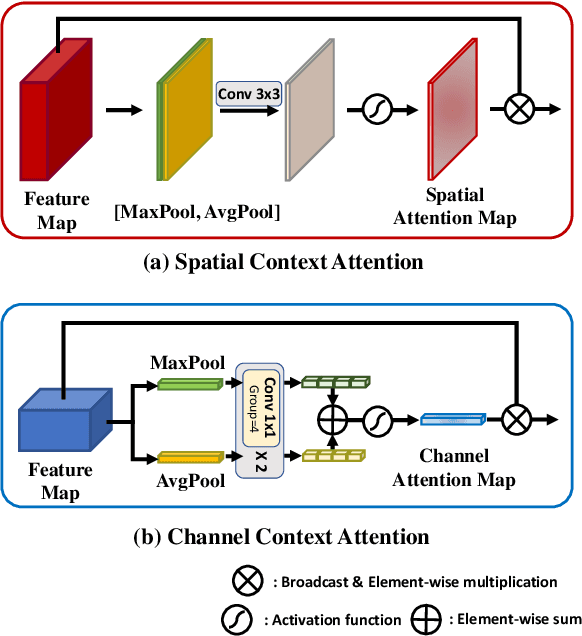

Semantic segmentation networks adopt transfer learning from image classification networks which occurs a shortage of spatial context information. For this reason, we propose Spatial Context Memoization (SpaM), a bypassing branch for spatial context by retaining the input dimension and constantly communicating its spatial context and rich semantic information mutually with the backbone network. Multi-scale context information for semantic segmentation is crucial for dealing with diverse sizes and shapes of target objects in the given scene. Conventional multi-scale context scheme adopts multiple effective receptive fields by multiple dilation rates or pooling operations, but often suffer from misalignment problem with respect to the target pixel. To this end, we propose Meshgrid Atrous Convolution Consensus (MetroCon^2) which brings multi-scale scheme into fine-grained multi-scale object context using convolutions with meshgrid-like scattered dilation rates. SpaceMeshLab (ResNet-101 + SpaM + MetroCon^2) achieves 82.0% mIoU in Cityscapes test and 53.5% mIoU on Pascal-Context validation set.
Don't read, just look: Main content extraction from web pages using visually apparent features
Oct 27, 2021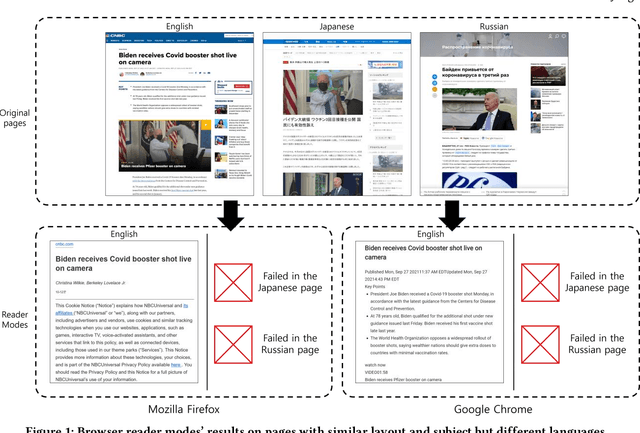
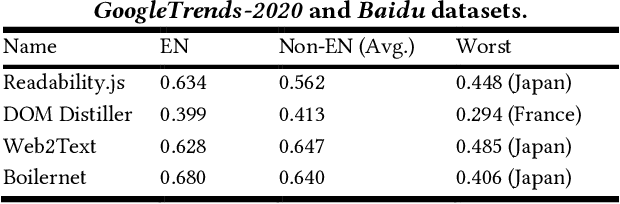
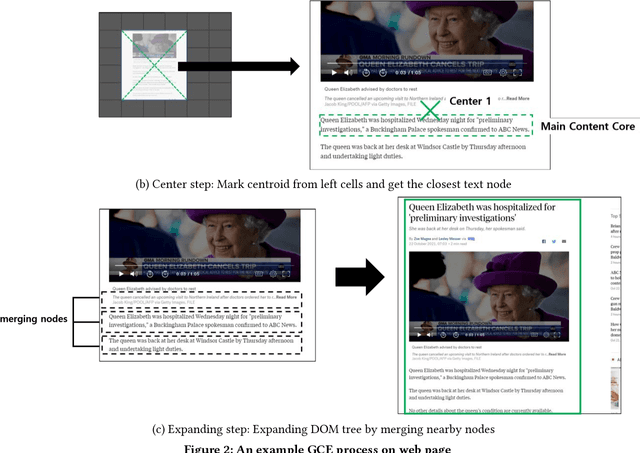
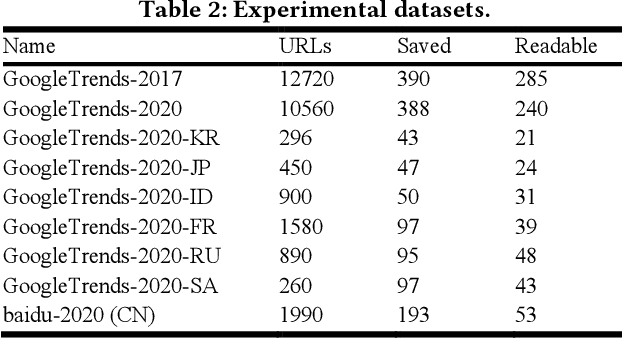
The extraction of main content provides only primary informative blocks by removing a web page's minor areas like navigation menu, ads, and site templates. It has various applications: information retrieval, search engine optimization, and browser reader mode. We tested the existing four main content extraction methods (Firefox Readability.js, Chrome DOM Distiller, Web2Text, and Boilernet) in web pages datasets of two English datasets from the global websites and seven non-English datasets from seven local regions each. It shows that the performance decreases by up to 40% in non-English datasets over English datasets. This paper proposes a multilingual main content extraction method that uses visually apparent features such as the elements' positions, size, and distances from the centers of the browser window and the web document. These are based on the authors' intention: the elements' placement and appearance in web pages have constraints because of humans' narrow central vision. Hence, our method, Grid-Center-Expand (GCE), finds the closest leaf node to the centroid of the web page from which minor areas have been removed. For the main content, the leaf node repeatedly ascends to the parent node of the DOM tree until this node fits one of the following conditions: <article> tag, containing specific attributes, or sudden width change. In the non-English datasets, our method performs better than up to 13% over Boilernet, especially 56% in the Japan dataset and 7% in the English dataset. Therefore, our method performs well regardless of the regional and linguistic characteristics of the web page. In addition, we create DNN models using Google's TabNet with GCE's features. The best of our models has similar performance to Boilernet and Web2text in all datasets. Accordingly, we show that these features can be useful to machine learning models for extracting main content.
Knowing False Negatives: An Adversarial Training Method for Distantly Supervised Relation Extraction
Sep 05, 2021
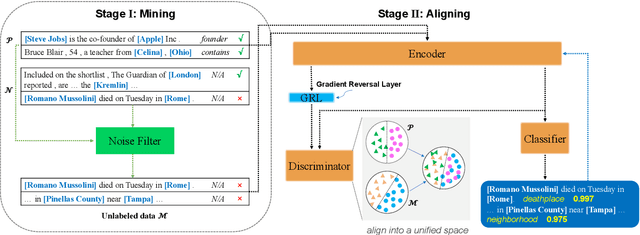
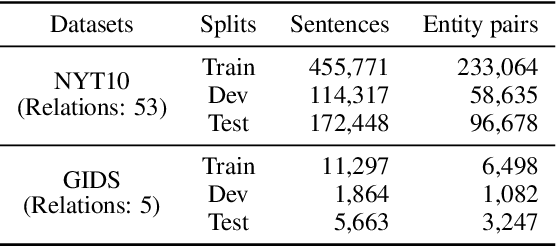
Distantly supervised relation extraction (RE) automatically aligns unstructured text with relation instances in a knowledge base (KB). Due to the incompleteness of current KBs, sentences implying certain relations may be annotated as N/A instances, which causes the so-called false negative (FN) problem. Current RE methods usually overlook this problem, inducing improper biases in both training and testing procedures. To address this issue, we propose a two-stage approach. First, it finds out possible FN samples by heuristically leveraging the memory mechanism of deep neural networks. Then, it aligns those unlabeled data with the training data into a unified feature space by adversarial training to assign pseudo labels and further utilize the information contained in them. Experiments on two wildly-used benchmark datasets demonstrate the effectiveness of our approach.
Spatiotemporal Fusion in Remote Sensing
Jul 06, 2021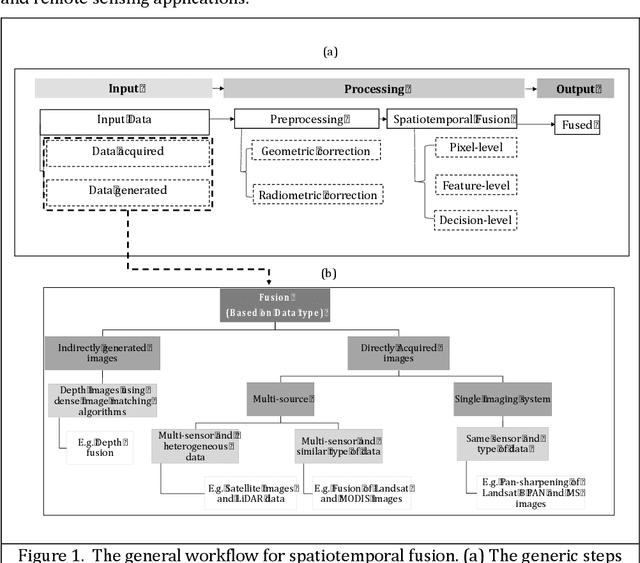
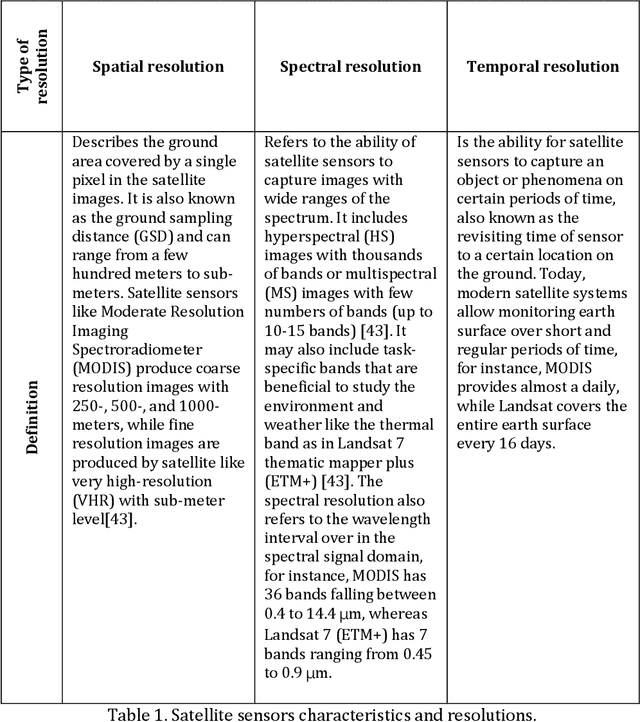
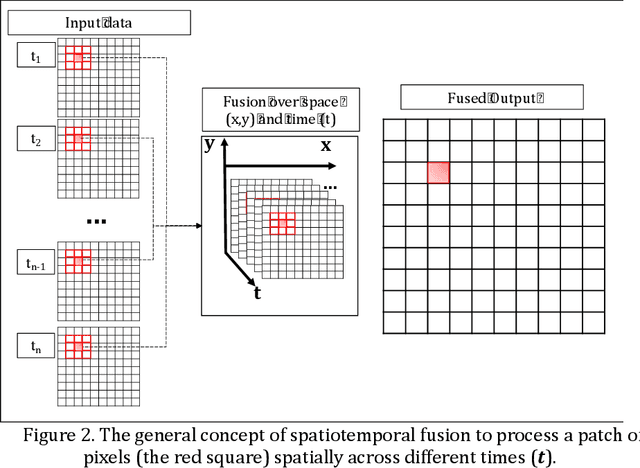
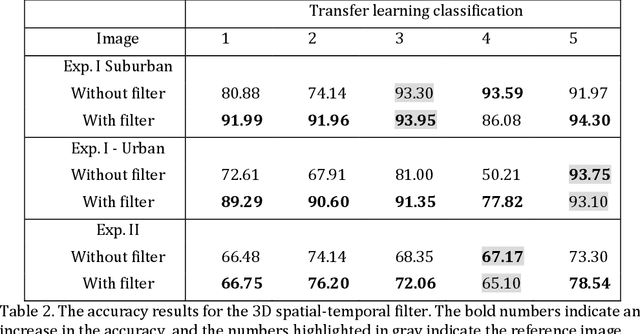
Remote sensing images and techniques are powerful tools to investigate earth surface. Data quality is the key to enhance remote sensing applications and obtaining a clear and noise-free set of data is very difficult in most situations due to the varying acquisition (e.g., atmosphere and season), sensor, and platform (e.g., satellite angles and sensor characteristics) conditions. With the increasing development of satellites, nowadays Terabytes of remote sensing images can be acquired every day. Therefore, information and data fusion can be particularly important in the remote sensing community. The fusion integrates data from various sources acquired asynchronously for information extraction, analysis, and quality improvement. In this chapter, we aim to discuss the theory of spatiotemporal fusion by investigating previous works, in addition to describing the basic concepts and some of its applications by summarizing our prior and ongoing works.
Stable Recovery of Weighted Sparse Signals from Phaseless Measurements via Weighted l1 Minimization
Jul 10, 2021The goal of phaseless compressed sensing is to recover an unknown sparse or approximately sparse signal from the magnitude of its measurements. However, it does not take advantage of any support information of the original signal. Therefore, our main contribution in this paper is to extend the theoretical framework for phaseless compressed sensing to incorporate with prior knowledge of the support structure of the signal. Specifically, we investigate two conditions that guarantee stable recovery of a weighted $k$-sparse signal via weighted l1 minimization without any phase information. We first prove that the weighted null space property (WNSP) is a sufficient and necessary condition for the success of weighted l1 minimization for weighted k-sparse phase retrievable. Moreover, we show that if a measurement matrix satisfies the strong weighted restricted isometry property (SWRIP), then the original signal can be stably recovered from the phaseless measurements.
The Image Local Autoregressive Transformer
Jun 04, 2021

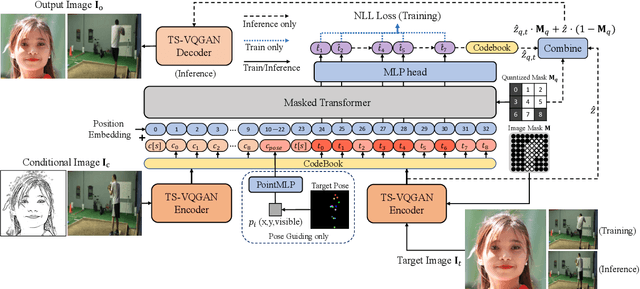
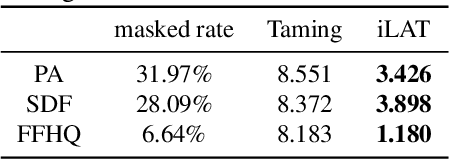
Recently, AutoRegressive (AR) models for the whole image generation empowered by transformers have achieved comparable or even better performance to Generative Adversarial Networks (GANs). Unfortunately, directly applying such AR models to edit/change local image regions, may suffer from the problems of missing global information, slow inference speed, and information leakage of local guidance. To address these limitations, we propose a novel model -- image Local Autoregressive Transformer (iLAT), to better facilitate the locally guided image synthesis. Our iLAT learns the novel local discrete representations, by the newly proposed local autoregressive (LA) transformer of the attention mask and convolution mechanism. Thus iLAT can efficiently synthesize the local image regions by key guidance information. Our iLAT is evaluated on various locally guided image syntheses, such as pose-guided person image synthesis and face editing. Both the quantitative and qualitative results show the efficacy of our model.
Near optimal sample complexity for matrix and tensor normal models via geodesic convexity
Oct 14, 2021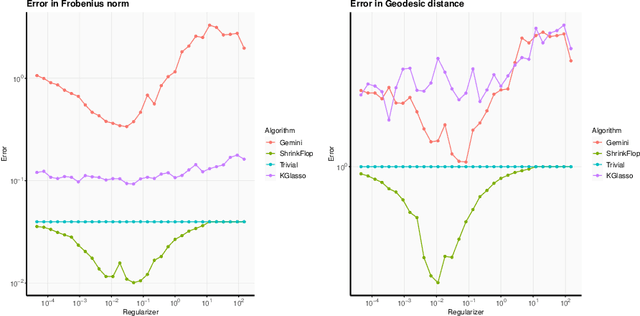
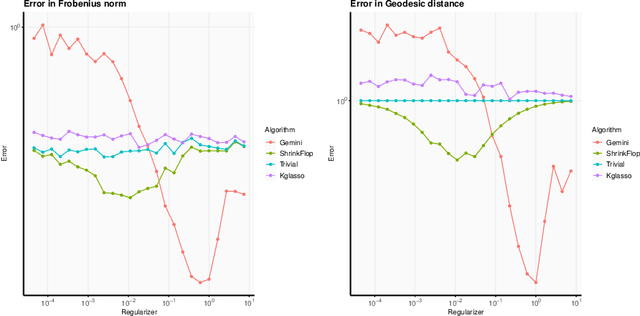
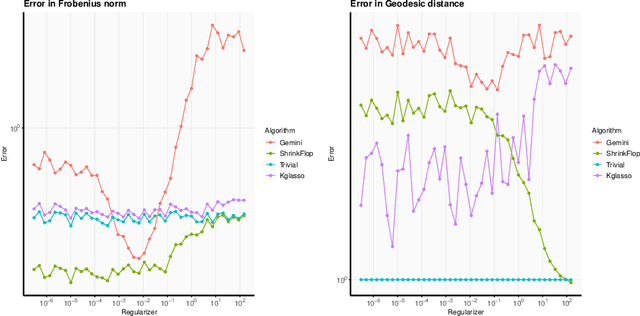
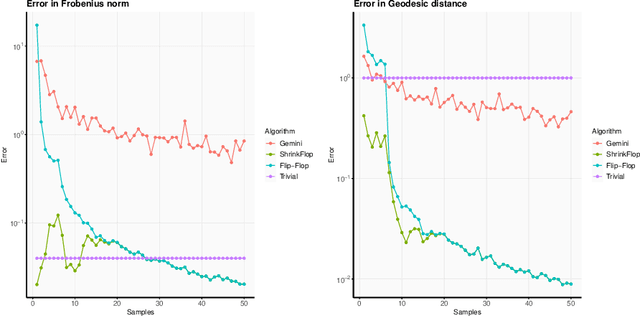
The matrix normal model, the family of Gaussian matrix-variate distributions whose covariance matrix is the Kronecker product of two lower dimensional factors, is frequently used to model matrix-variate data. The tensor normal model generalizes this family to Kronecker products of three or more factors. We study the estimation of the Kronecker factors of the covariance matrix in the matrix and tensor models. We show nonasymptotic bounds for the error achieved by the maximum likelihood estimator (MLE) in several natural metrics. In contrast to existing bounds, our results do not rely on the factors being well-conditioned or sparse. For the matrix normal model, all our bounds are minimax optimal up to logarithmic factors, and for the tensor normal model our bound for the largest factor and overall covariance matrix are minimax optimal up to constant factors provided there are enough samples for any estimator to obtain constant Frobenius error. In the same regimes as our sample complexity bounds, we show that an iterative procedure to compute the MLE known as the flip-flop algorithm converges linearly with high probability. Our main tool is geodesic strong convexity in the geometry on positive-definite matrices induced by the Fisher information metric. This strong convexity is determined by the expansion of certain random quantum channels. We also provide numerical evidence that combining the flip-flop algorithm with a simple shrinkage estimator can improve performance in the undersampled regime.
Self-appearance-aided Differential Evolution for Motion Transfer
Oct 09, 2021
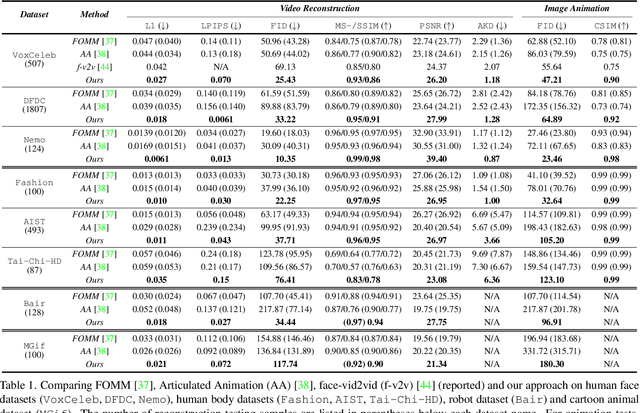
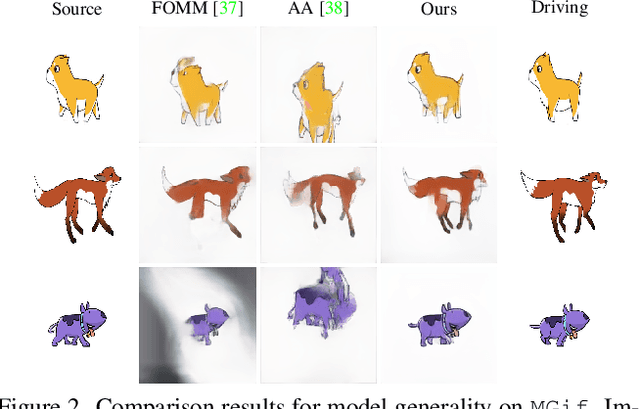
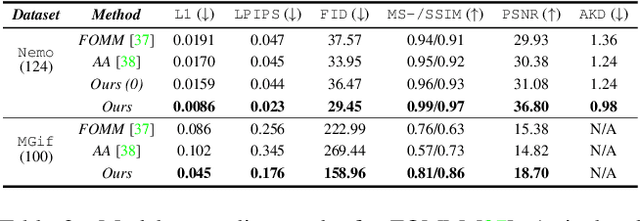
Image animation transfers the motion of a driving video to a static object in a source image, while keeping the source identity unchanged. Great progress has been made in unsupervised motion transfer recently, where no labelled data or ground truth domain priors are needed. However, current unsupervised approaches still struggle when there are large motion or viewpoint discrepancies between the source and driving images. In this paper, we introduce three measures that we found to be effective for overcoming such large viewpoint changes. Firstly, to achieve more fine-grained motion deformation fields, we propose to apply Neural-ODEs for parametrizing the evolution dynamics of the motion transfer from source to driving. Secondly, to handle occlusions caused by large viewpoint and motion changes, we take advantage of the appearance flow obtained from the source image itself ("self-appearance"), which essentially "borrows" similar structures from other regions of an image to inpaint missing regions. Finally, our framework is also able to leverage the information from additional reference views which help to drive the source identity in spite of varying motion state. Extensive experiments demonstrate that our approach outperforms the state-of-the-arts by a significant margin (~40%), across six benchmarks varying from human faces, human bodies to robots and cartoon characters. Model generality analysis indicates that our approach generalises the best across different object categories as well.
Differentiable Quality Diversity
Jun 07, 2021
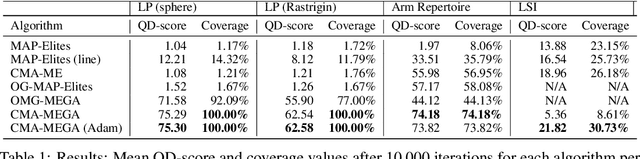
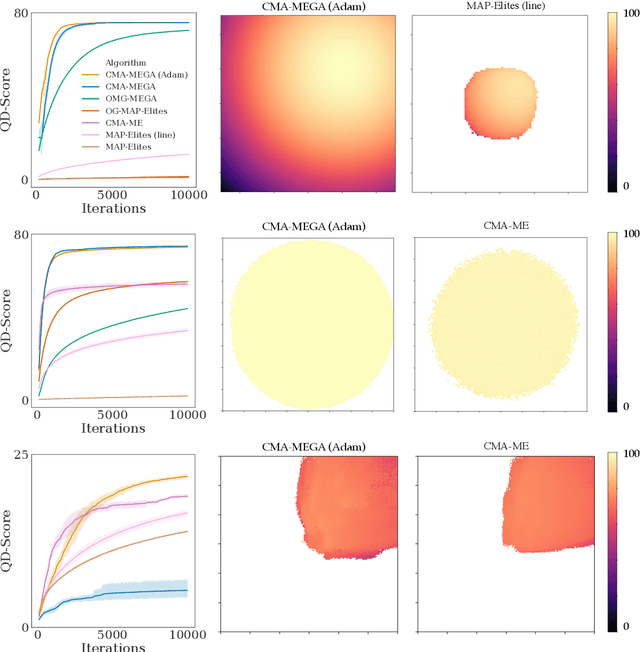
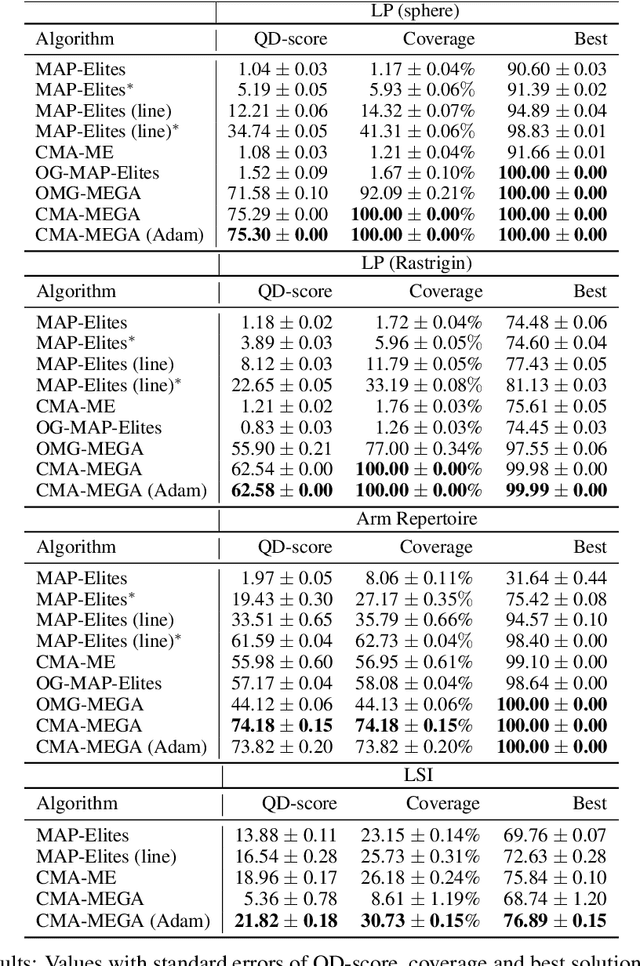
Quality diversity (QD) is a growing branch of stochastic optimization research that studies the problem of generating an archive of solutions that maximize a given objective function but are also diverse with respect to a set of specified measure functions. However, even when these functions are differentiable, QD algorithms treat them as "black boxes", ignoring gradient information. We present the differentiable quality diversity (DQD) problem, a special case of QD, where both the objective and measure functions are first order differentiable. We then present MAP-Elites via Gradient Arborescence (MEGA), a DQD algorithm that leverages gradient information to efficiently explore the joint range of the objective and measure functions. Results in two QD benchmark domains and in searching the latent space of a StyleGAN show that MEGA significantly outperforms state-of-the-art QD algorithms, highlighting DQD's promise for efficient quality diversity optimization when gradient information is available. Source code is available at https://github.com/icaros-usc/dqd.
Event-Based Communication in Multi-Agent Distributed Q-Learning
Sep 09, 2021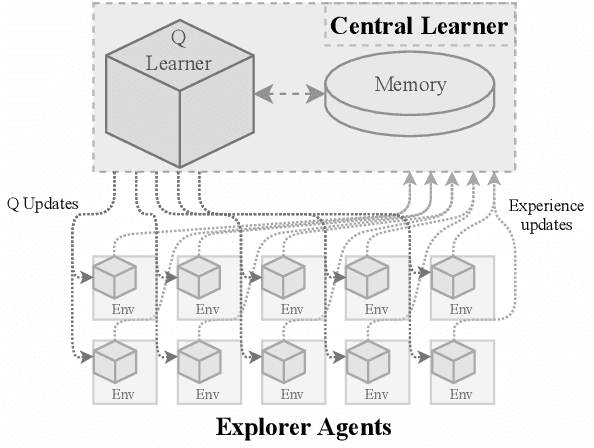
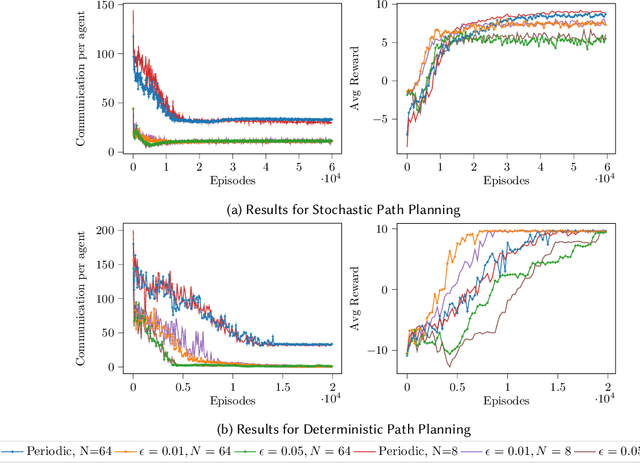
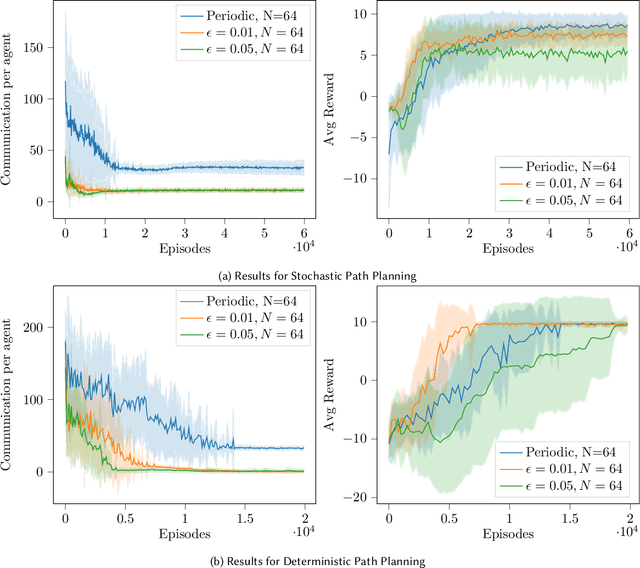
We present in this work an approach to reduce the communication of information needed on a multi-agent learning system inspired by Event Triggered Control (ETC) techniques. We consider a baseline scenario of a distributed Q-learning problem on a Markov Decision Process (MDP). Following an event-based approach, N agents explore the MDP and communicate experiences to a central learner only when necessary, which performs updates of the actor Q functions. We analyse the convergence guarantees retained with respect to a regular Q-learning algorithm, and present experimental results showing that event-based communication results in a substantial reduction of data transmission rates in such distributed systems. Additionally, we discuss what effects (desired and undesired) these event-based approaches have on the learning processes studied, and how they can be applied to more complex multi-agent learning systems.