 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
D{é}composition et analyse de trac{é}s EMG pour aider au diagnostic des maladies neuromusculaires
Sep 30, 2021
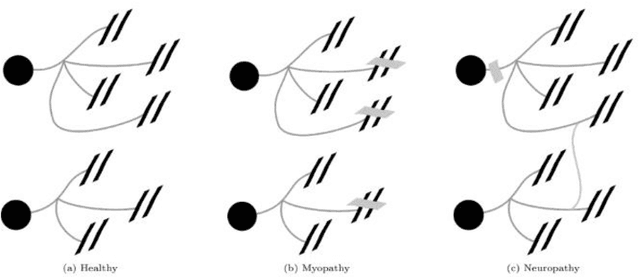
The electromyogram (EMG) in needle detection represents one of the steps of the electroneuromyogram (ENMG), an examination commonly performed in neurology. By inserting a needle into a muscle and studying the contraction during effort, the EMG provides extremely useful information on the functioning of the neuromuscular system of an individual, but it is an examination that remains complex to interpret. The objective of this work is to participate in the design and evaluation of a software allowing an automated analysis of EMG tracings of patients suspected of neuromuscular diseases, orienting the diagnosis towards either a neuropathic or myopathic process from recorded tracings. The software uses a method of signal decomposition according to a Markovian model, based on the analysis of motor unit potentials obtained by EMG, then a classification of the tracings. The tracings of 9 patients were thus analyzed and classified on the basis of the clinical interpretation of the neurologist, making it possible to initiate a "machine learning" process. The software will then be submitted to new tracings in order to test it against a practitioner experienced in EMG analysis.Translated with www.DeepL.com/Translator (free version)
Non asymptotic estimation lower bounds for LTI state space models with Cramér-Rao and van Trees
Sep 17, 2021We study the estimation problem for linear time-invariant (LTI) state-space models with Gaussian excitation of an unknown covariance. We provide non asymptotic lower bounds for the expected estimation error and the mean square estimation risk of the least square estimator, and the minimax mean square estimation risk. These bounds are sharp with explicit constants when the matrix of the dynamics has no eigenvalues on the unit circle and are rate-optimal when they do. Our results extend and improve existing lower bounds to lower bounds in expectation of the mean square estimation risk and to systems with a general noise covariance. Instrumental to our derivation are new concentration results for rescaled sample covariances and deviation results for the corresponding multiplication processes of the covariates, a differential geometric construction of a prior on the unit operator ball of small Fisher information, and an extension of the Cram\'er-Rao and van Treesinequalities to matrix-valued estimators.
A Point Cloud Generative Model via Tree-Structured Graph Convolutions for 3D Brain Shape Reconstruction
Jul 21, 2021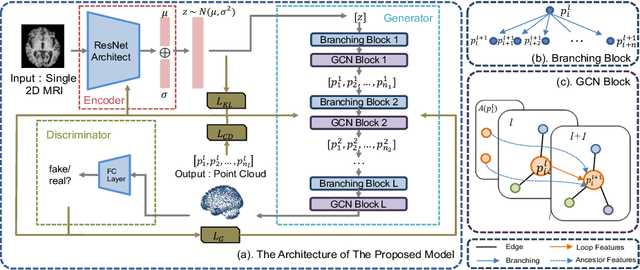

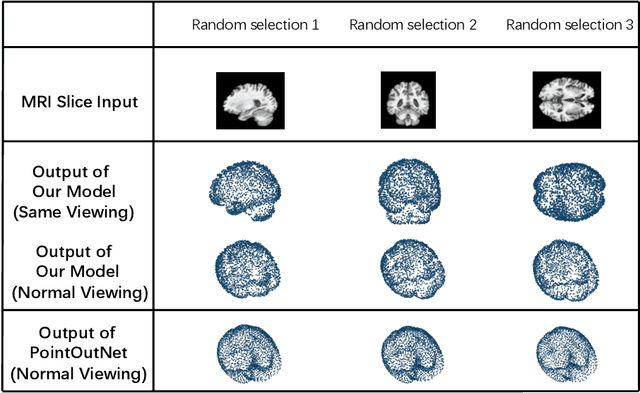

Fusing medical images and the corresponding 3D shape representation can provide complementary information and microstructure details to improve the operational performance and accuracy in brain surgery. However, compared to the substantial image data, it is almost impossible to obtain the intraoperative 3D shape information by using physical methods such as sensor scanning, especially in minimally invasive surgery and robot-guided surgery. In this paper, a general generative adversarial network (GAN) architecture based on graph convolutional networks is proposed to reconstruct the 3D point clouds (PCs) of brains by using one single 2D image, thus relieving the limitation of acquiring 3D shape data during surgery. Specifically, a tree-structured generative mechanism is constructed to use the latent vector effectively and transfer features between hidden layers accurately. With the proposed generative model, a spontaneous image-to-PC conversion is finished in real-time. Competitive qualitative and quantitative experimental results have been achieved on our model. In multiple evaluation methods, the proposed model outperforms another common point cloud generative model PointOutNet.
All-Digital LoS MIMO with Low-Precision Analog-to-Digital Conversion
Aug 02, 2021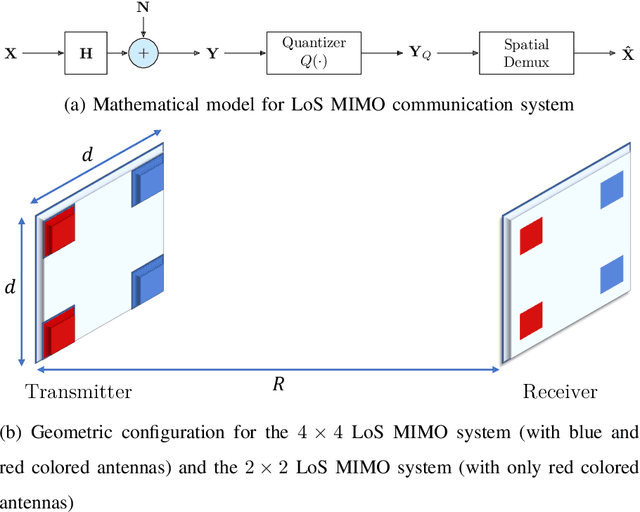
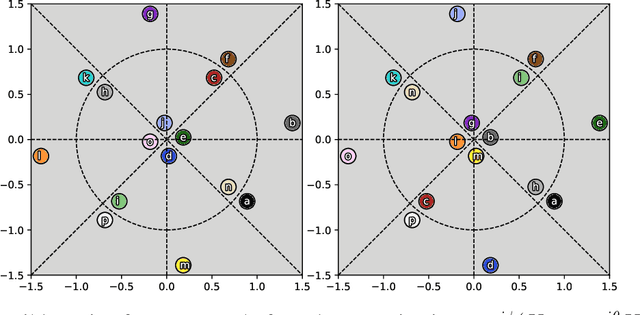
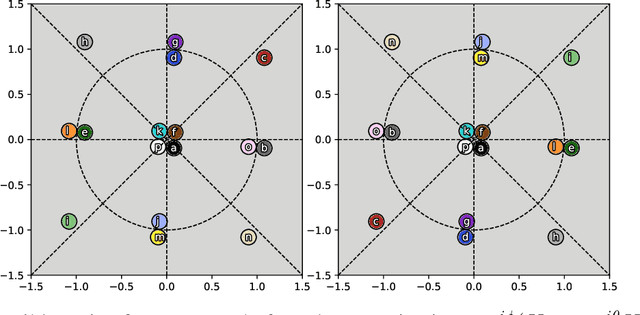
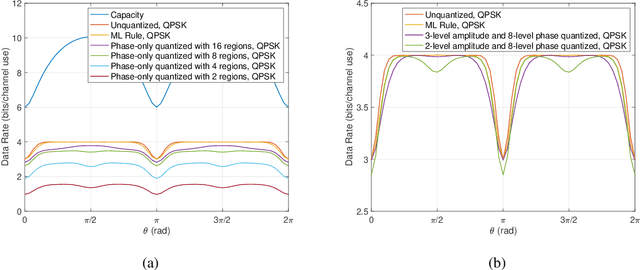
Line-of-sight (LoS) multi-input multi-output (MIMO) systems exhibit attractive scaling properties with increase in carrier frequency: for a fixed form factor and range, the spatial degrees of freedom increase quadratically for 2D arrays, in addition to the typically linear increase in available bandwidth. In this paper, we investigate whether modern all-digital baseband signal processing architectures can be devised for such regimes, given the difficulty of analog-to-digital conversion for large bandwidths. We propose low-precision quantizer designs and accompanying spatial demultiplexing algorithms, considering 2x2 LoS MIMO with QPSK for analytical insight, and 4x4 MIMO with QPSK and 16QAM for performance evaluation. Unlike prior work, channel state information is utilized only at the receiver (i.e., transmit precoding is not employed). We investigate quantizers with regular structure whose high-SNR mutual information approaches that of an unquantized system. We prove that amplitude-phase quantization is necessary to attain this benchmark; phase-only quantization falls short. We show that quantizers based on maximizing per-antenna output entropy perform better than standard Minimum Mean Squared Quantization Error (MMSQE) quantization. For spatial demultiplexing with severely quantized observations, we introduce the novel concept of virtual quantization which, combined with linear detection, provides reliable demodulation at significantly reduced complexity compared to maximum likelihood detection.
Does Data Repair Lead to Fair Models? Curating Contextually Fair Data To Reduce Model Bias
Oct 20, 2021
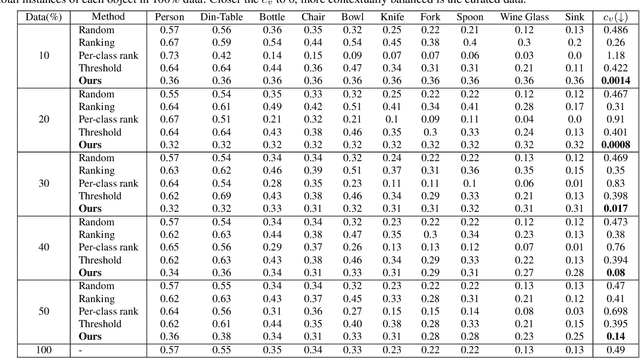
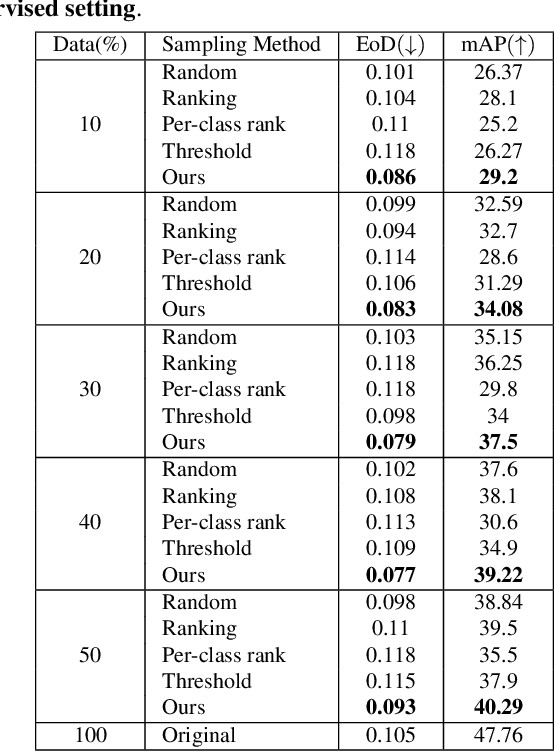
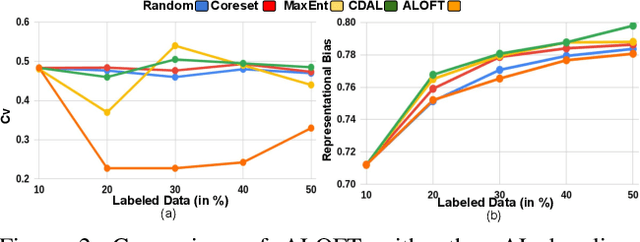
Contextual information is a valuable cue for Deep Neural Networks (DNNs) to learn better representations and improve accuracy. However, co-occurrence bias in the training dataset may hamper a DNN model's generalizability to unseen scenarios in the real world. For example, in COCO, many object categories have a much higher co-occurrence with men compared to women, which can bias a DNN's prediction in favor of men. Recent works have focused on task-specific training strategies to handle bias in such scenarios, but fixing the available data is often ignored. In this paper, we propose a novel and more generic solution to address the contextual bias in the datasets by selecting a subset of the samples, which is fair in terms of the co-occurrence with various classes for a protected attribute. We introduce a data repair algorithm using the coefficient of variation, which can curate fair and contextually balanced data for a protected class(es). This helps in training a fair model irrespective of the task, architecture or training methodology. Our proposed solution is simple, effective, and can even be used in an active learning setting where the data labels are not present or being generated incrementally. We demonstrate the effectiveness of our algorithm for the task of object detection and multi-label image classification across different datasets. Through a series of experiments, we validate that curating contextually fair data helps make model predictions fair by balancing the true positive rate for the protected class across groups without compromising on the model's overall performance.
Terrain-Aware Foot Placement for Bipedal Locomotion Combining Model Predictive Control, Virtual Constraints, and the ALIP
Sep 30, 2021
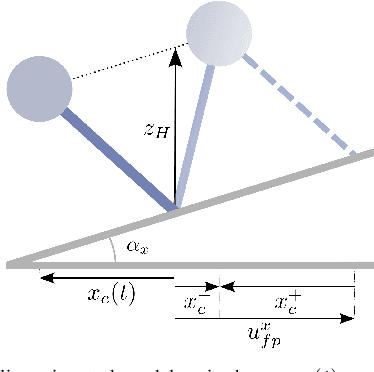

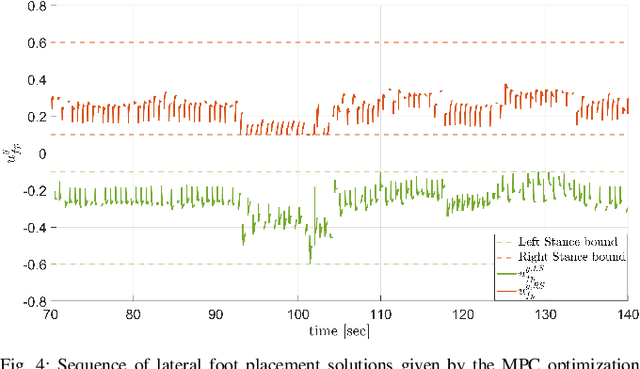
This paper draws upon three themes in the bipedal control literature to achieve highly agile, terrain-aware locomotion. By terrain aware, we mean the robot can use information on terrain slope and friction cone as supplied by state-of-the-art mapping and trajectory planning algorithms. The process starts with abstracting from the full dynamics of a Cassie 3D bipedal robot, an exact low-dimensional representation of its centroidal dynamics, parameterized by angular momentum. Under a piecewise planar terrain assumption, and the elimination of terms for the angular momentum about the robot's center of mass, the centroidal dynamics become linear and has dimension four. Four-step-horizon model predictive control (MPC) of the centroidal dynamics provides step-to-step foot placement commands. Importantly, we also include the intra-step dynamics at 10 ms intervals so that realistic terrain-aware constraints on robot's evolution can be imposed in the MPC formulation. The output of the MPC is directly implemented on Cassie through the method of virtual constraints. In experiments, we validate the performance of our control strategy for the robot on inclined and stationary terrain, both indoors on a treadmill and outdoors on a hill.
SaCoFa: Semantics-aware Control-flow Anonymization for Process Mining
Sep 17, 2021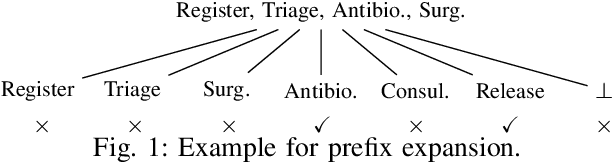
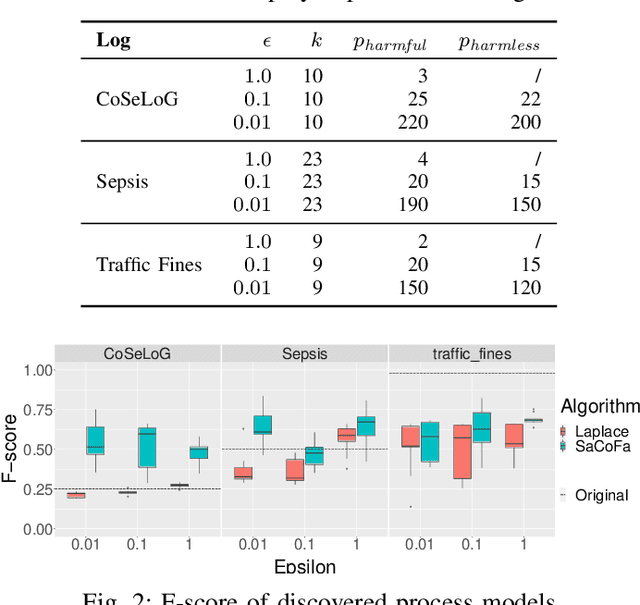
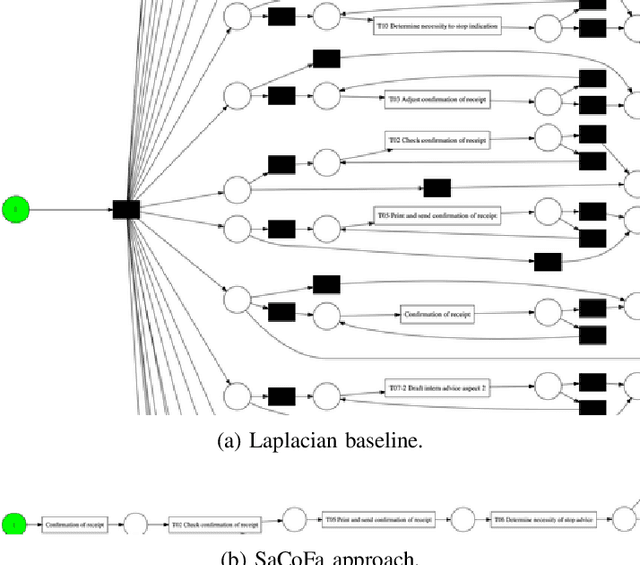
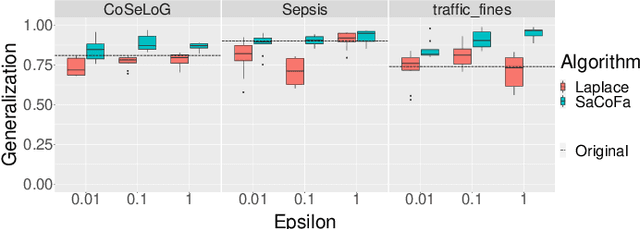
Privacy-preserving process mining enables the analysis of business processes using event logs, while giving guarantees on the protection of sensitive information on process stakeholders. To this end, existing approaches add noise to the results of queries that extract properties of an event log, such as the frequency distribution of trace variants, for analysis.Noise insertion neglects the semantics of the process, though, and may generate traces not present in the original log. This is problematic. It lowers the utility of the published data and makes noise easily identifiable, as some traces will violate well-known semantic constraints.In this paper, we therefore argue for privacy preservation that incorporates a process semantics. For common trace-variant queries, we show how, based on the exponential mechanism, semantic constraints are incorporated to ensure differential privacy of the query result. Experiments demonstrate that our semantics-aware anonymization yields event logs of significantly higher utility than existing approaches.
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
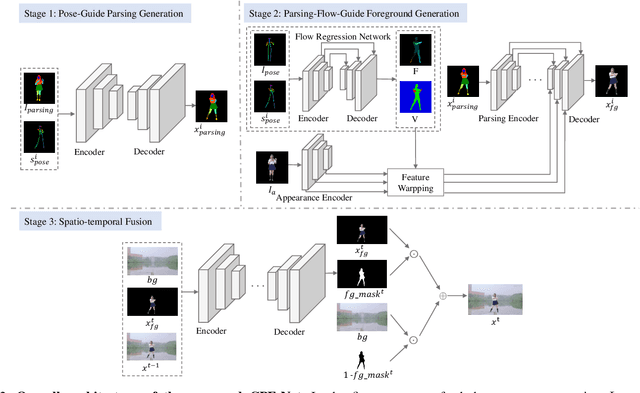


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.
SpaceMeshLab: Spatial Context Memoization and Meshgrid Atrous Convolution Consensus for Semantic Segmentation
Jun 08, 2021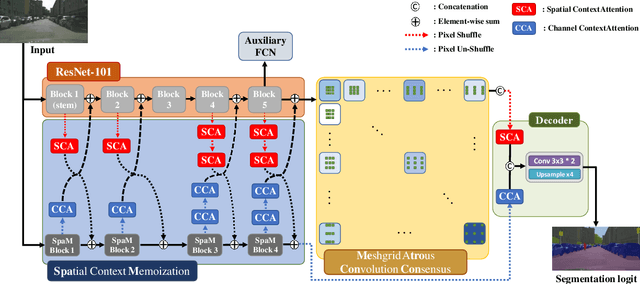

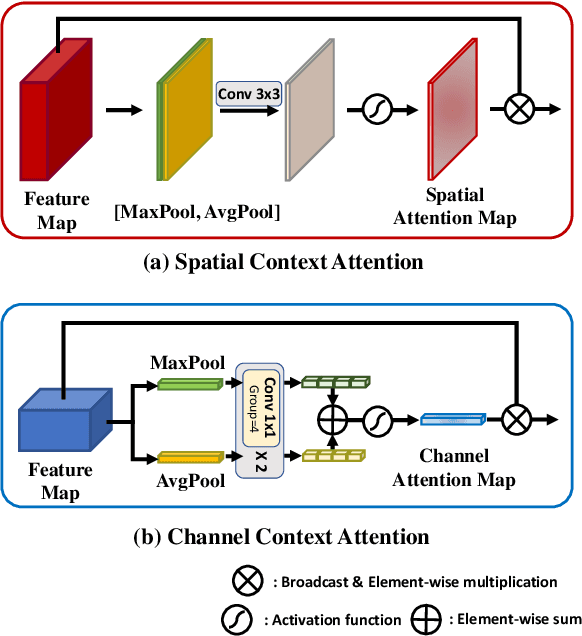

Semantic segmentation networks adopt transfer learning from image classification networks which occurs a shortage of spatial context information. For this reason, we propose Spatial Context Memoization (SpaM), a bypassing branch for spatial context by retaining the input dimension and constantly communicating its spatial context and rich semantic information mutually with the backbone network. Multi-scale context information for semantic segmentation is crucial for dealing with diverse sizes and shapes of target objects in the given scene. Conventional multi-scale context scheme adopts multiple effective receptive fields by multiple dilation rates or pooling operations, but often suffer from misalignment problem with respect to the target pixel. To this end, we propose Meshgrid Atrous Convolution Consensus (MetroCon^2) which brings multi-scale scheme into fine-grained multi-scale object context using convolutions with meshgrid-like scattered dilation rates. SpaceMeshLab (ResNet-101 + SpaM + MetroCon^2) achieves 82.0% mIoU in Cityscapes test and 53.5% mIoU on Pascal-Context validation set.
Decentralized Cooperative Lane Changing at Freeway Weaving Areas Using Multi-Agent Deep Reinforcement Learning
Oct 05, 2021
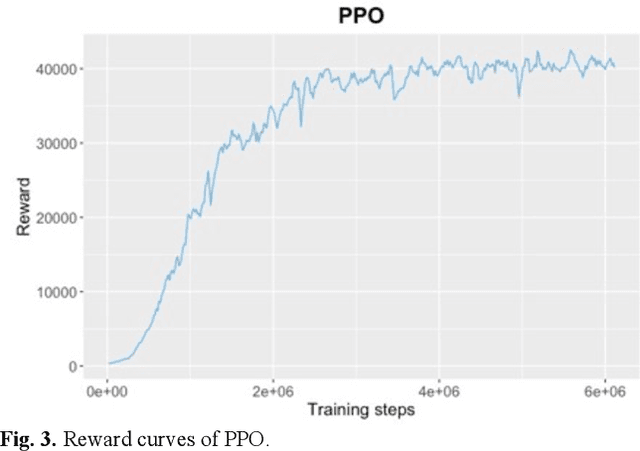
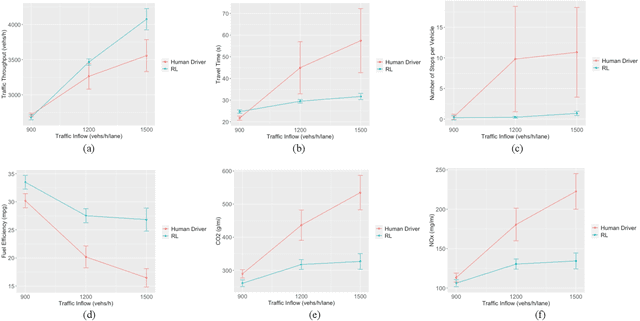
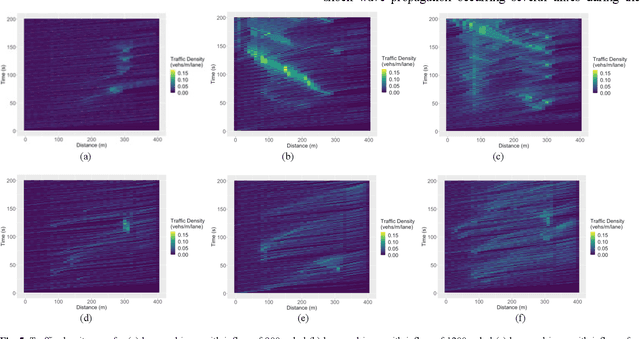
Frequent lane changes during congestion at freeway bottlenecks such as merge and weaving areas further reduce roadway capacity. The emergence of deep reinforcement learning (RL) and connected and automated vehicle technology provides a possible solution to improve mobility and energy efficiency at freeway bottlenecks through cooperative lane changing. Deep RL is a collection of machine-learning methods that enables an agent to improve its performance by learning from the environment. In this study, a decentralized cooperative lane-changing controller was developed using proximal policy optimization by adopting a multi-agent deep RL paradigm. In the decentralized control strategy, policy learning and action reward are evaluated locally, with each agent (vehicle) getting access to global state information. Multi-agent deep RL requires lower computational resources and is more scalable than single-agent deep RL, making it a powerful tool for time-sensitive applications such as cooperative lane changing. The results of this study show that cooperative lane changing enabled by multi-agent deep RL yields superior performance to human drivers in term of traffic throughput, vehicle speed, number of stops per vehicle, vehicle fuel efficiency, and emissions. The trained RL policy is transferable and can be generalized to uncongested, moderately congested, and extremely congested traffic conditions.