 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Variational voxelwise rs-fMRI representation learning: Evaluation of sex, age, and neuropsychiatric signatures
Aug 29, 2021
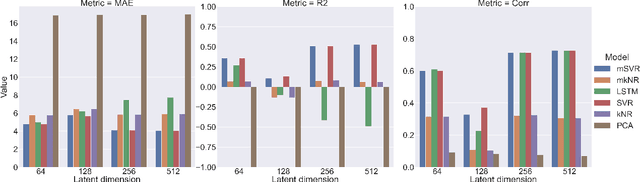
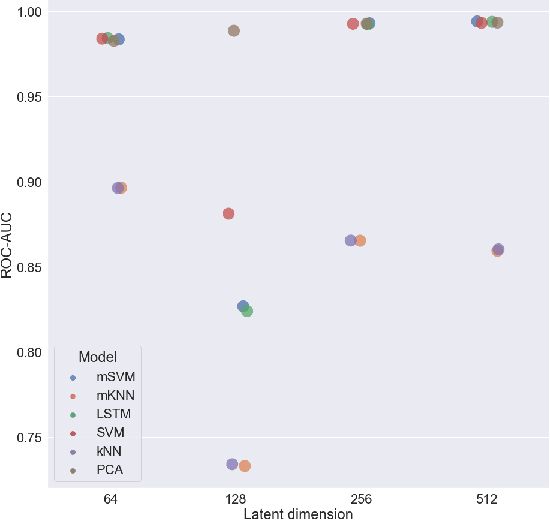
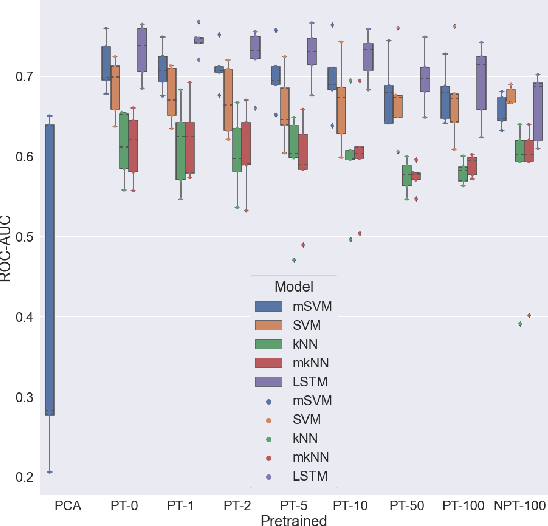
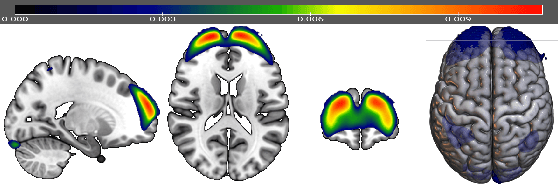
We propose to apply non-linear representation learning to voxelwise rs-fMRI data. Learning the non-linear representations is done using a variational autoencoder (VAE). The VAE is trained on voxelwise rs-fMRI data and performs non-linear dimensionality reduction that retains meaningful information. The retention of information in the model's representations is evaluated using downstream age regression and sex classification tasks. The results on these tasks are highly encouraging and a linear regressor trained with the representations of our unsupervised model performs almost as well as a supervised neural network, trained specifically for age regression on the same dataset. The model is also evaluated with a schizophrenia diagnosis prediction task, to assess its feasibility as a dimensionality reduction method for neuropsychiatric datasets. These results highlight the potential for pre-training on a larger set of individuals who do not have mental illness, to improve the downstream neuropsychiatric task results. The pre-trained model is fine-tuned for a variable number of epochs on a schizophrenia dataset and we find that fine-tuning for 1 epoch yields the best results. This work therefore not only opens up non-linear dimensionality reduction for voxelwise rs-fMRI data but also shows that pre-training a deep learning model on voxelwise rs-fMRI datasets greatly increases performance even on smaller datasets. It also opens up the ability to look at the distribution of rs-fMRI time series in the latent space of the VAE for heterogeneous neuropsychiatric disorders like schizophrenia in future work. This can be complemented with the generative aspect of the model that allows us to reconstruct points from the model's latent space back into brain space and obtain an improved understanding of the relation that the VAE learns between subjects, timepoints, and a subject's characteristics.
It's not what you said, it's how you said it: discriminative perception of speech as a multichannel communication system
May 01, 2021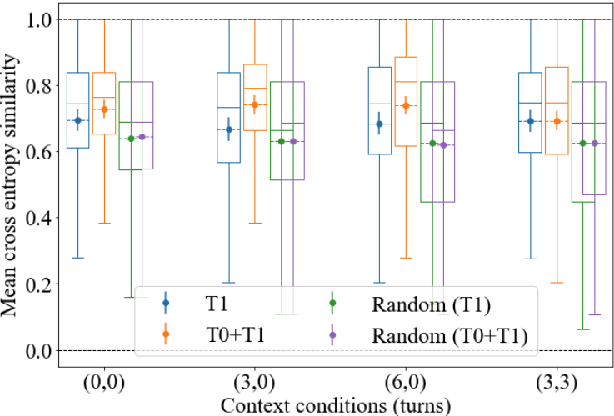
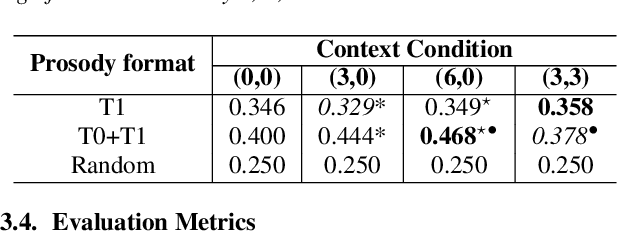
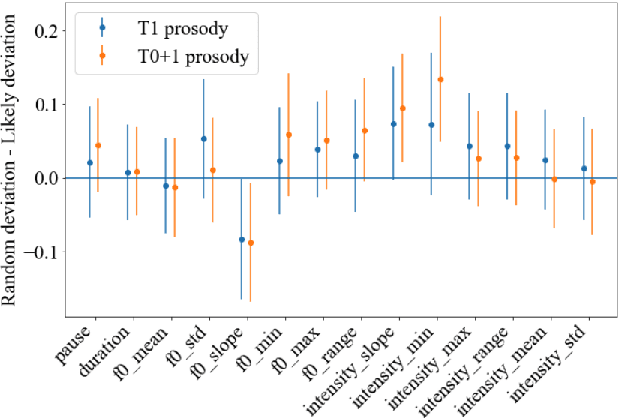
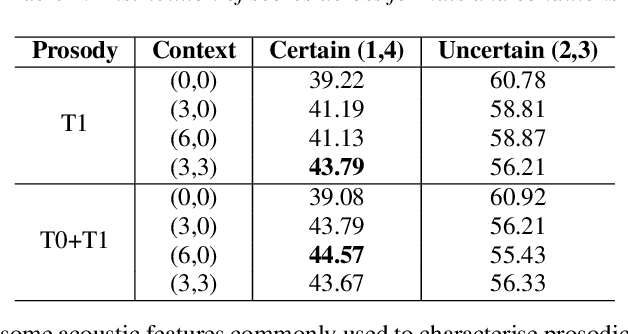
People convey information extremely effectively through spoken interaction using multiple channels of information transmission: the lexical channel of what is said, and the non-lexical channel of how it is said. We propose studying human perception of spoken communication as a means to better understand how information is encoded across these channels, focusing on the question 'What characteristics of communicative context affect listener's expectations of speech?'. To investigate this, we present a novel behavioural task testing whether listeners can discriminate between the true utterance in a dialogue and utterances sampled from other contexts with the same lexical content. We characterize how perception - and subsequent discriminative capability - is affected by different degrees of additional contextual information across both the lexical and non-lexical channel of speech. Results demonstrate that people can effectively discriminate between different prosodic realisations, that non-lexical context is informative, and that this channel provides more salient information than the lexical channel, highlighting the importance of the non-lexical channel in spoken interaction.
AMRA*: Anytime Multi-Resolution Multi-Heuristic A*
Oct 11, 2021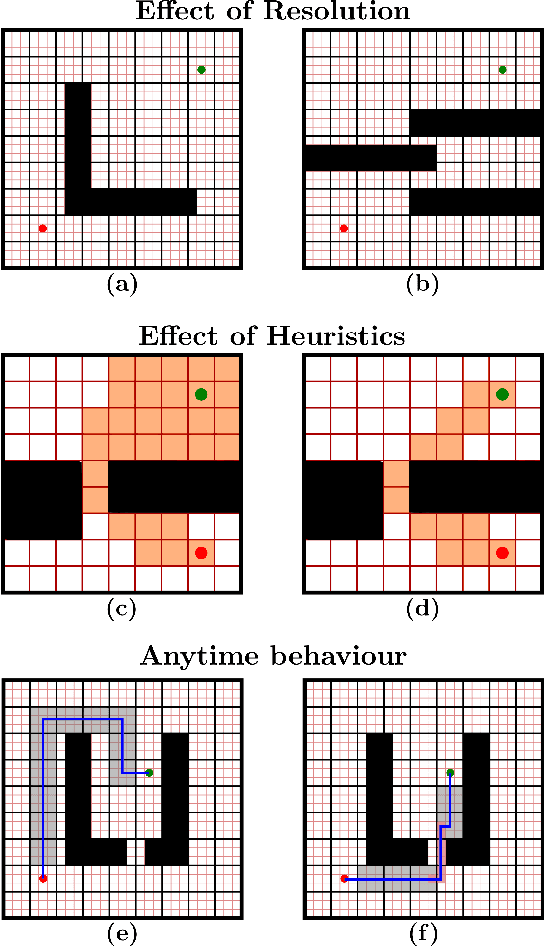
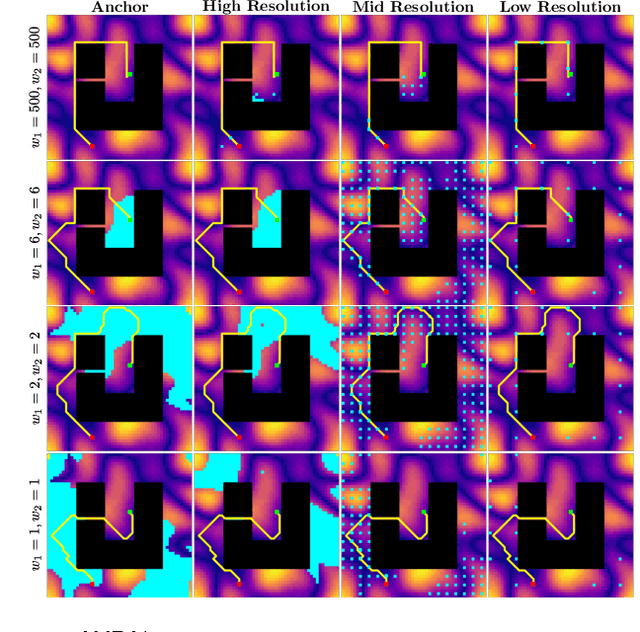

Heuristic search-based motion planning algorithms typically discretise the search space in order to solve the shortest path problem. Their performance is closely related to this discretisation. A fine discretisation allows for better approximations of the continuous search space, but makes the search for a solution more computationally costly. A coarser resolution might allow the algorithms to find solutions quickly at the expense of quality. For large state spaces, it can be beneficial to search for solutions across multiple resolutions even though defining the discretisations is challenging. The recently proposed algorithm Multi-Resolution A* (MRA*) searches over multiple resolutions. It traverses large areas of obstacle-free space and escapes local minima at a coarse resolution. It can also navigate so-called narrow passageways at a finer resolution. In this work, we develop AMRA*, an anytime version of MRA*. AMRA* tries to find a solution quickly using the coarse resolution as much as possible. It then refines the solution by relying on the fine resolution to discover better paths that may not have been available at the coarse resolution. In addition to being anytime, AMRA* can also leverage information sharing between multiple heuristics. We prove that AMRA* is complete and optimal (in-the-limit of time) with respect to the finest resolution. We show its performance on 2D grid navigation and 4D kinodynamic planning problems.
Low SNR Capacity of Keyhole MIMO Channel in Nakagami-m Fading With Full CSI
Sep 07, 2021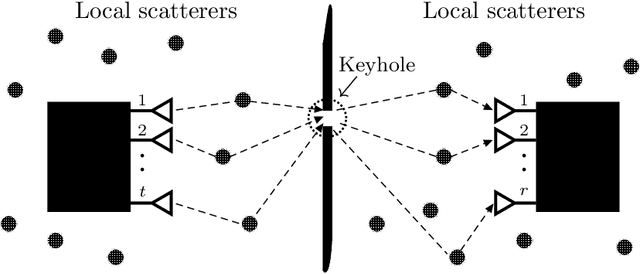
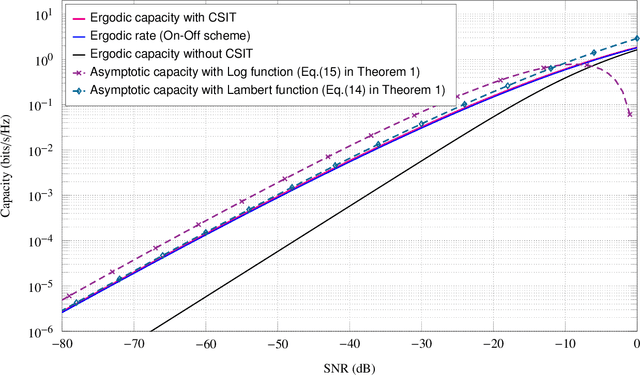
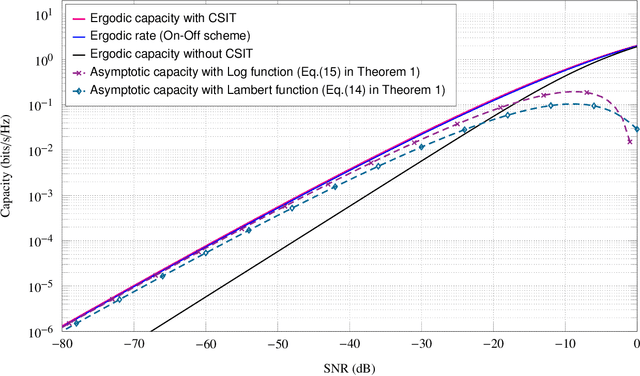
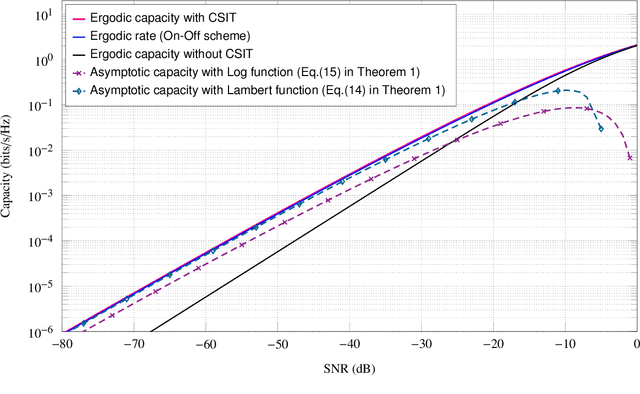
In this paper, we derive asymptotic expressions for the ergodic capacity of the multiple-input multiple-output (MIMO) keyhole channel at low SNR in independent and identically distributed (i.i.d.) Nakagami-$m$ fading conditions with perfect channel state information available at both the transmitter (CSI-T) and the receiver (CSI-R). We show that the low-SNR capacity of this keyhole channel scales proportionally as $\frac{\textrm{SNR}}{4} \log^2 \left(1/{\textrm{SNR}}\right)$. Further, we develop a practically appealing On-Off transmission scheme that is aymptotically capacity achieving at low SNR; it requires only one-bit CSI-T feedback and is robust against both mild and severe Nakagami-$m$ fadings for a very wide range of low-SNR values. These results also extend to the Rayleigh keyhole MIMO channel as a special case.
Novel Features for Time Series Analysis: A Complex Networks Approach
Oct 11, 2021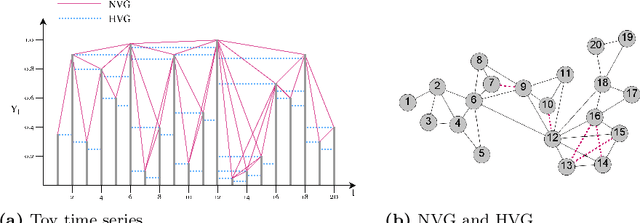
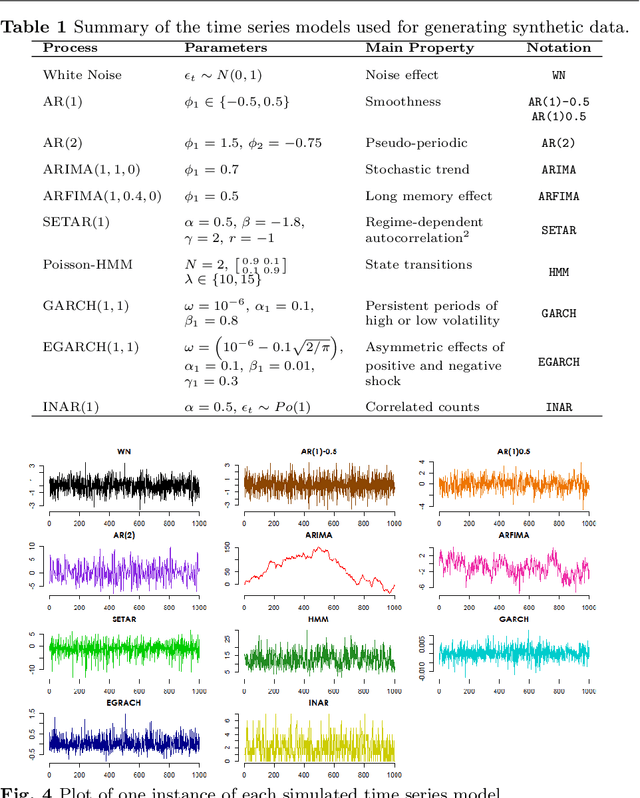
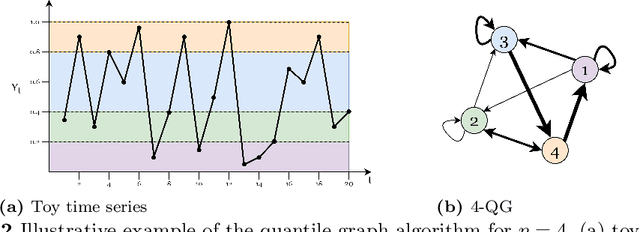
Time series data are ubiquitous in several domains as climate, economics and health care. Mining features from these time series is a crucial task with a multidisciplinary impact. Usually, these features are obtained from structural characteristics of time series, such as trend, seasonality and autocorrelation, sometimes requiring data transformations and parametric models. A recent conceptual approach relies on time series mapping to complex networks, where the network science methodologies can help characterize time series. In this paper, we consider two mapping concepts, visibility and transition probability and propose network topological measures as a new set of time series features. To evaluate the usefulness of the proposed features, we address the problem of time series clustering. More specifically, we propose a clustering method that consists in mapping the time series into visibility graphs and quantile graphs, calculating global topological metrics of the resulting networks, and using data mining techniques to form clusters. We apply this method to a data sets of synthetic and empirical time series. The results indicate that network-based features capture the information encoded in each of the time series models, resulting in high accuracy in a clustering task. Our results are promising and show that network analysis can be used to characterize different types of time series and that different mapping methods capture different characteristics of the time series.
Is An Image Worth Five Sentences? A New Look into Semantics for Image-Text Matching
Oct 06, 2021


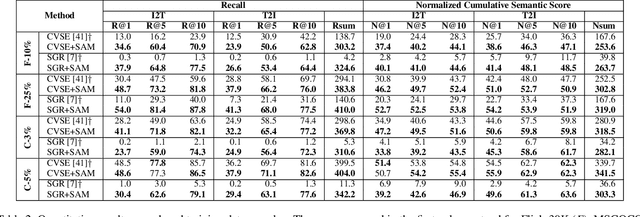
The task of image-text matching aims to map representations from different modalities into a common joint visual-textual embedding. However, the most widely used datasets for this task, MSCOCO and Flickr30K, are actually image captioning datasets that offer a very limited set of relationships between images and sentences in their ground-truth annotations. This limited ground truth information forces us to use evaluation metrics based on binary relevance: given a sentence query we consider only one image as relevant. However, many other relevant images or captions may be present in the dataset. In this work, we propose two metrics that evaluate the degree of semantic relevance of retrieved items, independently of their annotated binary relevance. Additionally, we incorporate a novel strategy that uses an image captioning metric, CIDEr, to define a Semantic Adaptive Margin (SAM) to be optimized in a standard triplet loss. By incorporating our formulation to existing models, a \emph{large} improvement is obtained in scenarios where available training data is limited. We also demonstrate that the performance on the annotated image-caption pairs is maintained while improving on other non-annotated relevant items when employing the full training set. Code with our metrics and adaptive margin formulation will be made public.
Deep Artificial Intelligence for Fantasy Football Language Understanding
Nov 04, 2021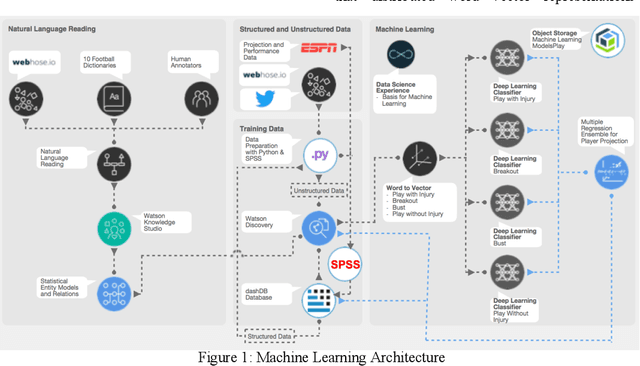
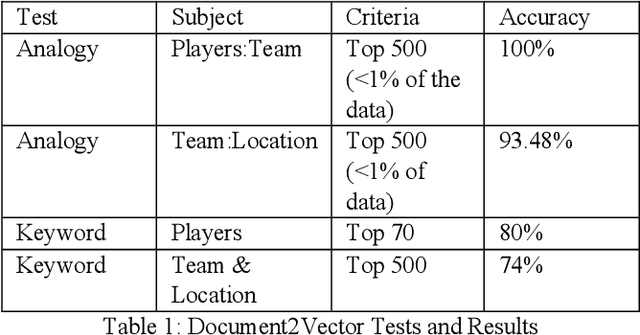
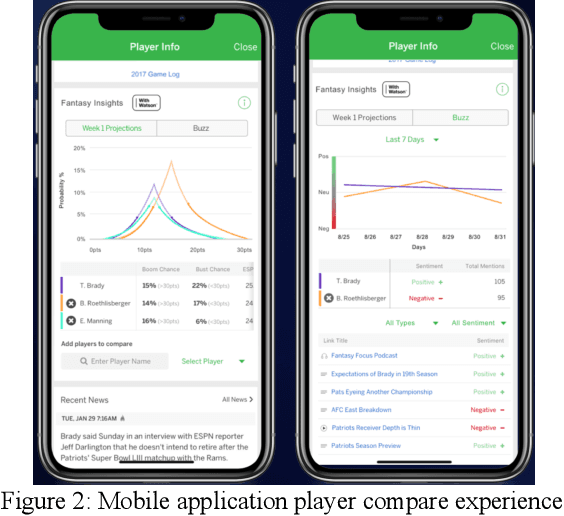
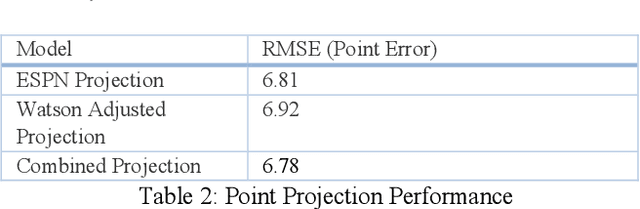
Fantasy sports allow fans to manage a team of their favorite athletes and compete with friends. The fantasy platform aligns the real-world statistical performance of athletes to fantasy scoring and has steadily risen in popularity to an estimated 9.1 million players per month with 4.4 billion player card views on the ESPN Fantasy Football platform from 2018-2019. In parallel, the sports media community produces news stories, blogs, forum posts, tweets, videos, podcasts and opinion pieces that are both within and outside the context of fantasy sports. However, human fantasy football players can only analyze an average of 3.9 sources of information. Our work discusses the results of a machine learning pipeline to manage an ESPN Fantasy Football team. The use of trained statistical entity detectors and document2vector models applied to over 100,000 news sources and 2.3 million articles, videos and podcasts each day enables the system to comprehend natural language with an analogy test accuracy of 100% and keyword test accuracy of 80%. Deep learning feedforward neural networks provide player classifications such as if a player will be a bust, boom, play with a hidden injury or play meaningful touches with a cumulative 72% accuracy. Finally, a multiple regression ensemble uses the deep learning output and ESPN projection data to provide a point projection for each of the top 500+ fantasy football players in 2018. The point projection maintained a RMSE of 6.78 points. The best fit probability density function from a set of 24 is selected to visualize score spreads. Within the first 6 weeks of the product launch, the total number of users spent a cumulative time of over 4.6 years viewing our AI insights. The training data for our models was provided by a 2015 to 2016 web archive from Webhose, ESPN statistics, and Rotowire injury reports. We used 2017 fantasy football data as a test set.
Kompetenzerwerbsförderung durch E-Assessment: Individuelle Kompetenzerfassung am Beispiel des Fachs Mathematik
Aug 20, 2021In this article, we present a concept of how micro- and e-assessments can be used for the mathematical domain to automatically determine acquired and missing individual skills and, based on these information, guide individuals to acquire missing or additional skills in a software-supported process. The models required for this concept are a digitally prepared and annotated e-assessment item pool, a digital modeling of the domain that includes topics, necessary competencies, as well as introductory and continuative material, as well as a digital individual model, which can reliably record competencies and integrates aspects about the loss of such.
Weakly-Supervised Spatio-Temporal Anomaly Detection in Surveillance Video
Aug 09, 2021
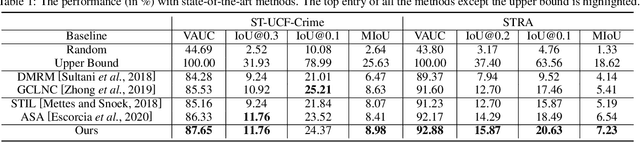
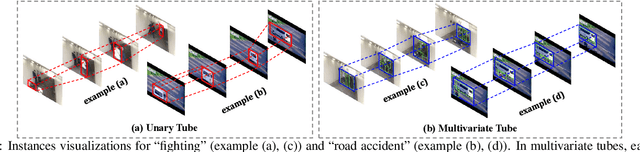
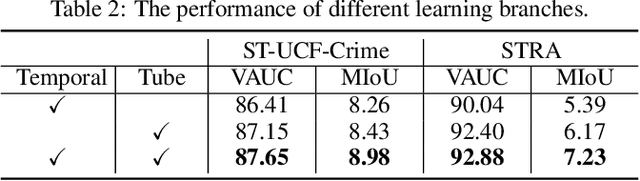
In this paper, we introduce a novel task, referred to as Weakly-Supervised Spatio-Temporal Anomaly Detection (WSSTAD) in surveillance video. Specifically, given an untrimmed video, WSSTAD aims to localize a spatio-temporal tube (i.e., a sequence of bounding boxes at consecutive times) that encloses the abnormal event, with only coarse video-level annotations as supervision during training. To address this challenging task, we propose a dual-branch network which takes as input the proposals with multi-granularities in both spatial-temporal domains. Each branch employs a relationship reasoning module to capture the correlation between tubes/videolets, which can provide rich contextual information and complex entity relationships for the concept learning of abnormal behaviors. Mutually-guided Progressive Refinement framework is set up to employ dual-path mutual guidance in a recurrent manner, iteratively sharing auxiliary supervision information across branches. It impels the learned concepts of each branch to serve as a guide for its counterpart, which progressively refines the corresponding branch and the whole framework. Furthermore, we contribute two datasets, i.e., ST-UCF-Crime and STRA, consisting of videos containing spatio-temporal abnormal annotations to serve as the benchmarks for WSSTAD. We conduct extensive qualitative and quantitative evaluations to demonstrate the effectiveness of the proposed approach and analyze the key factors that contribute more to handle this task.
Aug3D-RPN: Improving Monocular 3D Object Detection by Synthetic Images with Virtual Depth
Jul 28, 2021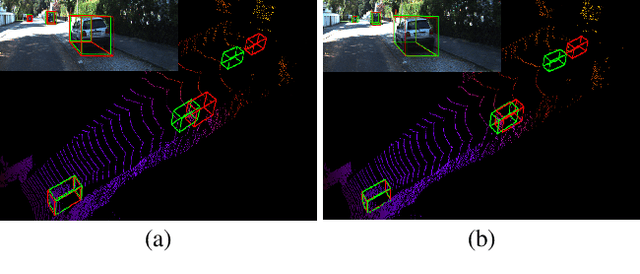
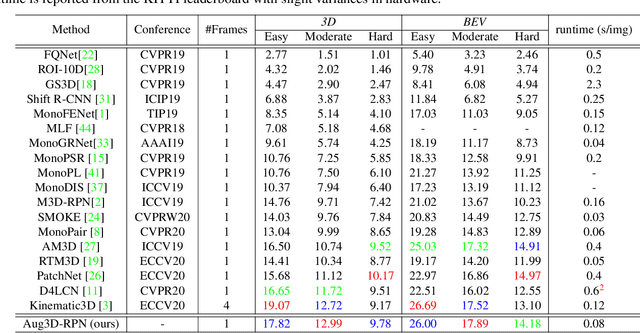
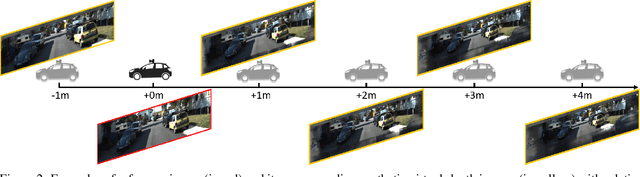
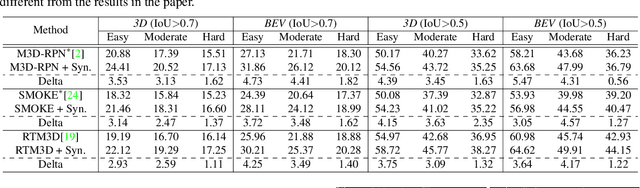
Current geometry-based monocular 3D object detection models can efficiently detect objects by leveraging perspective geometry, but their performance is limited due to the absence of accurate depth information. Though this issue can be alleviated in a depth-based model where a depth estimation module is plugged to predict depth information before 3D box reasoning, the introduction of such module dramatically reduces the detection speed. Instead of training a costly depth estimator, we propose a rendering module to augment the training data by synthesizing images with virtual-depths. The rendering module takes as input the RGB image and its corresponding sparse depth image, outputs a variety of photo-realistic synthetic images, from which the detection model can learn more discriminative features to adapt to the depth changes of the objects. Besides, we introduce an auxiliary module to improve the detection model by jointly optimizing it through a depth estimation task. Both modules are working in the training time and no extra computation will be introduced to the detection model. Experiments show that by working with our proposed modules, a geometry-based model can represent the leading accuracy on the KITTI 3D detection benchmark.