 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Human-in-the-Loop Refinement of Word Embeddings
Oct 06, 2021
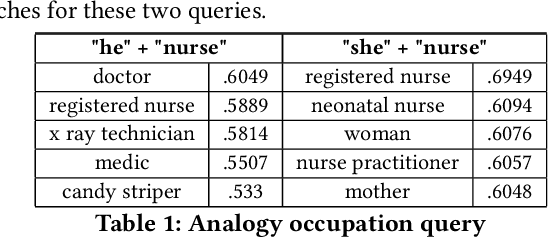
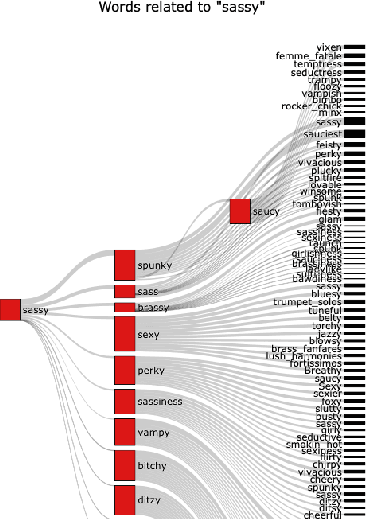
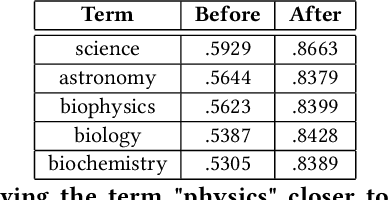
Word embeddings are a fixed, distributional representation of the context of words in a corpus learned from word co-occurrences. Despite their proven utility in machine learning tasks, word embedding models may capture uneven semantic and syntactic representations, and can inadvertently reflect various kinds of bias present within corpora upon which they were trained. It has been demonstrated that post-processing of word embeddings to apply information found in lexical dictionaries can improve the semantic associations, thus improving their quality. Building on this idea, we propose a system that incorporates an adaptation of word embedding post-processing, which we call "interactive refitting", to address some of the most daunting qualitative problems found in word embeddings. Our approach allows a human to identify and address potential quality issues with word embeddings interactively. This has the advantage of negating the question of who decides what constitutes bias or what other quality issues may affect downstream tasks. It allows each organization or entity to address concerns they may have at a fine grained level and to do so in an iterative and interactive fashion. It also allows for better insight into what effect word embeddings, and refinements to word embeddings, have on machine learning pipelines.
Augmenting Visual Question Answering with Semantic Frame Information in a Multitask Learning Approach
Jan 31, 2020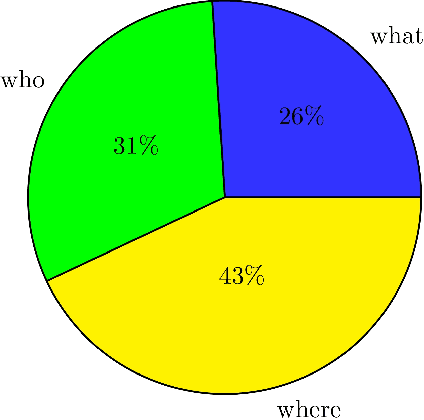
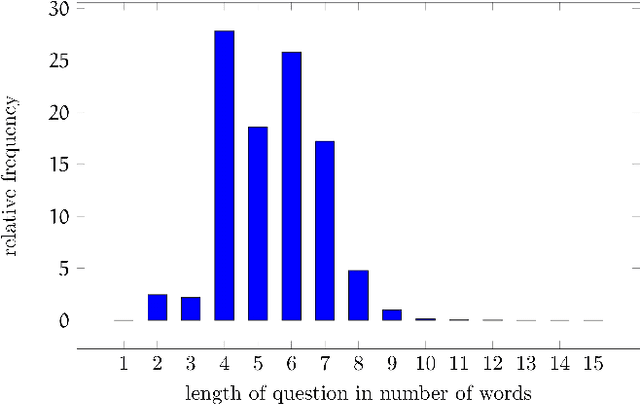
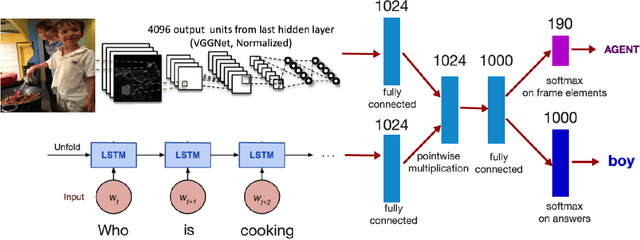
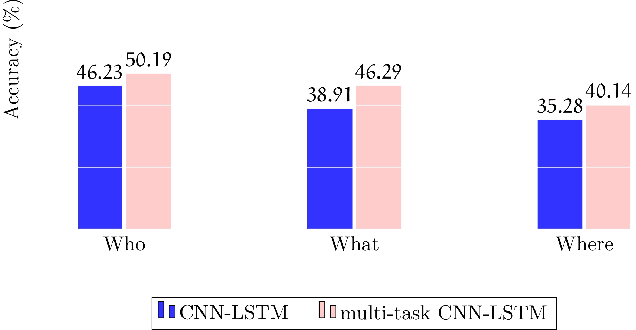
Visual Question Answering (VQA) concerns providing answers to Natural Language questions about images. Several deep neural network approaches have been proposed to model the task in an end-to-end fashion. Whereas the task is grounded in visual processing, if the question focuses on events described by verbs, the language understanding component becomes crucial. Our hypothesis is that models should be aware of verb semantics, as expressed via semantic role labels, argument types, and/or frame elements. Unfortunately, no VQA dataset exists that includes verb semantic information. Our first contribution is a new VQA dataset (imSituVQA) that we built by taking advantage of the imSitu annotations. The imSitu dataset consists of images manually labeled with semantic frame elements, mostly taken from FrameNet. Second, we propose a multitask CNN-LSTM VQA model that learns to classify the answers as well as the semantic frame elements. Our experiments show that semantic frame element classification helps the VQA system avoid inconsistent responses and improves performance.
Improvement of image classification by multiple optical scattering
Jul 12, 2021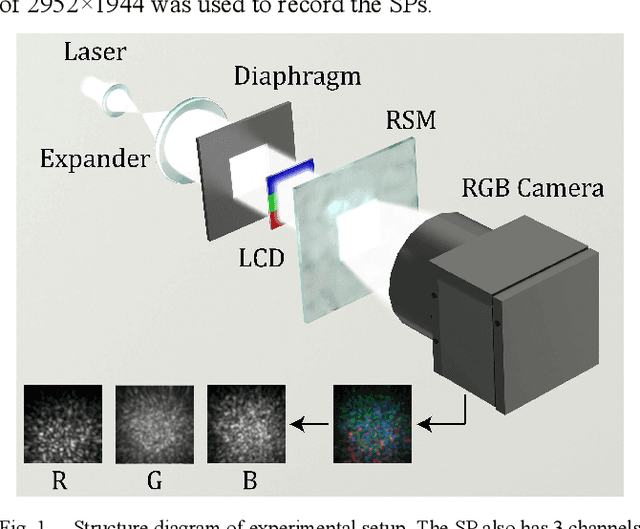
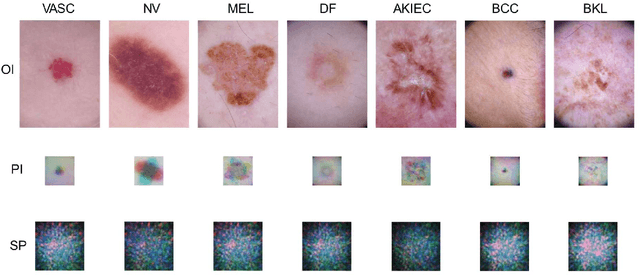
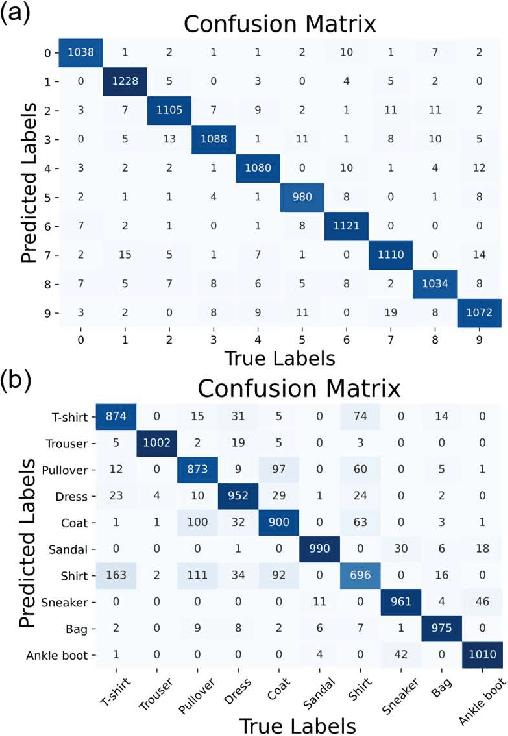
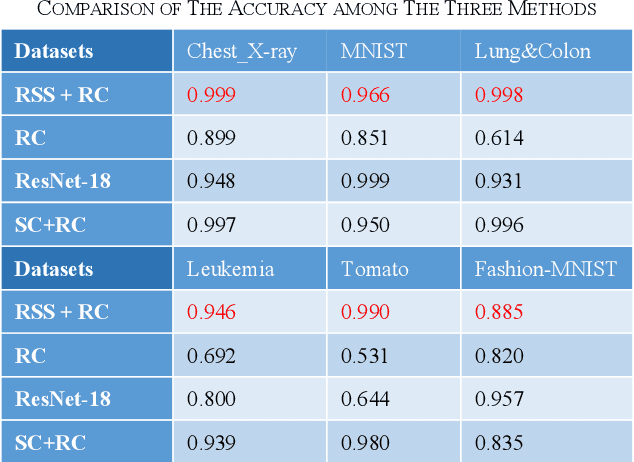
Multiple optical scattering occurs when light propagates in a non-uniform medium. During the multiple scattering, images were distorted and the spatial information they carried became scrambled. However, the image information is not lost but presents in the form of speckle patterns (SPs). In this study, we built up an optical random scattering system based on an LCD and an RGB laser source. We found that the image classification can be improved by the help of random scattering which is considered as a feedforward neural network to extracts features from image. Along with the ridge classification deployed on computer, we achieved excellent classification accuracy higher than 94%, for a variety of data sets covering medical, agricultural, environmental protection and other fields. In addition, the proposed optical scattering system has the advantages of high speed, low power consumption, and miniaturization, which is suitable for deploying in edge computing applications.
NOPE: A Corpus of Naturally-Occurring Presuppositions in English
Sep 14, 2021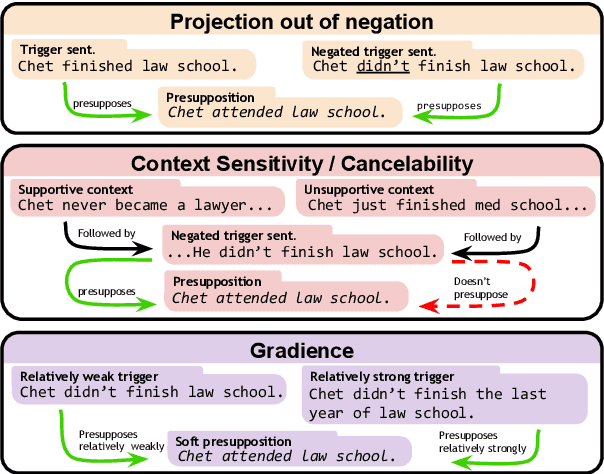
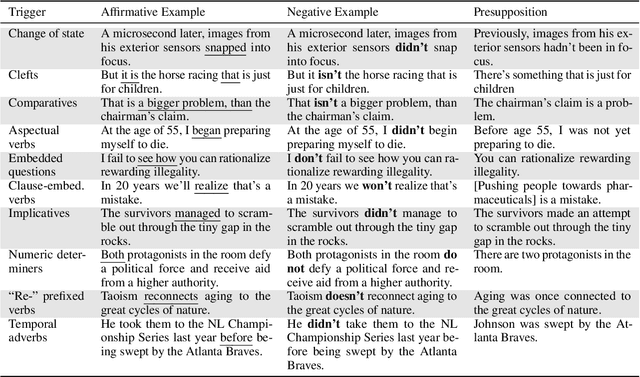
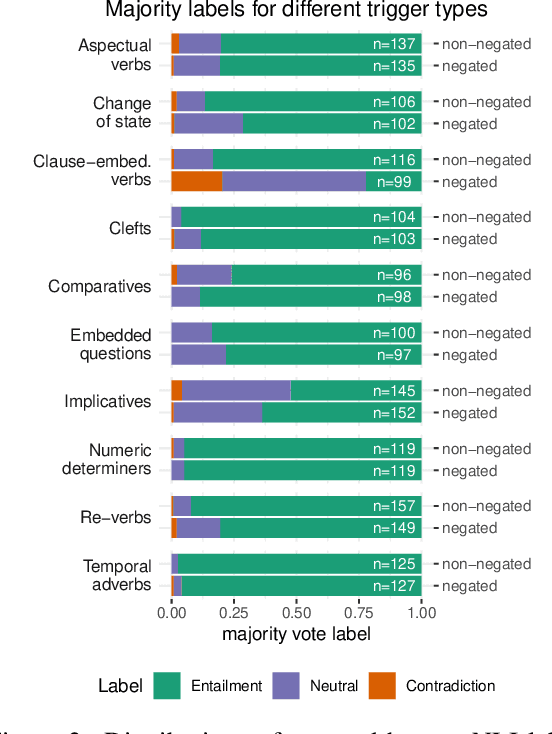
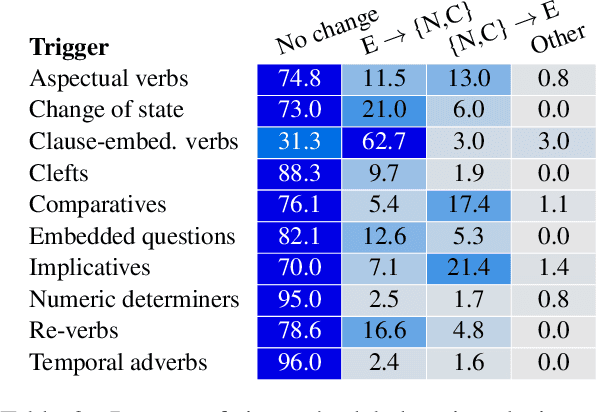
Understanding language requires grasping not only the overtly stated content, but also making inferences about things that were left unsaid. These inferences include presuppositions, a phenomenon by which a listener learns about new information through reasoning about what a speaker takes as given. Presuppositions require complex understanding of the lexical and syntactic properties that trigger them as well as the broader conversational context. In this work, we introduce the Naturally-Occurring Presuppositions in English (NOPE) Corpus to investigate the context-sensitivity of 10 different types of presupposition triggers and to evaluate machine learning models' ability to predict human inferences. We find that most of the triggers we investigate exhibit moderate variability. We further find that transformer-based models draw correct inferences in simple cases involving presuppositions, but they fail to capture the minority of exceptional cases in which human judgments reveal complex interactions between context and triggers.
CCMI : Classifier based Conditional Mutual Information Estimation
Jun 05, 2019
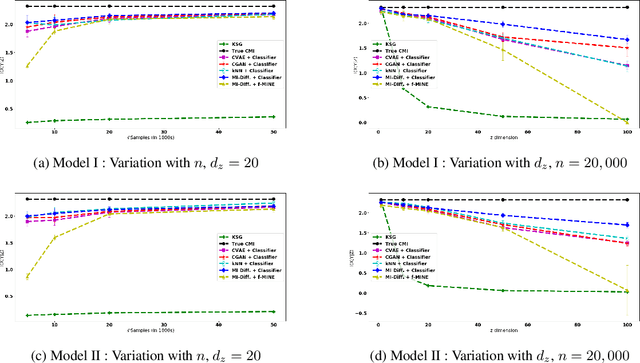
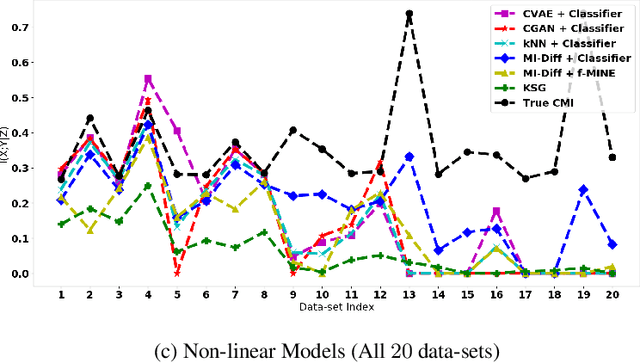
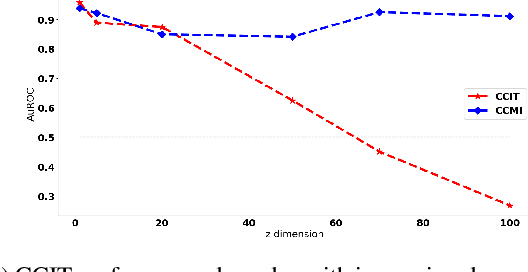
Conditional Mutual Information (CMI) is a measure of conditional dependence between random variables X and Y, given another random variable Z. It can be used to quantify conditional dependence among variables in many data-driven inference problems such as graphical models, causal learning, feature selection and time-series analysis. While k-nearest neighbor (kNN) based estimators as well as kernel-based methods have been widely used for CMI estimation, they suffer severely from the curse of dimensionality. In this paper, we leverage advances in classifiers and generative models to design methods for CMI estimation. Specifically, we introduce an estimator for KL-Divergence based on the likelihood ratio by training a classifier to distinguish the observed joint distribution from the product distribution. We then show how to construct several CMI estimators using this basic divergence estimator by drawing ideas from conditional generative models. We demonstrate that the estimates from our proposed approaches do not degrade in performance with increasing dimension and obtain significant improvement over the widely used KSG estimator. Finally, as an application of accurate CMI estimation, we use our best estimator for conditional independence testing and achieve superior performance than the state-of-the-art tester on both simulated and real data-sets.
An information criterion for auxiliary variable selection in incomplete data analysis
Mar 09, 2019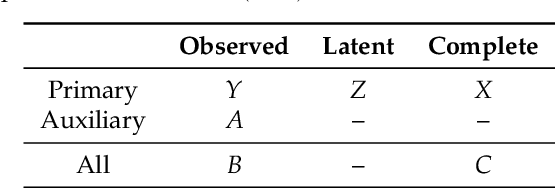
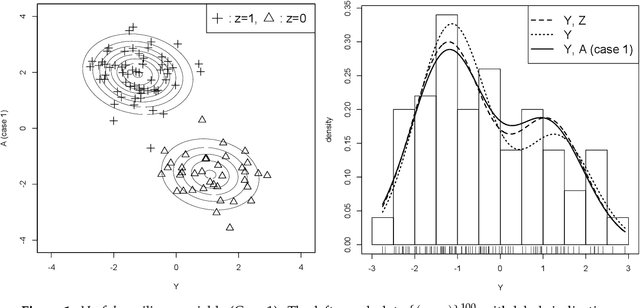
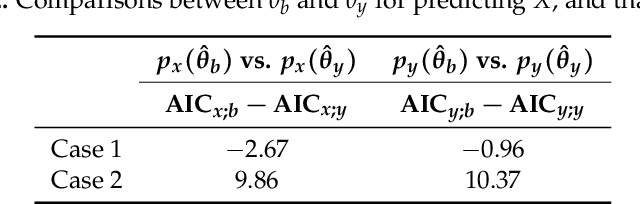
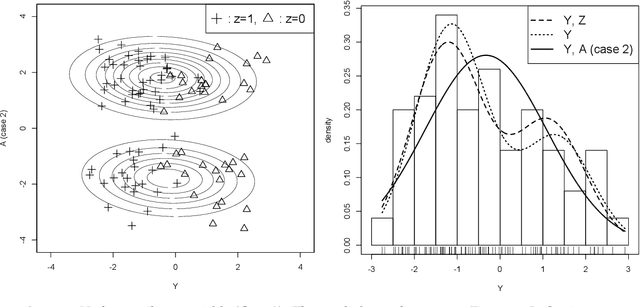
Statistical inference is considered for variables of interest, called primary variables, when auxiliary variables are observed along with the primary variables. We consider the setting of incomplete data analysis, where some primary variables are not observed. Utilizing a parametric model of joint distribution of primary and auxiliary variables, it is possible to improve the estimation of parametric model for the primary variables when the auxiliary variables are closely related to the primary variables. However, the estimation accuracy reduces when the auxiliary variables are irrelevant to the primary variables. For selecting useful auxiliary variables, we formulate the problem as model selection, and propose an information criterion for predicting primary variables by leveraging auxiliary variables. The proposed information criterion is an asymptotically unbiased estimator of the Kullback-Leibler divergence for complete data of primary variables under some reasonable conditions. We also clarify an asymptotic equivalence between the proposed information criterion and a variant of leave-one-out cross validation. Performance of our method is demonstrated via a simulation study and a real data example.
Efficient Behavior-aware Control of Automated Vehicles at Crosswalks using Minimal Information Pedestrian Prediction Model
Mar 22, 2020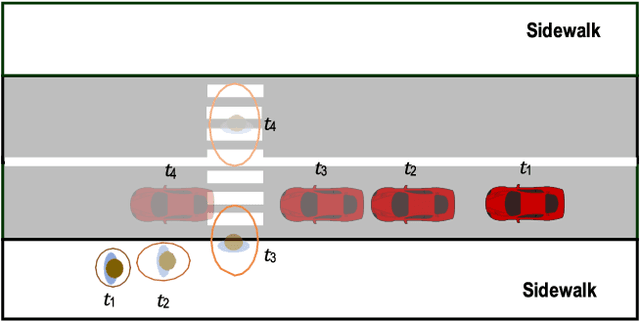
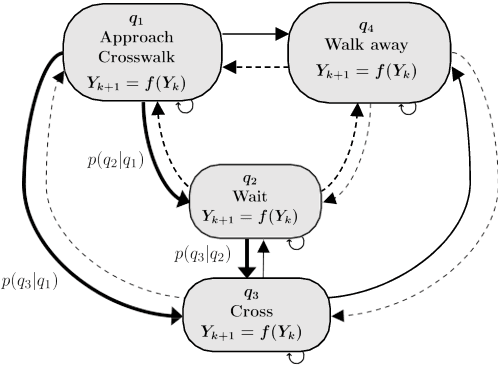
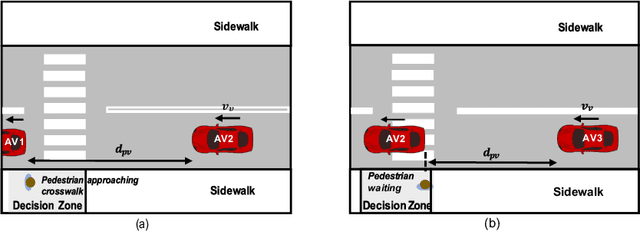
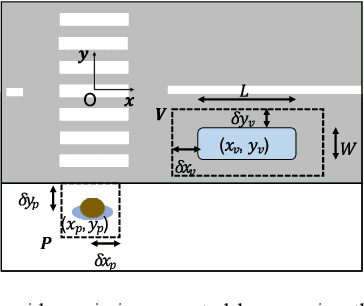
For automated vehicles (AVs) to reliably navigate through crosswalks, they need to understand pedestrians crossing behaviors. Simple and reliable pedestrian behavior models aid in real-time AV control by allowing the AVs to predict future pedestrian behaviors. In this paper, we present a Behavior aware Model Predictive Controller (B-MPC) for AVs that incorporates long-term predictions of pedestrian crossing behavior using a previously developed pedestrian crossing model. The model incorporates pedestrians gap acceptance behavior and utilizes minimal pedestrian information, namely their position and speed, to predict pedestrians crossing behaviors. The BMPC controller is validated through simulations and compared to a rule-based controller. By incorporating predictions of pedestrian behavior, the B-MPC controller is able to efficiently plan for longer horizons and handle a wider range of pedestrian interaction scenarios than the rule-based controller. Results demonstrate the applicability of the controller for safe and efficient navigation at crossing scenarios.
AMRA*: Anytime Multi-Resolution Multi-Heuristic A*
Oct 11, 2021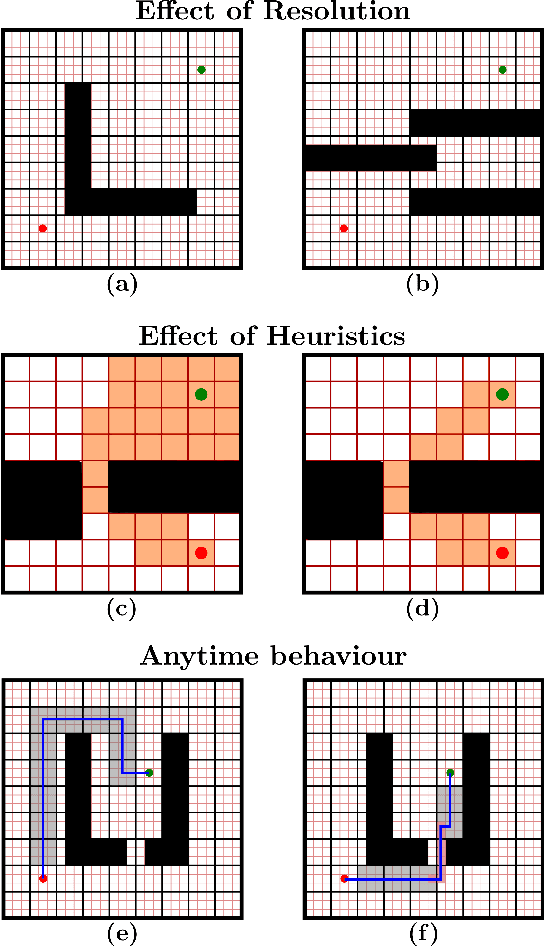
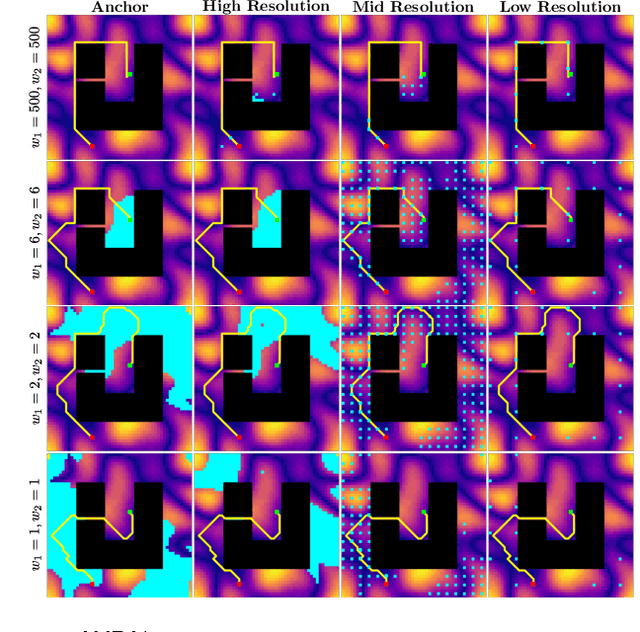

Heuristic search-based motion planning algorithms typically discretise the search space in order to solve the shortest path problem. Their performance is closely related to this discretisation. A fine discretisation allows for better approximations of the continuous search space, but makes the search for a solution more computationally costly. A coarser resolution might allow the algorithms to find solutions quickly at the expense of quality. For large state spaces, it can be beneficial to search for solutions across multiple resolutions even though defining the discretisations is challenging. The recently proposed algorithm Multi-Resolution A* (MRA*) searches over multiple resolutions. It traverses large areas of obstacle-free space and escapes local minima at a coarse resolution. It can also navigate so-called narrow passageways at a finer resolution. In this work, we develop AMRA*, an anytime version of MRA*. AMRA* tries to find a solution quickly using the coarse resolution as much as possible. It then refines the solution by relying on the fine resolution to discover better paths that may not have been available at the coarse resolution. In addition to being anytime, AMRA* can also leverage information sharing between multiple heuristics. We prove that AMRA* is complete and optimal (in-the-limit of time) with respect to the finest resolution. We show its performance on 2D grid navigation and 4D kinodynamic planning problems.
Variational voxelwise rs-fMRI representation learning: Evaluation of sex, age, and neuropsychiatric signatures
Aug 29, 2021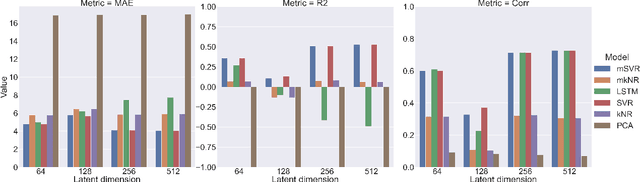
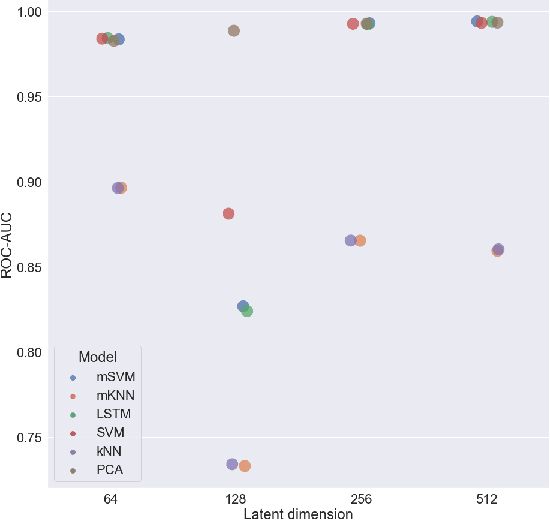
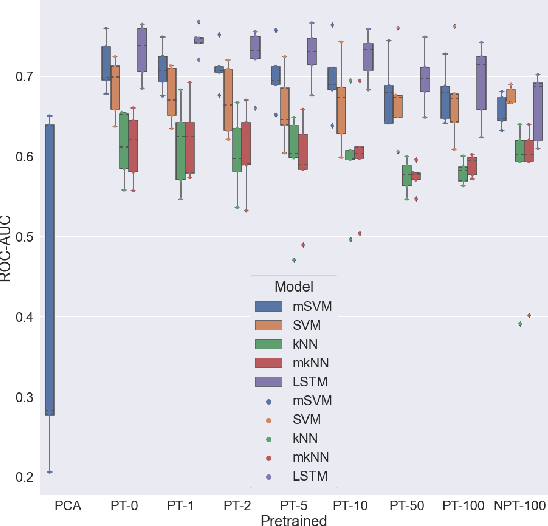
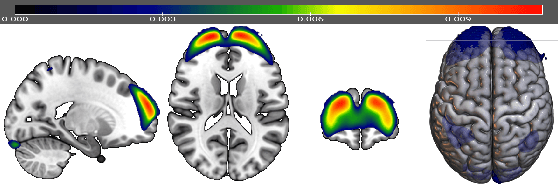
We propose to apply non-linear representation learning to voxelwise rs-fMRI data. Learning the non-linear representations is done using a variational autoencoder (VAE). The VAE is trained on voxelwise rs-fMRI data and performs non-linear dimensionality reduction that retains meaningful information. The retention of information in the model's representations is evaluated using downstream age regression and sex classification tasks. The results on these tasks are highly encouraging and a linear regressor trained with the representations of our unsupervised model performs almost as well as a supervised neural network, trained specifically for age regression on the same dataset. The model is also evaluated with a schizophrenia diagnosis prediction task, to assess its feasibility as a dimensionality reduction method for neuropsychiatric datasets. These results highlight the potential for pre-training on a larger set of individuals who do not have mental illness, to improve the downstream neuropsychiatric task results. The pre-trained model is fine-tuned for a variable number of epochs on a schizophrenia dataset and we find that fine-tuning for 1 epoch yields the best results. This work therefore not only opens up non-linear dimensionality reduction for voxelwise rs-fMRI data but also shows that pre-training a deep learning model on voxelwise rs-fMRI datasets greatly increases performance even on smaller datasets. It also opens up the ability to look at the distribution of rs-fMRI time series in the latent space of the VAE for heterogeneous neuropsychiatric disorders like schizophrenia in future work. This can be complemented with the generative aspect of the model that allows us to reconstruct points from the model's latent space back into brain space and obtain an improved understanding of the relation that the VAE learns between subjects, timepoints, and a subject's characteristics.
A frame semantic overview of NLP-based information extraction for cancer-related EHR notes
Apr 02, 2019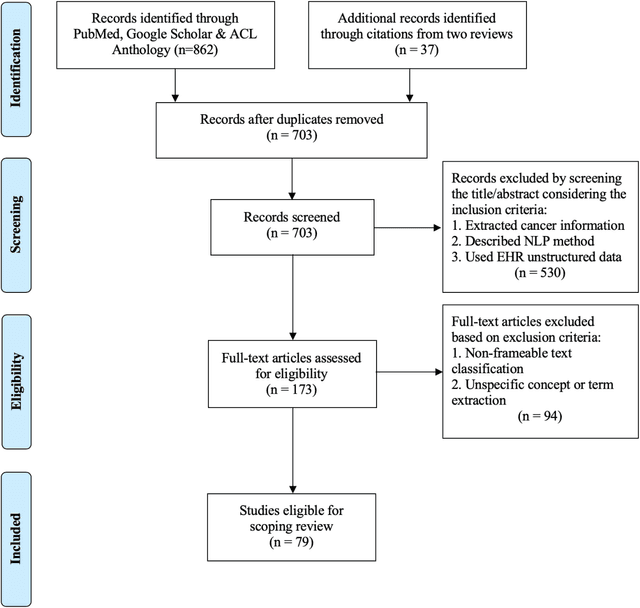
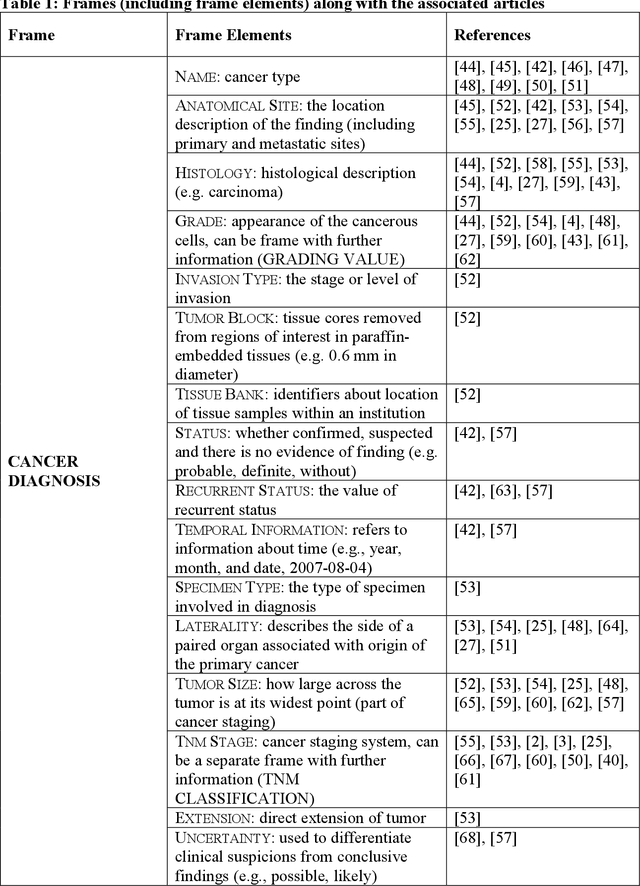
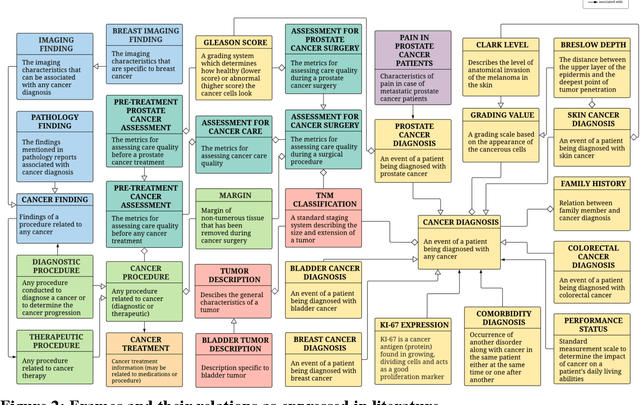
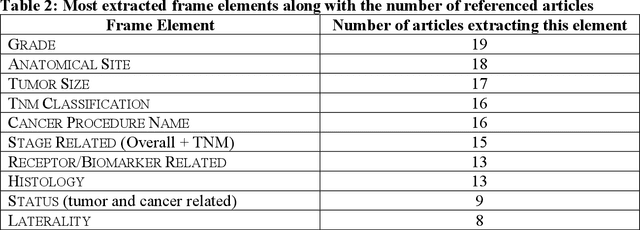
Objective: There is a lot of information about cancer in Electronic Health Record (EHR) notes that can be useful for biomedical research provided natural language processing (NLP) methods are available to extract and structure this information. In this paper, we present a scoping review of existing clinical NLP literature for cancer. Methods: We identified studies describing an NLP method to extract specific cancer-related information from EHR sources from PubMed, Google Scholar, ACL Anthology, and existing reviews. Two exclusion criteria were used in this study. We excluded articles where the extraction techniques used were too broad to be represented as frames and also where very low-level extraction methods were used. 79 articles were included in the final review. We organized this information according to frame semantic principles to help identify common areas of overlap and potential gaps. Results: Frames were created from the reviewed articles pertaining to cancer information such as cancer diagnosis, tumor description, cancer procedure, breast cancer diagnosis, prostate cancer diagnosis and pain in prostate cancer patients. These frames included both a definition as well as specific frame elements (i.e. extractable attributes). We found that cancer diagnosis was the most common frame among the reviewed papers (36 out of 79), with recent work focusing on extracting information related to treatment and breast cancer diagnosis. Conclusion: The list of common frames described in this paper identifies important cancer-related information extracted by existing NLP techniques and serves as a useful resource for future researchers requiring cancer information extracted from EHR notes. We also argue, due to the heavy duplication of cancer NLP systems, that a general purpose resource of annotated cancer frames and corresponding NLP tools would be valuable.