 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
It's not what you said, it's how you said it: discriminative perception of speech as a multichannel communication system
May 01, 2021
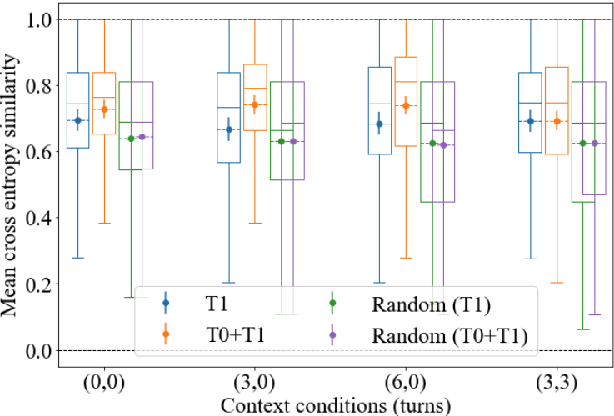
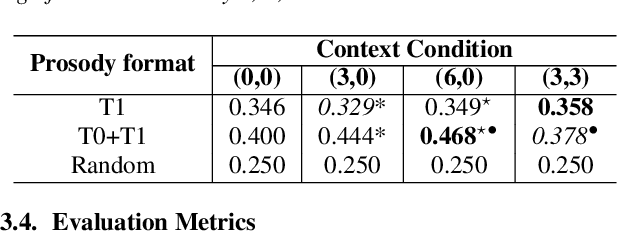
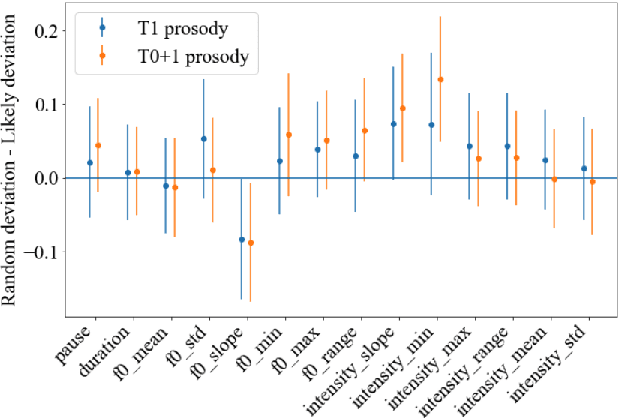
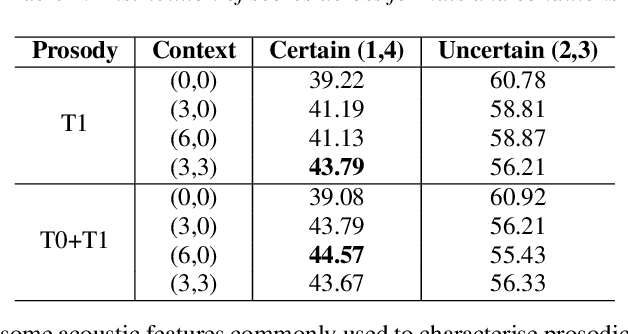
People convey information extremely effectively through spoken interaction using multiple channels of information transmission: the lexical channel of what is said, and the non-lexical channel of how it is said. We propose studying human perception of spoken communication as a means to better understand how information is encoded across these channels, focusing on the question 'What characteristics of communicative context affect listener's expectations of speech?'. To investigate this, we present a novel behavioural task testing whether listeners can discriminate between the true utterance in a dialogue and utterances sampled from other contexts with the same lexical content. We characterize how perception - and subsequent discriminative capability - is affected by different degrees of additional contextual information across both the lexical and non-lexical channel of speech. Results demonstrate that people can effectively discriminate between different prosodic realisations, that non-lexical context is informative, and that this channel provides more salient information than the lexical channel, highlighting the importance of the non-lexical channel in spoken interaction.
Multi-Task Learning in Natural Language Processing: An Overview
Sep 19, 2021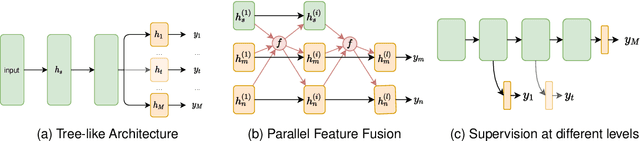
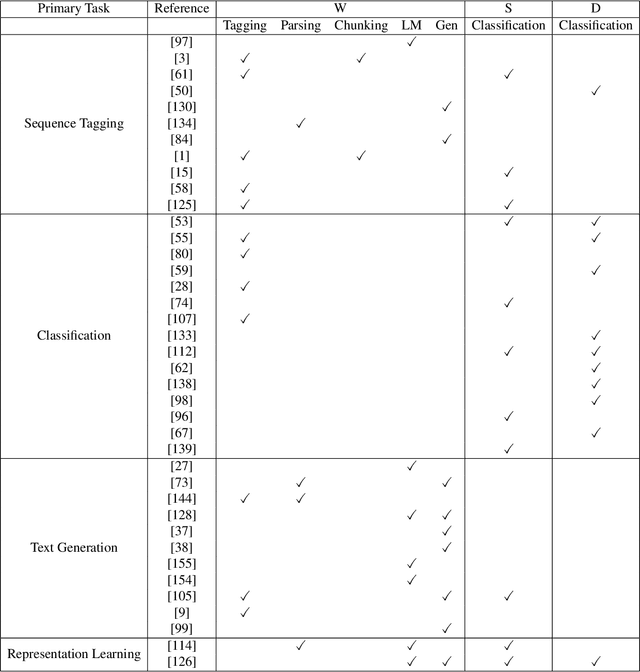
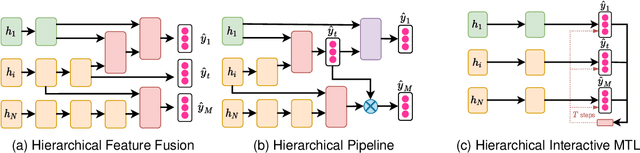
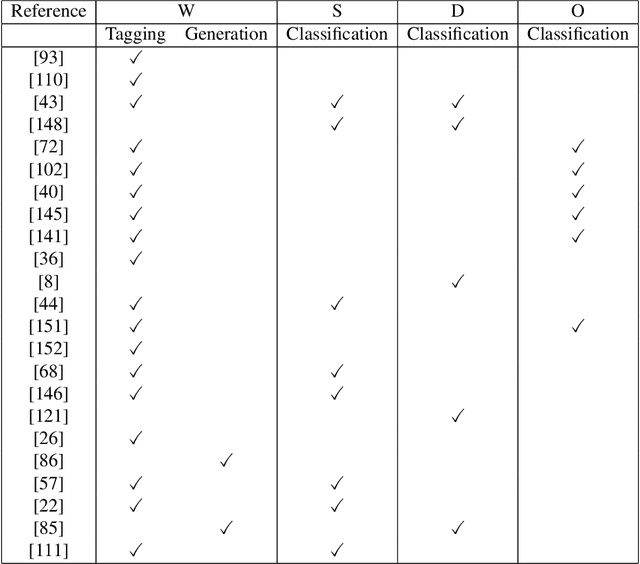
Deep learning approaches have achieved great success in the field of Natural Language Processing (NLP). However, deep neural models often suffer from overfitting and data scarcity problems that are pervasive in NLP tasks. In recent years, Multi-Task Learning (MTL), which can leverage useful information of related tasks to achieve simultaneous performance improvement on multiple related tasks, has been used to handle these problems. In this paper, we give an overview of the use of MTL in NLP tasks. We first review MTL architectures used in NLP tasks and categorize them into four classes, including the parallel architecture, hierarchical architecture, modular architecture, and generative adversarial architecture. Then we present optimization techniques on loss construction, data sampling, and task scheduling to properly train a multi-task model. After presenting applications of MTL in a variety of NLP tasks, we introduce some benchmark datasets. Finally, we make a conclusion and discuss several possible research directions in this field.
MARTINI: Smart Meter Driven Estimation of HVAC Schedules and Energy Savings Based on WiFi Sensing and Clustering
Oct 17, 2021

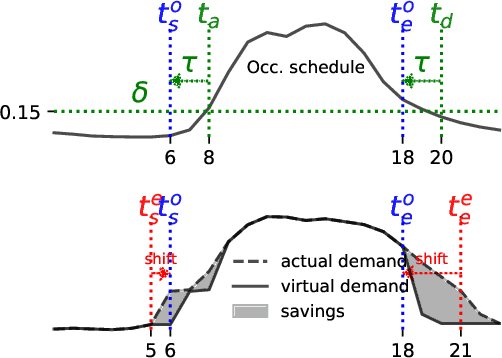
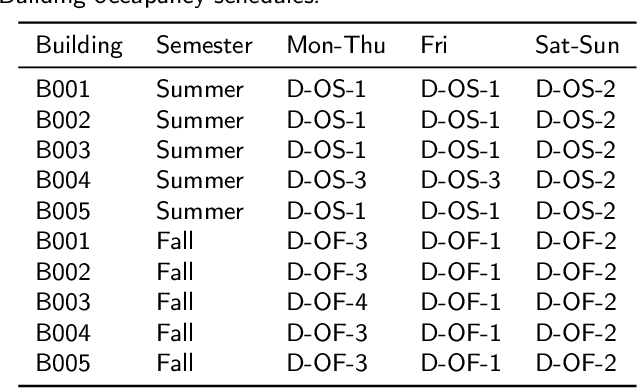
HVAC systems account for a significant portion of building energy use. Nighttime setback scheduling is an energy conservation measure where cooling and heating setpoints are increased and decreased respectively during unoccupied periods with the goal of obtaining energy savings. However, knowledge of a building's real occupancy is required to maximize the success of this measure. In addition, there is the need for a scalable way to estimate energy savings potential from energy conservation measures that is not limited by building specific parameters and experimental or simulation modeling investments. Here, we propose MARTINI, a sMARt meTer drIveN estImation of occupant-derived HVAC schedules and energy savings that leverages the ubiquity of energy smart meters and WiFi infrastructure in commercial buildings. We estimate the schedules by clustering WiFi-derived occupancy profiles and, energy savings by shifting ramp-up and setback times observed in typical/measured load profiles obtained by clustering smart meter energy profiles. Our case-study results with five buildings over seven months show an average of 8.1%-10.8% (summer) and 0.2%-5.9% (fall) chilled water energy savings when HVAC system operation is aligned with occupancy. We validate our method with results from building energy performance simulation (BEPS) and find that estimated average savings of MARTINI are within 0.9%-2.4% of the BEPS predictions. In the absence of occupancy information, we can still estimate potential savings from increasing ramp-up time and decreasing setback start time. In 51 academic buildings, we find savings potentials between 1%-5%.
Adversarial Attack across Datasets
Oct 13, 2021
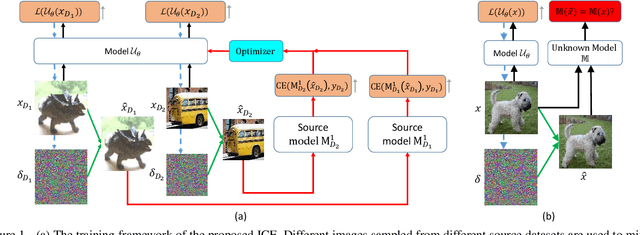
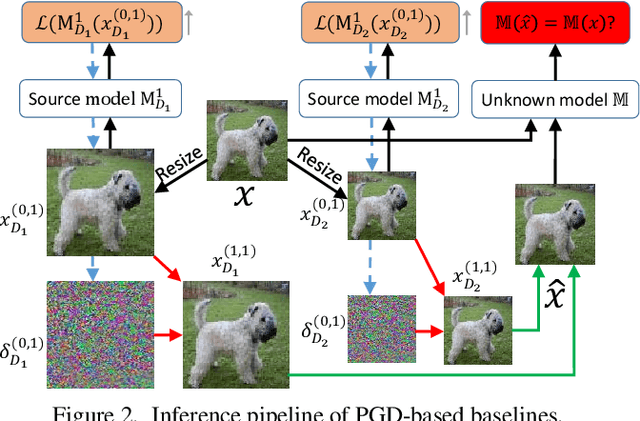
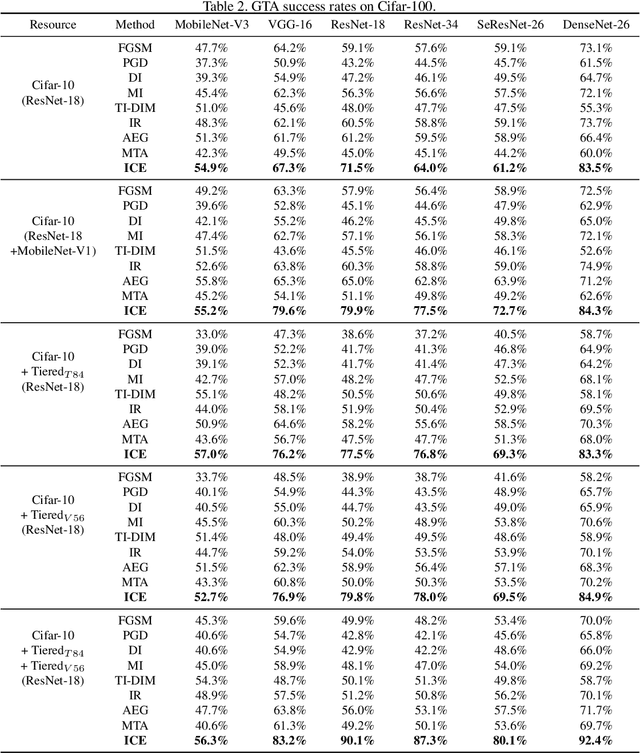
It has been observed that Deep Neural Networks (DNNs) are vulnerable to transfer attacks in the query-free black-box setting. However, all the previous studies on transfer attack assume that the white-box surrogate models possessed by the attacker and the black-box victim models are trained on the same dataset, which means the attacker implicitly knows the label set and the input size of the victim model. However, this assumption is usually unrealistic as the attacker may not know the dataset used by the victim model, and further, the attacker needs to attack any randomly encountered images that may not come from the same dataset. Therefore, in this paper we define a new Generalized Transferable Attack (GTA) problem where we assume the attacker has a set of surrogate models trained on different datasets (with different label sets and image sizes), and none of them is equal to the dataset used by the victim model. We then propose a novel method called Image Classification Eraser (ICE) to erase classification information for any encountered images from arbitrary dataset. Extensive experiments on Cifar-10, Cifar-100, and TieredImageNet demonstrate the effectiveness of the proposed ICE on the GTA problem. Furthermore, we show that existing transfer attack methods can be modified to tackle the GTA problem, but with significantly worse performance compared with ICE.
WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution
Jun 16, 2021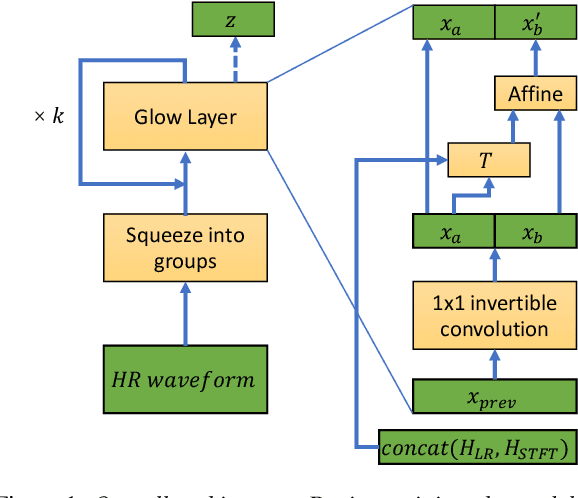

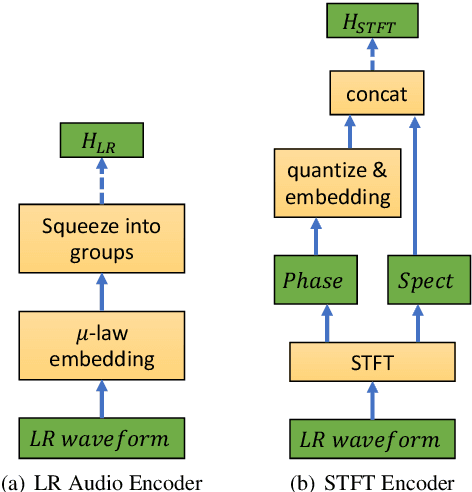
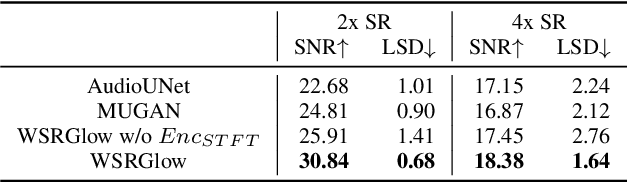
Audio super-resolution is the task of constructing a high-resolution (HR) audio from a low-resolution (LR) audio by adding the missing band. Previous methods based on convolutional neural networks and mean squared error training objective have relatively low performance, while adversarial generative models are difficult to train and tune. Recently, normalizing flow has attracted a lot of attention for its high performance, simple training and fast inference. In this paper, we propose WSRGlow, a Glow-based waveform generative model to perform audio super-resolution. Specifically, 1) we integrate WaveNet and Glow to directly maximize the exact likelihood of the target HR audio conditioned on LR information; and 2) to exploit the audio information from low-resolution audio, we propose an LR audio encoder and an STFT encoder, which encode the LR information from the time domain and frequency domain respectively. The experimental results show that the proposed model is easier to train and outperforms the previous works in terms of both objective and perceptual quality. WSRGlow is also the first model to produce 48kHz waveforms from 12kHz LR audio.
NeuType: A Simple and Effective Neural Network Approach for Predicting Missing Entity Type Information in Knowledge Bases
Jul 05, 2019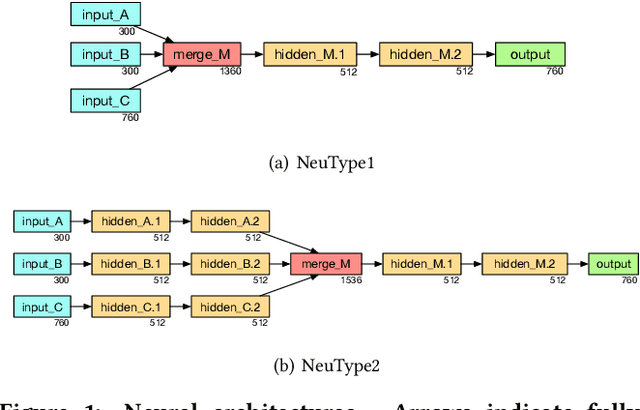
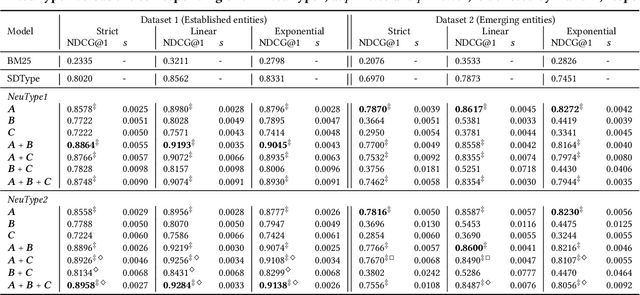
Knowledge bases store information about the semantic types of entities, which can be utilized in a range of information access tasks. This information, however, is often incomplete, due to new entities emerging on a daily basis. We address the task of automatically assigning types to entities in a knowledge base from a type taxonomy. Specifically, we present two neural network architectures, which take short entity descriptions and, optionally, information about related entities as input. Using the DBpedia knowledge base for experimental evaluation, we demonstrate that these simple architectures yield significant improvements over the current state of the art.
Efficient Force Estimation for Continuum Robot
Sep 26, 2021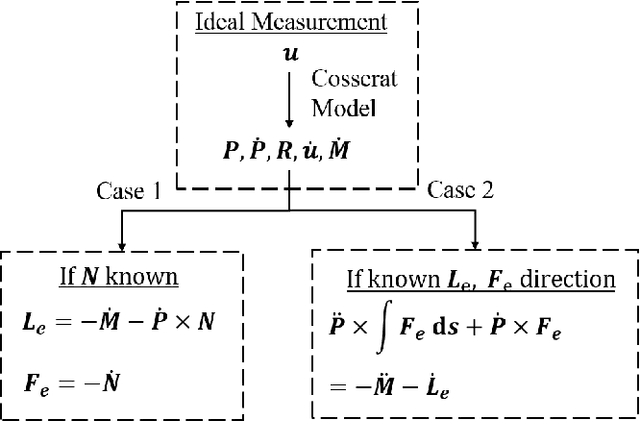
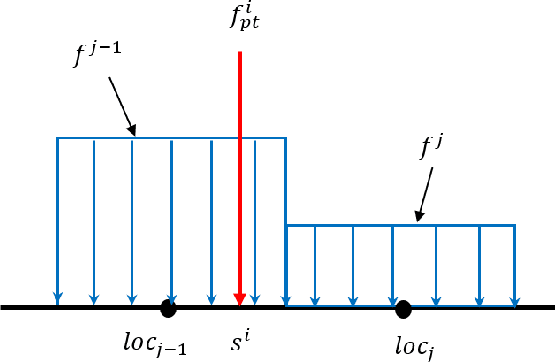
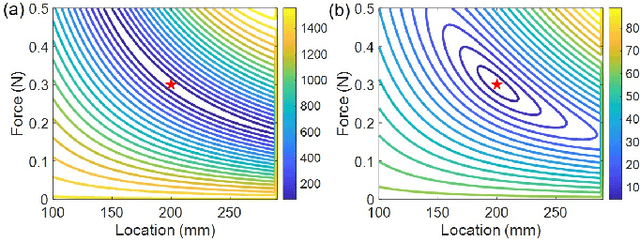
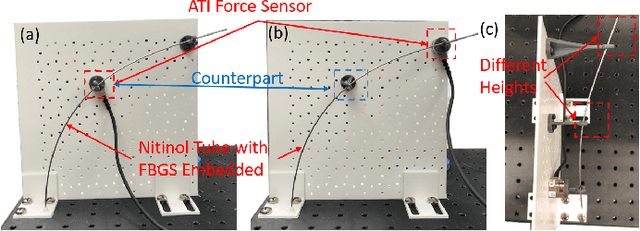
External contact force is one of the most significant information for the robots to model, control, and safely interact with external objects. For continuum robots, it is possible to estimate the contact force based on the measurements of robot configurations, which addresses the difficulty of implementing the force sensor feedback on the robot body with strict dimension constraints. In this paper, we use local curvatures measured from fiber Bragg grating sensors (FBGS) to estimate the magnitude and location of single or multiple external contact forces. A simplified mechanics model is derived from Cosserat rod theory to compute continuum robot curvatures. Least-square optimization is utilized to estimate the forces by minimizing errors between computed curvatures and measured curvatures. The results show that the proposed method is able to accurately estimate the contact force magnitude (error: 5.25\% -- 12.87\%) and locations (error: 1.02\% -- 2.19\%). The calculation speed of the proposed method is validated in MATLAB. The results indicate that our approach is 29.0 -- 101.6 times faster than the conventional methods. These results indicate that the proposed method is accurate and efficient for contact force estimations.
Dense Gaussian Processes for Few-Shot Segmentation
Oct 07, 2021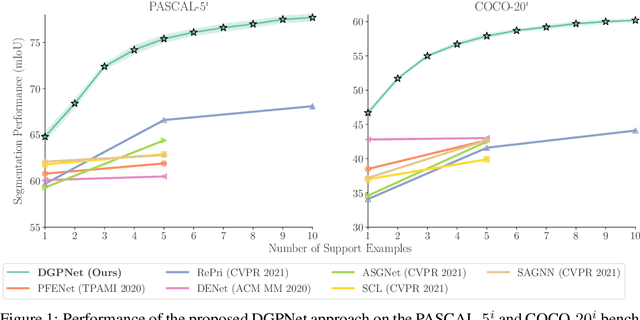
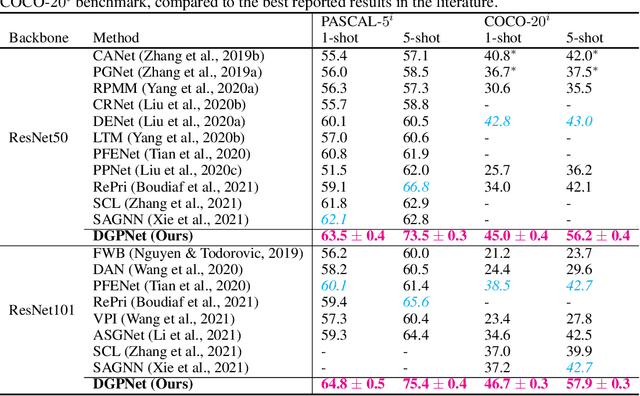
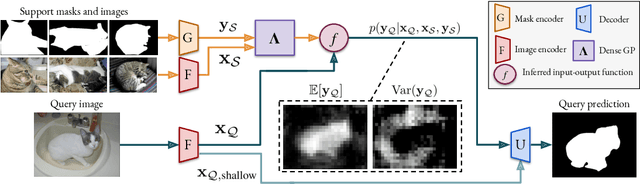

Few-shot segmentation is a challenging dense prediction task, which entails segmenting a novel query image given only a small annotated support set. The key problem is thus to design a method that aggregates detailed information from the support set, while being robust to large variations in appearance and context. To this end, we propose a few-shot segmentation method based on dense Gaussian process (GP) regression. Given the support set, our dense GP learns the mapping from local deep image features to mask values, capable of capturing complex appearance distributions. Furthermore, it provides a principled means of capturing uncertainty, which serves as another powerful cue for the final segmentation, obtained by a CNN decoder. Instead of a one-dimensional mask output, we further exploit the end-to-end learning capabilities of our approach to learn a high-dimensional output space for the GP. Our approach sets a new state-of-the-art for both 1-shot and 5-shot FSS on the PASCAL-5$^i$ and COCO-20$^i$ benchmarks, achieving an absolute gain of $+14.9$ mIoU in the COCO-20$^i$ 5-shot setting. Furthermore, the segmentation quality of our approach scales gracefully when increasing the support set size, while achieving robust cross-dataset transfer.
Robust Opponent Modeling via Adversarial Ensemble Reinforcement Learning in Asymmetric Imperfect-Information Games
Oct 28, 2019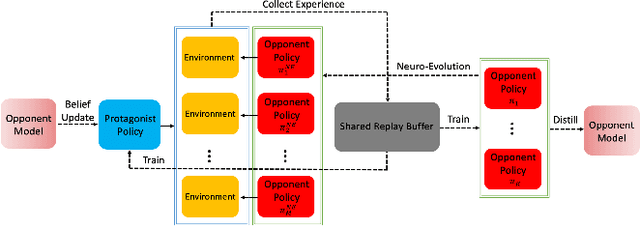
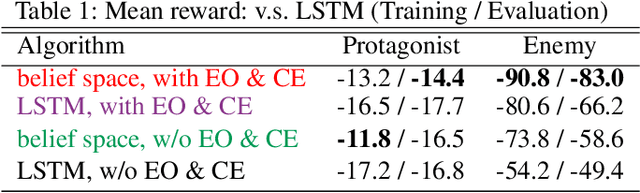

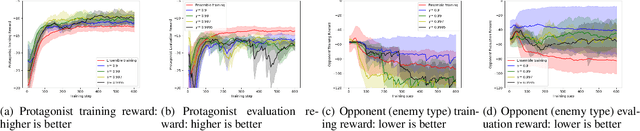
This paper presents an algorithmic framework for learning robust policies in asymmetric imperfect-information games, where the joint reward could depend on the uncertain opponent type (a private information known only to the opponent itself and its ally). In order to maximize the reward, the protagonist agent has to infer the opponent type through agent modeling. We use multiagent reinforcement learning (MARL) to learn opponent models through self-play, which captures the full strategy interaction and reasoning between agents. However, agent policies learned from self-play can suffer from mutual overfitting. Ensemble training methods can be used to improve the robustness of agent policy against different opponents, but it also significantly increases the computational overhead. In order to achieve a good trade-off between the robustness of the learned policy and the computation complexity, we propose to train a separate opponent policy against the protagonist agent for evaluation purposes. The reward achieved by this opponent is a noisy measure of the robustness of the protagonist agent policy due to the intrinsic stochastic nature of a reinforcement learner. To handle this stochasticity, we apply a stochastic optimization scheme to dynamically update the opponent ensemble to optimize an objective function that strikes a balance between robustness and computation complexity. We empirically show that, under the same limited computational budget, the proposed method results in more robust policy learning than standard ensemble training.
DQN-based Beamforming for Uplink mmWave Cellular-Connected UAVs
Oct 12, 2021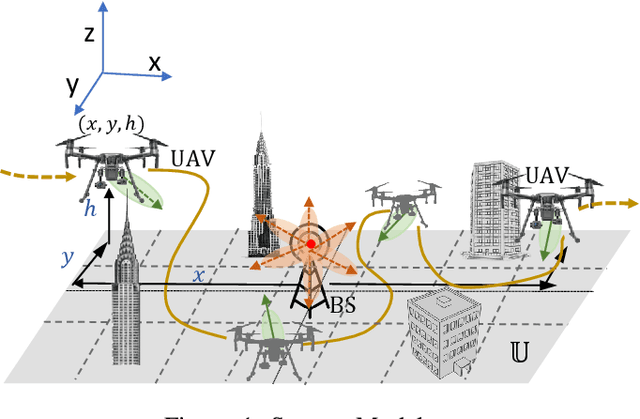
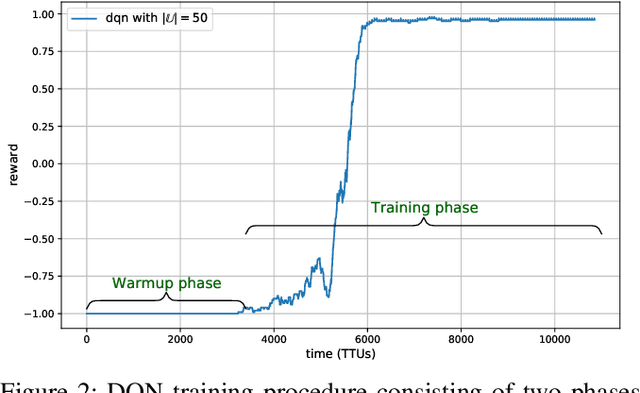
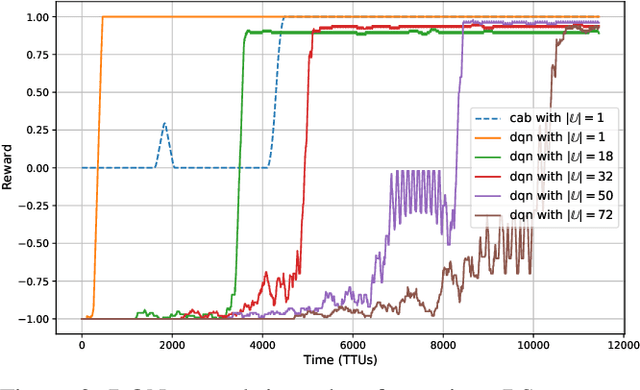
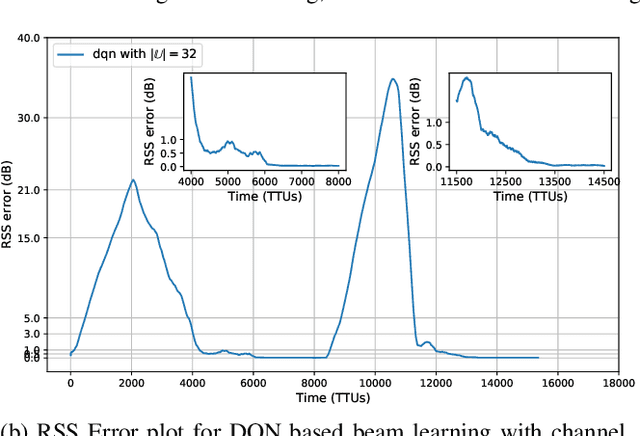
Unmanned aerial vehicles (UAVs) are the emerging vital components of millimeter wave (mmWave) wireless systems. Accurate beam alignment is essential for efficient beam-based mmWave communications of UAVs with base stations (BSs). Conventional beam sweeping approaches often have large overhead due to the high mobility and autonomous operation of UAVs. Learning-based approaches greatly reduce the overhead by leveraging UAV data, like position to identify optimal beam directions. In this paper, we propose a reinforcement learning (RL)-based framework for UAV-BS beam alignment using deep Q-Network (DQN) in a mmWave setting. We consider uplink communications where the UAV hovers around 5G new radio (NR) BS coverage area, with varying channel conditions. The proposed learning framework uses the location information to maximize data rate through the optimal beam-pairs efficiently, upon every communication request from UAV inside the multi-location environment. We compare our proposed framework against the Multi-Armed Bandit (MAB) learning-based approach and the traditional exhaustive approach, respectively, and also analyse the training performance of DQN-based beam alignment over different coverage area requirements and channel conditions. Our results show that the proposed DQN-based beam alignment converges faster and generic for different environmental conditions. The framework can also learn optimal beam alignment comparable to the exhaustive approach in an online manner under real-time conditions.