 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-based Instance Representation Learning
Oct 10, 2021
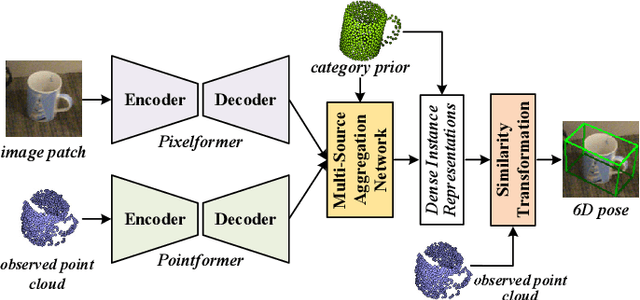


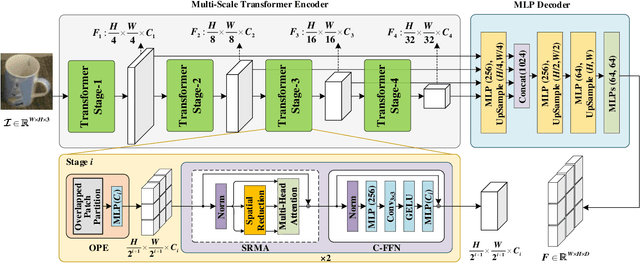
This paper presents 6D-ViT, a transformer-based instance representation learning network, which is suitable for highly accurate category-level object pose estimation on RGB-D images. Specifically, a novel two-stream encoder-decoder framework is dedicated to exploring complex and powerful instance representations from RGB images, point clouds and categorical shape priors. For this purpose, the whole framework consists of two main branches, named Pixelformer and Pointformer. The Pixelformer contains a pyramid transformer encoder with an all-MLP decoder to extract pixelwise appearance representations from RGB images, while the Pointformer relies on a cascaded transformer encoder and an all-MLP decoder to acquire the pointwise geometric characteristics from point clouds. Then, dense instance representations (i.e., correspondence matrix, deformation field) are obtained from a multi-source aggregation network with shape priors, appearance and geometric information as input. Finally, the instance 6D pose is computed by leveraging the correspondence among dense representations, shape priors, and the instance point clouds. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed 3D instance representation learning framework achieves state-of-the-art performance on both datasets, and significantly outperforms all existing methods.
Adversarial Attacks on Gaussian Process Bandits
Oct 16, 2021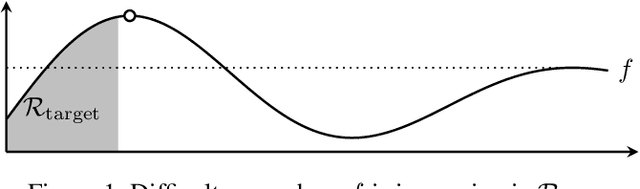
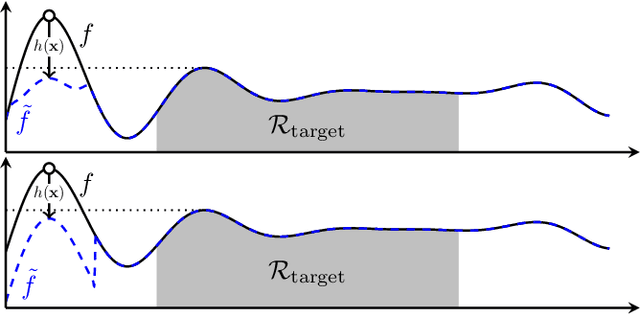
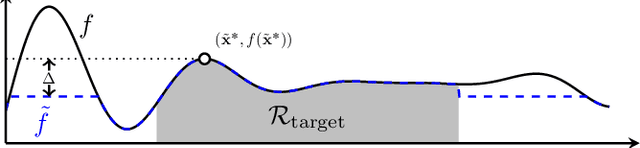
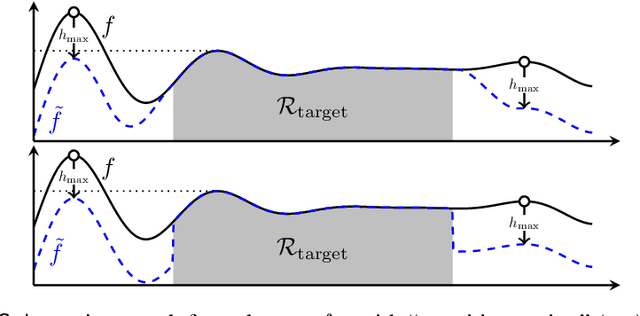
Gaussian processes (GP) are a widely-adopted tool used to sequentially optimize black-box functions, where evaluations are costly and potentially noisy. Recent works on GP bandits have proposed to move beyond random noise and devise algorithms robust to adversarial attacks. In this paper, we study this problem from the attacker's perspective, proposing various adversarial attack methods with differing assumptions on the attacker's strength and prior information. Our goal is to understand adversarial attacks on GP bandits from both a theoretical and practical perspective. We focus primarily on targeted attacks on the popular GP-UCB algorithm and a related elimination-based algorithm, based on adversarially perturbing the function $f$ to produce another function $\tilde{f}$ whose optima are in some region $\mathcal{R}_{\rm target}$. Based on our theoretical analysis, we devise both white-box attacks (known $f$) and black-box attacks (unknown $f$), with the former including a Subtraction attack and Clipping attack, and the latter including an Aggressive subtraction attack. We demonstrate that adversarial attacks on GP bandits can succeed in forcing the algorithm towards $\mathcal{R}_{\rm target}$ even with a low attack budget, and we compare our attacks' performance and efficiency on several real and synthetic functions.
Self-Annotated Training for Controllable Image Captioning
Oct 16, 2021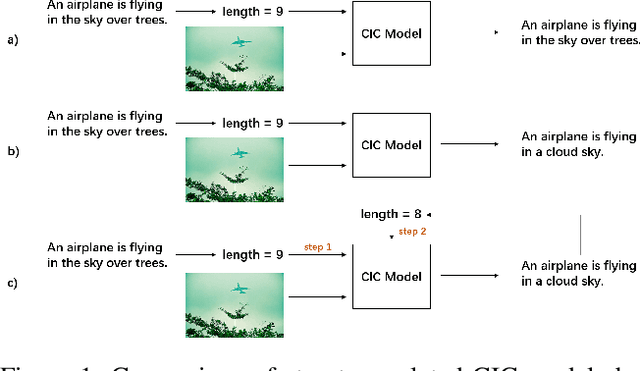
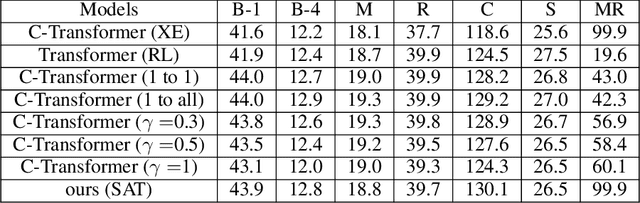
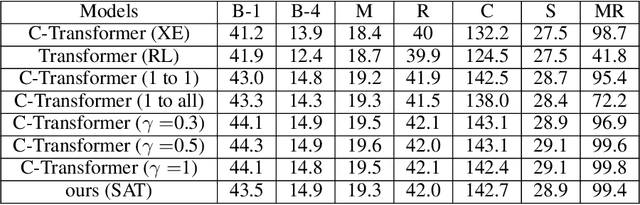
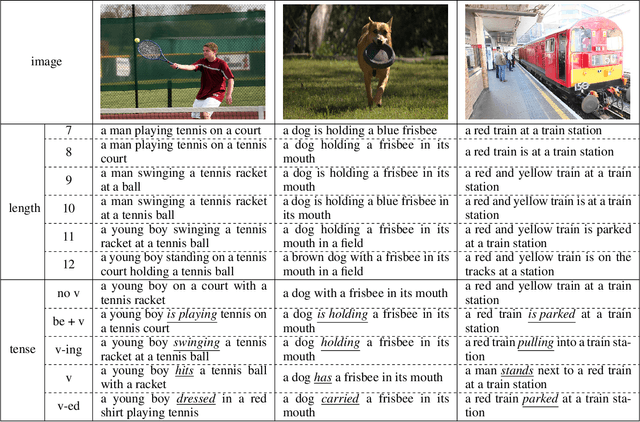
The Controllable Image Captioning (CIC) task aims to generate captions conditioned on designated control signals. In this paper, we improve CIC from two aspects: 1) Existing reinforcement training methods are not applicable to structure-related CIC models due to the fact that the accuracy-based reward focuses mainly on contents rather than semantic structures. The lack of reinforcement training prevents the model from generating more accurate and controllable sentences. To solve the problem above, we propose a novel reinforcement training method for structure-related CIC models: Self-Annotated Training (SAT), where a recursive sampling mechanism (RSM) is designed to force the input control signal to match the actual output sentence. Extensive experiments conducted on MSCOCO show that our SAT method improves C-Transformer (XE) on CIDEr-D score from 118.6 to 130.1 in the length-control task and from 132.2 to 142.7 in the tense-control task, while maintaining more than 99$\%$ matching accuracy with the control signal. 2) We introduce a new control signal: sentence quality. Equipped with it, CIC models are able to generate captions of different quality levels as needed. Experiments show that without additional information of ground truth captions, models controlled by the highest level of sentence quality perform much better in accuracy than baseline models.
AngularGrad: A New Optimization Technique for Angular Convergence of Convolutional Neural Networks
May 21, 2021Convolutional neural networks (CNNs) are trained using stochastic gradient descent (SGD)-based optimizers. Recently, the adaptive moment estimation (Adam) optimizer has become very popular due to its adaptive momentum, which tackles the dying gradient problem of SGD. Nevertheless, existing optimizers are still unable to exploit the optimization curvature information efficiently. This paper proposes a new AngularGrad optimizer that considers the behavior of the direction/angle of consecutive gradients. This is the first attempt in the literature to exploit the gradient angular information apart from its magnitude. The proposed AngularGrad generates a score to control the step size based on the gradient angular information of previous iterations. Thus, the optimization steps become smoother as a more accurate step size of immediate past gradients is captured through the angular information. Two variants of AngularGrad are developed based on the use of Tangent or Cosine functions for computing the gradient angular information. Theoretically, AngularGrad exhibits the same regret bound as Adam for convergence purposes. Nevertheless, extensive experiments conducted on benchmark data sets against state-of-the-art methods reveal a superior performance of AngularGrad. The source code will be made publicly available at: https://github.com/mhaut/AngularGrad.
Context-Aware Unsupervised Clustering for Person Search
Oct 04, 2021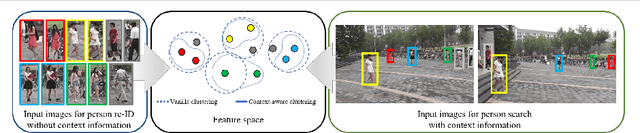
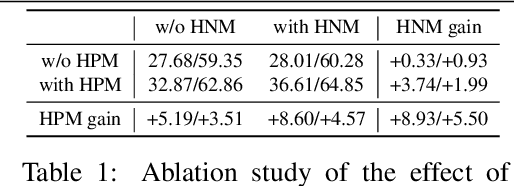
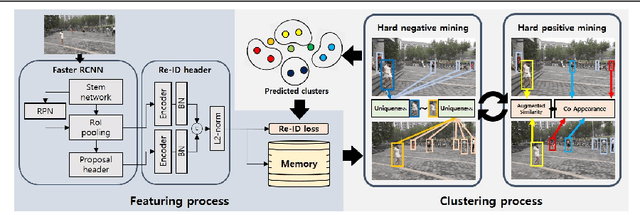
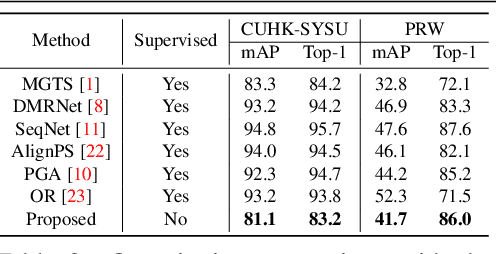
The existing person search methods use the annotated labels of person identities to train deep networks in a supervised manner that requires a huge amount of time and effort for human labeling. In this paper, we first introduce a novel framework of person search that is able to train the network in the absence of the person identity labels, and propose efficient unsupervised clustering methods to substitute the supervision process using annotated person identity labels. Specifically, we propose a hard negative mining scheme based on the uniqueness property that only a single person has the same identity to a given query person in each image. We also propose a hard positive mining scheme by using the contextual information of co-appearance that neighboring persons in one image tend to appear simultaneously in other images. The experimental results show that the proposed method achieves comparable performance to that of the state-of-the-art supervised person search methods, and furthermore outperforms the extended unsupervised person re-identification methods on the benchmark person search datasets.
Audio-to-Image Cross-Modal Generation
Sep 27, 2021

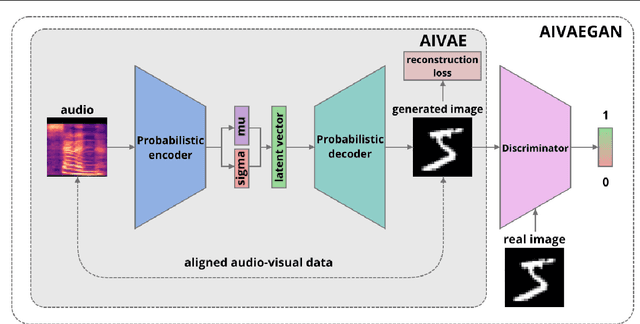

Cross-modal representation learning allows to integrate information from different modalities into one representation. At the same time, research on generative models tends to focus on the visual domain with less emphasis on other domains, such as audio or text, potentially missing the benefits of shared representations. Studies successfully linking more than one modality in the generative setting are rare. In this context, we verify the possibility to train variational autoencoders (VAEs) to reconstruct image archetypes from audio data. Specifically, we consider VAEs in an adversarial training framework in order to ensure more variability in the generated data and find that there is a trade-off between the consistency and diversity of the generated images - this trade-off can be governed by scaling the reconstruction loss up or down, respectively. Our results further suggest that even in the case when the generated images are relatively inconsistent (diverse), features that are critical for proper image classification are preserved.
Quantifying point cloud realism through adversarially learned latent representations
Sep 24, 2021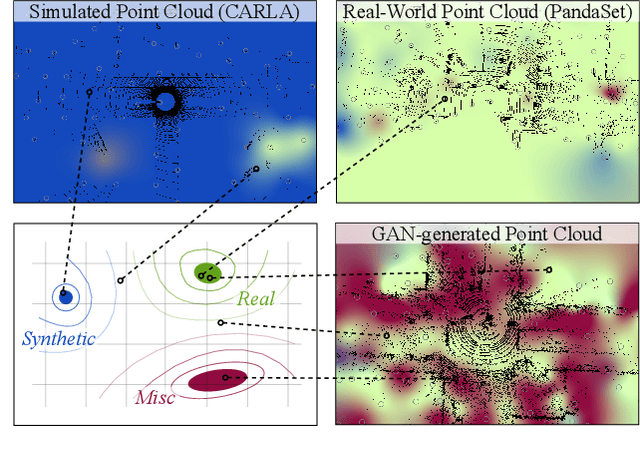
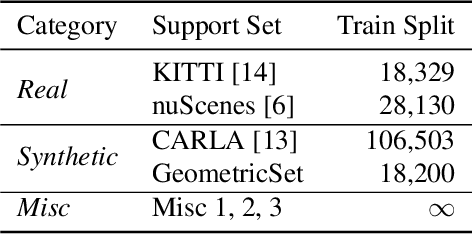
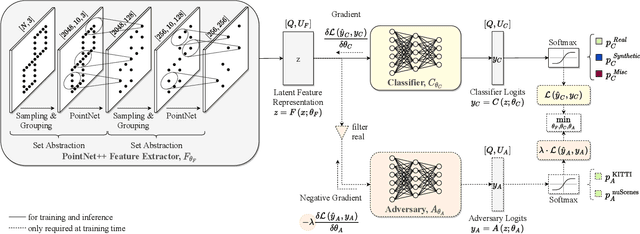
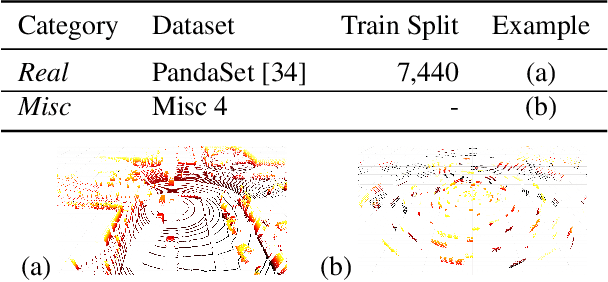
Judging the quality of samples synthesized by generative models can be tedious and time consuming, especially for complex data structures, such as point clouds. This paper presents a novel approach to quantify the realism of local regions in LiDAR point clouds. Relevant features are learned from real-world and synthetic point clouds by training on a proxy classification task. Inspired by fair networks, we use an adversarial technique to discourage the encoding of dataset-specific information. The resulting metric can assign a quality score to samples without requiring any task specific annotations. In a series of experiments, we confirm the soundness of our metric by applying it in controllable task setups and on unseen data. Additional experiments show reliable interpolation capabilities of the metric between data with varying degree of realism. As one important application, we demonstrate how the local realism score can be used for anomaly detection in point clouds.
Social Analysis of Young Basque Speaking Communities in Twitter
Sep 08, 2021
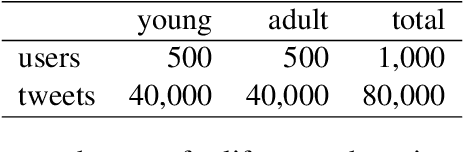

In this paper we take into account both social and linguistic aspects to perform demographic analysis by processing a large amount of tweets in Basque language. The study of demographic characteristics and social relationships are approached by applying machine learning and modern deep-learning Natural Language Processing (NLP) techniques, combining social sciences with automatic text processing. More specifically, our main objective is to combine demographic inference and social analysis in order to detect young Basque Twitter users and to identify the communities that arise from their relationships or shared content. This social and demographic analysis will be entirely based on the~automatically collected tweets using NLP to convert unstructured textual information into interpretable knowledge.
Identifying causal associations in tweets using deep learning: Use case on diabetes-related tweets from 2017-2021
Nov 03, 2021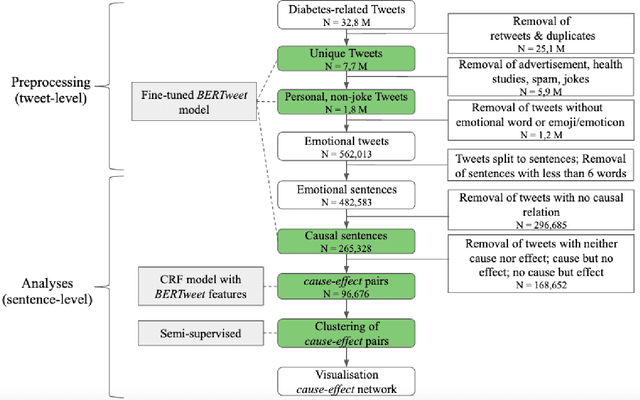
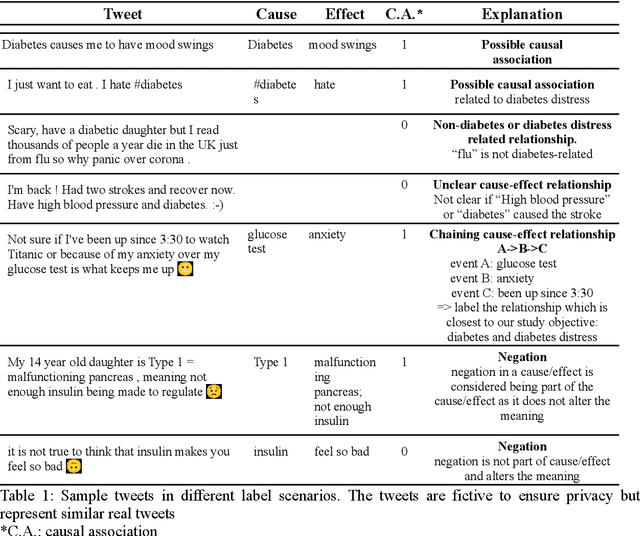
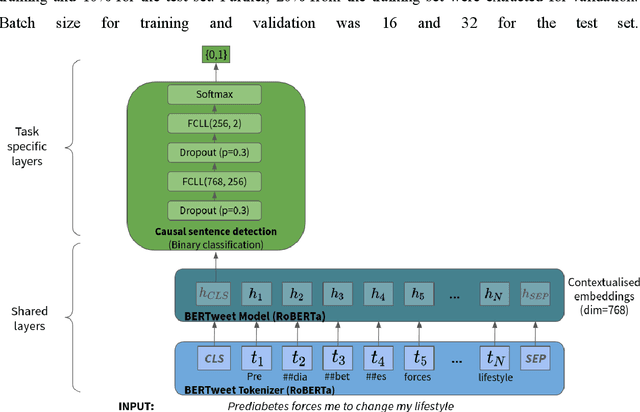
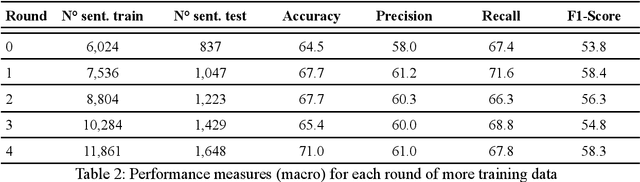
Objective: Leveraging machine learning methods, we aim to extract both explicit and implicit cause-effect associations in patient-reported, diabetes-related tweets and provide a tool to better understand opinion, feelings and observations shared within the diabetes online community from a causality perspective. Materials and Methods: More than 30 million diabetes-related tweets in English were collected between April 2017 and January 2021. Deep learning and natural language processing methods were applied to focus on tweets with personal and emotional content. A cause-effect-tweet dataset was manually labeled and used to train 1) a fine-tuned Bertweet model to detect causal sentences containing a causal association 2) a CRF model with BERT based features to extract possible cause-effect associations. Causes and effects were clustered in a semi-supervised approach and visualised in an interactive cause-effect-network. Results: Causal sentences were detected with a recall of 68% in an imbalanced dataset. A CRF model with BERT based features outperformed a fine-tuned BERT model for cause-effect detection with a macro recall of 68%. This led to 96,676 sentences with cause-effect associations. "Diabetes" was identified as the central cluster followed by "Death" and "Insulin". Insulin pricing related causes were frequently associated with "Death". Conclusions: A novel methodology was developed to detect causal sentences and identify both explicit and implicit, single and multi-word cause and corresponding effect as expressed in diabetes-related tweets leveraging BERT-based architectures and visualised as cause-effect-network. Extracting causal associations on real-life, patient reported outcomes in social media data provides a useful complementary source of information in diabetes research.
Automated Recovery of Issue-Commit Links Leveraging Both Textual and Non-textual Data
Jul 05, 2021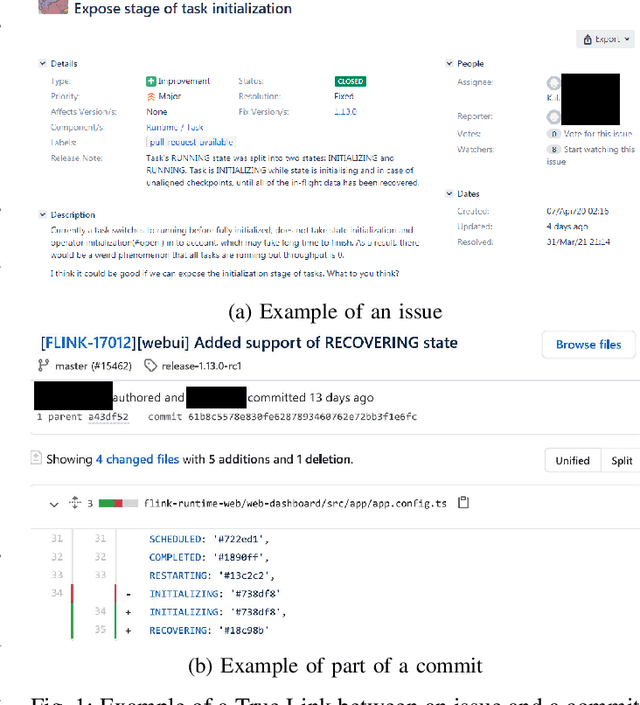
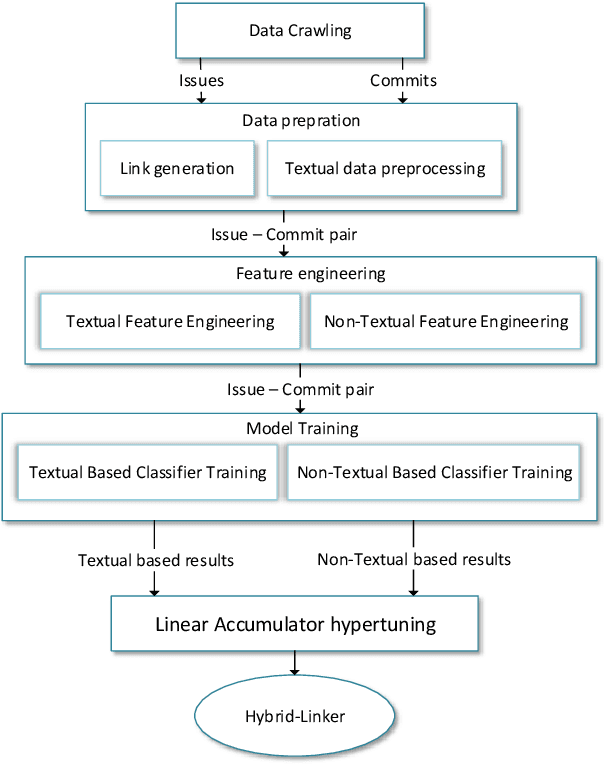
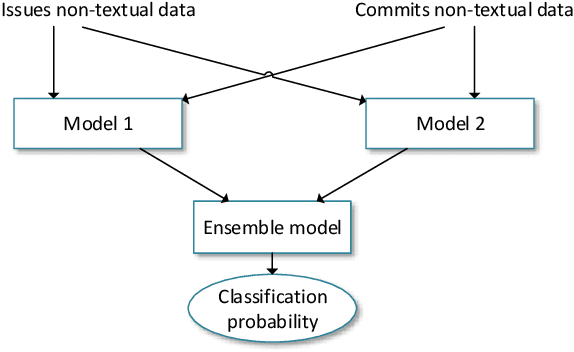
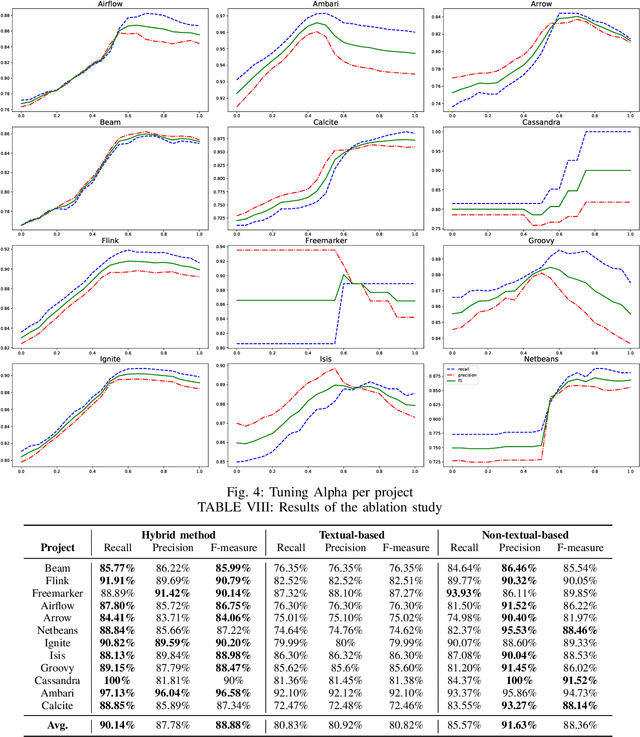
An issue documents discussions around required changes in issue-tracking systems, while a commit contains the change itself in the version control systems. Recovering links between issues and commits can facilitate many software evolution tasks such as bug localization, and software documentation. A previous study on over half a million issues from GitHub reports only about 42.2% of issues are manually linked by developers to their pertinent commits. Automating the linking of commit-issue pairs can contribute to the improvement of the said tasks. By far, current state-of-the-art approaches for automated commit-issue linking suffer from low precision, leading to unreliable results, sometimes to the point that imposes human supervision on the predicted links. The low performance gets even more severe when there is a lack of textual information in either commits or issues. Current approaches are also proven computationally expensive. We propose Hybrid-Linker to overcome such limitations by exploiting two information channels; (1) a non-textual-based component that operates on non-textual, automatically recorded information of the commit-issue pairs to predict a link, and (2) a textual-based one which does the same using textual information of the commit-issue pairs. Then, combining the results from the two classifiers, Hybrid-Linker makes the final prediction. Thus, every time one component falls short in predicting a link, the other component fills the gap and improves the results. We evaluate Hybrid-Linker against competing approaches, namely FRLink and DeepLink on a dataset of 12 projects. Hybrid-Linker achieves 90.1%, 87.8%, and 88.9% based on recall, precision, and F-measure, respectively. It also outperforms FRLink and DeepLink by 31.3%, and 41.3%, regarding the F-measure. Moreover, Hybrid-Linker exhibits extensive improvements in terms of performance as well.