 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving GNSS Positioning using Neural Network-based Corrections
Oct 18, 2021
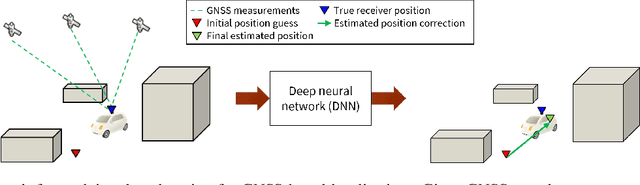



Deep Neural Networks (DNNs) are a promising tool for Global Navigation Satellite System (GNSS) positioning in the presence of multipath and non-line-of-sight errors, owing to their ability to model complex errors using data. However, developing a DNN for GNSS positioning presents various challenges, such as 1) poor numerical conditioning caused by large variations in measurements and position values across the globe, 2) varying number and order within the set of measurements due to changing satellite visibility, and 3) overfitting to available data. In this work, we address the aforementioned challenges and propose an approach for GNSS positioning by applying DNN-based corrections to an initial position guess. Our DNN learns to output the position correction using the set of pseudorange residuals and satellite line-of-sight vectors as inputs. The limited variation in these input and output values improves the numerical conditioning for our DNN. We design our DNN architecture to combine information from the available GNSS measurements, which vary both in number and order, by leveraging recent advancements in set-based deep learning methods. Furthermore, we present a data augmentation strategy for reducing overfitting in the DNN by randomizing the initial position guesses. We first perform simulations and show an improvement in the initial positioning error when our DNN-based corrections are applied. After this, we demonstrate that our approach outperforms a WLS baseline on real-world data. Our implementation is available at github.com/Stanford-NavLab/deep_gnss.
Local and Global Context-Based Pairwise Models for Sentence Ordering
Oct 08, 2021
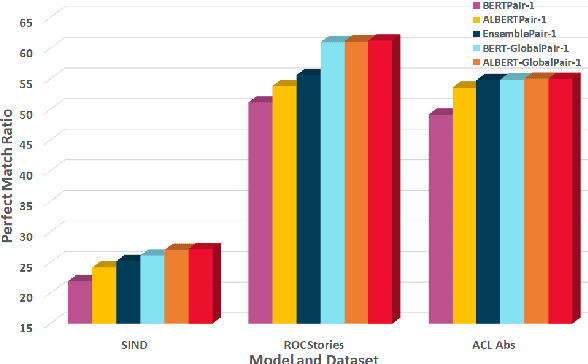
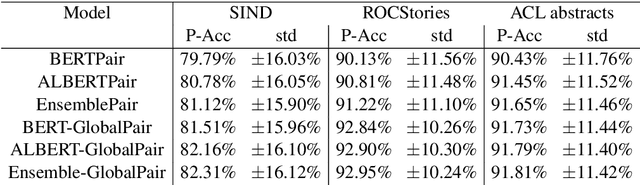
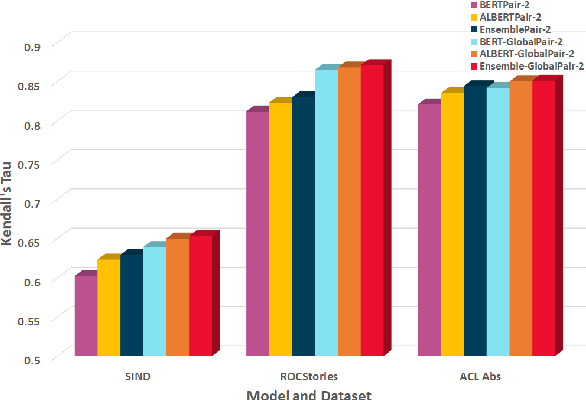
Sentence Ordering refers to the task of rearranging a set of sentences into the appropriate coherent order. For this task, most previous approaches have explored global context-based end-to-end methods using Sequence Generation techniques. In this paper, we put forward a set of robust local and global context-based pairwise ordering strategies, leveraging which our prediction strategies outperform all previous works in this domain. Our proposed encoding method utilizes the paragraph's rich global contextual information to predict the pairwise order using novel transformer architectures. Analysis of the two proposed decoding strategies helps better explain error propagation in pairwise models. This approach is the most accurate pure pairwise model and our encoding strategy also significantly improves the performance of other recent approaches that use pairwise models, including the previous state-of-the-art, demonstrating the research novelty and generalizability of this work. Additionally, we show how the pre-training task for ALBERT helps it to significantly outperform BERT, despite having considerably lesser parameters. The extensive experimental results, architectural analysis and ablation studies demonstrate the effectiveness and superiority of the proposed models compared to the previous state-of-the-art, besides providing a much better understanding of the functioning of pairwise models.
A frame semantic overview of NLP-based information extraction for cancer-related EHR notes
Apr 02, 2019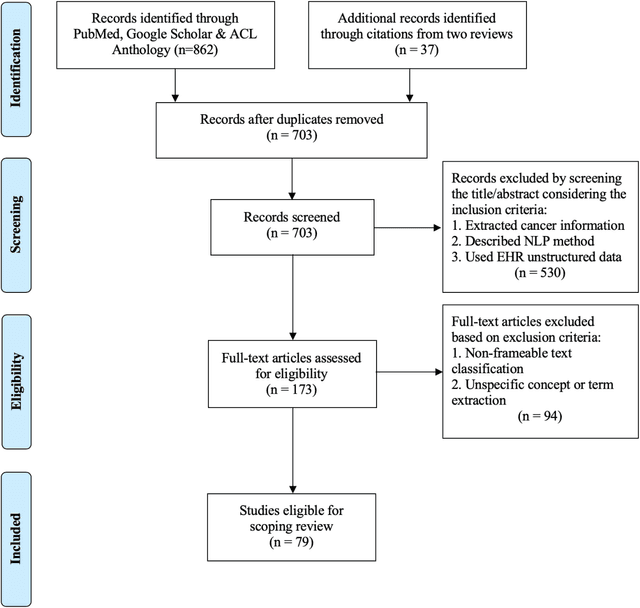
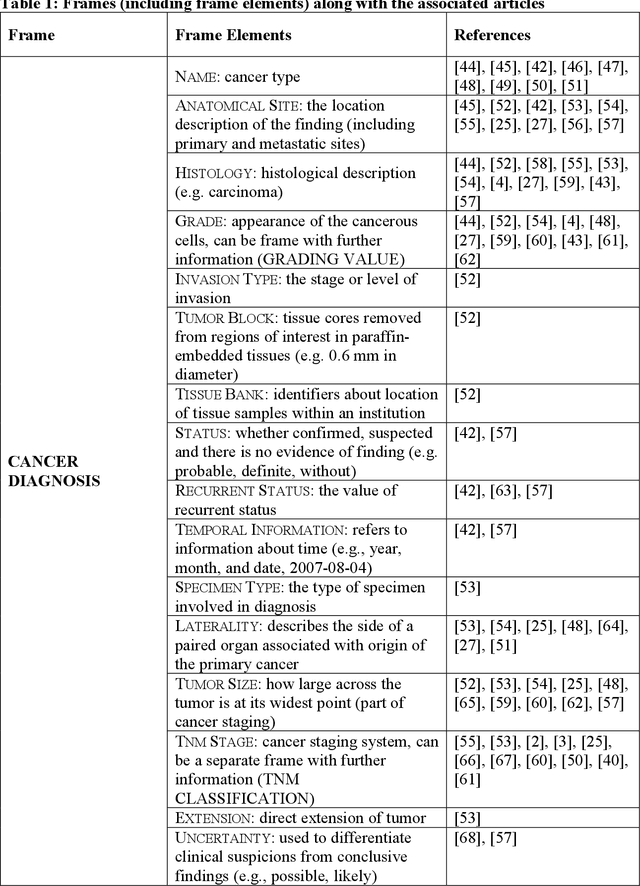
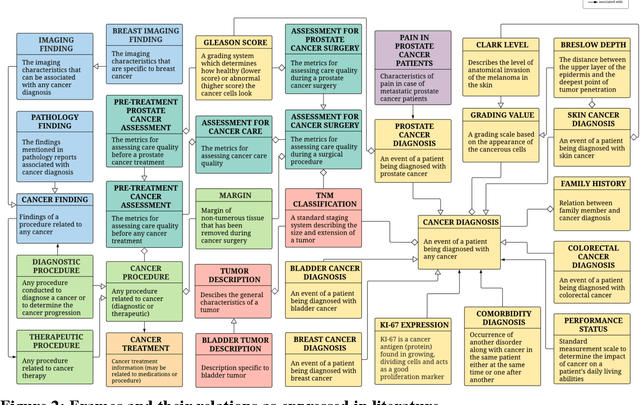
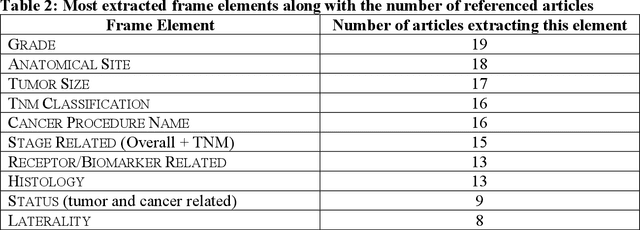
Objective: There is a lot of information about cancer in Electronic Health Record (EHR) notes that can be useful for biomedical research provided natural language processing (NLP) methods are available to extract and structure this information. In this paper, we present a scoping review of existing clinical NLP literature for cancer. Methods: We identified studies describing an NLP method to extract specific cancer-related information from EHR sources from PubMed, Google Scholar, ACL Anthology, and existing reviews. Two exclusion criteria were used in this study. We excluded articles where the extraction techniques used were too broad to be represented as frames and also where very low-level extraction methods were used. 79 articles were included in the final review. We organized this information according to frame semantic principles to help identify common areas of overlap and potential gaps. Results: Frames were created from the reviewed articles pertaining to cancer information such as cancer diagnosis, tumor description, cancer procedure, breast cancer diagnosis, prostate cancer diagnosis and pain in prostate cancer patients. These frames included both a definition as well as specific frame elements (i.e. extractable attributes). We found that cancer diagnosis was the most common frame among the reviewed papers (36 out of 79), with recent work focusing on extracting information related to treatment and breast cancer diagnosis. Conclusion: The list of common frames described in this paper identifies important cancer-related information extracted by existing NLP techniques and serves as a useful resource for future researchers requiring cancer information extracted from EHR notes. We also argue, due to the heavy duplication of cancer NLP systems, that a general purpose resource of annotated cancer frames and corresponding NLP tools would be valuable.
Hyperspectral Remote Sensing Image Classification Based on Multi-scale Cross Graphic Convolution
Jun 28, 2021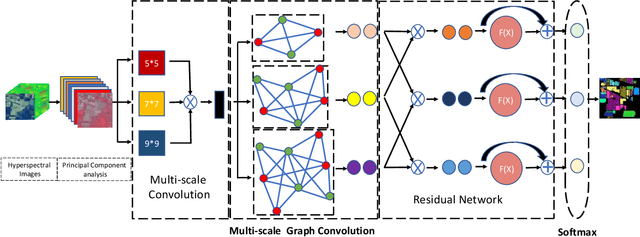
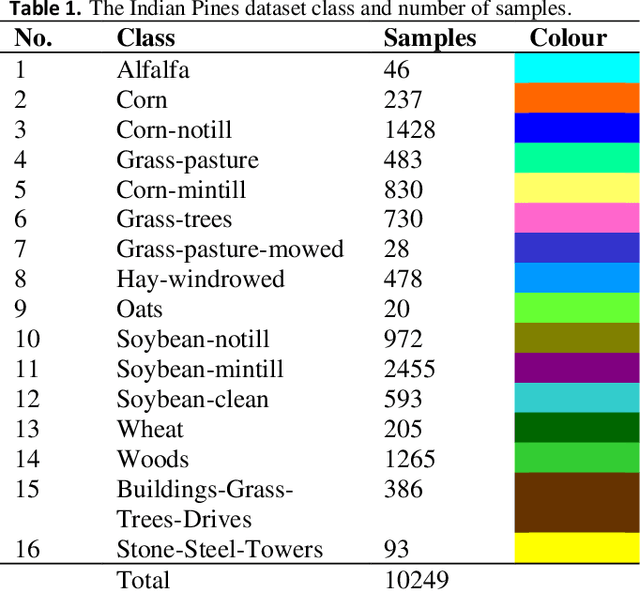
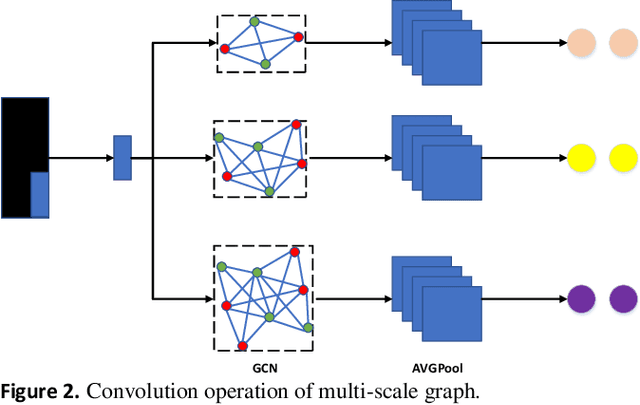
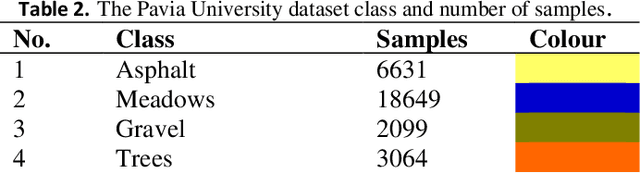
The mining and utilization of features directly affect the classification performance of models used in the classification and recognition of hyperspectral remote sensing images. Traditional models usually conduct feature mining from a single perspective, with the features mined being limited and the internal relationships between them being ignored. Consequently, useful features are lost and classification results are unsatisfactory. To fully mine and utilize image features, a new multi-scale feature-mining learning algorithm (MGRNet) is proposed. The model uses principal component analysis to reduce the dimensionality of the original hyperspectral image (HSI) to retain 99.99% of its semantic information and extract dimensionality reduction features. Using a multi-scale convolution algorithm, the input dimensionality reduction features were mined to obtain shallow features, which then served as inputs into a multi-scale graph convolution algorithm to construct the internal relationships between eigenvalues at different scales. We then carried out cross fusion of multi-scale information obtained by graph convolution, before inputting the new information obtained into the residual network algorithm for deep feature mining. Finally, a flexible maximum transfer function classifier was used to predict the final features and complete the classification. Experiments on three common hyperspectral datasets showed the MGRNet algorithm proposed in this paper to be superior to traditional methods in recognition accuracy.
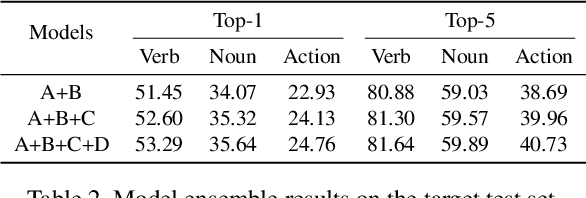
EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2021: Team M3EM Technical Report
Jun 27, 2021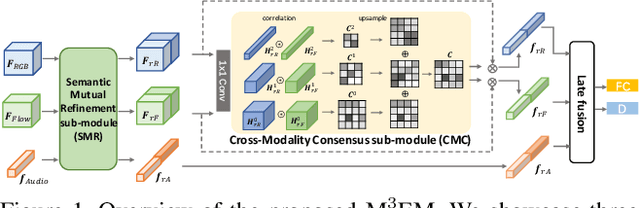

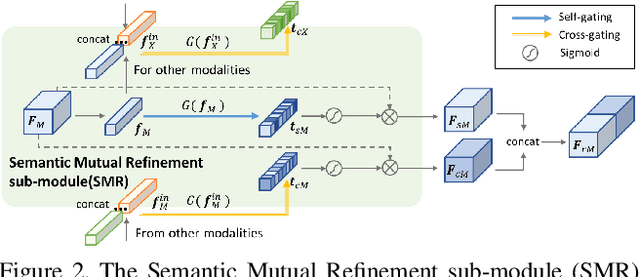
In this report, we describe the technical details of our submission to the 2021 EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition. Leveraging multiple modalities has been proved to benefit the Unsupervised Domain Adaptation (UDA) task. In this work, we present Multi-Modal Mutual Enhancement Module (M3EM), a deep module for jointly considering information from multiple modalities to find the most transferable representations across domains. We achieve this by implementing two sub-modules for enhancing each modality using the context of other modalities. The first sub-module exchanges information across modalities through the semantic space, while the second sub-module finds the most transferable spatial region based on the consensus of all modalities.
Trusted-Maximizers Entropy Search for Efficient Bayesian Optimization
Jul 30, 2021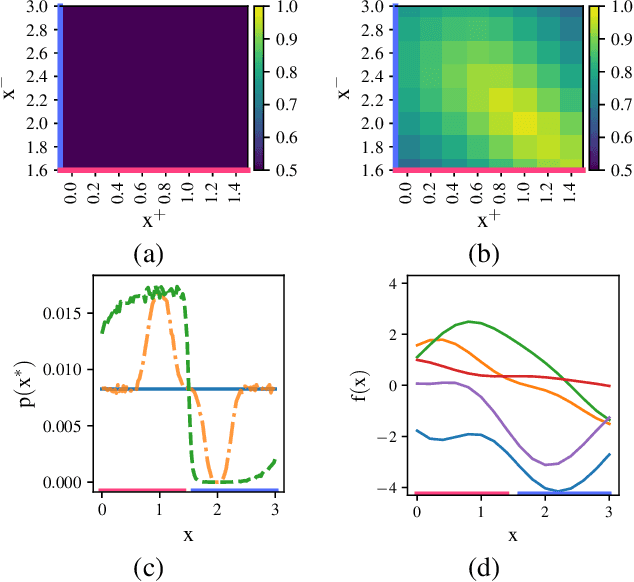
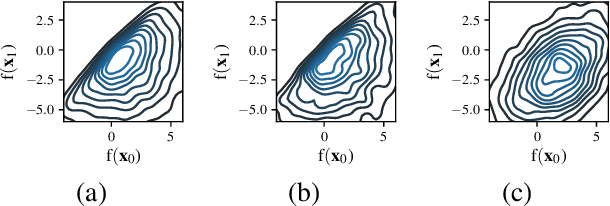
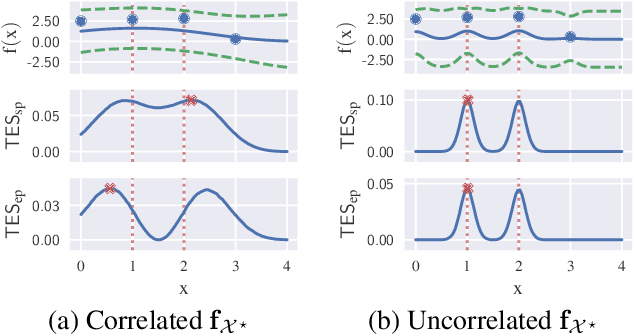
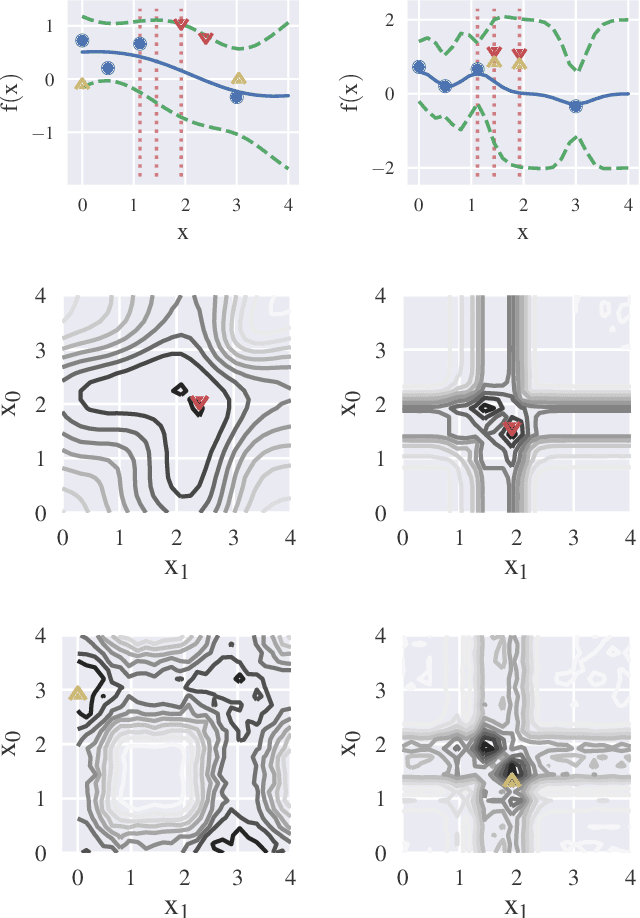
Information-based Bayesian optimization (BO) algorithms have achieved state-of-the-art performance in optimizing a black-box objective function. However, they usually require several approximations or simplifying assumptions (without clearly understanding their effects on the BO performance) and/or their generalization to batch BO is computationally unwieldy, especially with an increasing batch size. To alleviate these issues, this paper presents a novel trusted-maximizers entropy search (TES) acquisition function: It measures how much an input query contributes to the information gain on the maximizer over a finite set of trusted maximizers, i.e., inputs optimizing functions that are sampled from the Gaussian process posterior belief of the objective function. Evaluating TES requires either only a stochastic approximation with sampling or a deterministic approximation with expectation propagation, both of which are investigated and empirically evaluated using synthetic benchmark objective functions and real-world optimization problems, e.g., hyperparameter tuning of a convolutional neural network and synthesizing 'physically realizable' faces to fool a black-box face recognition system. Though TES can naturally be generalized to a batch variant with either approximation, the latter is amenable to be scaled to a much larger batch size in our experiments.
Model Order Selection Based on Information Theoretic Criteria: Design of the Penalty
Oct 04, 2019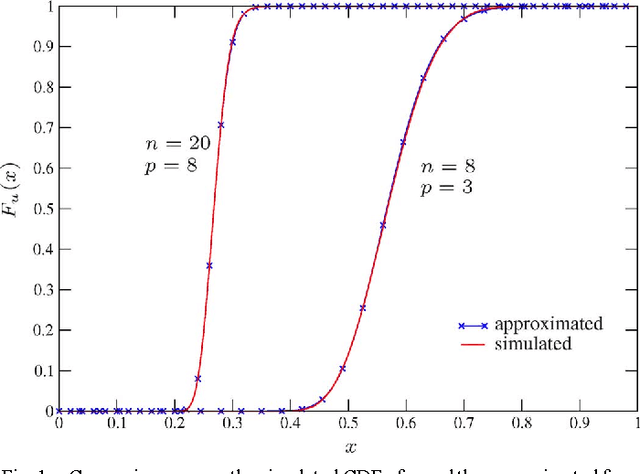
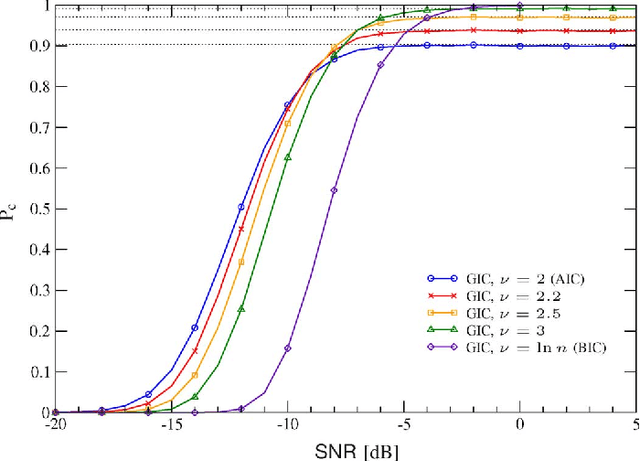
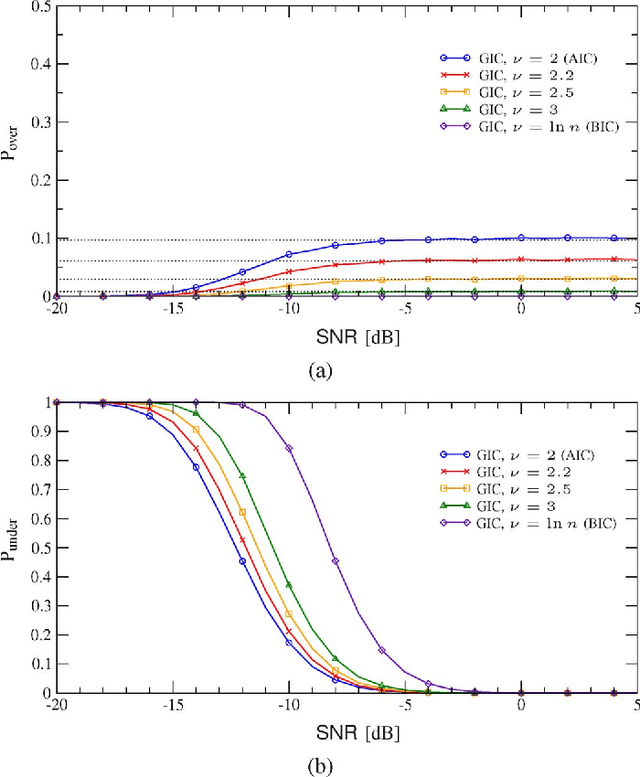
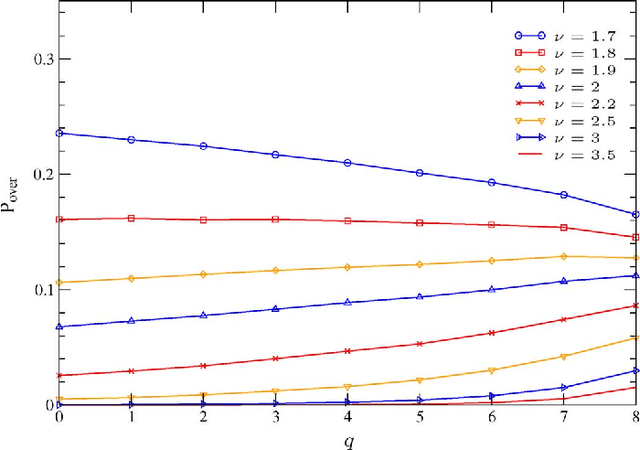
Information theoretic criteria (ITC) have been widely adopted in engineering and statistics for selecting, among an ordered set of candidate models, the one that better fits the observed sample data. The selected model minimizes a penalized likelihood metric, where the penalty is determined by the criterion adopted. While rules for choosing a penalty that guarantees a consistent estimate of the model order are known, theoretical tools for its design with finite samples have never been provided in a general setting. In this paper, we study model order selection for finite samples under a design perspective, focusing on the generalized information criterion (GIC), which embraces the most common ITC. The theory is general, and as case studies we consider: a) the problem of estimating the number of signals embedded in additive white Gaussian noise (AWGN) by using multiple sensors; b) model selection for the general linear model (GLM), which includes e.g. the problem of estimating the number of sinusoids in AWGN. The analysis reveals a trade-off between the probabilities of overestimating and underestimating the order of the model. We then propose to design the GIC penalty to minimize underestimation while keeping the overestimation probability below a specified level. For the considered problems, this method leads to analytical derivation of the optimal penalty for a given sample size. A performance comparison between the penalty optimized GIC and common AIC and BIC is provided, demonstrating the effectiveness of the proposed design strategy.
* 11 pages, 8 figures, journal
Structure-Aware Feature Generation for Zero-Shot Learning
Aug 16, 2021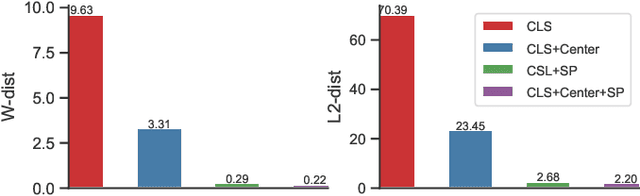

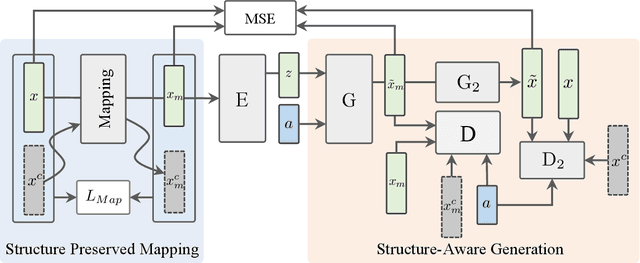
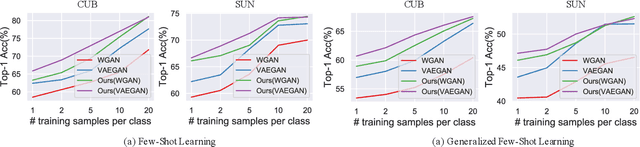
Zero-Shot Learning (ZSL) targets at recognizing unseen categories by leveraging auxiliary information, such as attribute embedding. Despite the encouraging results achieved, prior ZSL approaches focus on improving the discriminant power of seen-class features, yet have largely overlooked the geometric structure of the samples and the prototypes. The subsequent attribute-based generative adversarial network (GAN), as a result, also neglects the topological information in sample generation and further yields inferior performances in classifying the visual features of unseen classes. In this paper, we introduce a novel structure-aware feature generation scheme, termed as SA-GAN, to explicitly account for the topological structure in learning both the latent space and the generative networks. Specifically, we introduce a constraint loss to preserve the initial geometric structure when learning a discriminative latent space, and carry out our GAN training with additional supervising signals from a structure-aware discriminator and a reconstruction module. The former supervision distinguishes fake and real samples based on their affinity to class prototypes, while the latter aims to reconstruct the original feature space from the generated latent space. This topology-preserving mechanism enables our method to significantly enhance the generalization capability on unseen-classes and consequently improve the classification performance. Experiments on four benchmarks demonstrate that the proposed approach consistently outperforms the state of the art. Our code can be found in the supplementary material and will also be made publicly available.
Emergency Incident Detection from Crowdsourced Waze Data using Bayesian Information Fusion
Nov 10, 2020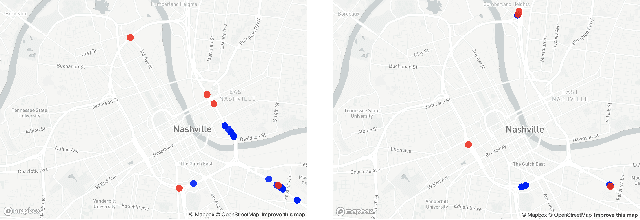
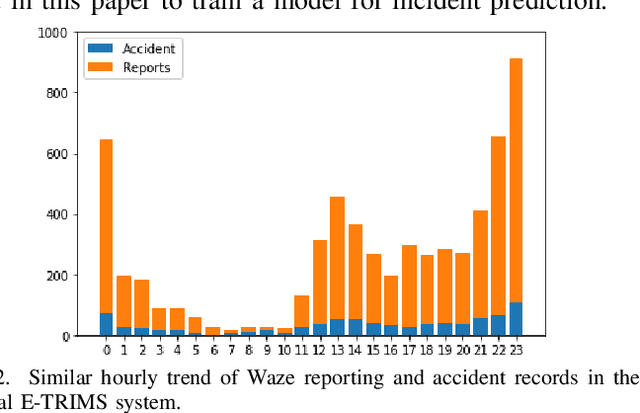
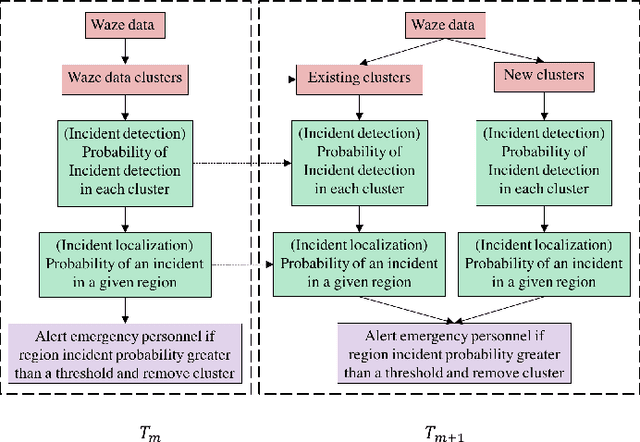
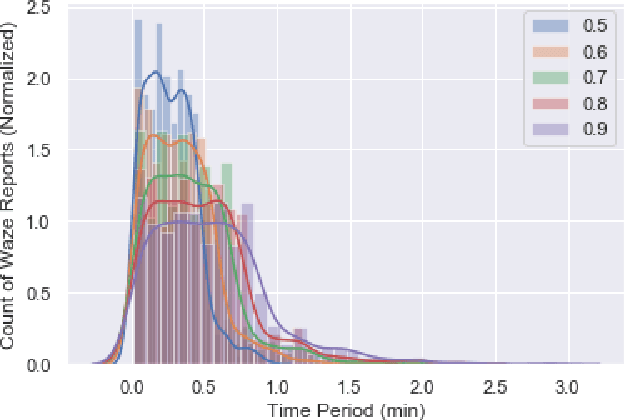
The number of emergencies have increased over the years with the growth in urbanization. This pattern has overwhelmed the emergency services with limited resources and demands the optimization of response processes. It is partly due to traditional `reactive' approach of emergency services to collect data about incidents, where a source initiates a call to the emergency number (e.g., 911 in U.S.), delaying and limiting the potentially optimal response. Crowdsourcing platforms such as Waze provides an opportunity to develop a rapid, `proactive' approach to collect data about incidents through crowd-generated observational reports. However, the reliability of reporting sources and spatio-temporal uncertainty of the reported incidents challenge the design of such a proactive approach. Thus, this paper presents a novel method for emergency incident detection using noisy crowdsourced Waze data. We propose a principled computational framework based on Bayesian theory to model the uncertainty in the reliability of crowd-generated reports and their integration across space and time to detect incidents. Extensive experiments using data collected from Waze and the official reported incidents in Nashville, Tenessee in the U.S. show our method can outperform strong baselines for both F1-score and AUC. The application of this work provides an extensible framework to incorporate different noisy data sources for proactive incident detection to improve and optimize emergency response operations in our communities.
Eigenbehaviour as an Indicator of Cognitive Abilities
Oct 18, 2021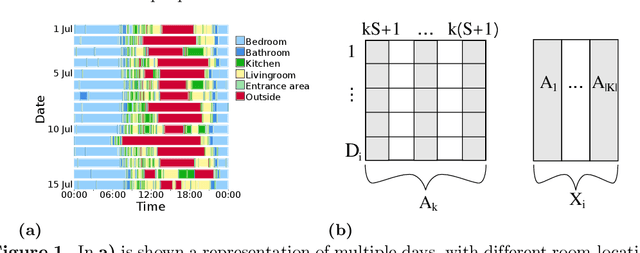

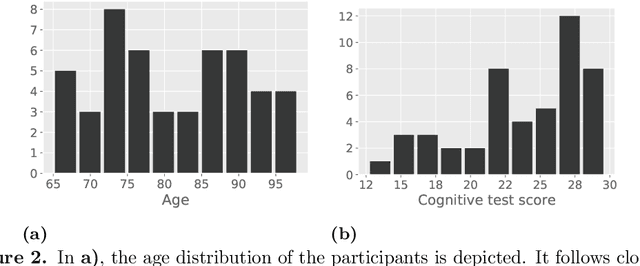
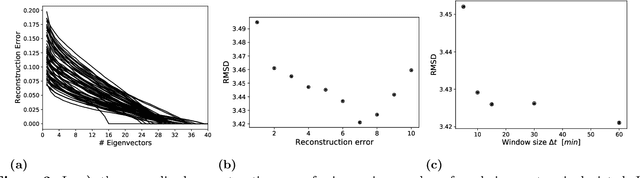
With growing usage of machine learning algorithms and big data in health applications, digital biomarkers have become an important key feature to ensure the success of those applications. In this paper, we focus on one important use-case, the long-term continuous monitoring of the cognitive ability of older adults. The cognitive ability is a factor both for long-term monitoring of people living alone as well as an outcome in clinical studies. In this work, we propose a new digital biomarker for cognitive abilities based on location eigenbehaviour obtained from contactless ambient sensors. Indoor location information obtained from passive infrared sensors is used to build a location matrix covering several weeks of measurement. Based on the eigenvectors of this matrix, the reconstruction error is calculated for various numbers of used eigenvectors. The reconstruction error is used to predict cognitive ability scores collected at baseline, using linear regression. Additionally, classification of normal versus pathological cognition level is performed using a support-vector-machine. Prediction performance is strong for high levels of cognitive ability, but grows weaker for low levels of cognitive ability. Classification into normal versus pathological cognitive ability level reaches high accuracy with a AUC = 0.94. Due to the unobtrusive method of measurement based on contactless ambient sensors, this digital biomarker of cognitive ability is easily obtainable. The usage of the reconstruction error is a strong digital biomarker for the binary classification and, to a lesser extent, for more detailed prediction of interindividual differences in cognition.