 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Zooming Into the Darknet: Characterizing Internet Background Radiation and its Structural Changes
Aug 05, 2021
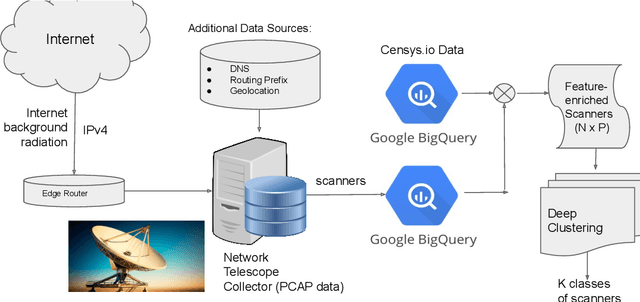

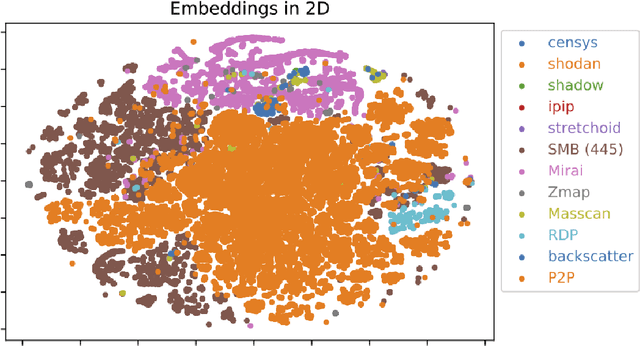

Network telescopes or "Darknets" provide a unique window into Internet-wide malicious activities associated with malware propagation, denial of service attacks, scanning performed for network reconnaissance, and others. Analyses of the resulting data can provide actionable insights to security analysts that can be used to prevent or mitigate cyber-threats. Large Darknets, however, observe millions of nefarious events on a daily basis which makes the transformation of the captured information into meaningful insights challenging. We present a novel framework for characterizing Darknet behavior and its temporal evolution aiming to address this challenge. The proposed framework: (i) Extracts a high dimensional representation of Darknet events composed of features distilled from Darknet data and other external sources; (ii) Learns, in an unsupervised fashion, an information-preserving low-dimensional representation of these events (using deep representation learning) that is amenable to clustering; (iv) Performs clustering of the scanner data in the resulting representation space and provides interpretable insights using optimal decision trees; and (v) Utilizes the clustering outcomes as "signatures" that can be used to detect structural changes in the Darknet activities. We evaluate the proposed system on a large operational Network Telescope and demonstrate its ability to detect real-world, high-impact cybersecurity incidents.
Explain Me the Painting: Multi-Topic Knowledgeable Art Description Generation
Sep 13, 2021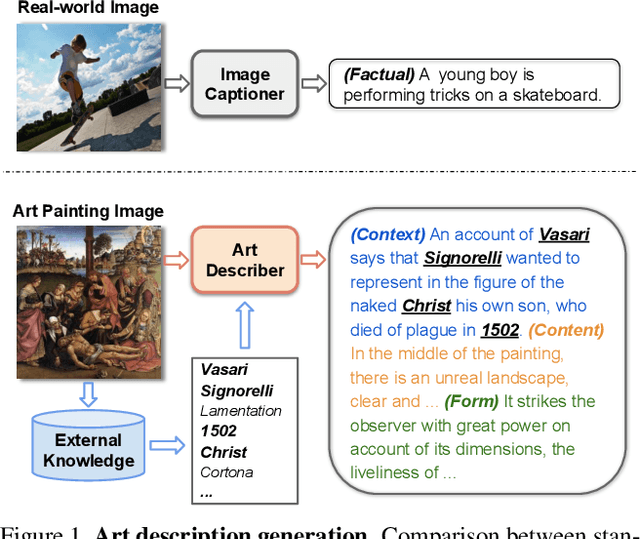
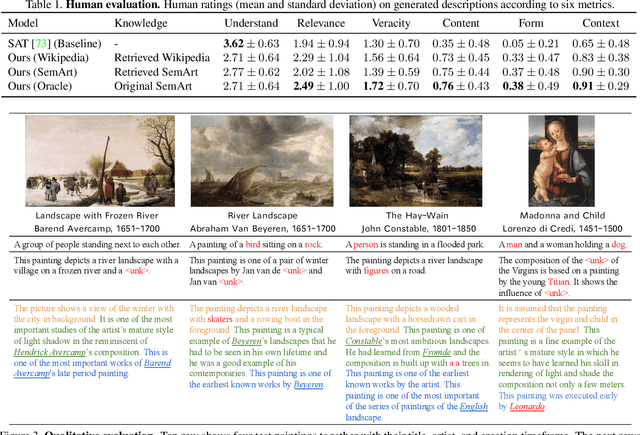
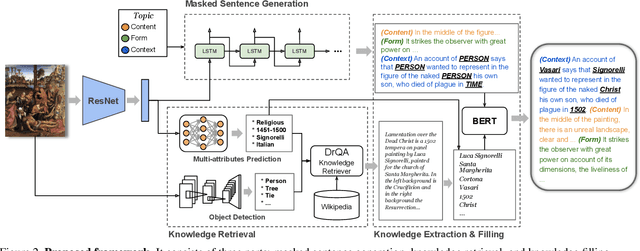
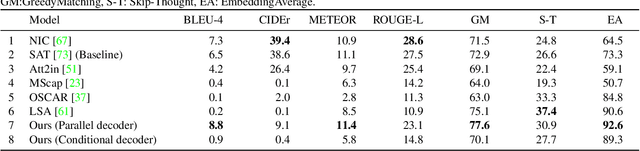
Have you ever looked at a painting and wondered what is the story behind it? This work presents a framework to bring art closer to people by generating comprehensive descriptions of fine-art paintings. Generating informative descriptions for artworks, however, is extremely challenging, as it requires to 1) describe multiple aspects of the image such as its style, content, or composition, and 2) provide background and contextual knowledge about the artist, their influences, or the historical period. To address these challenges, we introduce a multi-topic and knowledgeable art description framework, which modules the generated sentences according to three artistic topics and, additionally, enhances each description with external knowledge. The framework is validated through an exhaustive analysis, both quantitative and qualitative, as well as a comparative human evaluation, demonstrating outstanding results in terms of both topic diversity and information veracity.
SDR: Efficient Neural Re-ranking using Succinct Document Representation
Oct 03, 2021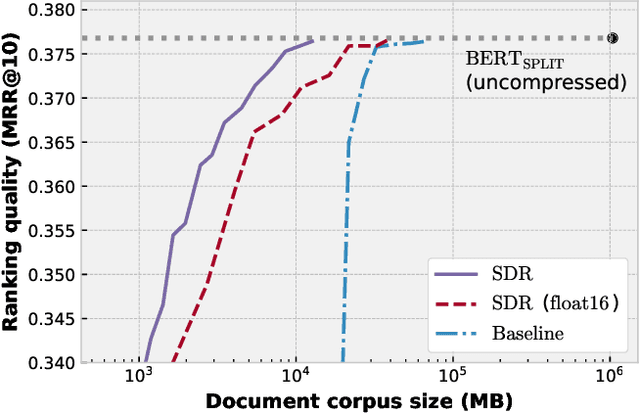
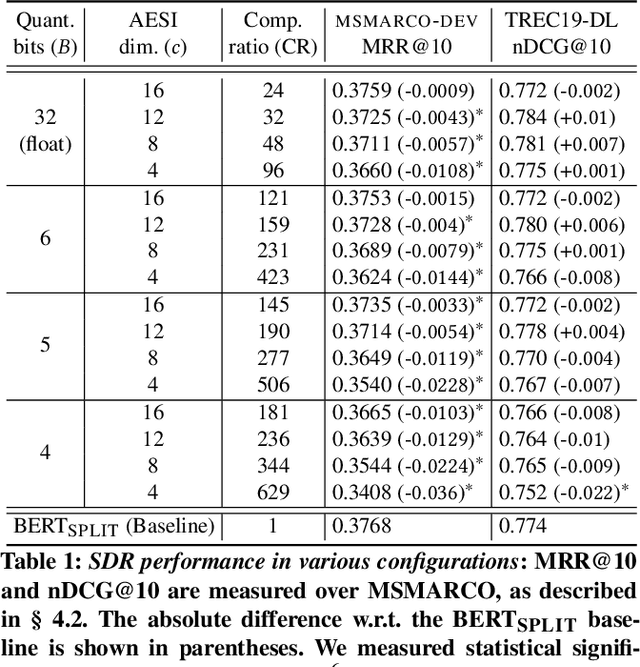
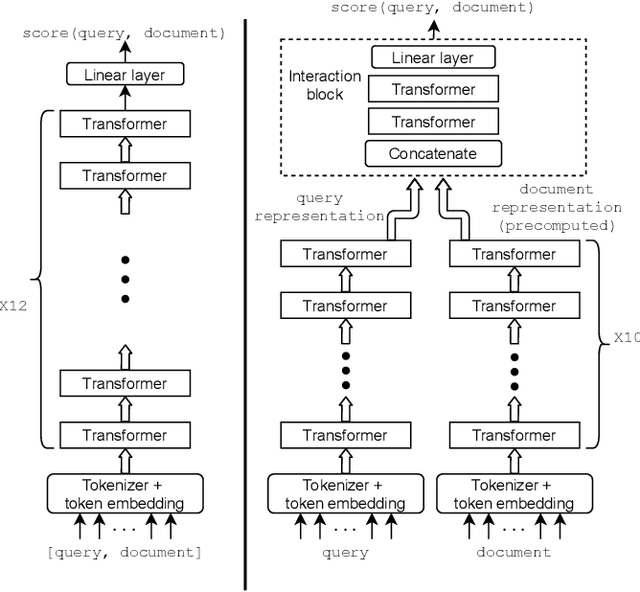
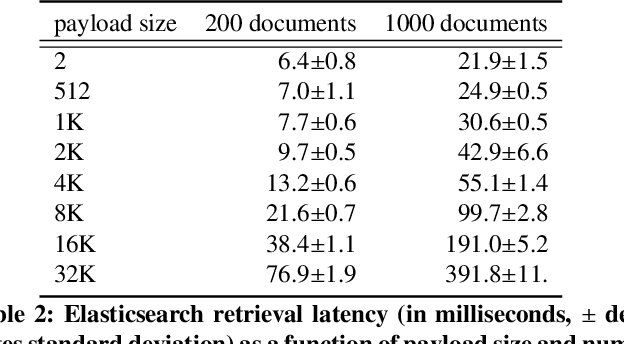
BERT based ranking models have achieved superior performance on various information retrieval tasks. However, the large number of parameters and complex self-attention operation come at a significant latency overhead. To remedy this, recent works propose late-interaction architectures, which allow pre-computation of intermediate document representations, thus reducing the runtime latency. Nonetheless, having solved the immediate latency issue, these methods now introduce storage costs and network fetching latency, which limits their adoption in real-life production systems. In this work, we propose the Succinct Document Representation (SDR) scheme that computes highly compressed intermediate document representations, mitigating the storage/network issue. Our approach first reduces the dimension of token representations by encoding them using a novel autoencoder architecture that uses the document's textual content in both the encoding and decoding phases. After this token encoding step, we further reduce the size of entire document representations using a modern quantization technique. Extensive evaluations on passage re-reranking on the MSMARCO dataset show that compared to existing approaches using compressed document representations, our method is highly efficient, achieving 4x-11.6x better compression rates for the same ranking quality.
Gradient Disaggregation: Breaking Privacy in Federated Learning by Reconstructing the User Participant Matrix
Jun 10, 2021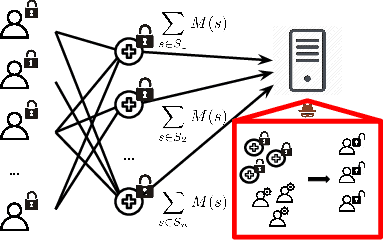
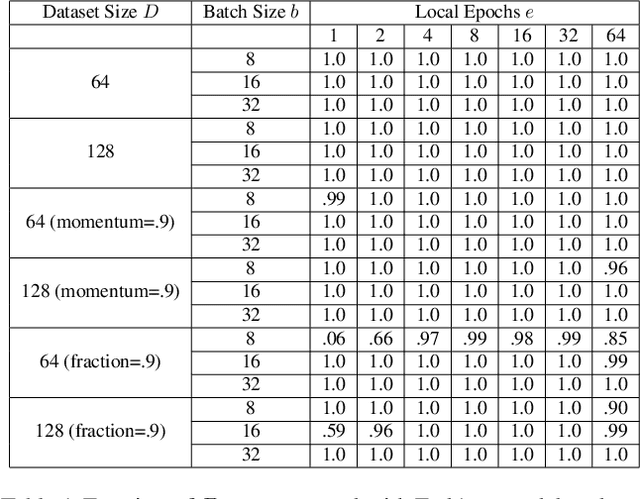
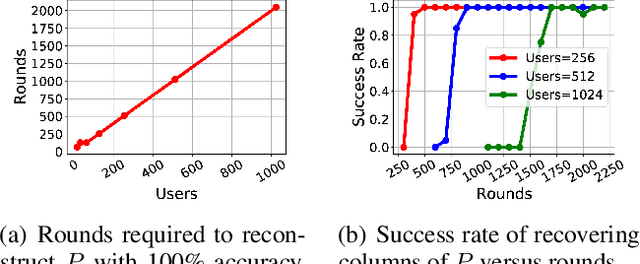

We show that aggregated model updates in federated learning may be insecure. An untrusted central server may disaggregate user updates from sums of updates across participants given repeated observations, enabling the server to recover privileged information about individual users' private training data via traditional gradient inference attacks. Our method revolves around reconstructing participant information (e.g: which rounds of training users participated in) from aggregated model updates by leveraging summary information from device analytics commonly used to monitor, debug, and manage federated learning systems. Our attack is parallelizable and we successfully disaggregate user updates on settings with up to thousands of participants. We quantitatively and qualitatively demonstrate significant improvements in the capability of various inference attacks on the disaggregated updates. Our attack enables the attribution of learned properties to individual users, violating anonymity, and shows that a determined central server may undermine the secure aggregation protocol to break individual users' data privacy in federated learning.
Debiasing Methods in Natural Language Understanding Make Bias More Accessible
Sep 09, 2021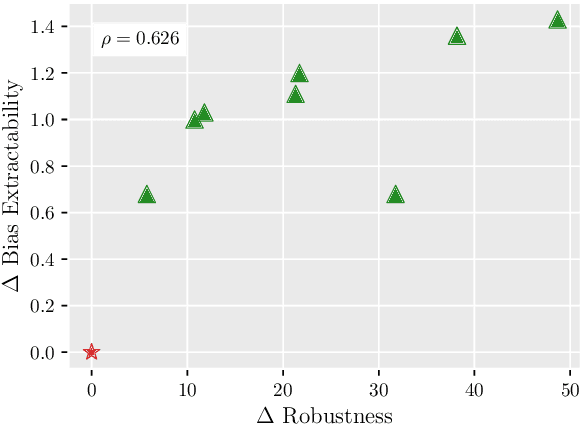
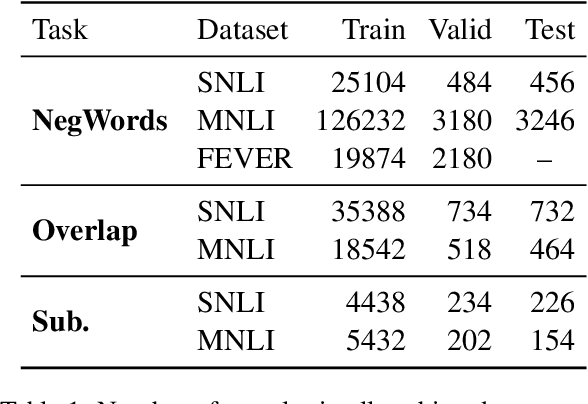
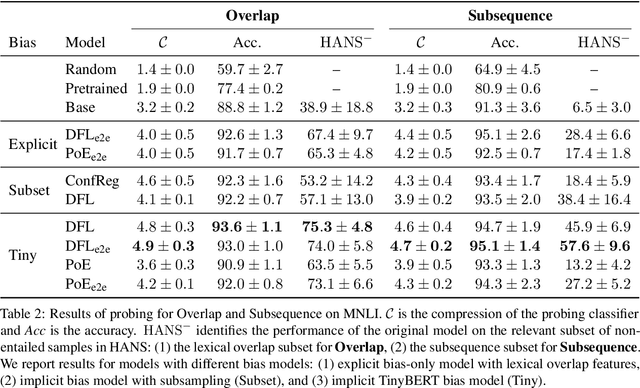
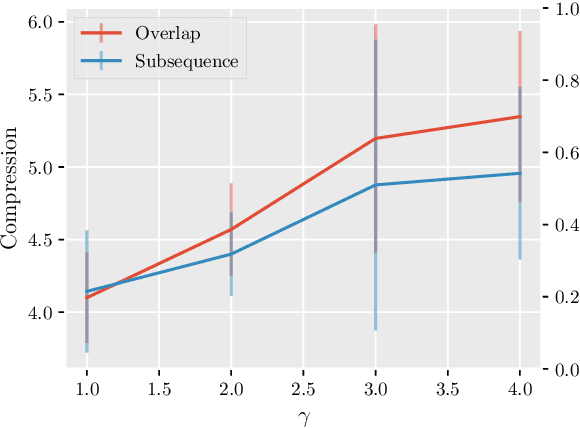
Model robustness to bias is often determined by the generalization on carefully designed out-of-distribution datasets. Recent debiasing methods in natural language understanding (NLU) improve performance on such datasets by pressuring models into making unbiased predictions. An underlying assumption behind such methods is that this also leads to the discovery of more robust features in the model's inner representations. We propose a general probing-based framework that allows for post-hoc interpretation of biases in language models, and use an information-theoretic approach to measure the extractability of certain biases from the model's representations. We experiment with several NLU datasets and known biases, and show that, counter-intuitively, the more a language model is pushed towards a debiased regime, the more bias is actually encoded in its inner representations.
Neural Link Prediction with Walk Pooling
Oct 08, 2021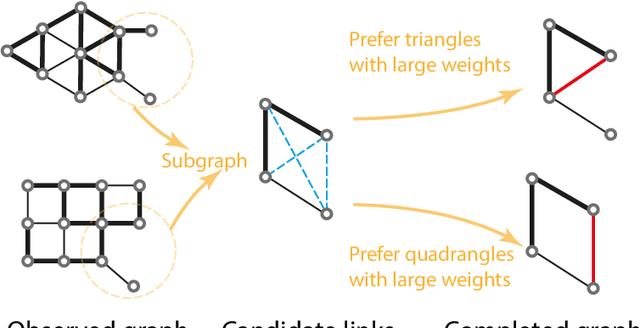
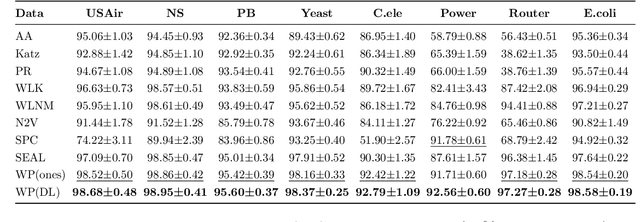
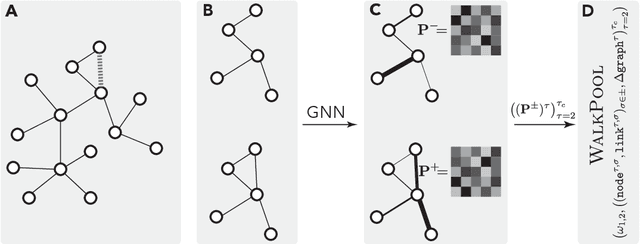
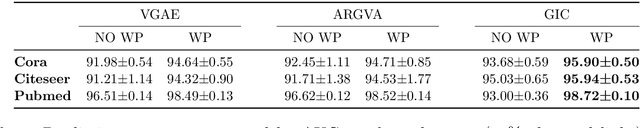
Graph neural networks achieve high accuracy in link prediction by jointly leveraging graph topology and node attributes. Topology, however, is represented indirectly; state-of-the-art methods based on subgraph classification label nodes with distance to the target link, so that, although topological information is present, it is tempered by pooling. This makes it challenging to leverage features like loops and motifs associated with network formation mechanisms. We propose a link prediction algorithm based on a new pooling scheme called WalkPool. WalkPool combines the expressivity of topological heuristics with the feature-learning ability of neural networks. It summarizes a putative link by random walk probabilities of adjacent paths. Instead of extracting transition probabilities from the original graph, it computes the transition matrix of a "predictive" latent graph by applying attention to learned features; this may be interpreted as feature-sensitive topology fingerprinting. WalkPool can leverage unsupervised node features or be combined with GNNs and trained end-to-end. It outperforms state-of-the-art methods on all common link prediction benchmarks, both homophilic and heterophilic, with and without node attributes. Applying WalkPool to a set of unsupervised GNNs significantly improves prediction accuracy, suggesting that it may be used as a general-purpose graph pooling scheme.
Improving GNSS Positioning using Neural Network-based Corrections
Oct 18, 2021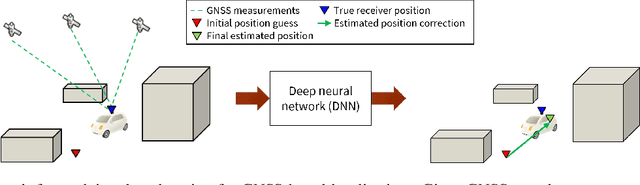



Deep Neural Networks (DNNs) are a promising tool for Global Navigation Satellite System (GNSS) positioning in the presence of multipath and non-line-of-sight errors, owing to their ability to model complex errors using data. However, developing a DNN for GNSS positioning presents various challenges, such as 1) poor numerical conditioning caused by large variations in measurements and position values across the globe, 2) varying number and order within the set of measurements due to changing satellite visibility, and 3) overfitting to available data. In this work, we address the aforementioned challenges and propose an approach for GNSS positioning by applying DNN-based corrections to an initial position guess. Our DNN learns to output the position correction using the set of pseudorange residuals and satellite line-of-sight vectors as inputs. The limited variation in these input and output values improves the numerical conditioning for our DNN. We design our DNN architecture to combine information from the available GNSS measurements, which vary both in number and order, by leveraging recent advancements in set-based deep learning methods. Furthermore, we present a data augmentation strategy for reducing overfitting in the DNN by randomizing the initial position guesses. We first perform simulations and show an improvement in the initial positioning error when our DNN-based corrections are applied. After this, we demonstrate that our approach outperforms a WLS baseline on real-world data. Our implementation is available at github.com/Stanford-NavLab/deep_gnss.
Bidirectional Regression for Arbitrary-Shaped Text Detection
Jul 13, 2021
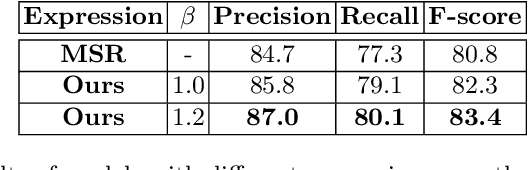
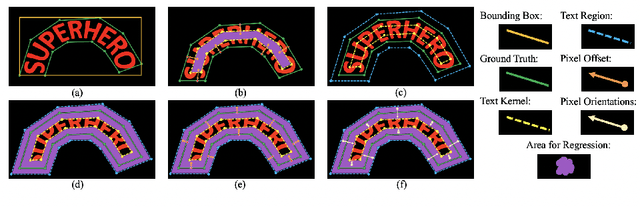

Arbitrary-shaped text detection has recently attracted increasing interests and witnessed rapid development with the popularity of deep learning algorithms. Nevertheless, existing approaches often obtain inaccurate detection results, mainly due to the relatively weak ability to utilize context information and the inappropriate choice of offset references. This paper presents a novel text instance expression which integrates both foreground and background information into the pipeline, and naturally uses the pixels near text boundaries as the offset starts. Besides, a corresponding post-processing algorithm is also designed to sequentially combine the four prediction results and reconstruct the text instance accurately. We evaluate our method on several challenging scene text benchmarks, including both curved and multi-oriented text datasets. Experimental results demonstrate that the proposed approach obtains superior or competitive performance compared to other state-of-the-art methods, e.g., 83.4% F-score for Total-Text, 82.4% F-score for MSRA-TD500, etc.
IQ-Learn: Inverse soft-Q Learning for Imitation
Jun 23, 2021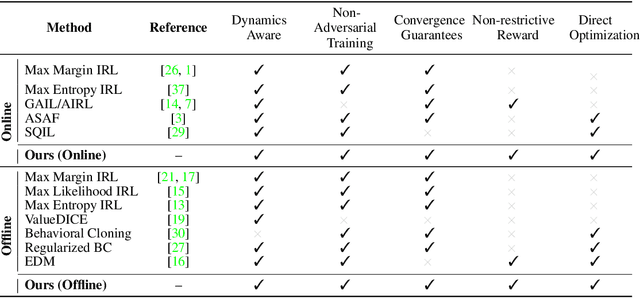
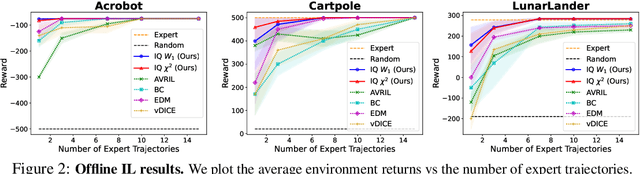
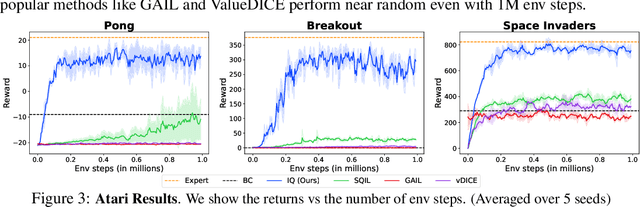
In many sequential decision-making problems (e.g., robotics control, game playing, sequential prediction), human or expert data is available containing useful information about the task. However, imitation learning (IL) from a small amount of expert data can be challenging in high-dimensional environments with complex dynamics. Behavioral cloning is a simple method that is widely used due to its simplicity of implementation and stable convergence but doesn't utilize any information involving the environment's dynamics. Many existing methods that exploit dynamics information are difficult to train in practice due to an adversarial optimization process over reward and policy approximators or biased, high variance gradient estimators. We introduce a method for dynamics-aware IL which avoids adversarial training by learning a single Q-function, implicitly representing both reward and policy. On standard benchmarks, the implicitly learned rewards show a high positive correlation with the ground-truth rewards, illustrating our method can also be used for inverse reinforcement learning (IRL). Our method, Inverse soft-Q learning (IQ-Learn) obtains state-of-the-art results in offline and online imitation learning settings, surpassing existing methods both in the number of required environment interactions and scalability in high-dimensional spaces.
Local and Global Context-Based Pairwise Models for Sentence Ordering
Oct 08, 2021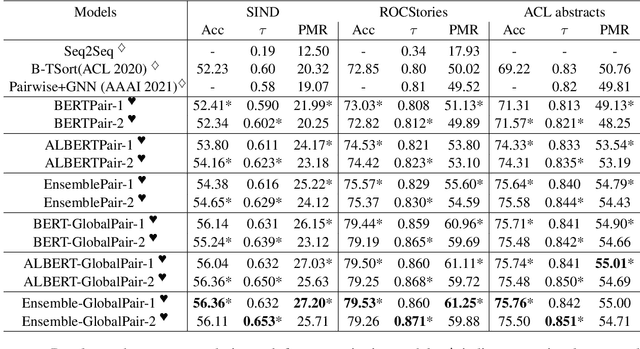
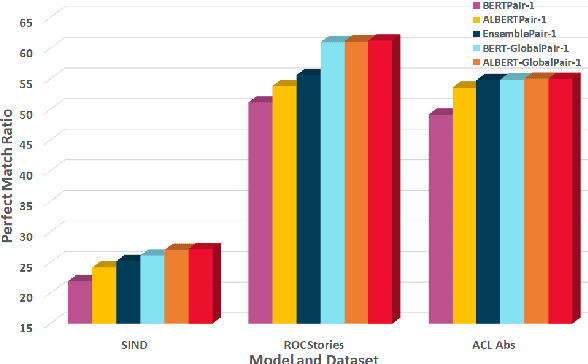
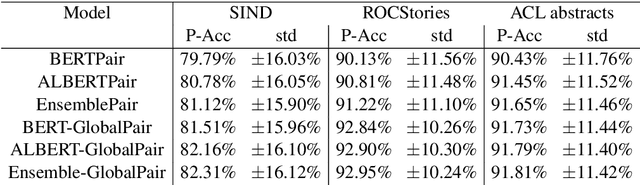
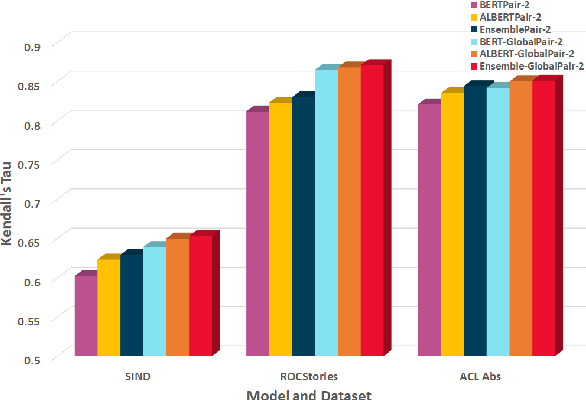
Sentence Ordering refers to the task of rearranging a set of sentences into the appropriate coherent order. For this task, most previous approaches have explored global context-based end-to-end methods using Sequence Generation techniques. In this paper, we put forward a set of robust local and global context-based pairwise ordering strategies, leveraging which our prediction strategies outperform all previous works in this domain. Our proposed encoding method utilizes the paragraph's rich global contextual information to predict the pairwise order using novel transformer architectures. Analysis of the two proposed decoding strategies helps better explain error propagation in pairwise models. This approach is the most accurate pure pairwise model and our encoding strategy also significantly improves the performance of other recent approaches that use pairwise models, including the previous state-of-the-art, demonstrating the research novelty and generalizability of this work. Additionally, we show how the pre-training task for ALBERT helps it to significantly outperform BERT, despite having considerably lesser parameters. The extensive experimental results, architectural analysis and ablation studies demonstrate the effectiveness and superiority of the proposed models compared to the previous state-of-the-art, besides providing a much better understanding of the functioning of pairwise models.