 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transformer-based unsupervised patient representation learning based on medical claims for risk stratification and analysis
Jun 23, 2021
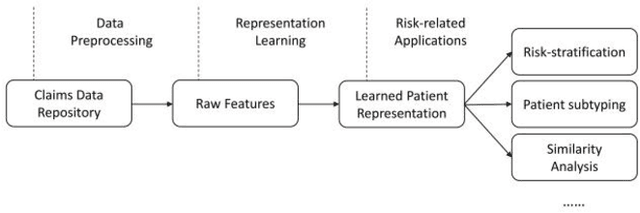
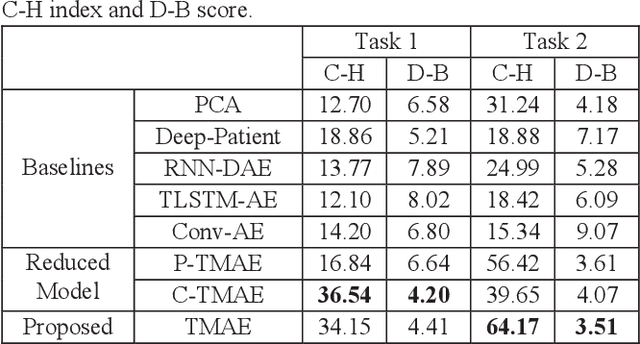
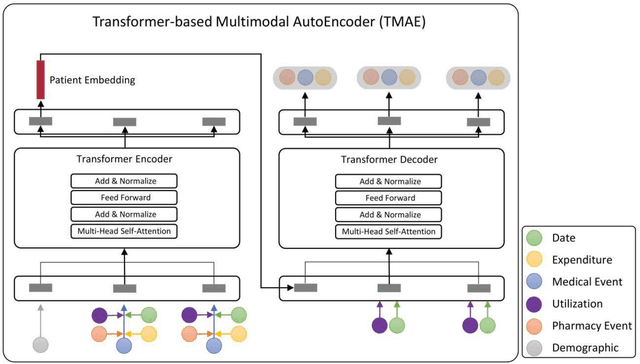
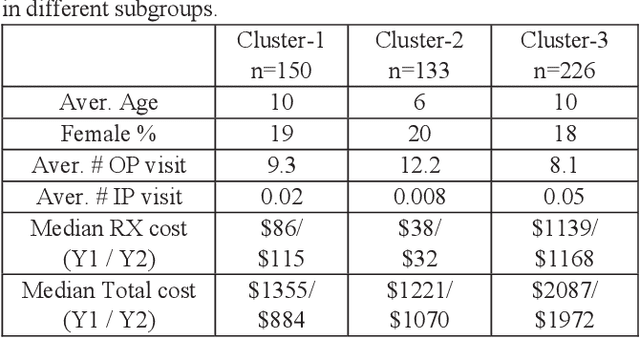
The claims data, containing medical codes, services information, and incurred expenditure, can be a good resource for estimating an individual's health condition and medical risk level. In this study, we developed Transformer-based Multimodal AutoEncoder (TMAE), an unsupervised learning framework that can learn efficient patient representation by encoding meaningful information from the claims data. TMAE is motivated by the practical needs in healthcare to stratify patients into different risk levels for improving care delivery and management. Compared to previous approaches, TMAE is able to 1) model inpatient, outpatient, and medication claims collectively, 2) handle irregular time intervals between medical events, 3) alleviate the sparsity issue of the rare medical codes, and 4) incorporate medical expenditure information. We trained TMAE using a real-world pediatric claims dataset containing more than 600,000 patients and compared its performance with various approaches in two clustering tasks. Experimental results demonstrate that TMAE has superior performance compared to all baselines. Multiple downstream applications are also conducted to illustrate the effectiveness of our framework. The promising results confirm that the TMAE framework is scalable to large claims data and is able to generate efficient patient embeddings for risk stratification and analysis.
Explain Me the Painting: Multi-Topic Knowledgeable Art Description Generation
Sep 13, 2021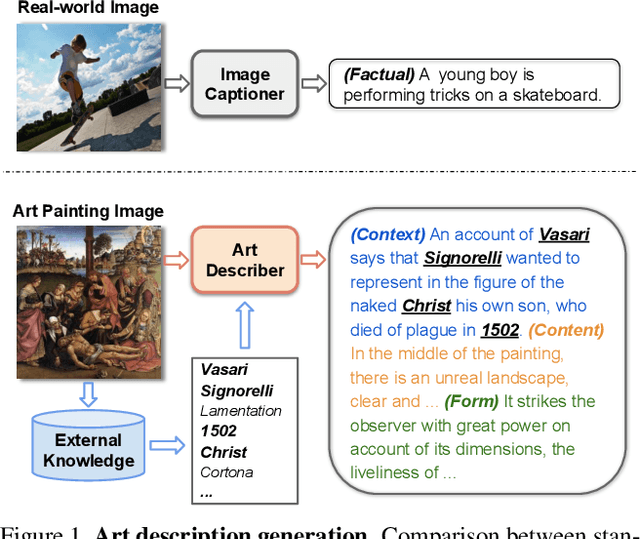
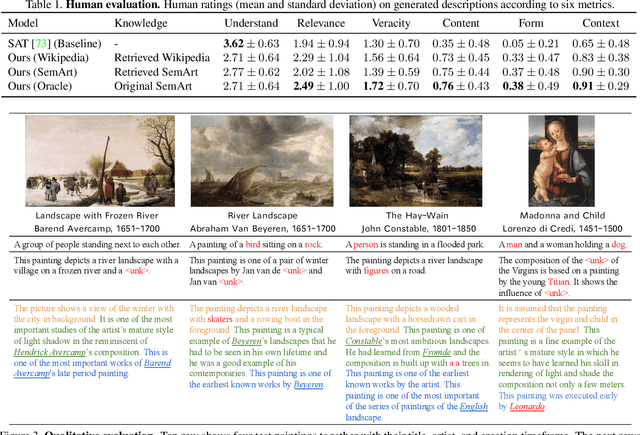
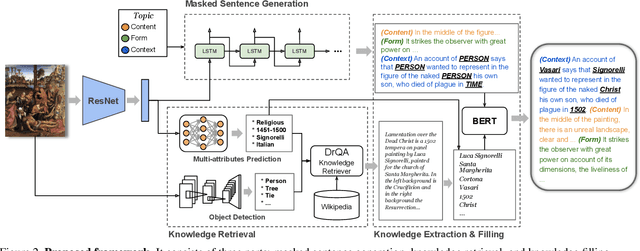
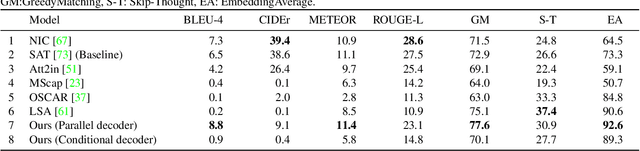
Have you ever looked at a painting and wondered what is the story behind it? This work presents a framework to bring art closer to people by generating comprehensive descriptions of fine-art paintings. Generating informative descriptions for artworks, however, is extremely challenging, as it requires to 1) describe multiple aspects of the image such as its style, content, or composition, and 2) provide background and contextual knowledge about the artist, their influences, or the historical period. To address these challenges, we introduce a multi-topic and knowledgeable art description framework, which modules the generated sentences according to three artistic topics and, additionally, enhances each description with external knowledge. The framework is validated through an exhaustive analysis, both quantitative and qualitative, as well as a comparative human evaluation, demonstrating outstanding results in terms of both topic diversity and information veracity.
Local and Global Context-Based Pairwise Models for Sentence Ordering
Oct 08, 2021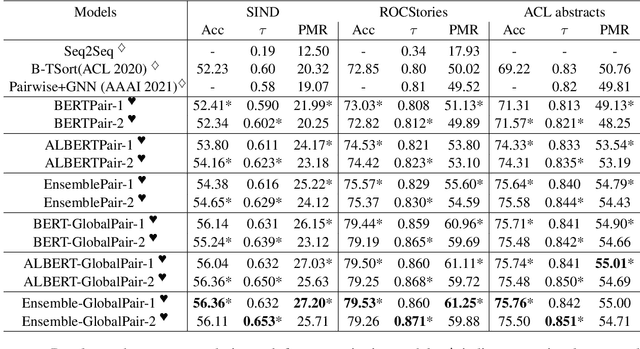
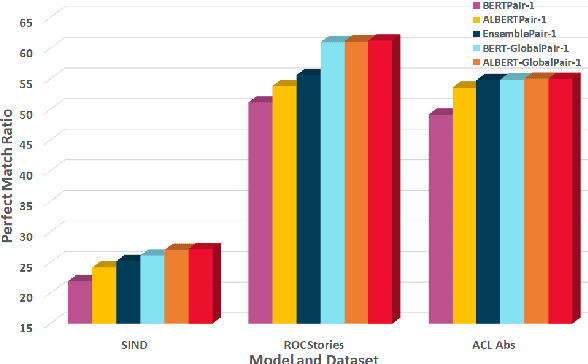
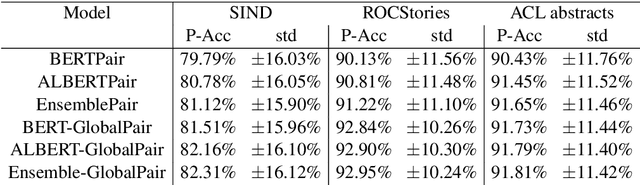
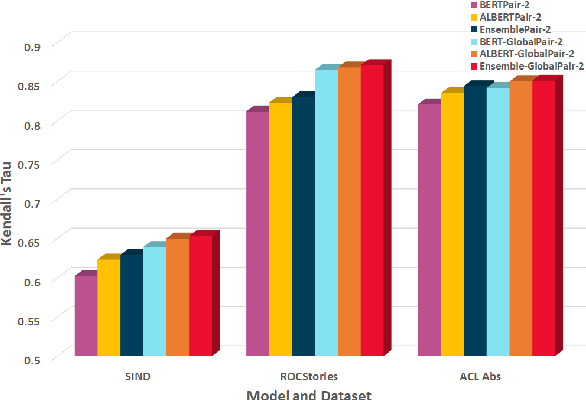
Sentence Ordering refers to the task of rearranging a set of sentences into the appropriate coherent order. For this task, most previous approaches have explored global context-based end-to-end methods using Sequence Generation techniques. In this paper, we put forward a set of robust local and global context-based pairwise ordering strategies, leveraging which our prediction strategies outperform all previous works in this domain. Our proposed encoding method utilizes the paragraph's rich global contextual information to predict the pairwise order using novel transformer architectures. Analysis of the two proposed decoding strategies helps better explain error propagation in pairwise models. This approach is the most accurate pure pairwise model and our encoding strategy also significantly improves the performance of other recent approaches that use pairwise models, including the previous state-of-the-art, demonstrating the research novelty and generalizability of this work. Additionally, we show how the pre-training task for ALBERT helps it to significantly outperform BERT, despite having considerably lesser parameters. The extensive experimental results, architectural analysis and ablation studies demonstrate the effectiveness and superiority of the proposed models compared to the previous state-of-the-art, besides providing a much better understanding of the functioning of pairwise models.
AID-Purifier: A Light Auxiliary Network for Boosting Adversarial Defense
Jul 14, 2021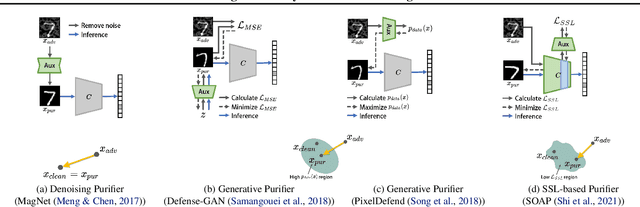
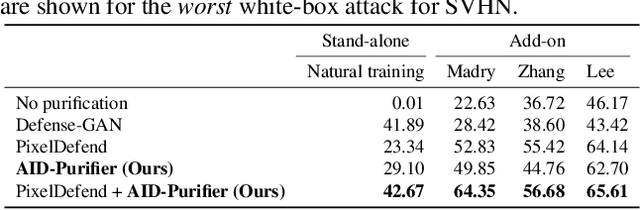
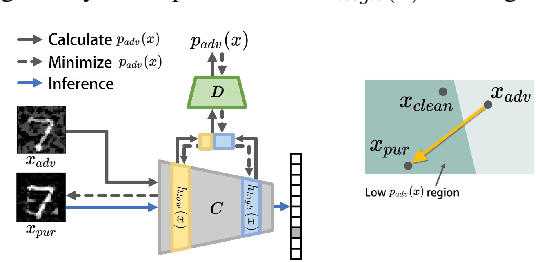

We propose an AID-purifier that can boost the robustness of adversarially-trained networks by purifying their inputs. AID-purifier is an auxiliary network that works as an add-on to an already trained main classifier. To keep it computationally light, it is trained as a discriminator with a binary cross-entropy loss. To obtain additionally useful information from the adversarial examples, the architecture design is closely related to information maximization principles where two layers of the main classification network are piped to the auxiliary network. To assist the iterative optimization procedure of purification, the auxiliary network is trained with AVmixup. AID-purifier can be used together with other purifiers such as PixelDefend for an extra enhancement. The overall results indicate that the best performing adversarially-trained networks can be enhanced by the best performing purification networks, where AID-purifier is a competitive candidate that is light and robust.
Debiasing Methods in Natural Language Understanding Make Bias More Accessible
Sep 09, 2021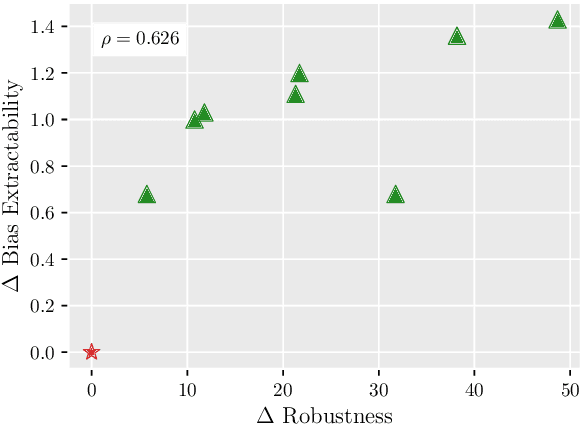
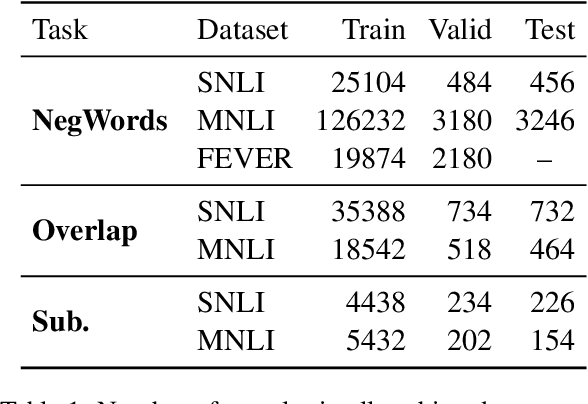
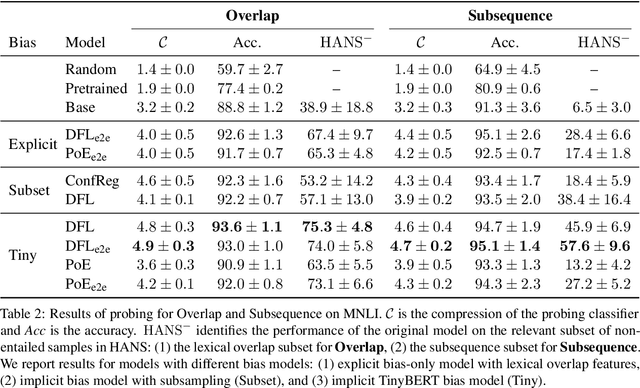
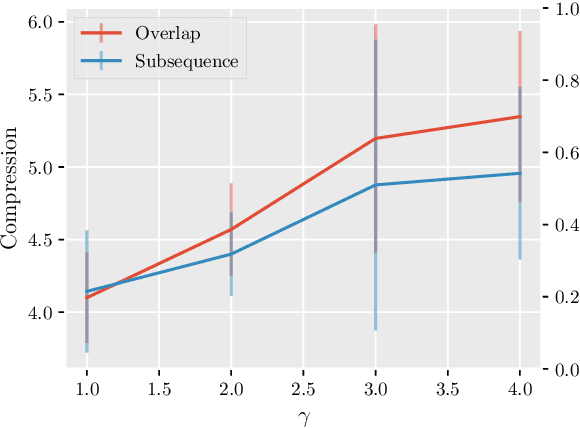
Model robustness to bias is often determined by the generalization on carefully designed out-of-distribution datasets. Recent debiasing methods in natural language understanding (NLU) improve performance on such datasets by pressuring models into making unbiased predictions. An underlying assumption behind such methods is that this also leads to the discovery of more robust features in the model's inner representations. We propose a general probing-based framework that allows for post-hoc interpretation of biases in language models, and use an information-theoretic approach to measure the extractability of certain biases from the model's representations. We experiment with several NLU datasets and known biases, and show that, counter-intuitively, the more a language model is pushed towards a debiased regime, the more bias is actually encoded in its inner representations.
Eigenbehaviour as an Indicator of Cognitive Abilities
Oct 18, 2021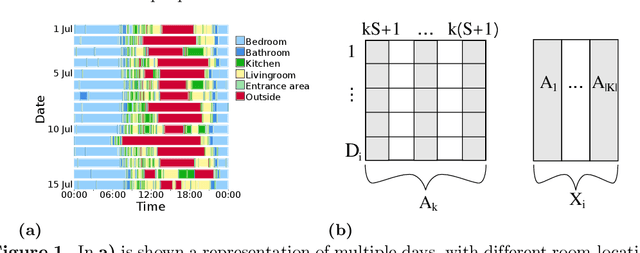

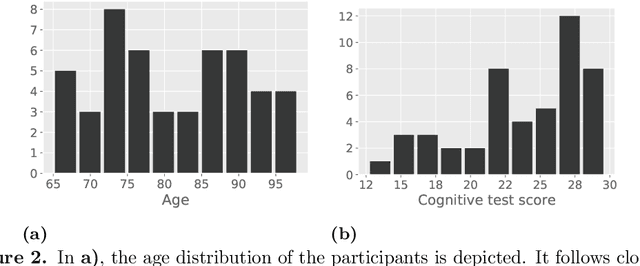
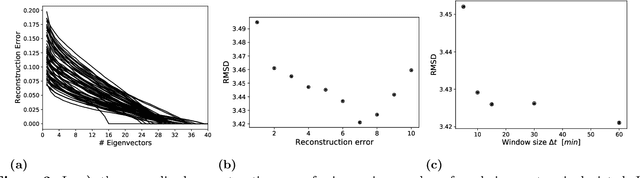
With growing usage of machine learning algorithms and big data in health applications, digital biomarkers have become an important key feature to ensure the success of those applications. In this paper, we focus on one important use-case, the long-term continuous monitoring of the cognitive ability of older adults. The cognitive ability is a factor both for long-term monitoring of people living alone as well as an outcome in clinical studies. In this work, we propose a new digital biomarker for cognitive abilities based on location eigenbehaviour obtained from contactless ambient sensors. Indoor location information obtained from passive infrared sensors is used to build a location matrix covering several weeks of measurement. Based on the eigenvectors of this matrix, the reconstruction error is calculated for various numbers of used eigenvectors. The reconstruction error is used to predict cognitive ability scores collected at baseline, using linear regression. Additionally, classification of normal versus pathological cognition level is performed using a support-vector-machine. Prediction performance is strong for high levels of cognitive ability, but grows weaker for low levels of cognitive ability. Classification into normal versus pathological cognitive ability level reaches high accuracy with a AUC = 0.94. Due to the unobtrusive method of measurement based on contactless ambient sensors, this digital biomarker of cognitive ability is easily obtainable. The usage of the reconstruction error is a strong digital biomarker for the binary classification and, to a lesser extent, for more detailed prediction of interindividual differences in cognition.
Zooming Into the Darknet: Characterizing Internet Background Radiation and its Structural Changes
Aug 05, 2021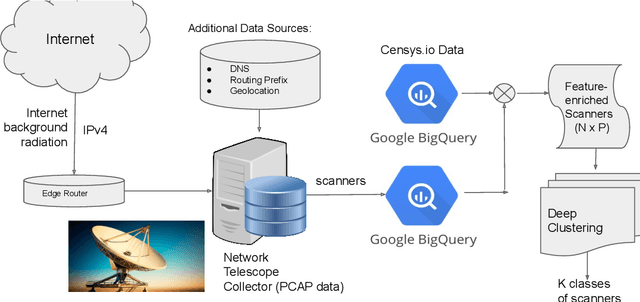

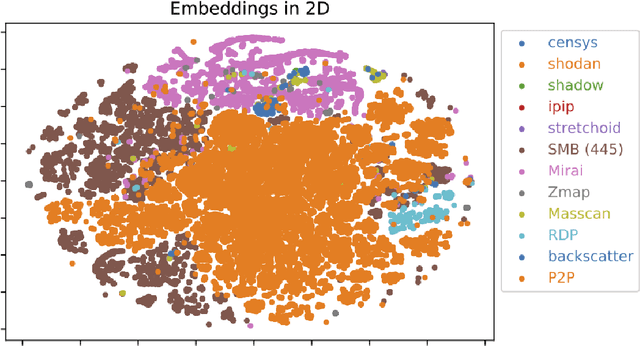

Network telescopes or "Darknets" provide a unique window into Internet-wide malicious activities associated with malware propagation, denial of service attacks, scanning performed for network reconnaissance, and others. Analyses of the resulting data can provide actionable insights to security analysts that can be used to prevent or mitigate cyber-threats. Large Darknets, however, observe millions of nefarious events on a daily basis which makes the transformation of the captured information into meaningful insights challenging. We present a novel framework for characterizing Darknet behavior and its temporal evolution aiming to address this challenge. The proposed framework: (i) Extracts a high dimensional representation of Darknet events composed of features distilled from Darknet data and other external sources; (ii) Learns, in an unsupervised fashion, an information-preserving low-dimensional representation of these events (using deep representation learning) that is amenable to clustering; (iv) Performs clustering of the scanner data in the resulting representation space and provides interpretable insights using optimal decision trees; and (v) Utilizes the clustering outcomes as "signatures" that can be used to detect structural changes in the Darknet activities. We evaluate the proposed system on a large operational Network Telescope and demonstrate its ability to detect real-world, high-impact cybersecurity incidents.
Context-LGM: Leveraging Object-Context Relation for Context-Aware Object Recognition
Oct 08, 2021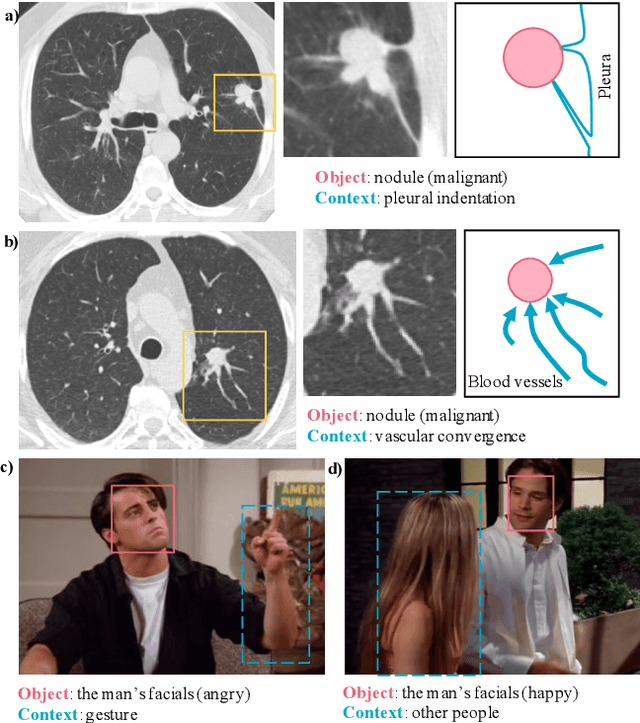
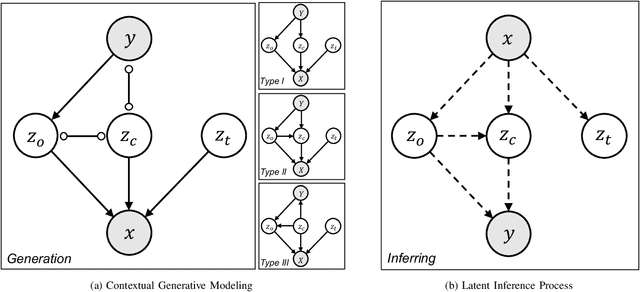
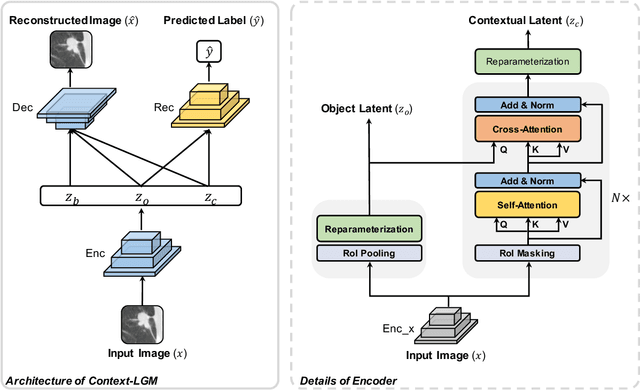
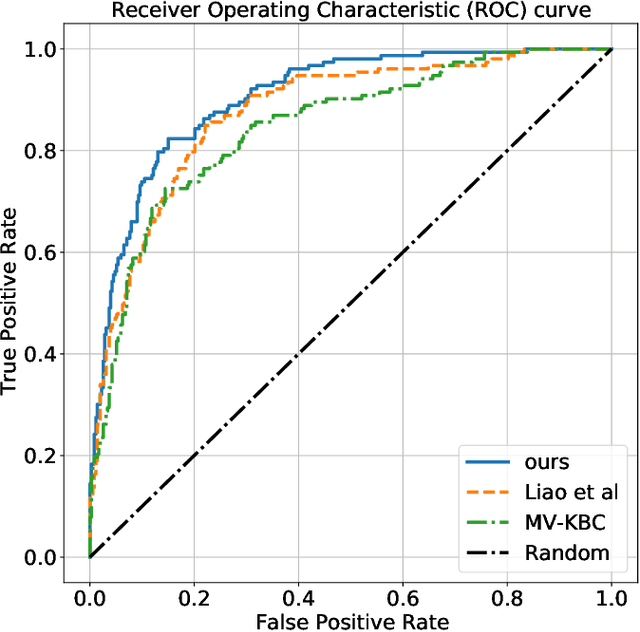
Context, as referred to situational factors related to the object of interest, can help infer the object's states or properties in visual recognition. As such contextual features are too diverse (across instances) to be annotated, existing attempts simply exploit image labels as supervision to learn them, resulting in various contextual tricks, such as features pyramid, context attention, etc. However, without carefully modeling the context's properties, especially its relation to the object, their estimated context can suffer from large inaccuracy. To amend this problem, we propose a novel Contextual Latent Generative Model (Context-LGM), which considers the object-context relation and models it in a hierarchical manner. Specifically, we firstly introduce a latent generative model with a pair of correlated latent variables to respectively model the object and context, and embed their correlation via the generative process. Then, to infer contextual features, we reformulate the objective function of Variational Auto-Encoder (VAE), where contextual features are learned as a posterior distribution conditioned on the object. Finally, to implement this contextual posterior, we introduce a Transformer that takes the object's information as a reference and locates correlated contextual factors. The effectiveness of our method is verified by state-of-the-art performance on two context-aware object recognition tasks, i.e. lung cancer prediction and emotion recognition.
Towards General Deep Leakage in Federated Learning
Oct 18, 2021

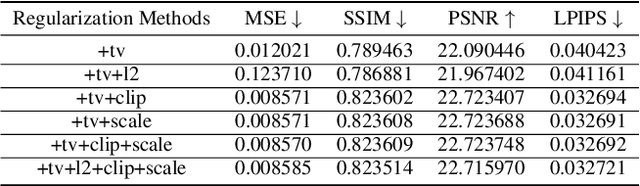
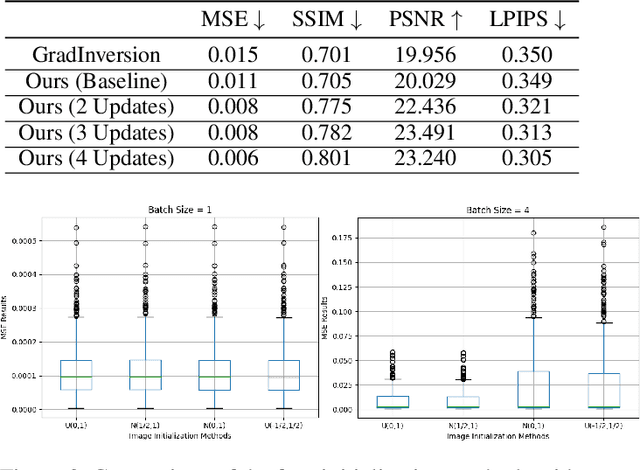
Unlike traditional central training, federated learning (FL) improves the performance of the global model by sharing and aggregating local models rather than local data to protect the users' privacy. Although this training approach appears secure, some research has demonstrated that an attacker can still recover private data based on the shared gradient information. This on-the-fly reconstruction attack deserves to be studied in depth because it can occur at any stage of training, whether at the beginning or at the end of model training; no relevant dataset is required and no additional models need to be trained. We break through some unrealistic assumptions and limitations to apply this reconstruction attack in a broader range of scenarios. We propose methods that can reconstruct the training data from shared gradients or weights, corresponding to the FedSGD and FedAvg usage scenarios, respectively. We propose a zero-shot approach to restore labels even if there are duplicate labels in the batch. We study the relationship between the label and image restoration. We find that image restoration fails even if there is only one incorrectly inferred label in the batch; we also find that when batch images have the same label, the corresponding image is restored as a fusion of that class of images. Our approaches are evaluated on classic image benchmarks, including CIFAR-10 and ImageNet. The batch size, image quality, and the adaptability of the label distribution of our approach exceed those of GradInversion, the state-of-the-art.
Information Theory: A Tutorial Introduction
Feb 20, 2018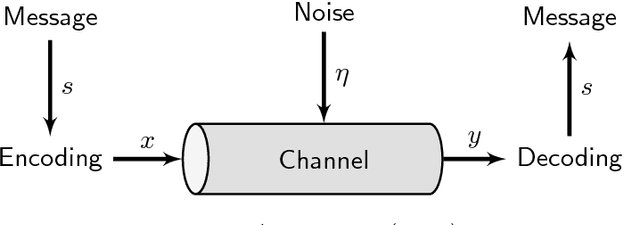
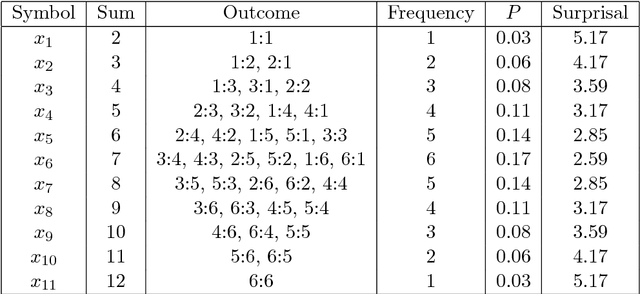
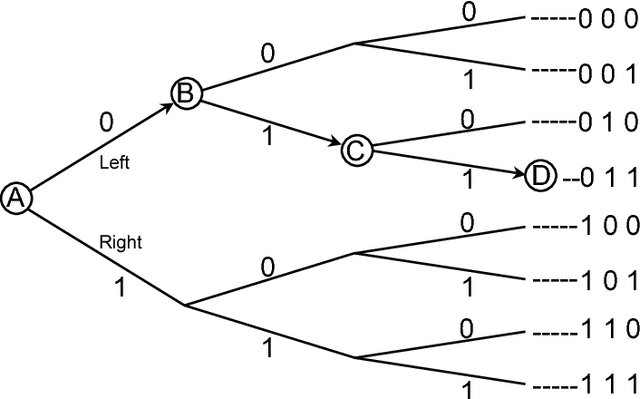
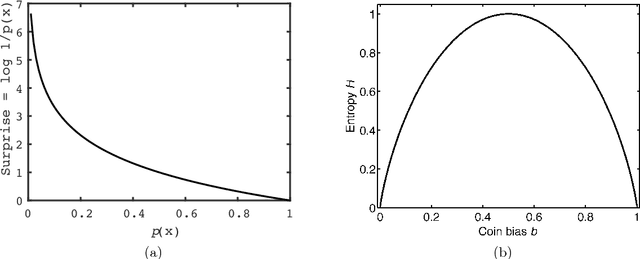
Shannon's mathematical theory of communication defines fundamental limits on how much information can be transmitted between the different components of any man-made or biological system. This paper is an informal but rigorous introduction to the main ideas implicit in Shannon's theory. An annotated reading list is provided for further reading.