 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Momentum Centering and Asynchronous Update for Adaptive Gradient Methods
Oct 11, 2021

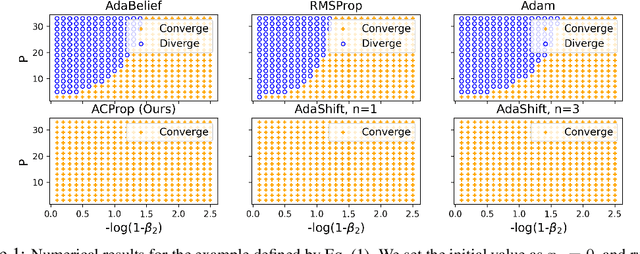
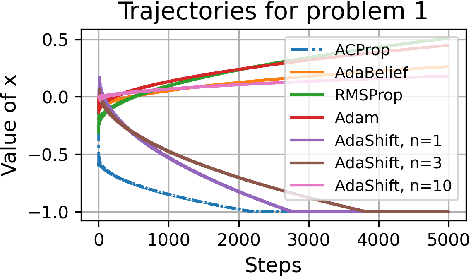
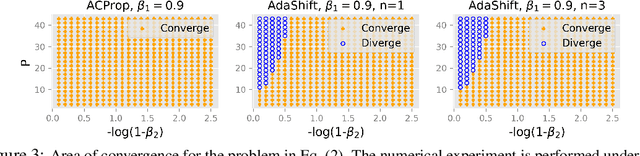
We propose ACProp (Asynchronous-centering-Prop), an adaptive optimizer which combines centering of second momentum and asynchronous update (e.g. for $t$-th update, denominator uses information up to step $t-1$, while numerator uses gradient at $t$-th step). ACProp has both strong theoretical properties and empirical performance. With the example by Reddi et al. (2018), we show that asynchronous optimizers (e.g. AdaShift, ACProp) have weaker convergence condition than synchronous optimizers (e.g. Adam, RMSProp, AdaBelief); within asynchronous optimizers, we show that centering of second momentum further weakens the convergence condition. We demonstrate that ACProp has a convergence rate of $O(\frac{1}{\sqrt{T}})$ for the stochastic non-convex case, which matches the oracle rate and outperforms the $O(\frac{logT}{\sqrt{T}})$ rate of RMSProp and Adam. We validate ACProp in extensive empirical studies: ACProp outperforms both SGD and other adaptive optimizers in image classification with CNN, and outperforms well-tuned adaptive optimizers in the training of various GAN models, reinforcement learning and transformers. To sum up, ACProp has good theoretical properties including weak convergence condition and optimal convergence rate, and strong empirical performance including good generalization like SGD and training stability like Adam.
Multi-frame Joint Enhancement for Early Interlaced Videos
Sep 29, 2021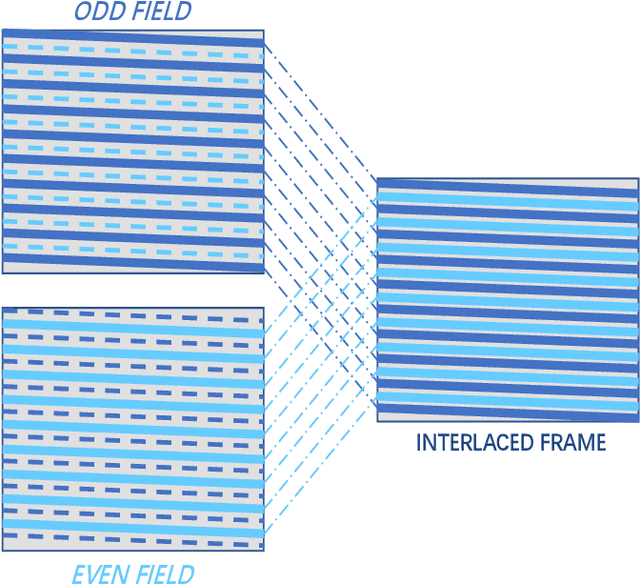


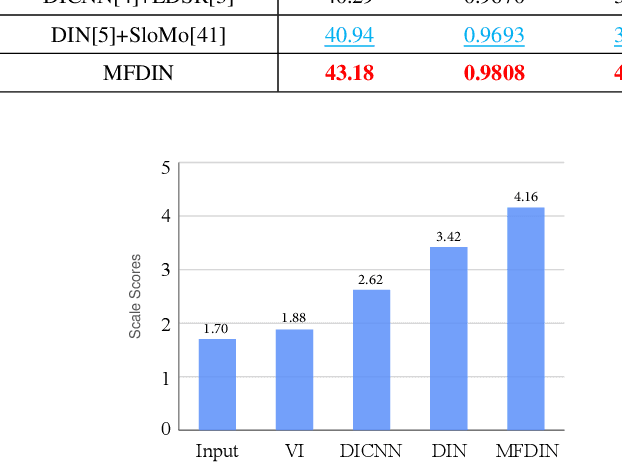
Early interlaced videos usually contain multiple and interlacing and complex compression artifacts, which significantly reduce the visual quality. Although the high-definition reconstruction technology for early videos has made great progress in recent years, related research on deinterlacing is still lacking. Traditional methods mainly focus on simple interlacing mechanism, and cannot deal with the complex artifacts in real-world early videos. Recent interlaced video reconstruction deep deinterlacing models only focus on single frame, while neglecting important temporal information. Therefore, this paper proposes a multiframe deinterlacing network joint enhancement network for early interlaced videos that consists of three modules, i.e., spatial vertical interpolation module, temporal alignment and fusion module, and final refinement module. The proposed method can effectively remove the complex artifacts in early videos by using temporal redundancy of multi-fields. Experimental results demonstrate that the proposed method can recover high quality results for both synthetic dataset and real-world early interlaced videos.
Protecting gender and identity with disentangled speech representations
Apr 22, 2021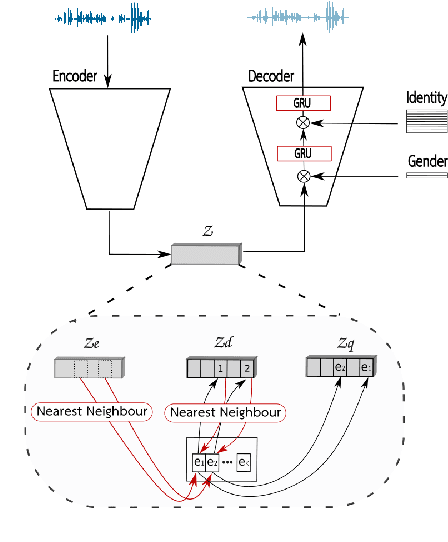
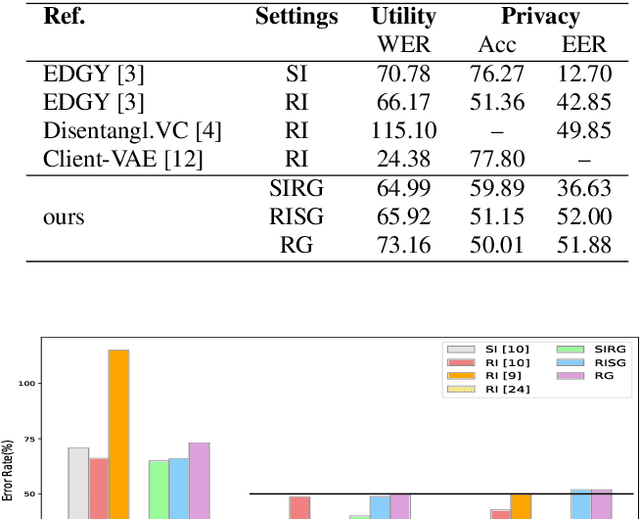
Besides its linguistic content, our speech is rich in biometric information that can be inferred by classifiers. Learning privacy-preserving representations for speech signals enables downstream tasks without sharing unnecessary, private information about an individual. In this paper, we show that protecting gender information in speech is more effective than modelling speaker-identity information only when generating a non-sensitive representation of speech. Our method relies on reconstructing speech by decoding linguistic content along with gender information using a variational autoencoder. Specifically, we exploit disentangled representation learning to encode information about different attributes into separate subspaces that can be factorised independently. We present a novel way to encode gender information and disentangle two sensitive biometric identifiers, namely gender and identity, in a privacy-protecting setting. Experiments on the LibriSpeech dataset show that gender recognition and speaker verification can be reduced to a random guess, protecting against classification-based attacks, while maintaining the utility of the signal for speech recognition.
Experimental Study on the Imitation of the Human Neck-and-Eye Pose Using the 3-DOF Agile Eye Parallel Robot Based on a Deep Neural Network Approach
Oct 31, 2021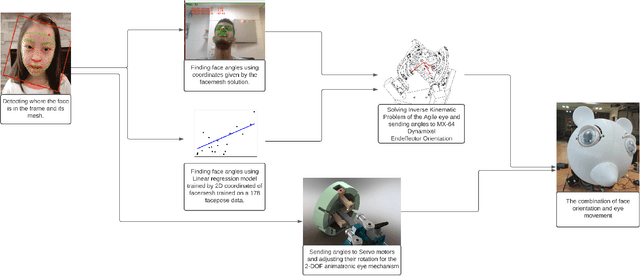

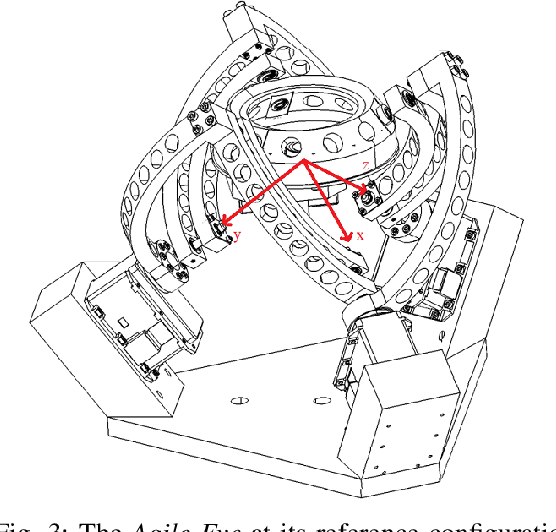
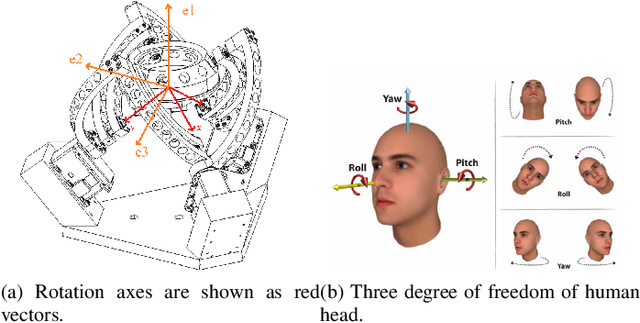
In this paper, a method to mimic a human face and eyes is proposed which can be regarded as a combination of computer vision techniques and neural network concepts. From a mechanical standpoint, a 3-DOF spherical parallel robot is used which imitates the human face movement. In what concerns eye movement, a 2-DOF mechanism is attached to the end-effector of the 3-DOF spherical parallel mechanism. In order to have robust and reliable results for the imitation, meaningful information should be extracted from the face mesh for obtaining the pose of a face, i.e., the roll, yaw, and pitch angles. To this end, two methods are proposed where each of them has its own pros and cons. The first method consists in resorting to the so-called Mediapipe library which is a machine learning solution for high-fidelity body pose tracking, introduced by Google. As the second method, a model is trained by a linear regression model for a gathered dataset of face pictures in different poses. In addition, a 3-DOF Agile Eye parallel robot is utilized to show the ability of this robot to be used as a system which is similar to a human neck for performing a 3-DOF rotational motion pattern. Furthermore, a 3D printed face and a 2-DOF eye mechanism are fabricated to display the whole system more stylish way. Experiments on this platform demonstrate the effectiveness of the proposed methods for tracking the human neck and eye movement.
Hindsight Value Function for Variance Reduction in Stochastic Dynamic Environment
Jul 26, 2021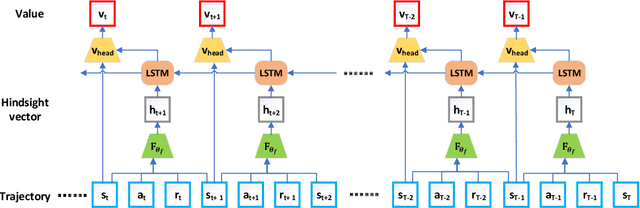
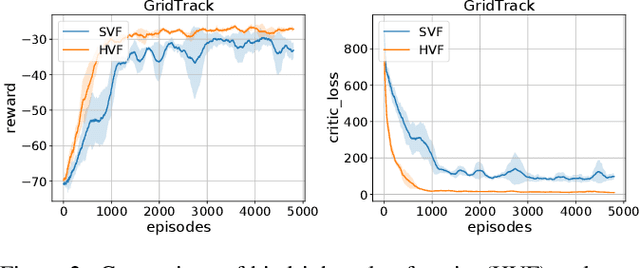
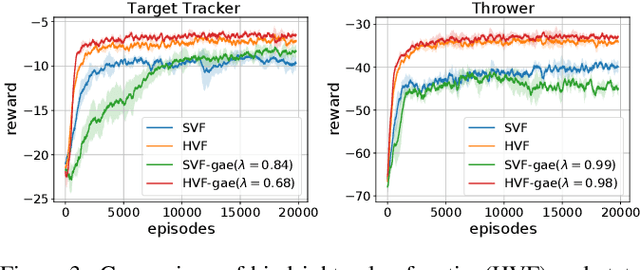
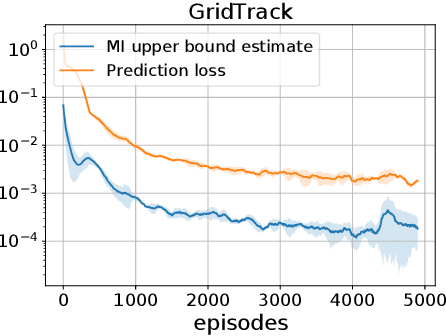
Policy gradient methods are appealing in deep reinforcement learning but suffer from high variance of gradient estimate. To reduce the variance, the state value function is applied commonly. However, the effect of the state value function becomes limited in stochastic dynamic environments, where the unexpected state dynamics and rewards will increase the variance. In this paper, we propose to replace the state value function with a novel hindsight value function, which leverages the information from the future to reduce the variance of the gradient estimate for stochastic dynamic environments. Particularly, to obtain an ideally unbiased gradient estimate, we propose an information-theoretic approach, which optimizes the embeddings of the future to be independent of previous actions. In our experiments, we apply the proposed hindsight value function in stochastic dynamic environments, including discrete-action environments and continuous-action environments. Compared with the standard state value function, the proposed hindsight value function consistently reduces the variance, stabilizes the training, and improves the eventual policy.
Multi-Echo LiDAR for 3D Object Detection
Jul 23, 2021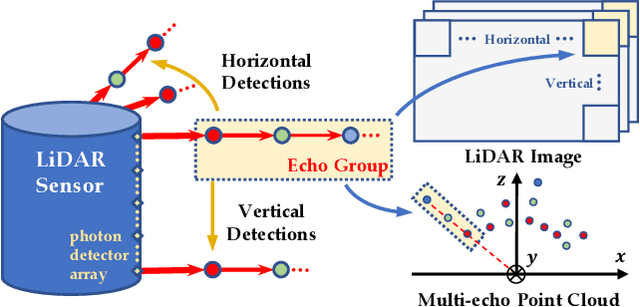
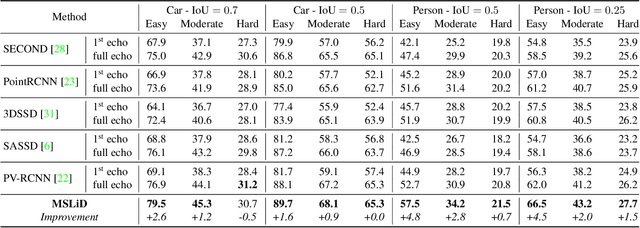
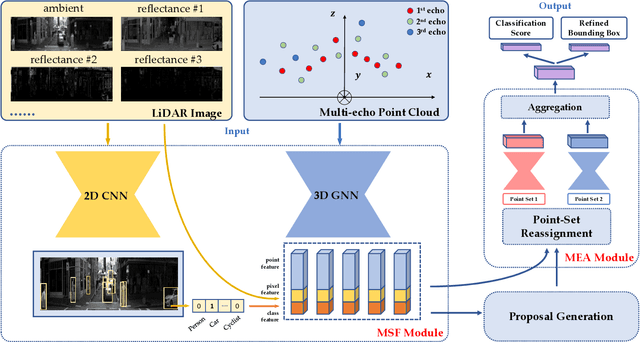
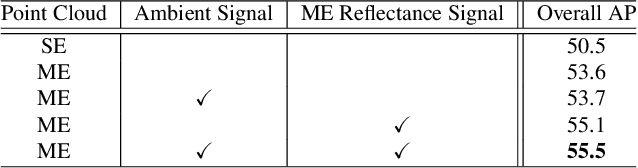
LiDAR sensors can be used to obtain a wide range of measurement signals other than a simple 3D point cloud, and those signals can be leveraged to improve perception tasks like 3D object detection. A single laser pulse can be partially reflected by multiple objects along its path, resulting in multiple measurements called echoes. Multi-echo measurement can provide information about object contours and semi-transparent surfaces which can be used to better identify and locate objects. LiDAR can also measure surface reflectance (intensity of laser pulse return), as well as ambient light of the scene (sunlight reflected by objects). These signals are already available in commercial LiDAR devices but have not been used in most LiDAR-based detection models. We present a 3D object detection model which leverages the full spectrum of measurement signals provided by LiDAR. First, we propose a multi-signal fusion (MSF) module to combine (1) the reflectance and ambient features extracted with a 2D CNN, and (2) point cloud features extracted using a 3D graph neural network (GNN). Second, we propose a multi-echo aggregation (MEA) module to combine the information encoded in different set of echo points. Compared with traditional single echo point cloud methods, our proposed Multi-Signal LiDAR Detector (MSLiD) extracts richer context information from a wider range of sensing measurements and achieves more accurate 3D object detection. Experiments show that by incorporating the multi-modality of LiDAR, our method outperforms the state-of-the-art by up to 9.1%.
Developmental Stage Classification of Embryos Using Two-Stream Neural Network with Linear-Chain Conditional Random Field
Jul 13, 2021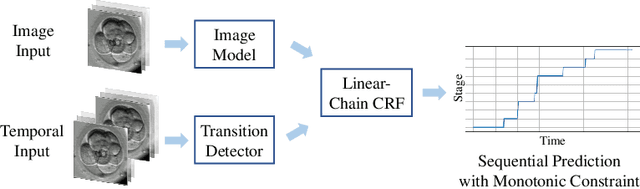
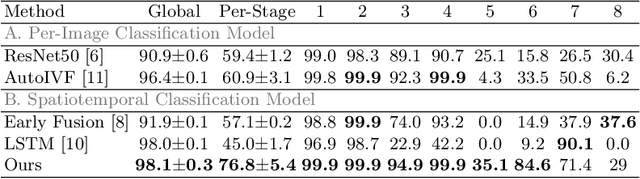

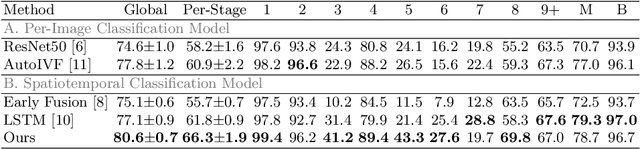
The developmental process of embryos follows a monotonic order. An embryo can progressively cleave from one cell to multiple cells and finally transform to morula and blastocyst. For time-lapse videos of embryos, most existing developmental stage classification methods conduct per-frame predictions using an image frame at each time step. However, classification using only images suffers from overlapping between cells and imbalance between stages. Temporal information can be valuable in addressing this problem by capturing movements between neighboring frames. In this work, we propose a two-stream model for developmental stage classification. Unlike previous methods, our two-stream model accepts both temporal and image information. We develop a linear-chain conditional random field (CRF) on top of neural network features extracted from the temporal and image streams to make use of both modalities. The linear-chain CRF formulation enables tractable training of global sequential models over multiple frames while also making it possible to inject monotonic development order constraints into the learning process explicitly. We demonstrate our algorithm on two time-lapse embryo video datasets: i) mouse and ii) human embryo datasets. Our method achieves 98.1 % and 80.6 % for mouse and human embryo stage classification, respectively. Our approach will enable more profound clinical and biological studies and suggests a new direction for developmental stage classification by utilizing temporal information.
Chaos as an interpretable benchmark for forecasting and data-driven modelling
Oct 11, 2021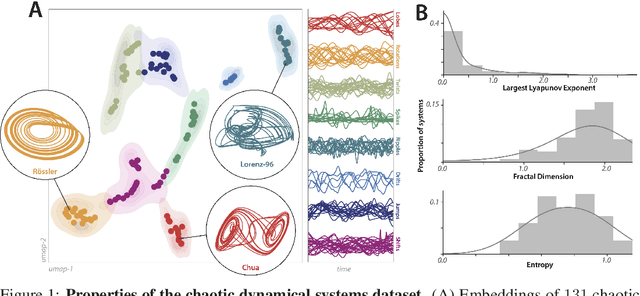

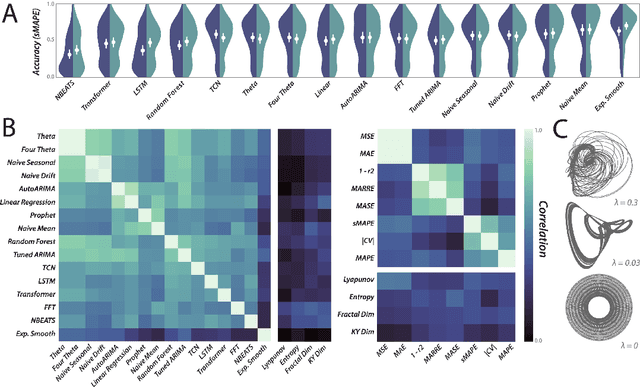
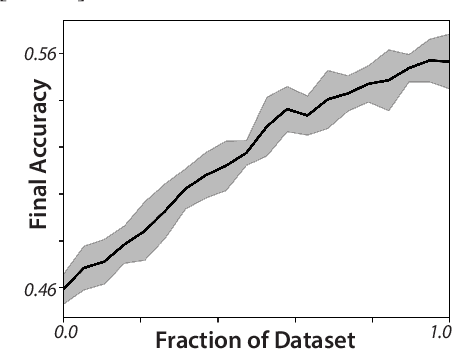
The striking fractal geometry of strange attractors underscores the generative nature of chaos: like probability distributions, chaotic systems can be repeatedly measured to produce arbitrarily-detailed information about the underlying attractor. Chaotic systems thus pose a unique challenge to modern statistical learning techniques, while retaining quantifiable mathematical properties that make them controllable and interpretable as benchmarks. Here, we present a growing database currently comprising 131 known chaotic dynamical systems spanning fields such as astrophysics, climatology, and biochemistry. Each system is paired with precomputed multivariate and univariate time series. Our dataset has comparable scale to existing static time series databases; however, our systems can be re-integrated to produce additional datasets of arbitrary length and granularity. Our dataset is annotated with known mathematical properties of each system, and we perform feature analysis to broadly categorize the diverse dynamics present across the collection. Chaotic systems inherently challenge forecasting models, and across extensive benchmarks we correlate forecasting performance with the degree of chaos present. We also exploit the unique generative properties of our dataset in several proof-of-concept experiments: surrogate transfer learning to improve time series classification, importance sampling to accelerate model training, and benchmarking symbolic regression algorithms.
* 10 pages, 4 figures, plus appendices
The Commodities News Corpus: A Resource forUnderstanding Commodity News Better
May 23, 2021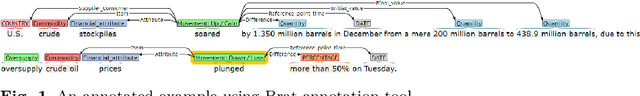
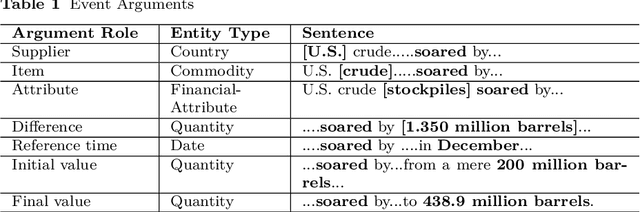

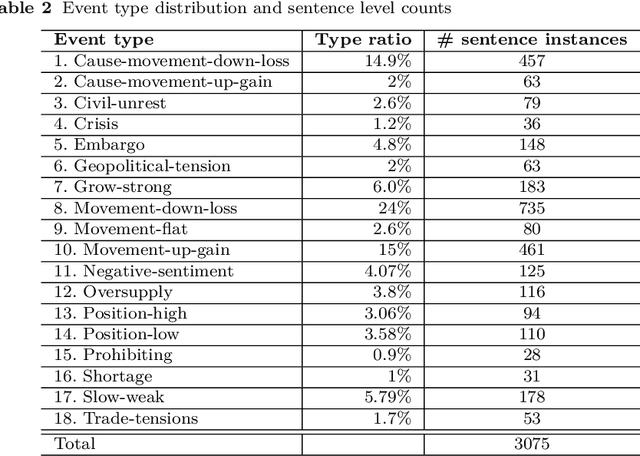
Commodity News contains a wealth of information such as sum-mary of the recent commodity price movement and notable events that led tothe movement. Through event extraction, useful information extracted fromcommodity news is extremely useful in mining for causal relation betweenevents and commodity price movement, which can be used for commodity priceprediction. To facilitate the future research, we introduce a new dataset withthe following information identified and annotated: (i) entities (both nomi-nal and named), (ii) events (trigger words and argument roles), (iii) eventmetadata: modality, polarity and intensity and (iv) event-event relations.