 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Polarity in the Classroom: A Case Study Leveraging Peer Sentiment Toward Scalable Assessment
Aug 02, 2021
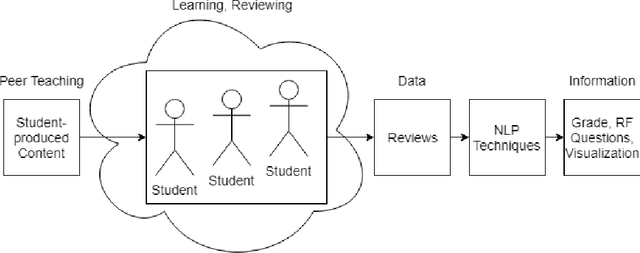

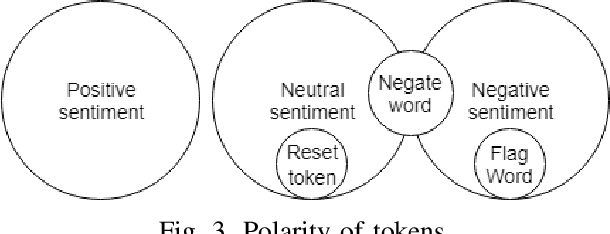
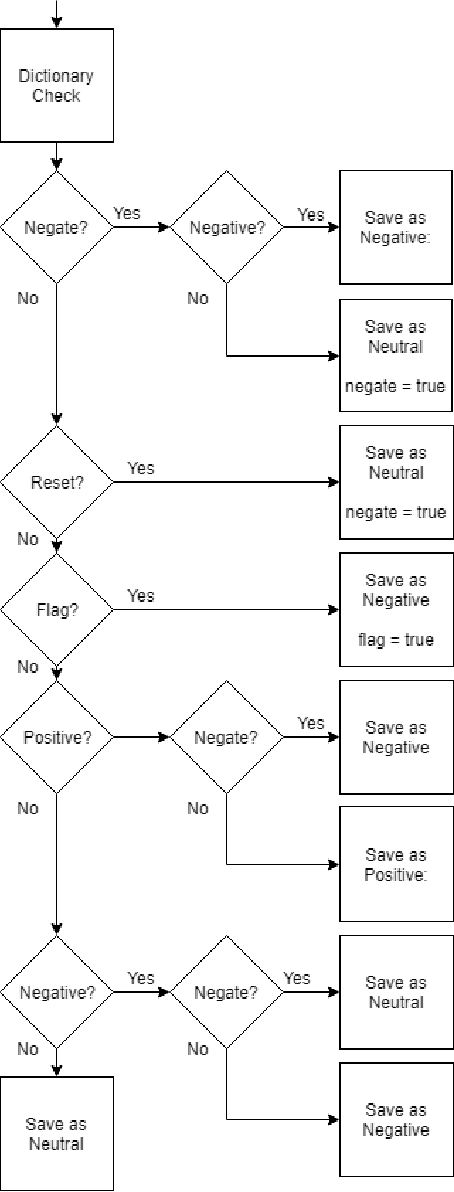
Accurately grading open-ended assignments in large or massive open online courses (MOOCs) is non-trivial. Peer review is a promising solution but can be unreliable due to few reviewers and an unevaluated review form. To date, no work has 1) leveraged sentiment analysis in the peer-review process to inform or validate grades or 2) utilized aspect extraction to craft a review form from what students actually communicated. Our work utilizes, rather than discards, student data from review form comments to deliver better information to the instructor. In this work, we detail the process by which we create our domain-dependent lexicon and aspect-informed review form as well as our entire sentiment analysis algorithm which provides a fine-grained sentiment score from text alone. We end by analyzing validity and discussing conclusions from our corpus of over 6800 peer reviews from nine courses to understand the viability of sentiment in the classroom for increasing the information from and reliability of grading open-ended assignments in large courses.
Document-level Relation Extraction as Semantic Segmentation
Jun 07, 2021
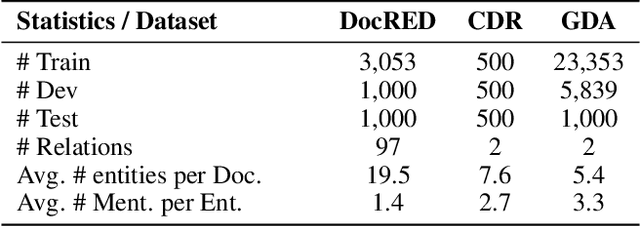
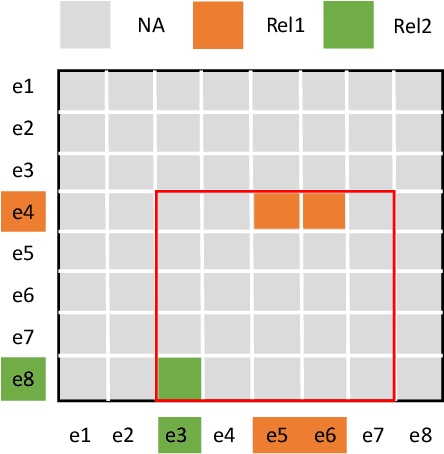
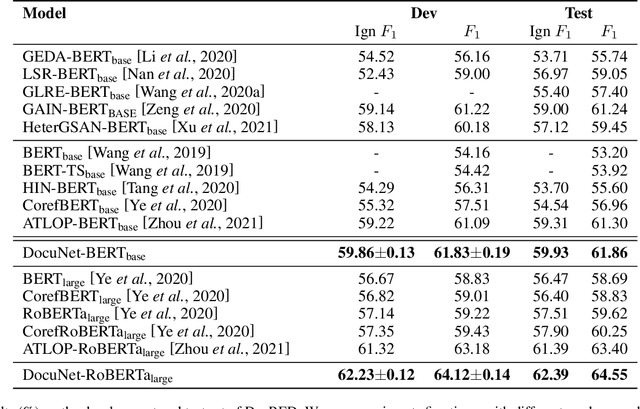
Document-level relation extraction aims to extract relations among multiple entity pairs from a document. Previously proposed graph-based or transformer-based models utilize the entities independently, regardless of global information among relational triples. This paper approaches the problem by predicting an entity-level relation matrix to capture local and global information, parallel to the semantic segmentation task in computer vision. Herein, we propose a Document U-shaped Network for document-level relation extraction. Specifically, we leverage an encoder module to capture the context information of entities and a U-shaped segmentation module over the image-style feature map to capture global interdependency among triples. Experimental results show that our approach can obtain state-of-the-art performance on three benchmark datasets DocRED, CDR, and GDA.
DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
Oct 11, 2021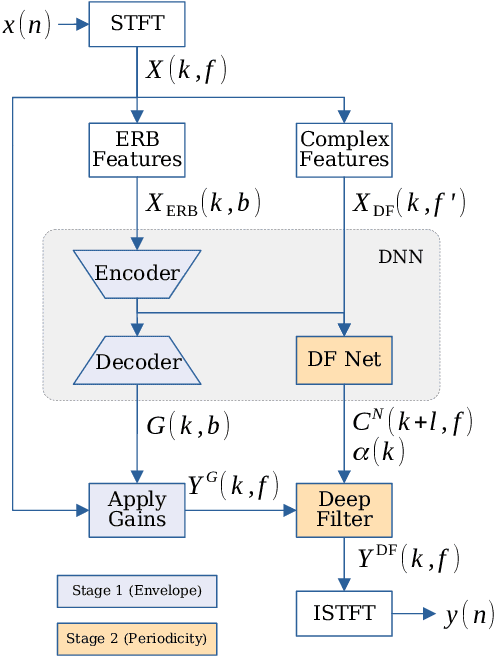
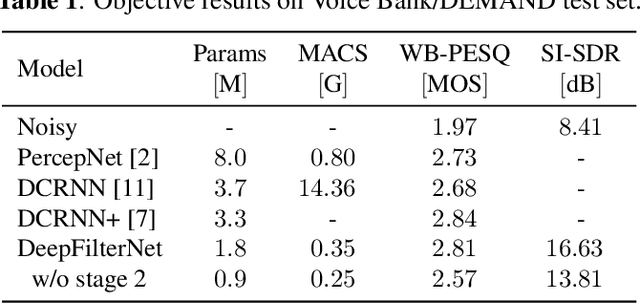
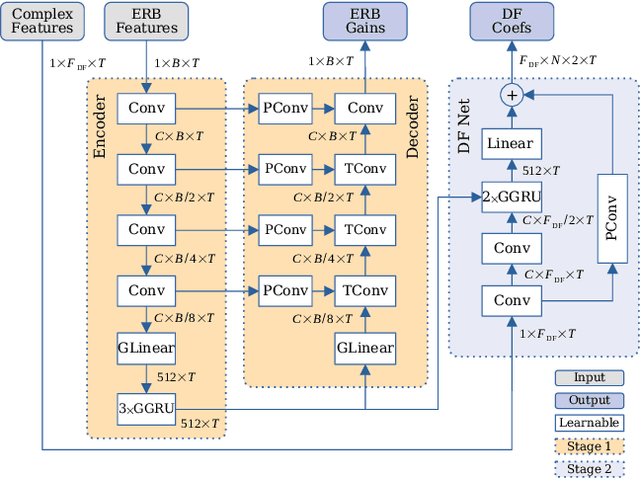
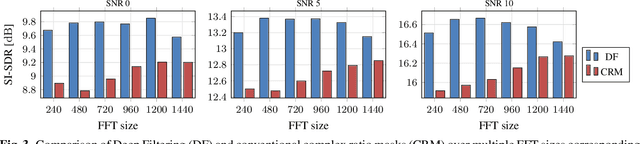
Complex-valued processing has brought deep learning-based speech enhancement and signal extraction to a new level. Typically, the process is based on a time-frequency (TF) mask which is applied to a noisy spectrogram, while complex masks (CM) are usually preferred over real-valued masks due to their ability to modify the phase. Recent work proposed to use a complex filter instead of a point-wise multiplication with a mask. This allows to incorporate information from previous and future time steps exploiting local correlations within each frequency band. In this work, we propose DeepFilterNet, a two stage speech enhancement framework utilizing deep filtering. First, we enhance the spectral envelope using ERB-scaled gains modeling the human frequency perception. The second stage employs deep filtering to enhance the periodic components of speech. Additionally to taking advantage of perceptual properties of speech, we enforce network sparsity via separable convolutions and extensive grouping in linear and recurrent layers to design a low complexity architecture. We further show that our two stage deep filtering approach outperforms complex masks over a variety of frequency resolutions and latencies and demonstrate convincing performance compared to other state-of-the-art models.
A Deep, Information-theoretic Framework for Robust Biometric Recognition
Feb 23, 2019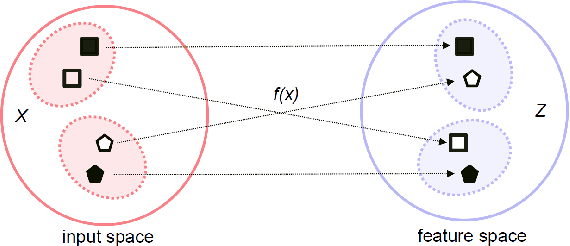

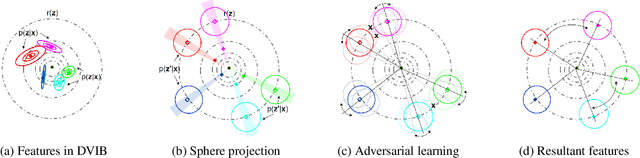

Deep neural networks (DNN) have been a de facto standard for nowadays biometric recognition solutions. A serious, but still overlooked problem in these DNN-based recognition systems is their vulnerability against adversarial attacks. Adversarial attacks can easily cause the output of a DNN system to greatly distort with only tiny changes in its input. Such distortions can potentially lead to an unexpected match between a valid biometric and a synthetic one constructed by a strategic attacker, raising security issue. In this work, we show how this issue can be resolved by learning robust biometric features through a deep, information-theoretic framework, which builds upon the recent deep variational information bottleneck method but is carefully adapted to biometric recognition tasks. Empirical evaluation demonstrates that our method not only offers stronger robustness against adversarial attacks but also provides better recognition performance over state-of-the-art approaches.
On the Optimality of Ergodic Trajectories for Information Gathering Tasks
Aug 20, 2018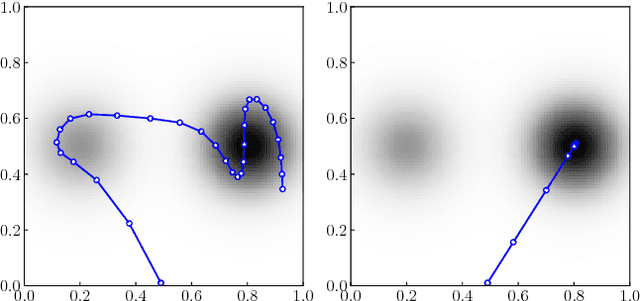
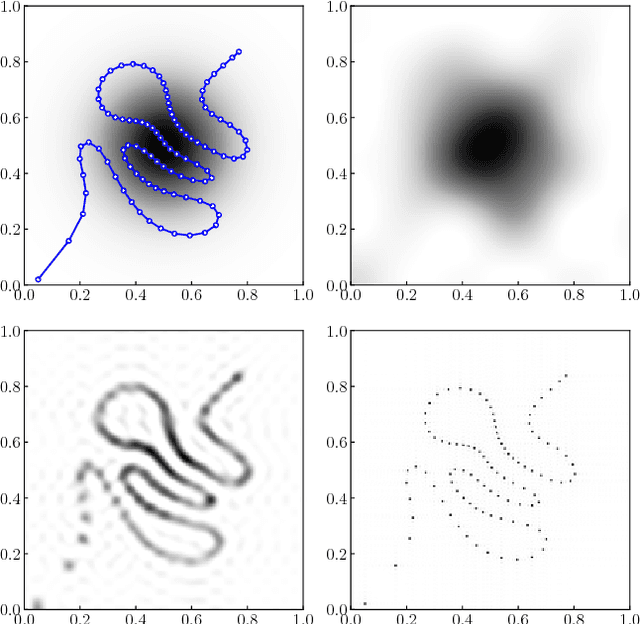
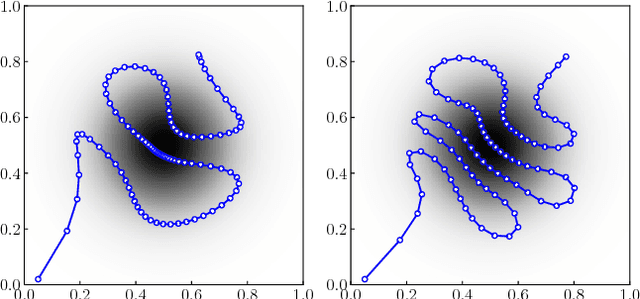
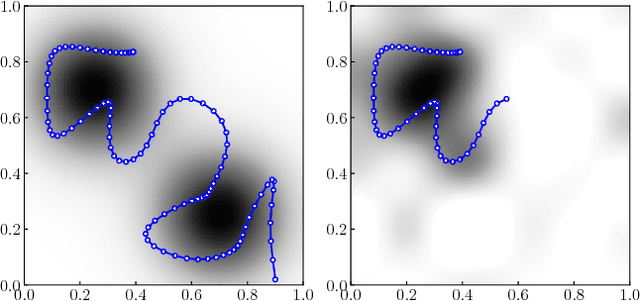
Recently, ergodic control has been suggested as a means to guide mobile sensors for information gathering tasks. In ergodic control, a mobile sensor follows a trajectory that is ergodic with respect to some information density distribution. A trajectory is ergodic if time spent in a state space region is proportional to the information density of the region. Although ergodic control has shown promising experimental results, there is little understanding of why it works or when it is optimal. In this paper, we study a problem class under which optimal information gathering trajectories are ergodic. This class relies on a submodularity assumption for repeated measurements from the same state. It is assumed that information available in a region decays linearly with time spent there. This assumption informs selection of the horizon used in ergodic trajectory generation. We support our claims with a set of experiments that demonstrate the link between ergodicity, optimal information gathering, and submodularity.
Autonomous Urban Localization and Navigation with Limited Information
Oct 09, 2018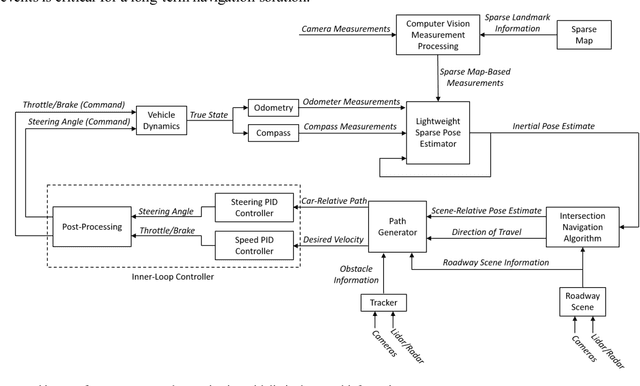
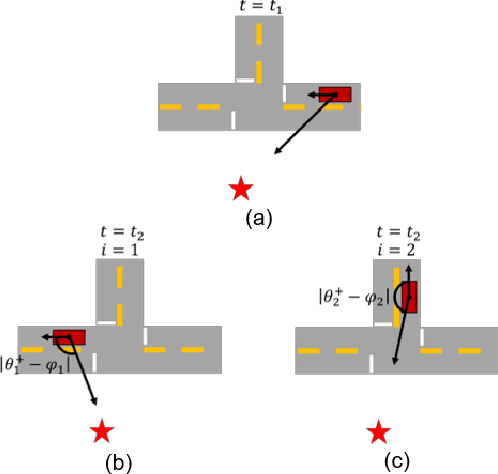
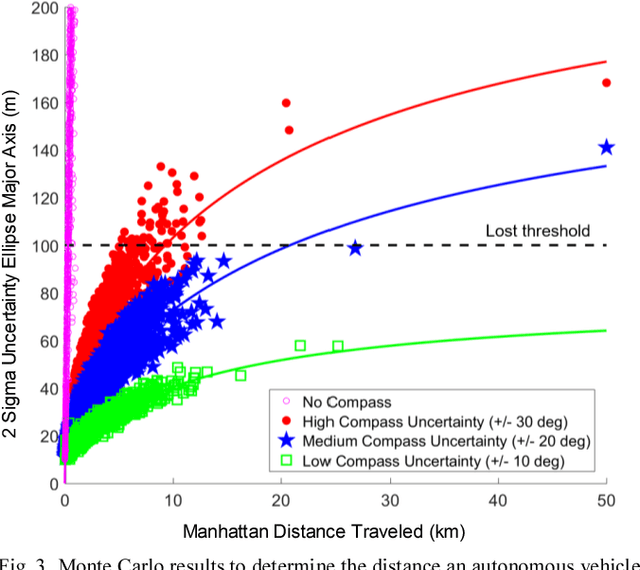
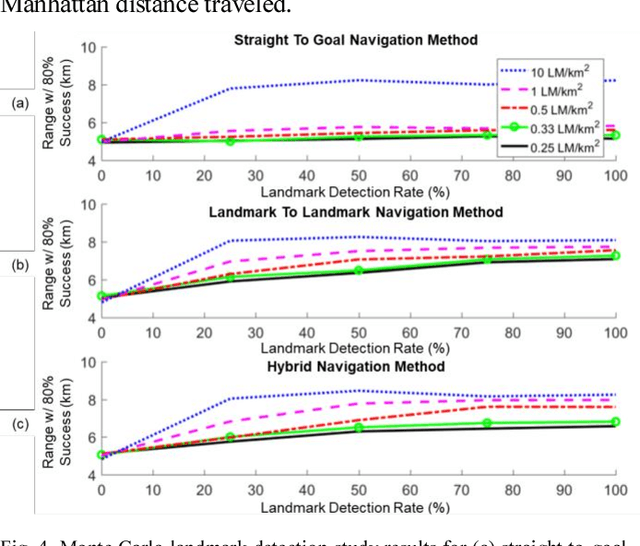
Urban environments offer a challenging scenario for autonomous driving. Globally localizing information, such as a GPS signal, can be unreliable due to signal shadowing and multipath errors. Detailed a priori maps of the environment with sufficient information for autonomous navigation typically require driving the area multiple times to collect large amounts of data, substantial post-processing on that data to obtain the map, and then maintaining updates on the map as the environment changes. This paper addresses the issue of autonomous driving in an urban environment by investigating algorithms and an architecture to enable fully functional autonomous driving with limited information. An algorithm to autonomously navigate urban roadways with little to no reliance on an a priori map or GPS is developed. Localization is performed with an extended Kalman filter with odometry, compass, and sparse landmark measurement updates. Navigation is accomplished by a compass-based navigation control law. Key results from Monte Carlo studies show success rates of urban navigation under different environmental conditions. Experiments validate the simulated results and demonstrate that, for given test conditions, an expected range can be found for a given success rate.
Momentum Centering and Asynchronous Update for Adaptive Gradient Methods
Oct 11, 2021
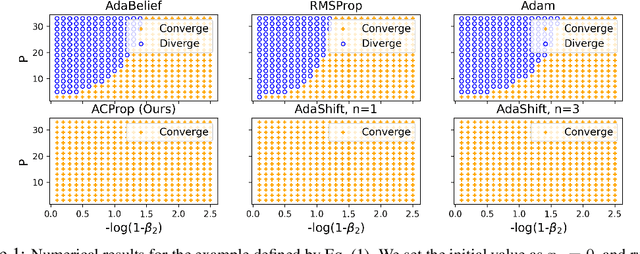
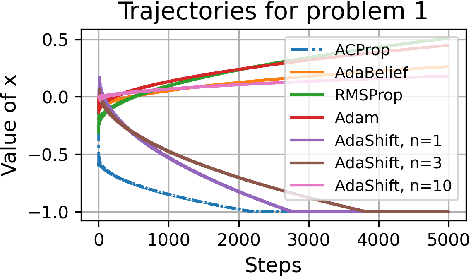
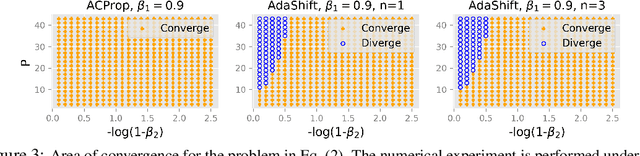
We propose ACProp (Asynchronous-centering-Prop), an adaptive optimizer which combines centering of second momentum and asynchronous update (e.g. for $t$-th update, denominator uses information up to step $t-1$, while numerator uses gradient at $t$-th step). ACProp has both strong theoretical properties and empirical performance. With the example by Reddi et al. (2018), we show that asynchronous optimizers (e.g. AdaShift, ACProp) have weaker convergence condition than synchronous optimizers (e.g. Adam, RMSProp, AdaBelief); within asynchronous optimizers, we show that centering of second momentum further weakens the convergence condition. We demonstrate that ACProp has a convergence rate of $O(\frac{1}{\sqrt{T}})$ for the stochastic non-convex case, which matches the oracle rate and outperforms the $O(\frac{logT}{\sqrt{T}})$ rate of RMSProp and Adam. We validate ACProp in extensive empirical studies: ACProp outperforms both SGD and other adaptive optimizers in image classification with CNN, and outperforms well-tuned adaptive optimizers in the training of various GAN models, reinforcement learning and transformers. To sum up, ACProp has good theoretical properties including weak convergence condition and optimal convergence rate, and strong empirical performance including good generalization like SGD and training stability like Adam.
Cross-Modal Knowledge Transfer via Inter-Modal Translation and Alignment for Affect Recognition
Aug 02, 2021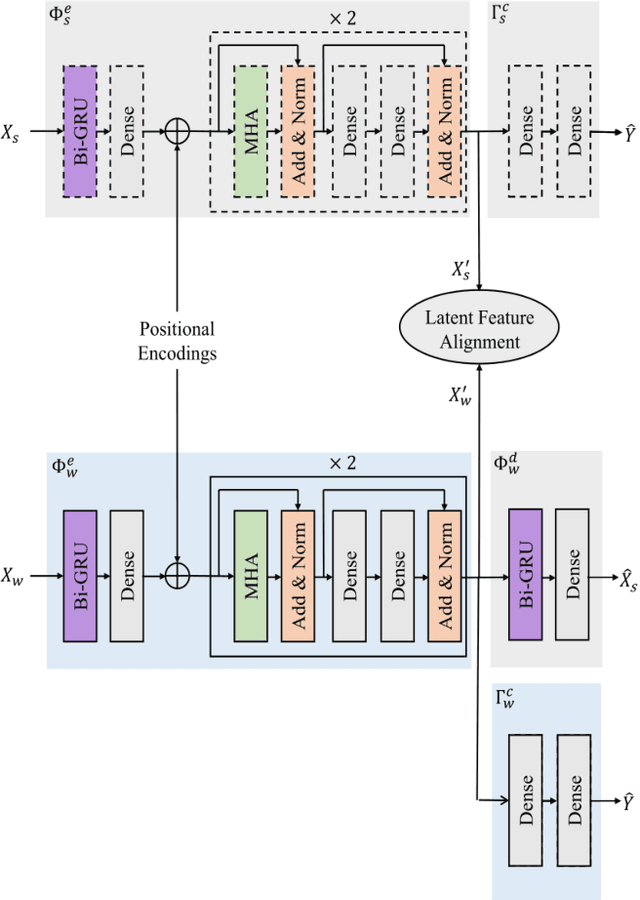
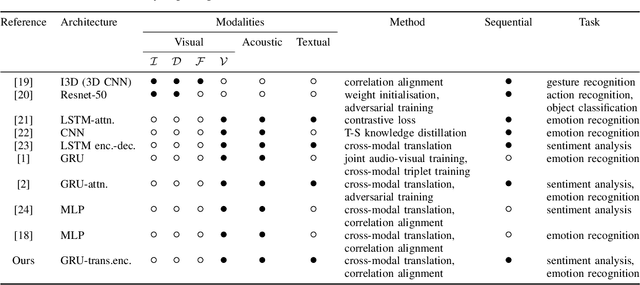
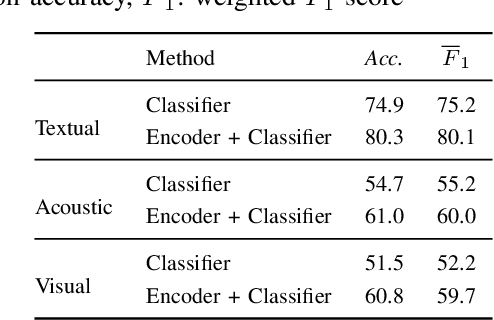
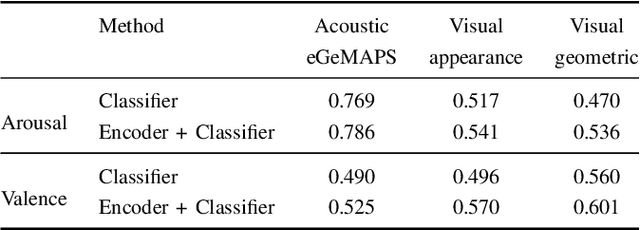
Multi-modal affect recognition models leverage complementary information in different modalities to outperform their uni-modal counterparts. However, due to the unavailability of modality-specific sensors or data, multi-modal models may not be always employable. For this reason, we aim to improve the performance of uni-modal affect recognition models by transferring knowledge from a better-performing (or stronger) modality to a weaker modality during training. Our proposed multi-modal training framework for cross-modal knowledge transfer relies on two main steps. First, an encoder-classifier model creates task-specific representations for the stronger modality. Then, cross-modal translation generates multi-modal intermediate representations, which are also aligned in the latent space with the stronger modality representations. To exploit the contextual information in temporal sequential affect data, we use Bi-GRU and transformer encoder. We validate our approach on two multi-modal affect datasets, namely CMU-MOSI for binary sentiment classification and RECOLA for dimensional emotion regression. The results show that the proposed approach consistently improves the uni-modal test-time performance of the weaker modalities.
Multi-frame Joint Enhancement for Early Interlaced Videos
Sep 29, 2021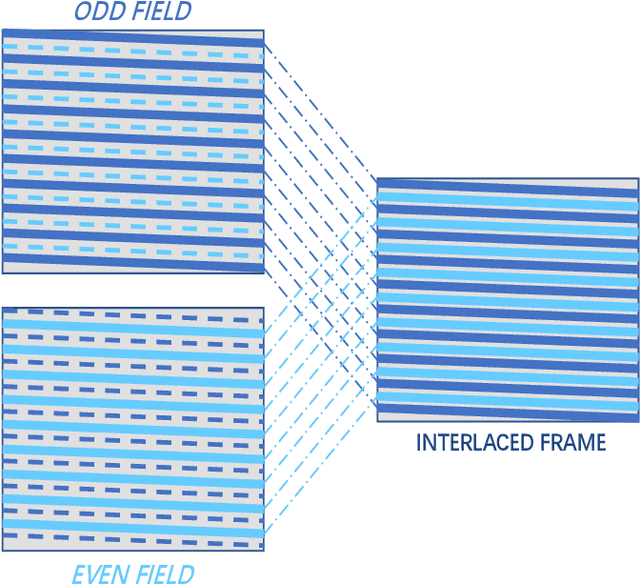


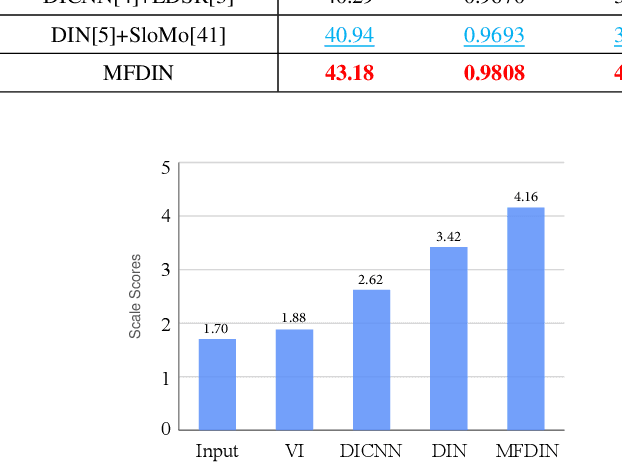
Early interlaced videos usually contain multiple and interlacing and complex compression artifacts, which significantly reduce the visual quality. Although the high-definition reconstruction technology for early videos has made great progress in recent years, related research on deinterlacing is still lacking. Traditional methods mainly focus on simple interlacing mechanism, and cannot deal with the complex artifacts in real-world early videos. Recent interlaced video reconstruction deep deinterlacing models only focus on single frame, while neglecting important temporal information. Therefore, this paper proposes a multiframe deinterlacing network joint enhancement network for early interlaced videos that consists of three modules, i.e., spatial vertical interpolation module, temporal alignment and fusion module, and final refinement module. The proposed method can effectively remove the complex artifacts in early videos by using temporal redundancy of multi-fields. Experimental results demonstrate that the proposed method can recover high quality results for both synthetic dataset and real-world early interlaced videos.
Experimental Study on the Imitation of the Human Neck-and-Eye Pose Using the 3-DOF Agile Eye Parallel Robot Based on a Deep Neural Network Approach
Oct 31, 2021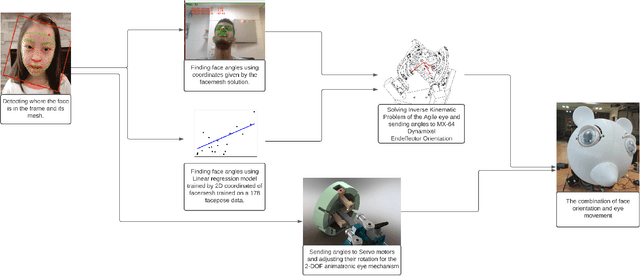

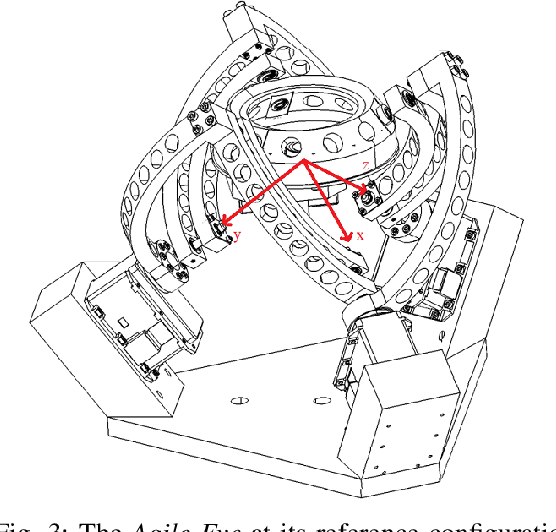
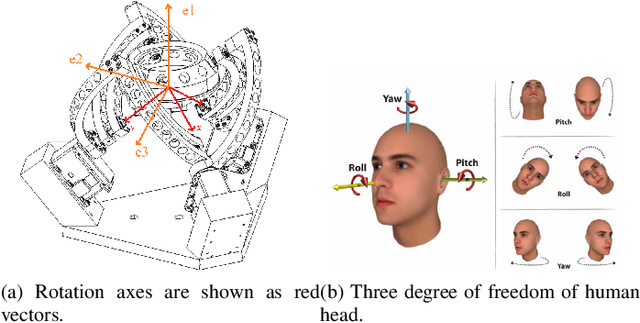
In this paper, a method to mimic a human face and eyes is proposed which can be regarded as a combination of computer vision techniques and neural network concepts. From a mechanical standpoint, a 3-DOF spherical parallel robot is used which imitates the human face movement. In what concerns eye movement, a 2-DOF mechanism is attached to the end-effector of the 3-DOF spherical parallel mechanism. In order to have robust and reliable results for the imitation, meaningful information should be extracted from the face mesh for obtaining the pose of a face, i.e., the roll, yaw, and pitch angles. To this end, two methods are proposed where each of them has its own pros and cons. The first method consists in resorting to the so-called Mediapipe library which is a machine learning solution for high-fidelity body pose tracking, introduced by Google. As the second method, a model is trained by a linear regression model for a gathered dataset of face pictures in different poses. In addition, a 3-DOF Agile Eye parallel robot is utilized to show the ability of this robot to be used as a system which is similar to a human neck for performing a 3-DOF rotational motion pattern. Furthermore, a 3D printed face and a 2-DOF eye mechanism are fabricated to display the whole system more stylish way. Experiments on this platform demonstrate the effectiveness of the proposed methods for tracking the human neck and eye movement.