 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Secure Multi-Party Computation based Privacy Preserving Data Analysis in Healthcare IoT Systems
Sep 29, 2021
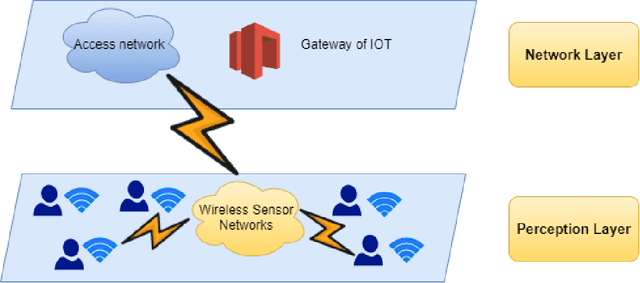
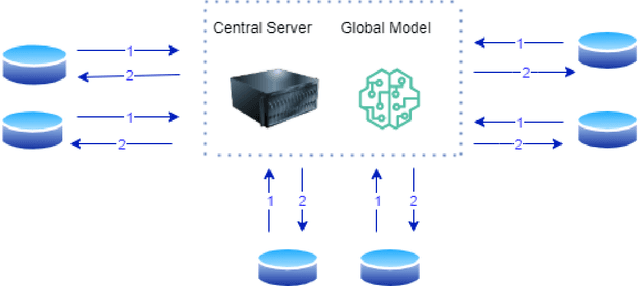
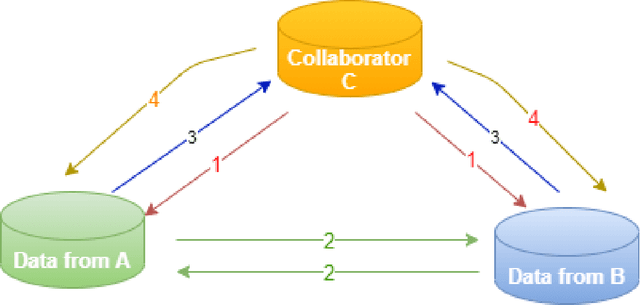
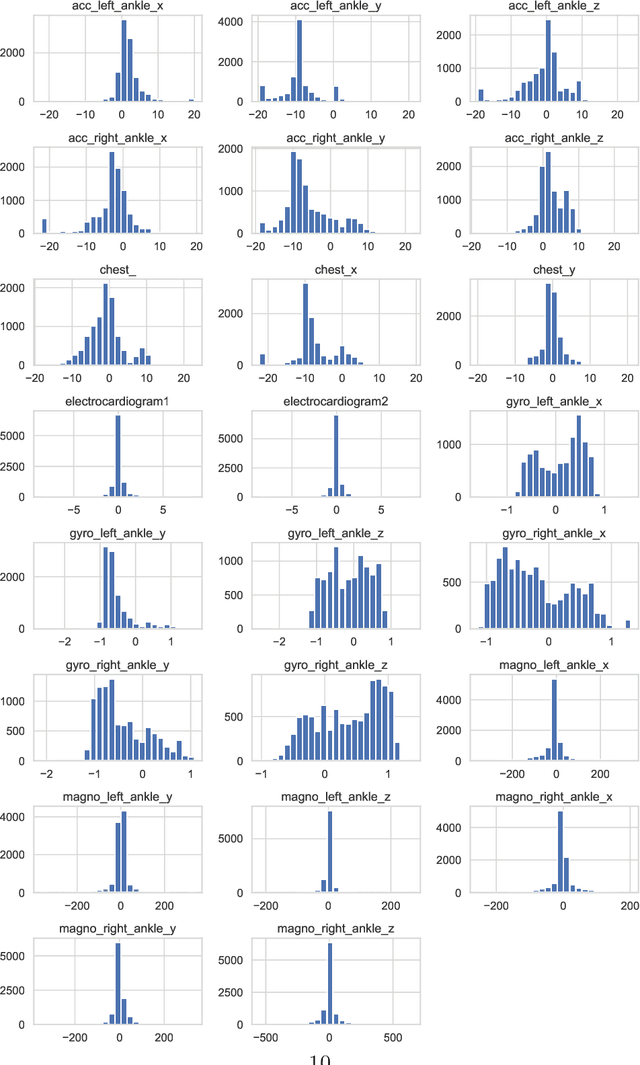
Recently, many innovations have been experienced in healthcare by rapidly growing Internet-of-Things (IoT) technology that provides significant developments and facilities in the health sector and improves daily human life. The IoT bridges people, information technology and speed up shopping. For these reasons, IoT technology has started to be used on a large scale. Thanks to the use of IoT technology in health services, chronic disease monitoring, health monitoring, rapid intervention, early diagnosis and treatment, etc. facilitates the delivery of health services. However, the data transferred to the digital environment pose a threat of privacy leakage. Unauthorized persons have used them, and there have been malicious attacks on the health and privacy of individuals. In this study, it is aimed to propose a model to handle the privacy problems based on federated learning. Besides, we apply secure multi party computation. Our proposed model presents an extensive privacy and data analysis and achieve high performance.
DONet: Learning Category-Level 6D Object Pose and Size Estimation from Depth Observation
Jun 27, 2021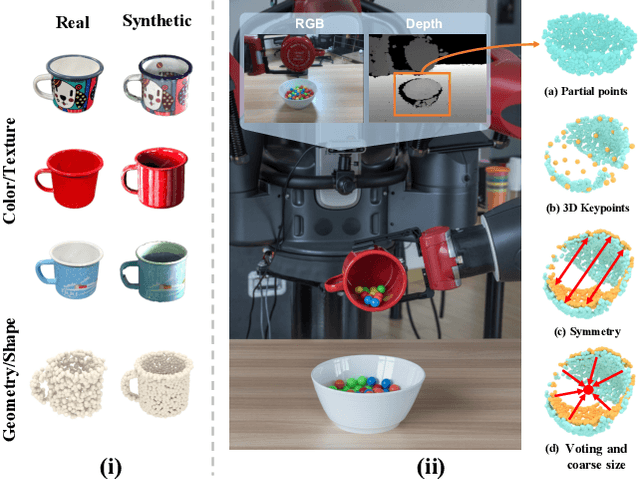
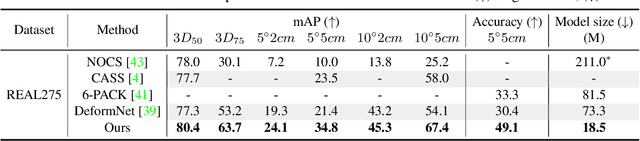
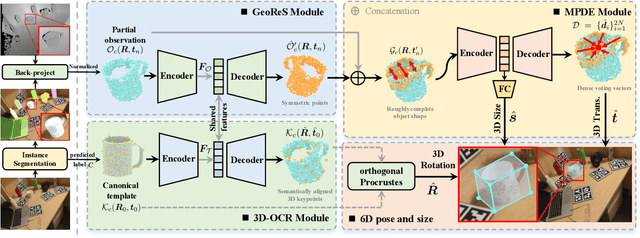
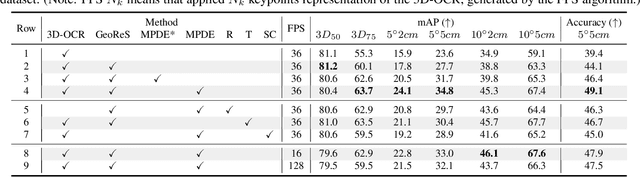
We propose a method of Category-level 6D Object Pose and Size Estimation (COPSE) from a single depth image, without external pose-annotated real-world training data. While previous works exploit visual cues in RGB(D) images, our method makes inferences based on the rich geometric information of the object in the depth channel alone. Essentially, our framework explores such geometric information by learning the unified 3D Orientation-Consistent Representations (3D-OCR) module, and further enforced by the property of Geometry-constrained Reflection Symmetry (GeoReS) module. The magnitude information of object size and the center point is finally estimated by Mirror-Paired Dimensional Estimation (MPDE) module. Extensive experiments on the category-level NOCS benchmark demonstrate that our framework competes with state-of-the-art approaches that require labeled real-world images. We also deploy our approach to a physical Baxter robot to perform manipulation tasks on unseen but category-known instances, and the results further validate the efficacy of our proposed model. Our videos are available in the supplementary material.
SimulLR: Simultaneous Lip Reading Transducer with Attention-Guided Adaptive Memory
Aug 31, 2021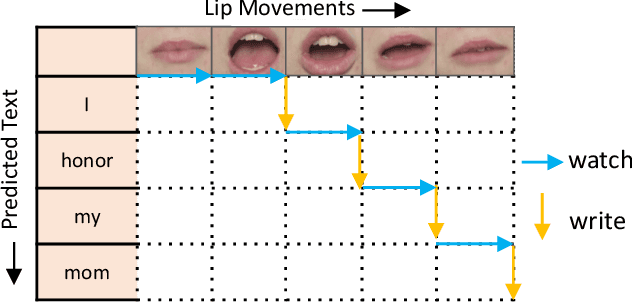
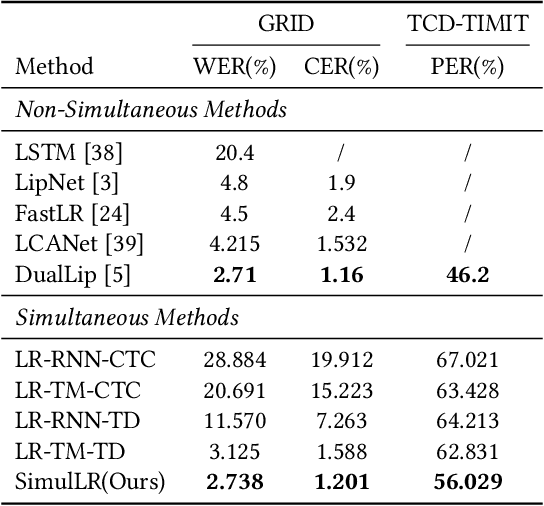
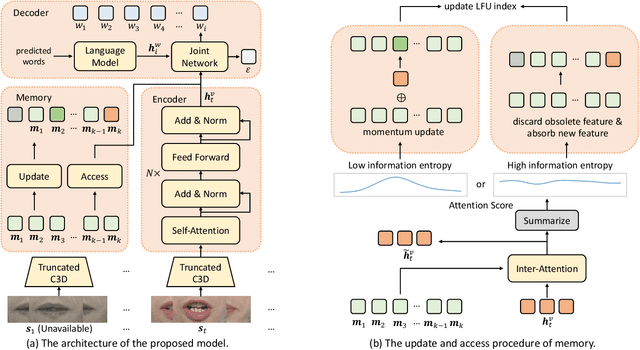
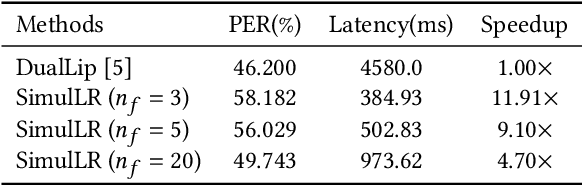
Lip reading, aiming to recognize spoken sentences according to the given video of lip movements without relying on the audio stream, has attracted great interest due to its application in many scenarios. Although prior works that explore lip reading have obtained salient achievements, they are all trained in a non-simultaneous manner where the predictions are generated requiring access to the full video. To breakthrough this constraint, we study the task of simultaneous lip reading and devise SimulLR, a simultaneous lip Reading transducer with attention-guided adaptive memory from three aspects: (1) To address the challenge of monotonic alignments while considering the syntactic structure of the generated sentences under simultaneous setting, we build a transducer-based model and design several effective training strategies including CTC pre-training, model warm-up and curriculum learning to promote the training of the lip reading transducer. (2) To learn better spatio-temporal representations for simultaneous encoder, we construct a truncated 3D convolution and time-restricted self-attention layer to perform the frame-to-frame interaction within a video segment containing fixed number of frames. (3) The history information is always limited due to the storage in real-time scenarios, especially for massive video data. Therefore, we devise a novel attention-guided adaptive memory to organize semantic information of history segments and enhance the visual representations with acceptable computation-aware latency. The experiments show that the SimulLR achieves the translation speedup 9.10$\times$ compared with the state-of-the-art non-simultaneous methods, and also obtains competitive results, which indicates the effectiveness of our proposed methods.
Attention W-Net: Improved Skip Connections for better Representations
Oct 17, 2021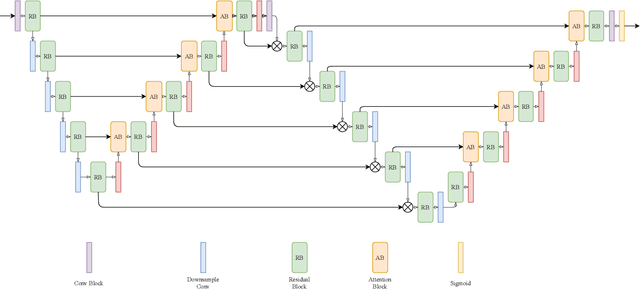

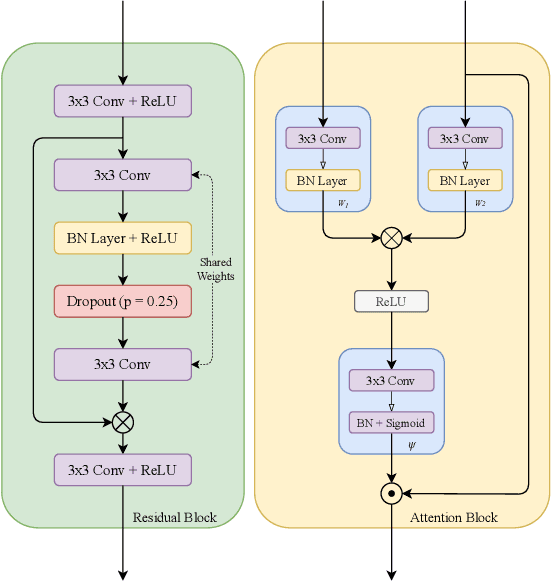
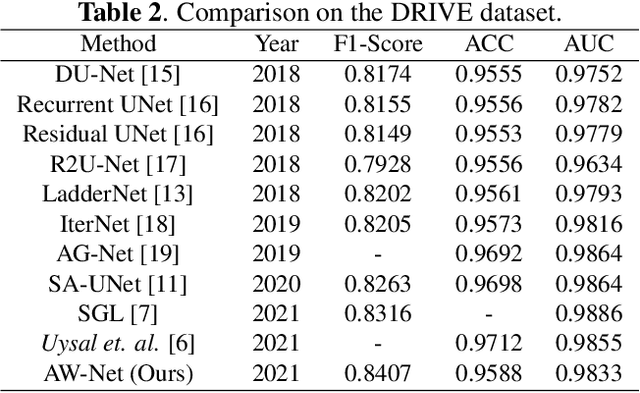
Segmentation of macro and microvascular structures in fundoscopic retinal images plays a crucial role in detection of multiple retinal and systemic diseases, yet it is a difficult problem to solve. Most deep learning approaches for this task involve an autoencoder based architecture, but they face several issues such as lack of enough parameters, overfitting when there are enough parameters and incompatibility between internal feature-spaces. Due to such issues, these techniques are hence not able to extract the best semantic information from the limited data present for such tasks. We propose Attention W-Net, a new U-Net based architecture for retinal vessel segmentation to address these problems. In this architecture with a LadderNet backbone, we have two main contributions: Attention Block and regularisation measures. Our Attention Block uses decoder features to attend over the encoder features from skip-connections during upsampling, resulting in higher compatibility when the encoder and decoder features are added. Our regularisation measures include image augmentation and modifications to the ResNet Block used, which prevent overfitting. With these additions, we observe an AUC and F1-Score of 0.8407 and 0.9833 - a sizeable improvement over its LadderNet backbone as well as competitive performance among the contemporary state-of-the-art methods.
SDL: New data generation tools for full-level annotated document layout
Jun 29, 2021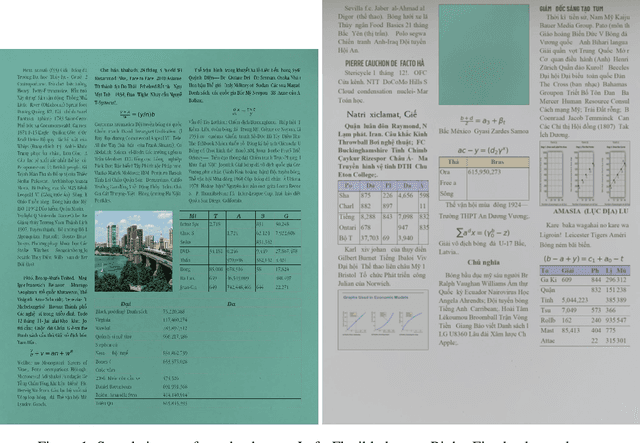
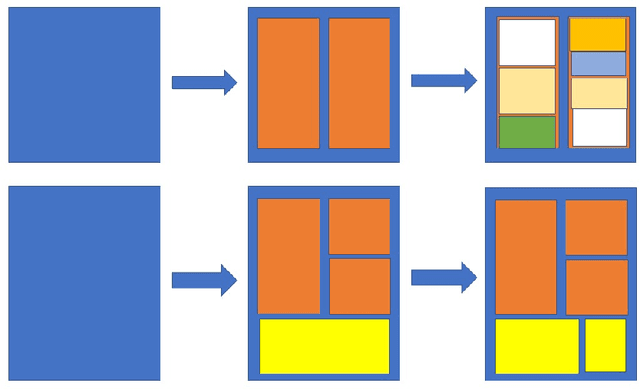
We present a novel data generation tool for document processing. The tool focuses on providing a maximal level of visual information in a normal type document, ranging from character position to paragraph-level position. It also enables working with a large dataset on low-resource languages as well as providing a mean of processing thorough full-level information of the documented text. The data generation tools come with a dataset of 320000 Vietnamese synthetic document images and an instruction to generate a dataset of similar size in other languages. The repository can be found at: https://github.com/tson1997/SDL-Document-Image-Generation
Emoji-aware Co-attention Network with EmoGraph2vec Model for Sentiment Anaylsis
Oct 27, 2021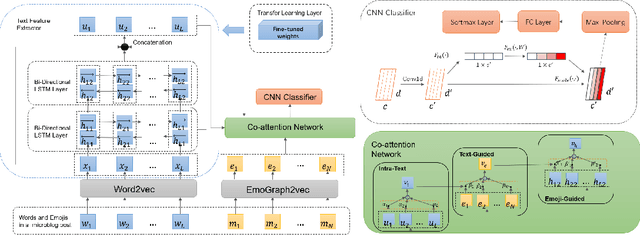
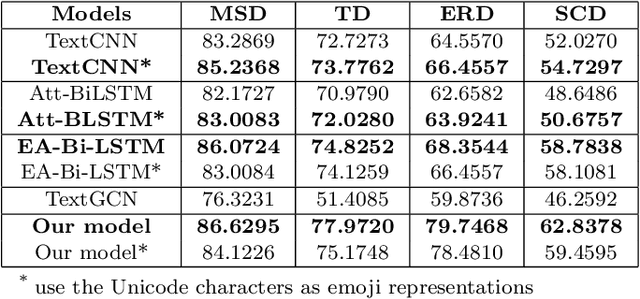
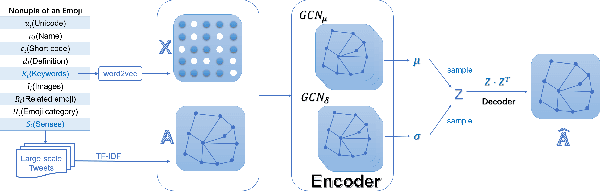
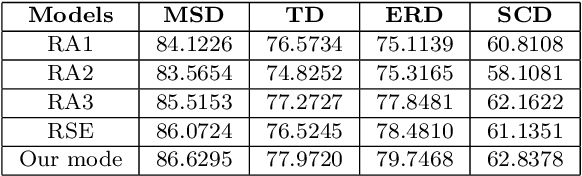
In social media platforms, emojis have an extremely high occurrence in computer-mediated communications. Many emojis are used to strengthen the emotional expressions and the emojis that co-occurs in a sentence also have a strong sentiment connection. However, when it comes to emoji representation learning, most studies have only utilized the fixed descriptions provided by the Unicode Consortium, without consideration of actual usage scenario. As for the sentiment analysis task, many researchers ignore the emotional impact of the interaction between text and emojis. It results that the emotional semantics of emojis cannot be fully explored. In this work, we propose a method to learn emoji representations called EmoGraph2vec and design an emoji-aware co-attention network that learns the mutual emotional semantics between text and emojis on short texts of social media. In EmoGraph2vec, we form an emoji co-occurrence network on real social data and enrich the semantic information based on an external knowledge base EmojiNet to obtain emoji node embeddings. Our model designs a co-attention mechanism to incorporate the text and emojis, and integrates a squeeze-and-excitation (SE) block into a convolutional neural network as a classifier. Finally, we use the transfer learning method to increase converge speed and achieve higher accuracy. Experimental results show that the proposed model can outperform several baselines for sentiment analysis on benchmark datasets. Additionally, we conduct a series of ablation and comparison experiments to investigate the effectiveness of our model.
Federated Unlearning via Class-Discriminative Pruning
Oct 22, 2021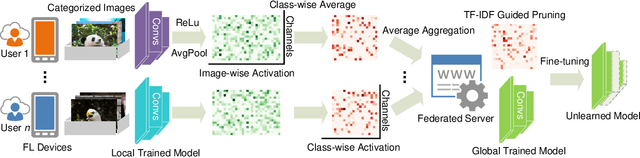



We explore the problem of selectively forgetting categories from trained CNN classification models in the federated learning (FL). Given that the data used for training cannot be accessed globally in FL, our insights probe deep into the internal influence of each channel. Through the visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we propose a method for scrubbing the model clean of information about particular categories. The method does not require retraining from scratch, nor global access to the data used for training. Instead, we introduce the concept of Term Frequency Inverse Document Frequency (TF-IDF) to quantize the class discrimination of channels. Channels with high TF-IDF scores have more discrimination on the target categories and thus need to be pruned to unlearn. The channel pruning is followed by a fine-tuning process to recover the performance of the pruned model. Evaluated on CIFAR10 dataset, our method accelerates the speed of unlearning by 8.9x for the ResNet model, and 7.9x for the VGG model under no degradation in accuracy, compared to retraining from scratch. For CIFAR100 dataset, the speedups are 9.9x and 8.4x, respectively. We envision this work as a complementary block for FL towards compliance with legal and ethical criteria.
Predictive Representation Learning for Language Modeling
May 29, 2021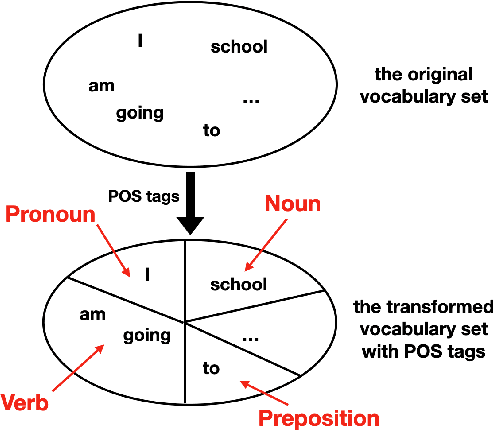
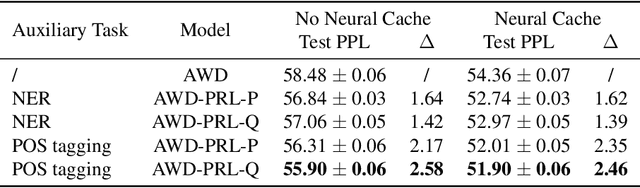
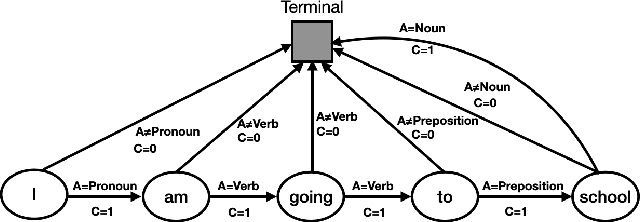
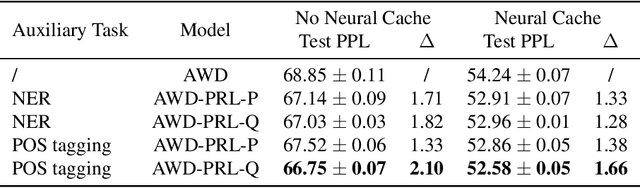
To effectively perform the task of next-word prediction, long short-term memory networks (LSTMs) must keep track of many types of information. Some information is directly related to the next word's identity, but some is more secondary (e.g. discourse-level features or features of downstream words). Correlates of secondary information appear in LSTM representations even though they are not part of an \emph{explicitly} supervised prediction task. In contrast, in reinforcement learning (RL), techniques that explicitly supervise representations to predict secondary information have been shown to be beneficial. Inspired by that success, we propose Predictive Representation Learning (PRL), which explicitly constrains LSTMs to encode specific predictions, like those that might need to be learned implicitly. We show that PRL 1) significantly improves two strong language modeling methods, 2) converges more quickly, and 3) performs better when data is limited. Our work shows that explicitly encoding a simple predictive task facilitates the search for a more effective language model.
G-DetKD: Towards General Distillation Framework for Object Detectors via Contrastive and Semantic-guided Feature Imitation
Aug 20, 2021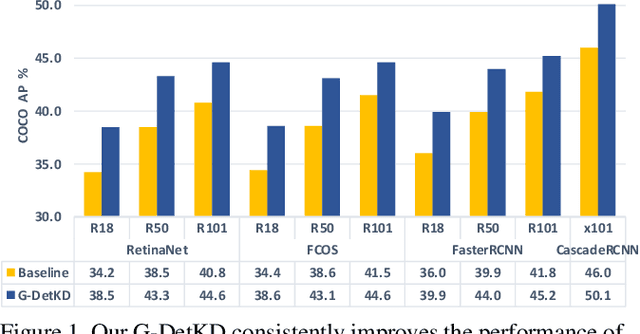
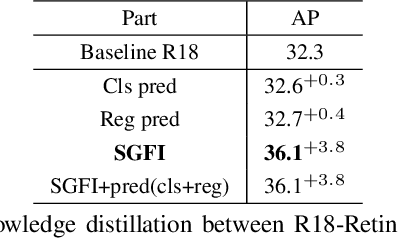
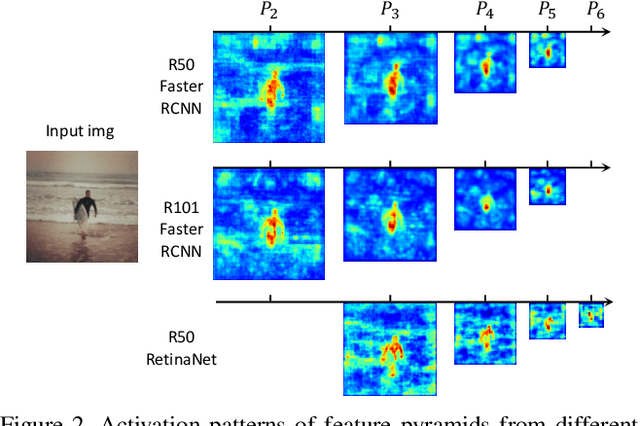
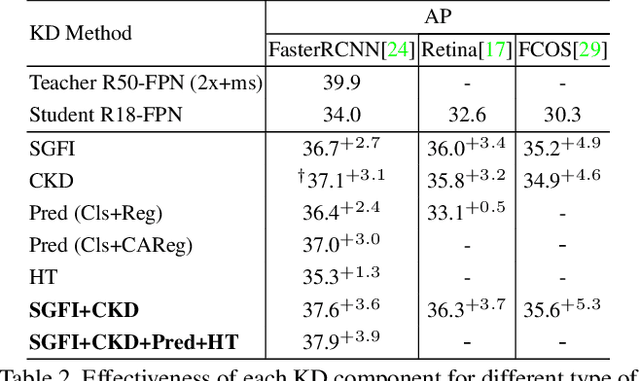
In this paper, we investigate the knowledge distillation (KD) strategy for object detection and propose an effective framework applicable to both homogeneous and heterogeneous student-teacher pairs. The conventional feature imitation paradigm introduces imitation masks to focus on informative foreground areas while excluding the background noises. However, we find that those methods fail to fully utilize the semantic information in all feature pyramid levels, which leads to inefficiency for knowledge distillation between FPN-based detectors. To this end, we propose a novel semantic-guided feature imitation technique, which automatically performs soft matching between feature pairs across all pyramid levels to provide the optimal guidance to the student. To push the envelop even further, we introduce contrastive distillation to effectively capture the information encoded in the relationship between different feature regions. Finally, we propose a generalized detection KD pipeline, which is capable of distilling both homogeneous and heterogeneous detector pairs. Our method consistently outperforms the existing detection KD techniques, and works when (1) components in the framework are used separately and in conjunction; (2) for both homogeneous and heterogenous student-teacher pairs and (3) on multiple detection benchmarks. With a powerful X101-FasterRCNN-Instaboost detector as the teacher, R50-FasterRCNN reaches 44.0% AP, R50-RetinaNet reaches 43.3% AP and R50-FCOS reaches 43.1% AP on COCO dataset.
MemSum: Extractive Summarization of Long Documents using Multi-step Episodic Markov Decision Processes
Jul 19, 2021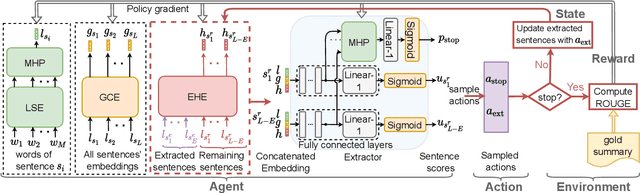
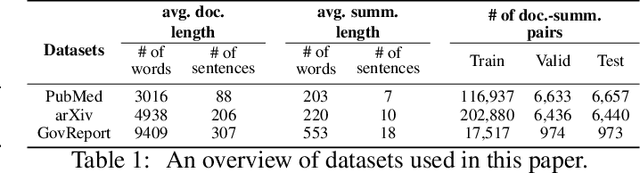
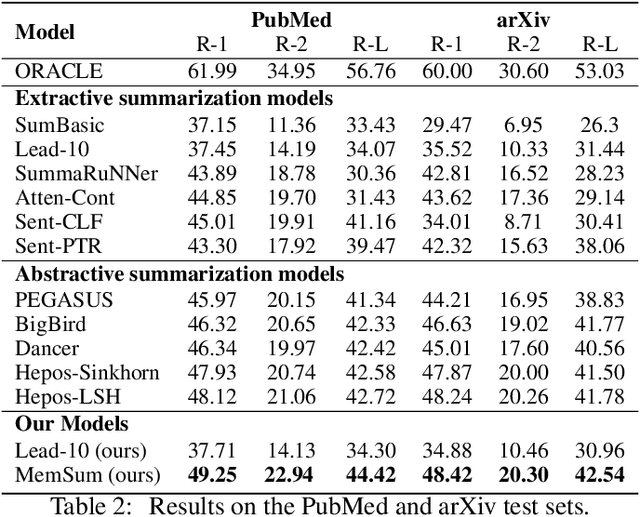
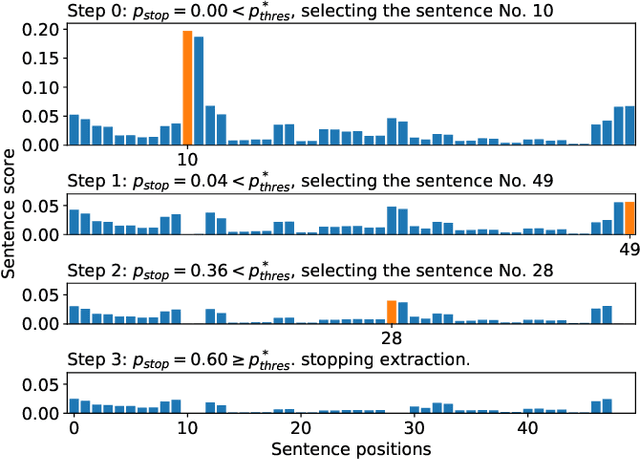
We introduce MemSum (Multi-step Episodic Markov decision process extractive SUMmarizer), a reinforcement-learning-based extractive summarizer enriched at any given time step with information on the current extraction history. Similar to previous models in this vein, MemSum iteratively selects sentences into the summary. Our innovation is in considering a broader information set when summarizing that would intuitively also be used by humans in this task: 1) the text content of the sentence, 2) the global text context of the rest of the document, and 3) the extraction history consisting of the set of sentences that have already been extracted. With a lightweight architecture, MemSum nonetheless obtains state-of-the-art test-set performance (ROUGE score) on long document datasets (PubMed, arXiv, and GovReport). Supporting analysis demonstrates that the added awareness of extraction history gives MemSum robustness against redundancy in the source document.