 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DoSSIER@COLIEE 2021: Leveraging dense retrieval and summarization-based re-ranking for case law retrieval
Aug 09, 2021
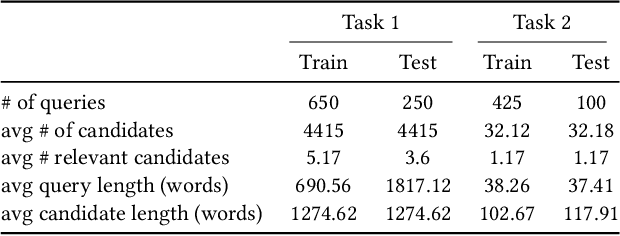
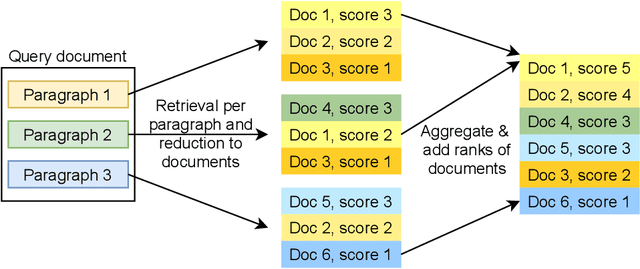
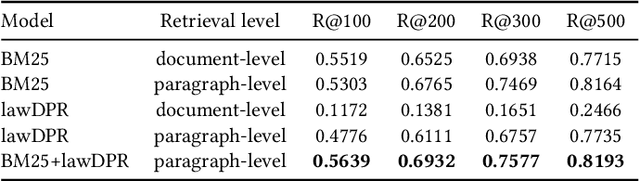
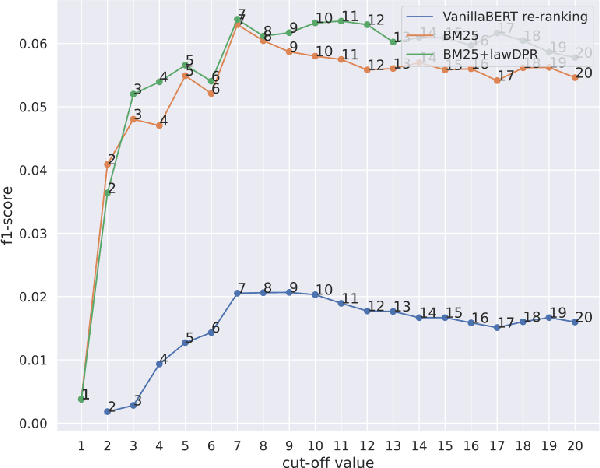
In this paper, we present our approaches for the case law retrieval and the legal case entailment task in the Competition on Legal Information Extraction/Entailment (COLIEE) 2021. As first stage retrieval methods combined with neural re-ranking methods using contextualized language models like BERT achieved great performance improvements for information retrieval in the web and news domain, we evaluate these methods for the legal domain. A distinct characteristic of legal case retrieval is that the query case and case description in the corpus tend to be long documents and therefore exceed the input length of BERT. We address this challenge by combining lexical and dense retrieval methods on the paragraph-level of the cases for the first stage retrieval. Here we demonstrate that the retrieval on the paragraph-level outperforms the retrieval on the document-level. Furthermore the experiments suggest that dense retrieval methods outperform lexical retrieval. For re-ranking we address the problem of long documents by summarizing the cases and fine-tuning a BERT-based re-ranker with the summaries. Overall, our best results were obtained with a combination of BM25 and dense passage retrieval using domain-specific embeddings.
UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training
Oct 12, 2021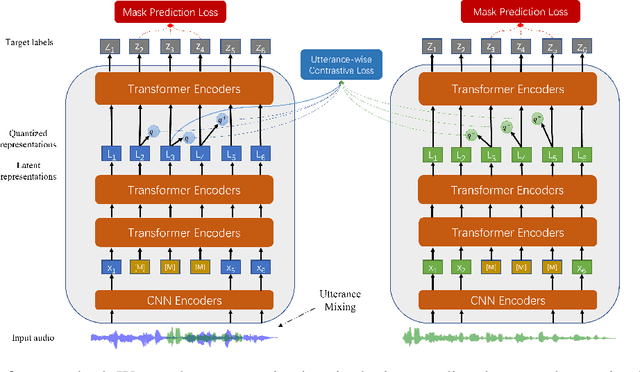
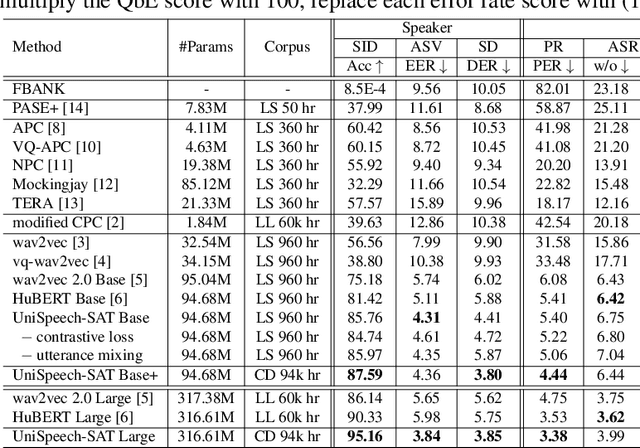
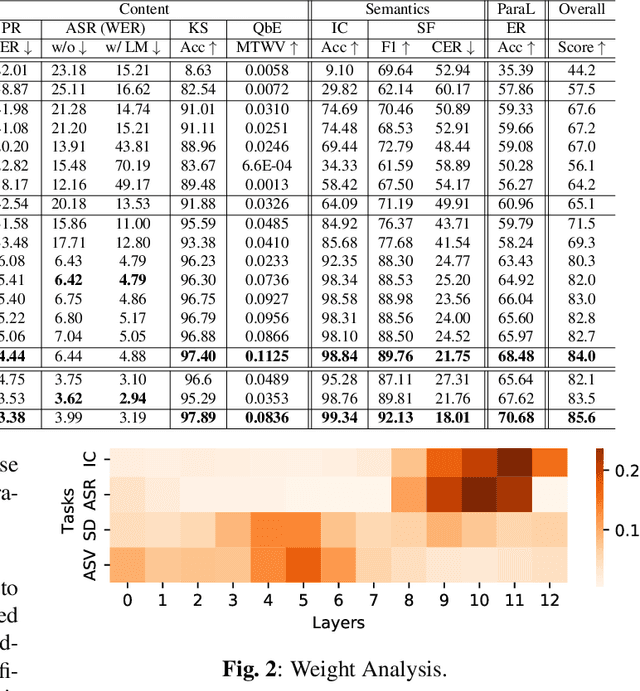
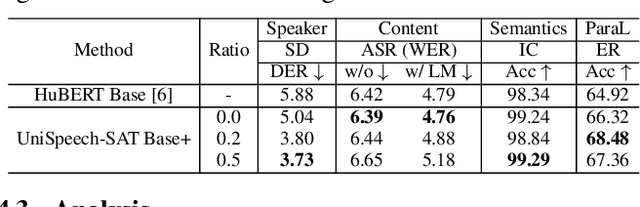
Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.
CCTrans: Simplifying and Improving Crowd Counting with Transformer
Sep 29, 2021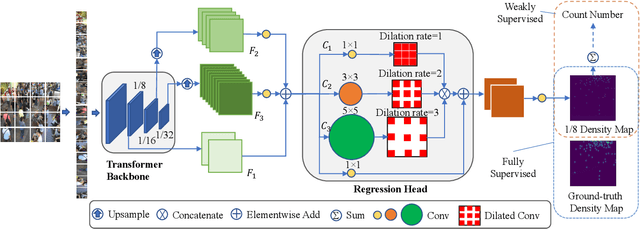
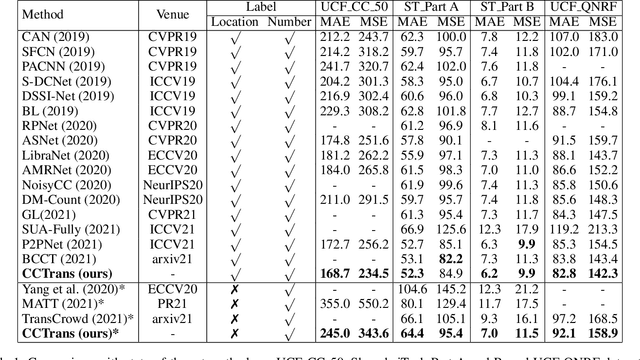
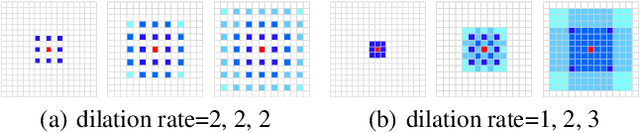
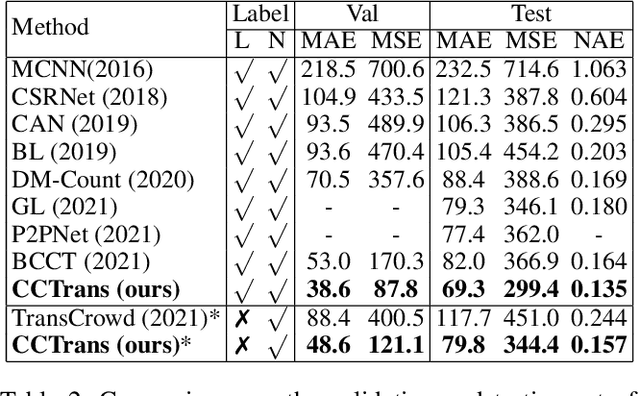
Most recent methods used for crowd counting are based on the convolutional neural network (CNN), which has a strong ability to extract local features. But CNN inherently fails in modeling the global context due to the limited receptive fields. However, the transformer can model the global context easily. In this paper, we propose a simple approach called CCTrans to simplify the design pipeline. Specifically, we utilize a pyramid vision transformer backbone to capture the global crowd information, a pyramid feature aggregation (PFA) model to combine low-level and high-level features, an efficient regression head with multi-scale dilated convolution (MDC) to predict density maps. Besides, we tailor the loss functions for our pipeline. Without bells and whistles, extensive experiments demonstrate that our method achieves new state-of-the-art results on several benchmarks both in weakly and fully-supervised crowd counting. Moreover, we currently rank No.1 on the leaderboard of NWPU-Crowd. Our code will be made available.
The chemical space of terpenes: insights from data science and AI
Oct 27, 2021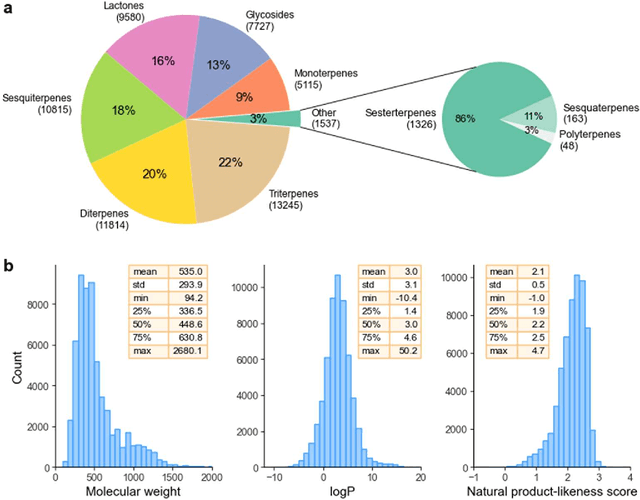
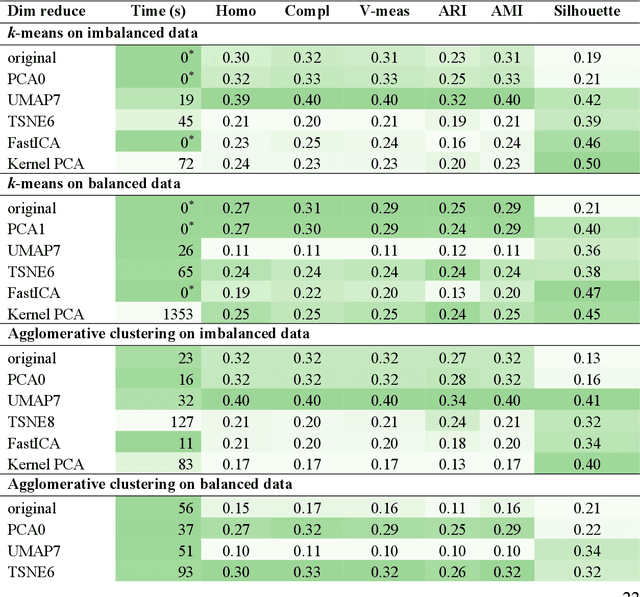
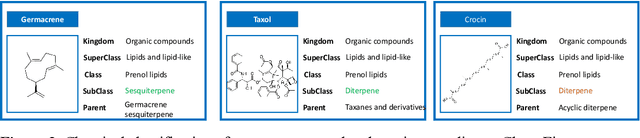
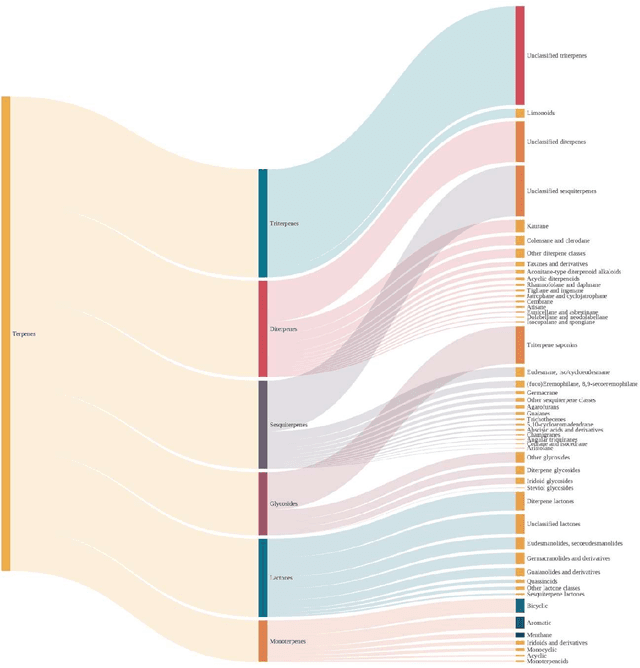
Terpenes are a widespread class of natural products with significant chemical and biological diversity and many of these molecules have already made their way into medicines. Given the thousands of molecules already described, the full characterization of this chemical space can be a challenging task when relying in classical approaches. In this work we employ a data science-based approach to identify, compile and characterize the diversity of terpenes currently known in a systematic way. We worked with a natural product database, COCONUT, from which we extracted information for nearly 60000 terpenes. For these molecules, we conducted a subclass-by-subclass analysis in which we highlight several chemical and physical properties relevant to several fields, such as natural products chemistry, medicinal chemistry and drug discovery, among others. We were also interested in assessing the potential of this data for clustering and classification tasks. For clustering, we have applied and compared k-means with agglomerative clustering, both to the original data and following a step of dimensionality reduction. To this end, PCA, FastICA, Kernel PCA, t-SNE and UMAP were used and benchmarked. We also employed a number of methods for the purpose of classifying terpene subclasses using their physico-chemical descriptors. Light gradient boosting machine, k-nearest neighbors, random forests, Gaussian naiive Bayes and Multilayer perceptron, with the best-performing algorithms yielding accuracy, F1 score, precision and other metrics all over 0.9, thus showing the capabilities of these approaches for the classification of terpene subclasses.
Vector-Decomposed Disentanglement for Domain-Invariant Object Detection
Aug 15, 2021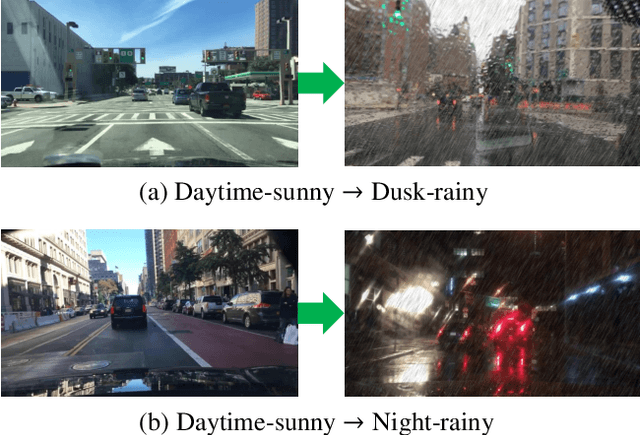
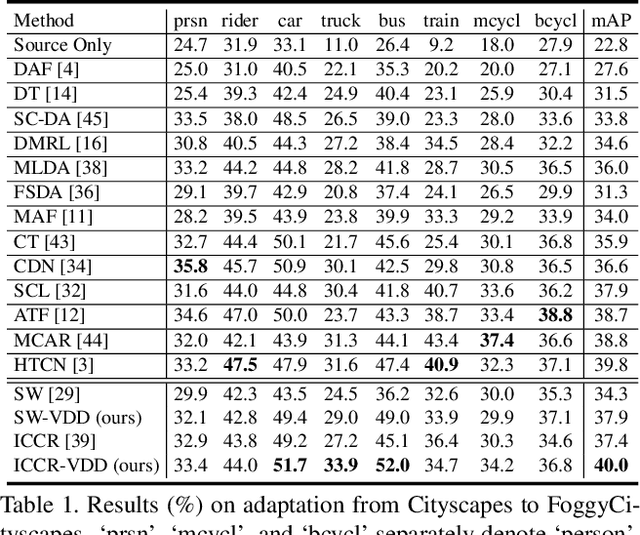
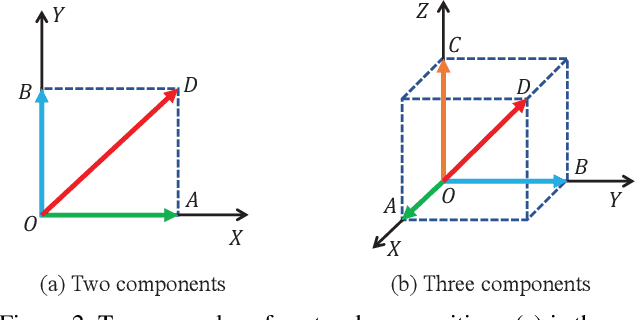
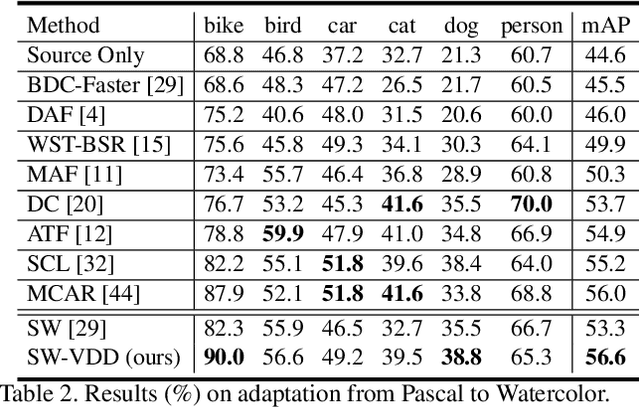
To improve the generalization of detectors, for domain adaptive object detection (DAOD), recent advances mainly explore aligning feature-level distributions between the source and single-target domain, which may neglect the impact of domain-specific information existing in the aligned features. Towards DAOD, it is important to extract domain-invariant object representations. To this end, in this paper, we try to disentangle domain-invariant representations from domain-specific representations. And we propose a novel disentangled method based on vector decomposition. Firstly, an extractor is devised to separate domain-invariant representations from the input, which are used for extracting object proposals. Secondly, domain-specific representations are introduced as the differences between the input and domain-invariant representations. Through the difference operation, the gap between the domain-specific and domain-invariant representations is enlarged, which promotes domain-invariant representations to contain more domain-irrelevant information. In the experiment, we separately evaluate our method on the single- and compound-target case. For the single-target case, experimental results of four domain-shift scenes show our method obtains a significant performance gain over baseline methods. Moreover, for the compound-target case (i.e., the target is a compound of two different domains without domain labels), our method outperforms baseline methods by around 4%, which demonstrates the effectiveness of our method.
Toward Automatic Interpretation of 3D Plots
Jun 14, 2021

This paper explores the challenge of teaching a machine how to reverse-engineer the grid-marked surfaces used to represent data in 3D surface plots of two-variable functions. These are common in scientific and economic publications; and humans can often interpret them with ease, quickly gleaning general shape and curvature information from the simple collection of curves. While machines have no such visual intuition, they do have the potential to accurately extract the more detailed quantitative data that guided the surface's construction. We approach this problem by synthesizing a new dataset of 3D grid-marked surfaces (SurfaceGrid) and training a deep neural net to estimate their shape. Our algorithm successfully recovers shape information from synthetic 3D surface plots that have had axes and shading information removed, been rendered with a variety of grid types, and viewed from a range of viewpoints.
Provable RL with Exogenous Distractors via Multistep Inverse Dynamics
Oct 17, 2021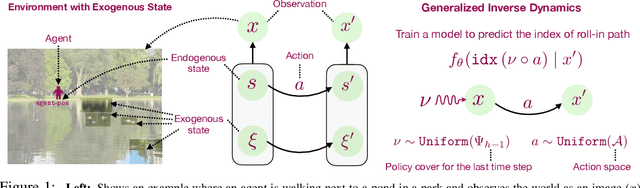

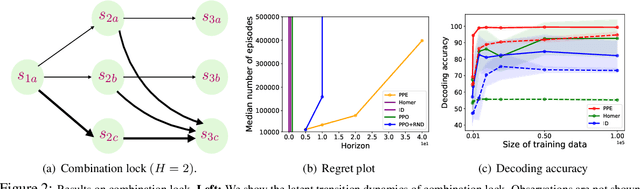
Many real-world applications of reinforcement learning (RL) require the agent to deal with high-dimensional observations such as those generated from a megapixel camera. Prior work has addressed such problems with representation learning, through which the agent can provably extract endogenous, latent state information from raw observations and subsequently plan efficiently. However, such approaches can fail in the presence of temporally correlated noise in the observations, a phenomenon that is common in practice. We initiate the formal study of latent state discovery in the presence of such exogenous noise sources by proposing a new model, the Exogenous Block MDP (EX-BMDP), for rich observation RL. We start by establishing several negative results, by highlighting failure cases of prior representation learning based approaches. Then, we introduce the Predictive Path Elimination (PPE) algorithm, that learns a generalization of inverse dynamics and is provably sample and computationally efficient in EX-BMDPs when the endogenous state dynamics are near deterministic. The sample complexity of PPE depends polynomially on the size of the latent endogenous state space while not directly depending on the size of the observation space, nor the exogenous state space. We provide experiments on challenging exploration problems which show that our approach works empirically.
Elevation Angle-Dependent Trajectory Design for Aerial RIS-aided Communication
Sep 10, 2021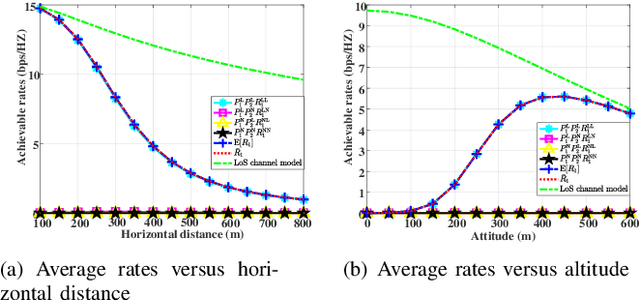
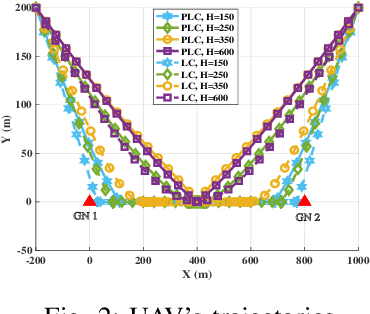
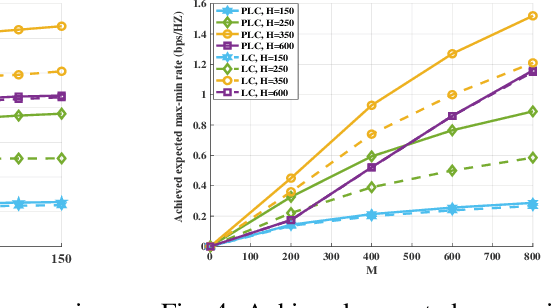
This paper investigates an aerial reconfigurable intelligent surface (RIS)-aided communication system under the probabilistic line-of-sight (LoS) channel, where an unmanned aerial vehicle (UAV) equipped with an RIS is deployed to assist two ground nodes in their information exchange. An optimization problem with the objective of maximizing the minimum average achievable rate is formulated to design the communication scheduling, the RIS's phase, and the UAV trajectory. To solve such a non-convex problem, we propose an efficient iterative algorithm to obtain its suboptimal solution. Simulation results show that our proposed design significantly outperforms the existing schemes and provides new insights into the elevation angle and distance trade-off for the UAV-borne RIS communication system.
Towards Robust Cross-domain Image Understanding with Unsupervised Noise Removal
Sep 09, 2021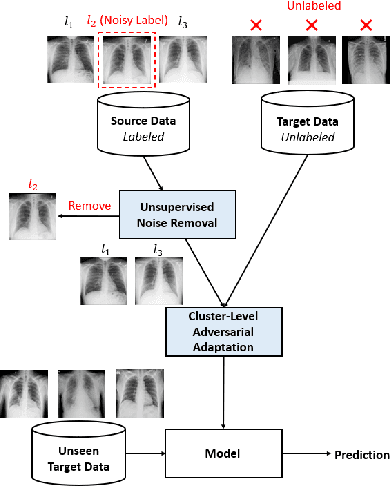
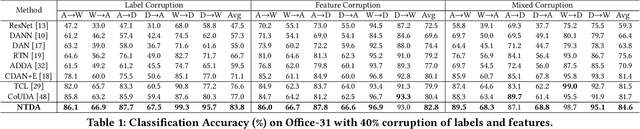
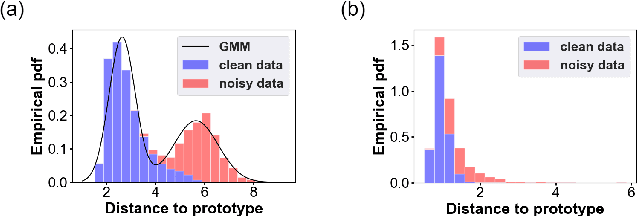
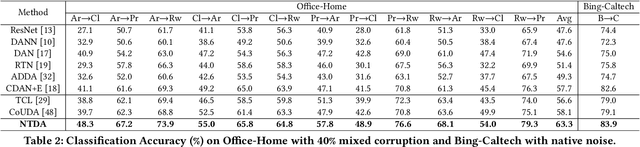
Deep learning models usually require a large amount of labeled data to achieve satisfactory performance. In multimedia analysis, domain adaptation studies the problem of cross-domain knowledge transfer from a label rich source domain to a label scarce target domain, thus potentially alleviates the annotation requirement for deep learning models. However, we find that contemporary domain adaptation methods for cross-domain image understanding perform poorly when source domain is noisy. Weakly Supervised Domain Adaptation (WSDA) studies the domain adaptation problem under the scenario where source data can be noisy. Prior methods on WSDA remove noisy source data and align the marginal distribution across domains without considering the fine-grained semantic structure in the embedding space, which have the problem of class misalignment, e.g., features of cats in the target domain might be mapped near features of dogs in the source domain. In this paper, we propose a novel method, termed Noise Tolerant Domain Adaptation, for WSDA. Specifically, we adopt the cluster assumption and learn cluster discriminatively with class prototypes in the embedding space. We propose to leverage the location information of the data points in the embedding space and model the location information with a Gaussian mixture model to identify noisy source data. We then design a network which incorporates the Gaussian mixture noise model as a sub-module for unsupervised noise removal and propose a novel cluster-level adversarial adaptation method which aligns unlabeled target data with the less noisy class prototypes for mapping the semantic structure across domains. We conduct extensive experiments to evaluate the effectiveness of our method on both general images and medical images from COVID-19 and e-commerce datasets. The results show that our method significantly outperforms state-of-the-art WSDA methods.
DONet: Learning Category-Level 6D Object Pose and Size Estimation from Depth Observation
Jun 27, 2021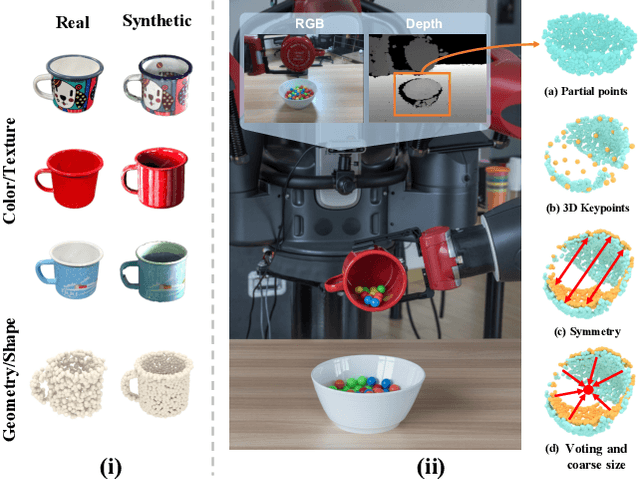
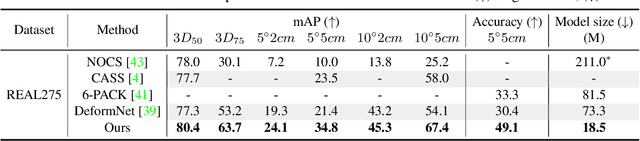
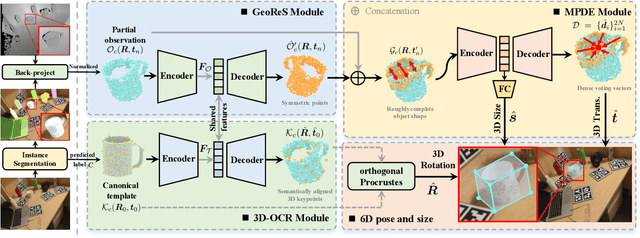
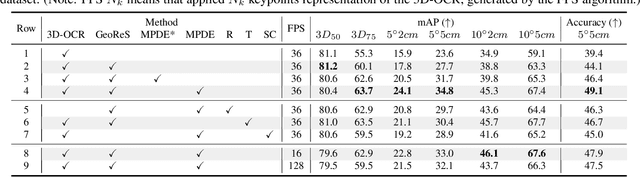
We propose a method of Category-level 6D Object Pose and Size Estimation (COPSE) from a single depth image, without external pose-annotated real-world training data. While previous works exploit visual cues in RGB(D) images, our method makes inferences based on the rich geometric information of the object in the depth channel alone. Essentially, our framework explores such geometric information by learning the unified 3D Orientation-Consistent Representations (3D-OCR) module, and further enforced by the property of Geometry-constrained Reflection Symmetry (GeoReS) module. The magnitude information of object size and the center point is finally estimated by Mirror-Paired Dimensional Estimation (MPDE) module. Extensive experiments on the category-level NOCS benchmark demonstrate that our framework competes with state-of-the-art approaches that require labeled real-world images. We also deploy our approach to a physical Baxter robot to perform manipulation tasks on unseen but category-known instances, and the results further validate the efficacy of our proposed model. Our videos are available in the supplementary material.