 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What makes us curious? analysis of a corpus of open-domain questions
Oct 28, 2021
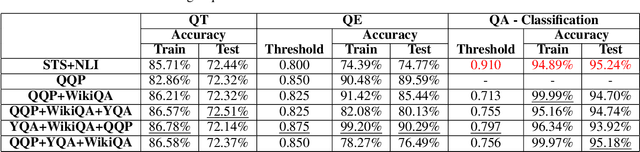
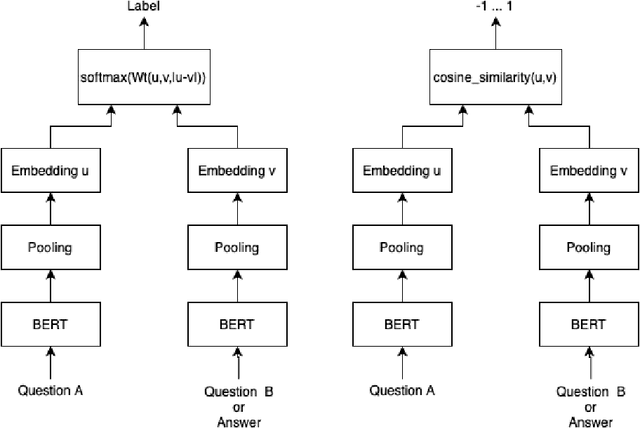
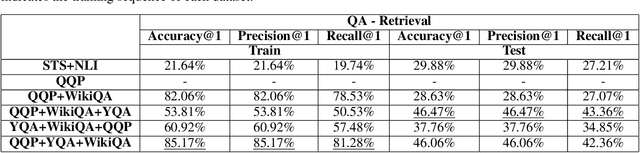
Every day people ask short questions through smart devices or online forums to seek answers to all kinds of queries. With the increasing number of questions collected it becomes difficult to provide answers to each of them, which is one of the reasons behind the growing interest in automated question answering. Some questions are similar to existing ones that have already been answered, while others could be answered by an external knowledge source such as Wikipedia. An important question is what can be revealed by analysing a large set of questions. In 2017, "We the Curious" science centre in Bristol started a project to capture the curiosity of Bristolians: the project collected more than 10,000 questions on various topics. As no rules were given during collection, the questions are truly open-domain, and ranged across a variety of topics. One important aim for the science centre was to understand what concerns its visitors had beyond science, particularly on societal and cultural issues. We addressed this question by developing an Artificial Intelligence tool that can be used to perform various processing tasks: detection of equivalence between questions; detection of topic and type; and answering of the question. As we focused on the creation of a "generalist" tool, we trained it with labelled data from different datasets. We called the resulting model QBERT. This paper describes what information we extracted from the automated analysis of the WTC corpus of open-domain questions.
Multi-scale speaker embedding-based graph attention networks for speaker diarisation
Oct 07, 2021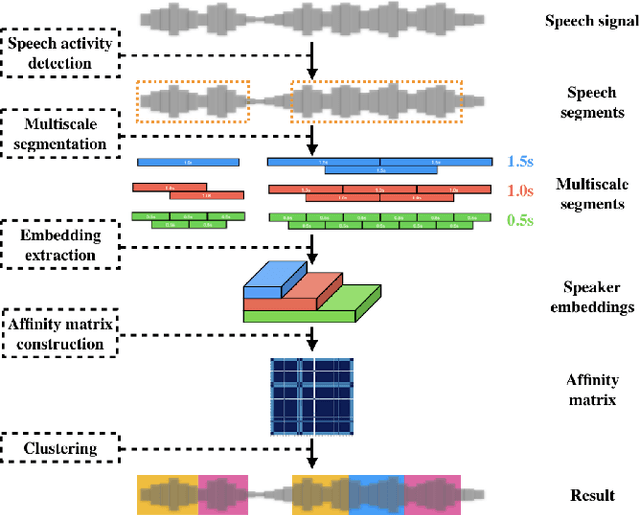
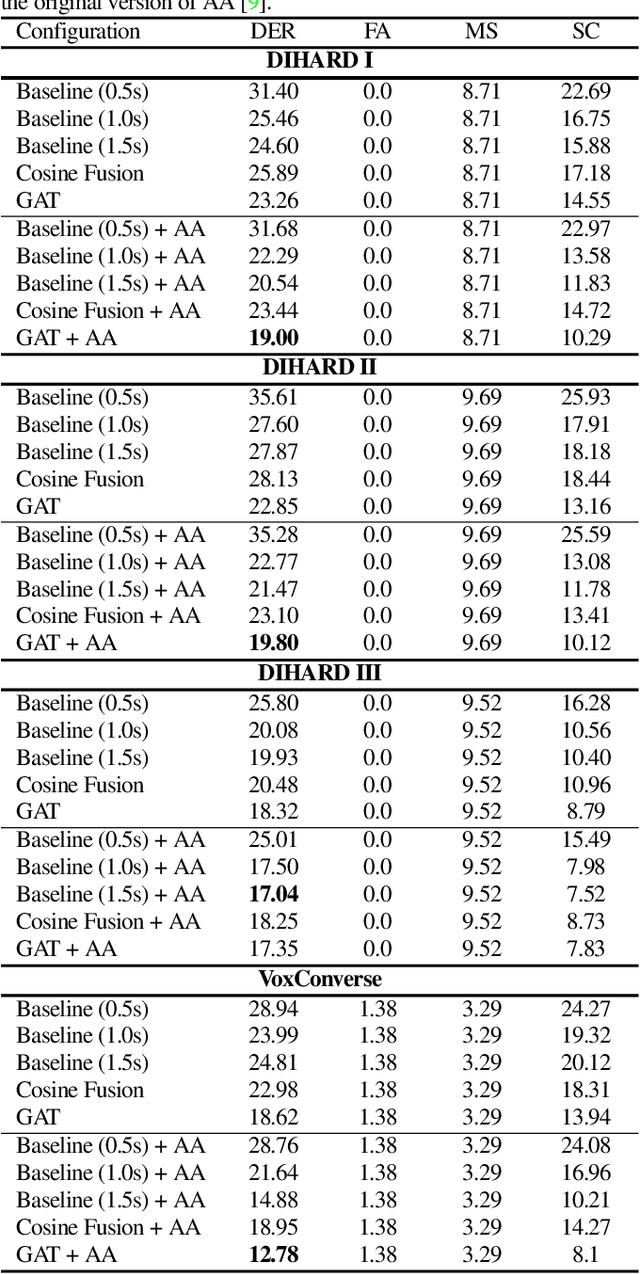
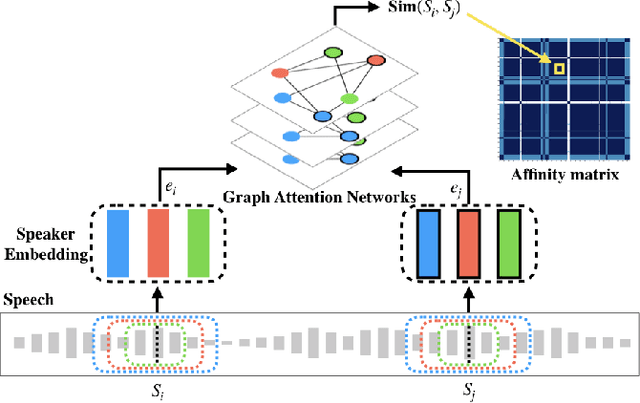
The objective of this work is effective speaker diarisation using multi-scale speaker embeddings. Typically, there is a trade-off between the ability to recognise short speaker segments and the discriminative power of the embedding, according to the segment length used for embedding extraction. To this end, recent works have proposed the use of multi-scale embeddings where segments with varying lengths are used. However, the scores are combined using a weighted summation scheme where the weights are fixed after the training phase, whereas the importance of segment lengths can differ with in a single session. To address this issue, we present three key contributions in this paper: (1) we propose graph attention networks for multi-scale speaker diarisation; (2) we design scale indicators to utilise scale information of each embedding; (3) we adapt the attention-based aggregation to utilise a pre-computed affinity matrix from multi-scale embeddings. We demonstrate the effectiveness of our method in various datasets where the speaker confusion which constitutes the primary metric drops over 10% in average relative compared to the baseline.
Depth Infused Binaural Audio Generation using Hierarchical Cross-Modal Attention
Aug 10, 2021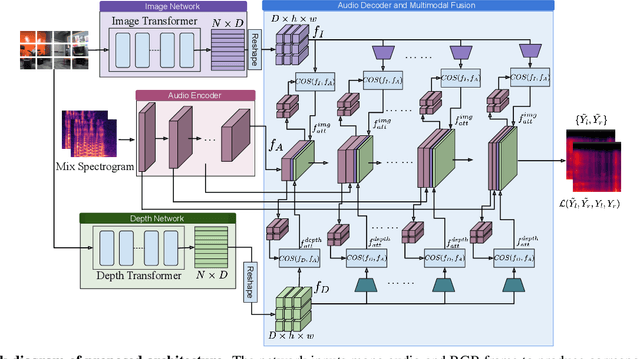
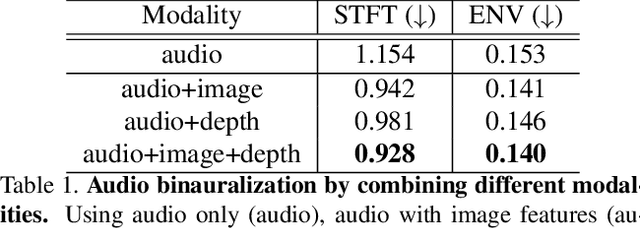
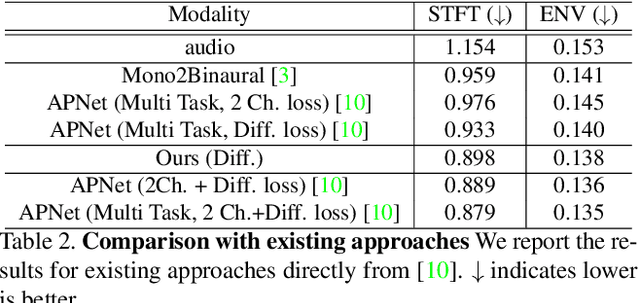

Binaural audio gives the listener the feeling of being in the recording place and enhances the immersive experience if coupled with AR/VR. But the problem with binaural audio recording is that it requires a specialized setup which is not possible to fabricate within handheld devices as compared to traditional mono audio that can be recorded with a single microphone. In order to overcome this drawback, prior works have tried to uplift the mono recorded audio to binaural audio as a post processing step conditioning on the visual input. But all the prior approaches missed other most important information required for the task, i.e. distance of different sound producing objects from the recording setup. In this work, we argue that the depth map of the scene can act as a proxy for encoding distance information of objects in the scene and show that adding depth features along with image features improves the performance both qualitatively and quantitatively. We propose a novel encoder-decoder architecture, where we use a hierarchical attention mechanism to encode the image and depth feature extracted from individual transformer backbone, with audio features at each layer of the decoder.
Accelerating Inverse Rendering By Using a GPU and Reuse of Light Paths
Sep 30, 2021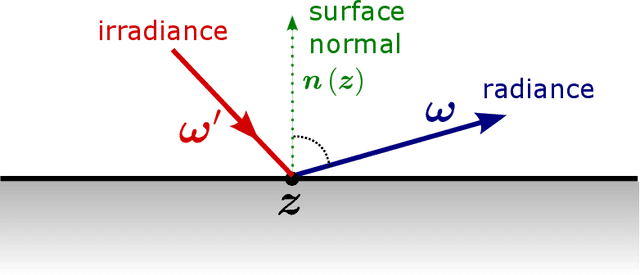
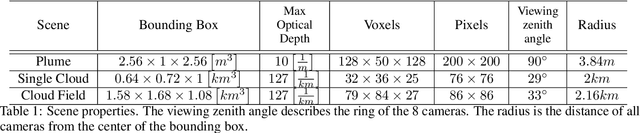
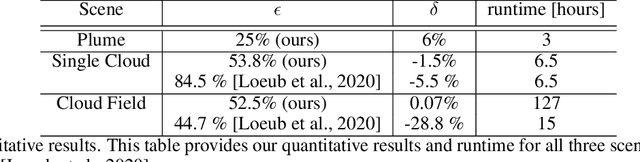
Inverse rendering seeks to estimate scene characteristics from a set of data images. The dominant approach is based on differential rendering using Monte-Carlo. Algorithms as such usually rely on a forward model and use an iterative gradient method that requires sampling millions of light paths per iteration. This paper presents an efficient framework that speeds up existing inverse rendering algorithms. This is achieved by tailoring the iterative process of inverse rendering specifically to a GPU architecture. For this cause, we introduce two interleaved steps - Path Sorting and Path Recycling. Path Sorting allows the GPU to deal with light paths of the same size. Path Recycling allows the algorithm to use light paths from previous iterations to better utilize the information they encode. Together, these steps significantly speed up gradient optimization. In this paper, we give the theoretical background for Path Recycling. We demonstrate its efficiency for volumetric scattering tomography and reflectometry (surface reflections).
Provenance, Anonymisation and Data Environments: a Unifying Construction
Jul 21, 2021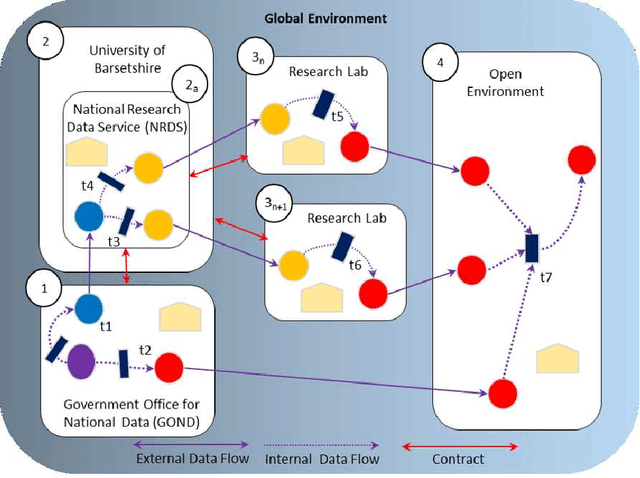
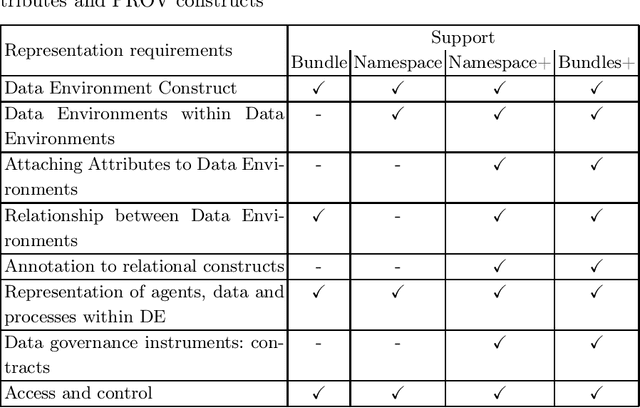
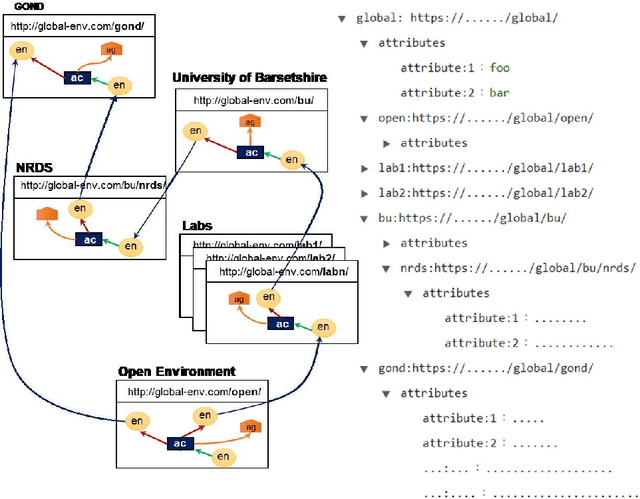
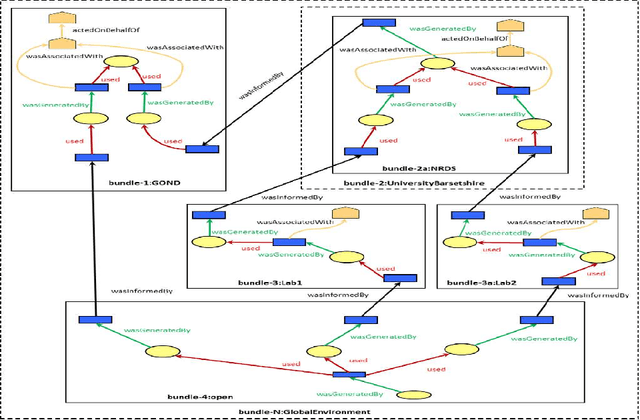
The Anonymisation Decision-making Framework (ADF) operationalizes the risk management of data exchange between organizations, referred to as "data environments". The second edition of ADF has increased its emphasis on modeling data flows, highlighting a potential new use of provenance information to support anonymisation decision-making. In this paper, we provide a use case that showcases this functionality more. Based on this use case, we identify how provenance information could be utilized within the ADF framework, and identify a currently un-met requirement which is the modeling of \textit{data environments}. We show how data environments can be implemented within the W3C PROV in four different ways. We analyze the costs and benefits of each approach, and consider another use case as a partial check for completeness. We then summarize our findings and suggest ways forward.
Vibration-Based Condition Monitoring By Ensemble Deep Learning
Oct 13, 2021
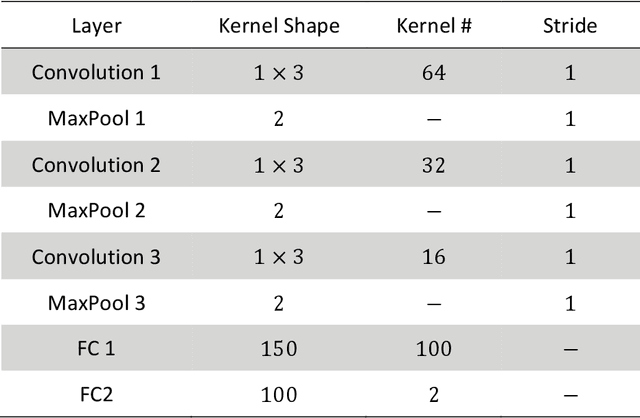
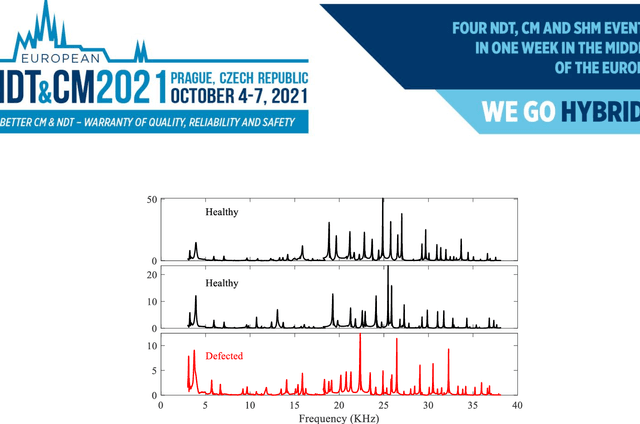
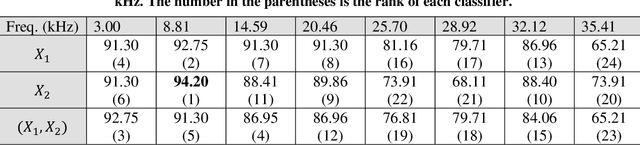
Vibration-based techniques are among the most common condition monitoring approaches. With the advancement of computers, these approaches have also been improved such that recently, these approaches in conjunction with deep learning methods attract attention among researchers. This is mostly due to the nature of the deep learning method that could facilitate the monitoring procedure by integrating the feature extraction, feature selection, and classification steps into one automated step. However, this can be achieved at the expense of challenges in designing the architecture of a deep learner, tuning its hyper-parameters. Moreover, it sometimes gives low generalization capability. As a remedy to these problems, this study proposes a framework based on ensemble deep learning methodology. The framework was initiated by creating a pool of Convolutional neural networks (CNN). To create diversity to the CNNs, they are fed by frequency responses which are passed through different functions. As the next step, proper CNNs are selected based on an information criterion to be used for fusion. The fusion is then carried out by improved Dempster-Shafer theory. The proposed framework is applied to real test data collected from Equiax Polycrystalline Nickel alloy first-stage turbine blades with complex geometry.
EdgeConv with Attention Module for Monocular Depth Estimation
Jun 16, 2021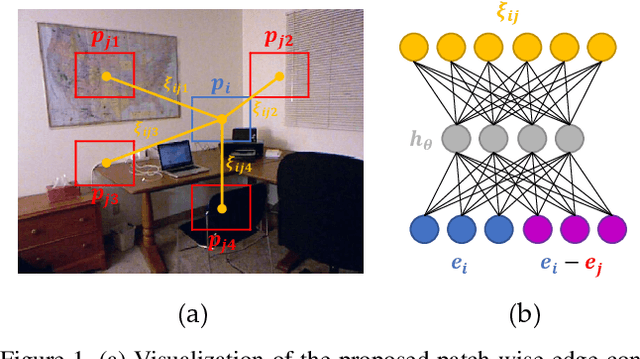
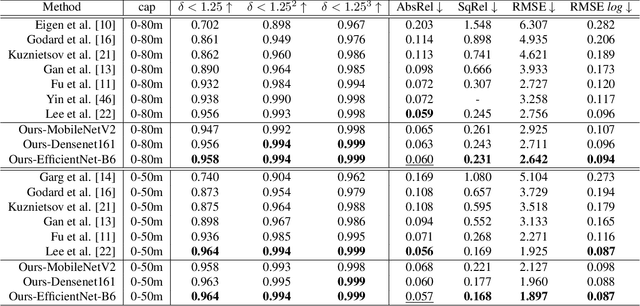
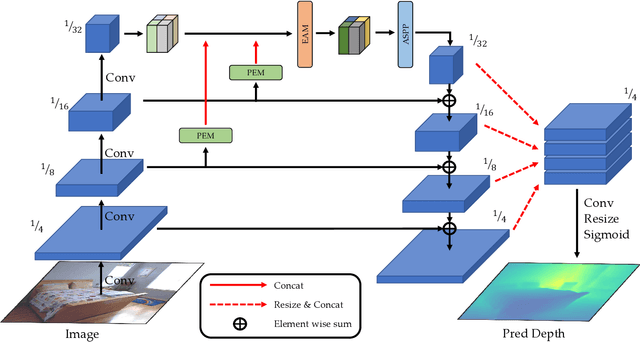
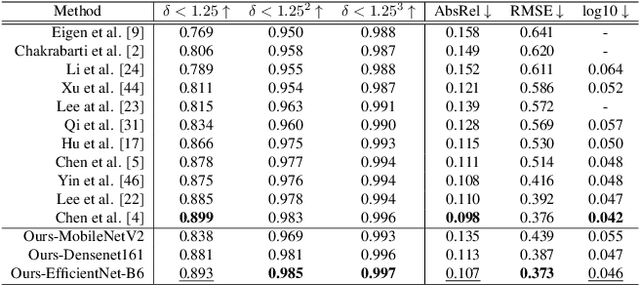
Monocular depth estimation is an especially important task in robotics and autonomous driving, where 3D structural information is essential. However, extreme lighting conditions and complex surface objects make it difficult to predict depth in a single image. Therefore, to generate accurate depth maps, it is important for the model to learn structural information about the scene. We propose a novel Patch-Wise EdgeConv Module (PEM) and EdgeConv Attention Module (EAM) to solve the difficulty of monocular depth estimation. The proposed modules extract structural information by learning the relationship between image patches close to each other in space using edge convolution. Our method is evaluated on two popular datasets, the NYU Depth V2 and the KITTI Eigen split, achieving state-of-the-art performance. We prove that the proposed model predicts depth robustly in challenging scenes through various comparative experiments.
Automating Internet of Things Network Traffic Collection with Robotic Arm Interactions
Sep 30, 2021

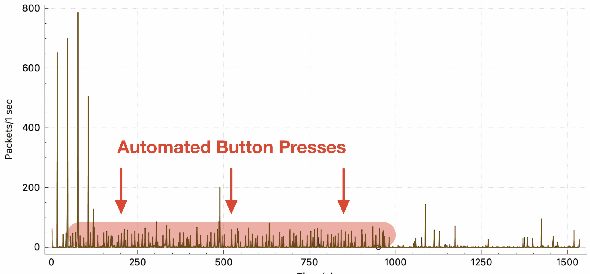
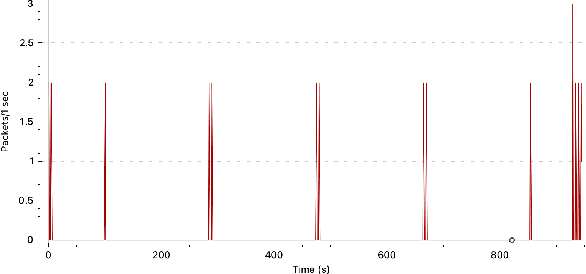
Consumer Internet of things research often involves collecting network traffic sent or received by IoT devices. These data are typically collected via crowdsourcing or while researchers manually interact with IoT devices in a laboratory setting. However, manual interactions and crowdsourcing are often tedious, expensive, inaccurate, or do not provide comprehensive coverage of possible IoT device behaviors. We present a new method for generating IoT network traffic using a robotic arm to automate user interactions with devices. This eliminates manual button pressing and enables permutation-based interaction sequences that rigorously explore the range of possible device behaviors. We test this approach with an Arduino-controlled robotic arm, a smart speaker and a smart thermostat, using machine learning to demonstrate that collected network traffic contains information about device interactions that could be useful for network, security, or privacy analyses. We also provide source code and documentation allowing researchers to easily automate IoT device interactions and network traffic collection in future studies.
Generalizing RNN-Transducer to Out-Domain Audio via Sparse Self-Attention Layers
Aug 22, 2021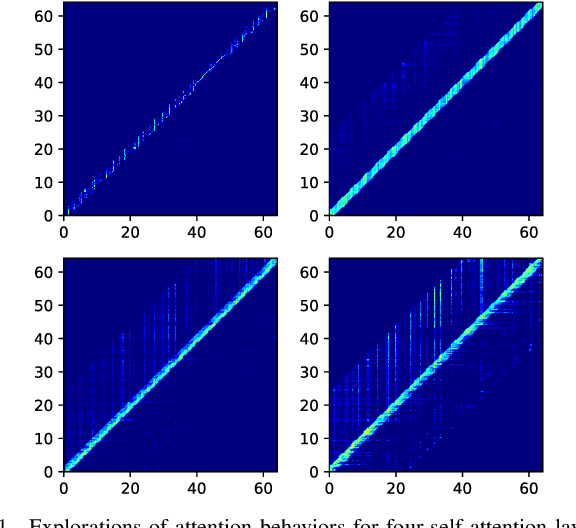
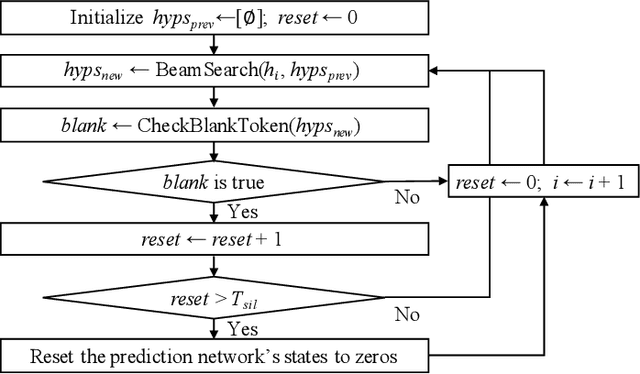

Recurrent neural network transducers (RNN-T) are a promising end-to-end speech recognition framework that transduces input acoustic frames into a character sequence. The state-of-the-art encoder network for RNN-T is the Conformer, which can effectively model the local-global context information via its convolution and self-attention layers. Although Conformer RNN-T has shown outstanding performance (measured by word error rate (WER) in general), most studies have been verified in the setting where the train and test data are drawn from the same domain. The domain mismatch problem for Conformer RNN-T has not been intensively investigated yet, which is an important issue for the product-level speech recognition system. In this study, we identified that fully connected self-attention layers in the Conformer caused high deletion errors, specifically in the long-form out-domain utterances. To address this problem, we introduce sparse self-attention layers for Conformer-based encoder networks, which can exploit local and generalized global information by pruning most of the in-domain fitted global connections. Further, we propose a state reset method for the generalization of the prediction network to cope with long-form utterances. Applying proposed methods to an out-domain test, we obtained 24.6\% and 6.5\% relative character error rate (CER) reduction compared to the fully connected and local self-attention layer-based Conformers, respectively.
RPBA -- Robust Parallel Bundle Adjustment Based on Covariance Information
Oct 17, 2019
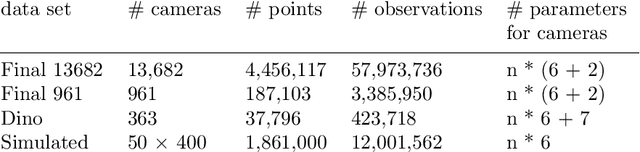


A core component of all Structure from Motion (SfM) approaches is bundle adjustment. As the latter is a computational bottleneck for larger blocks, parallel bundle adjustment has become an active area of research. Particularly, consensus-based optimization methods have been shown to be suitable for this task. We have extended them using covariance information derived by the adjustment of individual three-dimensional (3D) points, i.e., "triangulation" or "intersection". This does not only lead to a much better convergence behavior, but also avoids fiddling with the penalty parameter of standard consensus-based approaches. The corresponding novel approach can also be seen as a variant of resection / intersection schemes, where we adjust during intersection a number of sub-blocks directly related to the number of threads available on a computer each containing a fraction of the cameras of the block. We show that our novel approach is suitable for robust parallel bundle adjustment and demonstrate its capabilities in comparison to the basic consensus-based approach as well as a state-of-the-art parallel implementation of bundle adjustment. Code for our novel approach is available on GitHub: https://github.com/helmayer/RPBA