 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uplink Performance of Cell-Free Massive MIMO with Multi-Antenna Users Over Jointly-Correlated Rayleigh Fading Channels
Oct 11, 2021
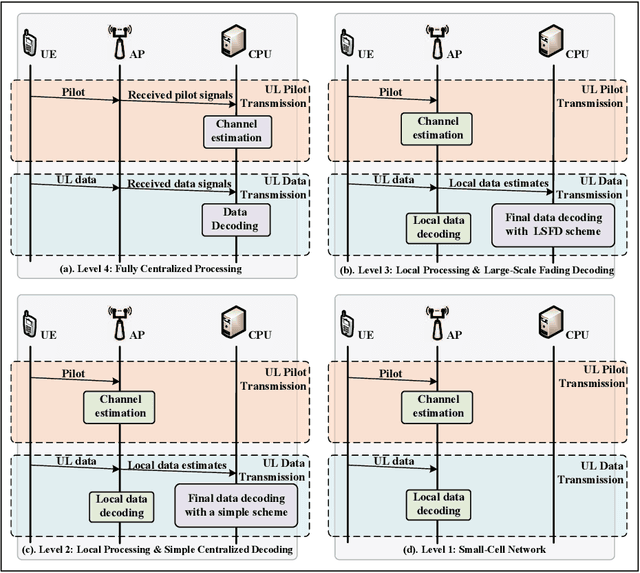
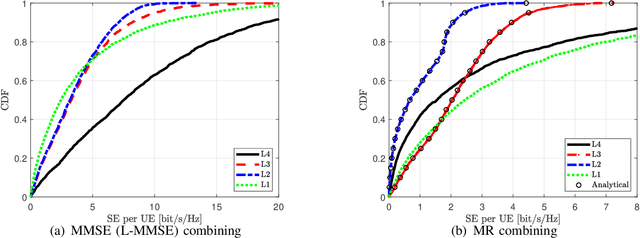
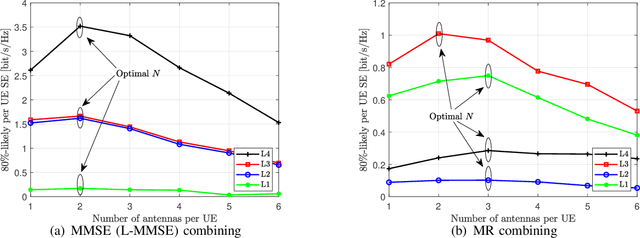
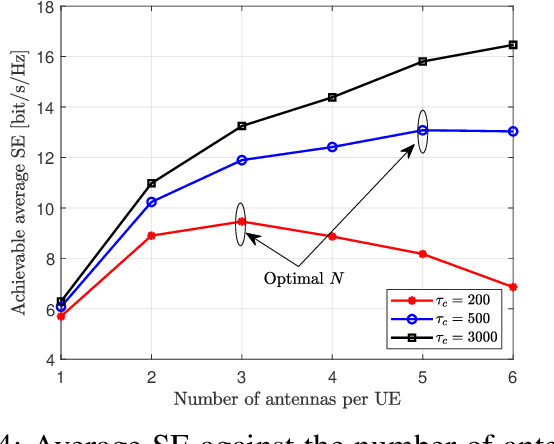
In this paper, we investigate a cell-free massive MIMO system with both access points (APs) and user equipments (UEs) equipped with multiple antennas over jointly correlated Rayleigh fading channels. We study four uplink implementations, from fully centralized processing to fully distributed processing, and derive achievable spectral efficiency (SE) expressions with minimum mean-squared error successive interference cancellation (MMSE-SIC) detectors and arbitrary combining schemes. Furthermore, the global and local MMSE combining schemes are derived based on full and local channel state information (CSI) obtained under pilot contamination, which can maximize the achievable SE for the fully centralized and distributed implementation, respectively. We study a two-layer decoding implementation with an arbitrary combining scheme in the first layer and optimal large-scale fading decoding in the second layer. Besides, we compute novel closed-form SE expressions for the two-layer decoding implementation with maximum ratio combining. We compare the SE of different implementation levels and combining schemes and investigate the effect of having additional UE antennas. Note that increasing the number of antennas per UE may degrade the SE performance and the optimal number of UE antennas maximizing the SE is related to the implementation levels, the length of the resource block, and the number of UEs.
Exploiting Twitter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings
Oct 05, 2021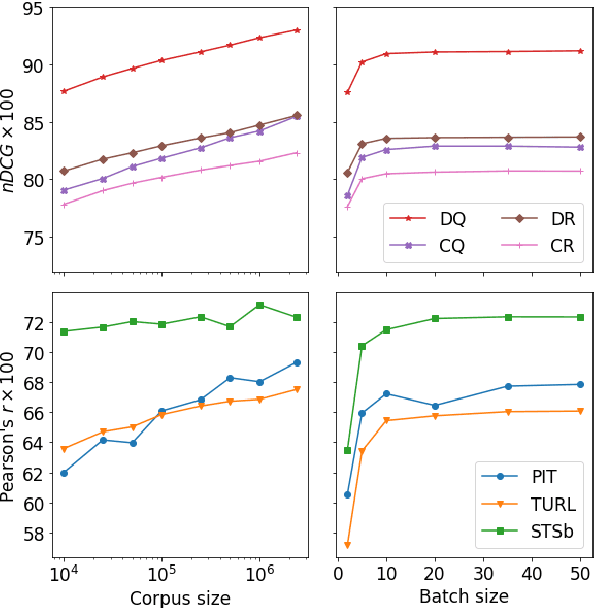
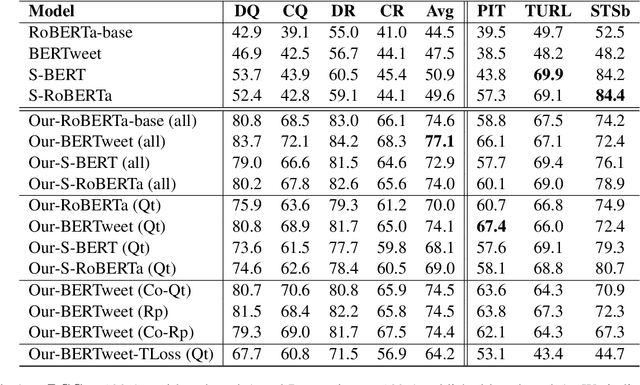
Semantic sentence embeddings are usually supervisedly built minimizing distances between pairs of embeddings of sentences labelled as semantically similar by annotators. Since big labelled datasets are rare, in particular for non-English languages, and expensive, recent studies focus on unsupervised approaches that require not-paired input sentences. We instead propose a language-independent approach to build large datasets of pairs of informal texts weakly similar, without manual human effort, exploiting Twitter's intrinsic powerful signals of relatedness: replies and quotes of tweets. We use the collected pairs to train a Transformer model with triplet-like structures, and we test the generated embeddings on Twitter NLP similarity tasks (PIT and TURL) and STSb. We also introduce four new sentence ranking evaluation benchmarks of informal texts, carefully extracted from the initial collections of tweets, proving not only that our best model learns classical Semantic Textual Similarity, but also excels on tasks where pairs of sentences are not exact paraphrases. Ablation studies reveal how increasing the corpus size influences positively the results, even at 2M samples, suggesting that bigger collections of Tweets still do not contain redundant information about semantic similarities.
Learning Temporally-Consistent Representations for Data-Efficient Reinforcement Learning
Oct 11, 2021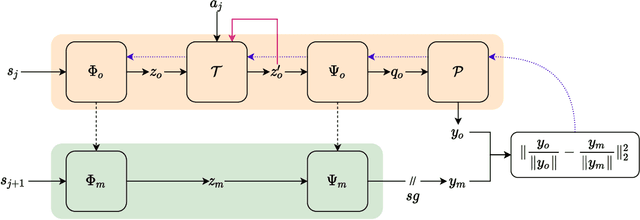
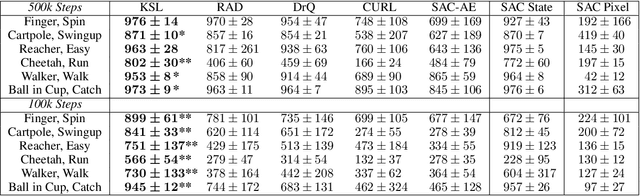
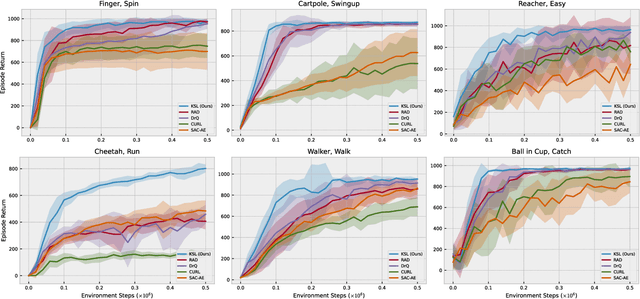
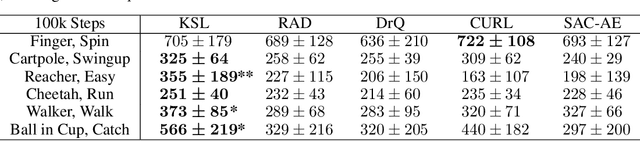
Deep reinforcement learning (RL) agents that exist in high-dimensional state spaces, such as those composed of images, have interconnected learning burdens. Agents must learn an action-selection policy that completes their given task, which requires them to learn a representation of the state space that discerns between useful and useless information. The reward function is the only supervised feedback that RL agents receive, which causes a representation learning bottleneck that can manifest in poor sample efficiency. We present $k$-Step Latent (KSL), a new representation learning method that enforces temporal consistency of representations via a self-supervised auxiliary task wherein agents learn to recurrently predict action-conditioned representations of the state space. The state encoder learned by KSL produces low-dimensional representations that make optimization of the RL task more sample efficient. Altogether, KSL produces state-of-the-art results in both data efficiency and asymptotic performance in the popular PlaNet benchmark suite. Our analyses show that KSL produces encoders that generalize better to new tasks unseen during training, and its representations are more strongly tied to reward, are more invariant to perturbations in the state space, and move more smoothly through the temporal axis of the RL problem than other methods such as DrQ, RAD, CURL, and SAC-AE.
Prix-LM: Pretraining for Multilingual Knowledge Base Construction
Oct 16, 2021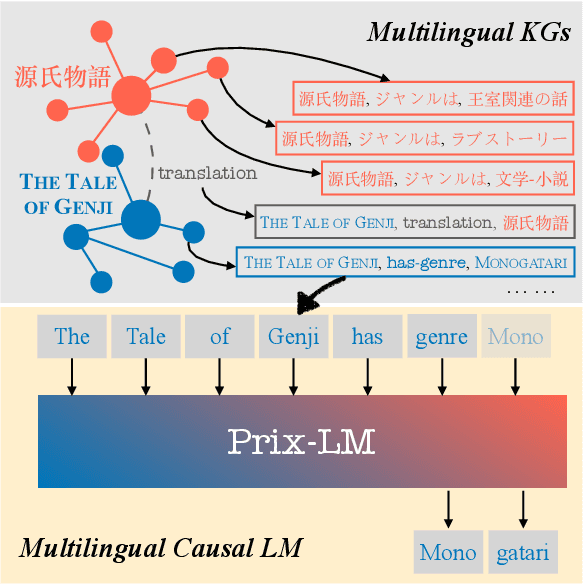
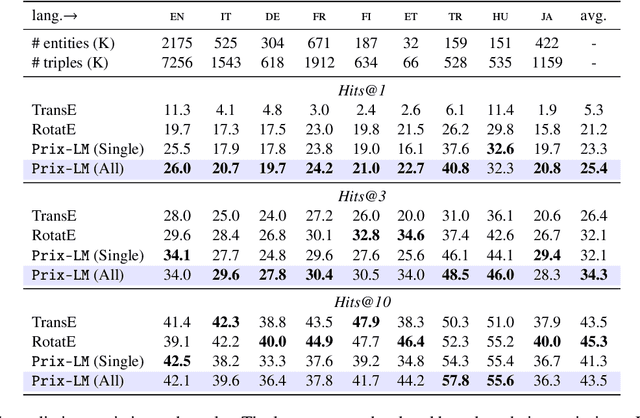
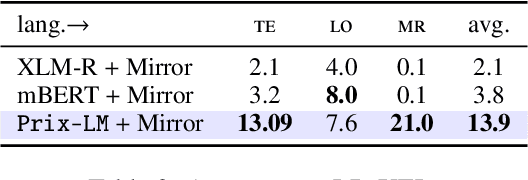
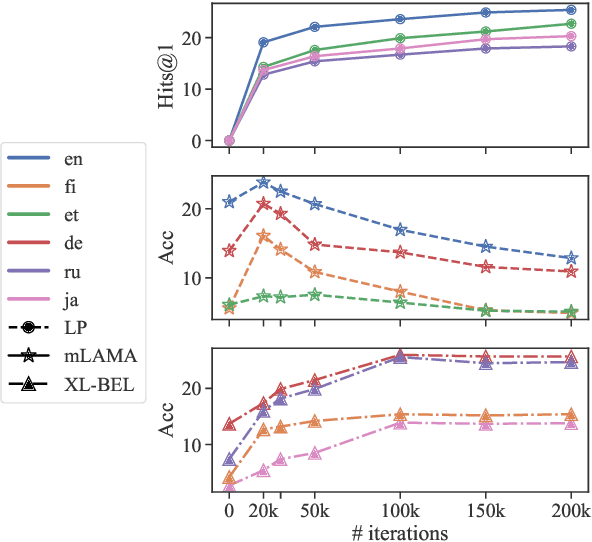
Knowledge bases (KBs) contain plenty of structured world and commonsense knowledge. As such, they often complement distributional text-based information and facilitate various downstream tasks. Since their manual construction is resource- and time-intensive, recent efforts have tried leveraging large pretrained language models (PLMs) to generate additional monolingual knowledge facts for KBs. However, such methods have not been attempted for building and enriching multilingual KBs. Besides wider application, such multilingual KBs can provide richer combined knowledge than monolingual (e.g., English) KBs. Knowledge expressed in different languages may be complementary and unequally distributed: this implies that the knowledge available in high-resource languages can be transferred to low-resource ones. To achieve this, it is crucial to represent multilingual knowledge in a shared/unified space. To this end, we propose a unified framework, Prix-LM, for multilingual KB construction and completion. We leverage two types of knowledge, monolingual triples and cross-lingual links, extracted from existing multilingual KBs, and tune a multilingual language encoder XLM-R via a causal language modeling objective. Prix-LM integrates useful multilingual and KB-based factual knowledge into a single model. Experiments on standard entity-related tasks, such as link prediction in multiple languages, cross-lingual entity linking and bilingual lexicon induction, demonstrate its effectiveness, with gains reported over strong task-specialised baselines.
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
Aug 19, 2021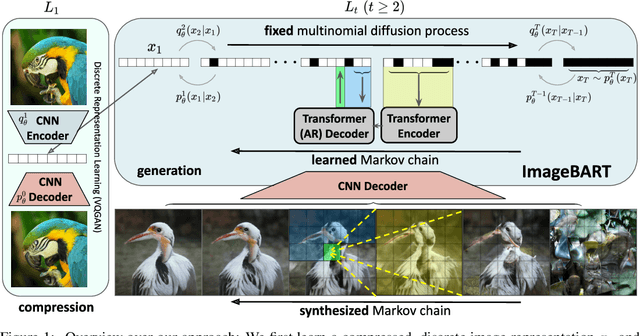



Autoregressive models and their sequential factorization of the data likelihood have recently demonstrated great potential for image representation and synthesis. Nevertheless, they incorporate image context in a linear 1D order by attending only to previously synthesized image patches above or to the left. Not only is this unidirectional, sequential bias of attention unnatural for images as it disregards large parts of a scene until synthesis is almost complete. It also processes the entire image on a single scale, thus ignoring more global contextual information up to the gist of the entire scene. As a remedy we incorporate a coarse-to-fine hierarchy of context by combining the autoregressive formulation with a multinomial diffusion process: Whereas a multistage diffusion process successively removes information to coarsen an image, we train a (short) Markov chain to invert this process. In each stage, the resulting autoregressive ImageBART model progressively incorporates context from previous stages in a coarse-to-fine manner. Experiments show greatly improved image modification capabilities over autoregressive models while also providing high-fidelity image generation, both of which are enabled through efficient training in a compressed latent space. Specifically, our approach can take unrestricted, user-provided masks into account to perform local image editing. Thus, in contrast to pure autoregressive models, it can solve free-form image inpainting and, in the case of conditional models, local, text-guided image modification without requiring mask-specific training.
Metadata Shaping: Natural Language Annotations for the Tail
Oct 16, 2021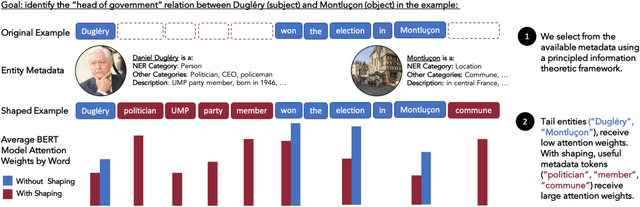
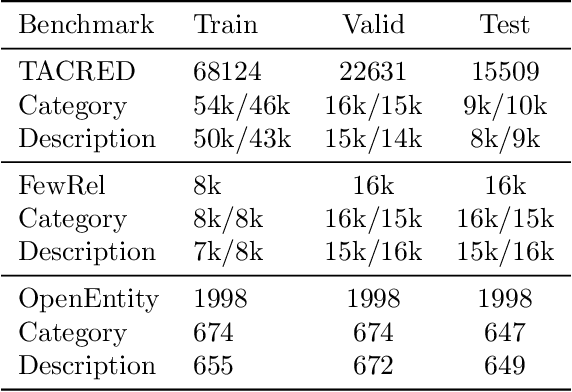
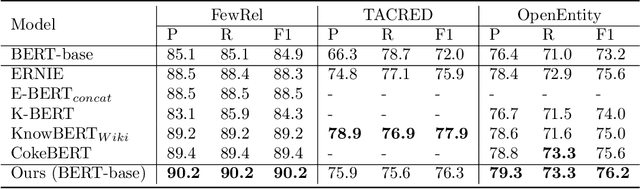
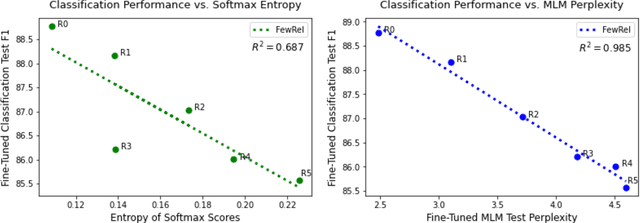
Language models (LMs) have made remarkable progress, but still struggle to generalize beyond the training data to rare linguistic patterns. Since rare entities and facts are prevalent in the queries users submit to popular applications such as search and personal assistant systems, improving the ability of LMs to reliably capture knowledge over rare entities is a pressing challenge studied in significant prior work. Noticing that existing approaches primarily modify the LM architecture or introduce auxiliary objectives to inject useful entity knowledge, we ask to what extent we could match the quality of these architectures using a base LM architecture, and only changing the data? We propose metadata shaping, a method in which readily available metadata, such as entity descriptions and categorical tags, are appended to examples based on information theoretic metrics. Intuitively, if metadata corresponding to popular entities overlap with metadata for rare entities, the LM may be able to better reason about the rare entities using patterns learned from similar popular entities. On standard entity-rich tasks (TACRED, FewRel, OpenEntity), with no changes to the LM whatsoever, metadata shaping exceeds the BERT-baseline by up to 5.3 F1 points, and achieves or competes with state-of-the-art results. We further show the improvements are up to 10x larger on examples containing tail versus popular entities.
End-to-End Deep Learning of Long-Haul Coherent Optical Fiber Communications via Regular Perturbation Model
Jul 26, 2021
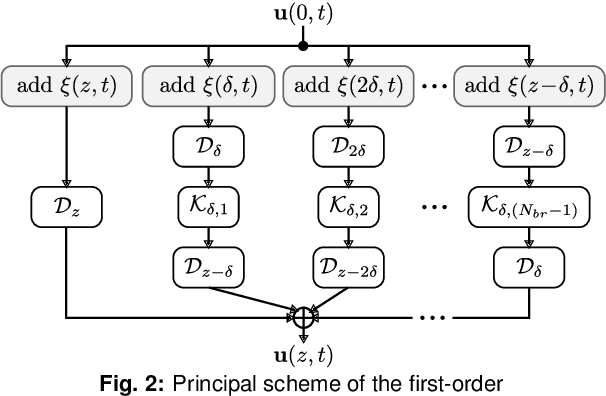
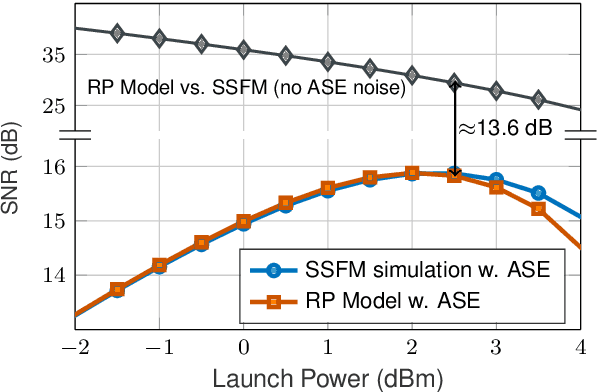
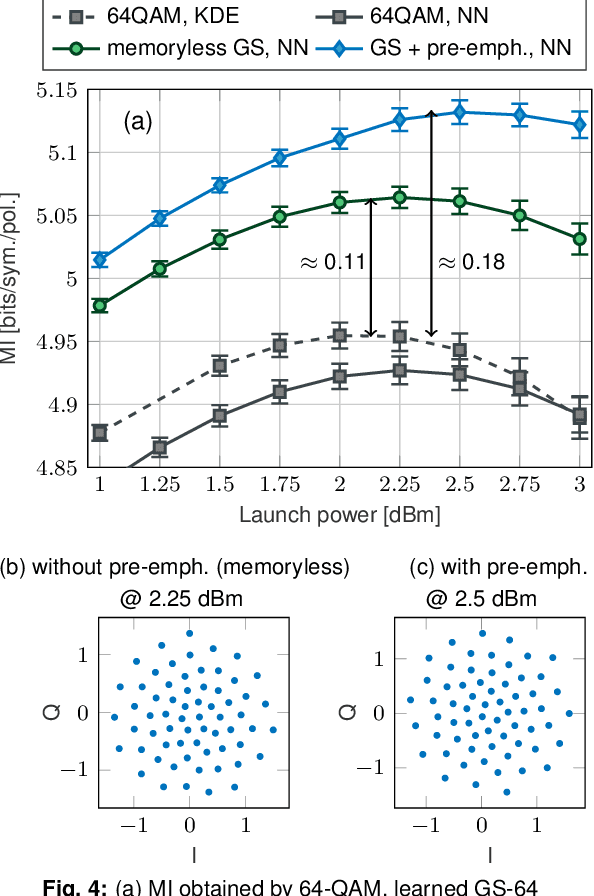
We present a novel end-to-end autoencoder-based learning for coherent optical communications using a "parallelizable" perturbative channel model. We jointly optimized constellation shaping and nonlinear pre-emphasis achieving mutual information gain of 0.18 bits/sym./pol. simulating 64 GBd dual-polarization single-channel transmission over 30x80 km G.652 SMF link with EDFAs.
From Textual Information Sources to Linked Data in the Agatha Project
Sep 03, 2019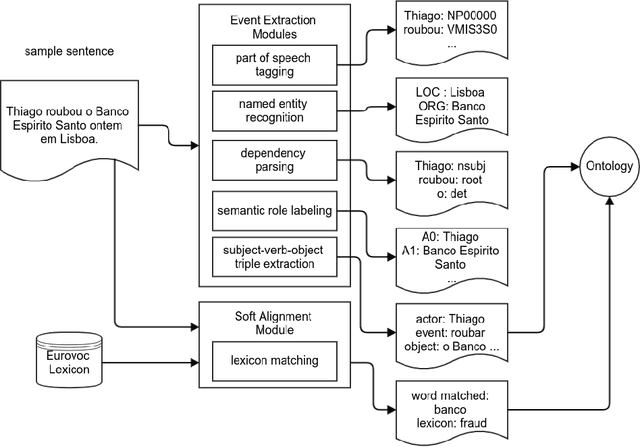
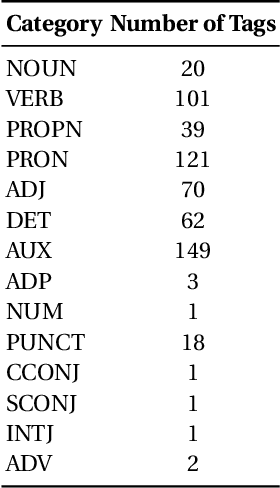
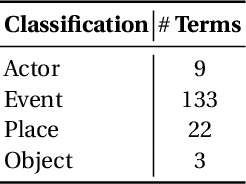
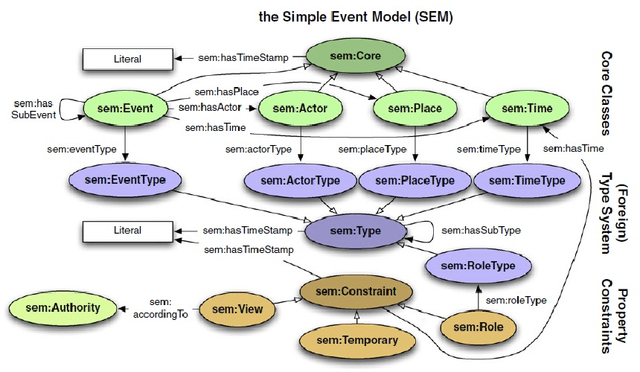
Automatic reasoning about textual information is a challenging task in modern Natural Language Processing (NLP) systems. In this work we describe our proposal for representing and reasoning about Portuguese documents by means of Linked Data like ontologies and thesauri. Our approach resorts to a specialized pipeline of natural language processing (part-of-speech tagger, named entity recognition, semantic role labeling) to populate an ontology for the domain of criminal investigations. The provided architecture and ontology are language independent. Although some of the NLP modules are language dependent, they can be built using adequate AI methodologies.
Recurrent neural network models for working memory of continuous variables: activity manifolds, connectivity patterns, and dynamic codes
Nov 01, 2021
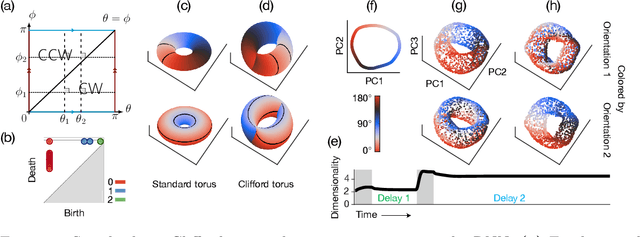
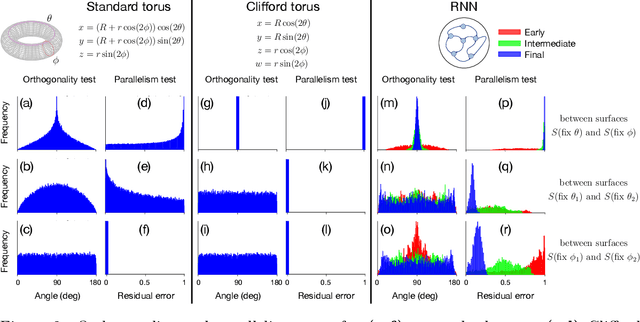
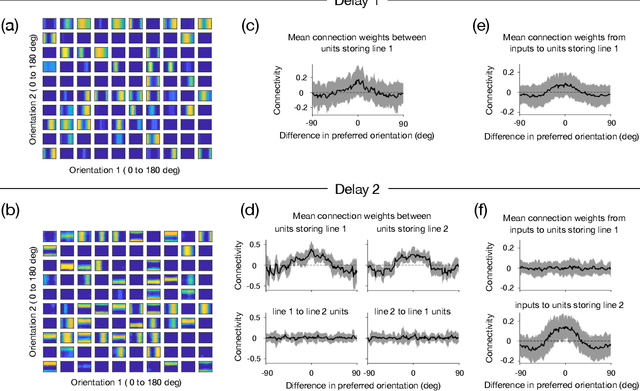
Many daily activities and psychophysical experiments involve keeping multiple items in working memory. When items take continuous values (e.g., orientation, contrast, length, loudness) they must be stored in a continuous structure of appropriate dimensions. We investigate how this structure is represented in neural circuits by training recurrent networks to report two previously shown stimulus orientations. We find the activity manifold for the two orientations resembles a Clifford torus. Although a Clifford and standard torus (the surface of a donut) are topologically equivalent, they have important functional differences. A Clifford torus treats the two orientations equally and keeps them in orthogonal subspaces, as demanded by the task, whereas a standard torus does not. We find and characterize the connectivity patterns that support the Clifford torus. Moreover, in addition to attractors that store information via persistent activity, our networks also use a dynamic code where units change their tuning to prevent new sensory input from overwriting the previously stored one. We argue that such dynamic codes are generally required whenever multiple inputs enter a memory system via shared connections. Finally, we apply our framework to a human psychophysics experiment in which subjects reported two remembered orientations. By varying the training conditions of the RNNs, we test and support the hypothesis that human behavior is a product of both neural noise and reliance on the more stable and behaviorally relevant memory of the ordinal relationship between the two orientations. This suggests that suitable inductive biases in RNNs are important for uncovering how the human brain implements working memory. Together, these results offer an understanding of the neural computations underlying a class of visual decoding tasks, bridging the scales from human behavior to synaptic connectivity.
Adaptive Sample Selection for Robust Learning under Label Noise
Jul 27, 2021



Deep Neural Networks (DNNs) have been shown to be susceptible to memorization or overfitting in the presence of noisily labelled data. For the problem of robust learning under such noisy data, several algorithms have been proposed. A prominent class of algorithms rely on sample selection strategies, motivated by curriculum learning. For example, many algorithms use the `small loss trick' wherein a fraction of samples with loss values below a certain threshold are selected for training. These algorithms are sensitive to such thresholds, and it is difficult to fix or learn these thresholds. Often, these algorithms also require information such as label noise rates which are typically unavailable in practice. In this paper, we propose a data-dependent, adaptive sample selection strategy that relies only on batch statistics of a given mini-batch to provide robustness against label noise. The algorithm does not have any additional hyperparameters for sample selection, does not need any information on noise rates, and does not need access to separate data with clean labels. We empirically demonstrate the effectiveness of our algorithm on benchmark datasets.