 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From Canonical Correlation Analysis to Self-supervised Graph Neural Networks
Jun 23, 2021

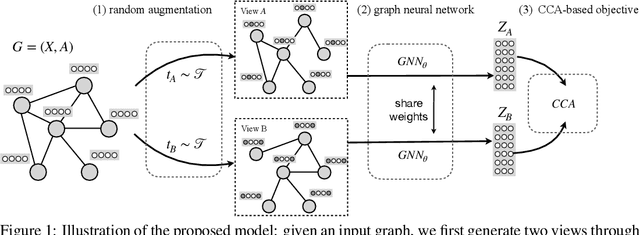
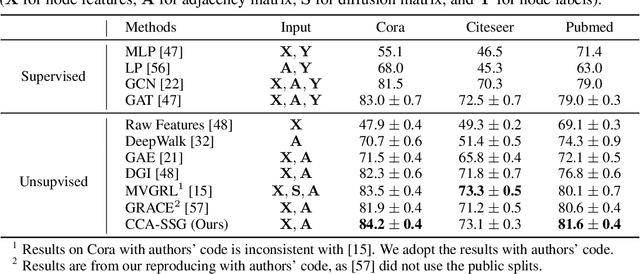
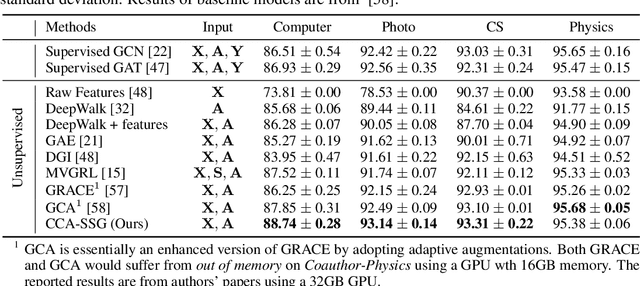
We introduce a conceptually simple yet effective model for self-supervised representation learning with graph data. It follows the previous methods that generate two views of an input graph through data augmentation. However, unlike contrastive methods that focus on instance-level discrimination, we optimize an innovative feature-level objective inspired by classical Canonical Correlation Analysis. Compared with other works, our approach requires none of the parameterized mutual information estimator, additional projector, asymmetric structures, and most importantly, negative samples which can be costly. We show that the new objective essentially 1) aims at discarding augmentation-variant information by learning invariant representations, and 2) can prevent degenerated solutions by decorrelating features in different dimensions. Our theoretical analysis further provides an understanding for the new objective which can be equivalently seen as an instantiation of the Information Bottleneck Principle under the self-supervised setting. Despite its simplicity, our method performs competitively on seven public graph datasets.
A/B/n Testing with Control in the Presence of Subpopulations
Oct 29, 2021
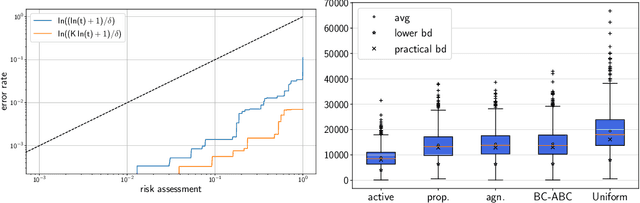
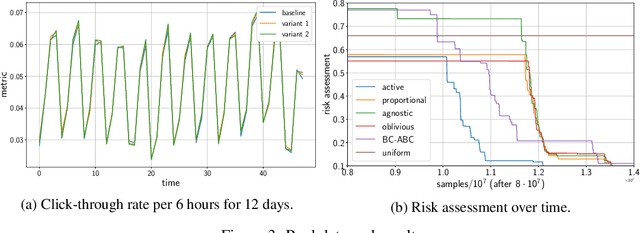

Motivated by A/B/n testing applications, we consider a finite set of distributions (called \emph{arms}), one of which is treated as a \emph{control}. We assume that the population is stratified into homogeneous subpopulations. At every time step, a subpopulation is sampled and an arm is chosen: the resulting observation is an independent draw from the arm conditioned on the subpopulation. The quality of each arm is assessed through a weighted combination of its subpopulation means. We propose a strategy for sequentially choosing one arm per time step so as to discover as fast as possible which arms, if any, have higher weighted expectation than the control. This strategy is shown to be asymptotically optimal in the following sense: if $\tau_\delta$ is the first time when the strategy ensures that it is able to output the correct answer with probability at least $1-\delta$, then $\mathbb{E}[\tau_\delta]$ grows linearly with $\log(1/\delta)$ at the exact optimal rate. This rate is identified in the paper in three different settings: (1) when the experimenter does not observe the subpopulation information, (2) when the subpopulation of each sample is observed but not chosen, and (3) when the experimenter can select the subpopulation from which each response is sampled. We illustrate the efficiency of the proposed strategy with numerical simulations on synthetic and real data collected from an A/B/n experiment.
Exposing Deepfake with Pixel-wise AR and PPG Correlation from Faint Signals
Oct 29, 2021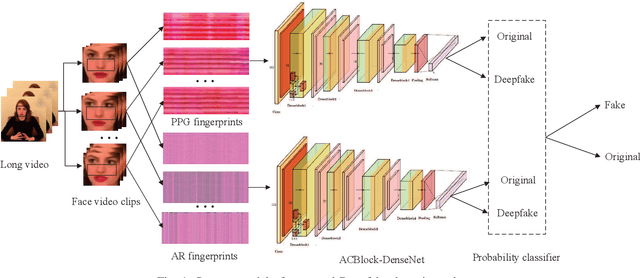
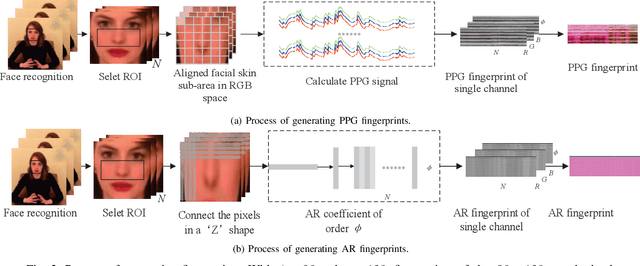

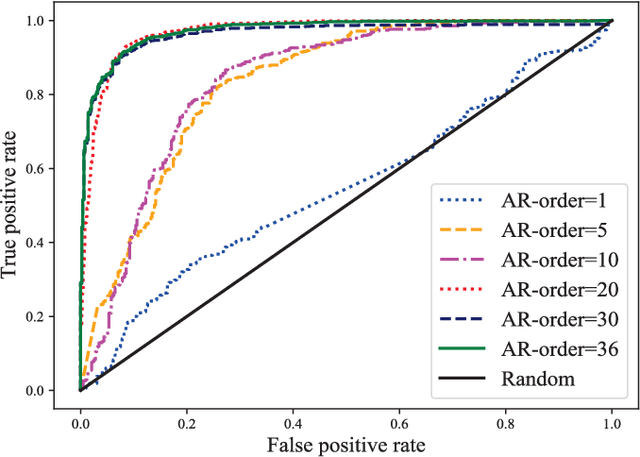
Deepfake poses a serious threat to the reliability of judicial evidence and intellectual property protection. In spite of an urgent need for Deepfake identification, existing pixel-level detection methods are increasingly unable to resist the growing realism of fake videos and lack generalization. In this paper, we propose a scheme to expose Deepfake through faint signals hidden in face videos. This scheme extracts two types of minute information hidden between face pixels-photoplethysmography (PPG) features and auto-regressive (AR) features, which are used as the basis for forensics in the temporal and spatial domains, respectively. According to the principle of PPG, tracking the absorption of light by blood cells allows remote estimation of the temporal domains heart rate (HR) of face video, and irregular HR fluctuations can be seen as traces of tampering. On the other hand, AR coefficients are able to reflect the inter-pixel correlation, and can also reflect the traces of smoothing caused by up-sampling in the process of generating fake faces. Furthermore, the scheme combines asymmetric convolution block (ACBlock)-based improved densely connected networks (DenseNets) to achieve face video authenticity forensics. Its asymmetric convolutional structure enhances the robustness of network to the input feature image upside-down and left-right flipping, so that the sequence of feature stitching does not affect detection results. Simulation results show that our proposed scheme provides more accurate authenticity detection results on multiple deep forgery datasets and has better generalization compared to the benchmark strategy.
Measuring Hidden Bias within Face Recognition via Racial Phenotypes
Oct 19, 2021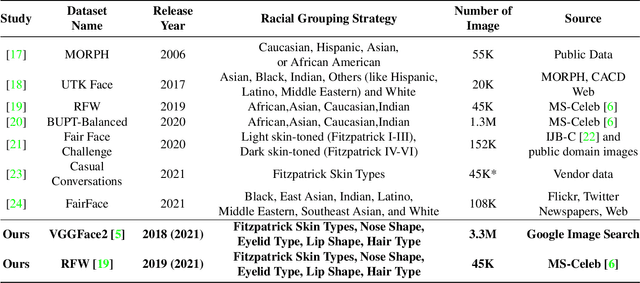
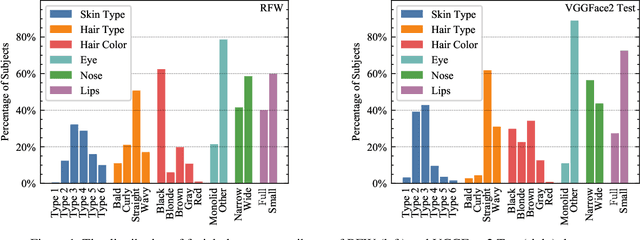

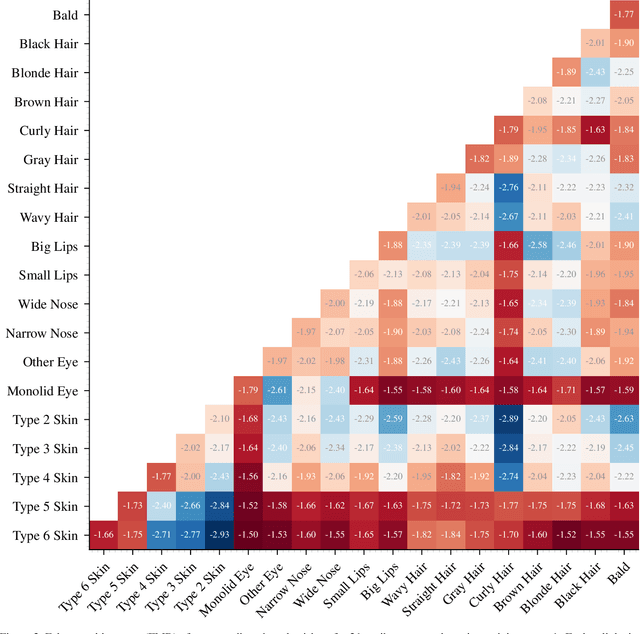
Recent work reports disparate performance for intersectional racial groups across face recognition tasks: face verification and identification. However, the definition of those racial groups has a significant impact on the underlying findings of such racial bias analysis. Previous studies define these groups based on either demographic information (e.g. African, Asian etc.) or skin tone (e.g. lighter or darker skins). The use of such sensitive or broad group definitions has disadvantages for bias investigation and subsequent counter-bias solutions design. By contrast, this study introduces an alternative racial bias analysis methodology via facial phenotype attributes for face recognition. We use the set of observable characteristics of an individual face where a race-related facial phenotype is hence specific to the human face and correlated to the racial profile of the subject. We propose categorical test cases to investigate the individual influence of those attributes on bias within face recognition tasks. We compare our phenotype-based grouping methodology with previous grouping strategies and show that phenotype-based groupings uncover hidden bias without reliance upon any potentially protected attributes or ill-defined grouping strategies. Furthermore, we contribute corresponding phenotype attribute category labels for two face recognition tasks: RFW for face verification and VGGFace2 (test set) for face identification.
Continual learning using lattice-free MMI for speech recognition
Oct 13, 2021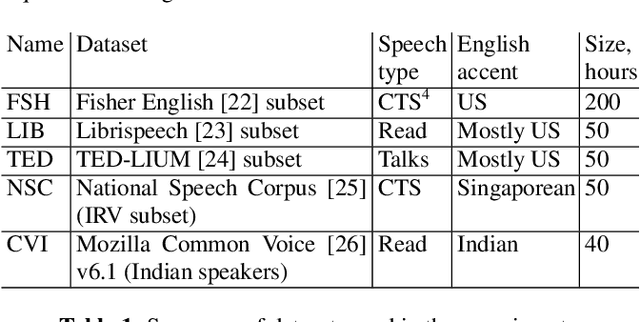
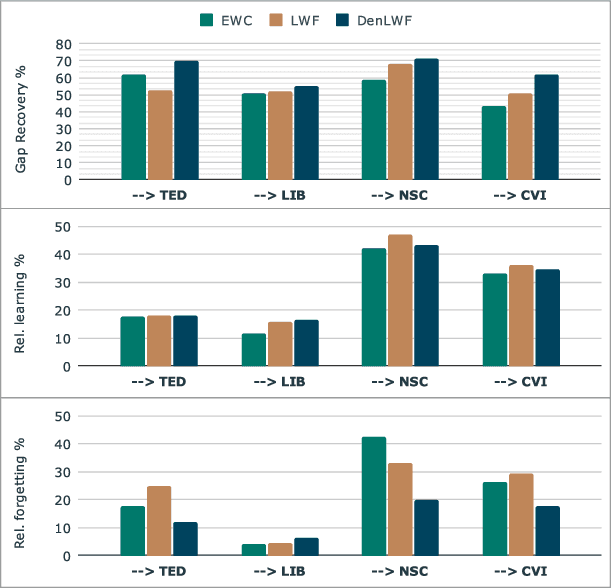

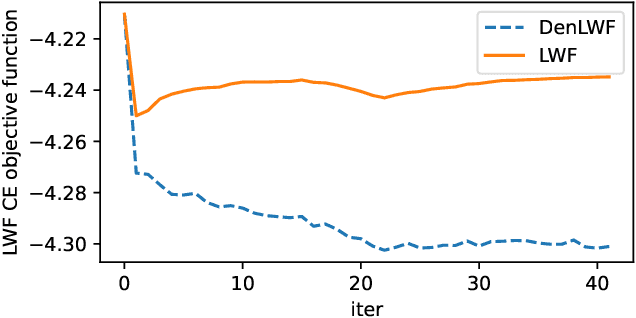
Continual learning (CL), or domain expansion, recently became a popular topic for automatic speech recognition (ASR) acoustic modeling because practical systems have to be updated frequently in order to work robustly on types of speech not observed during initial training. While sequential adaptation allows tuning a system to a new domain, it may result in performance degradation on the old domains due to catastrophic forgetting. In this work we explore regularization-based CL for neural network acoustic models trained with the lattice-free maximum mutual information (LF-MMI) criterion. We simulate domain expansion by incrementally adapting the acoustic model on different public datasets that include several accents and speaking styles. We investigate two well-known CL techniques, elastic weight consolidation (EWC) and learning without forgetting (LWF), which aim to reduce forgetting by preserving model weights or network outputs. We additionally introduce a sequence-level LWF regularization, which exploits posteriors from the denominator graph of LF-MMI to further reduce forgetting. Empirical results show that the proposed sequence-level LWF can improve the best average word error rate across all domains by up to 9.4% relative compared with using regular LWF.
Representation Learning for Remote Sensing: An Unsupervised Sensor Fusion Approach
Aug 11, 2021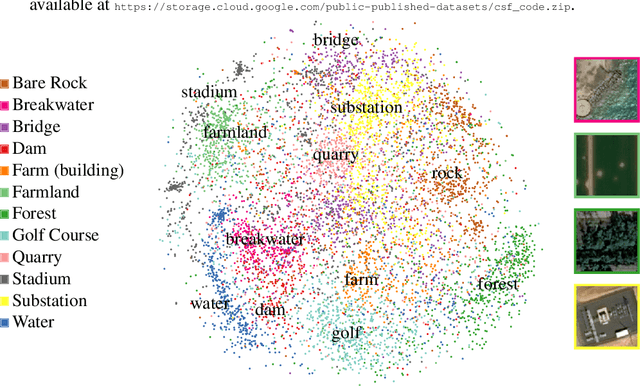
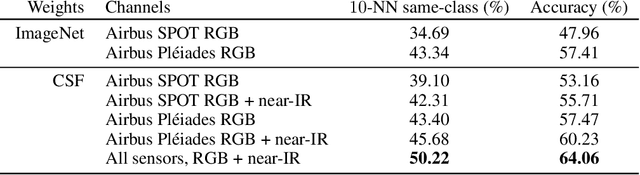

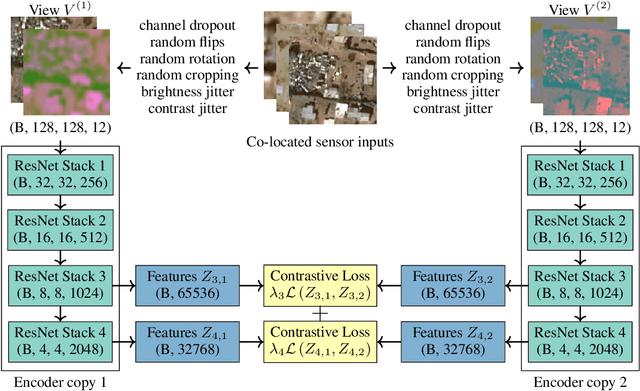
In the application of machine learning to remote sensing, labeled data is often scarce or expensive, which impedes the training of powerful models like deep convolutional neural networks. Although unlabeled data is abundant, recent self-supervised learning approaches are ill-suited to the remote sensing domain. In addition, most remote sensing applications currently use only a small subset of the multi-sensor, multi-channel information available, motivating the need for fused multi-sensor representations. We propose a new self-supervised training objective, Contrastive Sensor Fusion, which exploits coterminous data from multiple sources to learn useful representations of every possible combination of those sources. This method uses information common across multiple sensors and bands by training a single model to produce a representation that remains similar when any subset of its input channels is used. Using a dataset of 47 million unlabeled coterminous image triplets, we train an encoder to produce semantically meaningful representations from any possible combination of channels from the input sensors. These representations outperform fully supervised ImageNet weights on a remote sensing classification task and improve as more sensors are fused. Our code is available at https://storage.cloud.google.com/public-published-datasets/csf_code.zip.
Knowledge Sheaves: A Sheaf-Theoretic Framework for Knowledge Graph Embedding
Oct 07, 2021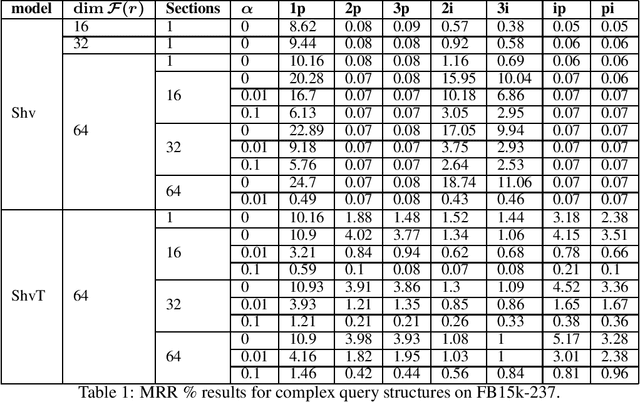
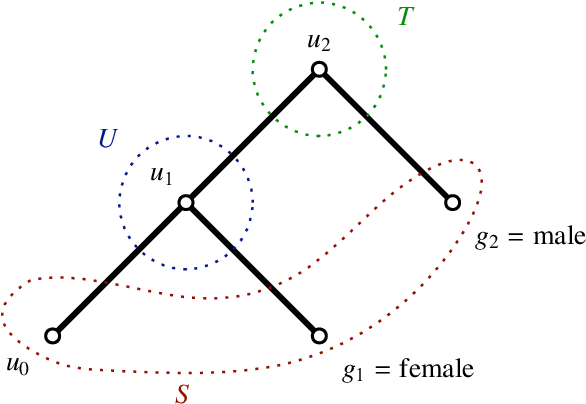
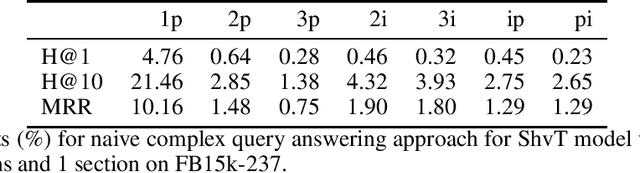
Knowledge graph embedding involves learning representations of entities -- the vertices of the graph -- and relations -- the edges of the graph -- such that the resulting representations encode the known factual information represented by the knowledge graph are internally consistent and can be used in the inference of new relations. We show that knowledge graph embedding is naturally expressed in the topological and categorical language of \textit{cellular sheaves}: learning a knowledge graph embedding corresponds to learning a \textit{knowledge sheaf} over the graph, subject to certain constraints. In addition to providing a generalized framework for reasoning about knowledge graph embedding models, this sheaf-theoretic perspective admits the expression of a broad class of prior constraints on embeddings and offers novel inferential capabilities. We leverage the recently developed spectral theory of sheaf Laplacians to understand the local and global consistency of embeddings and develop new methods for reasoning over composite relations through harmonic extension with respect to the sheaf Laplacian. We then implement these ideas to highlight the benefits of the extensions inspired by this new perspective.
Conversational Recommendation:Theoretical Model and Complexity Analysis
Nov 10, 2021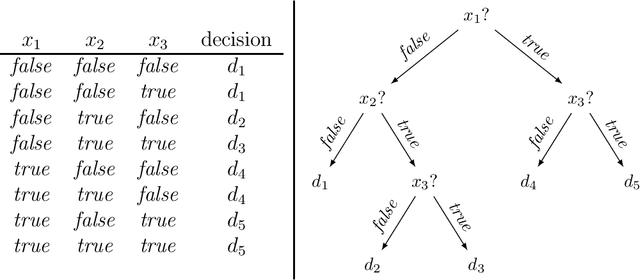


Recommender systems are software applications that help users find items of interest in situations of information overload in a personalized way, using knowledge about the needs and preferences of individual users. In conversational recommendation approaches, these needs and preferences are acquired by the system in an interactive, multi-turn dialog. A common approach in the literature to drive such dialogs is to incrementally ask users about their preferences regarding desired and undesired item features or regarding individual items. A central research goal in this context is efficiency, evaluated with respect to the number of required interactions until a satisfying item is found. This is usually accomplished by making inferences about the best next question to ask to the user. Today, research on dialog efficiency is almost entirely empirical, aiming to demonstrate, for example, that one strategy for selecting questions is better than another one in a given application. With this work, we complement empirical research with a theoretical, domain-independent model of conversational recommendation. This model, which is designed to cover a range of application scenarios, allows us to investigate the efficiency of conversational approaches in a formal way, in particular with respect to the computational complexity of devising optimal interaction strategies. Through such a theoretical analysis we show that finding an efficient conversational strategy is NP-hard, and in PSPACE in general, but for particular kinds of catalogs the upper bound lowers to POLYLOGSPACE. From a practical point of view, this result implies that catalog characteristics can strongly influence the efficiency of individual conversational strategies and should therefore be considered when designing new strategies. A preliminary empirical analysis on datasets derived from a real-world one aligns with our findings.
Multiple Graph Learning for Scalable Multi-view Clustering
Jun 29, 2021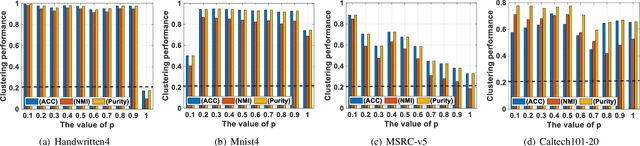
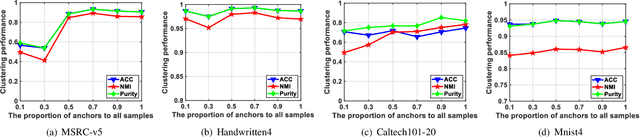
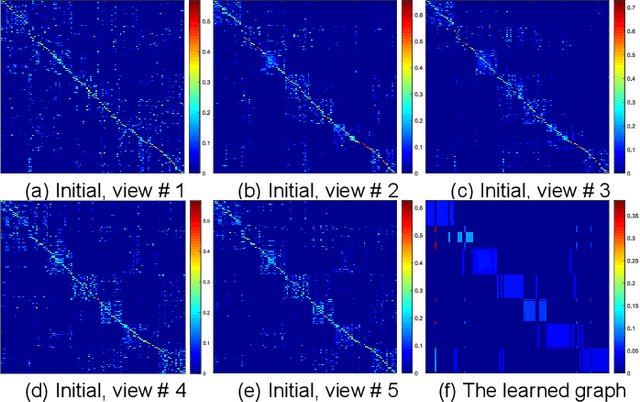
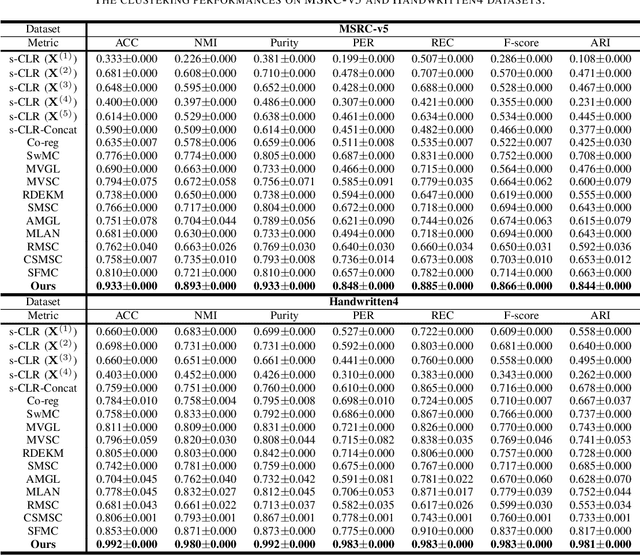
Graph-based multi-view clustering has become an active topic due to the efficiency in characterizing both the complex structure and relationship between multimedia data. However, existing methods have the following shortcomings: (1) They are inefficient or even fail for graph learning in large scale due to the graph construction and eigen-decomposition. (2) They cannot well exploit both the complementary information and spatial structure embedded in graphs of different views. To well exploit complementary information and tackle the scalability issue plaguing graph-based multi-view clustering, we propose an efficient multiple graph learning model via a small number of anchor points and tensor Schatten p-norm minimization. Specifically, we construct a hidden and tractable large graph by anchor graph for each view and well exploit complementary information embedded in anchor graphs of different views by tensor Schatten p-norm regularizer. Finally, we develop an efficient algorithm, which scales linearly with the data size, to solve our proposed model. Extensive experimental results on several datasets indicate that our proposed method outperforms some state-of-the-art multi-view clustering algorithms.
QAInfomax: Learning Robust Question Answering System by Mutual Information Maximization
Aug 31, 2019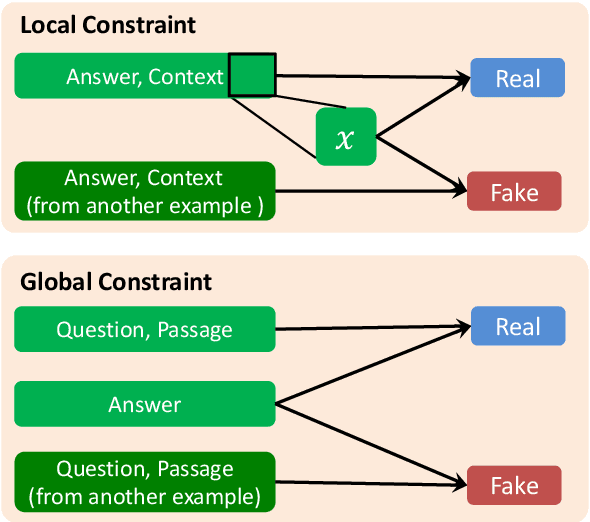
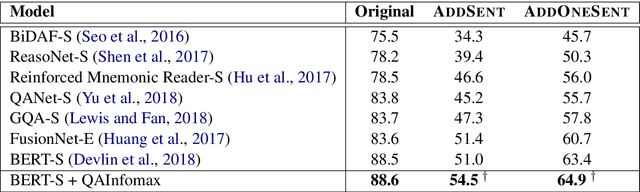

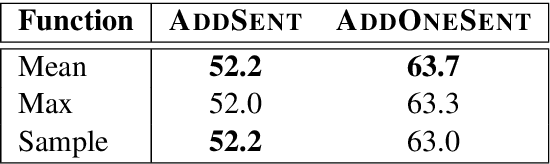
Standard accuracy metrics indicate that modern reading comprehension systems have achieved strong performance in many question answering datasets. However, the extent these systems truly understand language remains unknown, and existing systems are not good at distinguishing distractor sentences, which look related but do not actually answer the question. To address this problem, we propose QAInfomax as a regularizer in reading comprehension systems by maximizing mutual information among passages, a question, and its answer. QAInfomax helps regularize the model to not simply learn the superficial correlation for answering questions. The experiments show that our proposed QAInfomax achieves the state-of-the-art performance on the benchmark Adversarial-SQuAD dataset.