 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Word embeddings for topic modeling: an application to the estimation of the economic policy uncertainty index
Oct 29, 2021
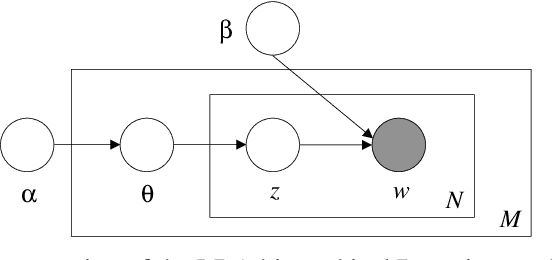
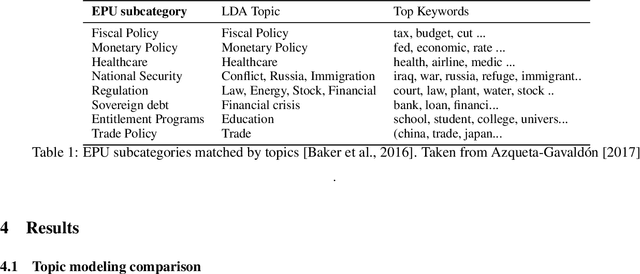
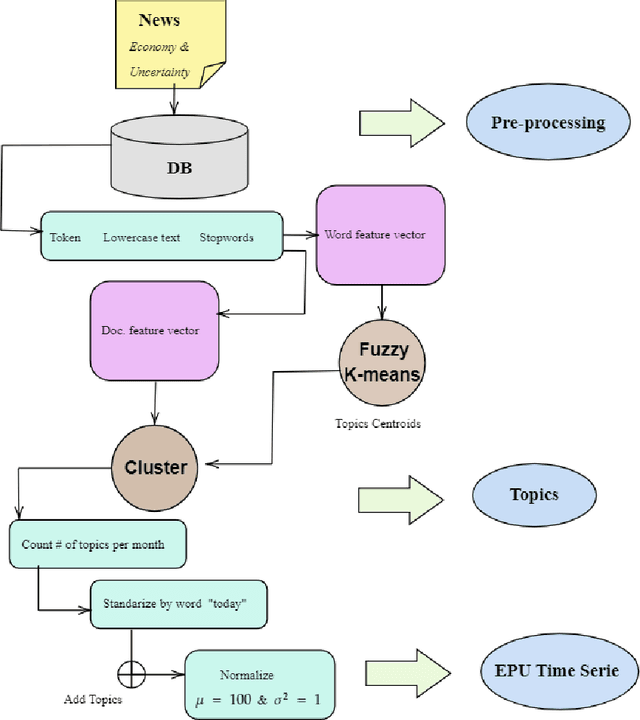
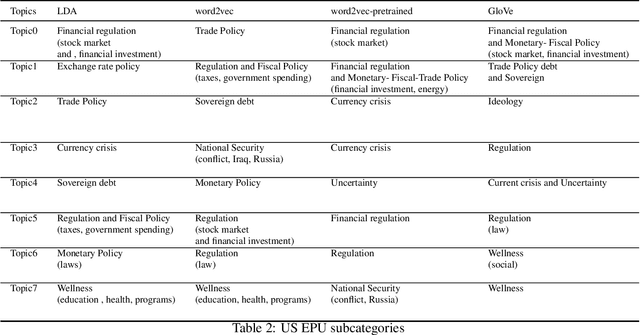
Quantification of economic uncertainty is a key concept for the prediction of macro economic variables such as gross domestic product (GDP), and it becomes particularly relevant on real-time or short-time predictions methodologies, such as nowcasting, where it is required a large amount of time series data, commonly with different structures and frequencies. Most of the data comes from the official agencies statistics and non-public institutions, however, relying our estimates in just the traditional data mentioned before, have some disadvantages. One of them is that economic uncertainty could not be represented or measured in a proper way based solely in financial or macroeconomic data, another one, is that they are susceptible to lack of information due to extraordinary events, such as the current COVID-19 pandemic. For these reasons, it is very common nowadays to use some non-traditional data from different sources, such as social networks or digital newspapers, in addition to the traditional data from official sources. The economic policy uncertainty (EPU) index, is the most used newspaper-based indicator to quantify the uncertainty, and is based on topic modeling of newspapers. In this paper, we propose a methodology to estimate the EPU index, which incorporates a fast and efficient method for topic modeling of digital news based on semantic clustering with word embeddings, allowing to update the index in real-time, which is a drawback with another proposals that use computationally intensive methods for topic modeling, such as Latent Dirichlet Allocation (LDA). We show that our proposal allow us to update the index and significantly reduces the time required for new document assignation into topics.
Fast Attributed Graph Embedding via Density of States
Oct 11, 2021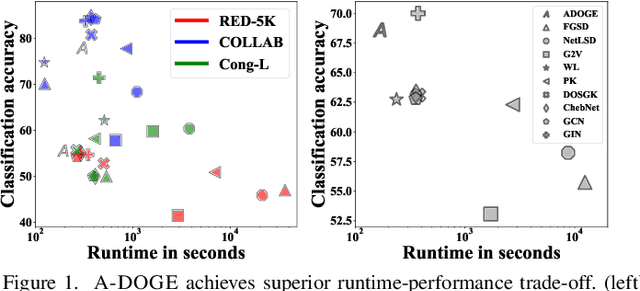
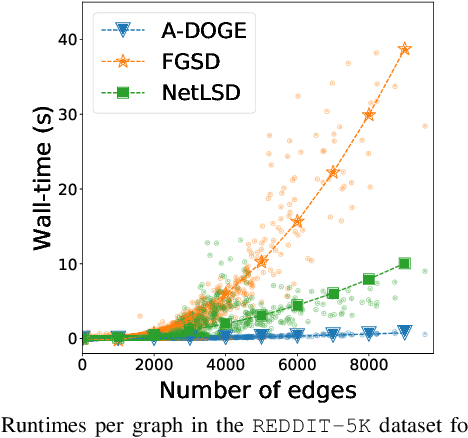
Given a node-attributed graph, how can we efficiently represent it with few numerical features that expressively reflect its topology and attribute information? We propose A-DOGE, for Attributed DOS-based Graph Embedding, based on density of states (DOS, a.k.a. spectral density) to tackle this problem. A-DOGE is designed to fulfill a long desiderata of desirable characteristics. Most notably, it capitalizes on efficient approximation algorithms for DOS, that we extend to blend in node labels and attributes for the first time, making it fast and scalable for large attributed graphs and graph databases. Being based on the entire eigenspectrum of a graph, A-DOGE can capture structural and attribute properties at multiple ("glocal") scales. Moreover, it is unsupervised (i.e. agnostic to any specific objective) and lends itself to various interpretations, which makes it is suitable for exploratory graph mining tasks. Finally, it processes each graph independent of others, making it amenable for streaming settings as well as parallelization. Through extensive experiments, we show the efficacy and efficiency of A-DOGE on exploratory graph analysis and graph classification tasks, where it significantly outperforms unsupervised baselines and achieves competitive performance with modern supervised GNNs, while achieving the best trade-off between accuracy and runtime.
Explore before Moving: A Feasible Path Estimation and Memory Recalling Framework for Embodied Navigation
Oct 16, 2021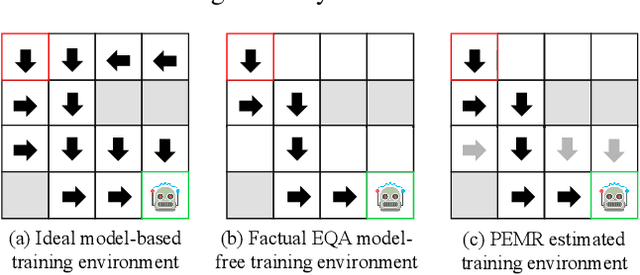
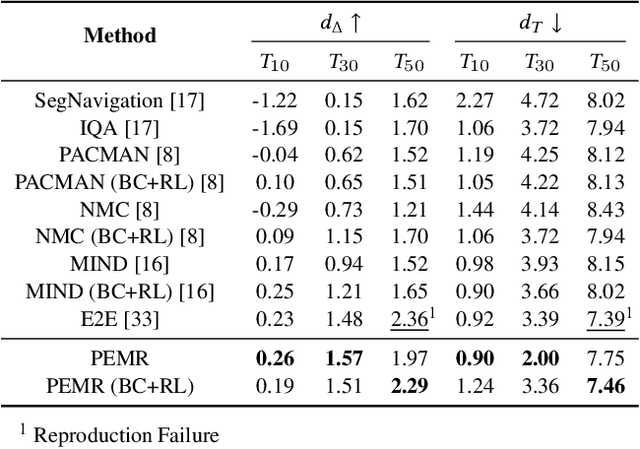
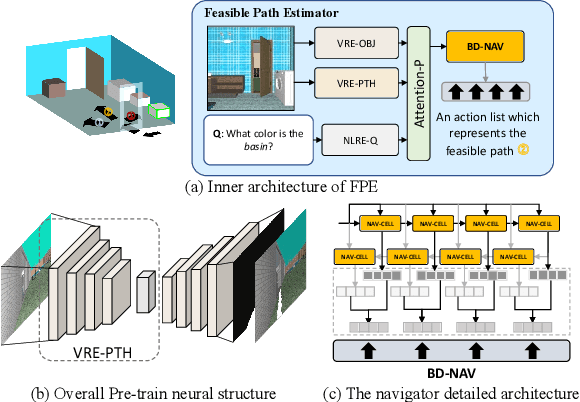
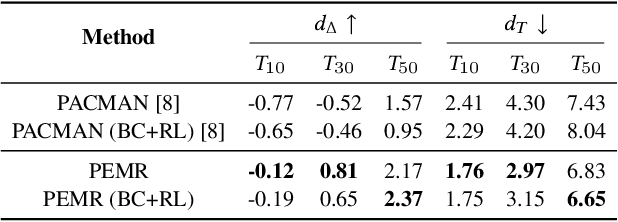
An embodied task such as embodied question answering (EmbodiedQA), requires an agent to explore the environment and collect clues to answer a given question that related with specific objects in the scene. The solution of such task usually includes two stages, a navigator and a visual Q&A module. In this paper, we focus on the navigation and solve the problem of existing navigation algorithms lacking experience and common sense, which essentially results in a failure finding target when robot is spawn in unknown environments. Inspired by the human ability to think twice before moving and conceive several feasible paths to seek a goal in unfamiliar scenes, we present a route planning method named Path Estimation and Memory Recalling (PEMR) framework. PEMR includes a "looking ahead" process, \textit{i.e.} a visual feature extractor module that estimates feasible paths for gathering 3D navigational information, which is mimicking the human sense of direction. PEMR contains another process ``looking behind'' process that is a memory recall mechanism aims at fully leveraging past experience collected by the feature extractor. Last but not the least, to encourage the navigator to learn more accurate prior expert experience, we improve the original benchmark dataset and provide a family of evaluation metrics for diagnosing both navigation and question answering modules. We show strong experimental results of PEMR on the EmbodiedQA navigation task.
RAIN: Reinforced Hybrid Attention Inference Network for Motion Forecasting
Aug 03, 2021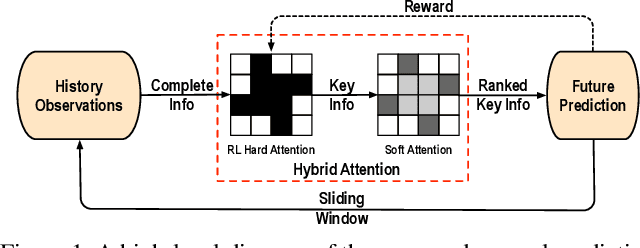
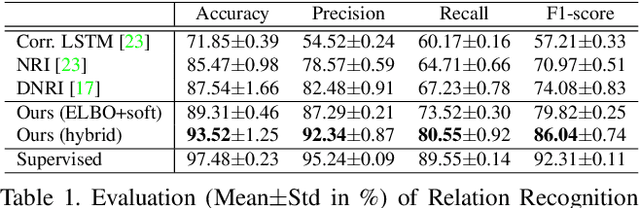
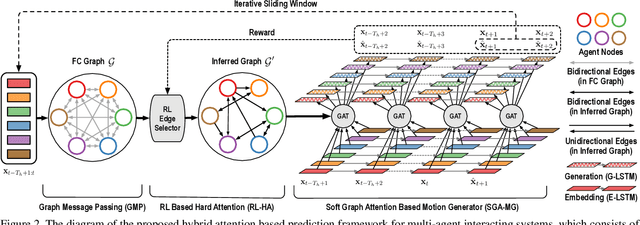
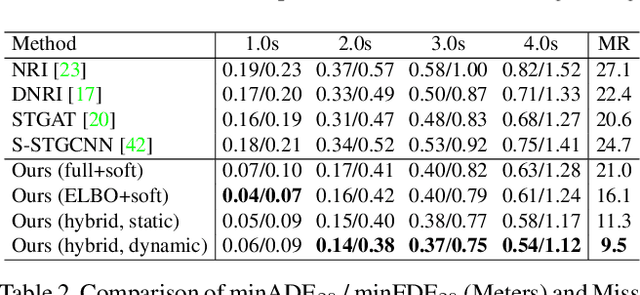
Motion forecasting plays a significant role in various domains (e.g., autonomous driving, human-robot interaction), which aims to predict future motion sequences given a set of historical observations. However, the observed elements may be of different levels of importance. Some information may be irrelevant or even distracting to the forecasting in certain situations. To address this issue, we propose a generic motion forecasting framework (named RAIN) with dynamic key information selection and ranking based on a hybrid attention mechanism. The general framework is instantiated to handle multi-agent trajectory prediction and human motion forecasting tasks, respectively. In the former task, the model learns to recognize the relations between agents with a graph representation and to determine their relative significance. In the latter task, the model learns to capture the temporal proximity and dependency in long-term human motions. We also propose an effective double-stage training pipeline with an alternating training strategy to optimize the parameters in different modules of the framework. We validate the framework on both synthetic simulations and motion forecasting benchmarks in different domains, demonstrating that our method not only achieves state-of-the-art forecasting performance, but also provides interpretable and reasonable hybrid attention weights.
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
Jul 21, 2021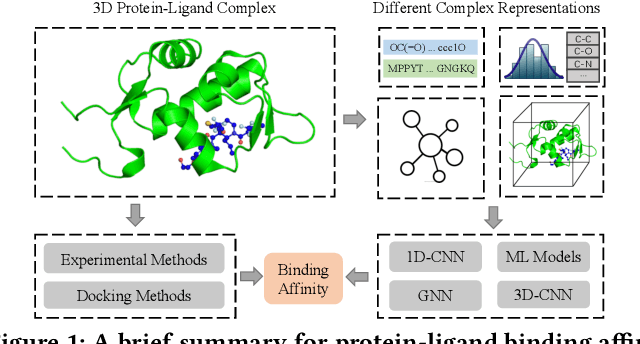
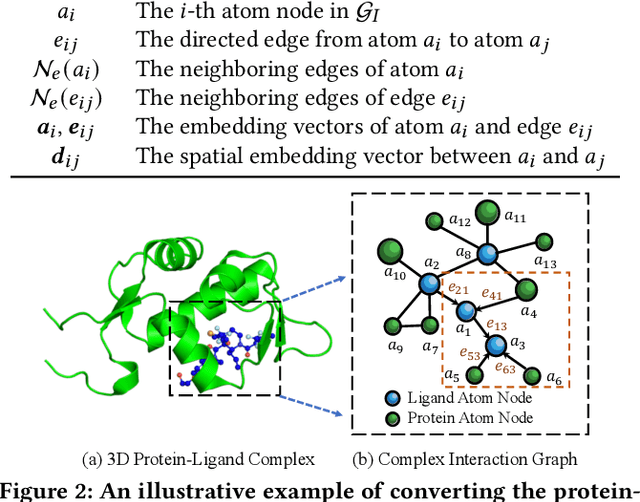
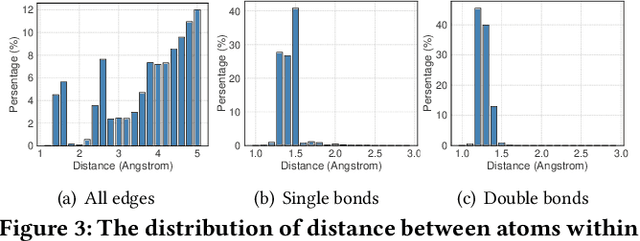
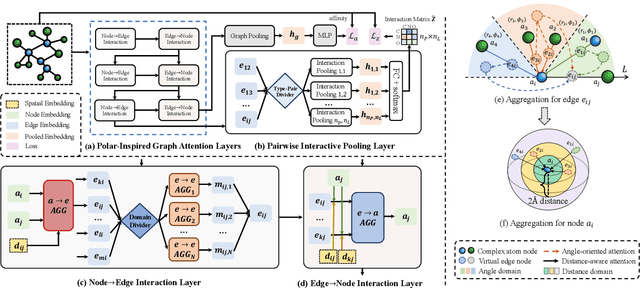
Drug discovery often relies on the successful prediction of protein-ligand binding affinity. Recent advances have shown great promise in applying graph neural networks (GNNs) for better affinity prediction by learning the representations of protein-ligand complexes. However, existing solutions usually treat protein-ligand complexes as topological graph data, thus the biomolecular structural information is not fully utilized. The essential long-range interactions among atoms are also neglected in GNN models. To this end, we propose a structure-aware interactive graph neural network (SIGN) which consists of two components: polar-inspired graph attention layers (PGAL) and pairwise interactive pooling (PiPool). Specifically, PGAL iteratively performs the node-edge aggregation process to update embeddings of nodes and edges while preserving the distance and angle information among atoms. Then, PiPool is adopted to gather interactive edges with a subsequent reconstruction loss to reflect the global interactions. Exhaustive experimental study on two benchmarks verifies the superiority of SIGN.
Understanding Individual Neuron Importance Using Information Theory
Apr 18, 2018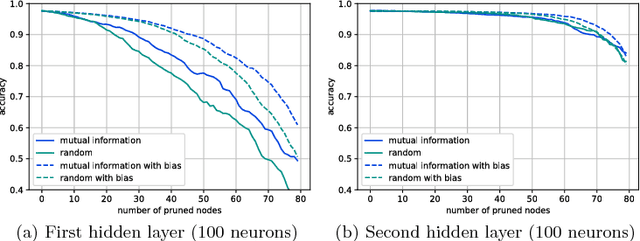
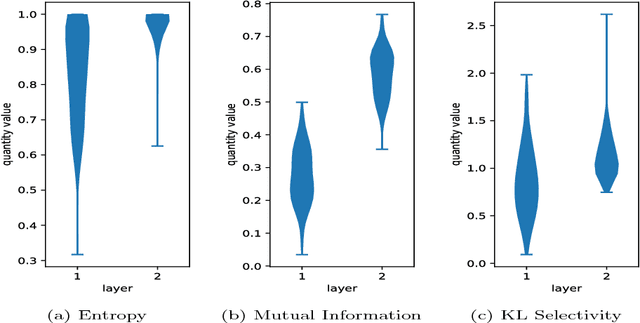
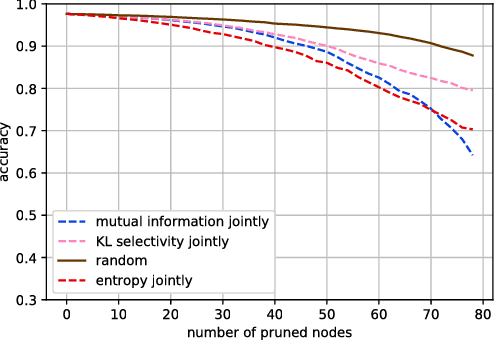
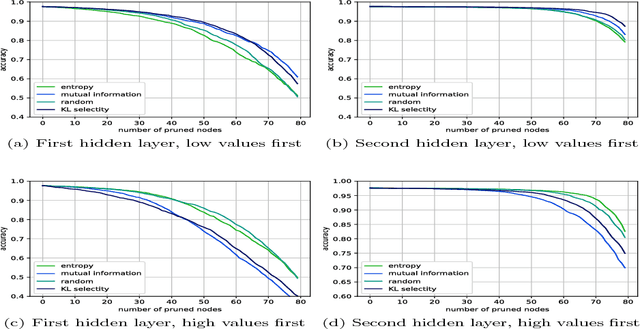
In this work, we characterize the outputs of individual neurons in a trained feed-forward neural network by entropy, mutual information with the class variable, and a class selectivity measure based on Kullback-Leibler divergence. By cumulatively ablating neurons in the network, we connect these information-theoretic measures to the impact their removal has on classification performance on the test set. We observe that, looking at the neural network as a whole, none of these measures is a good indicator for classification performance, thus confirming recent results by Morcos et al. However, looking at specific layers separately, both mutual information and class selectivity are positively correlated with classification performance. We thus conclude that it is ill-advised to compare these measures across layers, and that different layers may be most appropriately characterized by different measures. We then discuss pruning neurons from neural networks to reduce computational complexity of inference. Drawing from our results, we perform pruning based on information-theoretic measures on a fully connected feed-forward neural network with two hidden layers trained on MNIST dataset and compare the results to a recently proposed pruning method. We furthermore show that the common practice of re-training after pruning can partly be obviated by a surgery step called bias balancing, without incurring significant performance degradation.
Simultaneously Transmitting and Reflecting (STAR)-RISs: A Coupled Phase-Shift Model
Oct 05, 2021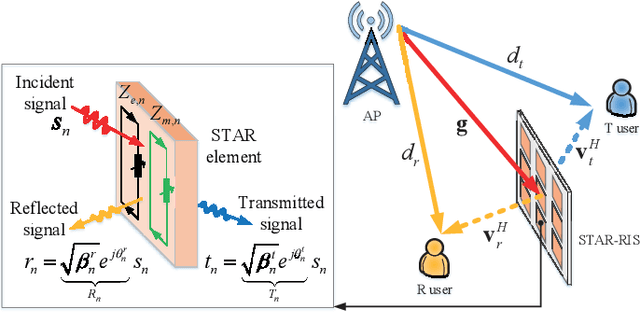
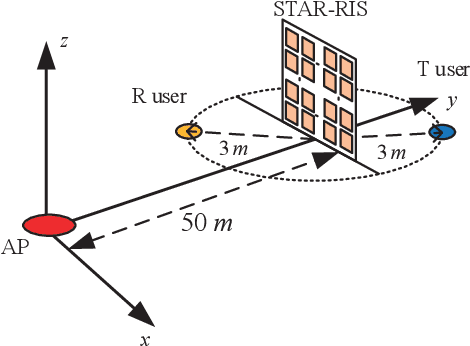
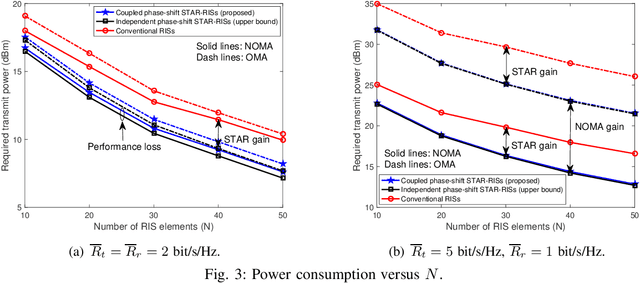
A simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) aided communication system is investigated, where an access point sends information to two users located on each side of the STAR-RIS. Different from current works assuming that the phase-shift coefficients for transmission and reflection can be independently adjusted, which is non-trivial to realize for purely passive STAR-RISs, a coupled transmission and reflection phase-shift model is considered. Based on this model, a power consumption minimization problem is formulated for both non-orthogonal multiple access (NOMA) and orthogonal multiple access (OMA). In particular, the amplitude and phase-shift coefficients for transmission and reflection are jointly optimized, subject to the rate constraints of the users. To solve this non-convex problem, an efficient element-wise alternating optimization algorithm is developed to find a high-quality suboptimal solution, whose complexity scales only linearly with the number of STAR elements. Finally, numerical results are provided for both NOMA and OMA to validate the effectiveness of the proposed algorithm by comparing its performance with that of STAR-RISs using the independent phase-shift model and conventional reflecting/transmitting-only RISs.
Adversarial defenses via a mixture of generators
Oct 05, 2021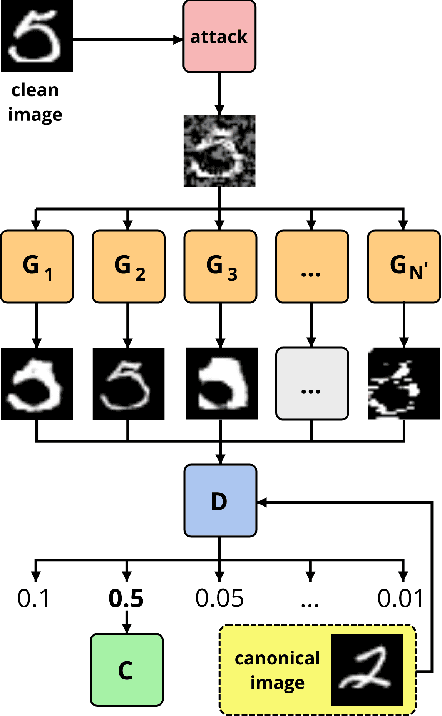


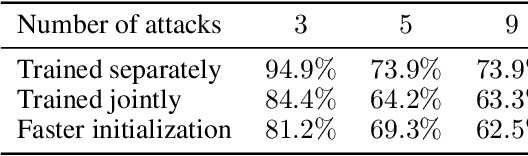
In spite of the enormous success of neural networks, adversarial examples remain a relatively weakly understood feature of deep learning systems. There is a considerable effort in both building more powerful adversarial attacks and designing methods to counter the effects of adversarial examples. We propose a method to transform the adversarial input data through a mixture of generators in order to recover the correct class obfuscated by the adversarial attack. A canonical set of images is used to generate adversarial examples through potentially multiple attacks. Such transformed images are processed by a set of generators, which are trained adversarially as a whole to compete in inverting the initial transformations. To our knowledge, this is the first use of a mixture-based adversarially trained system as a defense mechanism. We show that it is possible to train such a system without supervision, simultaneously on multiple adversarial attacks. Our system is able to recover class information for previously-unseen examples with neither attack nor data labels on the MNIST dataset. The results demonstrate that this multi-attack approach is competitive with adversarial defenses tested in single-attack settings.
Dynamic Feature Regularized Loss for Weakly Supervised Semantic Segmentation
Aug 03, 2021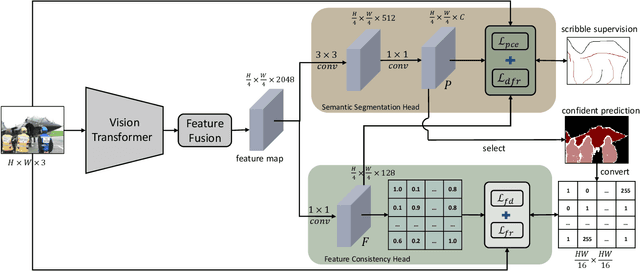
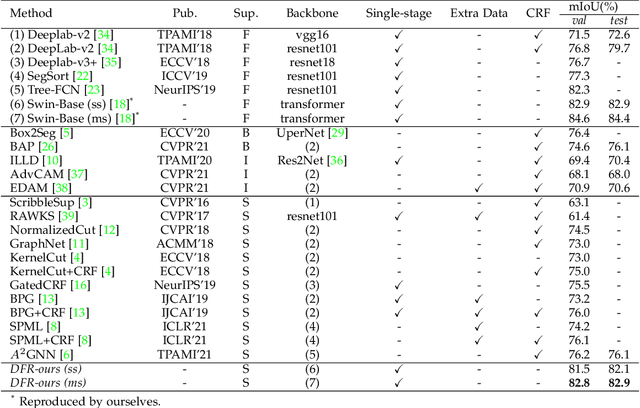
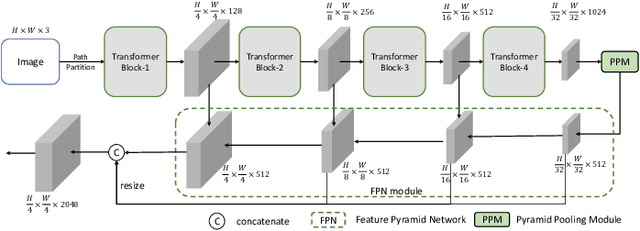

We focus on tackling weakly supervised semantic segmentation with scribble-level annotation. The regularized loss has been proven to be an effective solution for this task. However, most existing regularized losses only leverage static shallow features (color, spatial information) to compute the regularized kernel, which limits its final performance since such static shallow features fail to describe pair-wise pixel relationship in complicated cases. In this paper, we propose a new regularized loss which utilizes both shallow and deep features that are dynamically updated in order to aggregate sufficient information to represent the relationship of different pixels. Moreover, in order to provide accurate deep features, we adopt vision transformer as the backbone and design a feature consistency head to train the pair-wise feature relationship. Unlike most approaches that adopt multi-stage training strategy with many bells and whistles, our approach can be directly trained in an end-to-end manner, in which the feature consistency head and our regularized loss can benefit from each other. Extensive experiments show that our approach achieves new state-of-the-art performances, outperforming other approaches by a significant margin with more than 6\% mIoU increase.
Iterative Rule Extension for Logic Analysis of Data: an MILP-based heuristic to derive interpretable binary classification from large datasets
Oct 25, 2021
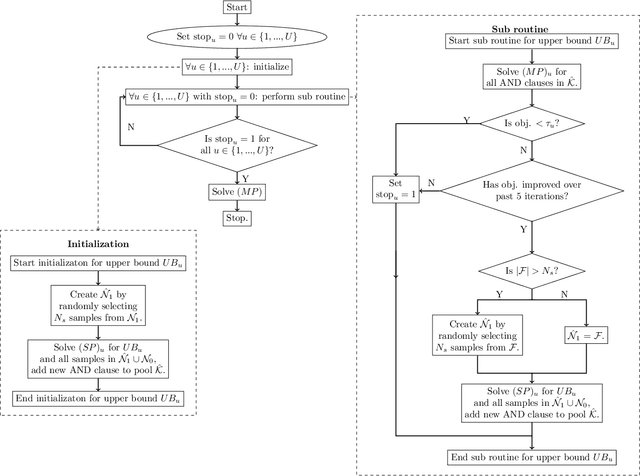
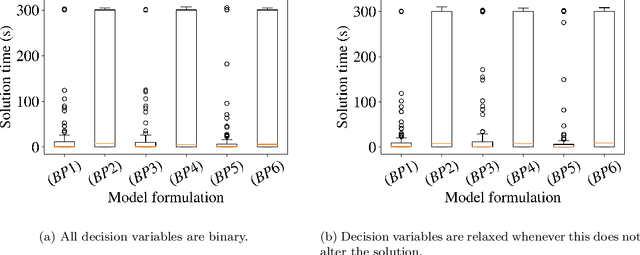
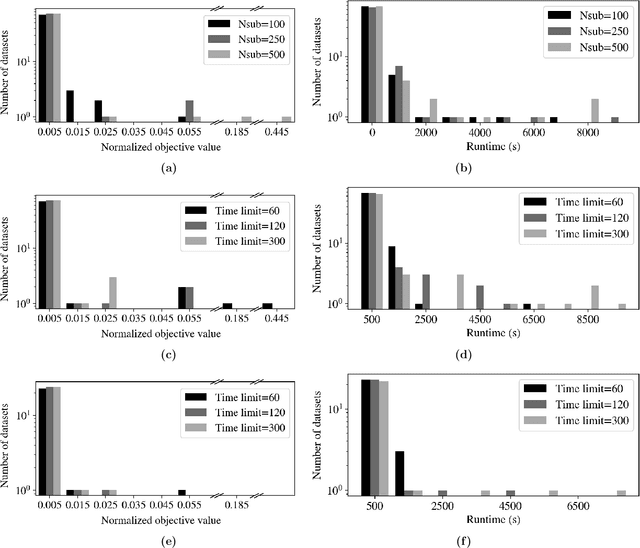
Data-driven decision making is rapidly gaining popularity, fueled by the ever-increasing amounts of available data and encouraged by the development of models that can identify beyond linear input-output relationships. Simultaneously the need for interpretable prediction- and classification methods is increasing, as this improves both our trust in these models and the amount of information we can abstract from data. An important aspect of this interpretability is to obtain insight in the sensitivity-specificity trade-off constituted by multiple plausible input-output relationships. These are often shown in a receiver operating characteristic (ROC) curve. These developments combined lead to the need for a method that can abstract complex yet interpretable input-output relationships from large data, i.e. data containing large numbers of samples and sample features. Boolean phrases in disjunctive normal form (DNF) are highly suitable for explaining non-linear input-output relationships in a comprehensible way. Mixed integer linear programming (MILP) can be used to abstract these Boolean phrases from binary data, though its computational complexity prohibits the analysis of large datasets. This work presents IRELAND, an algorithm that allows for abstracting Boolean phrases in DNF from data with up to 10,000 samples and sample characteristics. The results show that for large datasets IRELAND outperforms the current state-of-the-art and can find solutions for datasets where current models run out of memory or need excessive runtimes. Additionally, by construction IRELAND allows for an efficient computation of the sensitivity-specificity trade-off curve, allowing for further understanding of the underlying input-output relationship.