 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MSO: Multi-Feature Space Joint Optimization Network for RGB-Infrared Person Re-Identification
Oct 21, 2021
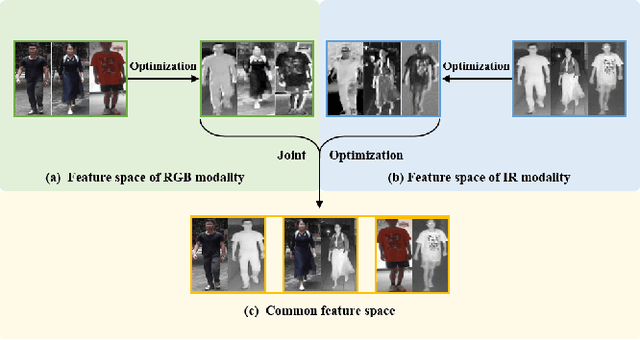
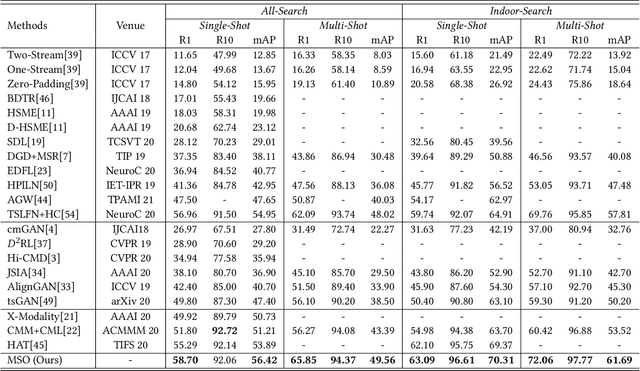
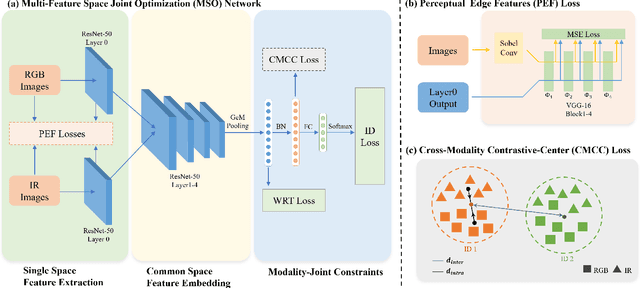
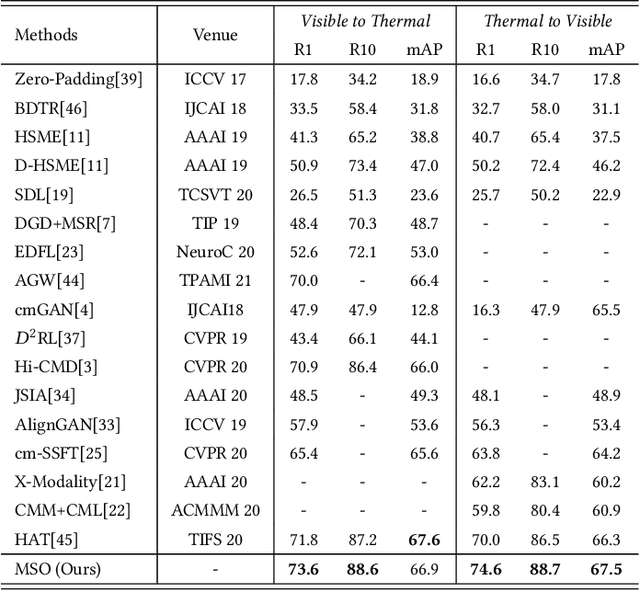
The RGB-infrared cross-modality person re-identification (ReID) task aims to recognize the images of the same identity between the visible modality and the infrared modality. Existing methods mainly use a two-stream architecture to eliminate the discrepancy between the two modalities in the final common feature space, which ignore the single space of each modality in the shallow layers. To solve it, in this paper, we present a novel multi-feature space joint optimization (MSO) network, which can learn modality-sharable features in both the single-modality space and the common space. Firstly, based on the observation that edge information is modality-invariant, we propose an edge features enhancement module to enhance the modality-sharable features in each single-modality space. Specifically, we design a perceptual edge features (PEF) loss after the edge fusion strategy analysis. According to our knowledge, this is the first work that proposes explicit optimization in the single-modality feature space on cross-modality ReID task. Moreover, to increase the difference between cross-modality distance and class distance, we introduce a novel cross-modality contrastive-center (CMCC) loss into the modality-joint constraints in the common feature space. The PEF loss and CMCC loss jointly optimize the model in an end-to-end manner, which markedly improves the network's performance. Extensive experiments demonstrate that the proposed model significantly outperforms state-of-the-art methods on both the SYSU-MM01 and RegDB datasets.
Process discovery on deviant traces and other stranger things
Sep 30, 2021
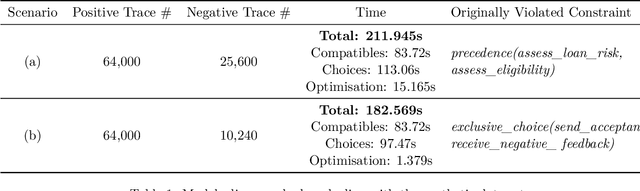
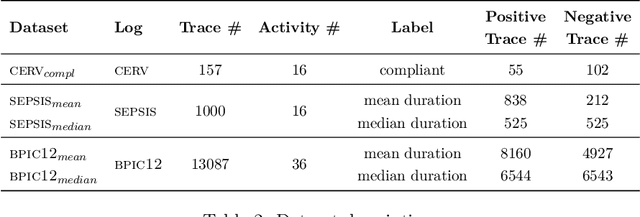

As the need to understand and formalise business processes into a model has grown over the last years, the process discovery research field has gained more and more importance, developing two different classes of approaches to model representation: procedural and declarative. Orthogonally to this classification, the vast majority of works envisage the discovery task as a one-class supervised learning process guided by the traces that are recorded into an input log. In this work instead, we focus on declarative processes and embrace the less-popular view of process discovery as a binary supervised learning task, where the input log reports both examples of the normal system execution, and traces representing "stranger" behaviours according to the domain semantics. We therefore deepen how the valuable information brought by both these two sets can be extracted and formalised into a model that is "optimal" according to user-defined goals. Our approach, namely NegDis, is evaluated w.r.t. other relevant works in this field, and shows promising results as regards both the performance and the quality of the obtained solution.
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
Jul 21, 2021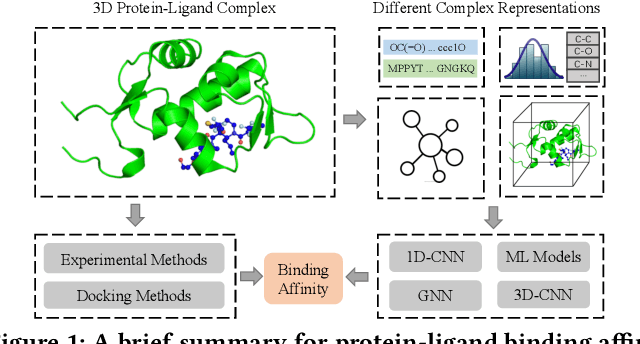
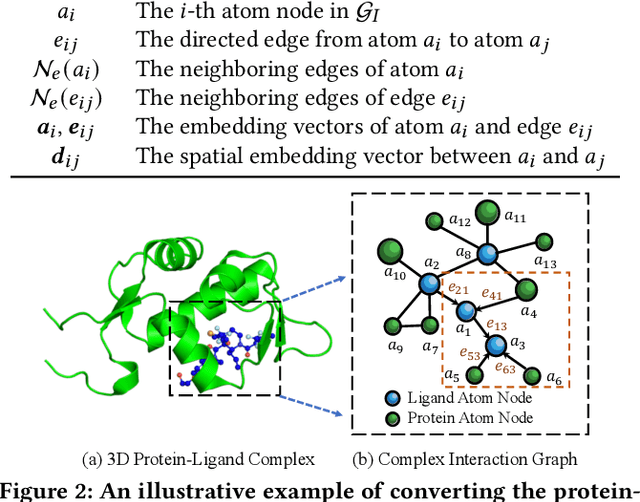
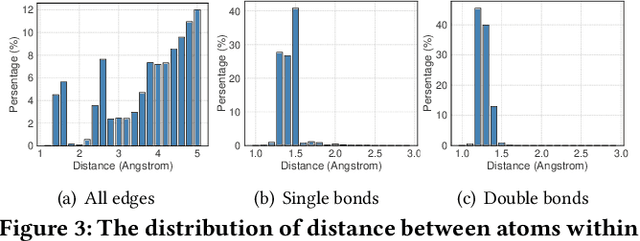
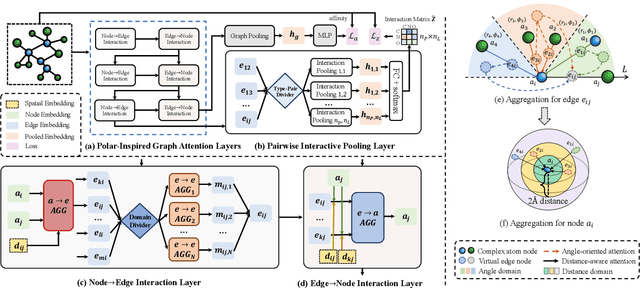
Drug discovery often relies on the successful prediction of protein-ligand binding affinity. Recent advances have shown great promise in applying graph neural networks (GNNs) for better affinity prediction by learning the representations of protein-ligand complexes. However, existing solutions usually treat protein-ligand complexes as topological graph data, thus the biomolecular structural information is not fully utilized. The essential long-range interactions among atoms are also neglected in GNN models. To this end, we propose a structure-aware interactive graph neural network (SIGN) which consists of two components: polar-inspired graph attention layers (PGAL) and pairwise interactive pooling (PiPool). Specifically, PGAL iteratively performs the node-edge aggregation process to update embeddings of nodes and edges while preserving the distance and angle information among atoms. Then, PiPool is adopted to gather interactive edges with a subsequent reconstruction loss to reflect the global interactions. Exhaustive experimental study on two benchmarks verifies the superiority of SIGN.
Exploring Classic and Neural Lexical Translation Models for Information Retrieval: Interpretability, Effectiveness, and Efficiency Benefits
Feb 12, 2021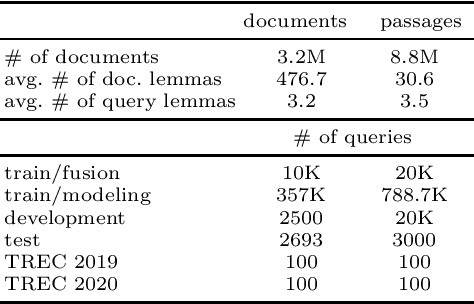

We study the utility of the lexical translation model (IBM Model 1) for English text retrieval, in particular, its neural variants that are trained end-to-end. We use the neural Model1 as an aggregator layer applied to context-free or contextualized query/document embeddings. This new approach to design a neural ranking system has benefits for effectiveness, efficiency, and interpretability. Specifically, we show that adding an interpretable neural Model 1 layer on top of BERT-based contextualized embeddings (1) does not decrease accuracy and/or efficiency; and (2) may overcome the limitation on the maximum sequence length of existing BERT models. The context-free neural Model 1 is less effective than a BERT-based ranking model, but it can run efficiently on a CPU (without expensive index-time precomputation or query-time operations on large tensors). Using Model 1 we produced best neural and non-neural runs on the MS MARCO document ranking leaderboard in late 2020.
Deep Supervised Hashing leveraging Quadratic Spherical Mutual Information for Content-based Image Retrieval
Jan 16, 2019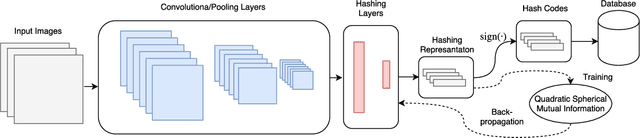

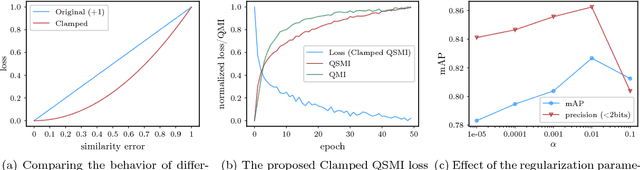
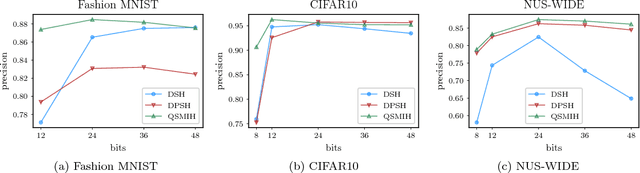
Several deep supervised hashing techniques have been proposed to allow for efficiently querying large image databases. However, deep supervised image hashing techniques are developed, to a great extent, heuristically often leading to suboptimal results. Contrary to this, we propose an efficient deep supervised hashing algorithm that optimizes the learned codes using an information-theoretic measure, the Quadratic Mutual Information (QMI). The proposed method is adapted to the needs of large-scale hashing and information retrieval leading to a novel information-theoretic measure, the Quadratic Spherical Mutual Information (QSMI). Apart from demonstrating the effectiveness of the proposed method under different scenarios and outperforming existing state-of-the-art image hashing techniques, this paper provides a structured way to model the process of information retrieval and develop novel methods adapted to the needs of each application.
RAIN: Reinforced Hybrid Attention Inference Network for Motion Forecasting
Aug 03, 2021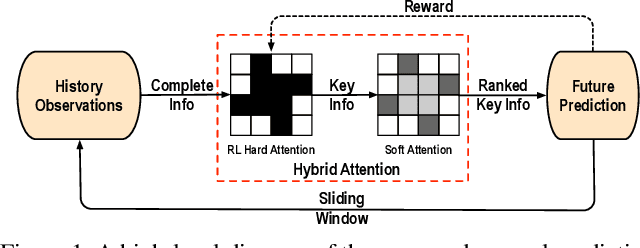
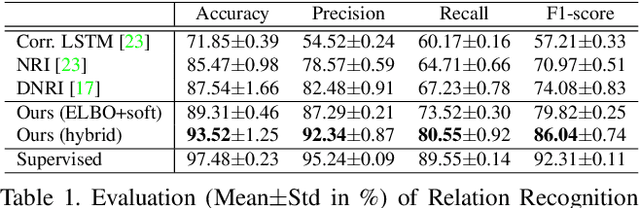
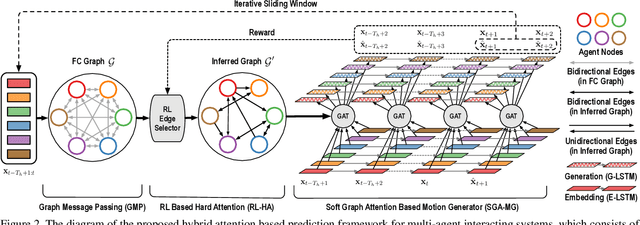
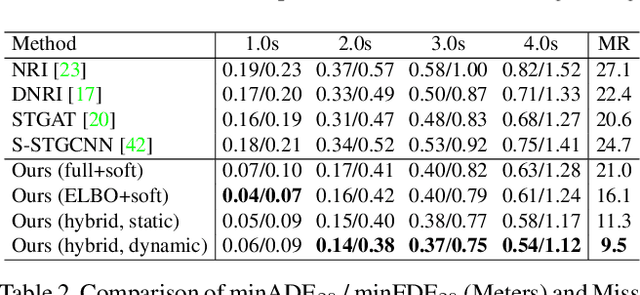
Motion forecasting plays a significant role in various domains (e.g., autonomous driving, human-robot interaction), which aims to predict future motion sequences given a set of historical observations. However, the observed elements may be of different levels of importance. Some information may be irrelevant or even distracting to the forecasting in certain situations. To address this issue, we propose a generic motion forecasting framework (named RAIN) with dynamic key information selection and ranking based on a hybrid attention mechanism. The general framework is instantiated to handle multi-agent trajectory prediction and human motion forecasting tasks, respectively. In the former task, the model learns to recognize the relations between agents with a graph representation and to determine their relative significance. In the latter task, the model learns to capture the temporal proximity and dependency in long-term human motions. We also propose an effective double-stage training pipeline with an alternating training strategy to optimize the parameters in different modules of the framework. We validate the framework on both synthetic simulations and motion forecasting benchmarks in different domains, demonstrating that our method not only achieves state-of-the-art forecasting performance, but also provides interpretable and reasonable hybrid attention weights.
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Oct 11, 2021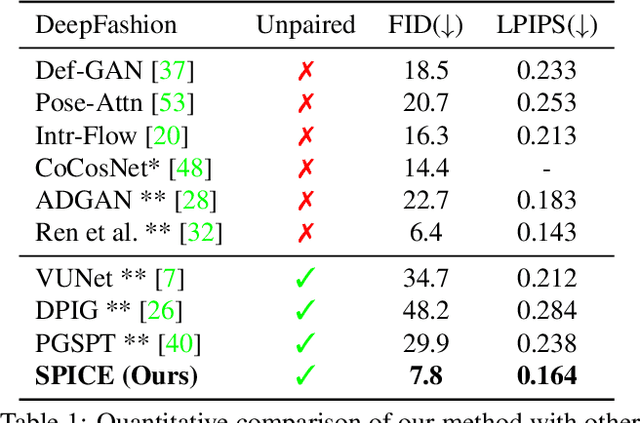
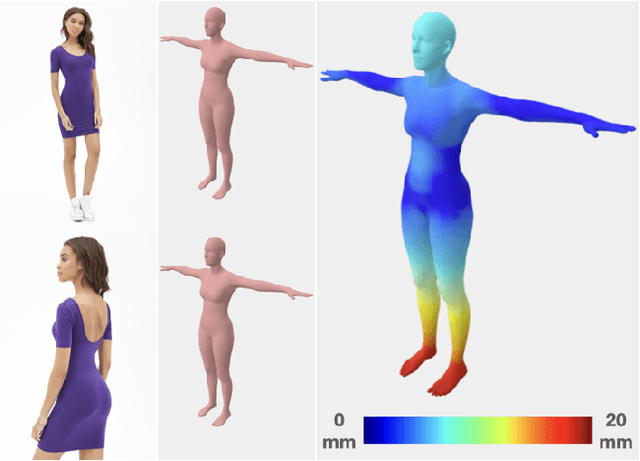

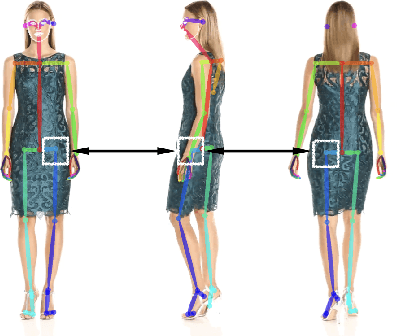
Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. We propose a self-supervised framework named SPICE (Self-supervised Person Image CrEation) that closes the image quality gap with supervised methods. The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
Dynamic Feature Regularized Loss for Weakly Supervised Semantic Segmentation
Aug 03, 2021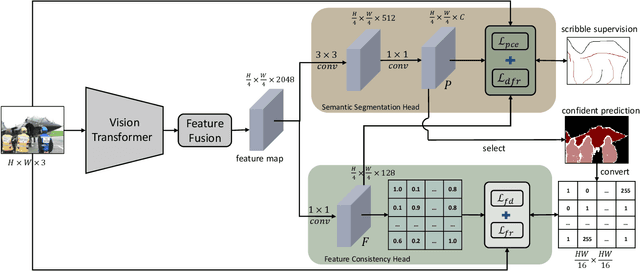
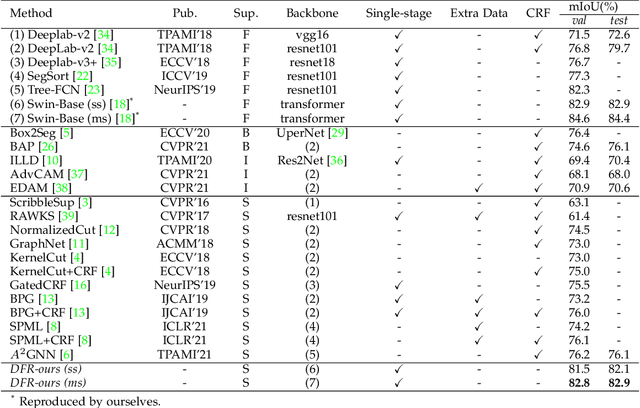

We focus on tackling weakly supervised semantic segmentation with scribble-level annotation. The regularized loss has been proven to be an effective solution for this task. However, most existing regularized losses only leverage static shallow features (color, spatial information) to compute the regularized kernel, which limits its final performance since such static shallow features fail to describe pair-wise pixel relationship in complicated cases. In this paper, we propose a new regularized loss which utilizes both shallow and deep features that are dynamically updated in order to aggregate sufficient information to represent the relationship of different pixels. Moreover, in order to provide accurate deep features, we adopt vision transformer as the backbone and design a feature consistency head to train the pair-wise feature relationship. Unlike most approaches that adopt multi-stage training strategy with many bells and whistles, our approach can be directly trained in an end-to-end manner, in which the feature consistency head and our regularized loss can benefit from each other. Extensive experiments show that our approach achieves new state-of-the-art performances, outperforming other approaches by a significant margin with more than 6\% mIoU increase.
Optimal Control via Combined Inference and Numerical Optimization
Sep 23, 2021

Derivative based optimization methods are efficient at solving optimal control problems near local optima. However, their ability to converge halts when derivative information vanishes. The inference approach to optimal control does not have strict requirements on the objective landscape. However, sampling, the primary tool for solving such problems, tends to be much slower in computation time. We propose a new method that combines second order methods with inference. We utilise the Kullback Leibler (KL) control framework to formulate an inference problem that computes the optimal controls from an adaptive distribution approximating the solution of the second order method. Our method allows for combining simple convex and non convex cost functions. This simplifies the process of cost function design and leverages the strengths of both inference and second order optimization. We compare our method to Model Predictive Path Integral (MPPI) and iterative Linear Quadratic Regulator (iLQG), outperforming both in sample efficiency and quality on manipulation and obstacle avoidance tasks.
SignBERT: Pre-Training of Hand-Model-Aware Representation for Sign Language Recognition
Oct 11, 2021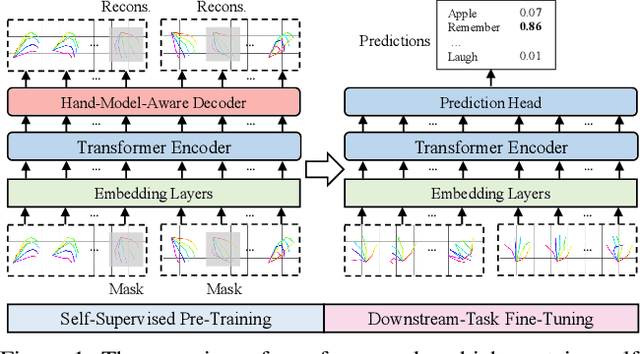
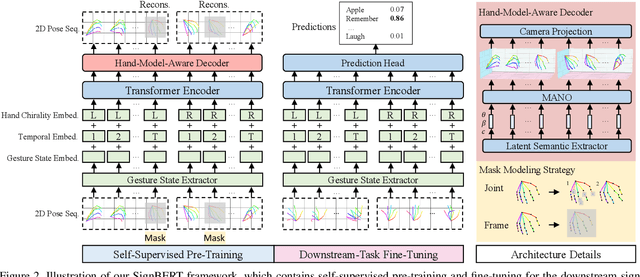
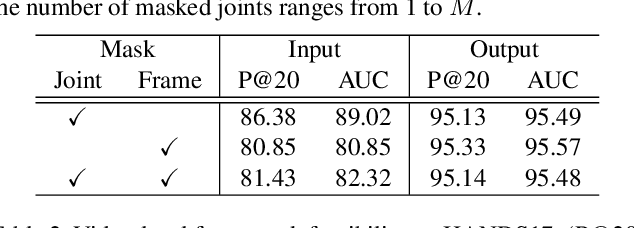
Hand gesture serves as a critical role in sign language. Current deep-learning-based sign language recognition (SLR) methods may suffer insufficient interpretability and overfitting due to limited sign data sources. In this paper, we introduce the first self-supervised pre-trainable SignBERT with incorporated hand prior for SLR. SignBERT views the hand pose as a visual token, which is derived from an off-the-shelf pose extractor. The visual tokens are then embedded with gesture state, temporal and hand chirality information. To take full advantage of available sign data sources, SignBERT first performs self-supervised pre-training by masking and reconstructing visual tokens. Jointly with several mask modeling strategies, we attempt to incorporate hand prior in a model-aware method to better model hierarchical context over the hand sequence. Then with the prediction head added, SignBERT is fine-tuned to perform the downstream SLR task. To validate the effectiveness of our method on SLR, we perform extensive experiments on four public benchmark datasets, i.e., NMFs-CSL, SLR500, MSASL and WLASL. Experiment results demonstrate the effectiveness of both self-supervised learning and imported hand prior. Furthermore, we achieve state-of-the-art performance on all benchmarks with a notable gain.