 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MSO: Multi-Feature Space Joint Optimization Network for RGB-Infrared Person Re-Identification
Oct 21, 2021
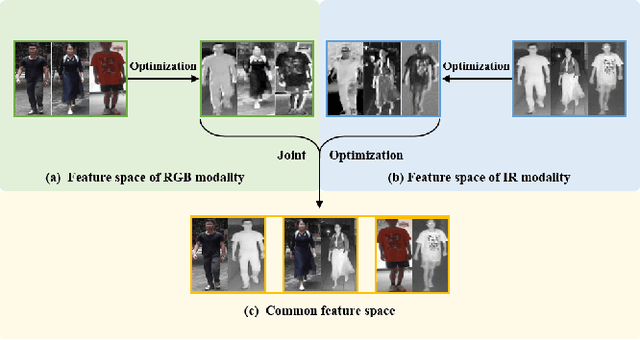
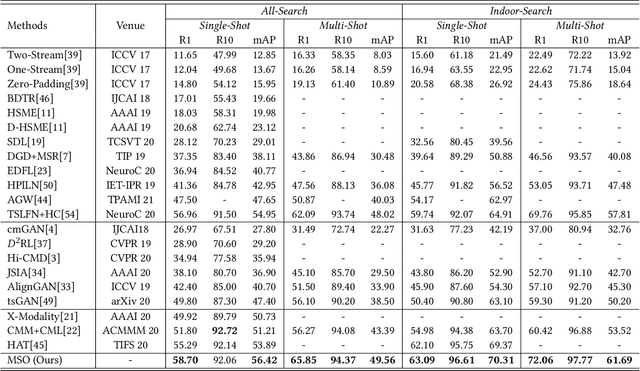
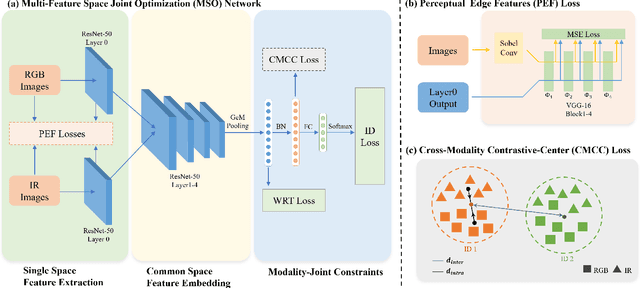
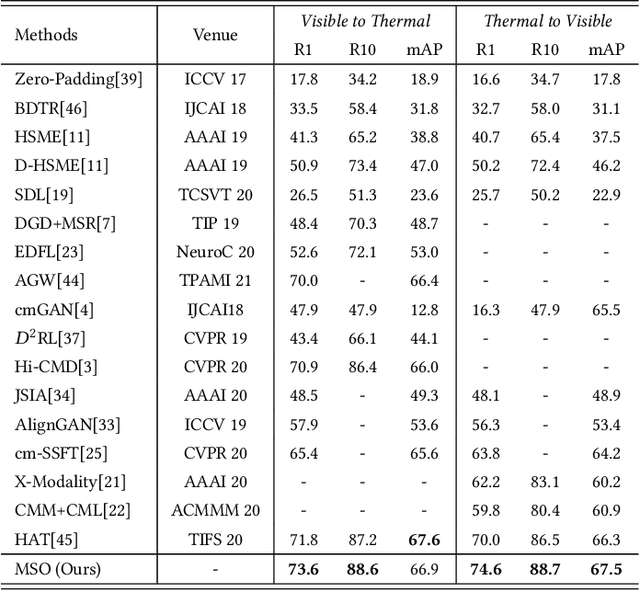
The RGB-infrared cross-modality person re-identification (ReID) task aims to recognize the images of the same identity between the visible modality and the infrared modality. Existing methods mainly use a two-stream architecture to eliminate the discrepancy between the two modalities in the final common feature space, which ignore the single space of each modality in the shallow layers. To solve it, in this paper, we present a novel multi-feature space joint optimization (MSO) network, which can learn modality-sharable features in both the single-modality space and the common space. Firstly, based on the observation that edge information is modality-invariant, we propose an edge features enhancement module to enhance the modality-sharable features in each single-modality space. Specifically, we design a perceptual edge features (PEF) loss after the edge fusion strategy analysis. According to our knowledge, this is the first work that proposes explicit optimization in the single-modality feature space on cross-modality ReID task. Moreover, to increase the difference between cross-modality distance and class distance, we introduce a novel cross-modality contrastive-center (CMCC) loss into the modality-joint constraints in the common feature space. The PEF loss and CMCC loss jointly optimize the model in an end-to-end manner, which markedly improves the network's performance. Extensive experiments demonstrate that the proposed model significantly outperforms state-of-the-art methods on both the SYSU-MM01 and RegDB datasets.
End-to-end Waveform Learning Through Joint Optimization of Pulse and Constellation Shaping
Jul 14, 2021

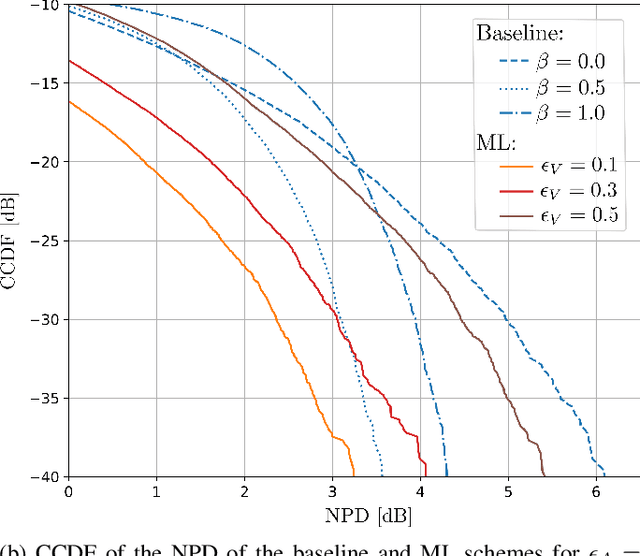
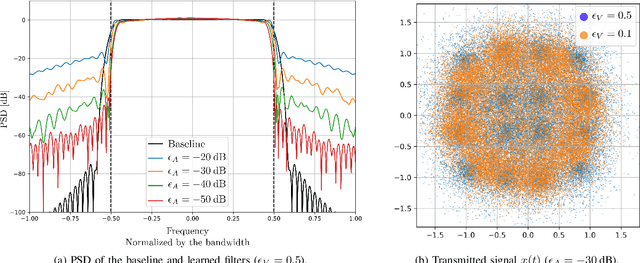
As communication systems are foreseen to enable new services such as joint communication and sensing and utilize parts of the sub-THz spectrum, the design of novel waveforms that can support these emerging applications becomes increasingly challenging. We present in this work an end-to-end learning approach to design waveforms through joint learning of pulse shaping and constellation geometry, together with a neural network (NN)-based receiver. Optimization is performed to maximize an achievable information rate, while satisfying constraints on out-of-band emission and power envelope. Our results show that the proposed approach enables up to orders of magnitude smaller adjacent channel leakage ratios (ACLRs) with peak-to-average power ratios (PAPRs) competitive with traditional filters, without significant loss of information rate on an additive white Gaussian noise (AWGN) channel, and no additional complexity at the transmitter.
Beyond Value-Function Gaps: Improved Instance-Dependent Regret Bounds for Episodic Reinforcement Learning
Jul 02, 2021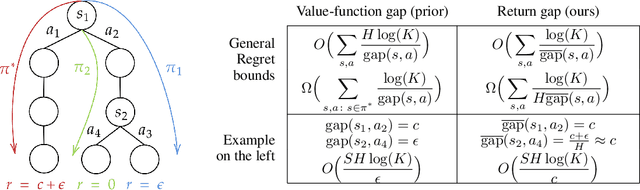
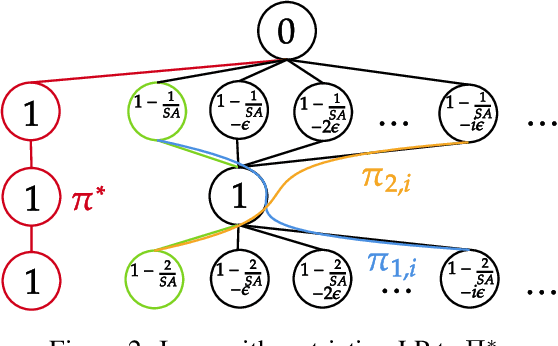
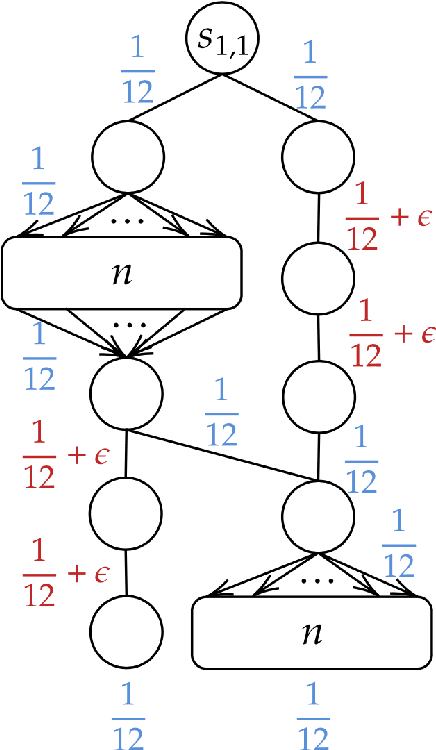
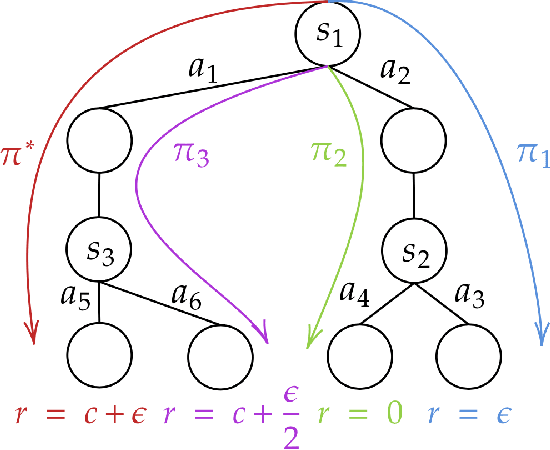
We provide improved gap-dependent regret bounds for reinforcement learning in finite episodic Markov decision processes. Compared to prior work, our bounds depend on alternative definitions of gaps. These definitions are based on the insight that, in order to achieve a favorable regret, an algorithm does not need to learn how to behave optimally in states that are not reached by an optimal policy. We prove tighter upper regret bounds for optimistic algorithms and accompany them with new information-theoretic lower bounds for a large class of MDPs. Our results show that optimistic algorithms can not achieve the information-theoretic lower bounds even in deterministic MDPs unless there is a unique optimal policy.
Genealogical Population-Based Training for Hyperparameter Optimization
Sep 30, 2021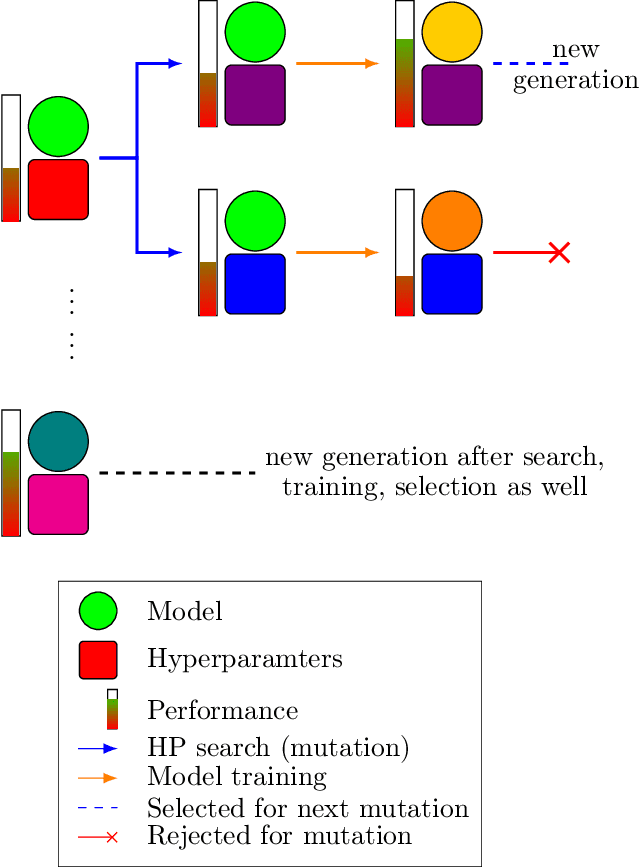
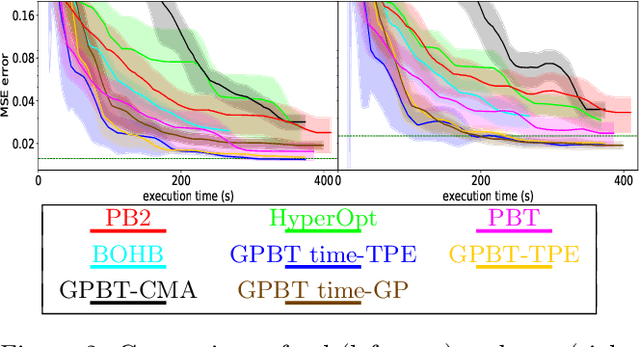
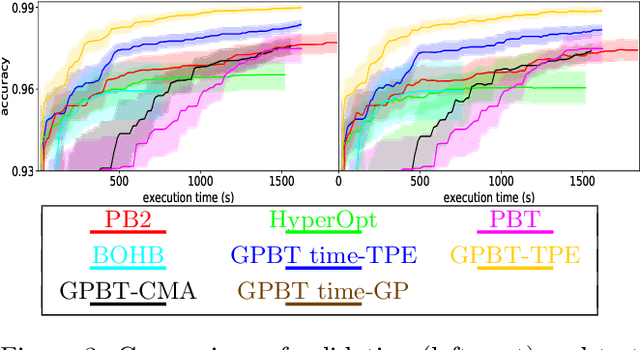
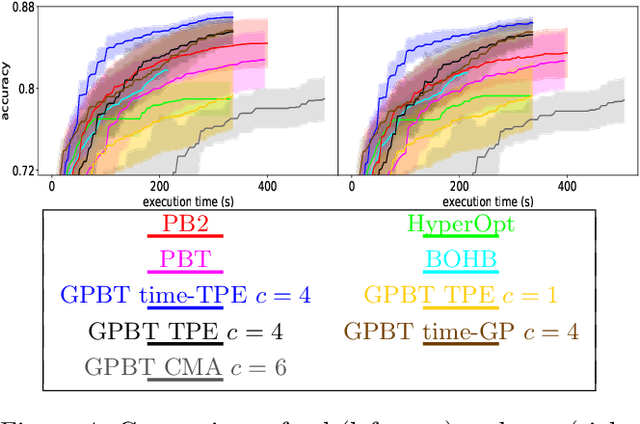
Hyperparameter optimization aims at finding more rapidly and efficiently the best hyperparameters (HPs) of learning models such as neural networks. In this work, we present a new approach called GPBT (Genealogical Population-Based Training), which shares many points with Population-Based Training: our approach outputs a schedule of HPs and updates both weights and HPs in a single run, but brings several novel contributions: the choice of new HPs is made by a modular search algorithm, the search algorithm can search HPs independently for models with different weights and can exploit separately the maximum amount of meaningful information (genealogically-related) from previous HPs evaluations instead of exploiting together all previous HPs evaluations, a variation of early stopping allows a 2-3 fold acceleration at small performance cost. GPBT significantly outperforms all other approaches of HP Optimization, on all supervised learning experiments tested in terms of speed and performances. HPs tuning will become less computationally expensive using our approach, not only in the deep learning field, but potentially for all processes based on iterative optimization.
Process discovery on deviant traces and other stranger things
Sep 30, 2021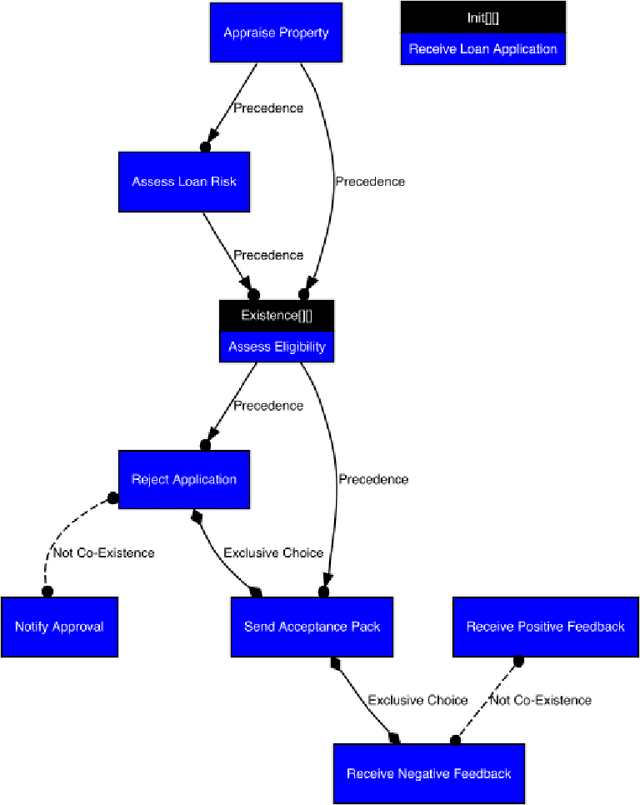
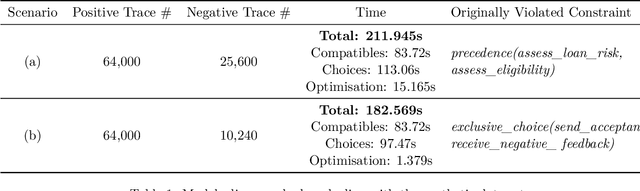
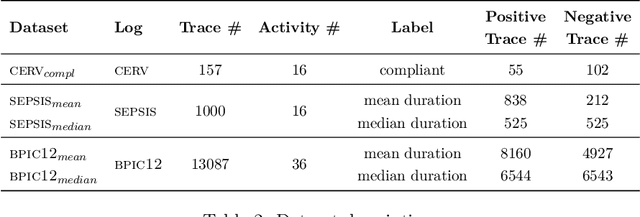

As the need to understand and formalise business processes into a model has grown over the last years, the process discovery research field has gained more and more importance, developing two different classes of approaches to model representation: procedural and declarative. Orthogonally to this classification, the vast majority of works envisage the discovery task as a one-class supervised learning process guided by the traces that are recorded into an input log. In this work instead, we focus on declarative processes and embrace the less-popular view of process discovery as a binary supervised learning task, where the input log reports both examples of the normal system execution, and traces representing "stranger" behaviours according to the domain semantics. We therefore deepen how the valuable information brought by both these two sets can be extracted and formalised into a model that is "optimal" according to user-defined goals. Our approach, namely NegDis, is evaluated w.r.t. other relevant works in this field, and shows promising results as regards both the performance and the quality of the obtained solution.
Graph Fourier Transform based Audio Zero-watermarking
Sep 16, 2021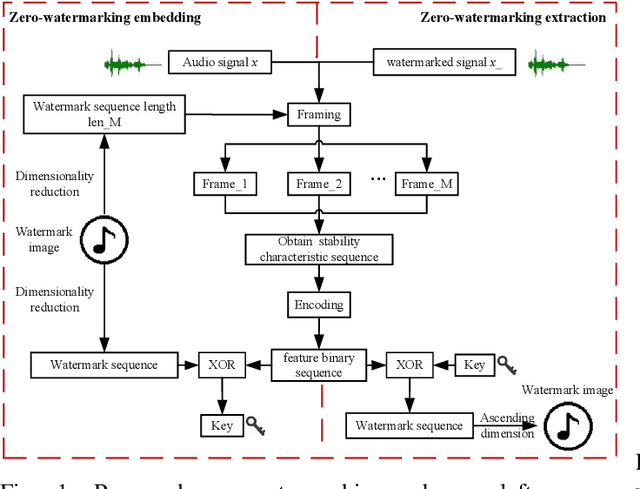
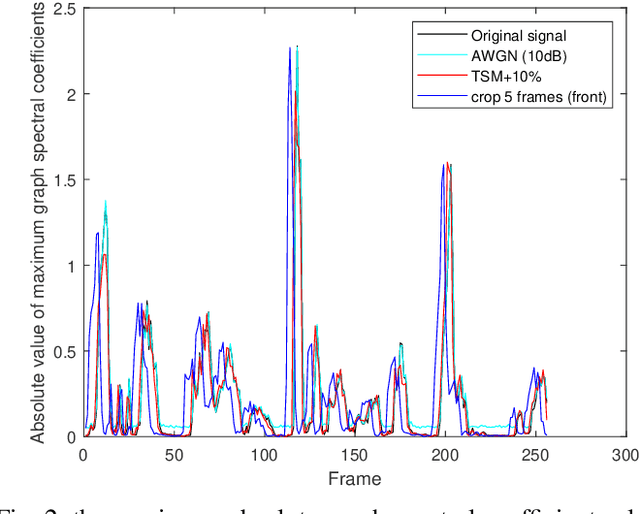


The frequent exchange of multimedia information in the present era projects an increasing demand for copyright protection. In this work, we propose a novel audio zero-watermarking technology based on graph Fourier transform for enhancing the robustness with respect to copyright protection. In this approach, the combined shift operator is used to construct the graph signal, upon which the graph Fourier analysis is performed. The selected maximum absolute graph Fourier coefficients representing the characteristics of the audio segment are then encoded into a feature binary sequence using K-means algorithm. Finally, the resultant feature binary sequence is XOR-ed with the watermark binary sequence to realize the embedding of the zero-watermarking. The experimental studies show that the proposed approach performs more effectively in resisting common or synchronization attacks than the existing state-of-the-art methods.
Exploiting BERT For Multimodal Target SentimentClassification Through Input Space Translation
Aug 03, 2021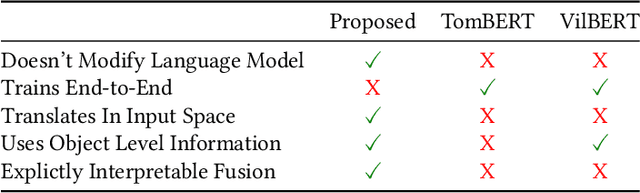
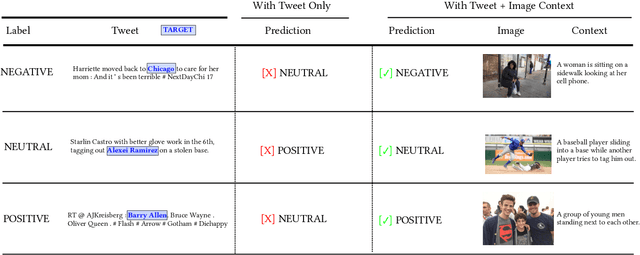

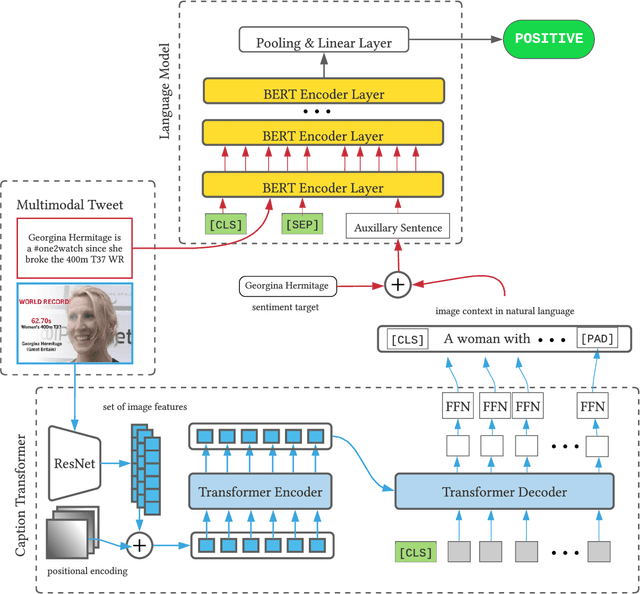
Multimodal target/aspect sentiment classification combines multimodal sentiment analysis and aspect/target sentiment classification. The goal of the task is to combine vision and language to understand the sentiment towards a target entity in a sentence. Twitter is an ideal setting for the task because it is inherently multimodal, highly emotional, and affects real world events. However, multimodal tweets are short and accompanied by complex, possibly irrelevant images. We introduce a two-stream model that translates images in input space using an object-aware transformer followed by a single-pass non-autoregressive text generation approach. We then leverage the translation to construct an auxiliary sentence that provides multimodal information to a language model. Our approach increases the amount of text available to the language model and distills the object-level information in complex images. We achieve state-of-the-art performance on two multimodal Twitter datasets without modifying the internals of the language model to accept multimodal data, demonstrating the effectiveness of our translation. In addition, we explain a failure mode of a popular approach for aspect sentiment analysis when applied to tweets. Our code is available at \textcolor{blue}{\url{https://github.com/codezakh/exploiting-BERT-thru-translation}}.
Egocentric View Hand Action Recognition by Leveraging Hand Surface and Hand Grasp Type
Sep 08, 2021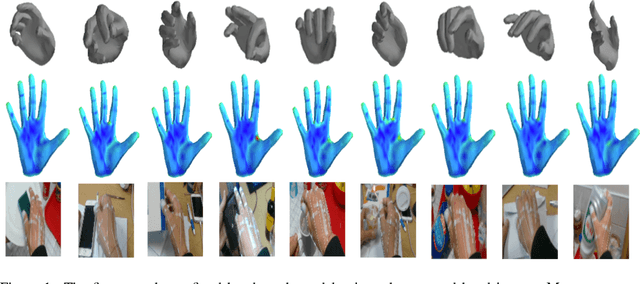

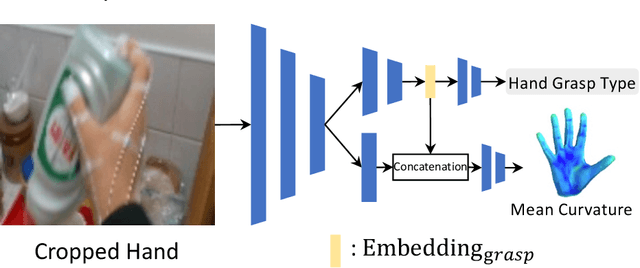

We introduce a multi-stage framework that uses mean curvature on a hand surface and focuses on learning interaction between hand and object by analyzing hand grasp type for hand action recognition in egocentric videos. The proposed method does not require 3D information of objects including 6D object poses which are difficult to annotate for learning an object's behavior while it interacts with hands. Instead, the framework synthesizes the mean curvature of the hand mesh model to encode the hand surface geometry in 3D space. Additionally, our method learns the hand grasp type which is highly correlated with the hand action. From our experiment, we notice that using hand grasp type and mean curvature of hand increases the performance of the hand action recognition.
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Oct 11, 2021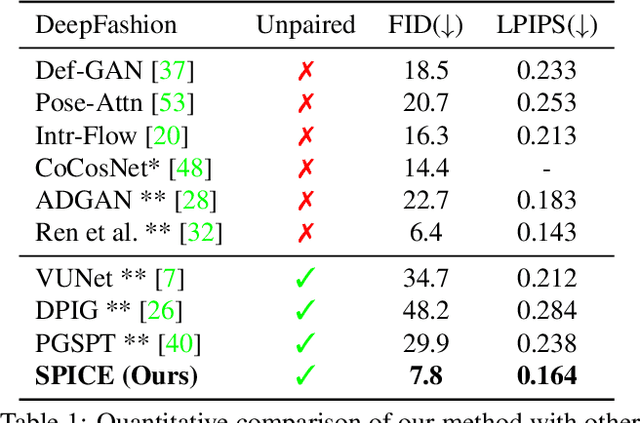
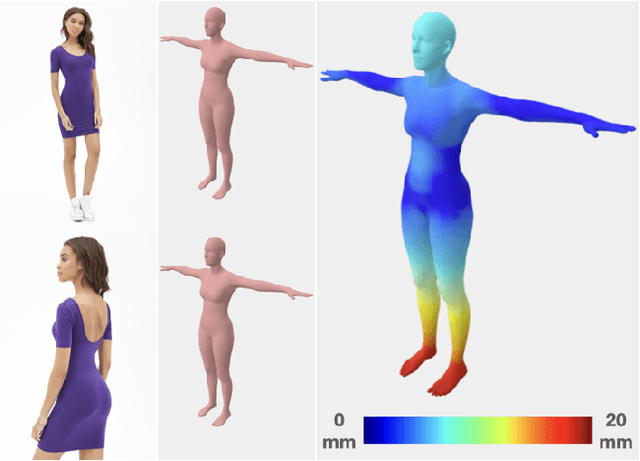

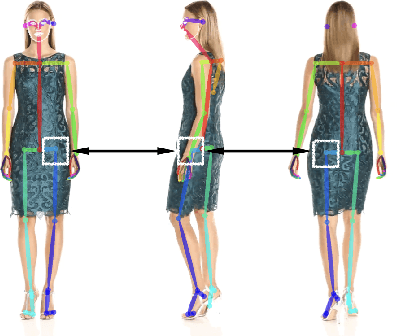
Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. We propose a self-supervised framework named SPICE (Self-supervised Person Image CrEation) that closes the image quality gap with supervised methods. The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection
Jul 28, 2021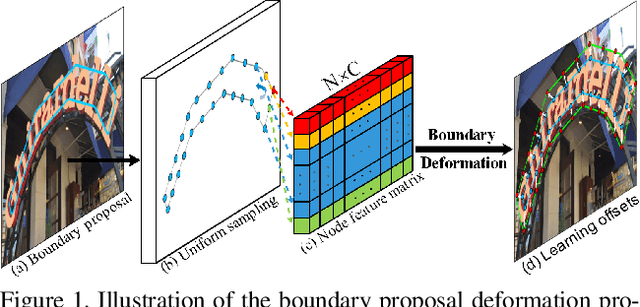
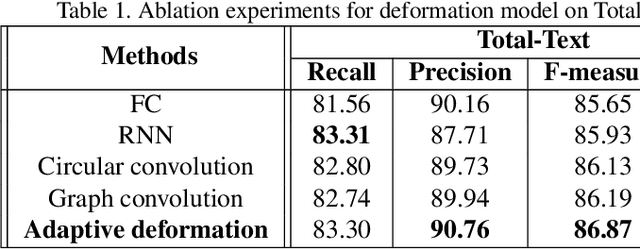
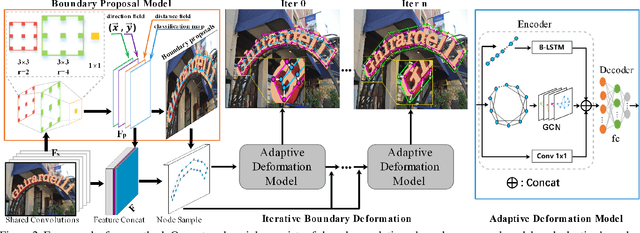
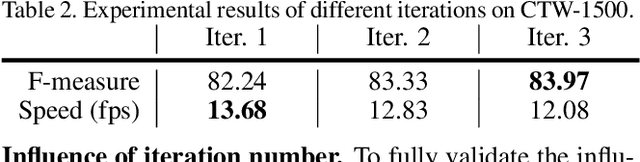
Arbitrary shape text detection is a challenging task due to the high complexity and variety of scene texts. In this work, we propose a novel adaptive boundary proposal network for arbitrary shape text detection, which can learn to directly produce accurate boundary for arbitrary shape text without any post-processing. Our method mainly consists of a boundary proposal model and an innovative adaptive boundary deformation model. The boundary proposal model constructed by multi-layer dilated convolutions is adopted to produce prior information (including classification map, distance field, and direction field) and coarse boundary proposals. The adaptive boundary deformation model is an encoder-decoder network, in which the encoder mainly consists of a Graph Convolutional Network (GCN) and a Recurrent Neural Network (RNN). It aims to perform boundary deformation in an iterative way for obtaining text instance shape guided by prior information from the boundary proposal model. In this way, our method can directly and efficiently generate accurate text boundaries without complex post-processing. Extensive experiments on publicly available datasets demonstrate the state-of-the-art performance of our method.
* 10 pages, 8 figures, Accepted by ICCV2021