 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Graph Co-Training for Session-based Recommendation
Aug 24, 2021
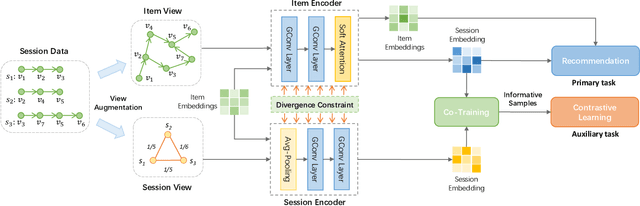
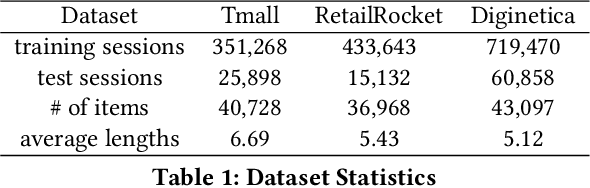
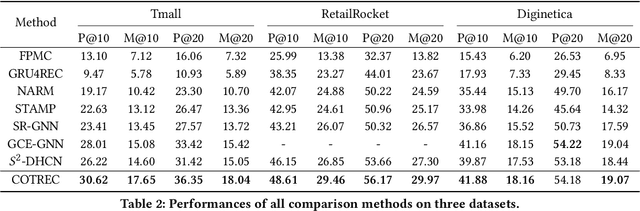
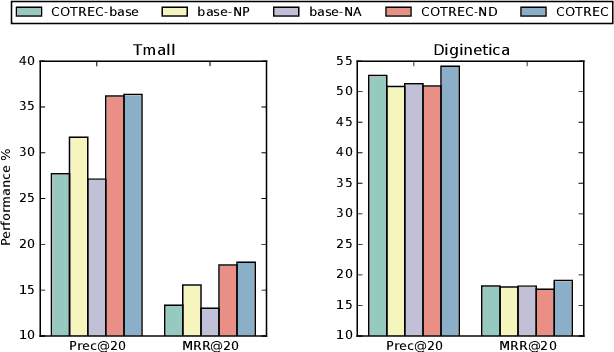
Session-based recommendation targets next-item prediction by exploiting user behaviors within a short time period. Compared with other recommendation paradigms, session-based recommendation suffers more from the problem of data sparsity due to the very limited short-term interactions. Self-supervised learning, which can discover ground-truth samples from the raw data, holds vast potentials to tackle this problem. However, existing self-supervised recommendation models mainly rely on item/segment dropout to augment data, which are not fit for session-based recommendation because the dropout leads to sparser data, creating unserviceable self-supervision signals. In this paper, for informative session-based data augmentation, we combine self-supervised learning with co-training, and then develop a framework to enhance session-based recommendation. Technically, we first exploit the session-based graph to augment two views that exhibit the internal and external connectivities of sessions, and then we build two distinct graph encoders over the two views, which recursively leverage the different connectivity information to generate ground-truth samples to supervise each other by contrastive learning. In contrast to the dropout strategy, the proposed self-supervised graph co-training preserves the complete session information and fulfills genuine data augmentation. Extensive experiments on multiple benchmark datasets show that, session-based recommendation can be remarkably enhanced under the regime of self-supervised graph co-training, achieving the state-of-the-art performance.
Trajectory Design for UAV-Based Internet-of-Things Data Collection: A Deep Reinforcement Learning Approach
Jul 23, 2021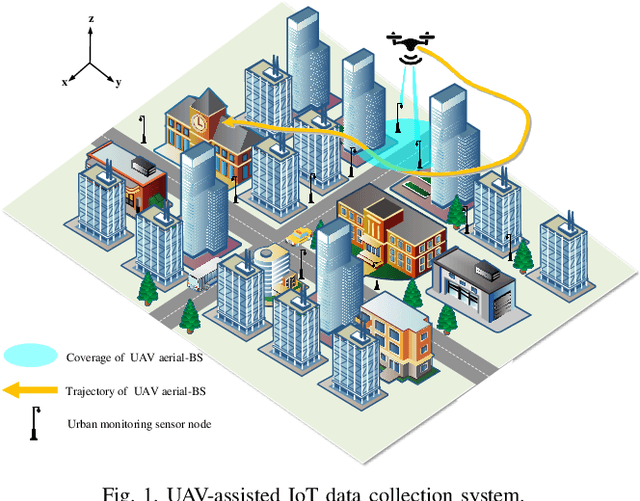
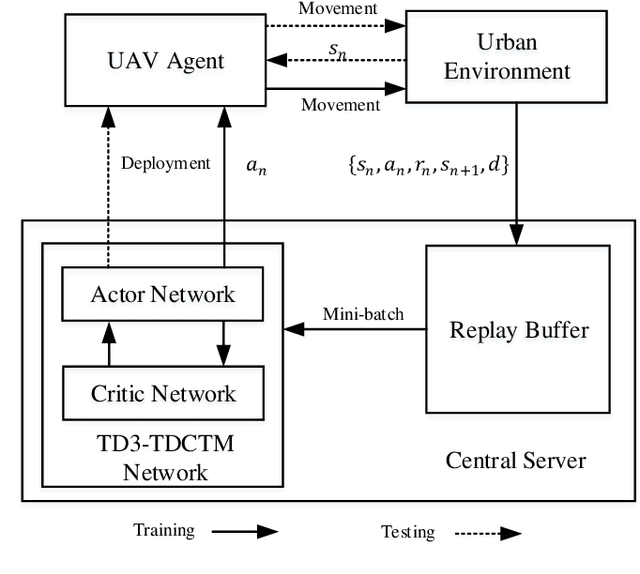
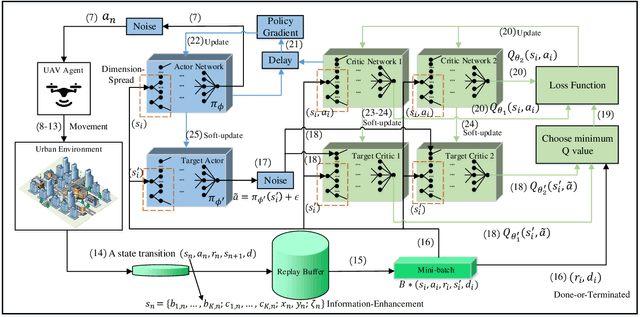
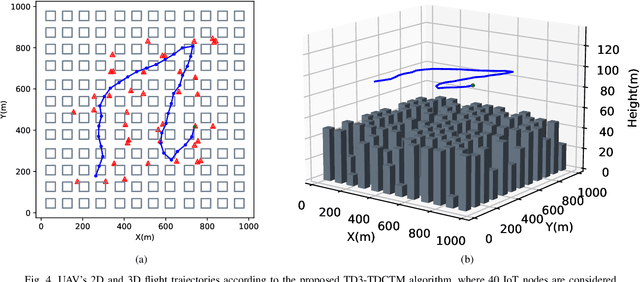
In this paper, we investigate an unmanned aerial vehicle (UAV)-assisted Internet-of-Things (IoT) system in a sophisticated three-dimensional (3D) environment, where the UAV's trajectory is optimized to efficiently collect data from multiple IoT ground nodes. Unlike existing approaches focusing only on a simplified two-dimensional scenario and the availability of perfect channel state information (CSI), this paper considers a practical 3D urban environment with imperfect CSI, where the UAV's trajectory is designed to minimize data collection completion time subject to practical throughput and flight movement constraints. Specifically, inspired from the state-of-the-art deep reinforcement learning approaches, we leverage the twin-delayed deep deterministic policy gradient (TD3) to design the UAV's trajectory and present a TD3-based trajectory design for completion time minimization (TD3-TDCTM) algorithm. In particular, we set an additional information, i.e., the merged pheromone, to represent the state information of UAV and environment as a reference of reward which facilitates the algorithm design. By taking the service statuses of IoT nodes, the UAV's position, and the merged pheromone as input, the proposed algorithm can continuously and adaptively learn how to adjust the UAV's movement strategy. By interacting with the external environment in the corresponding Markov decision process, the proposed algorithm can achieve a near-optimal navigation strategy. Our simulation results show the superiority of the proposed TD3-TDCTM algorithm over three conventional non-learning based baseline methods.
Learning Neural Models for Natural Language Processing in the Face of Distributional Shift
Sep 03, 2021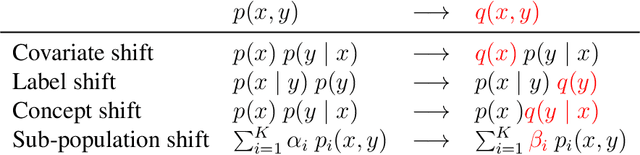
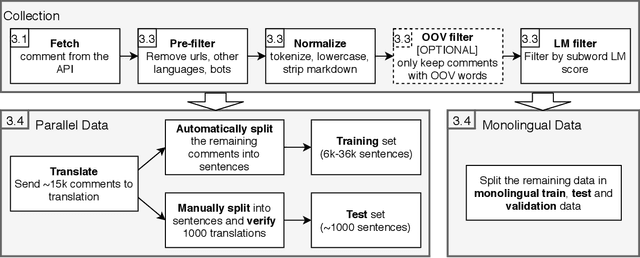
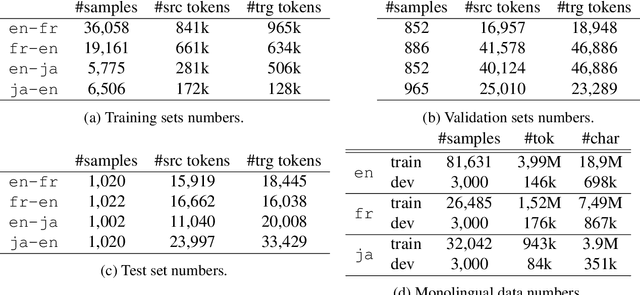
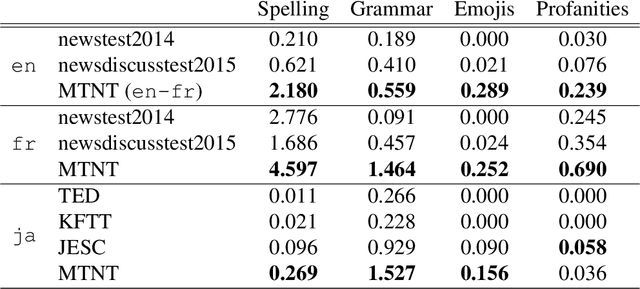
The dominating NLP paradigm of training a strong neural predictor to perform one task on a specific dataset has led to state-of-the-art performance in a variety of applications (eg. sentiment classification, span-prediction based question answering or machine translation). However, it builds upon the assumption that the data distribution is stationary, ie. that the data is sampled from a fixed distribution both at training and test time. This way of training is inconsistent with how we as humans are able to learn from and operate within a constantly changing stream of information. Moreover, it is ill-adapted to real-world use cases where the data distribution is expected to shift over the course of a model's lifetime. The first goal of this thesis is to characterize the different forms this shift can take in the context of natural language processing, and propose benchmarks and evaluation metrics to measure its effect on current deep learning architectures. We then proceed to take steps to mitigate the effect of distributional shift on NLP models. To this end, we develop methods based on parametric reformulations of the distributionally robust optimization framework. Empirically, we demonstrate that these approaches yield more robust models as demonstrated on a selection of realistic problems. In the third and final part of this thesis, we explore ways of efficiently adapting existing models to new domains or tasks. Our contribution to this topic takes inspiration from information geometry to derive a new gradient update rule which alleviate catastrophic forgetting issues during adaptation.
Sensoring and Application of Multimodal Data for the Detection of Freezing of Gait in Parkinson's Disease
Oct 09, 2021
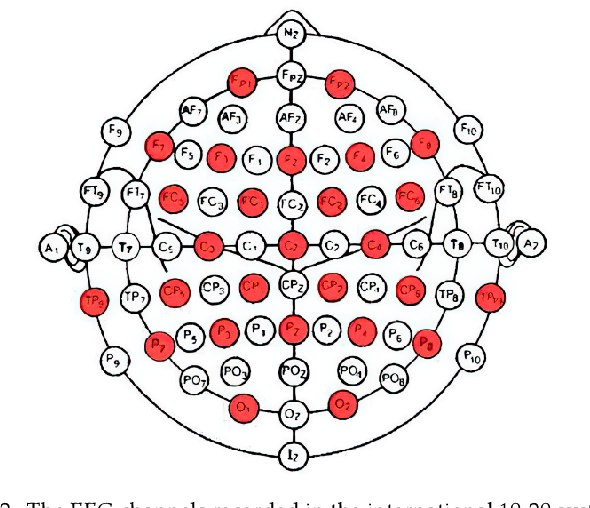

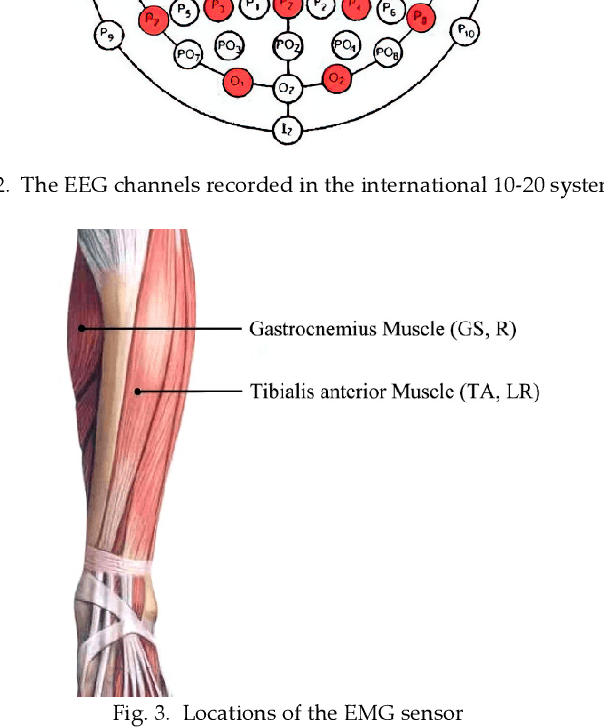
The accurate and reliable detection or prediction of freezing of gaits (FOG) is important for fall prevention in Parkinson's Disease (PD) and studying the physiological transitions during the occurrence of FOG. Integrating both commercial and self-designed sensors, a protocal has been designed to acquire multimodal physical and physiological information during FOG, including gait acceleration (ACC), electroencephalogram (EEG), electromyogram (EMG), and skin conductance (SC). Two tasks were designed to trigger FOG, including gait initiation failure and FOG during walking. A total number of 12 PD patients completed the experiments and produced a total length of 3 hours and 42 minutes of valid data. The FOG episodes were labeled by two qualified physicians. Each unimodal data and combinations have been used to detect FOG. Results showed that multimodal data benefit the detection of FOG. Among unimodal data, EEG had better discriminative ability than ACC and EMG. However, the acquisition of EEG are more complicated. Multimodal motional and electrophysiological data can also be used to study the physiological transition process during the occurrence of FOG and provide personalised interventions.
Can multi-label classification networks know what they don't know?
Sep 29, 2021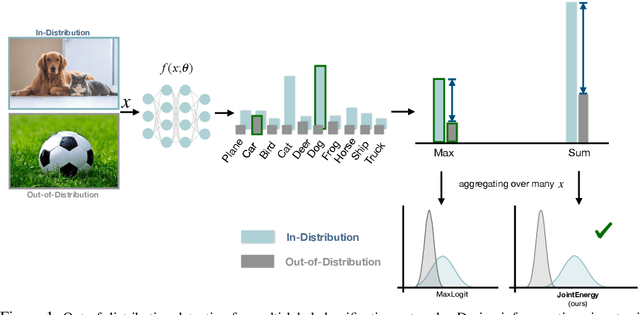
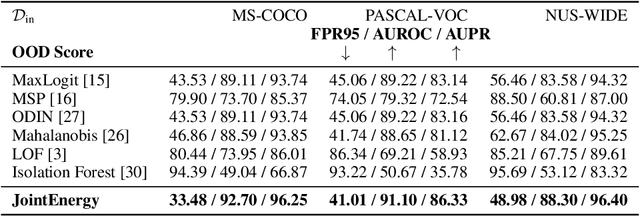
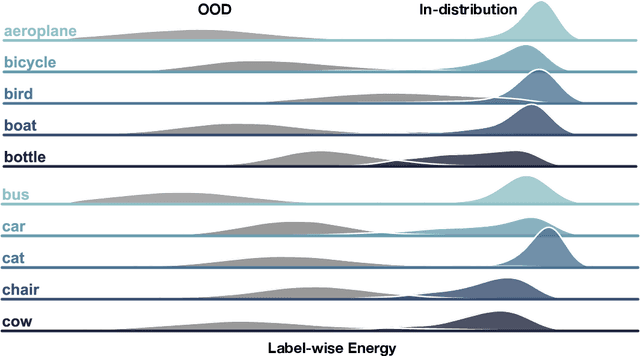
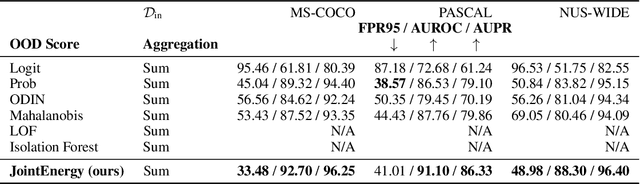
Estimating out-of-distribution (OOD) uncertainty is a central challenge for safely deploying machine learning models in the open-world environment. Improved methods for OOD detection in multi-class classification have emerged, while OOD detection methods for multi-label classification remain underexplored and use rudimentary techniques. We propose JointEnergy, a simple and effective method, which estimates the OOD indicator scores by aggregating energy scores from multiple labels. We show that JointEnergy can be mathematically interpreted from a joint likelihood perspective. Our results show consistent improvement over previous methods that are based on the maximum-valued scores, which fail to capture joint information from multiple labels. We demonstrate the effectiveness of our method on three common multi-label classification benchmarks, including MS-COCO, PASCAL-VOC, and NUS-WIDE. We show that JointEnergy can reduce the FPR95 by up to 10.05% compared to the previous best baseline, establishing state-of-the-art performance.
HoneyCar: A Framework to Configure HoneypotVulnerabilities on the Internet of Vehicles
Nov 03, 2021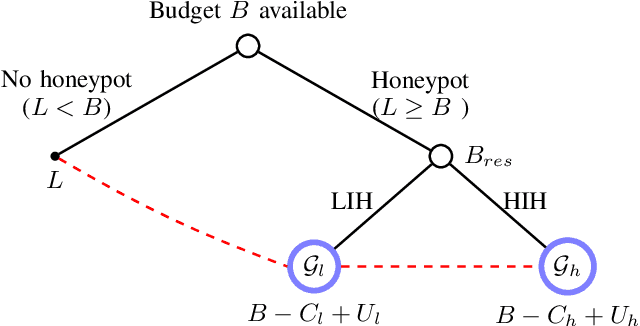
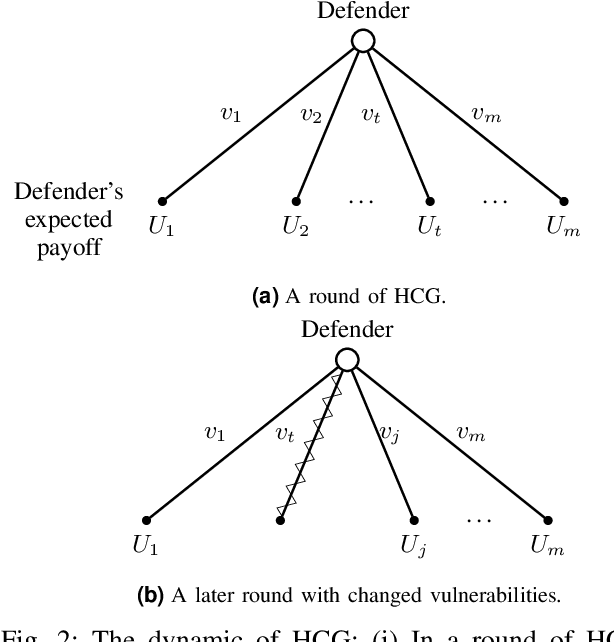
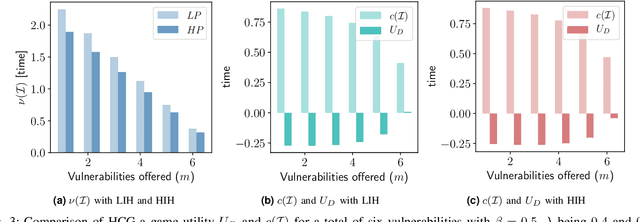
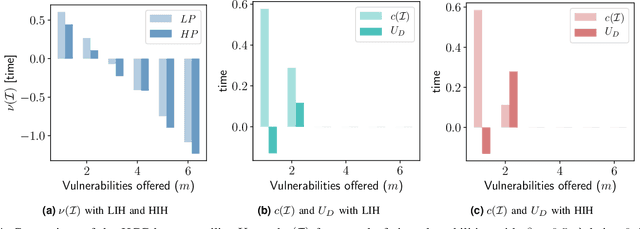
The Internet of Vehicles (IoV), whereby interconnected vehicles communicate with each other and with road infrastructure on a common network, has promising socio-economic benefits but also poses new cyber-physical threats. Data on vehicular attackers can be realistically gathered through cyber threat intelligence using systems like honeypots. Admittedly, configuring honeypots introduces a trade-off between the level of honeypot-attacker interactions and any incurred overheads and costs for implementing and monitoring these honeypots. We argue that effective deception can be achieved through strategically configuring the honeypots to represent components of the IoV and engage attackers to collect cyber threat intelligence. In this paper, we present HoneyCar, a novel decision support framework for honeypot deception in IoV. HoneyCar builds upon a repository of known vulnerabilities of the autonomous and connected vehicles found in the Common Vulnerabilities and Exposure (CVE) data within the National Vulnerability Database (NVD) to compute optimal honeypot configuration strategies. By taking a game-theoretic approach, we model the adversarial interaction as a repeated imperfect-information zero-sum game in which the IoV network administrator chooses a set of vulnerabilities to offer in a honeypot and a strategic attacker chooses a vulnerability of the IoV to exploit under uncertainty. Our investigation is substantiated by examining two different versions of the game, with and without the re-configuration cost to empower the network administrator to determine optimal honeypot configurations. We evaluate HoneyCar in a realistic use case to support decision makers with determining optimal honeypot configuration strategies for strategic deployment in IoV.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Nov 03, 2021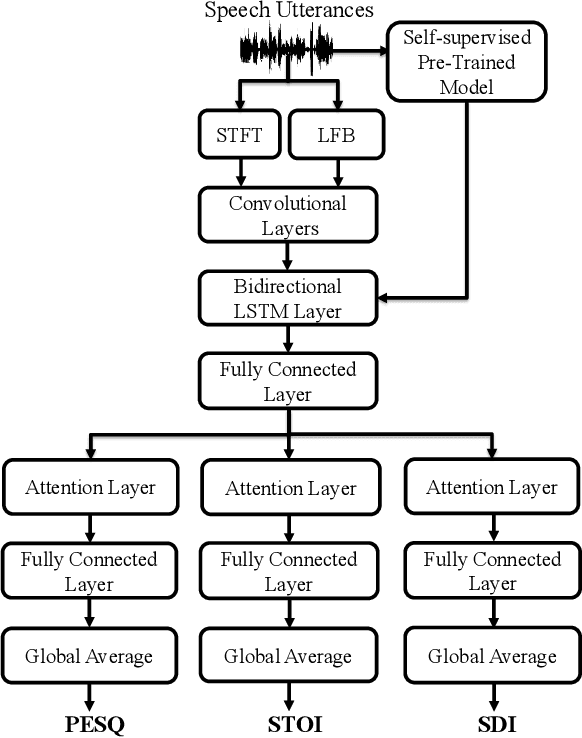
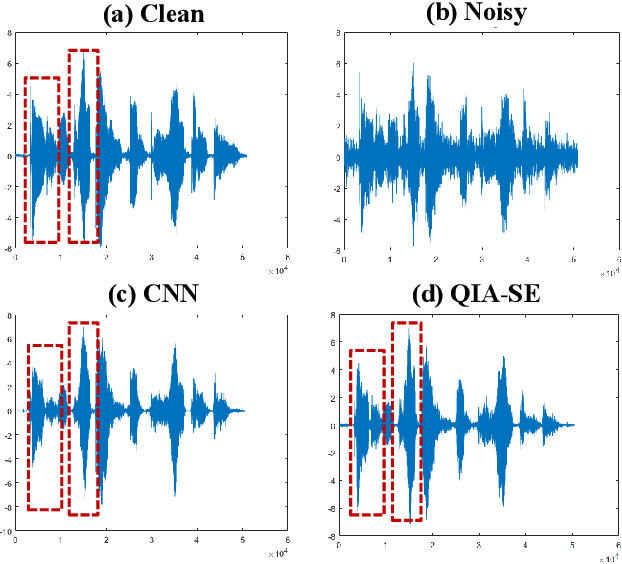
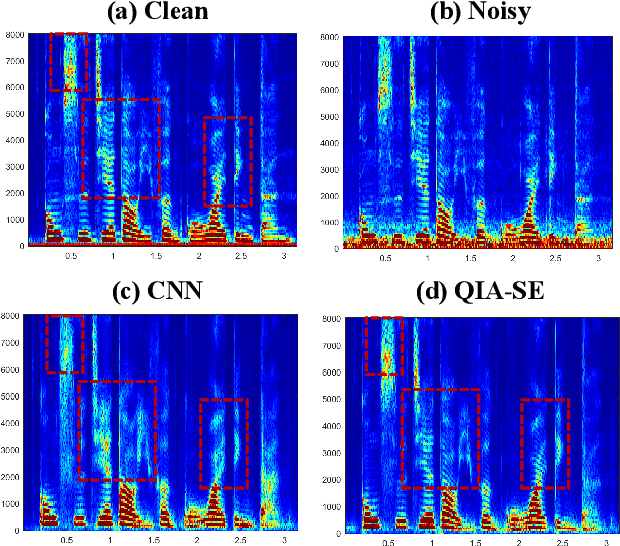
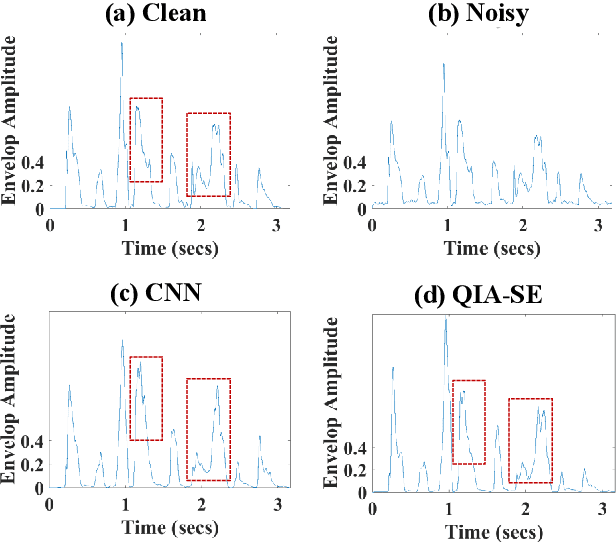
In this study, we propose a cross-domain multi-objective speech assessment model, i.e., the MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, the MOSA-Net is designed to estimate speech quality, intelligibility, and distortion assessment scores based on a test speech signal as input. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, as well as a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results reveal that the MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on both noisy and enhanced speech utterances under either seen test conditions (where the test speakers and noise types are involved in the training set) or unseen test conditions (where the test speakers and noise types are not involved in the training set). In light of the confirmed prediction capability, we further adopt the latent representations of the MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.
TVDIM: Enhancing Image Self-Supervised Pretraining via Noisy Text Data
Jun 13, 2021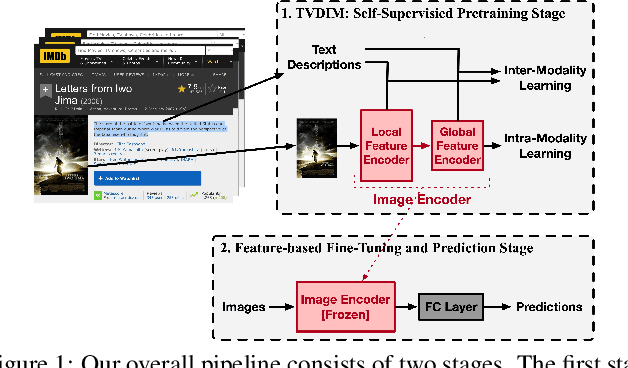
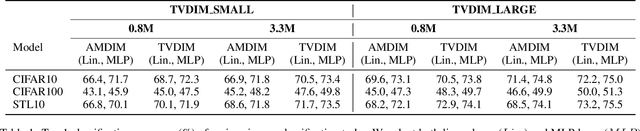
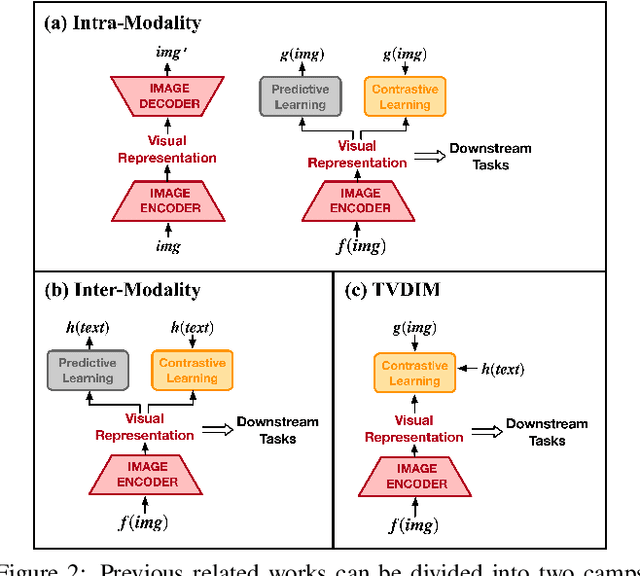
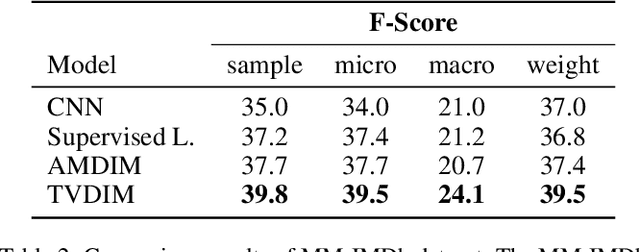
Among ubiquitous multimodal data in the real world, text is the modality generated by human, while image reflects the physical world honestly. In a visual understanding application, machines are expected to understand images like human. Inspired by this, we propose a novel self-supervised learning method, named Text-enhanced Visual Deep InfoMax (TVDIM), to learn better visual representations by fully utilizing the naturally-existing multimodal data. Our core idea of self-supervised learning is to maximize the mutual information between features extracted from multiple views of a shared context to a rational degree. Different from previous methods which only consider multiple views from a single modality, our work produces multiple views from different modalities, and jointly optimizes the mutual information for features pairs of intra-modality and inter-modality. Considering the information gap between inter-modality features pairs from data noise, we adopt a \emph{ranking-based} contrastive learning to optimize the mutual information. During evaluation, we directly use the pre-trained visual representations to complete various image classification tasks. Experimental results show that, TVDIM significantly outperforms previous visual self-supervised methods when processing the same set of images.
Gaussian Process Bandit Optimization with Few Batches
Oct 15, 2021
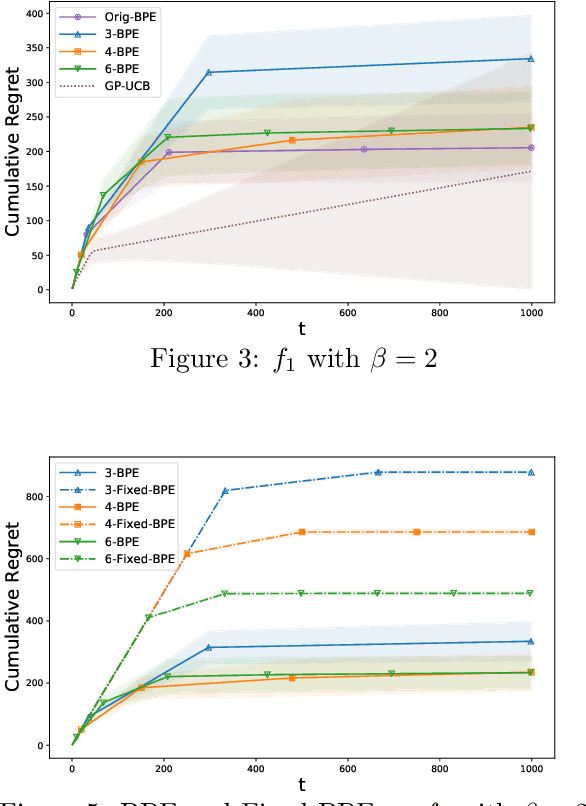
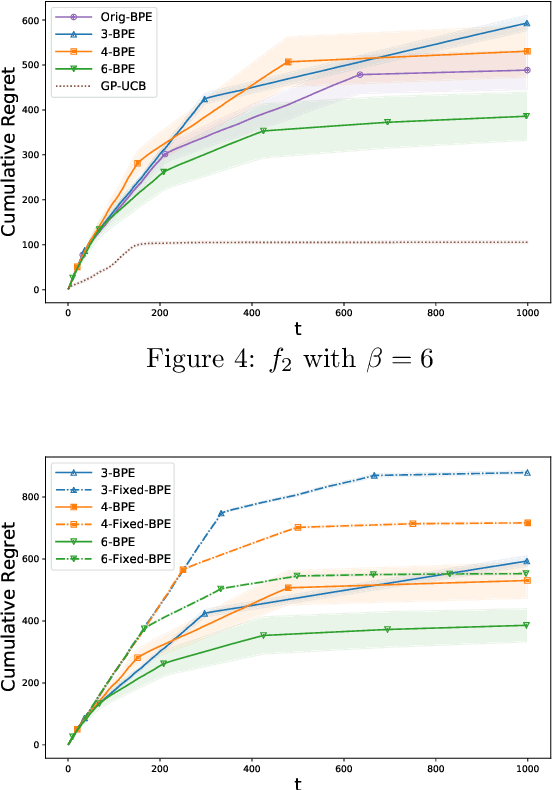
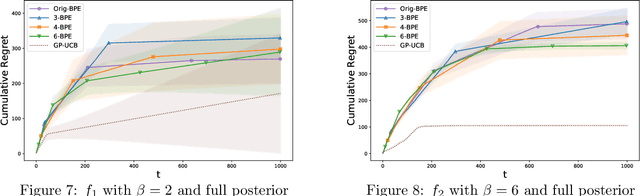
In this paper, we consider the problem of black-box optimization using Gaussian Process (GP) bandit optimization with a small number of batches. Assuming the unknown function has a low norm in the Reproducing Kernel Hilbert Space (RKHS), we introduce a batch algorithm inspired by batched finite-arm bandit algorithms, and show that it achieves the cumulative regret upper bound $O^\ast(\sqrt{T\gamma_T})$ using $O(\log\log T)$ batches within time horizon $T$, where the $O^\ast(\cdot)$ notation hides dimension-independent logarithmic factors and $\gamma_T$ is the maximum information gain associated with the kernel. This bound is near-optimal for several kernels of interest and improves on the typical $O^\ast(\sqrt{T}\gamma_T)$ bound, and our approach is arguably the simplest among algorithms attaining this improvement. In addition, in the case of a constant number of batches (not depending on $T$), we propose a modified version of our algorithm, and characterize how the regret is impacted by the number of batches, focusing on the squared exponential and Mat\'ern kernels. The algorithmic upper bounds are shown to be nearly minimax optimal via analogous algorithm-independent lower bounds.
COVINS: Visual-Inertial SLAM for Centralized Collaboration
Aug 12, 2021
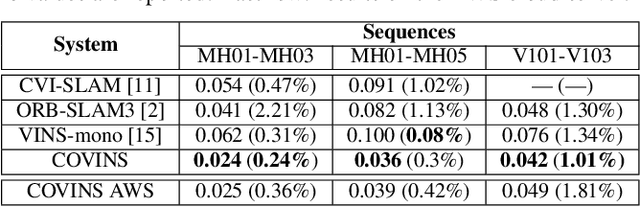
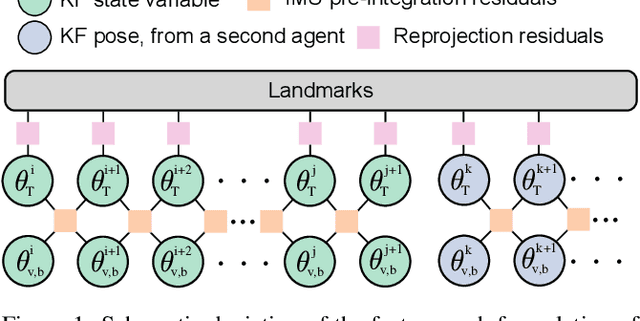
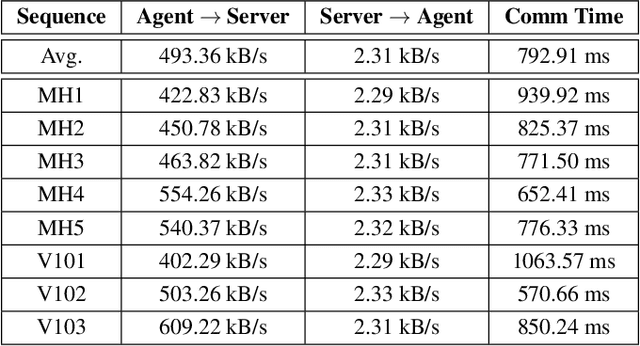
Collaborative SLAM enables a group of agents to simultaneously co-localize and jointly map an environment, thus paving the way to wide-ranging applications of multi-robot perception and multi-user AR experiences by eliminating the need for external infrastructure or pre-built maps. This article presents COVINS, a novel collaborative SLAM system, that enables multi-agent, scalable SLAM in large environments and for large teams of more than 10 agents. The paradigm here is that each agent runs visual-inertial odomety independently onboard in order to ensure its autonomy, while sharing map information with the COVINS server back-end running on a powerful local PC or a remote cloud server. The server back-end establishes an accurate collaborative global estimate from the contributed data, refining the joint estimate by means of place recognition, global optimization and removal of redundant data, in order to ensure an accurate, but also efficient SLAM process. A thorough evaluation of COVINS reveals increased accuracy of the collaborative SLAM estimates, as well as efficiency in both removing redundant information and reducing the coordination overhead, and demonstrates successful operation in a large-scale mission with 12 agents jointly performing SLAM.