 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What Averages Do Not Tell -- Predicting Real Life Processes with Sequential Deep Learning
Oct 31, 2021
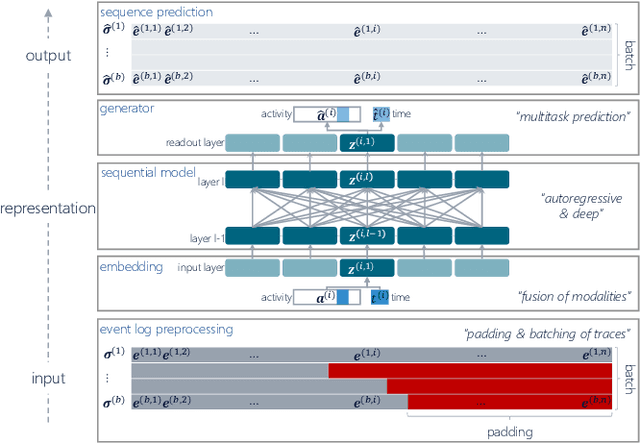
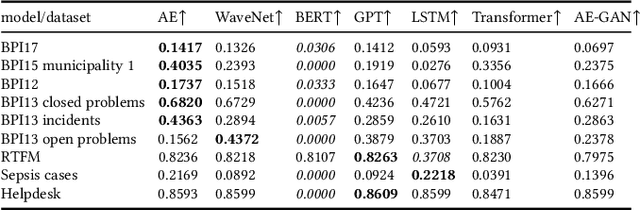
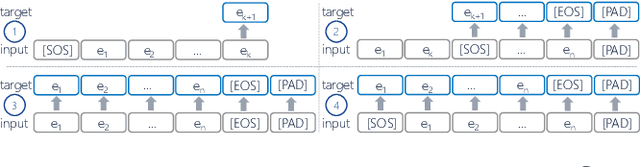
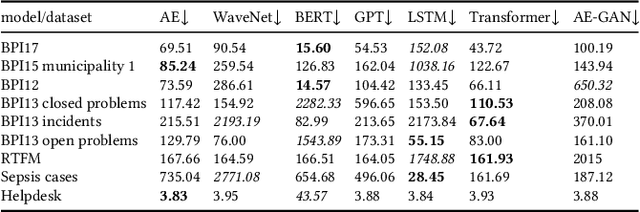
Deep Learning is proven to be an effective tool for modeling sequential data as shown by the success in Natural Language, Computer Vision and Signal Processing. Process Mining concerns discovering insights on business processes from their execution data that are logged by supporting information systems. The logged data (event log) is formed of event sequences (traces) that correspond to executions of a process. Many Deep Learning techniques have been successfully adapted for predictive Process Mining that aims to predict process outcomes, remaining time, the next event, or even the suffix of running traces. Traces in Process Mining are multimodal sequences and very differently structured than natural language sentences or images. This may require a different approach to processing. So far, there has been little focus on these differences and the challenges introduced. Looking at suffix prediction as the most challenging of these tasks, the performance of Deep Learning models was evaluated only on average measures and for a small number of real-life event logs. Comparing the results between papers is difficult due to different pre-processing and evaluation strategies. Challenges that may be relevant are the skewness of trace-length distribution and the skewness of the activity distribution in real-life event logs. We provide an end-to-end framework which enables to compare the performance of seven state-of-the-art sequential architectures in common settings. Results show that sequence modeling still has a lot of room for improvement for majority of the more complex datasets. Further research and insights are required to get consistent performance not just in average measures but additionally over all the prefixes.
Fuzzy Overclustering: Semi-Supervised Classification of Fuzzy Labels with Overclustering and Inverse Cross-Entropy
Oct 13, 2021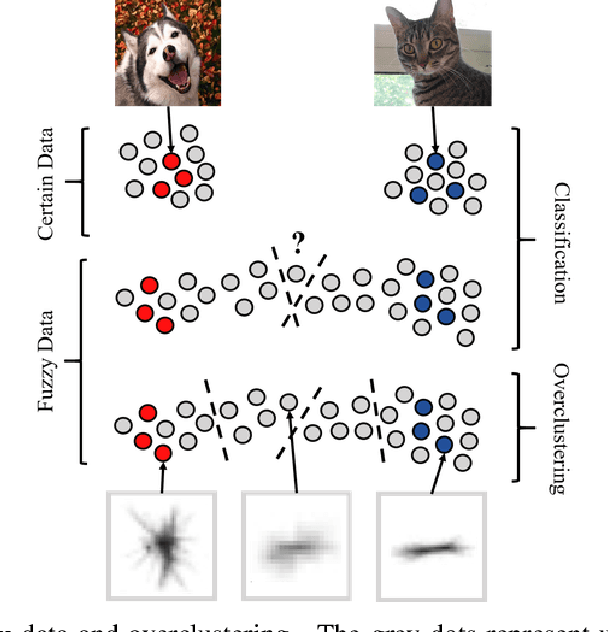
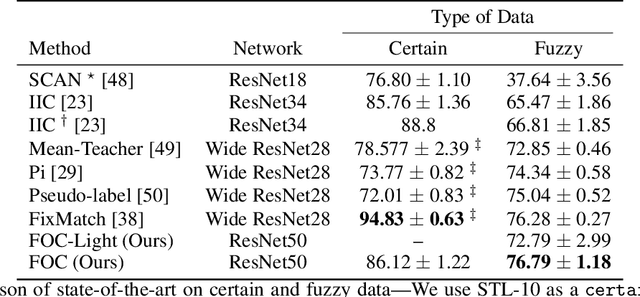
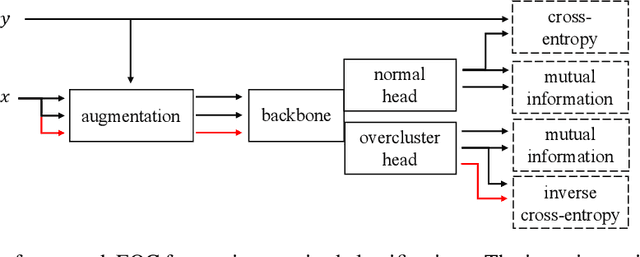

Deep learning has been successfully applied to many classification problems including underwater challenges. However, a long-standing issue with deep learning is the need for large and consistently labeled datasets. Although current approaches in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes. For underwater classification, and uncurated real-world datasets in general, clean class boundaries can often not be given due to a limited information content in the images and transitional stages of the depicted objects. This leads to different experts having different opinions and thus producing fuzzy labels which could also be considered ambiguous or divergent. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. It is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show the benefit of overclustering for fuzzy labels. We show that our framework is superior to previous state-of-the-art semi-supervised methods when applied to real-world plankton data with fuzzy labels. Moreover, we acquire 5 to 10\% more consistent predictions of substructures.
* Source code: https://github.com/Emprime/FuzzyOverclustering Datasets: https://doi.org/10.5281/zenodo.5550918. arXiv admin note: substantial text overlap with arXiv:2012.01768
CLIP4Caption: CLIP for Video Caption
Oct 13, 2021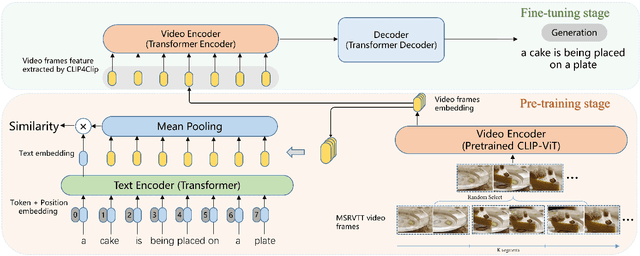

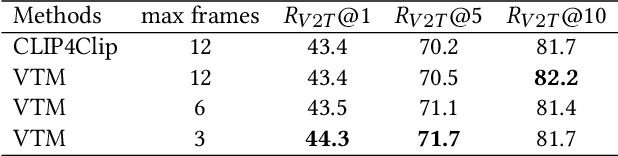
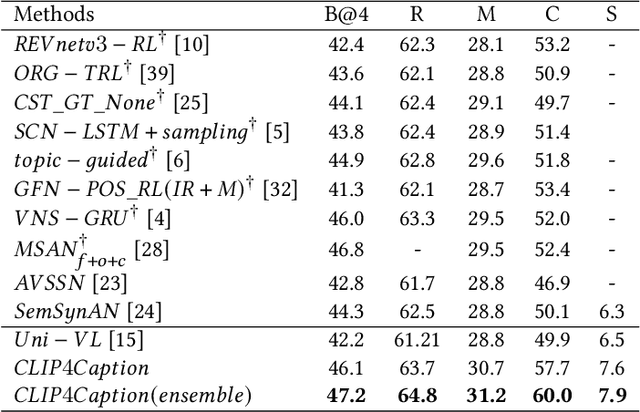
Video captioning is a challenging task since it requires generating sentences describing various diverse and complex videos. Existing video captioning models lack adequate visual representation due to the neglect of the existence of gaps between videos and texts. To bridge this gap, in this paper, we propose a CLIP4Caption framework that improves video captioning based on a CLIP-enhanced video-text matching network (VTM). This framework is taking full advantage of the information from both vision and language and enforcing the model to learn strongly text-correlated video features for text generation. Besides, unlike most existing models using LSTM or GRU as the sentence decoder, we adopt a Transformer structured decoder network to effectively learn the long-range visual and language dependency. Additionally, we introduce a novel ensemble strategy for captioning tasks. Experimental results demonstrate the effectiveness of our method on two datasets: 1) on MSR-VTT dataset, our method achieved a new state-of-the-art result with a significant gain of up to 10% in CIDEr; 2) on the private test data, our method ranking 2nd place in the ACM MM multimedia grand challenge 2021: Pre-training for Video Understanding Challenge. It is noted that our model is only trained on the MSR-VTT dataset.
WeClick: Weakly-Supervised Video Semantic Segmentation with Click Annotations
Aug 04, 2021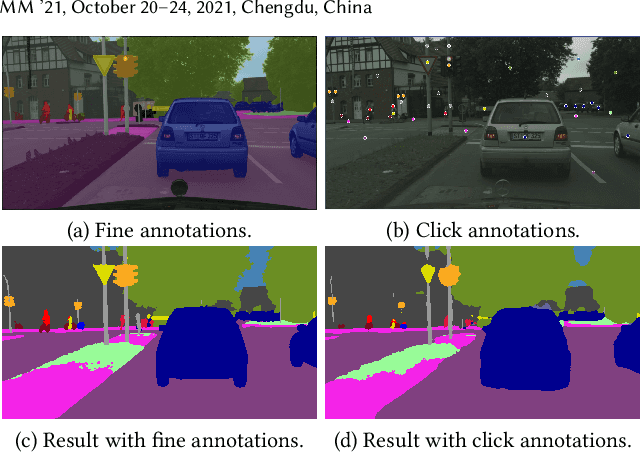
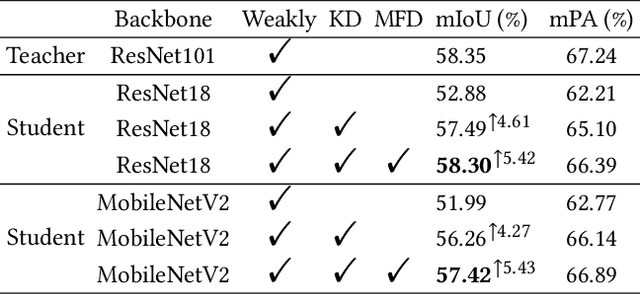
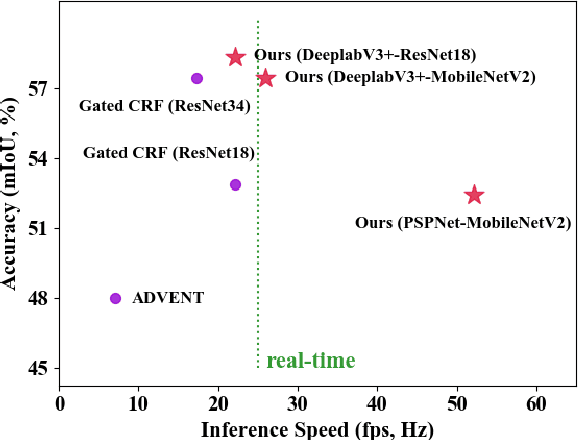
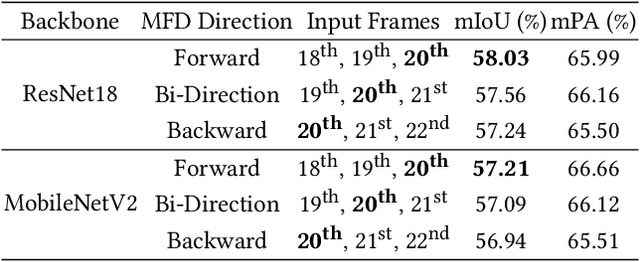
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
Sonorant spectra and coarticulation distinguish speakers with different dialects
Oct 07, 2021
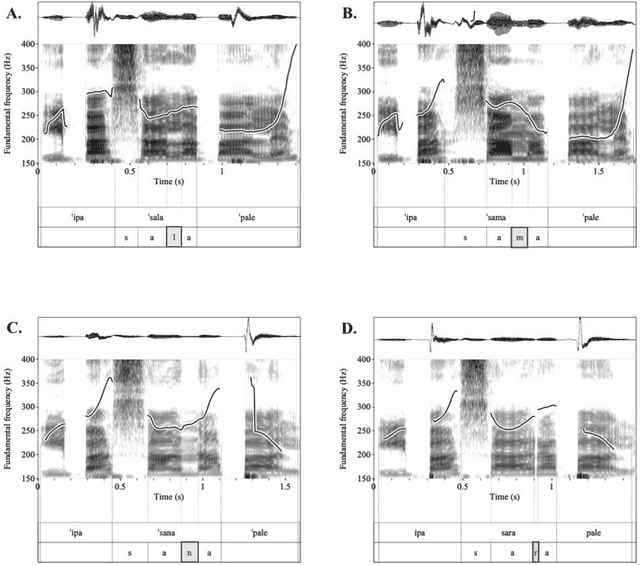
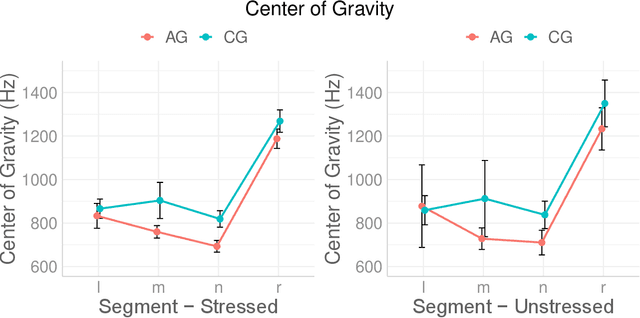
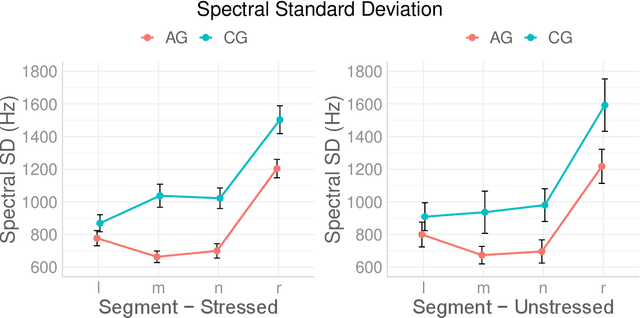
The aim of this study is to determine the effect of language varieties on the spectral distribution of stressed and unstressed sonorants (nasals /m, n/, lateral approximants /l/, and rhotics /r/) and on their coarticulatory effects on adjacent sounds. To quantify the shape of the spectral distribution, we calculated the spectral moments from the sonorant spectra of nasals /m, n/, lateral approximants /l/, and rhotics /r/ produced by Athenian Greek and Cypriot Greek speakers. To estimate the co-articulatory effects of sonorants on the adjacent vowels' F1 - F4 formant frequencies, we developed polynomial models of the adjacent vowel's formant contours. We found significant effects of language variety (sociolinguistic information) on the spectral moments of each sonorant /m/, /n/, /l/, /r/ (except between /m/ and /n/) and on the formant contours of the adjacent vowel. All sonorants (including /m/ and /n/) had distinct effects on adjacent vowel's formant contours, especially for F3 and F4. The study highlights that the combination of spectral moments and coarticulatory effects of sonorants determines linguistic (stress and phonemic category) and sociolinguistic (language variety) characteristics of sonorants. It also provides the first comparative acoustic analysis of Athenian Greek and Cypriot Greek sonorants.
Topologically Regularized Data Embeddings
Oct 18, 2021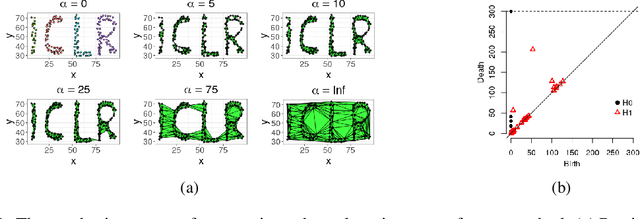

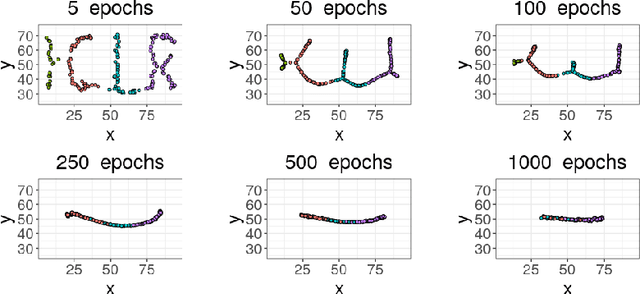

Unsupervised feature learning often finds low-dimensional embeddings that capture the structure of complex data. For tasks for which expert prior topological knowledge is available, incorporating this into the learned representation may lead to higher quality embeddings. For example, this may help one to embed the data into a given number of clusters, or to accommodate for noise that prevents one from deriving the distribution of the data over the model directly, which can then be learned more effectively. However, a general tool for integrating different prior topological knowledge into embeddings is lacking. Although differentiable topology layers have been recently developed that can (re)shape embeddings into prespecified topological models, they have two important limitations for representation learning, which we address in this paper. First, the currently suggested topological losses fail to represent simple models such as clusters and flares in a natural manner. Second, these losses neglect all original structural (such as neighborhood) information in the data that is useful for learning. We overcome these limitations by introducing a new set of topological losses, and proposing their usage as a way for topologically regularizing data embeddings to naturally represent a prespecified model. We include thorough experiments on synthetic and real data that highlight the usefulness and versatility of this approach, with applications ranging from modeling high-dimensional single cell data, to graph embedding.
Panoptic Multi-TSDFs: a Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency
Sep 21, 2021

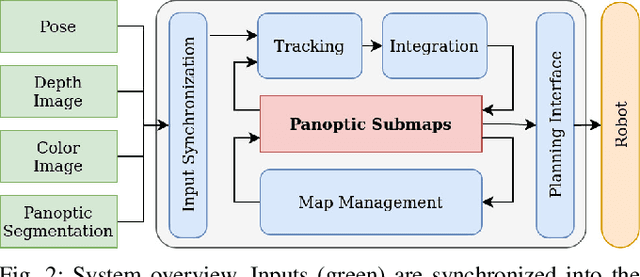
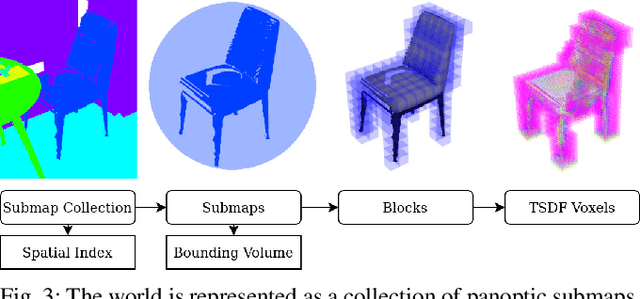
For robotic interaction in an environment shared with multiple agents, accessing a volumetric and semantic map of the scene is crucial. However, such environments are inevitably subject to long-term changes, which the map representation needs to account for.To this end, we propose panoptic multi-TSDFs, a novel representation for multi-resolution volumetric mapping over long periods of time. By leveraging high-level information for 3D reconstruction, our proposed system allocates high resolution only where needed. In addition, through reasoning on the object level, semantic consistency over time is achieved. This enables to maintain up-to-date reconstructions with high accuracy while improving coverage by incorporating and fusing previous data. We show in thorough experimental validations that our map representation can be efficiently constructed, maintained, and queried during online operation, and that the presented approach can operate robustly on real depth sensors using non-optimized panoptic segmentation as input.
A Cyber Threat Intelligence Sharing Scheme based on Federated Learning for Network Intrusion Detection
Nov 04, 2021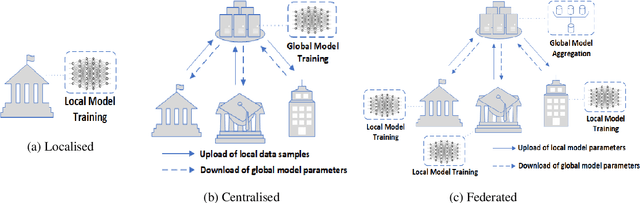

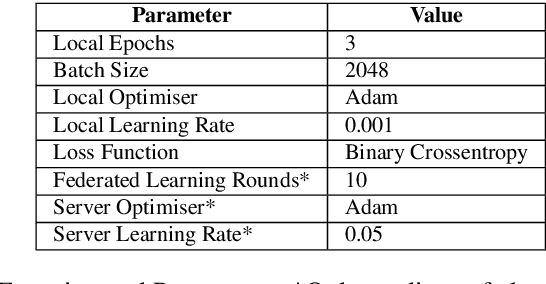
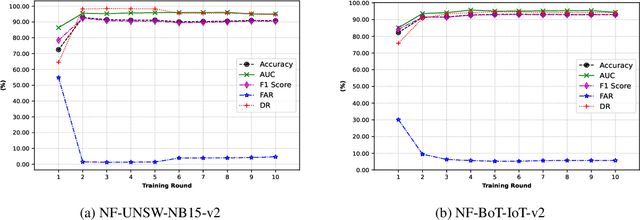
The uses of Machine Learning (ML) in detection of network attacks have been effective when designed and evaluated in a single organisation. However, it has been very challenging to design an ML-based detection system by utilising heterogeneous network data samples originating from several sources. This is mainly due to privacy concerns and the lack of a universal format of datasets. In this paper, we propose a collaborative federated learning scheme to address these issues. The proposed framework allows multiple organisations to join forces in the design, training, and evaluation of a robust ML-based network intrusion detection system. The threat intelligence scheme utilises two critical aspects for its application; the availability of network data traffic in a common format to allow for the extraction of meaningful patterns across data sources. Secondly, the adoption of a federated learning mechanism to avoid the necessity of sharing sensitive users' information between organisations. As a result, each organisation benefits from other organisations cyber threat intelligence while maintaining the privacy of its data internally. The model is trained locally and only the updated weights are shared with the remaining participants in the federated averaging process. The framework has been designed and evaluated in this paper by using two key datasets in a NetFlow format known as NF-UNSW-NB15-v2 and NF-BoT-IoT-v2. Two other common scenarios are considered in the evaluation process; a centralised training method where the local data samples are shared with other organisations and a localised training method where no threat intelligence is shared. The results demonstrate the efficiency and effectiveness of the proposed framework by designing a universal ML model effectively classifying benign and intrusive traffic originating from multiple organisations without the need for local data exchange.
Notes on Generalizing the Maximum Entropy Principle to Uncertain Data
Sep 09, 2021The principle of maximum entropy is a broadly applicable technique for computing a distribution with the least amount of information possible while commonly constrained to match empirically estimated feature expectations. We seek to generalize this principle to scenarios where the empirical feature expectations cannot be computed because the model variables are only partially observed, which introduces a dependency on the learned model. Extending and generalizing the principle of latent maximum entropy, we introduce uncertain maximum entropy and describe an expectation-maximization based solution to approximately solve these problems. We show that our technique generalizes the principle of maximum entropy and latent maximum entropy and discuss a generally applicable regularization technique for adding error terms to feature expectation constraints in the event of limited data.
Learning Meta-class Memory for Few-Shot Semantic Segmentation
Aug 10, 2021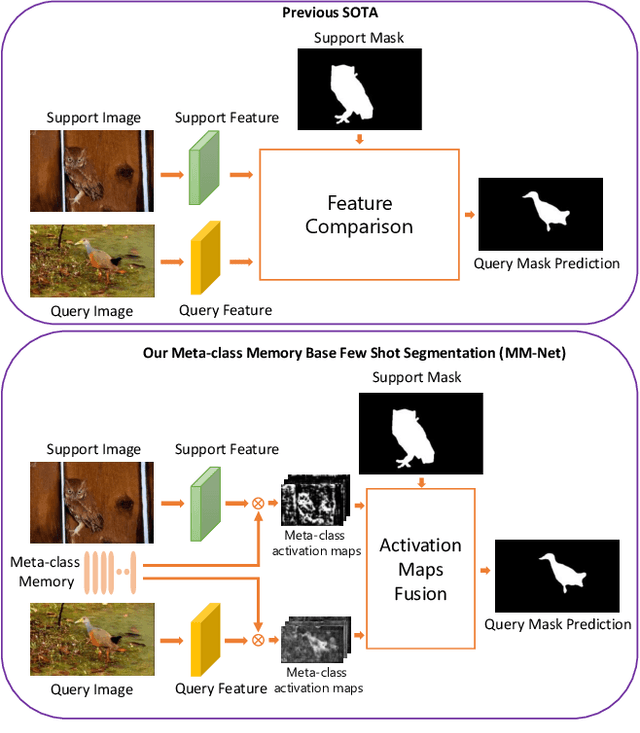
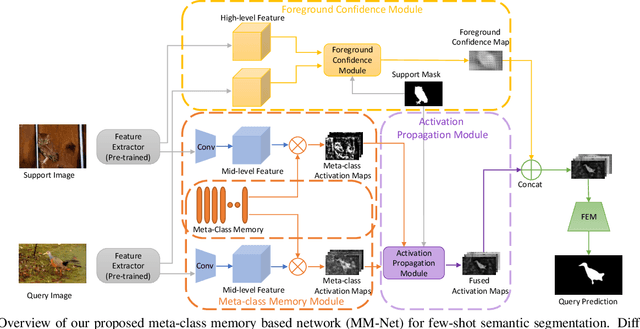
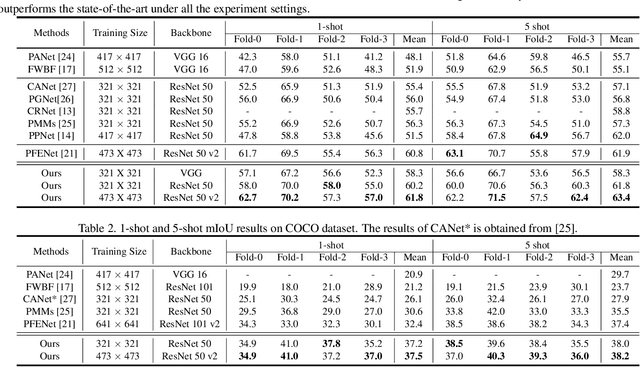
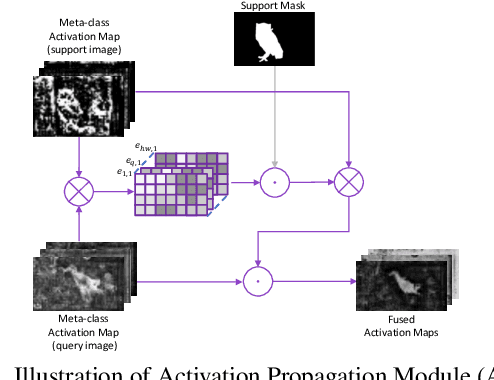
Currently, the state-of-the-art methods treat few-shot semantic segmentation task as a conditional foreground-background segmentation problem, assuming each class is independent. In this paper, we introduce the concept of meta-class, which is the meta information (e.g. certain middle-level features) shareable among all classes. To explicitly learn meta-class representations in few-shot segmentation task, we propose a novel Meta-class Memory based few-shot segmentation method (MM-Net), where we introduce a set of learnable memory embeddings to memorize the meta-class information during the base class training and transfer to novel classes during the inference stage. Moreover, for the $k$-shot scenario, we propose a novel image quality measurement module to select images from the set of support images. A high-quality class prototype could be obtained with the weighted sum of support image features based on the quality measure. Experiments on both PASCAL-$5^i$ and COCO dataset shows that our proposed method is able to achieve state-of-the-art results in both 1-shot and 5-shot settings. Particularly, our proposed MM-Net achieves 37.5\% mIoU on the COCO dataset in 1-shot setting, which is 5.1\% higher than the previous state-of-the-art.