 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting BERT For Multimodal Target Sentiment Classification Through Input Space Translation
Aug 05, 2021
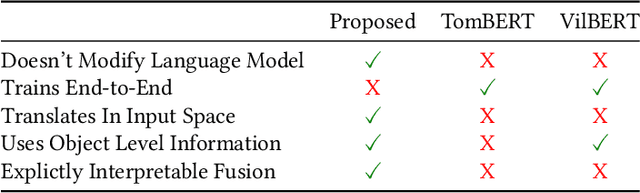
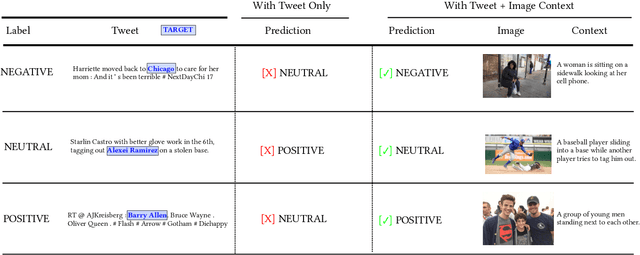

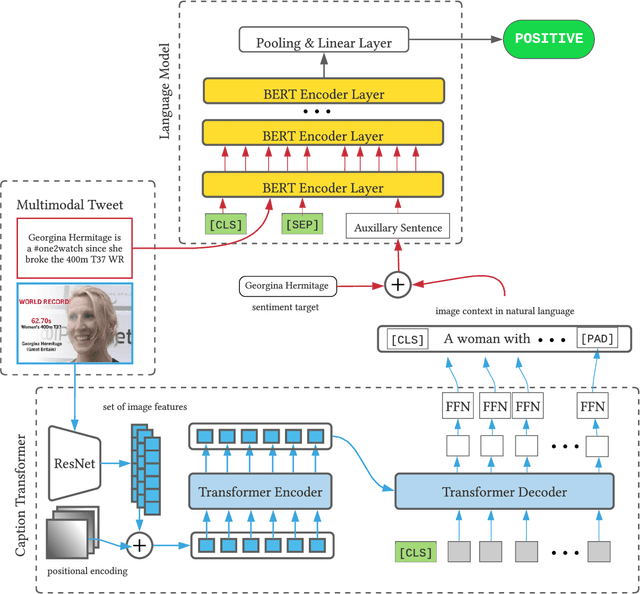
Multimodal target/aspect sentiment classification combines multimodal sentiment analysis and aspect/target sentiment classification. The goal of the task is to combine vision and language to understand the sentiment towards a target entity in a sentence. Twitter is an ideal setting for the task because it is inherently multimodal, highly emotional, and affects real world events. However, multimodal tweets are short and accompanied by complex, possibly irrelevant images. We introduce a two-stream model that translates images in input space using an object-aware transformer followed by a single-pass non-autoregressive text generation approach. We then leverage the translation to construct an auxiliary sentence that provides multimodal information to a language model. Our approach increases the amount of text available to the language model and distills the object-level information in complex images. We achieve state-of-the-art performance on two multimodal Twitter datasets without modifying the internals of the language model to accept multimodal data, demonstrating the effectiveness of our translation. In addition, we explain a failure mode of a popular approach for aspect sentiment analysis when applied to tweets. Our code is available at \textcolor{blue}{\url{https://github.com/codezakh/exploiting-BERT-thru-translation}}.
What Averages Do Not Tell -- Predicting Real Life Processes with Sequential Deep Learning
Oct 31, 2021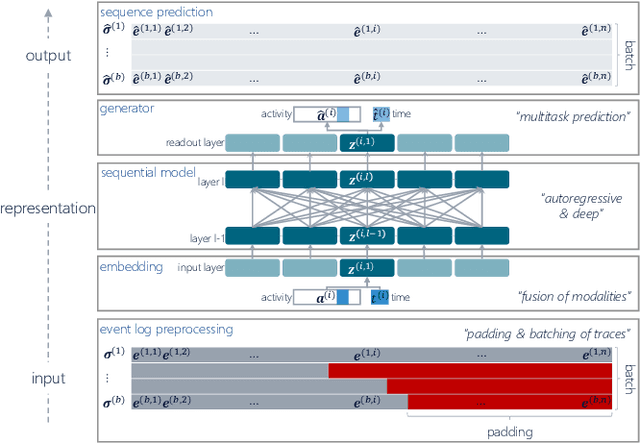
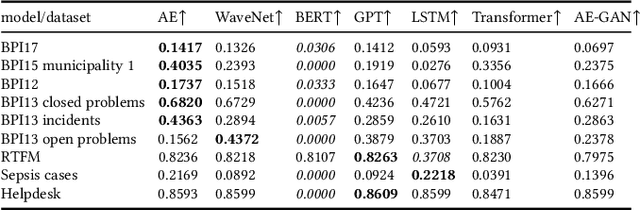
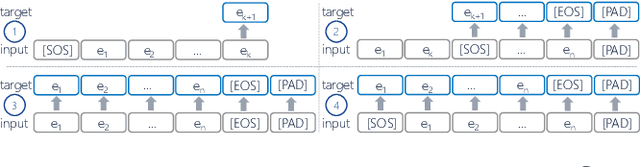
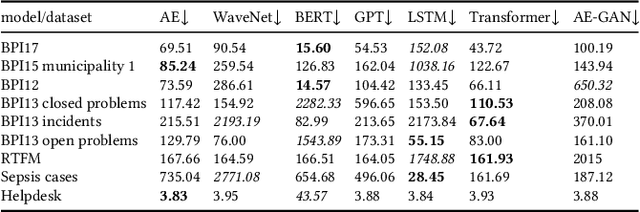
Deep Learning is proven to be an effective tool for modeling sequential data as shown by the success in Natural Language, Computer Vision and Signal Processing. Process Mining concerns discovering insights on business processes from their execution data that are logged by supporting information systems. The logged data (event log) is formed of event sequences (traces) that correspond to executions of a process. Many Deep Learning techniques have been successfully adapted for predictive Process Mining that aims to predict process outcomes, remaining time, the next event, or even the suffix of running traces. Traces in Process Mining are multimodal sequences and very differently structured than natural language sentences or images. This may require a different approach to processing. So far, there has been little focus on these differences and the challenges introduced. Looking at suffix prediction as the most challenging of these tasks, the performance of Deep Learning models was evaluated only on average measures and for a small number of real-life event logs. Comparing the results between papers is difficult due to different pre-processing and evaluation strategies. Challenges that may be relevant are the skewness of trace-length distribution and the skewness of the activity distribution in real-life event logs. We provide an end-to-end framework which enables to compare the performance of seven state-of-the-art sequential architectures in common settings. Results show that sequence modeling still has a lot of room for improvement for majority of the more complex datasets. Further research and insights are required to get consistent performance not just in average measures but additionally over all the prefixes.
Multimodal Meta-Learning for Time Series Regression
Aug 05, 2021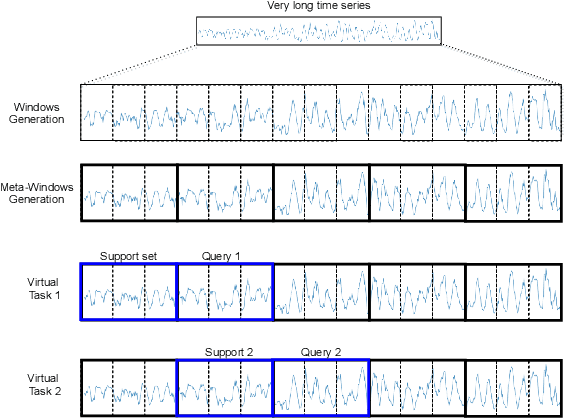
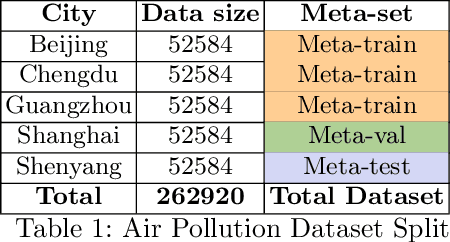
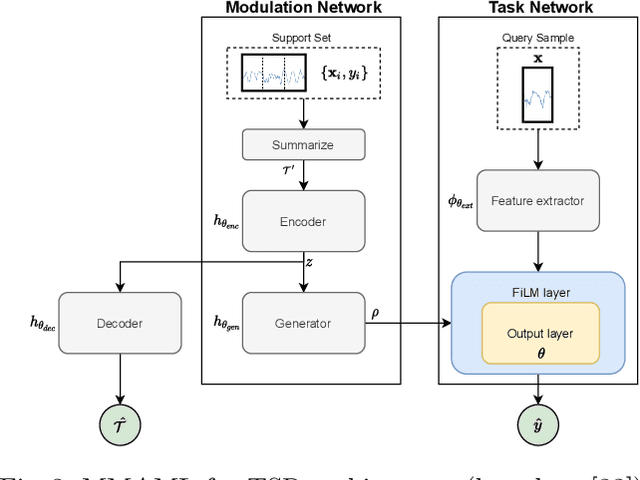
Recent work has shown the efficiency of deep learning models such as Fully Convolutional Networks (FCN) or Recurrent Neural Networks (RNN) to deal with Time Series Regression (TSR) problems. These models sometimes need a lot of data to be able to generalize, yet the time series are sometimes not long enough to be able to learn patterns. Therefore, it is important to make use of information across time series to improve learning. In this paper, we will explore the idea of using meta-learning for quickly adapting model parameters to new short-history time series by modifying the original idea of Model Agnostic Meta-Learning (MAML) \cite{finn2017model}. Moreover, based on prior work on multimodal MAML \cite{vuorio2019multimodal}, we propose a method for conditioning parameters of the model through an auxiliary network that encodes global information of the time series to extract meta-features. Finally, we apply the data to time series of different domains, such as pollution measurements, heart-rate sensors, and electrical battery data. We show empirically that our proposed meta-learning method learns TSR with few data fast and outperforms the baselines in 9 of 12 experiments.
A Speaker-Aware Learning Framework for Improving Multi-turn Dialogue Coherence
Oct 13, 2021
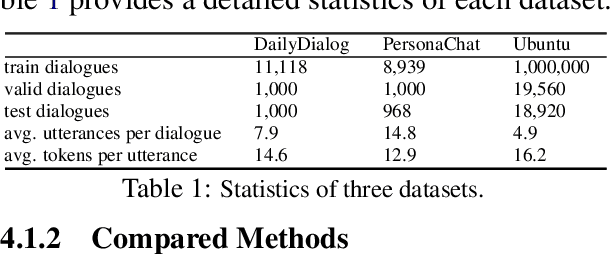
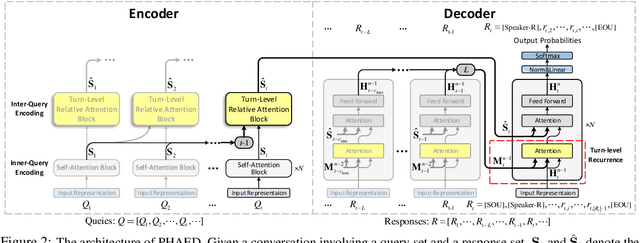
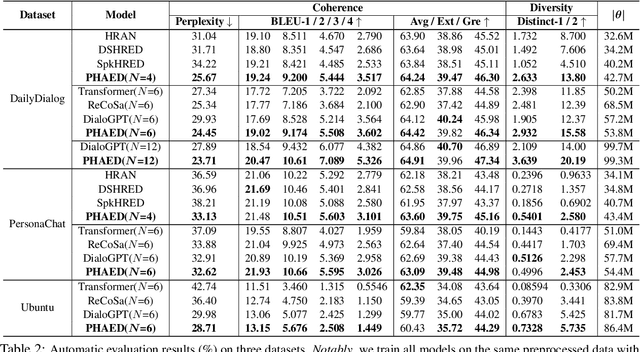
This paper presents a novel open-domain dialogue generation framework emphasizing the differentiation of speakers in multi-turn conversations. Differing from prior work that solely relies on the content of conversation history to generate a response, we argue that capturing relative social relations among utterances (i.e., generated by either the same speaker or different persons) benefits the machine capturing fine-grained context information from a conversation history to improve context coherence in the generated response. Given that, we propose a speaker-aware framework, named Parallel Hierarchical Attentive Encoder-Decoder (PHAED), that aims to model each utterance with the awareness of its speaker and contextual associations with the same speaker's previous messages. Specifically, in a conversation involving two speakers, we regard the utterances from one speaker as responses and those from the other as queries. After understanding queries via our encoder with inner-query and inter-query encodings, our decoder reuses the hidden states of previously generated responses to generate a new response. Our empirical results show that PHAED outperforms the state-of-the-art in both automatic and human evaluations. Furthermore, our ablation study shows that dialogue models with speaker tokens can generally decrease the possibility of generating non-coherent responses regarding the conversation context.
Exploring Classic and Neural Lexical Translation Models for Information Retrieval: Interpretability, Effectiveness, and Efficiency Benefits
Feb 12, 2021

We study the utility of the lexical translation model (IBM Model 1) for English text retrieval, in particular, its neural variants that are trained end-to-end. We use the neural Model1 as an aggregator layer applied to context-free or contextualized query/document embeddings. This new approach to design a neural ranking system has benefits for effectiveness, efficiency, and interpretability. Specifically, we show that adding an interpretable neural Model 1 layer on top of BERT-based contextualized embeddings (1) does not decrease accuracy and/or efficiency; and (2) may overcome the limitation on the maximum sequence length of existing BERT models. The context-free neural Model 1 is less effective than a BERT-based ranking model, but it can run efficiently on a CPU (without expensive index-time precomputation or query-time operations on large tensors). Using Model 1 we produced best neural and non-neural runs on the MS MARCO document ranking leaderboard in late 2020.
G-DetKD: Towards General Distillation Framework for Object Detectors via Contrastive and Semantic-guided Feature Imitation
Aug 17, 2021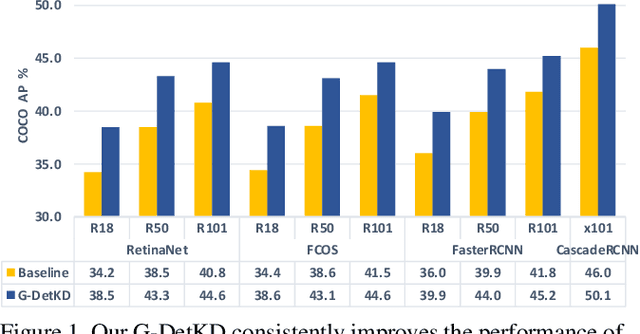
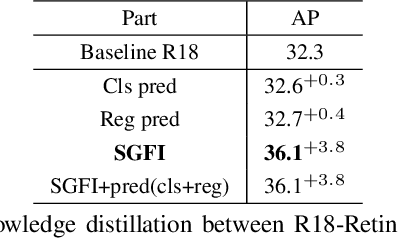
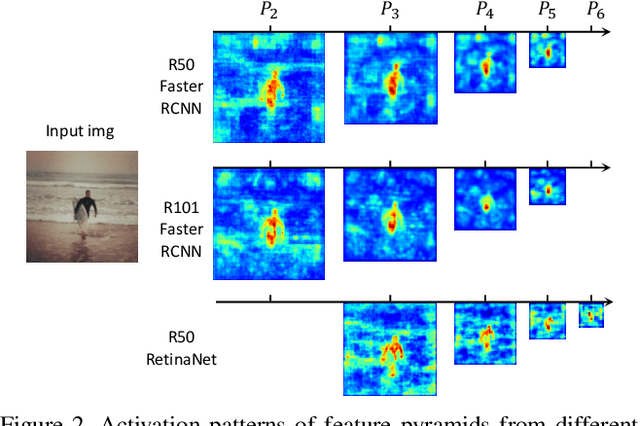
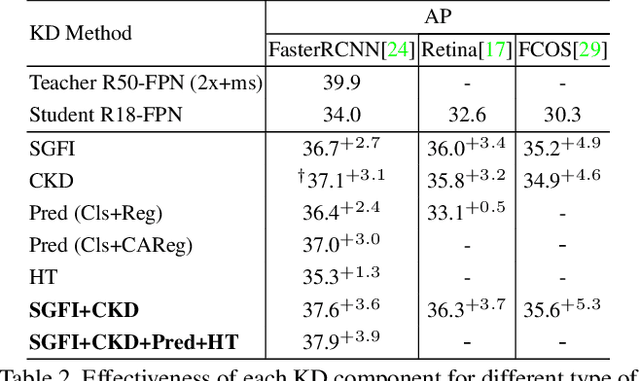
In this paper, we investigate the knowledge distillation (KD) strategy for object detection and propose an effective framework applicable to both homogeneous and heterogeneous student-teacher pairs. The conventional feature imitation paradigm introduces imitation masks to focus on informative foreground areas while excluding the background noises. However, we find that those methods fail to fully utilize the semantic information in all feature pyramid levels, which leads to inefficiency for knowledge distillation between FPN-based detectors. To this end, we propose a novel semantic-guided feature imitation technique, which automatically performs soft matching between feature pairs across all pyramid levels to provide the optimal guidance to the student. To push the envelop even further, we introduce contrastive distillation to effectively capture the information encoded in the relationship between different feature regions. Finally, we propose a generalized detection KD pipeline, which is capable of distilling both homogeneous and heterogeneous detector pairs. Our method consistently outperforms the existing detection KD techniques, and works when (1) components in the framework are used separately and in conjunction; (2) for both homogeneous and heterogenous student-teacher pairs and (3) on multiple detection benchmarks. With a powerful X101-FasterRCNN-Instaboost detector as the teacher, R50-FasterRCNN reaches 44.0% AP, R50-RetinaNet reaches 43.3% AP and R50-FCOS reaches 43.1% AP on COCO dataset.
Harvesting the Public MeSH Note field
Jun 01, 2021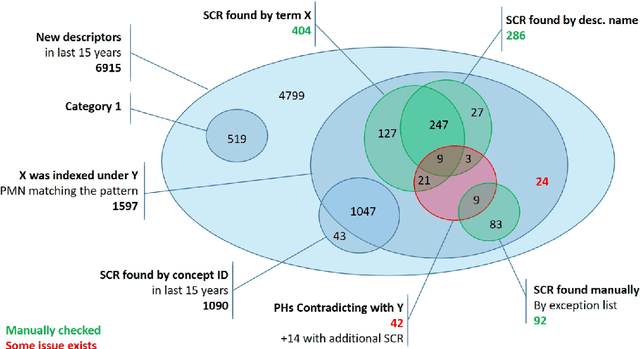

In this document, we report an analysis of the Public MeSH Note field of the new descriptors introduced in the MeSH thesaurus between 2006 and 2020. The aim of this analysis was to extract information about the previous status of these new descriptors as Supplementary Concept Records. The Public MeSH Note field contains information in semi-structured text, meant to be read by humans. Therefore, we adopted a semi-automated approach, based on regular expressions, to extract information from it. In the large majority of cases, we managed to minimize the required manual effort for extracting the previous state of a new descriptor as a Supplementary Concept Record. The source code for this analysis is openly available on GitHub.
A Cyber Threat Intelligence Sharing Scheme based on Federated Learning for Network Intrusion Detection
Nov 04, 2021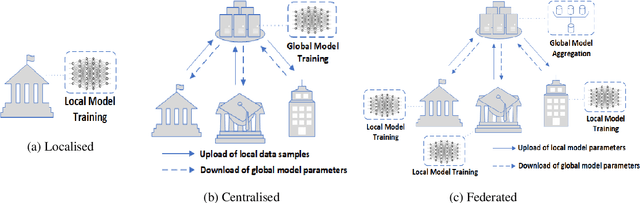

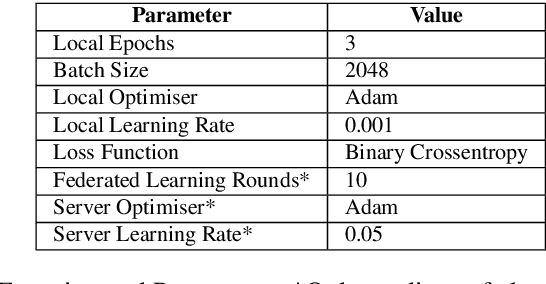
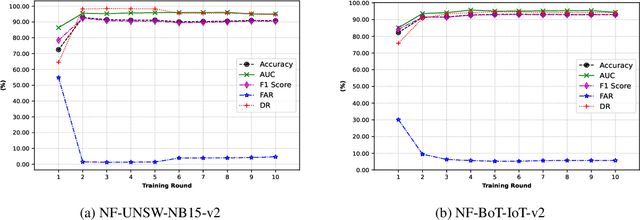
The uses of Machine Learning (ML) in detection of network attacks have been effective when designed and evaluated in a single organisation. However, it has been very challenging to design an ML-based detection system by utilising heterogeneous network data samples originating from several sources. This is mainly due to privacy concerns and the lack of a universal format of datasets. In this paper, we propose a collaborative federated learning scheme to address these issues. The proposed framework allows multiple organisations to join forces in the design, training, and evaluation of a robust ML-based network intrusion detection system. The threat intelligence scheme utilises two critical aspects for its application; the availability of network data traffic in a common format to allow for the extraction of meaningful patterns across data sources. Secondly, the adoption of a federated learning mechanism to avoid the necessity of sharing sensitive users' information between organisations. As a result, each organisation benefits from other organisations cyber threat intelligence while maintaining the privacy of its data internally. The model is trained locally and only the updated weights are shared with the remaining participants in the federated averaging process. The framework has been designed and evaluated in this paper by using two key datasets in a NetFlow format known as NF-UNSW-NB15-v2 and NF-BoT-IoT-v2. Two other common scenarios are considered in the evaluation process; a centralised training method where the local data samples are shared with other organisations and a localised training method where no threat intelligence is shared. The results demonstrate the efficiency and effectiveness of the proposed framework by designing a universal ML model effectively classifying benign and intrusive traffic originating from multiple organisations without the need for local data exchange.
From Observability to Significance in Distributed Information Systems
Jul 25, 2019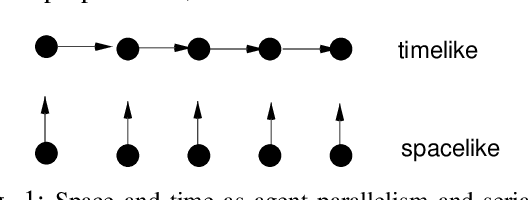
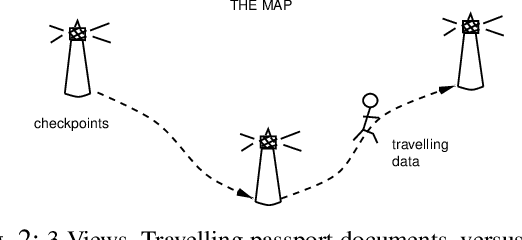
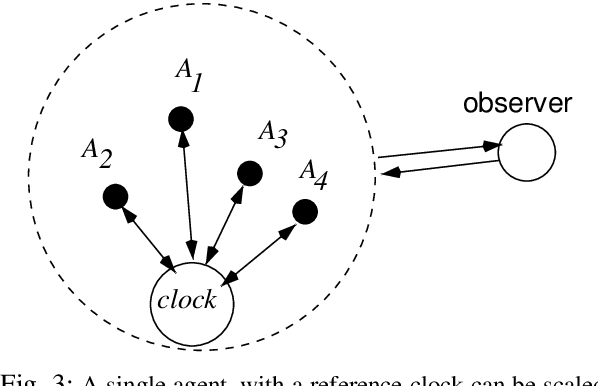
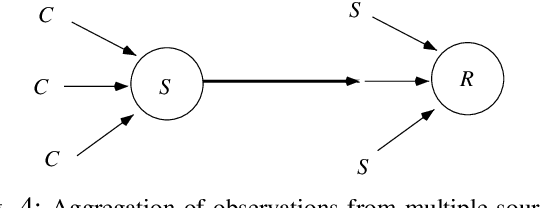
To understand and explain process behaviour we need to be able to see it, and decide its significance, i.e. be able to tell a story about its behaviours. This paper describes a few of the modelling challenges that underlie monitoring and observation of processes in IT, by human or by software. The topic of the observability of systems has been elevated recently in connection with computer monitoring and tracing of processes for debugging and forensics. It raises the issue of well-known principles of measurement, in bounded contexts, but these issues have been left implicit in the Computer Science literature. This paper aims to remedy this omission, by laying out a simple promise theoretic model, summarizing a long standing trail of work on the observation of distributed systems, based on elementary distinguishability of observations, and classical causality, with history. Three distinct views of a system are sought, across a number of scales, that described how information is transmitted (and lost) as it moves around the system, aggregated into journals and logs.
Conditionally Parameterized, Discretization-Aware Neural Networks for Mesh-Based Modeling of Physical Systems
Oct 08, 2021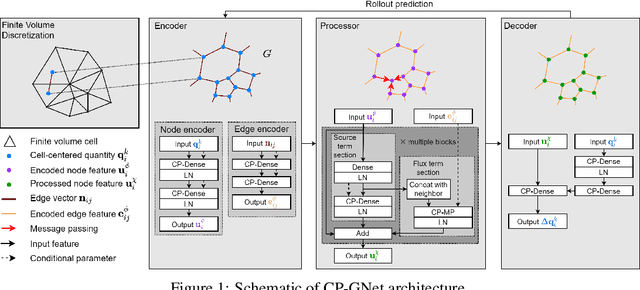
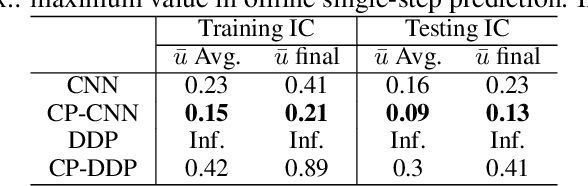
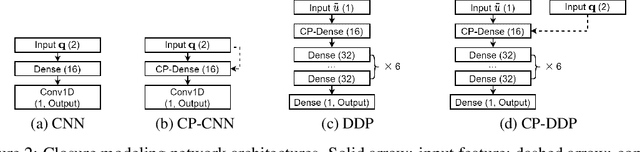

The numerical simulations of physical systems are heavily dependent on mesh-based models. While neural networks have been extensively explored to assist such tasks, they often ignore the interactions or hierarchical relations between input features, and process them as concatenated mixtures. In this work, we generalize the idea of conditional parametrization -- using trainable functions of input parameters to generate the weights of a neural network, and extend them in a flexible way to encode information critical to the numerical simulations. Inspired by discretized numerical methods, choices of the parameters include physical quantities and mesh topology features. The functional relation between the modeled features and the parameters are built into the network architecture. The method is implemented on different networks, which are applied to several frontier scientific machine learning tasks, including the discovery of unmodeled physics, super-resolution of coarse fields, and the simulation of unsteady flows with chemical reactions. The results show that the conditionally parameterized networks provide superior performance compared to their traditional counterparts. A network architecture named CP-GNet is also proposed as the first deep learning model capable of standalone prediction of reacting flows on irregular meshes.