 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting BERT For Multimodal Target Sentiment Classification Through Input Space Translation
Aug 05, 2021
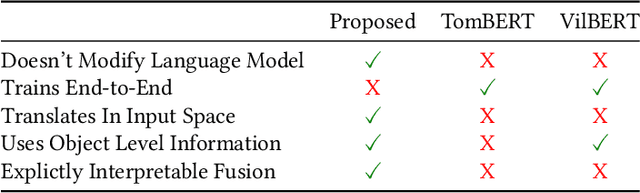
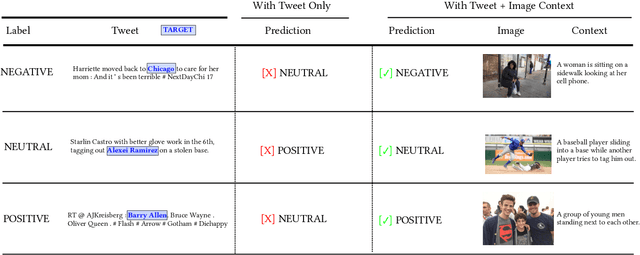

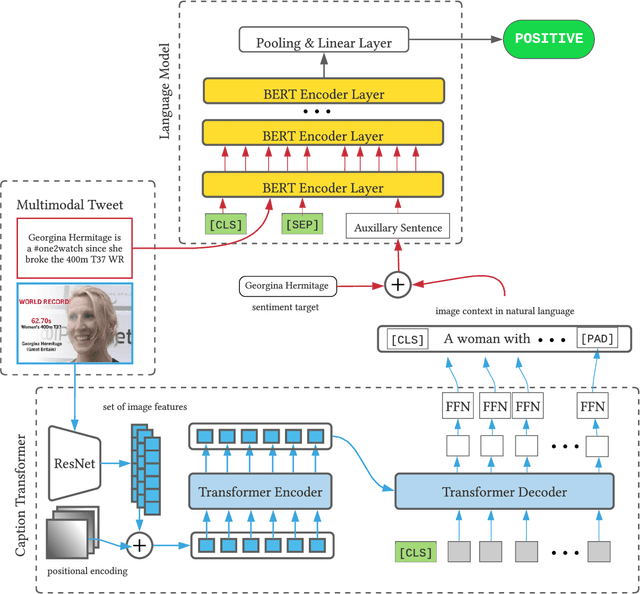
Multimodal target/aspect sentiment classification combines multimodal sentiment analysis and aspect/target sentiment classification. The goal of the task is to combine vision and language to understand the sentiment towards a target entity in a sentence. Twitter is an ideal setting for the task because it is inherently multimodal, highly emotional, and affects real world events. However, multimodal tweets are short and accompanied by complex, possibly irrelevant images. We introduce a two-stream model that translates images in input space using an object-aware transformer followed by a single-pass non-autoregressive text generation approach. We then leverage the translation to construct an auxiliary sentence that provides multimodal information to a language model. Our approach increases the amount of text available to the language model and distills the object-level information in complex images. We achieve state-of-the-art performance on two multimodal Twitter datasets without modifying the internals of the language model to accept multimodal data, demonstrating the effectiveness of our translation. In addition, we explain a failure mode of a popular approach for aspect sentiment analysis when applied to tweets. Our code is available at \textcolor{blue}{\url{https://github.com/codezakh/exploiting-BERT-thru-translation}}.
Multimodal Meta-Learning for Time Series Regression
Aug 05, 2021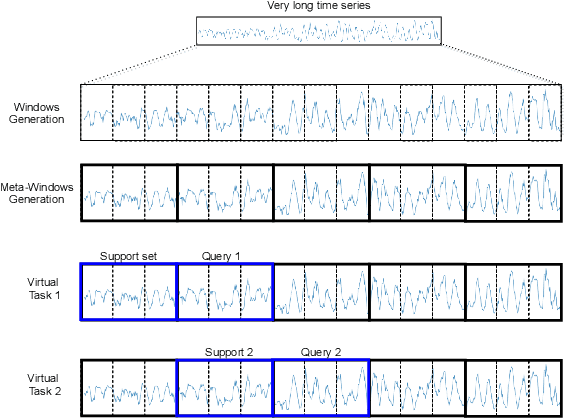
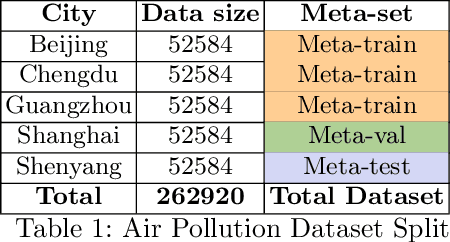
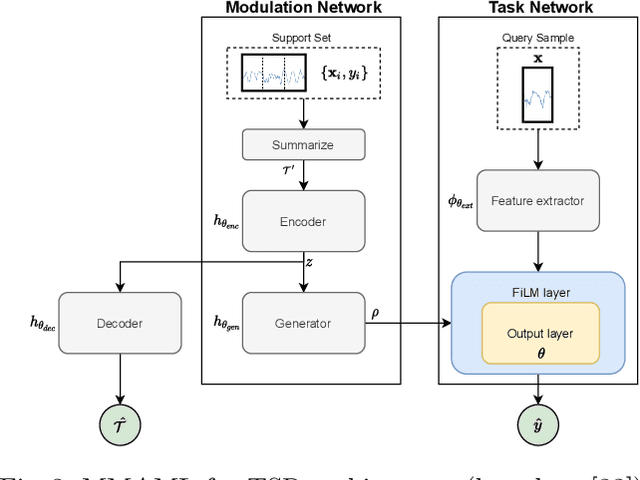
Recent work has shown the efficiency of deep learning models such as Fully Convolutional Networks (FCN) or Recurrent Neural Networks (RNN) to deal with Time Series Regression (TSR) problems. These models sometimes need a lot of data to be able to generalize, yet the time series are sometimes not long enough to be able to learn patterns. Therefore, it is important to make use of information across time series to improve learning. In this paper, we will explore the idea of using meta-learning for quickly adapting model parameters to new short-history time series by modifying the original idea of Model Agnostic Meta-Learning (MAML) \cite{finn2017model}. Moreover, based on prior work on multimodal MAML \cite{vuorio2019multimodal}, we propose a method for conditioning parameters of the model through an auxiliary network that encodes global information of the time series to extract meta-features. Finally, we apply the data to time series of different domains, such as pollution measurements, heart-rate sensors, and electrical battery data. We show empirically that our proposed meta-learning method learns TSR with few data fast and outperforms the baselines in 9 of 12 experiments.
Extracting Semantics from Maintenance Records
Aug 11, 2021

Rapid progress in natural language processing has led to its utilization in a variety of industrial and enterprise settings, including in its use for information extraction, specifically named entity recognition and relation extraction, from documents such as engineering manuals and field maintenance reports. While named entity recognition is a well-studied problem, existing state-of-the-art approaches require large labelled datasets which are hard to acquire for sensitive data such as maintenance records. Further, industrial domain experts tend to distrust results from black box machine learning models, especially when the extracted information is used in downstream predictive maintenance analytics. We overcome these challenges by developing three approaches built on the foundation of domain expert knowledge captured in dictionaries and ontologies. We develop a syntactic and semantic rules-based approach and an approach leveraging a pre-trained language model, fine-tuned for a question-answering task on top of our base dictionary lookup to extract entities of interest from maintenance records. We also develop a preliminary ontology to represent and capture the semantics of maintenance records. Our evaluations on a real-world aviation maintenance records dataset show promising results and help identify challenges specific to named entity recognition in the context of noisy industrial data.
Identifying causal associations in tweets using deep learning: Use case on diabetes-related tweets from 2017-2021
Nov 01, 2021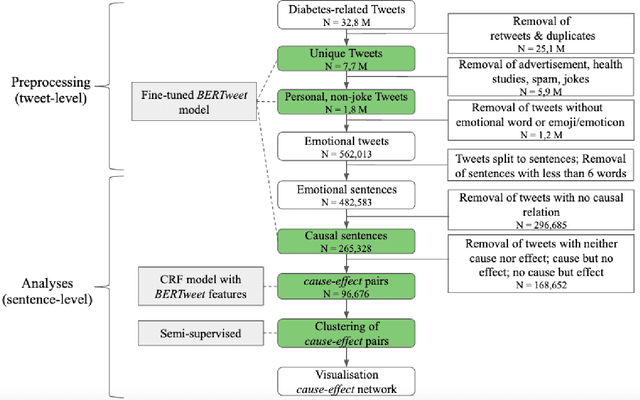
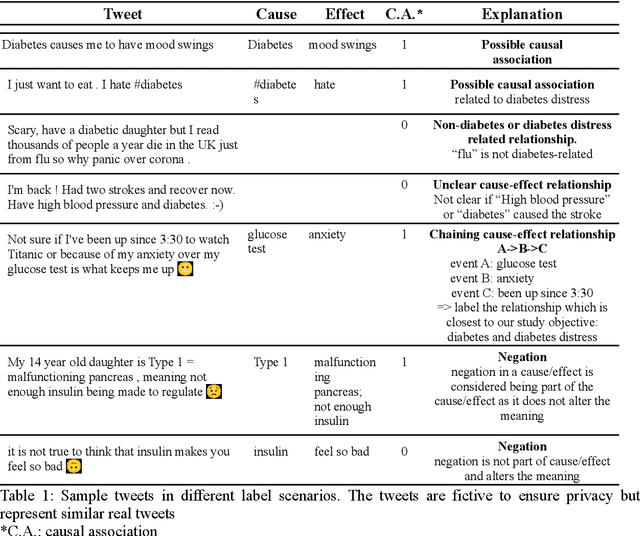
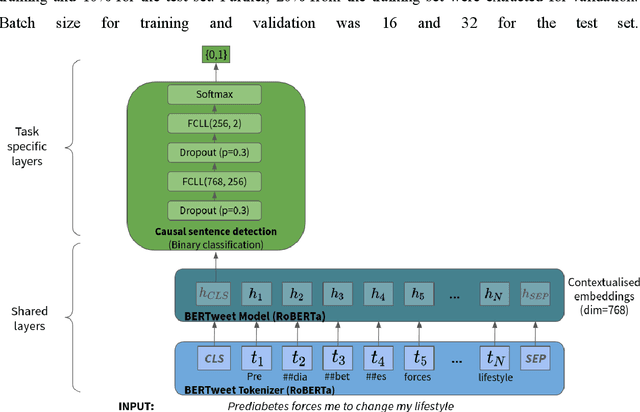
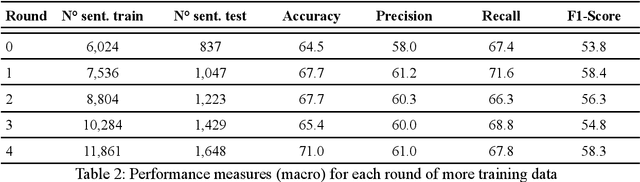
Objective: Leveraging machine learning methods, we aim to extract both explicit and implicit cause-effect associations in patient-reported, diabetes-related tweets and provide a tool to better understand opinion, feelings and observations shared within the diabetes online community from a causality perspective. Materials and Methods: More than 30 million diabetes-related tweets in English were collected between April 2017 and January 2021. Deep learning and natural language processing methods were applied to focus on tweets with personal and emotional content. A cause-effect-tweet dataset was manually labeled and used to train 1) a fine-tuned Bertweet model to detect causal sentences containing a causal association 2) a CRF model with BERT based features to extract possible cause-effect associations. Causes and effects were clustered in a semi-supervised approach and visualised in an interactive cause-effect-network. Results: Causal sentences were detected with a recall of 68% in an imbalanced dataset. A CRF model with BERT based features outperformed a fine-tuned BERT model for cause-effect detection with a macro recall of 68%. This led to 96,676 sentences with cause-effect associations. "Diabetes" was identified as the central cluster followed by "Death" and "Insulin". Insulin pricing related causes were frequently associated with "Death". Conclusions: A novel methodology was developed to detect causal sentences and identify both explicit and implicit, single and multi-word cause and corresponding effect as expressed in diabetes-related tweets leveraging BERT-based architectures and visualised as cause-effect-network. Extracting causal associations on real-life, patient reported outcomes in social media data provides a useful complementary source of information in diabetes research.
Deep Supervised Hashing leveraging Quadratic Spherical Mutual Information for Content-based Image Retrieval
Jan 16, 2019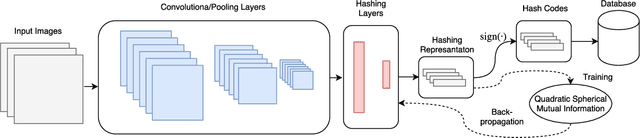

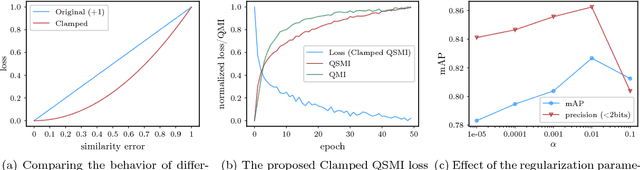
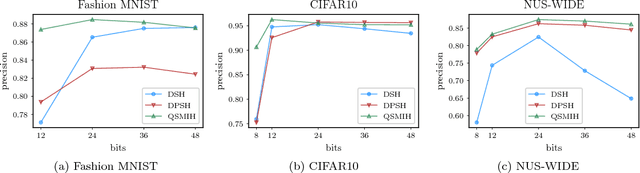
Several deep supervised hashing techniques have been proposed to allow for efficiently querying large image databases. However, deep supervised image hashing techniques are developed, to a great extent, heuristically often leading to suboptimal results. Contrary to this, we propose an efficient deep supervised hashing algorithm that optimizes the learned codes using an information-theoretic measure, the Quadratic Mutual Information (QMI). The proposed method is adapted to the needs of large-scale hashing and information retrieval leading to a novel information-theoretic measure, the Quadratic Spherical Mutual Information (QSMI). Apart from demonstrating the effectiveness of the proposed method under different scenarios and outperforming existing state-of-the-art image hashing techniques, this paper provides a structured way to model the process of information retrieval and develop novel methods adapted to the needs of each application.
Self-Supervised Video Representation Learning by Video Incoherence Detection
Sep 26, 2021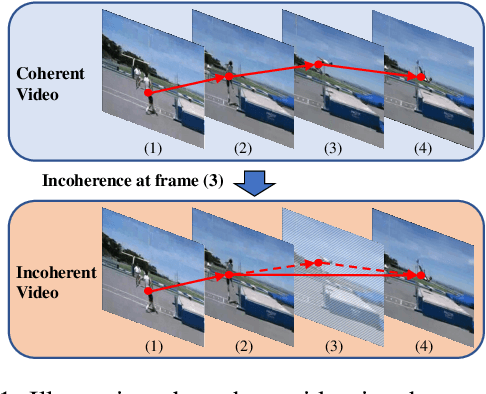
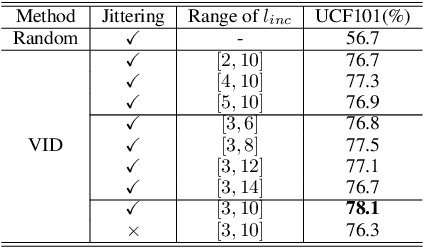
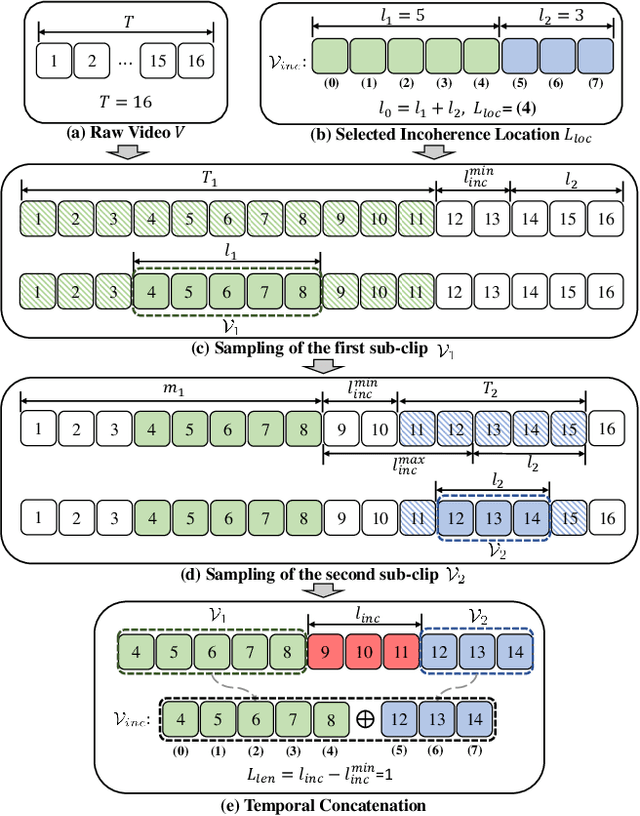
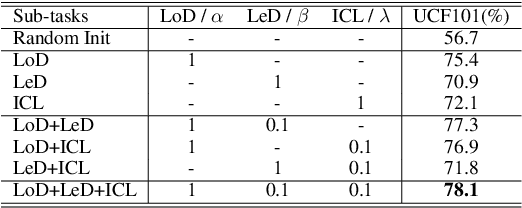
This paper introduces a novel self-supervised method that leverages incoherence detection for video representation learning. It roots from the observation that visual systems of human beings can easily identify video incoherence based on their comprehensive understanding of videos. Specifically, the training sample, denoted as the incoherent clip, is constructed by multiple sub-clips hierarchically sampled from the same raw video with various lengths of incoherence between each other. The network is trained to learn high-level representation by predicting the location and length of incoherence given the incoherent clip as input. Additionally, intra-video contrastive learning is introduced to maximize the mutual information between incoherent clips from the same raw video. We evaluate our proposed method through extensive experiments on action recognition and video retrieval utilizing various backbone networks. Experiments show that our proposed method achieves state-of-the-art performance across different backbone networks and different datasets compared with previous coherence-based methods.
Deep Learning Analysis of Cardiac MRI in Legacy Datasets: Multi-Ethnic Study of Atherosclerosis
Oct 28, 2021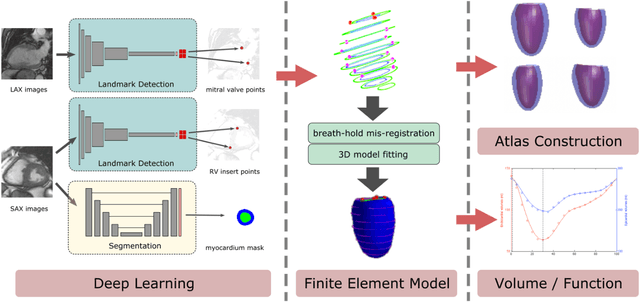
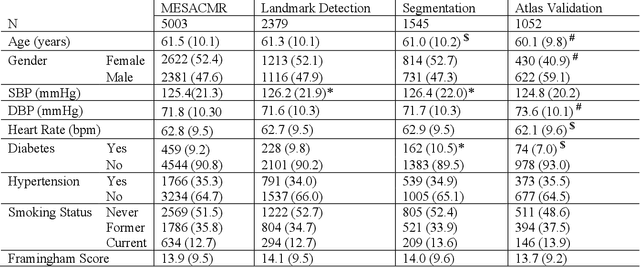
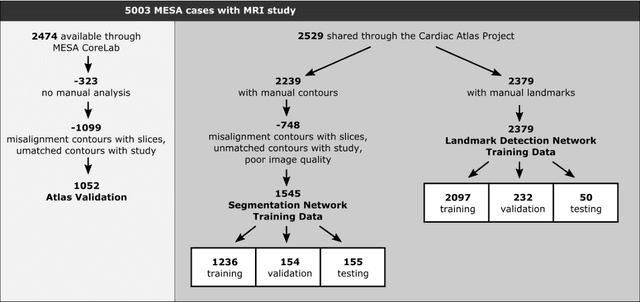
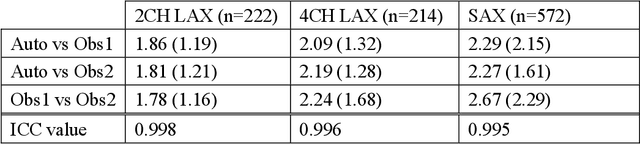
The shape and motion of the heart provide essential clues to understanding the mechanisms of cardiovascular disease. With the advent of large-scale cardiac imaging data, statistical atlases become a powerful tool to provide automated and precise quantification of the status of patient-specific heart geometry with respect to reference populations. The Multi-Ethnic Study of Atherosclerosis (MESA), begun in 2000, was the first large cohort study to incorporate cardiovascular MRI in over 5000 participants, and there is now a wealth of follow-up data over 20 years. Building a machine learning based automated analysis is necessary to extract the additional imaging information necessary for expanding original manual analyses. However, machine learning tools trained on MRI datasets with different pulse sequences fail on such legacy datasets. Here, we describe an automated atlas construction pipeline using deep learning methods applied to the legacy cardiac MRI data in MESA. For detection of anatomical cardiac landmark points, a modified VGGNet convolutional neural network architecture was used in conjunction with a transfer learning sequence between two-chamber, four-chamber, and short-axis MRI views. A U-Net architecture was used for detection of the endocardial and epicardial boundaries in short axis images. Both network architectures resulted in good segmentation and landmark detection accuracies compared with inter-observer variations. Statistical relationships with common risk factors were similar between atlases derived from automated vs manual annotations. The automated atlas can be employed in future studies to examine the relationships between cardiac morphology and future events.
From Observability to Significance in Distributed Information Systems
Jul 25, 2019
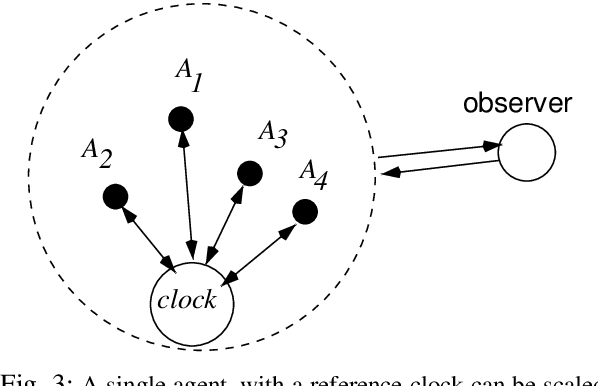
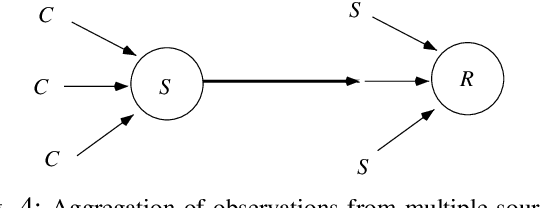
To understand and explain process behaviour we need to be able to see it, and decide its significance, i.e. be able to tell a story about its behaviours. This paper describes a few of the modelling challenges that underlie monitoring and observation of processes in IT, by human or by software. The topic of the observability of systems has been elevated recently in connection with computer monitoring and tracing of processes for debugging and forensics. It raises the issue of well-known principles of measurement, in bounded contexts, but these issues have been left implicit in the Computer Science literature. This paper aims to remedy this omission, by laying out a simple promise theoretic model, summarizing a long standing trail of work on the observation of distributed systems, based on elementary distinguishability of observations, and classical causality, with history. Three distinct views of a system are sought, across a number of scales, that described how information is transmitted (and lost) as it moves around the system, aggregated into journals and logs.
Estimating Redundancy in Clinical Text
May 25, 2021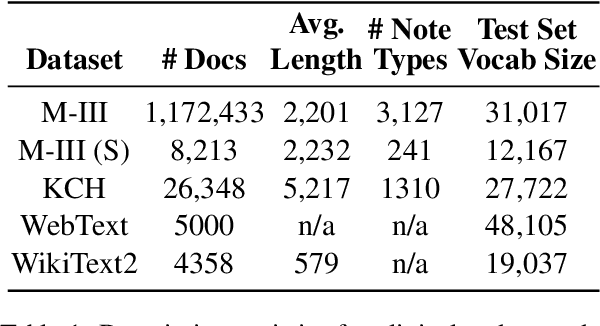
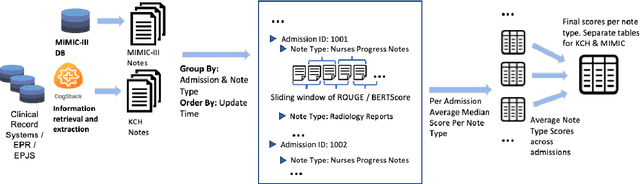
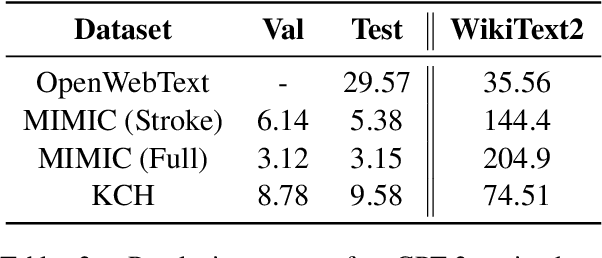
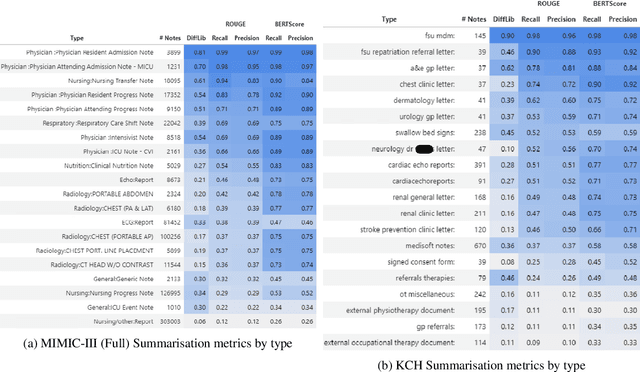
The current mode of use of Electronic Health Record (EHR) elicits text redundancy. Clinicians often populate new documents by duplicating existing notes, then updating accordingly. Data duplication can lead to a propagation of errors, inconsistencies and misreporting of care. Therefore, quantifying information redundancy can play an essential role in evaluating innovations that operate on clinical narratives. This work is a quantitative examination of information redundancy in EHR notes. We present and evaluate two strategies to measure redundancy: an information-theoretic approach and a lexicosyntactic and semantic model. We evaluate the measures by training large Transformer-based language models using clinical text from a large openly available US-based ICU dataset and a large multi-site UK based Trust. By comparing the information-theoretic content of the trained models with open-domain language models, the language models trained using clinical text have shown ~1.5x to ~3x less efficient than open-domain corpora. Manual evaluation shows a high correlation with lexicosyntactic and semantic redundancy, with averages ~43 to ~65%.
G-DetKD: Towards General Distillation Framework for Object Detectors via Contrastive and Semantic-guided Feature Imitation
Aug 17, 2021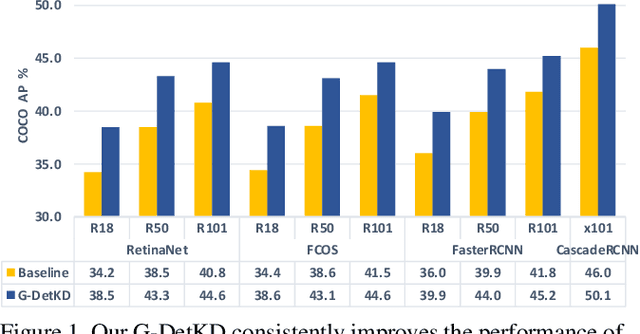
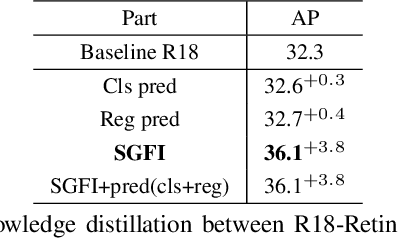
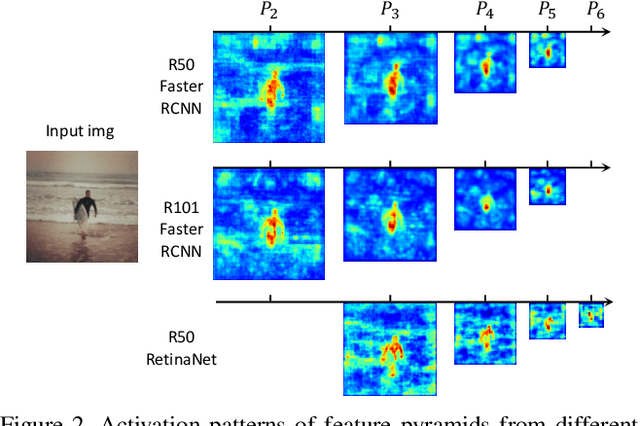
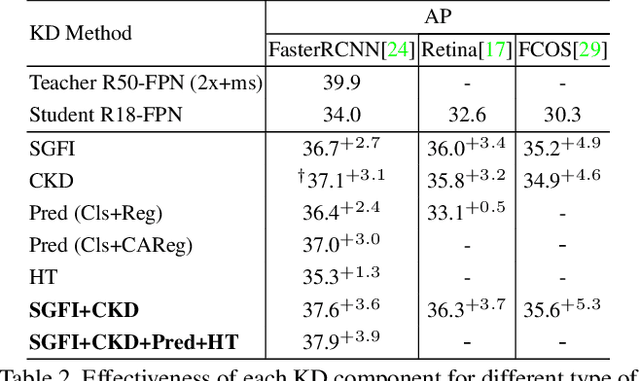
In this paper, we investigate the knowledge distillation (KD) strategy for object detection and propose an effective framework applicable to both homogeneous and heterogeneous student-teacher pairs. The conventional feature imitation paradigm introduces imitation masks to focus on informative foreground areas while excluding the background noises. However, we find that those methods fail to fully utilize the semantic information in all feature pyramid levels, which leads to inefficiency for knowledge distillation between FPN-based detectors. To this end, we propose a novel semantic-guided feature imitation technique, which automatically performs soft matching between feature pairs across all pyramid levels to provide the optimal guidance to the student. To push the envelop even further, we introduce contrastive distillation to effectively capture the information encoded in the relationship between different feature regions. Finally, we propose a generalized detection KD pipeline, which is capable of distilling both homogeneous and heterogeneous detector pairs. Our method consistently outperforms the existing detection KD techniques, and works when (1) components in the framework are used separately and in conjunction; (2) for both homogeneous and heterogenous student-teacher pairs and (3) on multiple detection benchmarks. With a powerful X101-FasterRCNN-Instaboost detector as the teacher, R50-FasterRCNN reaches 44.0% AP, R50-RetinaNet reaches 43.3% AP and R50-FCOS reaches 43.1% AP on COCO dataset.