 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Nonparametric Sparse Tensor Factorization with Hierarchical Gamma Processes
Oct 19, 2021

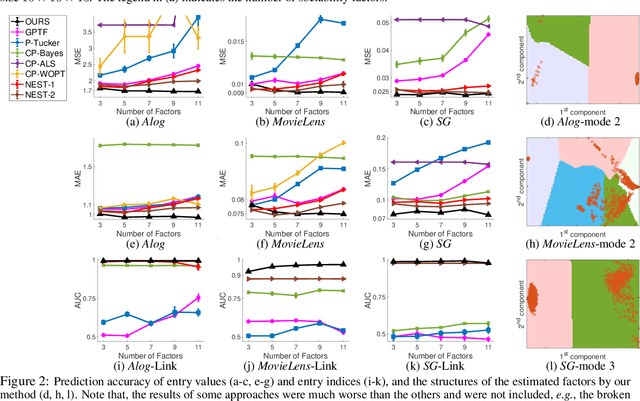
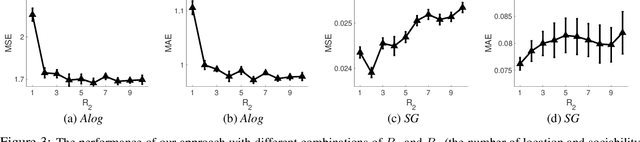
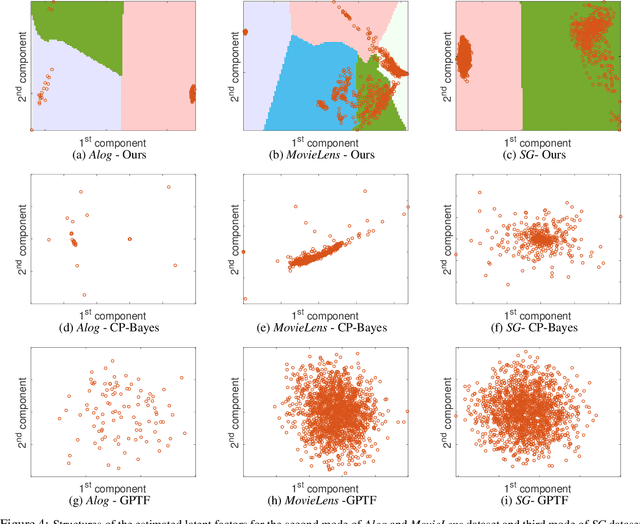
We propose a nonparametric factorization approach for sparsely observed tensors. The sparsity does not mean zero-valued entries are massive or dominated. Rather, it implies the observed entries are very few, and even fewer with the growth of the tensor; this is ubiquitous in practice. Compared with the existent works, our model not only leverages the structural information underlying the observed entry indices, but also provides extra interpretability and flexibility -- it can simultaneously estimate a set of location factors about the intrinsic properties of the tensor nodes, and another set of sociability factors reflecting their extrovert activity in interacting with others; users are free to choose a trade-off between the two types of factors. Specifically, we use hierarchical Gamma processes and Poisson random measures to construct a tensor-valued process, which can freely sample the two types of factors to generate tensors and always guarantees an asymptotic sparsity. We then normalize the tensor process to obtain hierarchical Dirichlet processes to sample each observed entry index, and use a Gaussian process to sample the entry value as a nonlinear function of the factors, so as to capture both the sparse structure properties and complex node relationships. For efficient inference, we use Dirichlet process properties over finite sample partitions, density transformations, and random features to develop a stochastic variational estimation algorithm. We demonstrate the advantage of our method in several benchmark datasets.
A Simple, Strong and Robust Baseline for Distantly Supervised Relation Extraction
Oct 14, 2021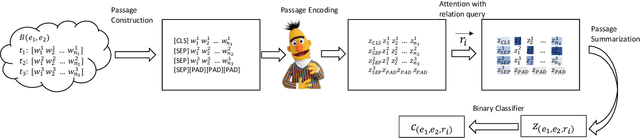
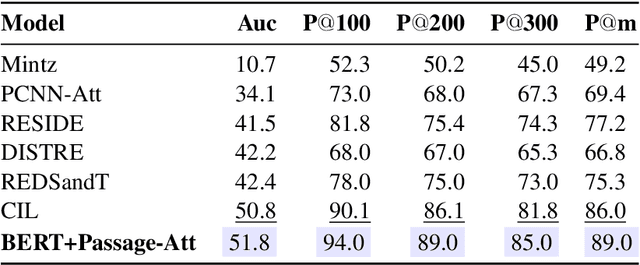
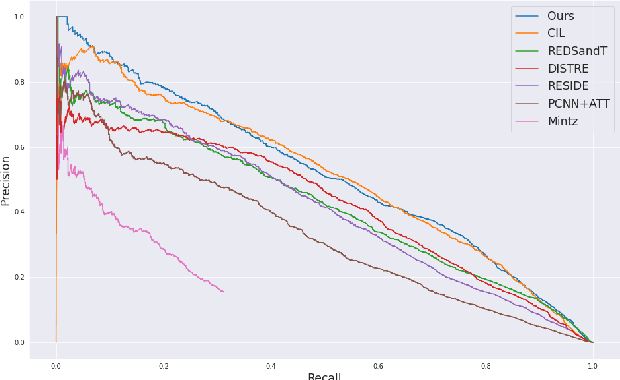

Distantly supervised relation extraction (DS-RE) is generally framed as a multi-instance multi-label (MI-ML) task, where the optimal aggregation of information from multiple instances is of key importance. Intra-bag attention (Lin et al., 2016) is an example of a popularly used aggregation scheme for this framework. Apart from this scheme, however, there is not much to choose from in the DS-RE literature as most of the advances in this field are focused on improving the instance-encoding step rather than the instance-aggregation step. With recent works leveraging large pre-trained language models as encoders, the increased capacity of models might allow for more flexibility in the instance-aggregation step. In this work, we explore this hypothesis and come up with a novel aggregation scheme which we call Passage-Att. Under this aggregation scheme, we combine all instances mentioning an entity pair into a "passage of instances", which is summarized independently for each relation class. These summaries are used to predict the validity of a potential triple. We show that our Passage-Att with BERT as passage encoder achieves state-of-the-art performance in three different settings (monolingual DS, monolingual DS with manually-annotated test set, multilingual DS).
Socially assistive robots' deployment in healthcare settings: a global perspective
Oct 14, 2021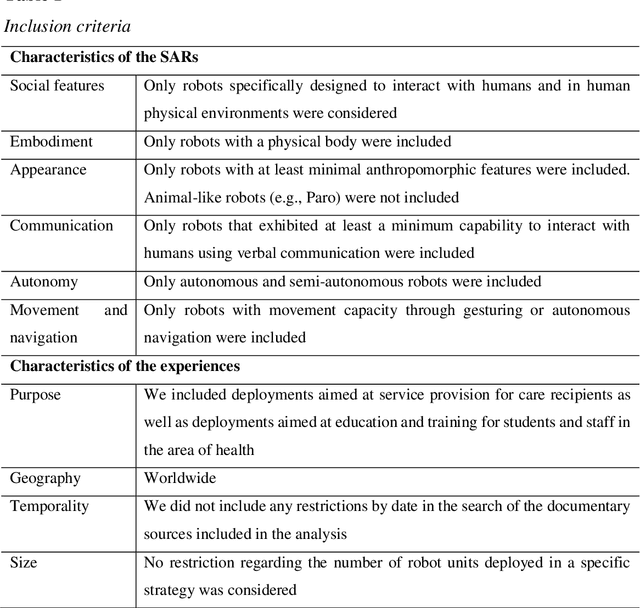
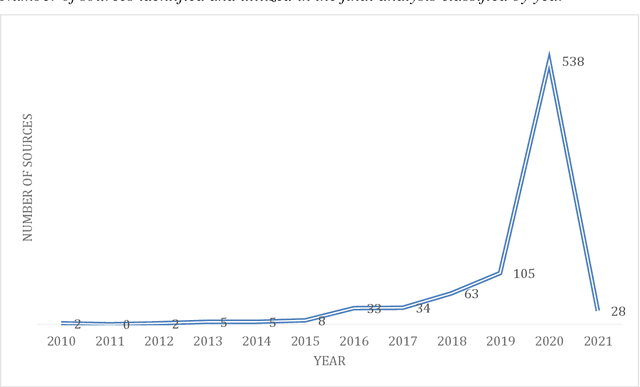
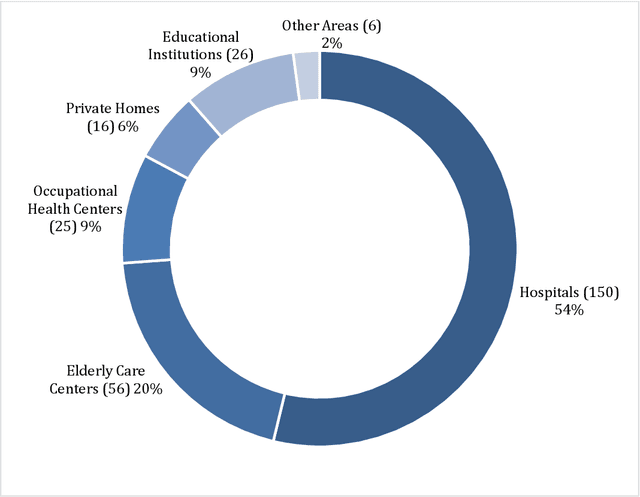
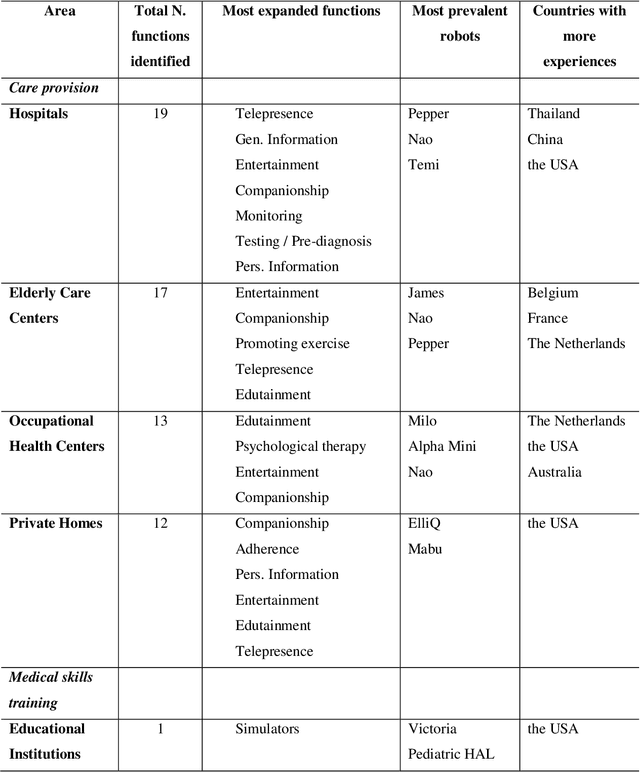
One of the major areas where social robots are finding their place in society is for healthcare-related applications. Yet, very little research has mapped the deployment of socially assistive robots (SARs) in real settings. Using a documentary research method, we were able to trace back 279 experiences of SARs deployments in hospitals, elderly care centers, occupational health centers, private homes, and educational institutions worldwide from 33 different countries, and involving 52 different robot models. We retrieved, analyzed, and classified the functions that SARs develop in these experiences, the areas in which they are deployed, the principal manufacturers, and the robot models that are being adopted. The functions we identified for SARs are entertainment, companionship, telepresence, edutainment, providing general and personalized information or advice, monitoring, promotion of physical exercise and rehabilitation, testing and pre-diagnosis, delivering supplies, patient registration, giving location indications, patient simulator, protective measure enforcement, medication and well-being adherence, translating and having conversations in multiple languages, psychological therapy, patrolling, interacting with digital devices, and disinfection. Our work provides an in-depth picture of the current state of the art of SARs' deployment in real scenarios for healthcare-related applications and contributes to understanding better the role of these machines in the healthcare sector.
Aspect-Sentiment-Multiple-Opinion Triplet Extraction
Oct 14, 2021
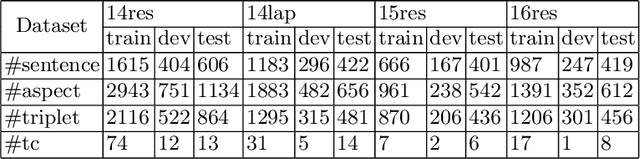
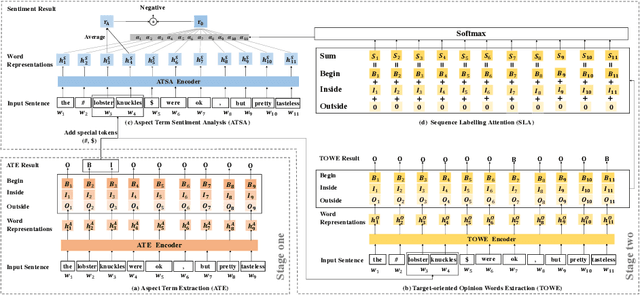
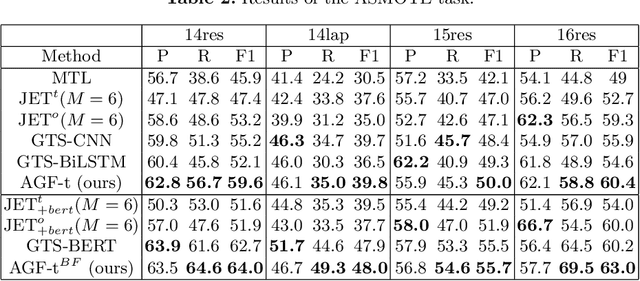
Aspect Sentiment Triplet Extraction (ASTE) aims to extract aspect term (aspect), sentiment and opinion term (opinion) triplets from sentences and can tell a complete story, i.e., the discussed aspect, the sentiment toward the aspect, and the cause of the sentiment. ASTE is a charming task, however, one triplet extracted by ASTE only includes one opinion of the aspect, but an aspect in a sentence may have multiple corresponding opinions and one opinion only provides part of the reason why the aspect has this sentiment, as a consequence, some triplets extracted by ASTE are hard to understand, and provide erroneous information for downstream tasks. In this paper, we introduce a new task, named Aspect Sentiment Multiple Opinions Triplet Extraction (ASMOTE). ASMOTE aims to extract aspect, sentiment and multiple opinions triplets. Specifically, one triplet extracted by ASMOTE contains all opinions about the aspect and can tell the exact reason that the aspect has the sentiment. We propose an Aspect-Guided Framework (AGF) to address this task. AGF first extracts aspects, then predicts their opinions and sentiments. Moreover, with the help of the proposed Sequence Labeling Attention(SLA), AGF improves the performance of the sentiment classification using the extracted opinions. Experimental results on multiple datasets demonstrate the effectiveness of our approach.
Deep Learning Analysis of Cardiac MRI in Legacy Datasets: Multi-Ethnic Study of Atherosclerosis
Oct 28, 2021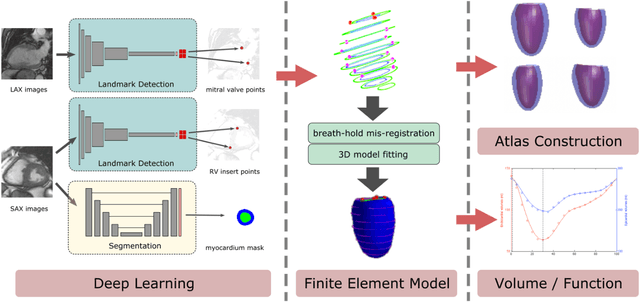
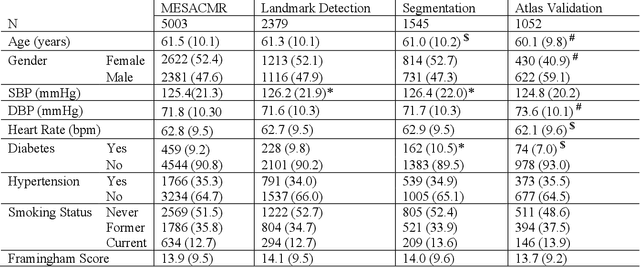
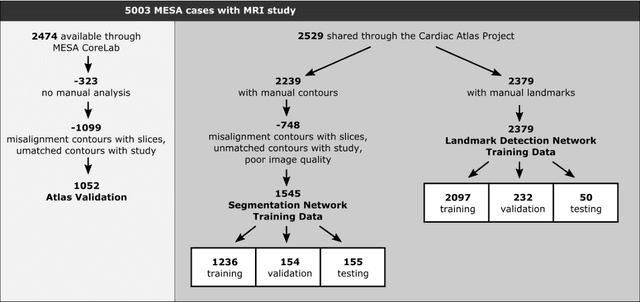
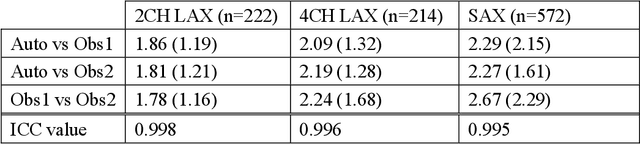
The shape and motion of the heart provide essential clues to understanding the mechanisms of cardiovascular disease. With the advent of large-scale cardiac imaging data, statistical atlases become a powerful tool to provide automated and precise quantification of the status of patient-specific heart geometry with respect to reference populations. The Multi-Ethnic Study of Atherosclerosis (MESA), begun in 2000, was the first large cohort study to incorporate cardiovascular MRI in over 5000 participants, and there is now a wealth of follow-up data over 20 years. Building a machine learning based automated analysis is necessary to extract the additional imaging information necessary for expanding original manual analyses. However, machine learning tools trained on MRI datasets with different pulse sequences fail on such legacy datasets. Here, we describe an automated atlas construction pipeline using deep learning methods applied to the legacy cardiac MRI data in MESA. For detection of anatomical cardiac landmark points, a modified VGGNet convolutional neural network architecture was used in conjunction with a transfer learning sequence between two-chamber, four-chamber, and short-axis MRI views. A U-Net architecture was used for detection of the endocardial and epicardial boundaries in short axis images. Both network architectures resulted in good segmentation and landmark detection accuracies compared with inter-observer variations. Statistical relationships with common risk factors were similar between atlases derived from automated vs manual annotations. The automated atlas can be employed in future studies to examine the relationships between cardiac morphology and future events.
MovieCuts: A New Dataset and Benchmark for Cut Type Recognition
Sep 19, 2021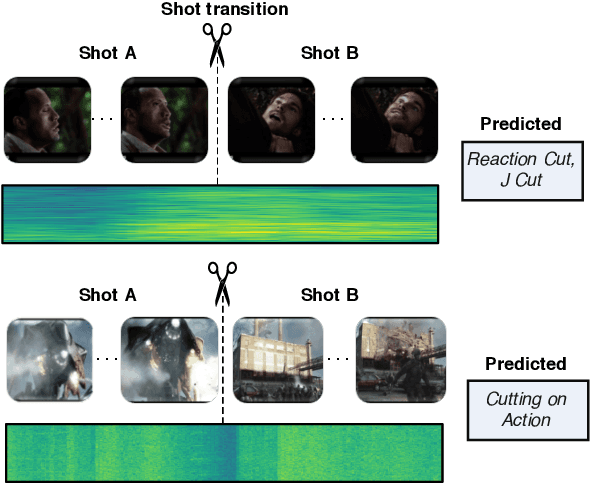
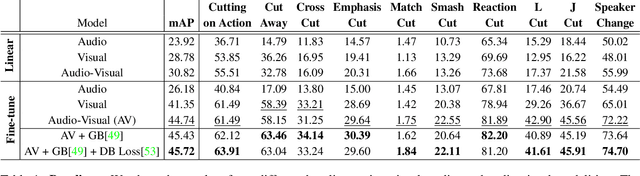
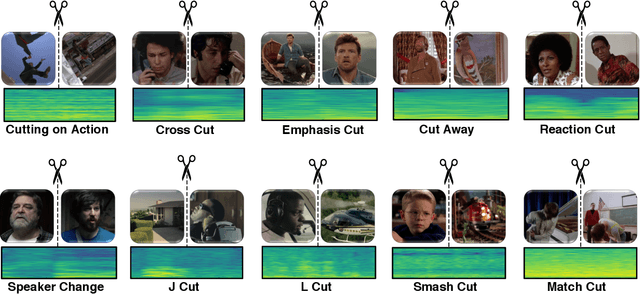
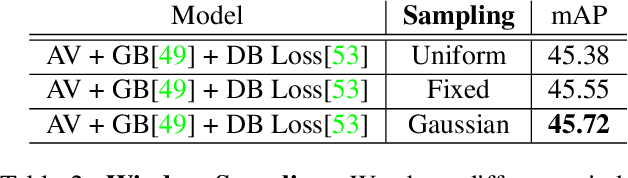
Understanding movies and their structural patterns is a crucial task to decode the craft of video editing. While previous works have developed tools for general analysis such as detecting characters or recognizing cinematography properties at the shot level, less effort has been devoted to understanding the most basic video edit, the Cut. This paper introduces the cut type recognition task, which requires modeling of multi-modal information. To ignite research in the new task, we construct a large-scale dataset called MovieCuts, which contains more than 170K videoclips labeled among ten cut types. We benchmark a series of audio-visual approaches, including some that deal with the problem's multi-modal and multi-label nature. Our best model achieves 45.7% mAP, which suggests that the task is challenging and that attaining highly accurate cut type recognition is an open research problem.
Accuracy analysis of Educational Data Mining using Feature Selection Algorithm
Jul 21, 2021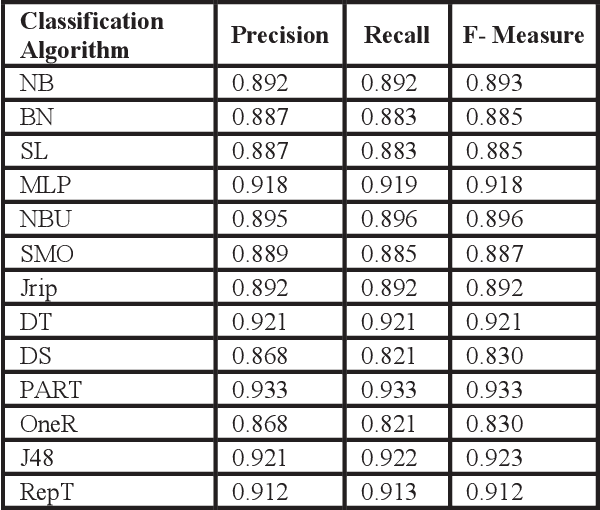
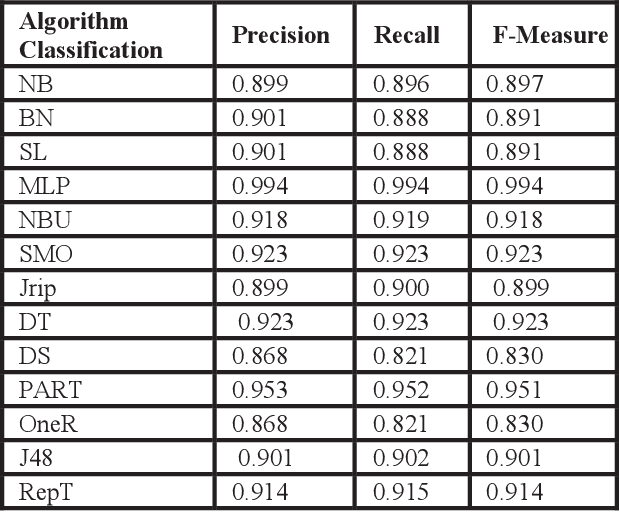
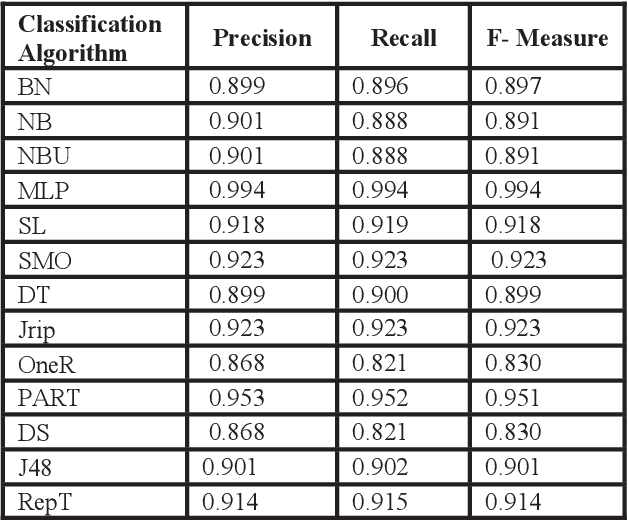
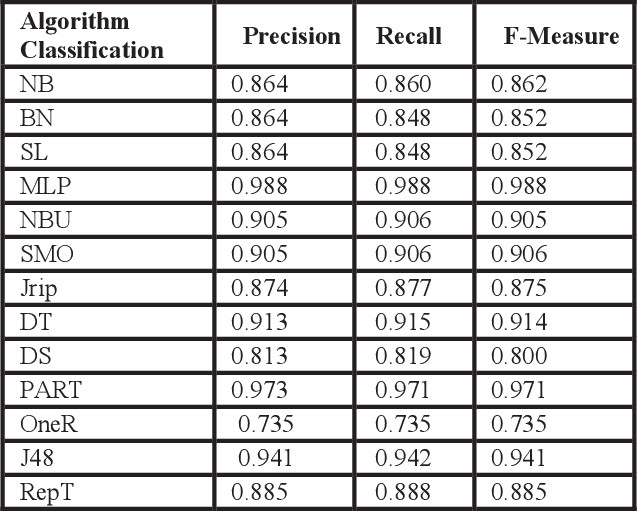
Abstract - Gathering relevant information to predict student academic progress is a tedious task. Due to the large amount of irrelevant data present in databases which provides inaccurate results. Currently, it is not possible to accurately measure and analyze student data because there are too many irrelevant attributes and features in the data. With the help of Educational Data Mining (EDM), the quality of information can be improved. This research demonstrates how EDM helps to measure the accuracy of data using relevant attributes and machine learning algorithms performed. With EDM, irrelevant features are removed without changing the original data. The data set used in this study was taken from Kaggle.com. The results compared on the basis of recall, precision and f-measure to check the accuracy of the student data. The importance of this research is to help improve the quality of educational research by providing more accurate results for researchers.
MMGET: A Markov model for generalized evidence theory
May 12, 2021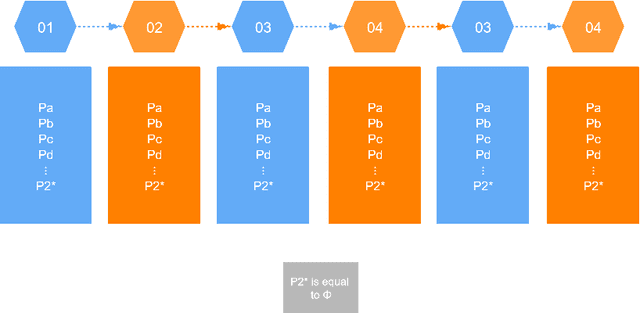
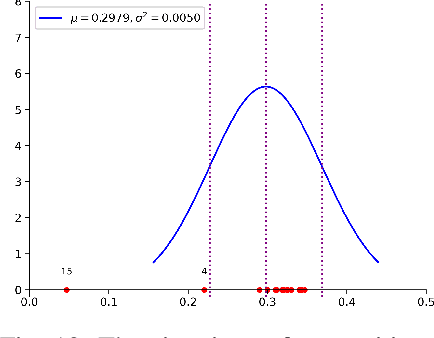
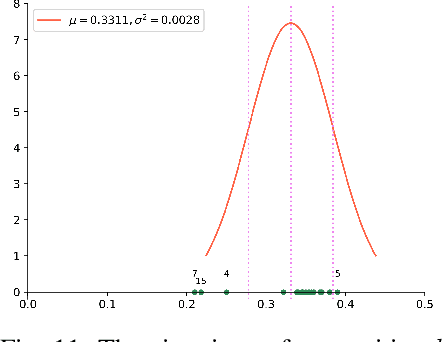
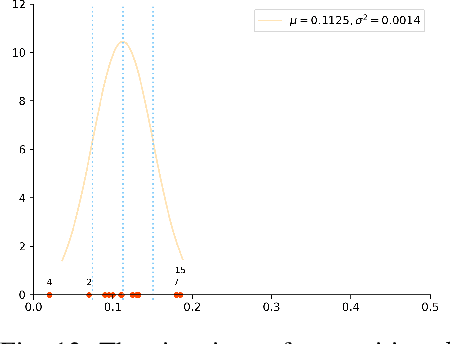
In real life, lots of information merges from time to time. To appropriately describe the actual situations, lots of theories have been proposed. Among them, Dempster-Shafer evidence theory is a very useful tool in managing uncertain information. To better adapt to complex situations of open world, a generalized evidence theory is designed. However, everything occurs in sequence and owns some underlying relationships with each other. In order to further embody the details of information and better conforms to situations of real world, a Markov model is introduced into the generalized evidence theory which helps extract complete information volume from evidence provided. Besides, some numerical examples is offered to verify the correctness and rationality of the proposed method.
SAIL-VOS 3D: A Synthetic Dataset and Baselines for Object Detection and 3D Mesh Reconstruction from Video Data
May 18, 2021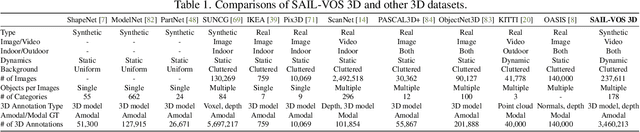
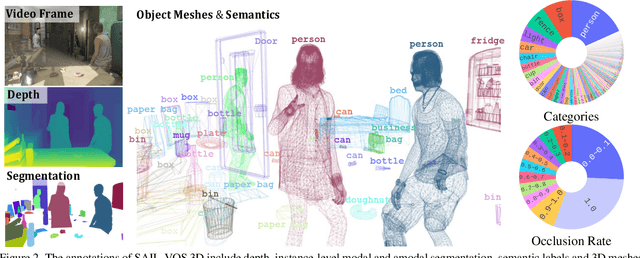

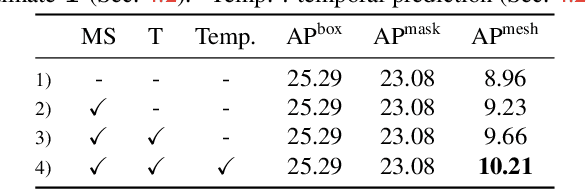
Extracting detailed 3D information of objects from video data is an important goal for holistic scene understanding. While recent methods have shown impressive results when reconstructing meshes of objects from a single image, results often remain ambiguous as part of the object is unobserved. Moreover, existing image-based datasets for mesh reconstruction don't permit to study models which integrate temporal information. To alleviate both concerns we present SAIL-VOS 3D: a synthetic video dataset with frame-by-frame mesh annotations which extends SAIL-VOS. We also develop first baselines for reconstruction of 3D meshes from video data via temporal models. We demonstrate efficacy of the proposed baseline on SAIL-VOS 3D and Pix3D, showing that temporal information improves reconstruction quality. Resources and additional information are available at http://sailvos.web.illinois.edu.
Session-based Recommendation with Heterogeneous Graph Neural Network
Aug 12, 2021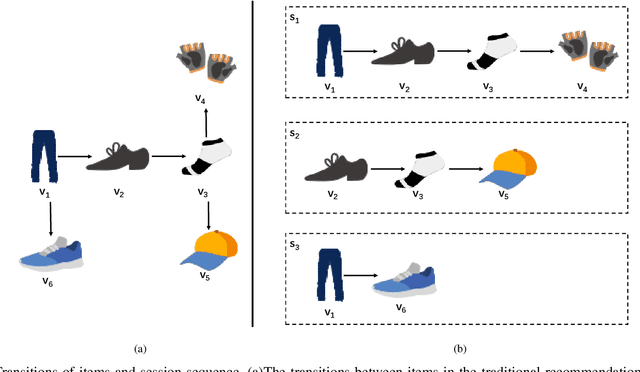
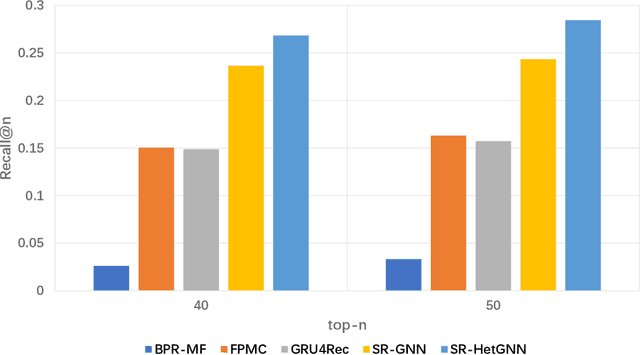
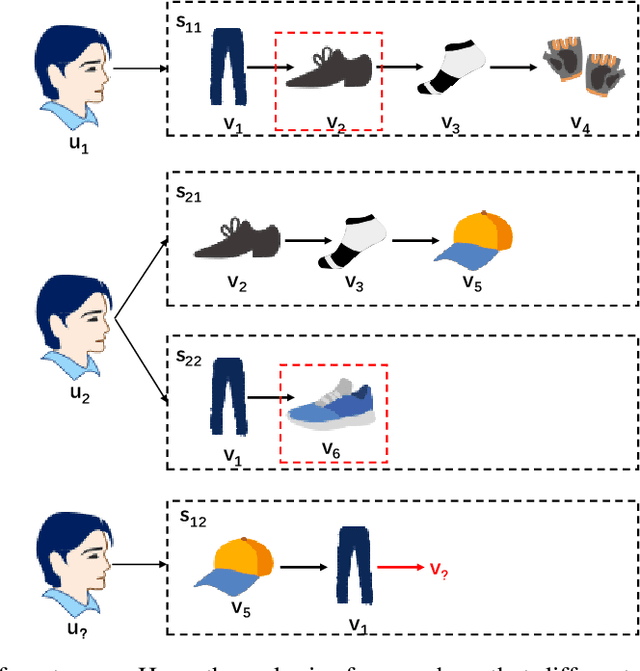
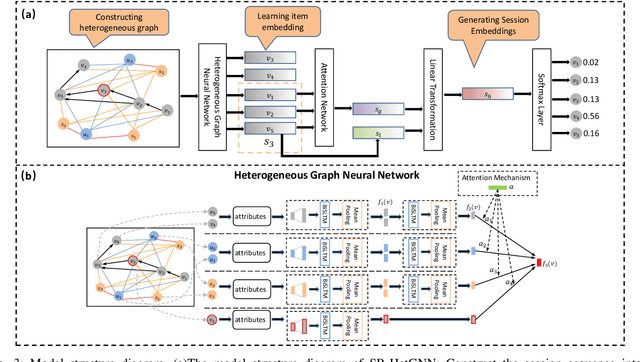
The purpose of the Session-Based Recommendation System is to predict the user's next click according to the previous session sequence. The current studies generally learn user preferences according to the transitions of items in the user's session sequence. However, other effective information in the session sequence, such as user profiles, are largely ignored which may lead to the model unable to learn the user's specific preferences. In this paper, we propose a heterogeneous graph neural network-based session recommendation method, named SR-HetGNN, which can learn session embeddings by heterogeneous graph neural network (HetGNN), and capture the specific preferences of anonymous users. Specifically, SR-HetGNN first constructs heterogeneous graphs containing various types of nodes according to the session sequence, which can capture the dependencies among items, users, and sessions. Second, HetGNN captures the complex transitions between items and learns the item embeddings containing user information. Finally, to consider the influence of users' long and short-term preferences, local and global session embeddings are combined with the attentional network to obtain the final session embedding. SR-HetGNN is shown to be superior to the existing state-of-the-art session-based recommendation methods through extensive experiments over two real large datasets Diginetica and Tmall.