 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Integrated System for Mobile Image-Based Dietary Assessment
Oct 05, 2021
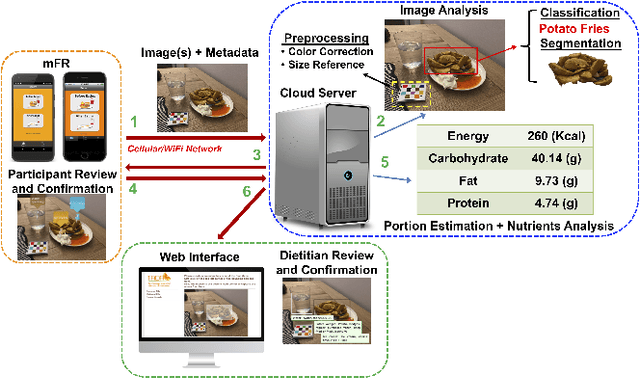
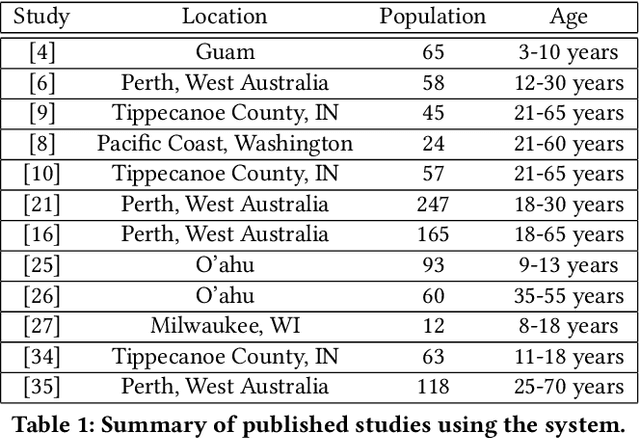
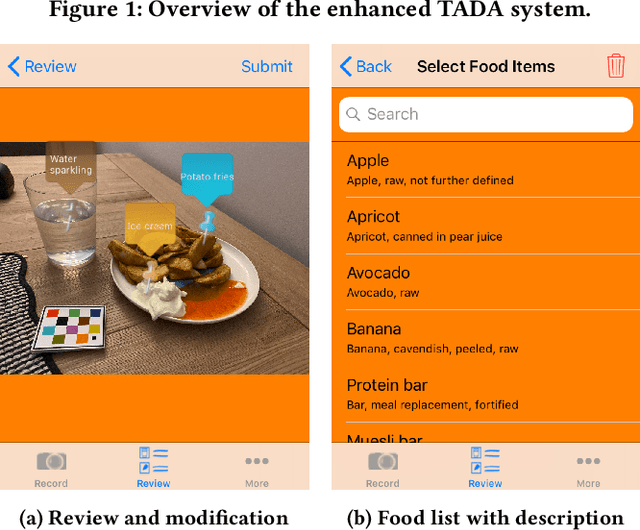

Accurate assessment of dietary intake requires improved tools to overcome limitations of current methods including user burden and measurement error. Emerging technologies such as image-based approaches using advanced machine learning techniques coupled with widely available mobile devices present new opportunities to improve the accuracy of dietary assessment that is cost-effective, convenient and timely. However, the quality and quantity of datasets are essential for achieving good performance for automated image analysis. Building a large image dataset with high quality groundtruth annotation is a challenging problem, especially for food images as the associated nutrition information needs to be provided or verified by trained dietitians with domain knowledge. In this paper, we present the design and development of a mobile, image-based dietary assessment system to capture and analyze dietary intake, which has been deployed in both controlled-feeding and community-dwelling dietary studies. Our system is capable of collecting high quality food images in naturalistic settings and provides groundtruth annotations for developing new computational approaches.
Neural Distributed Source Coding
Jun 05, 2021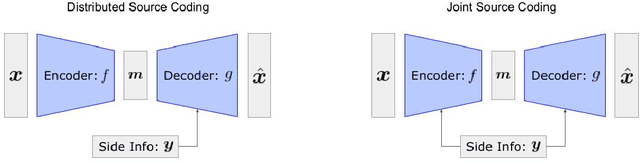
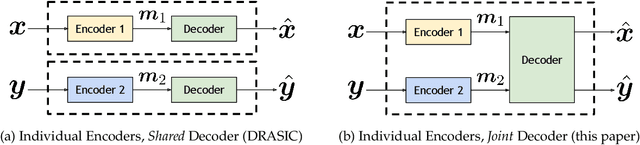


Distributed source coding is the task of encoding an input in the absence of correlated side information that is only available to the decoder. Remarkably, Slepian and Wolf showed in 1973 that an encoder that has no access to the correlated side information can asymptotically achieve the same compression rate as when the side information is available at both the encoder and the decoder. While there is significant prior work on this topic in information theory, practical distributed source coding has been limited to synthetic datasets and specific correlation structures. Here we present a general framework for lossy distributed source coding that is agnostic to the correlation structure and can scale to high dimensions. Rather than relying on hand-crafted source-modeling, our method utilizes a powerful conditional deep generative model to learn the distributed encoder and decoder. We evaluate our method on realistic high-dimensional datasets and show substantial improvements in distributed compression performance.
Machine Learning for Mediation in Armed Conflicts
Aug 26, 2021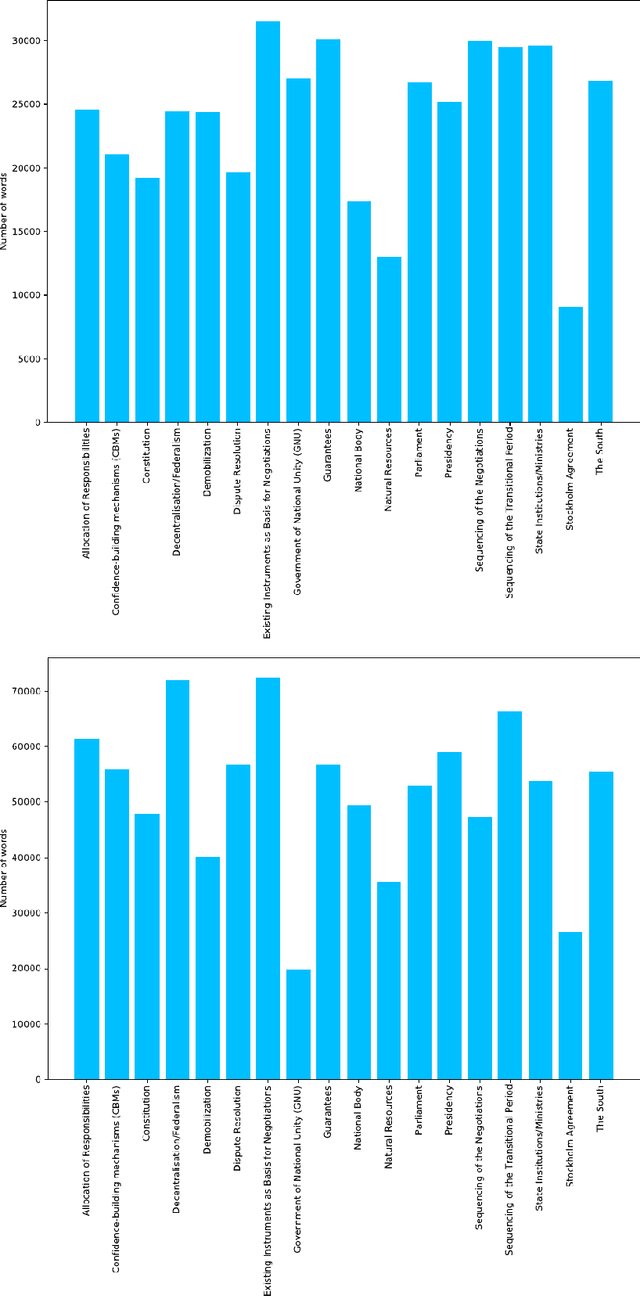
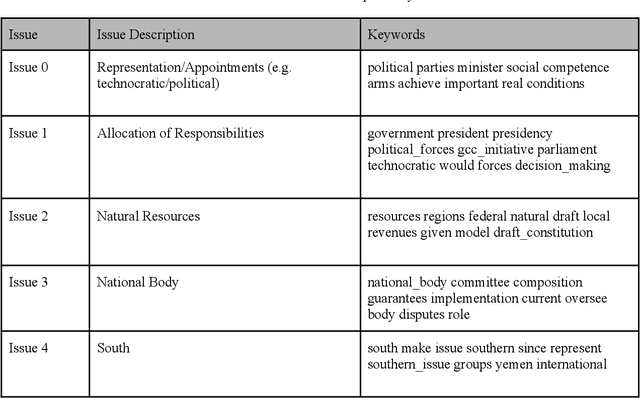
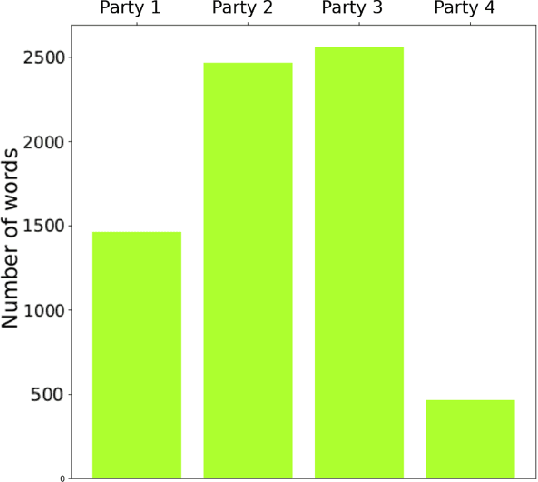
Today's conflicts are becoming increasingly complex, fluid and fragmented, often involving a host of national and international actors with multiple and often divergent interests. This development poses significant challenges for conflict mediation, as mediators struggle to make sense of conflict dynamics, such as the range of conflict parties and the evolution of their political positions, the distinction between relevant and less relevant actors in peace making, or the identification of key conflict issues and their interdependence. International peace efforts appear increasingly ill-equipped to successfully address these challenges. While technology is being increasingly used in a range of conflict related fields, such as conflict predicting or information gathering, less attention has been given to how technology can contribute to conflict mediation. This case study is the first to apply state-of-the-art machine learning technologies to data from an ongoing mediation process. Using dialogue transcripts from peace negotiations in Yemen, this study shows how machine-learning tools can effectively support international mediators by managing knowledge and offering additional conflict analysis tools to assess complex information. Apart from illustrating the potential of machine learning tools in conflict mediation, the paper also emphasises the importance of interdisciplinary and participatory research design for the development of context-sensitive and targeted tools and to ensure meaningful and responsible implementation.
Co-designing Intelligent Control of Building HVACs and Microgrids
Jul 18, 2021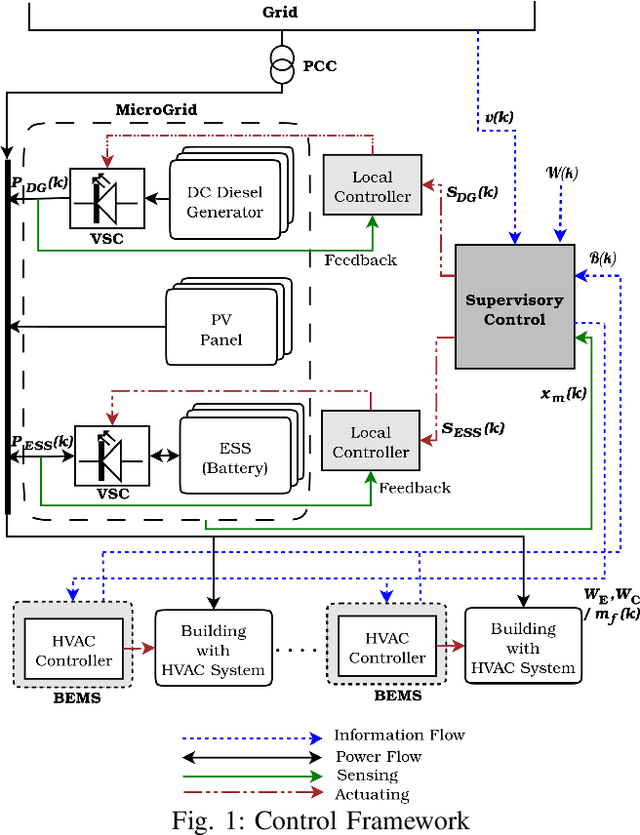
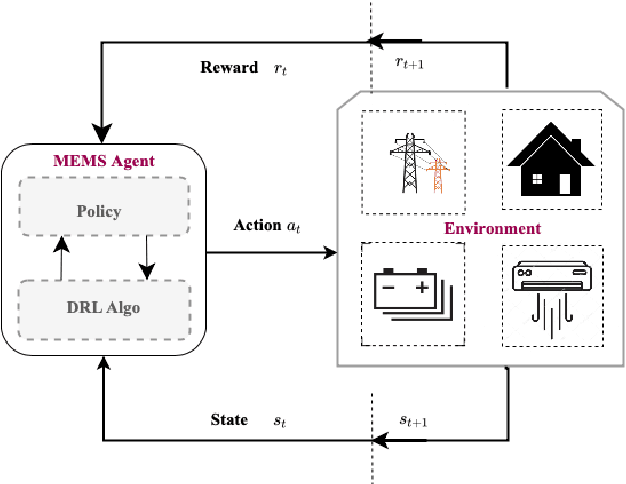
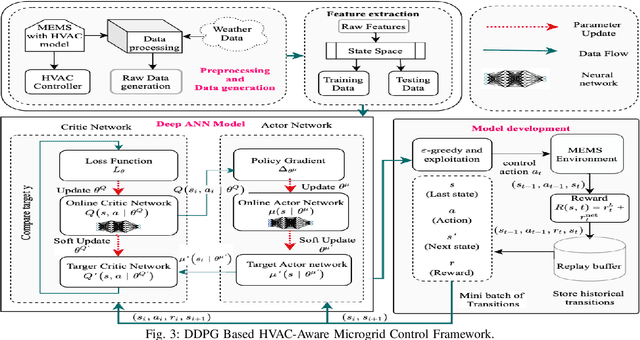
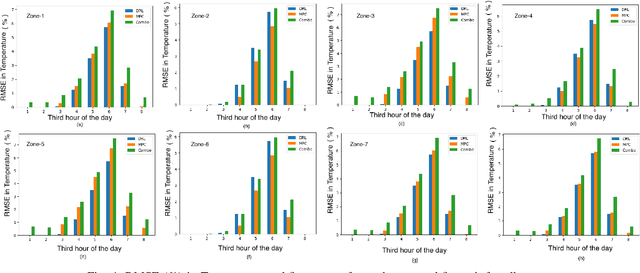
Building loads consume roughly 40% of the energy produced in developed countries, a significant part of which is invested towards building temperature-control infrastructure. Therein, renewable resource-based microgrids offer a greener and cheaper alternative. This communication explores the possible co-design of microgrid power dispatch and building HVAC (heating, ventilation and air conditioning system) actuations with the objective of effective temperature control under minimised operating cost. For this, we attempt control designs with various levels of abstractions based on information available about microgrid and HVAC system models using the Deep Reinforcement Learning (DRL) technique. We provide control architectures that consider model information ranging from completely determined system models to systems with fully unknown parameter settings and illustrate the advantages of DRL for the design prescriptions.
DFCANet: Dense Feature Calibration-Attention Guided Network for Cross Domain Iris Presentation Attack Detection
Nov 01, 2021
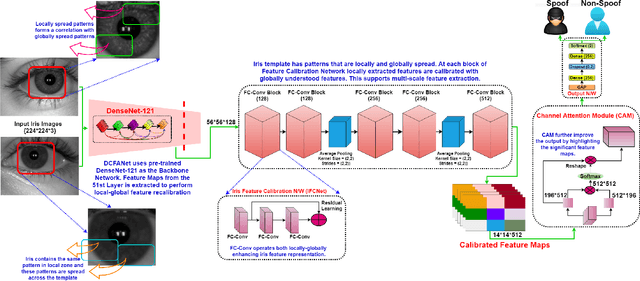
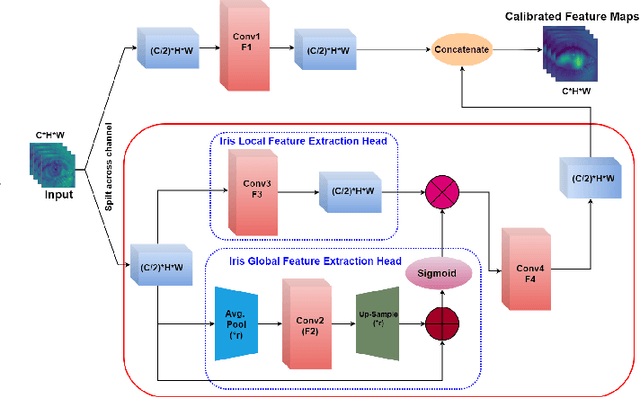
An iris presentation attack detection (IPAD) is essential for securing personal identity is widely used iris recognition systems. However, the existing IPAD algorithms do not generalize well to unseen and cross-domain scenarios because of capture in unconstrained environments and high visual correlation amongst bonafide and attack samples. These similarities in intricate textural and morphological patterns of iris ocular images contribute further to performance degradation. To alleviate these shortcomings, this paper proposes DFCANet: Dense Feature Calibration and Attention Guided Network which calibrates the locally spread iris patterns with the globally located ones. Uplifting advantages from feature calibration convolution and residual learning, DFCANet generates domain-specific iris feature representations. Since some channels in the calibrated feature maps contain more prominent information, we capitalize discriminative feature learning across the channels through the channel attention mechanism. In order to intensify the challenge for our proposed model, we make DFCANet operate over nonsegmented and non-normalized ocular iris images. Extensive experimentation conducted over challenging cross-domain and intra-domain scenarios highlights consistent outperforming results. Compared to state-of-the-art methods, DFCANet achieves significant gains in performance for the benchmark IIITD CLI, IIIT CSD and NDCLD13 databases respectively. Further, a novel incremental learning-based methodology has been introduced so as to overcome disentangled iris-data characteristics and data scarcity. This paper also pursues the challenging scenario that considers soft-lens under the attack category with evaluation performed under various cross-domain protocols. The code will be made publicly available.
Compressive Sensing Based Adaptive Defence Against Adversarial Images
Oct 11, 2021
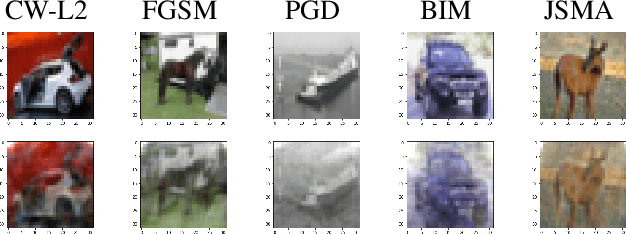
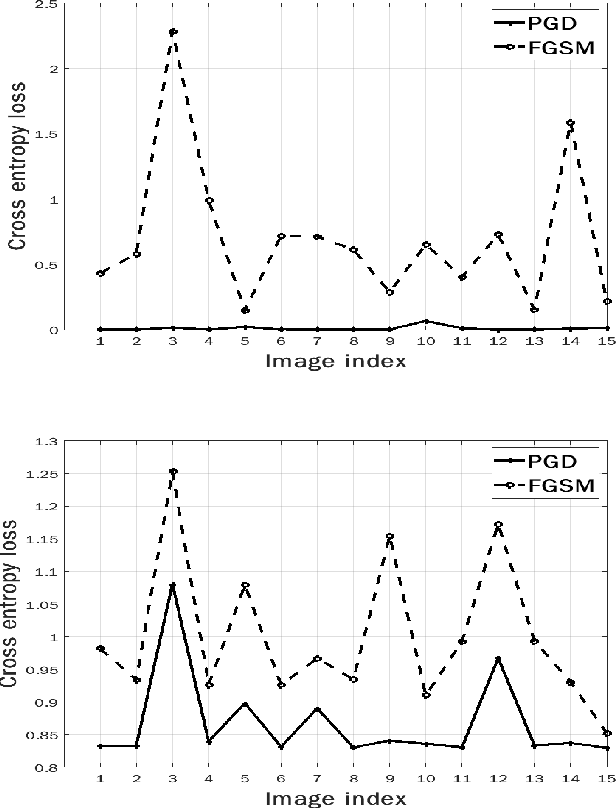
Herein, security of deep neural network against adversarial attack is considered. Existing compressive sensing based defence schemes assume that adversarial perturbations are usually on high frequency components, whereas recently it has been shown that low frequency perturbations are more effective. This paper proposes a novel Compressive sensing based Adaptive Defence (CAD) algorithm which combats distortion in frequency domain instead of time domain. Unlike existing literature, the proposed CAD algorithm does not use information about the type of attack such as l0, l2, l-infinity etc. CAD algorithm uses exponential weight algorithm for exploration and exploitation to identify the type of attack, compressive sampling matching pursuit (CoSaMP) to recover the coefficients in spectral domain, and modified basis pursuit using a novel constraint for l0, l-infinity norm attack. Tight performance bounds for various recovery schemes meant for various attack types are also provided. Experimental results against five state-of-the-art white box attacks on MNIST and CIFAR-10 show that the proposed CAD algorithm achieves excellent classification accuracy and generates good quality reconstructed image with much lower computation
Soft Attention: Does it Actually Help to Learn Social Interactions in Pedestrian Trajectory Prediction?
Jun 16, 2021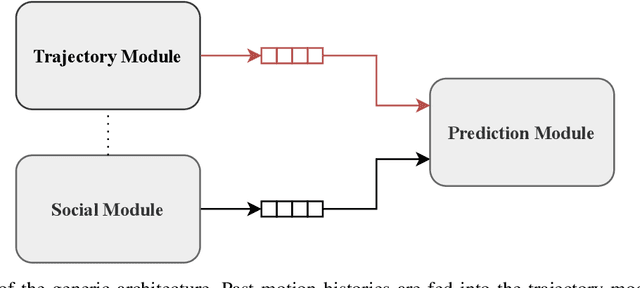
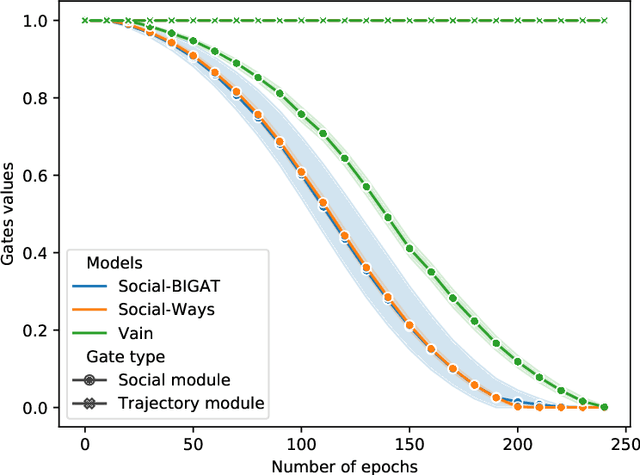
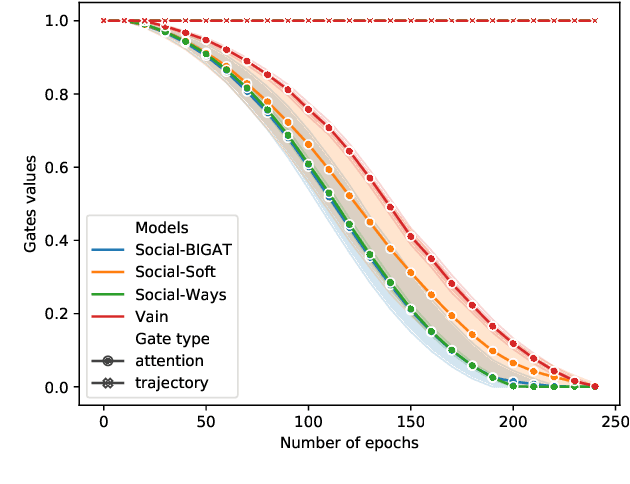
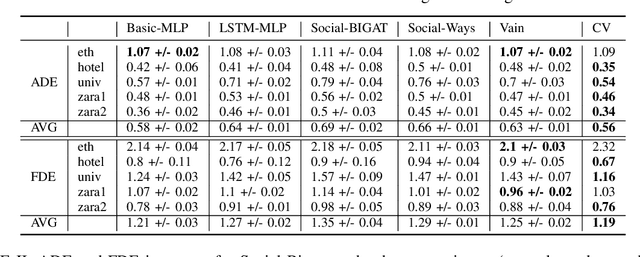
We consider the problem of predicting the future path of a pedestrian using its motion history and the motion history of the surrounding pedestrians, called social information. Since the seminal paper on Social-LSTM, deep-learning has become the main tool used to model the impact of social interactions on a pedestrian's motion. The demonstration that these models can learn social interactions relies on an ablative study of these models. The models are compared with and without their social interactions module on two standard metrics, the Average Displacement Error and Final Displacement Error. Yet, these complex models were recently outperformed by a simple constant-velocity approach. This questions if they actually allow to model social interactions as well as the validity of the proof. In this paper, we focus on the deep-learning models with a soft-attention mechanism for social interaction modeling and study whether they use social information at prediction time. We conduct two experiments across four state-of-the-art approaches on the ETH and UCY datasets, which were also used in previous work. First, the models are trained by replacing the social information with random noise and compared to model trained with actual social information. Second, we use a gating mechanism along with a $L_0$ penalty, allowing models to shut down their inner components. The models consistently learn to prune their soft-attention mechanism. For both experiments, neither the course of the convergence nor the prediction performance were altered. This demonstrates that the soft-attention mechanism and therefore the social information are ignored by the models.
Template-Based Graph Clustering
Jul 05, 2021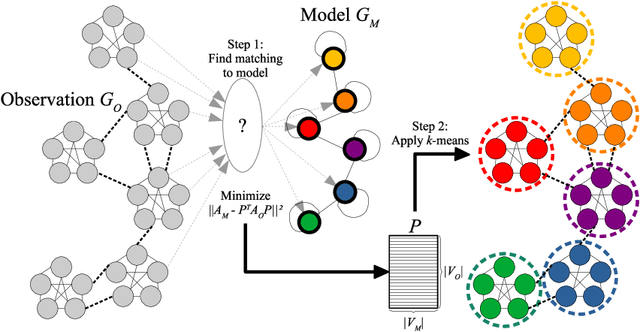
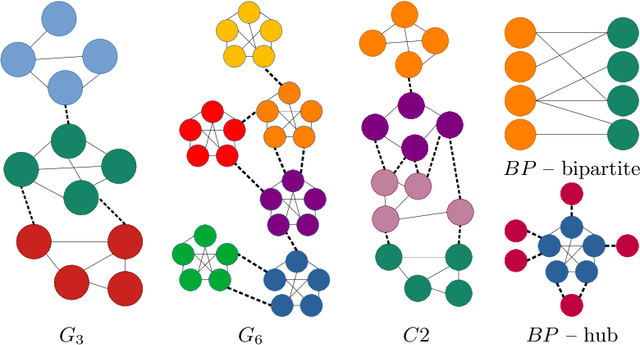
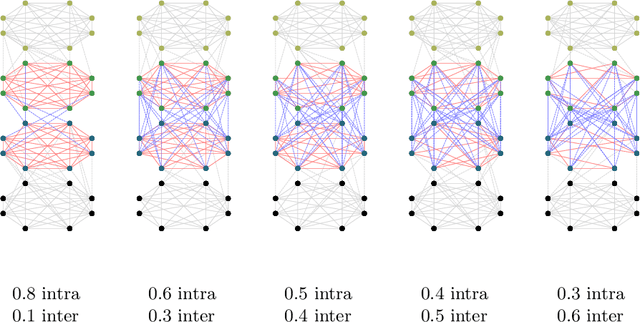
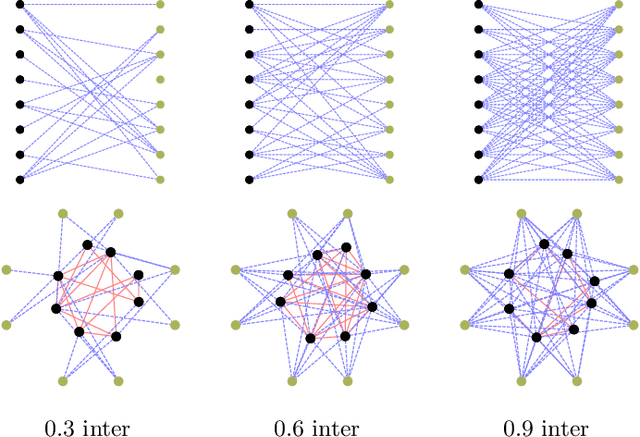
We propose a novel graph clustering method guided by additional information on the underlying structure of the clusters (or communities). The problem is formulated as the matching of a graph to a template with smaller dimension, hence matching $n$ vertices of the observed graph (to be clustered) to the $k$ vertices of a template graph, using its edges as support information, and relaxed on the set of orthonormal matrices in order to find a $k$ dimensional embedding. With relevant priors that encode the density of the clusters and their relationships, our method outperforms classical methods, especially for challenging cases.
* ECML-PKDD, Workshop on Graph Embedding and Minin (GEM) 2020
Video Object Segmentation Without Temporal Information
May 16, 2018
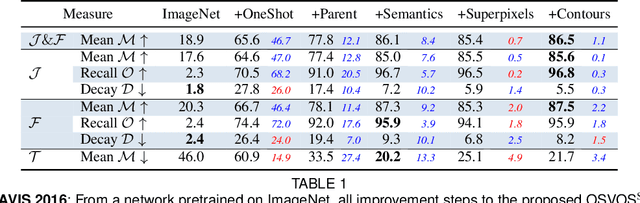
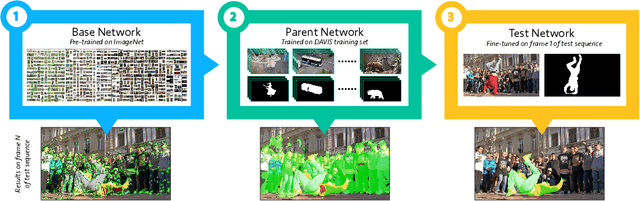
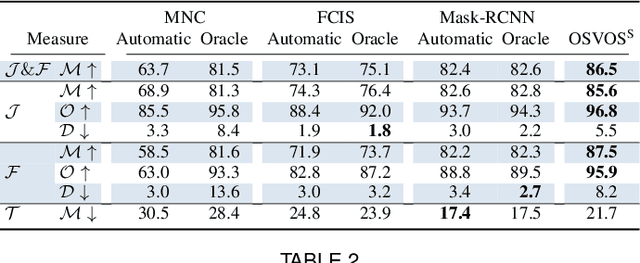
Video Object Segmentation, and video processing in general, has been historically dominated by methods that rely on the temporal consistency and redundancy in consecutive video frames. When the temporal smoothness is suddenly broken, such as when an object is occluded, or some frames are missing in a sequence, the result of these methods can deteriorate significantly or they may not even produce any result at all. This paper explores the orthogonal approach of processing each frame independently, i.e disregarding the temporal information. In particular, it tackles the task of semi-supervised video object segmentation: the separation of an object from the background in a video, given its mask in the first frame. We present Semantic One-Shot Video Object Segmentation (OSVOS-S), based on a fully-convolutional neural network architecture that is able to successively transfer generic semantic information, learned on ImageNet, to the task of foreground segmentation, and finally to learning the appearance of a single annotated object of the test sequence (hence one shot). We show that instance level semantic information, when combined effectively, can dramatically improve the results of our previous method, OSVOS. We perform experiments on two recent video segmentation databases, which show that OSVOS-S is both the fastest and most accurate method in the state of the art.
A Computable Piece of Uncomputable Art whose Expansion May Explain the Universe in Software Space
Sep 15, 2021



At the intersection of what I call uncomputable art and computational epistemology, a form of experimental philosophy, we find an exciting and promising area of science related to causation with an alternative, possibly best possible, solution to the challenge of the inverse problem. That is the problem of finding the possible causes, mechanistic origins, first principles, and generative models of a piece of data from a physical phenomenon. Here we explain how generating and exploring software space following the framework of Algorithmic Information Dynamics, it is possible to find small models and learn to navigate a sci-fi-looking space that can advance the field of scientific discovery with complementary tools to offer an opportunity to advance science itself.