 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Task Difficulty for Few-Shot Relation Extraction
Sep 28, 2021

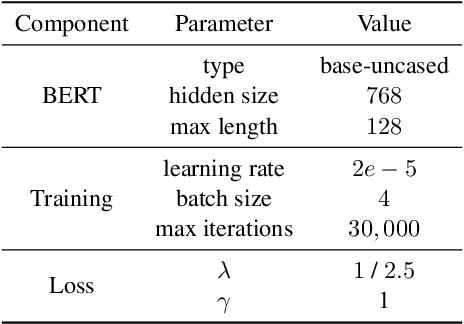
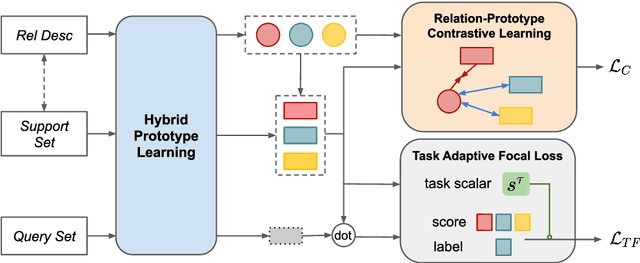
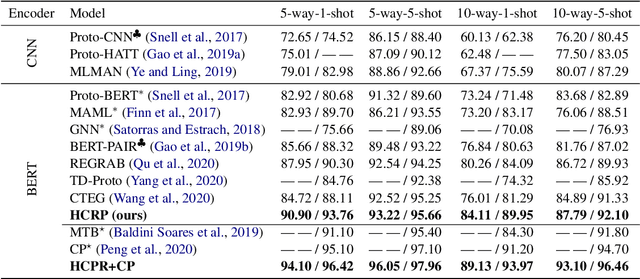
Few-shot relation extraction (FSRE) focuses on recognizing novel relations by learning with merely a handful of annotated instances. Meta-learning has been widely adopted for such a task, which trains on randomly generated few-shot tasks to learn generic data representations. Despite impressive results achieved, existing models still perform suboptimally when handling hard FSRE tasks, where the relations are fine-grained and similar to each other. We argue this is largely because existing models do not distinguish hard tasks from easy ones in the learning process. In this paper, we introduce a novel approach based on contrastive learning that learns better representations by exploiting relation label information. We further design a method that allows the model to adaptively learn how to focus on hard tasks. Experiments on two standard datasets demonstrate the effectiveness of our method.
Using Psychological Characteristics of Situations for Social Situation Comprehension in Support Agents
Oct 23, 2021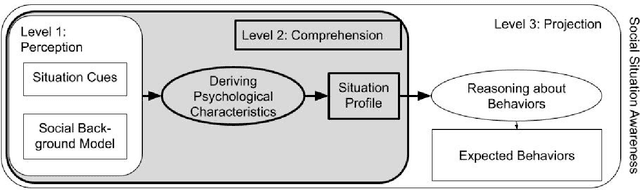
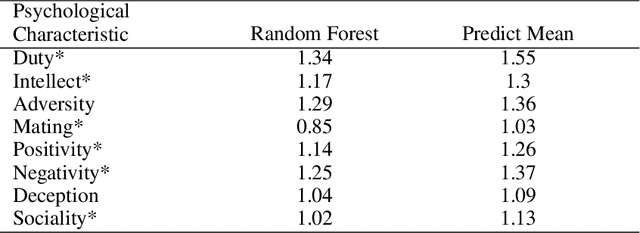
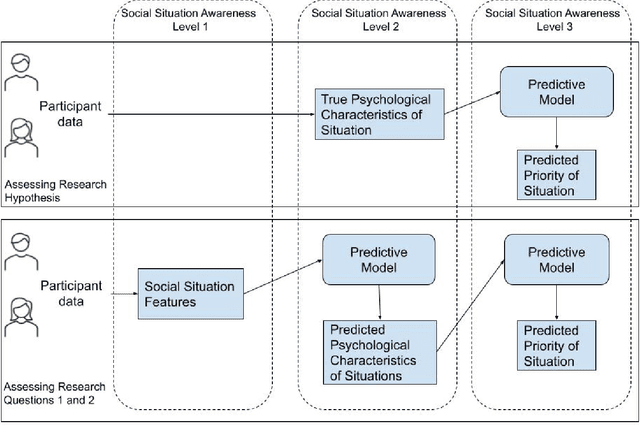

Support agents that help users in their daily lives need to take into account not only the user's characteristics, but also the social situation of the user. Existing work on including social context uses some type of situation cue as an input to information processing techniques in order to assess the expected behavior of the user. However, research shows that it is important to also determine the meaning of a situation, a step which we refer to as social situation comprehension. We propose using psychological characteristics of situations, which have been proposed in social science for ascribing meaning to situations, as the basis for social situation comprehension. Using data from user studies, we evaluate this proposal from two perspectives. First, from a technical perspective, we show that psychological characteristics of situations can be used as input to predict the priority of social situations, and that psychological characteristics of situations can be predicted from the features of a social situation. Second, we investigate the role of the comprehension step in human-machine meaning making. We show that psychological characteristics can be successfully used as a basis for explanations given to users about the decisions of an agenda management personal assistant agent.
Analyzing Bias in Sensitive Personal Information Used to Train Financial Models
Nov 09, 2019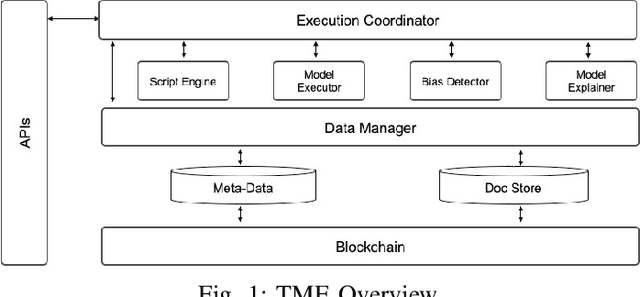
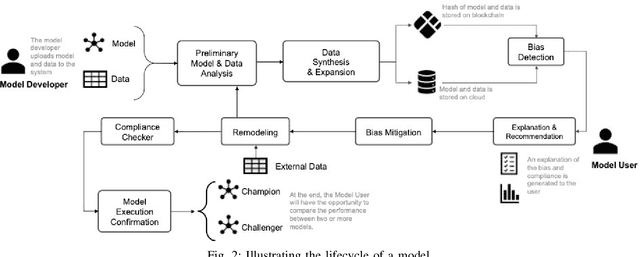
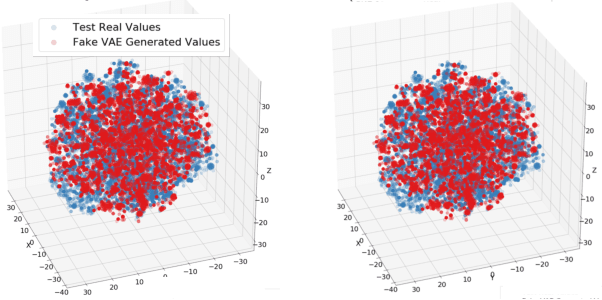
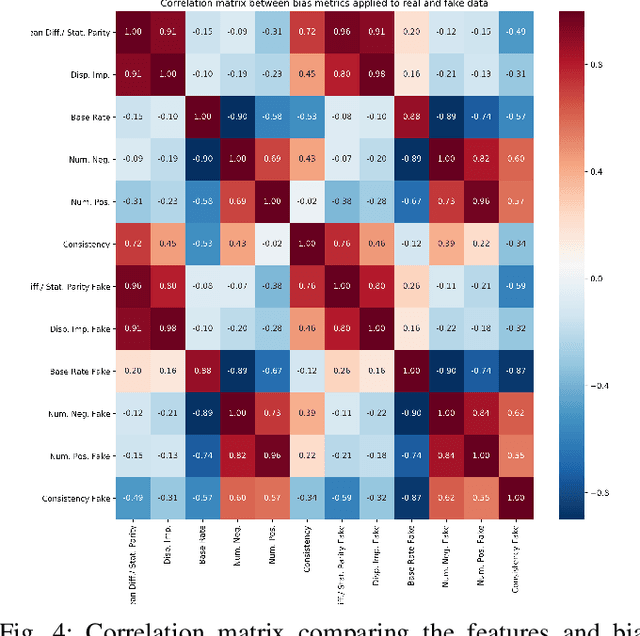
Bias in data can have unintended consequences that propagate to the design, development, and deployment of machine learning models. In the financial services sector, this can result in discrimination from certain financial instruments and services. At the same time, data privacy is of paramount importance, and recent data breaches have seen reputational damage for large institutions. Presented in this paper is a trusted model-lifecycle management platform that attempts to ensure consumer data protection, anonymization, and fairness. Specifically, we examine how datasets can be reproduced using deep learning techniques to effectively retain important statistical features in datasets whilst simultaneously protecting data privacy and enabling safe and secure sharing of sensitive personal information beyond the current state-of-practice.
Towards a Robust Differentiable Architecture Search under Label Noise
Oct 23, 2021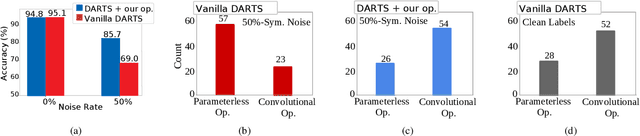
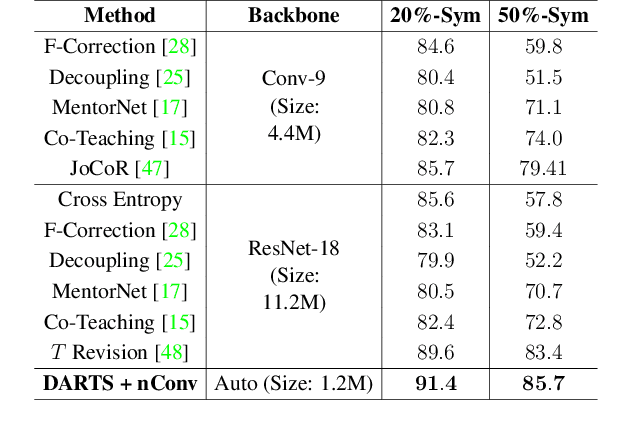

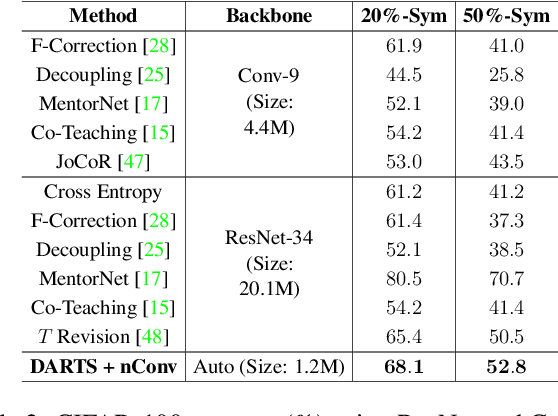
Neural Architecture Search (NAS) is the game changer in designing robust neural architectures. Architectures designed by NAS outperform or compete with the best manual network designs in terms of accuracy, size, memory footprint and FLOPs. That said, previous studies focus on developing NAS algorithms for clean high quality data, a restrictive and somewhat unrealistic assumption. In this paper, focusing on the differentiable NAS algorithms, we show that vanilla NAS algorithms suffer from a performance loss if class labels are noisy. To combat this issue, we make use of the principle of information bottleneck as a regularizer. This leads us to develop a noise injecting operation that is included during the learning process, preventing the network from learning from noisy samples. Our empirical evaluations show that the noise injecting operation does not degrade the performance of the NAS algorithm if the data is indeed clean. In contrast, if the data is noisy, the architecture learned by our algorithm comfortably outperforms algorithms specifically equipped with sophisticated mechanisms to learn in the presence of label noise. In contrast to many algorithms designed to work in the presence of noisy labels, prior knowledge about the properties of the noise and its characteristics are not required for our algorithm.
JobBERT: Understanding Job Titles through Skills
Sep 20, 2021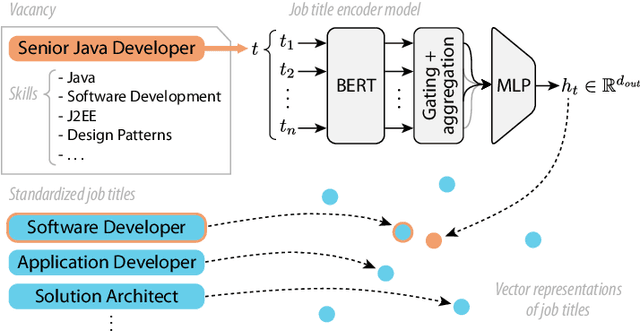
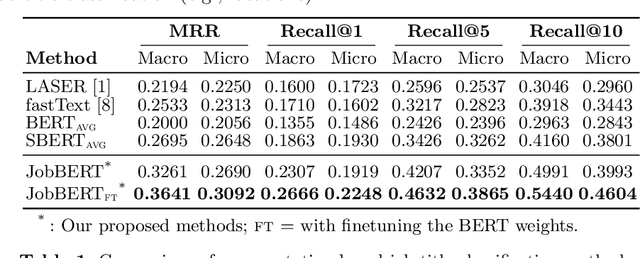
Job titles form a cornerstone of today's human resources (HR) processes. Within online recruitment, they allow candidates to understand the contents of a vacancy at a glance, while internal HR departments use them to organize and structure many of their processes. As job titles are a compact, convenient, and readily available data source, modeling them with high accuracy can greatly benefit many HR tech applications. In this paper, we propose a neural representation model for job titles, by augmenting a pre-trained language model with co-occurrence information from skill labels extracted from vacancies. Our JobBERT method leads to considerable improvements compared to using generic sentence encoders, for the task of job title normalization, for which we release a new evaluation benchmark.
Semi-Supervised Deep Learning for Multiplex Networks
Oct 05, 2021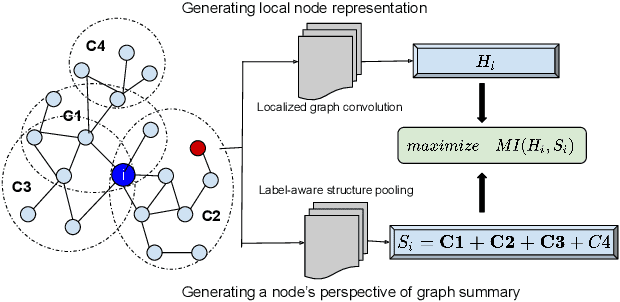
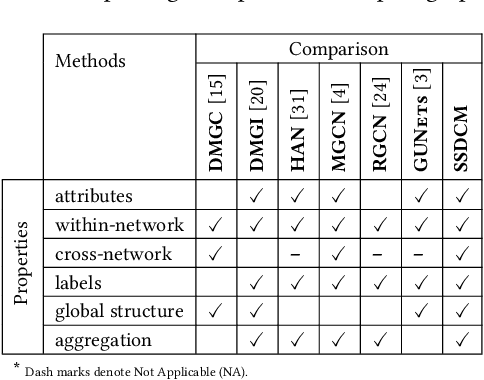
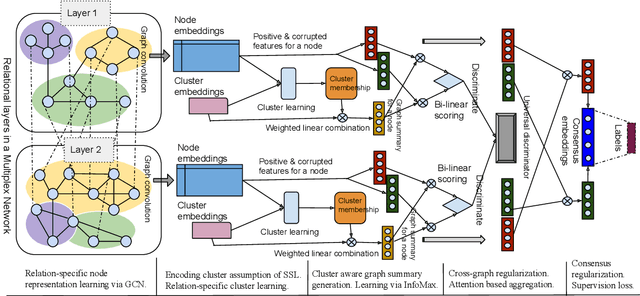
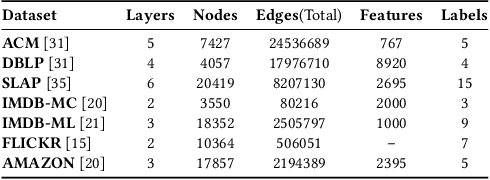
Multiplex networks are complex graph structures in which a set of entities are connected to each other via multiple types of relations, each relation representing a distinct layer. Such graphs are used to investigate many complex biological, social, and technological systems. In this work, we present a novel semi-supervised approach for structure-aware representation learning on multiplex networks. Our approach relies on maximizing the mutual information between local node-wise patch representations and label correlated structure-aware global graph representations to model the nodes and cluster structures jointly. Specifically, it leverages a novel cluster-aware, node-contextualized global graph summary generation strategy for effective joint-modeling of node and cluster representations across the layers of a multiplex network. Empirically, we demonstrate that the proposed architecture outperforms state-of-the-art methods in a range of tasks: classification, clustering, visualization, and similarity search on seven real-world multiplex networks for various experiment settings.
Graph-Based Learning for Stock Movement Prediction with Textual and Relational Data
Jul 22, 2021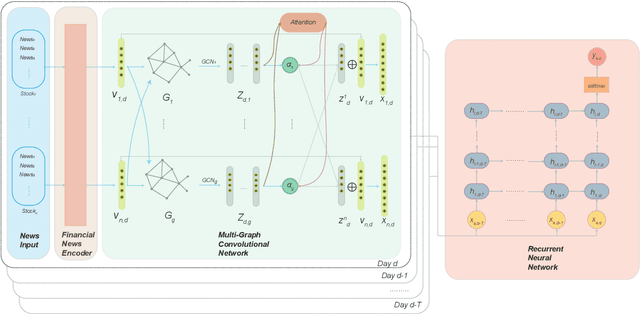
Predicting stock prices from textual information is a challenging task due to the uncertainty of the market and the difficulty understanding the natural language from a machine's perspective. Previous researches focus mostly on sentiment extraction based on single news. However, the stocks on the financial market can be highly correlated, one news regarding one stock can quickly impact the prices of other stocks. To take this effect into account, we propose a new stock movement prediction framework: Multi-Graph Recurrent Network for Stock Forecasting (MGRN). This architecture allows to combine the textual sentiment from financial news and multiple relational information extracted from other financial data. Through an accuracy test and a trading simulation on the stocks in the STOXX Europe 600 index, we demonstrate a better performance from our model than other benchmarks.
Active Visuo-Tactile Point Cloud Registration for Accurate Pose Estimation of Objects in an Unknown Workspace
Aug 09, 2021
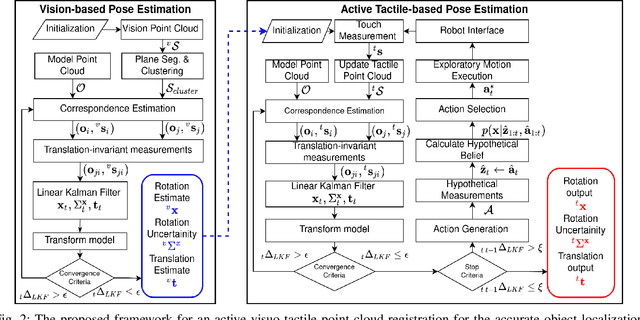
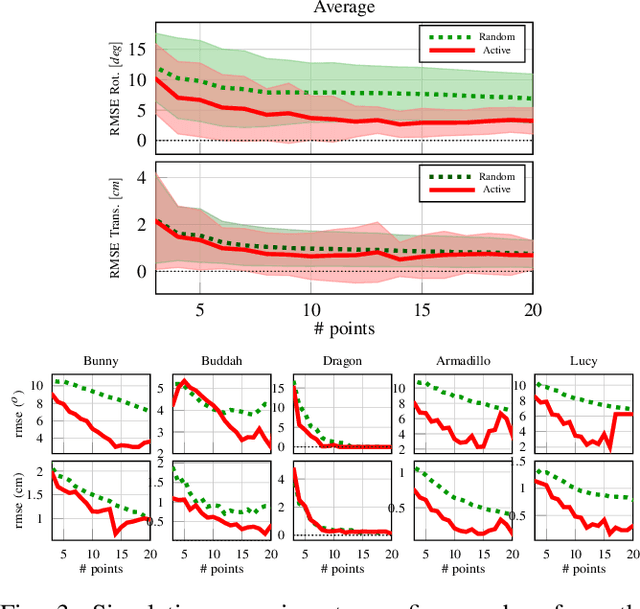
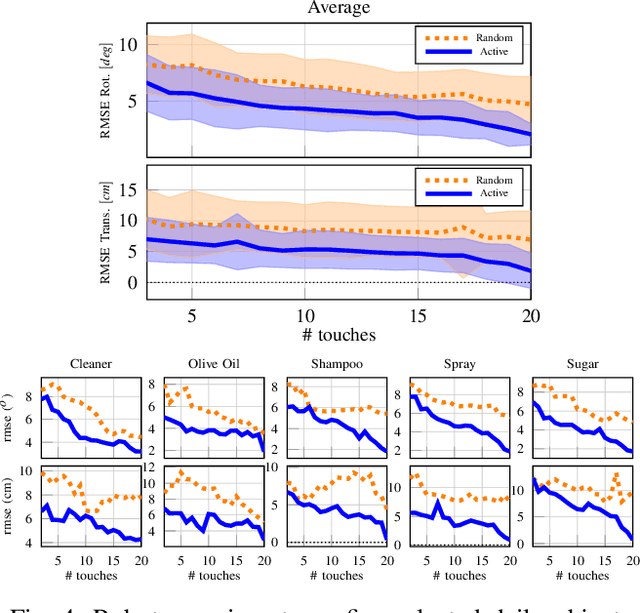
This paper proposes a novel active visuo-tactile based methodology wherein the accurate estimation of the time-invariant SE(3) pose of objects is considered for autonomous robotic manipulators. The robot equipped with tactile sensors on the gripper is guided by a vision estimate to actively explore and localize the objects in the unknown workspace. The robot is capable of reasoning over multiple potential actions, and execute the action to maximize information gain to update the current belief of the object. We formulate the pose estimation process as a linear translation invariant quaternion filter (TIQF) by decoupling the estimation of translation and rotation and formulating the update and measurement model in linear form. We perform pose estimation sequentially on acquired measurements using very sparse point cloud as acquiring each measurement using tactile sensing is time consuming. Furthermore, our proposed method is computationally efficient to perform an exhaustive uncertainty-based active touch selection strategy in real-time without the need for trading information gain with execution time. We evaluated the performance of our approach extensively in simulation and by a robotic system.
An Adaptable Approach to Learn Realistic Legged Locomotion without Examples
Oct 28, 2021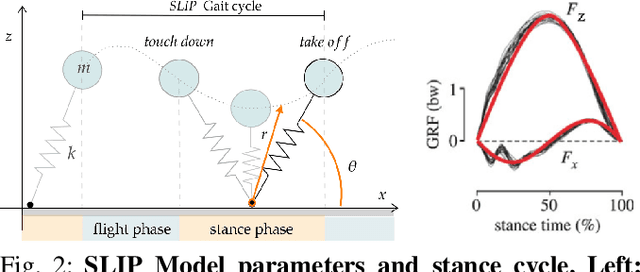
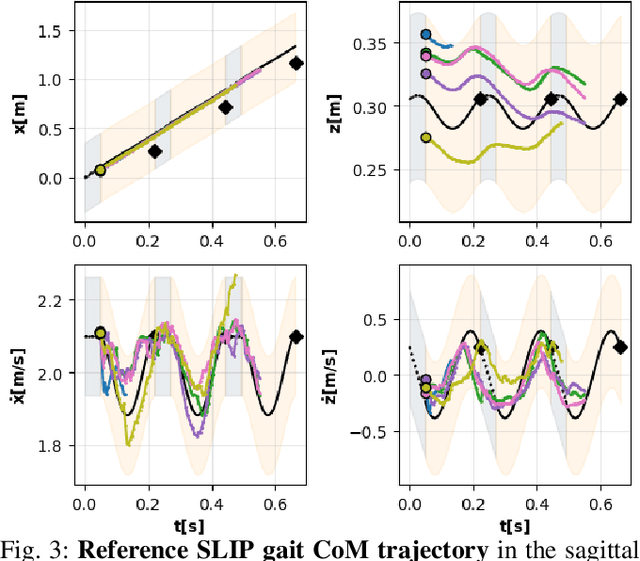
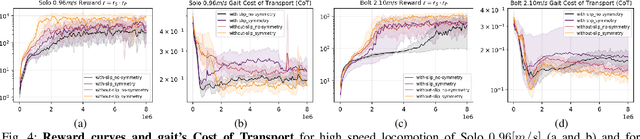
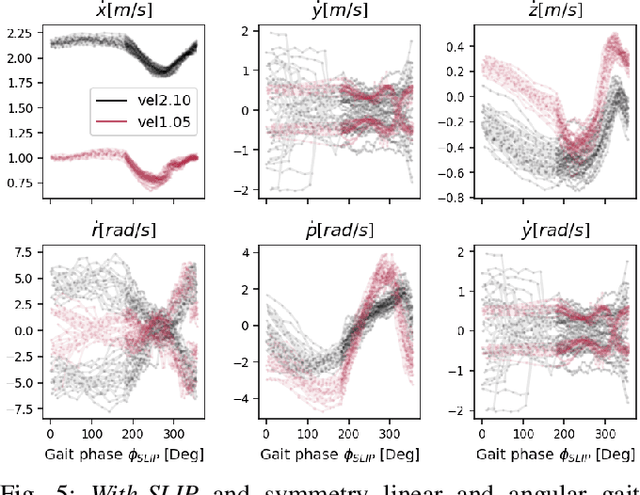
Learning controllers that reproduce legged locomotion in nature have been a long-time goal in robotics and computer graphics. While yielding promising results, recent approaches are not yet flexible enough to be applicable to legged systems of different morphologies. This is partly because they often rely on precise motion capture references or elaborate learning environments that ensure the naturality of the emergent locomotion gaits but prevent generalization. This work proposes a generic approach for ensuring realism in locomotion by guiding the learning process with the spring-loaded inverted pendulum model as a reference. Leveraging on the exploration capacities of Reinforcement Learning (RL), we learn a control policy that fills in the information gap between the template model and full-body dynamics required to maintain stable and periodic locomotion. The proposed approach can be applied to robots of different sizes and morphologies and adapted to any RL technique and control architecture. We present experimental results showing that even in a model-free setup and with a simple reactive control architecture, the learned policies can generate realistic and energy-efficient locomotion gaits for a bipedal and a quadrupedal robot. And most importantly, this is achieved without using motion capture, strong constraints in the dynamics or kinematics of the robot, nor prescribing limb coordination. We provide supplemental videos for qualitative analysis of the naturality of the learned gaits.
User-friendly introduction to PAC-Bayes bounds
Oct 28, 2021Aggregated predictors are obtained by making a set of basic predictors vote according to some weights, that is, to some probability distribution. Randomized predictors are obtained by sampling in a set of basic predictors, according to some prescribed probability distribution. Thus, aggregated and randomized predictors have in common that they are not defined by a minimization problem, but by a probability distribution on the set of predictors. In statistical learning theory, there is a set of tools designed to understand the generalization ability of such procedures: PAC-Bayesian or PAC-Bayes bounds. Since the original PAC-Bayes bounds of D. McAllester, these tools have been considerably improved in many directions (we will for example describe a simplified version of the localization technique of O. Catoni that was missed by the community, and later rediscovered as "mutual information bounds"). Very recently, PAC-Bayes bounds received a considerable attention: for example there was workshop on PAC-Bayes at NIPS 2017, "(Almost) 50 Shades of Bayesian Learning: PAC-Bayesian trends and insights", organized by B. Guedj, F. Bach and P. Germain. One of the reason of this recent success is the successful application of these bounds to neural networks by G. Dziugaite and D. Roy. An elementary introduction to PAC-Bayes theory is still missing. This is an attempt to provide such an introduction.