 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AdaLoss: A computationally-efficient and provably convergent adaptive gradient method
Sep 17, 2021


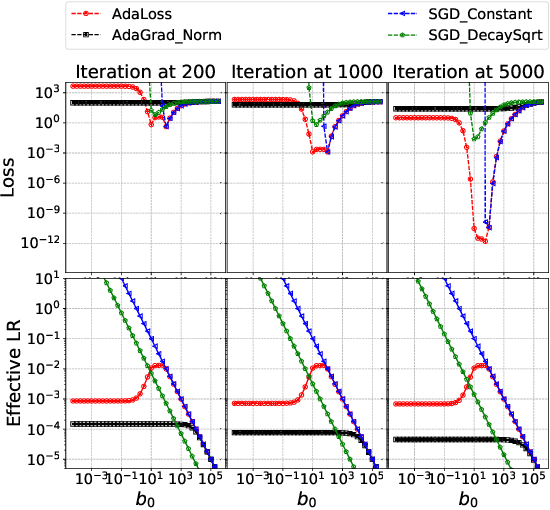
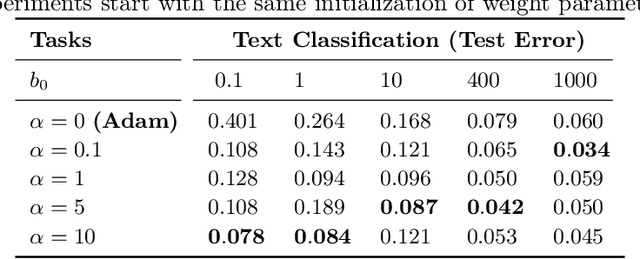
We propose a computationally-friendly adaptive learning rate schedule, "AdaLoss", which directly uses the information of the loss function to adjust the stepsize in gradient descent methods. We prove that this schedule enjoys linear convergence in linear regression. Moreover, we provide a linear convergence guarantee over the non-convex regime, in the context of two-layer over-parameterized neural networks. If the width of the first-hidden layer in the two-layer networks is sufficiently large (polynomially), then AdaLoss converges robustly \emph{to the global minimum} in polynomial time. We numerically verify the theoretical results and extend the scope of the numerical experiments by considering applications in LSTM models for text clarification and policy gradients for control problems.
Localized Graph Collaborative Filtering
Aug 10, 2021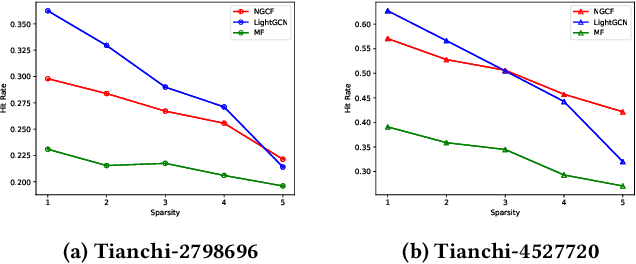
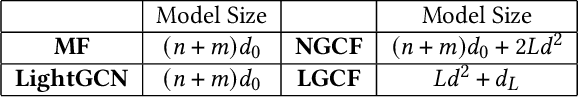
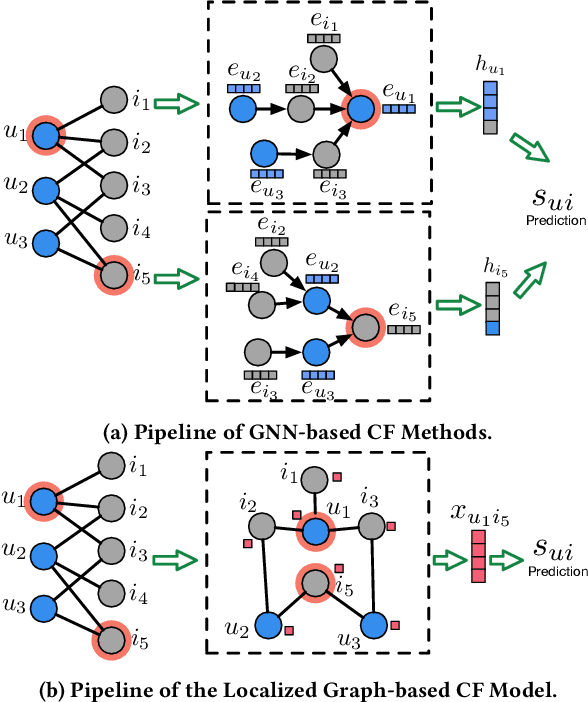
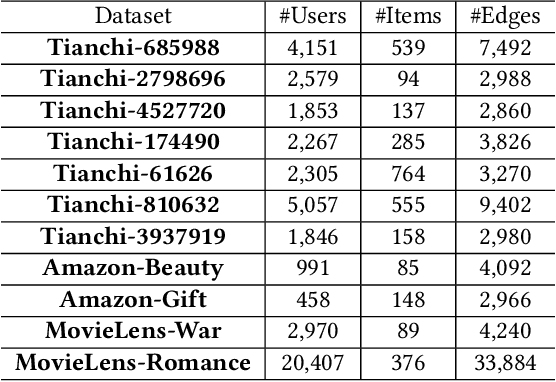
User-item interactions in recommendations can be naturally de-noted as a user-item bipartite graph. Given the success of graph neural networks (GNNs) in graph representation learning, GNN-based C methods have been proposed to advance recommender systems. These methods often make recommendations based on the learned user and item embeddings. However, we found that they do not perform well wit sparse user-item graphs which are quite common in real-world recommendations. Therefore, in this work, we introduce a novel perspective to build GNN-based CF methods for recommendations which leads to the proposed framework Localized Graph Collaborative Filtering (LGCF). One key advantage of LGCF is that it does not need to learn embeddings for each user and item, which is challenging in sparse scenarios. Alternatively, LGCF aims at encoding useful CF information into a localized graph and making recommendations based on such graph. Extensive experiments on various datasets validate the effectiveness of LGCF especially in sparse scenarios. Furthermore, empirical results demonstrate that LGCF provides complementary information to the embedding-based CF model which can be utilized to boost recommendation performance.
HARP-Net: Hyper-Autoencoded Reconstruction Propagation for Scalable Neural Audio Coding
Jul 23, 2021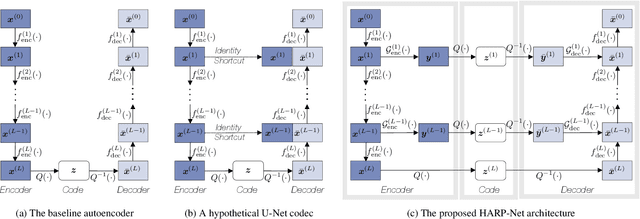
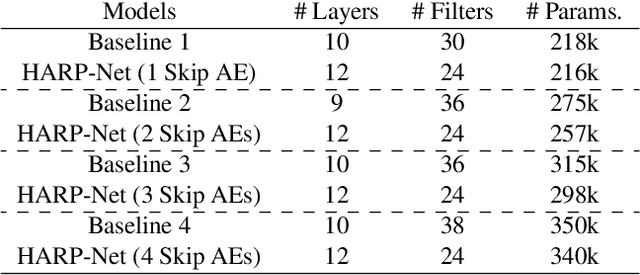
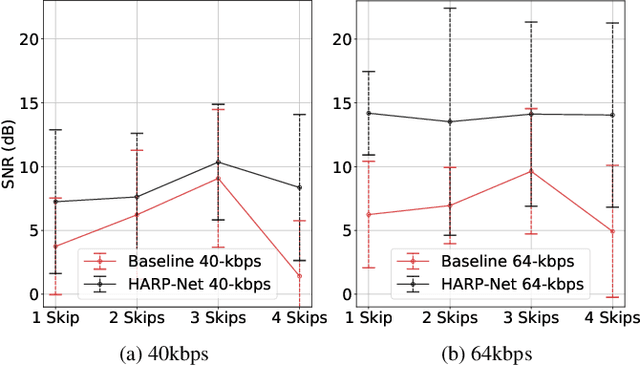
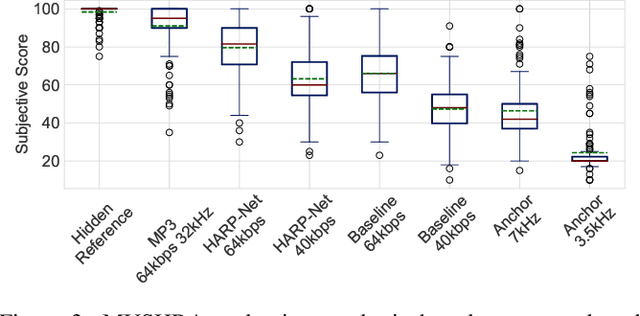
An autoencoder-based codec employs quantization to turn its bottleneck layer activation into bitstrings, a process that hinders information flow between the encoder and decoder parts. To circumvent this issue, we employ additional skip connections between the corresponding pair of encoder-decoder layers. The assumption is that, in a mirrored autoencoder topology, a decoder layer reconstructs the intermediate feature representation of its corresponding encoder layer. Hence, any additional information directly propagated from the corresponding encoder layer helps the reconstruction. We implement this kind of skip connections in the form of additional autoencoders, each of which is a small codec that compresses the massive data transfer between the paired encoder-decoder layers. We empirically verify that the proposed hyper-autoencoded architecture improves perceptual audio quality compared to an ordinary autoencoder baseline.
FacialGAN: Style Transfer and Attribute Manipulation on Synthetic Faces
Oct 18, 2021



Facial image manipulation is a generation task where the output face is shifted towards an intended target direction in terms of facial attribute and styles. Recent works have achieved great success in various editing techniques such as style transfer and attribute translation. However, current approaches are either focusing on pure style transfer, or on the translation of predefined sets of attributes with restricted interactivity. To address this issue, we propose FacialGAN, a novel framework enabling simultaneous rich style transfers and interactive facial attributes manipulation. While preserving the identity of a source image, we transfer the diverse styles of a target image to the source image. We then incorporate the geometry information of a segmentation mask to provide a fine-grained manipulation of facial attributes. Finally, a multi-objective learning strategy is introduced to optimize the loss of each specific tasks. Experiments on the CelebA-HQ dataset, with CelebAMask-HQ as semantic mask labels, show our model's capacity in producing visually compelling results in style transfer, attribute manipulation, diversity and face verification. For reproducibility, we provide an interactive open-source tool to perform facial manipulations, and the Pytorch implementation of the model.
On the Mutual Information between Source and Filter Contributions for Voice Pathology Detection
Jan 02, 2020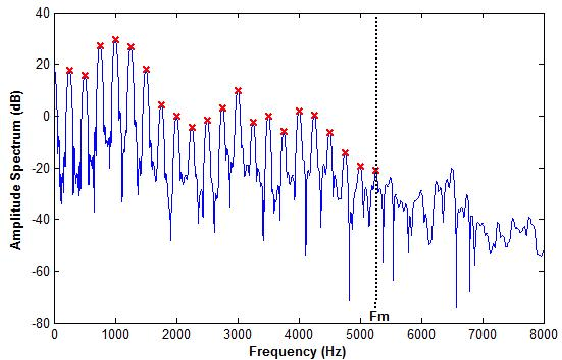
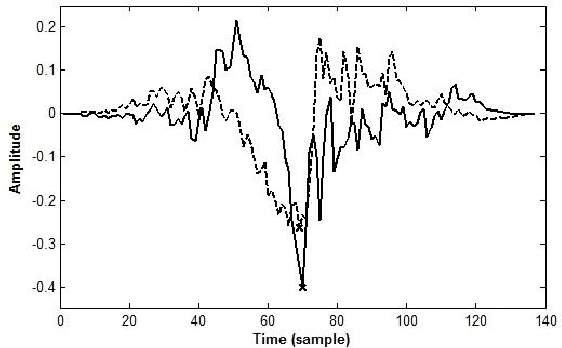
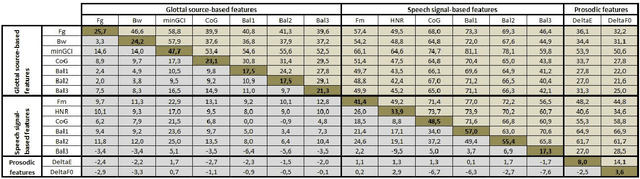
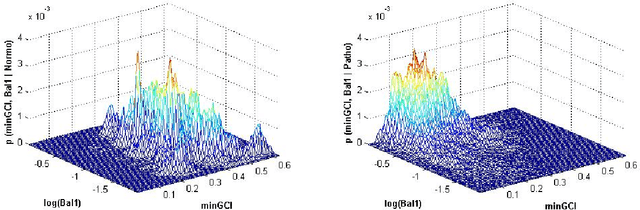
This paper addresses the problem of automatic detection of voice pathologies directly from the speech signal. For this, we investigate the use of the glottal source estimation as a means to detect voice disorders. Three sets of features are proposed, depending on whether they are related to the speech or the glottal signal, or to prosody. The relevancy of these features is assessed through mutual information-based measures. This allows an intuitive interpretation in terms of discrimation power and redundancy between the features, independently of any subsequent classifier. It is discussed which characteristics are interestingly informative or complementary for detecting voice pathologies.
Self-supervised Point Cloud Prediction Using 3D Spatio-temporal Convolutional Networks
Oct 18, 2021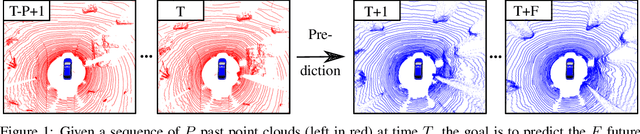
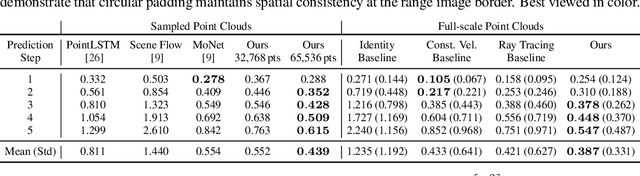
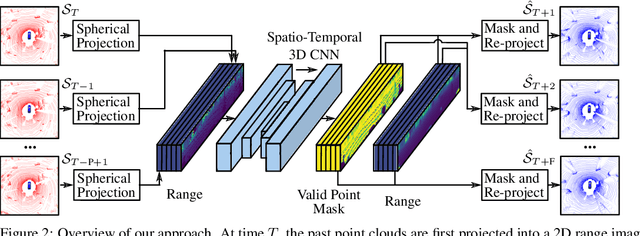
Exploiting past 3D LiDAR scans to predict future point clouds is a promising method for autonomous mobile systems to realize foresighted state estimation, collision avoidance, and planning. In this paper, we address the problem of predicting future 3D LiDAR point clouds given a sequence of past LiDAR scans. Estimating the future scene on the sensor level does not require any preceding steps as in localization or tracking systems and can be trained self-supervised. We propose an end-to-end approach that exploits a 2D range image representation of each 3D LiDAR scan and concatenates a sequence of range images to obtain a 3D tensor. Based on such tensors, we develop an encoder-decoder architecture using 3D convolutions to jointly aggregate spatial and temporal information of the scene and to predict the future 3D point clouds. We evaluate our method on multiple datasets and the experimental results suggest that our method outperforms existing point cloud prediction architectures and generalizes well to new, unseen environments without additional fine-tuning. Our method operates online and is faster than the common LiDAR frame rate of 10 Hz.
Guiding Query Position and Performing Similar Attention for Transformer-Based Detection Heads
Aug 22, 2021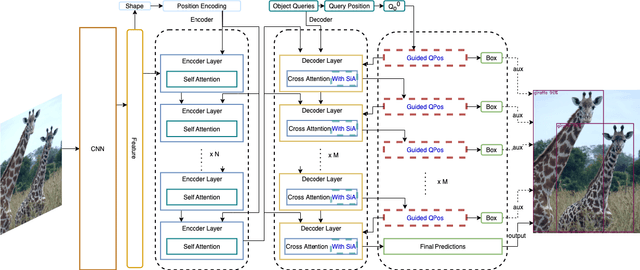
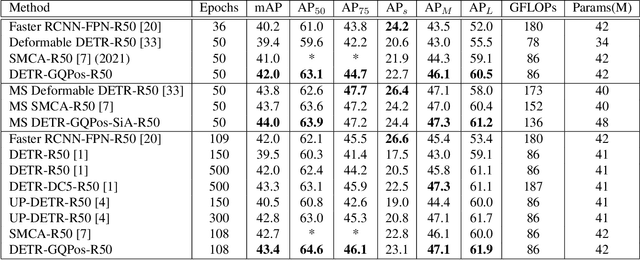
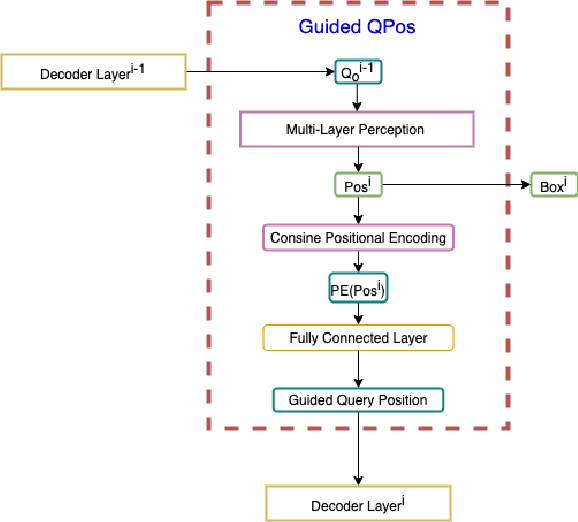
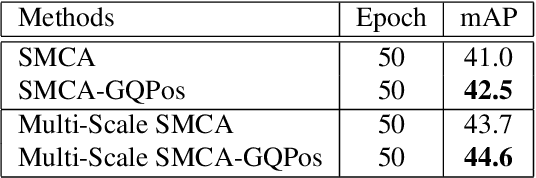
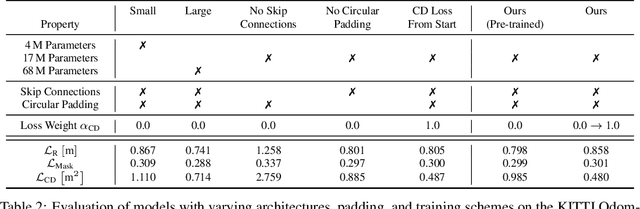
After DETR was proposed, this novel transformer-based detection paradigm which performs several cross-attentions between object queries and feature maps for predictions has subsequently derived a series of transformer-based detection heads. These models iterate object queries after each cross-attention. However, they don't renew the query position which indicates object queries' position information. Thus model needs extra learning to figure out the newest regions that query position should express and need more attention. To fix this issue, we propose the Guided Query Position (GQPos) method to embed the latest location information of object queries to query position iteratively. Another problem of such transformer-based detection heads is the high complexity to perform attention on multi-scale feature maps, which hinders them from improving detection performance at all scales. Therefore we propose a novel fusion scheme named Similar Attention (SiA): besides the feature maps is fused, SiA also fuse the attention weights maps to accelerate the learning of high-resolution attention weight map by well-learned low-resolution attention weight map. Our experiments show that the proposed GQPos improves the performance of a series of models, including DETR, SMCA, YoloS, and HoiTransformer and SiA consistently improve the performance of multi-scale transformer-based detection heads like DETR and HoiTransformer.
Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection
Aug 10, 2021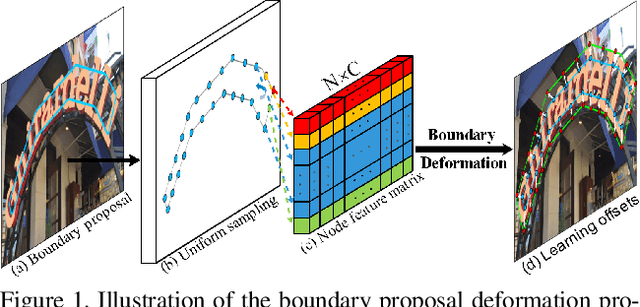
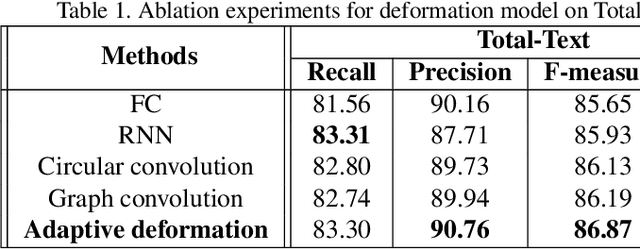
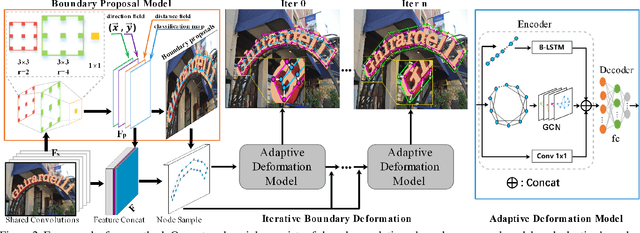
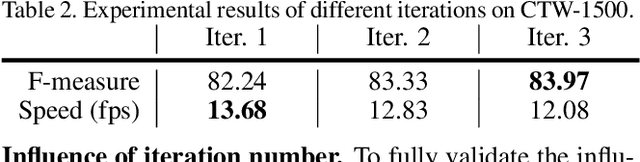
Arbitrary shape text detection is a challenging task due to the high complexity and variety of scene texts. In this work, we propose a novel adaptive boundary proposal network for arbitrary shape text detection, which can learn to directly produce accurate boundary for arbitrary shape text without any post-processing. Our method mainly consists of a boundary proposal model and an innovative adaptive boundary deformation model. The boundary proposal model constructed by multi-layer dilated convolutions is adopted to produce prior information (including classification map, distance field, and direction field) and coarse boundary proposals. The adaptive boundary deformation model is an encoder-decoder network, in which the encoder mainly consists of a Graph Convolutional Network (GCN) and a Recurrent Neural Network (RNN). It aims to perform boundary deformation in an iterative way for obtaining text instance shape guided by prior information from the boundary proposal model. In this way, our method can directly and efficiently generate accurate text boundaries without complex post-processing. Extensive experiments on publicly available datasets demonstrate the state-of-the-art performance of our method.
* 10 pages, 8 figures, Accepted by ICCV2021
Intrusion-Free Graph Mixup
Oct 18, 2021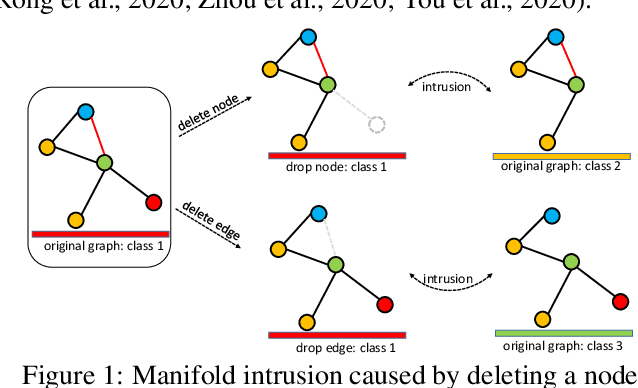
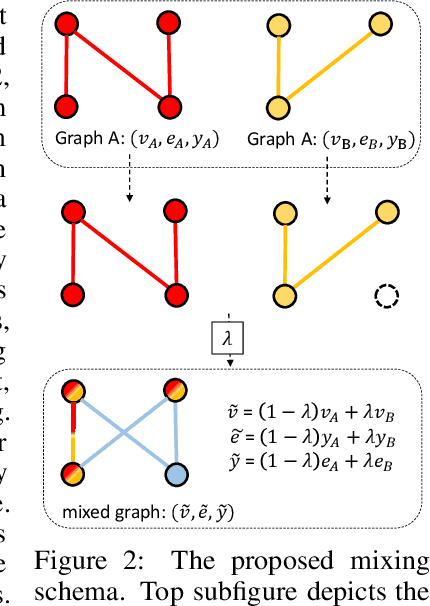
We present a simple and yet effective interpolation-based regularization technique to improve the generalization of Graph Neural Networks (GNNs). We leverage the recent advances in Mixup regularizer for vision and text, where random sample pairs and their labels are interpolated to create synthetic samples for training. Unlike images or natural sentences, which embrace a grid or linear sequence format, graphs have arbitrary structure and topology, which play a vital role on the semantic information of a graph. Consequently, even simply deleting or adding one edge from a graph can dramatically change its semantic meanings. This makes interpolating graph inputs very challenging because mixing random graph pairs may naturally create graphs with identical structure but with different labels, causing the manifold intrusion issue. To cope with this obstacle, we propose the first input mixing schema for Mixup on graph. We theoretically prove that our mixing strategy can recover the source graphs from the mixed graph, and guarantees that the mixed graphs are manifold intrusion free. We also empirically show that our method can effectively regularize the graph classification learning, resulting in superior predictive accuracy over popular graph augmentation baselines.
Analyzing Bias in Sensitive Personal Information Used to Train Financial Models
Nov 09, 2019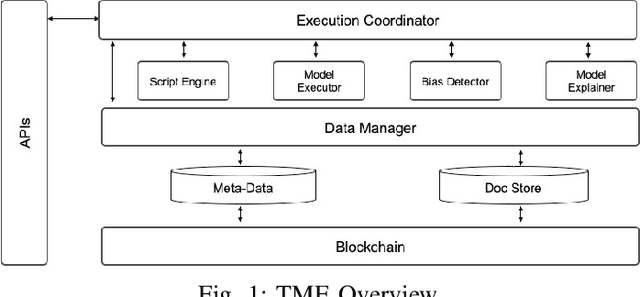
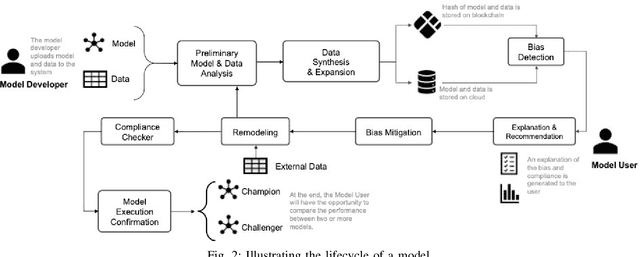
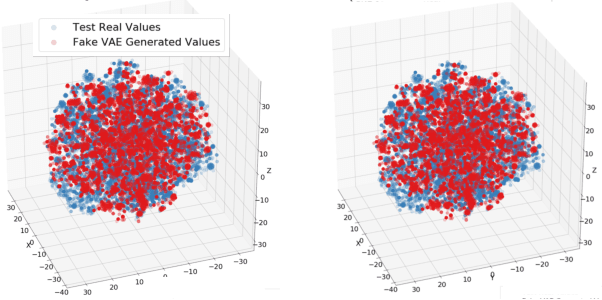
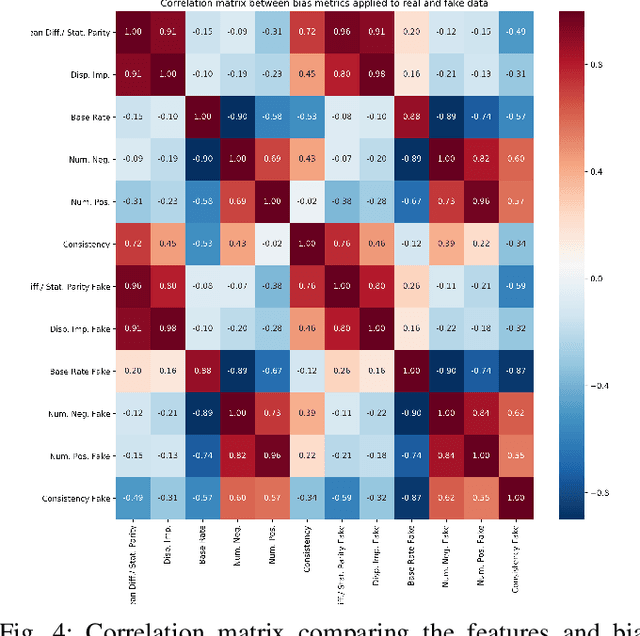
Bias in data can have unintended consequences that propagate to the design, development, and deployment of machine learning models. In the financial services sector, this can result in discrimination from certain financial instruments and services. At the same time, data privacy is of paramount importance, and recent data breaches have seen reputational damage for large institutions. Presented in this paper is a trusted model-lifecycle management platform that attempts to ensure consumer data protection, anonymization, and fairness. Specifically, we examine how datasets can be reproduced using deep learning techniques to effectively retain important statistical features in datasets whilst simultaneously protecting data privacy and enabling safe and secure sharing of sensitive personal information beyond the current state-of-practice.